公共资源速递
9 个公共数据集:
-
THINGS-EEG 脑电图数据集
-
THINGS-MEG 脑磁图数据集
-
RoVid-X 机器人视频生成数据集
-
THINGS-fMRI 磁共振成像数据集
* RubricHub_v1 多领域生成任务数据集
* CL-bench 上下文学习评估基准数据集
-
DeepPlanning 长期规划能力评估数据集
-
Google Streetview 国家街景图像数据集
-
Nemotron-Personas-Brazil 巴西合成角色数据集
5 个公共教程:
- DeepSeek-OCR-2 视觉因果流
* vLLM+Open WebUI 部署 GLM-4.7-Flash
-
PaddleOCR-VL-1.5:基于 vLLM 的本地 OCR
-
TurboDiffusion:图像与文本驱动视频生成系统
-
LightOnOCR-2-1B 轻量级高性能端到端 OCR 模型
访问官网立即使用: openbayes.com
公共数据集
1. THINGS-EEG 脑电图数据集
THINGS-EEG 是一个面向物体认知研究的脑电图数据集,记录了 50 名受试者在观看物体图像时的脑电活动(EEG),用于分析物体加工的时间动态与认知表征。
在线使用:
2. THINGS-MEG 脑磁图数据集
THINGS-MEG 是一个面向物体认知研究的脑磁图(MEG)数据集,记录了受试者观看物体图像时的毫秒级脑电磁活动,用于分析物体加工过程的时间动态。
在线使用:
3. RoVid-X 机器人视频生成数据集
该数据集包含约 4,000,000 段机器人的视频片段,总时长超过 10,000 小时,涵盖 1,300 多种细粒度的机器人技能。视频提供了多模态的物理标注,包括 RGB、深度和光流信息,支持多机器人和多任务的多样性,覆盖不同的机器人类型、场景和动作技能。
在线使用:
4. THINGS-fMRI 磁共振成像数据集
THINGS-fMRI 是一个面向物体认知研究的高密度功能性磁共振成像数据集,旨在系统刻画人脑对现实世界物体的视觉与语义表征。
在线使用:
5. CL-bench 上下文学习评估基准数据集
该数据集包含 500 个复杂上下文场景,覆盖 1,899 个具体任务,并配套提供 31,607 条细粒度评估准则。每个任务以多轮对话形式组织,涵盖规则推理、领域知识学习、复杂指令理解等多种上下文学习场景,评估模型对上下文中新信息的理解、归纳与迁移能力。
在线使用:
6. RubricHub_v1 多领域生成任务数据集
该数据集提供基于评分标准的高质量监督,用于开放式生成任务。数据集通过自动化的粗到细评分标准生成框架构建,整合了原则引导合成、多模型聚合和难度演变等策略,以产生全面且高度区分的评价标准。
在线使用:
7. DeepPlanning 长期规划能力评估数据集
该数据集包含多日旅行规划任务(Travel Planning)和多商品购物规划任务(Shopping Planning)两类任务。其中,旅行规划任务共包含 120 个独立任务样例,提供中英文版本,涵盖交通、住宿、景点、时间表和费用等信息的结构化背景数据。购物规划任务包含 120 个英文独立任务样例,涵盖商品价格、库存、优惠规则及预算约束等信息,平均约 170 条记录。
在线使用:
8. Google Streetview 国家街景图像数据集
Google Streetview 是一个涵盖多个国家的街景图像数据集,图像文件名中包含创建日期和地图名称,每个国家的图像都单独放置在相应的文件夹中。数据集构成:各个国家单独的文件夹,图像文件名包含创建日期和地图名称。
在线使用:

数据集示例
9. Nemotron-Personas-Brazil 巴西合成角色数据集
该数据集包括区域多样性、种族背景、教育水平及职业分布,共有 1,000,000 条记录,每条记录包含 6 个合成人物,每条数据包括 6 个角色字段和 14 个上下文字段,这些字段在统计上基于巴西官方人口结构和劳动市场分布构建。数据覆盖巴西所有 26 个州及联邦区的地理和人口分布。
在线使用:
公共教程
1. DeepSeek-OCR-2 视觉因果流
DeepSeek-OCR-2 通过引入 DeepEncoder V2 架构,实现从固定扫描到语义推理的范式转变。模型采用因果流查询和双流注意力机制,能动态重排视觉 Token,更精准地还原复杂文档的自然阅读逻辑。在 OmniDocBench v1.5 评测中,模型综合得分达到 91.09%,较前代提升显著,同时显著降低了 OCR 识别结果的重复率,为未来构建全模态编码器提供新路径。
在线运行:

项目示例
2. vLLM+Open WebUI 部署 GLM-4.7-Flash
GLM-4.7-Flash 是智谱 AI 推出的轻量化 MoE 推理模型,兼顾高性能与高吞吐,原生支持思考链(CoT)、工具调用与 Agent 能力。它采用 Mixture of Experts(MoE)架构,通过稀疏激活机制,在保持大模型表达能力的同时,大幅降低单次推理的计算成本。
在线运行:

项目示例
3. TurboDiffusion:图像与文本驱动视频生成系统
TurboDiffusion是由清华大学团队开发的高效视频扩散生成系统。该项目基于 Wan2.1 架构进行高阶蒸馏,旨在解决大规模视频模型推理速度慢、计算资源消耗大的痛点,实现了极少步数下的高质量视频生成。该系统基于 rCM 蒸馏技术,将 14B 模型 5 秒视频的生成耗时从分钟级压缩至 2-10 秒,实现百倍以上的效率飞跃。支持 720P T2V 与 I2V 任务,在极速生成下依然保持 SOTA 级的视觉连贯性与画质。
在线运行:
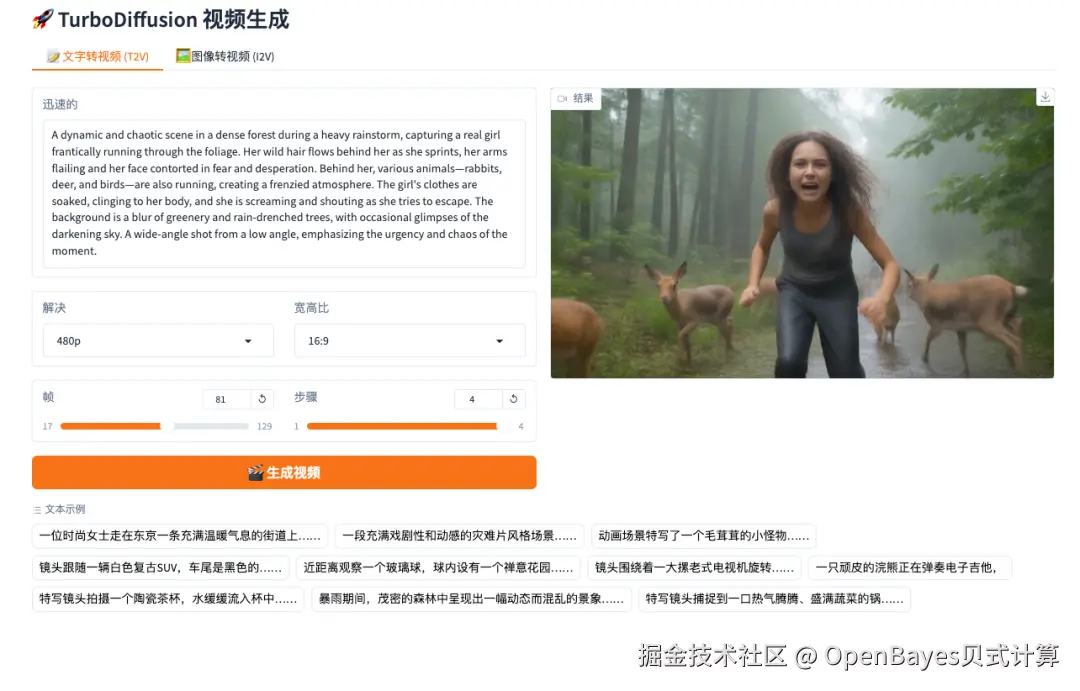
项目示例
4. LightOnOCR-2-1B 轻量级高性能端到端 OCR 模型
LightOnOCR-2-1B 是由 LightOn AI 于 2026 年 1 月推出的最新一代端到端视觉语言模型(OCR)。作为 LightOnOCR 系列中的旗舰级版本,它在一个紧凑的架构中统一了文档理解与文本生成功能,拥有 10 亿参数(1B),能够在消费级显卡(约 6GB 显存)上运行。该模型采用 Vision-Language Transformer 架构,并引入了 RLVR 训练技术,实现了极高的识别准确率与推理速度,专为需要处理复杂文档、手写体及 LaTeX 公式的应用场景设计。
在线运行:
5. PaddleOCR-VL-1.5:基于 vLLM 的本地 OCR
PaddleOCR-VL-1.5 是 PaddlePaddle 团队发布的 PaddleOCR 系列的多模态 OCR 模型之一,面向复杂文档场景(票据、合同、论文、扫描件等)提供更强的文字识别与版面理解能力。本教程使用 vLLM 的 OpenAI 兼容接口对接该模型,实现上传图片--返回识别结果的完整链路。
在线运行:
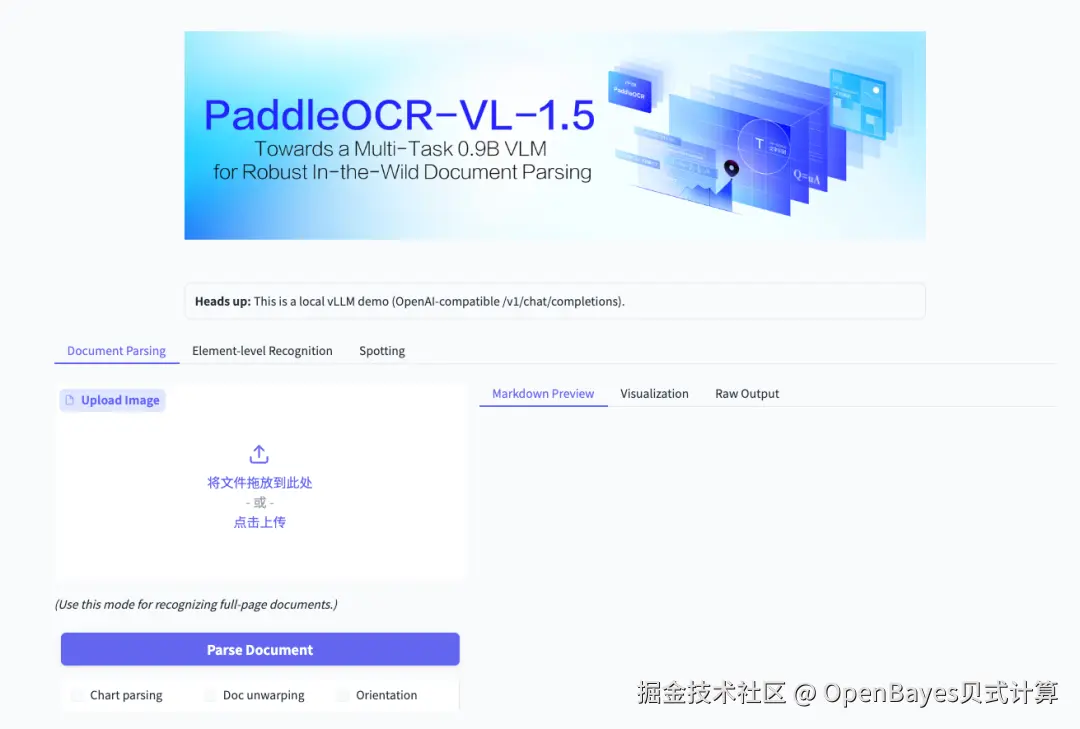
项目示例