基于DDPG算法的四旋翼飞行器内外环结构的PD控制方法,(matlab强化学习程序), 利用深度强化学习算法,对三个姿态角系统中的PD控制器总共6个参数进行自适应调节
在四旋翼飞行器控制领域,找到合适的控制参数一直是个挑战。传统的PD控制虽然简单有效,但固定的参数难以应对复杂多变的飞行环境。今天咱们来聊聊如何借助深度强化学习中的DDPG算法,对四旋翼飞行器内外环结构的PD控制参数进行自适应调节,并且看看Matlab强化学习程序是怎么实现的。
四旋翼飞行器内外环结构的PD控制基础
四旋翼飞行器控制一般采用内外环结构。外环负责计算期望的角速度,内环根据期望角速度产生实际的控制输入(电机转速等)。PD控制在其中扮演关键角色,它根据误差(期望状态与实际状态的差值)及其变化率来调整控制输出。
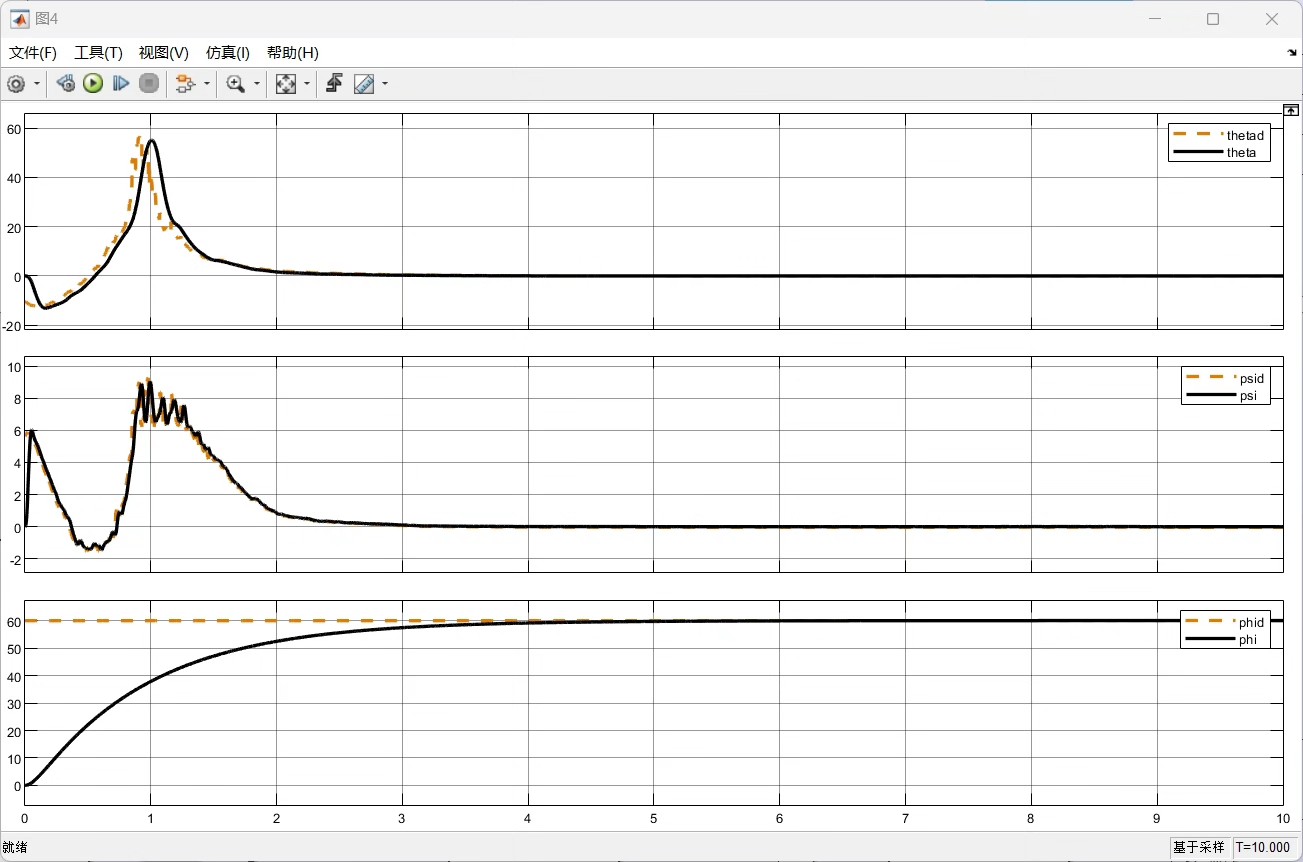
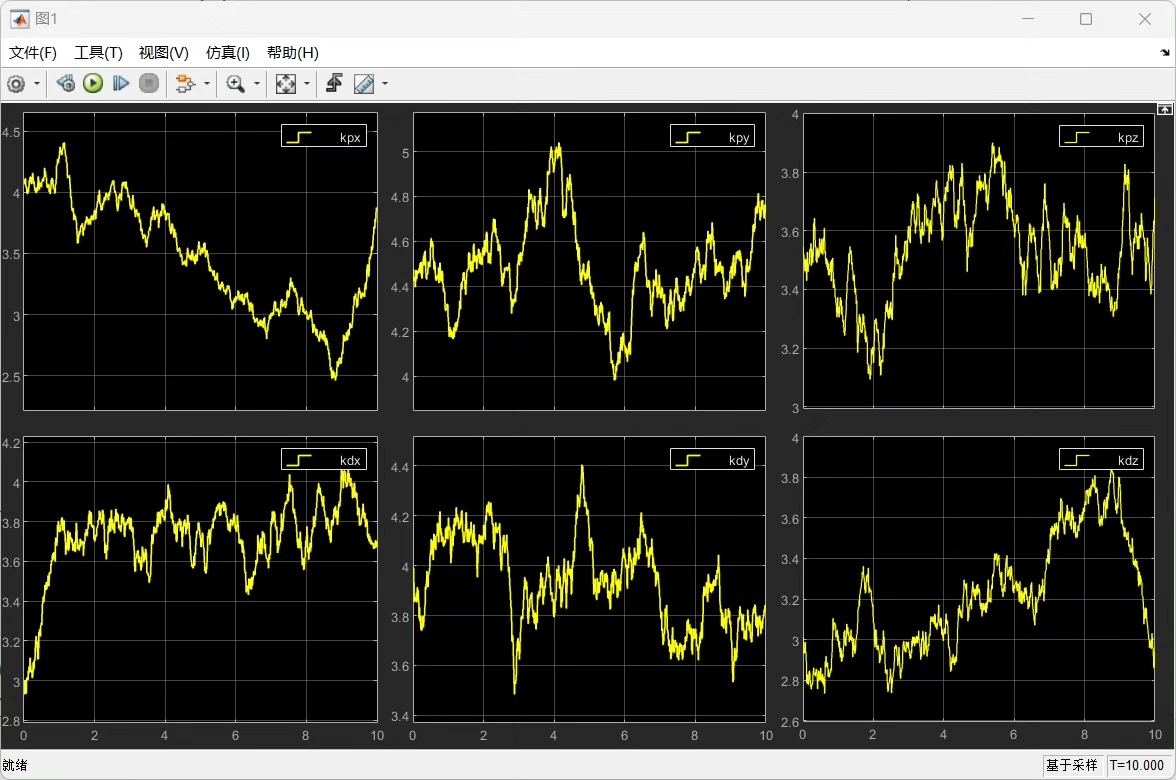
PD控制的基本公式为:u(t)=K*p e(t)+K* d \\frac{de(t)}{dt} ,其中u(t)是控制输出,K*p是比例系数,K* d是微分系数,e(t)是误差。在姿态角控制中,针对三个姿态角(俯仰角、滚转角、偏航角),总共就有6个这样的K*p和K*d参数需要调节。
DDPG算法为何能胜任参数调节
DDPG(深度确定性策略梯度)算法属于深度强化学习算法家族。它能在连续动作空间中有效学习,这正适合我们对6个PD参数的连续取值调节。它基于策略梯度,同时结合了深度神经网络来逼近值函数和策略函数。
基于DDPG算法的四旋翼飞行器内外环结构的PD控制方法,(matlab强化学习程序), 利用深度强化学习算法,对三个姿态角系统中的PD控制器总共6个参数进行自适应调节
DDPG算法中有两个关键网络:
- 评论家网络(Critic Network):用于评估当前策略下的价值,也就是预测采取某个动作后的长期累积奖励。
- 演员网络(Actor Network):负责生成动作,即产生当前状态下应该调整的PD参数值。
Matlab强化学习程序实现
环境搭建
首先,要在Matlab中搭建四旋翼飞行器的模拟环境,包括飞行器动力学模型。这可以通过自定义的函数来实现,比如定义一个quadrotor_dynamics函数:
matlab
function [state_next] = quadrotor_dynamics(state, control_input)
% 这里state包含姿态角、角速度等状态信息
% control_input是PD控制输出
% 根据动力学方程更新状态
dt = 0.01; % 时间步长
% 简单示例动力学更新,实际需要更详细推导
state_next(1) = state(1) + state(4)*dt; % 姿态角更新
state_next(4) = state(4) + control_input(1)/10; % 角速度更新
% 类似更新其他状态
end这个函数根据当前状态和控制输入,更新四旋翼飞行器的下一时刻状态。
定义DDPG网络结构
在Matlab中使用强化学习工具箱来定义演员和评论家网络。
matlab
% 定义演员网络
actorOpts = rlRepresentationOptions('LearnRate',1e-4);
actorNet = [
featureInputLayer(12,'Normalization','none','Name','state')
fullyConnectedLayer(64,'Name','fc1')
reluLayer('Name','relu1')
fullyConnectedLayer(64,'Name','fc2')
reluLayer('Name','relu2')
fullyConnectedLayer(6,'Name','fc3')
tanhLayer('Name','tanh')];
actor = rlDeterministicActorRepresentation(actorNet,[12 1],[6 1],actorOpts);
% 定义评论家网络
criticOpts = rlRepresentationOptions('LearnRate',1e-3);
criticNet = [
featureInputLayer(12,'Normalization','none','Name','state')
fullyConnectedLayer(64,'Name','fc1')
reluLayer('Name','relu1')
featureInputLayer(6,'Normalization','none','Name','action')
concatenationLayer(2,1,'Name','concat')
fullyConnectedLayer(64,'Name','fc2')
reluLayer('Name','relu2')
fullyConnectedLayer(1,'Name','fc3')];
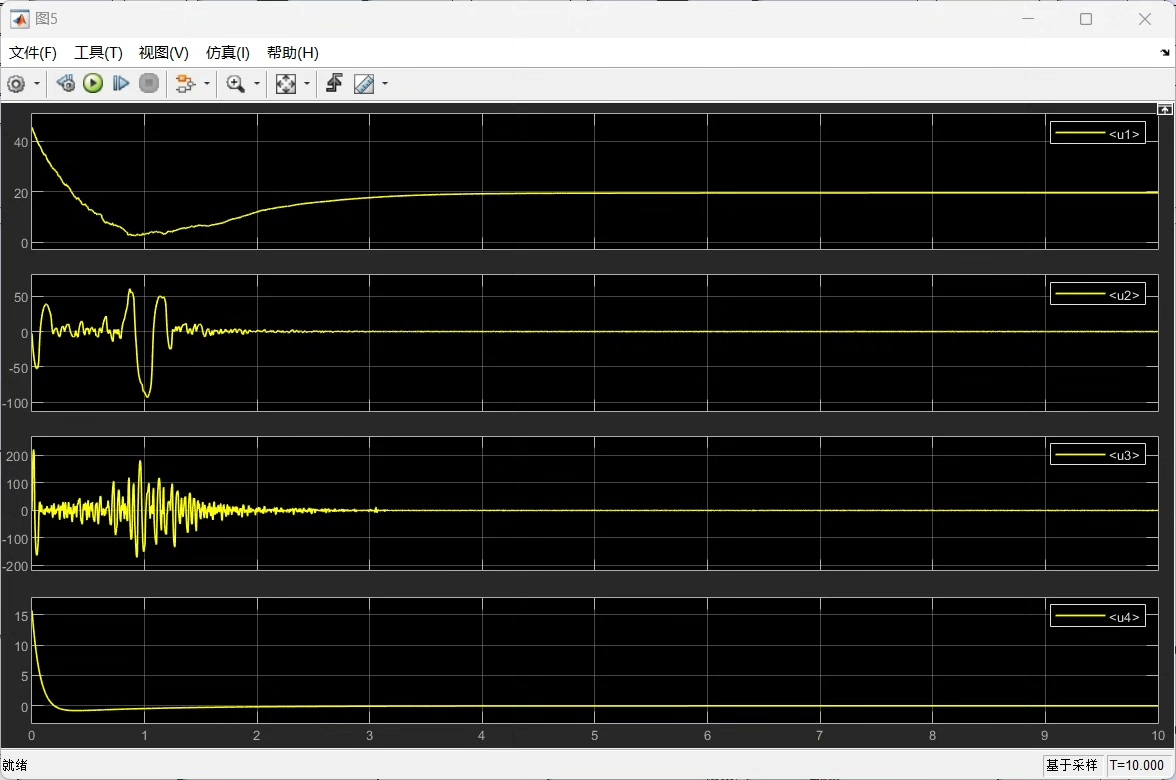
critic = rlQValueRepresentation(criticNet,[12 1],[6 1],criticOpts);这里演员网络接收12维的状态输入,输出6维的动作(对应6个PD参数),评论家网络接收状态和动作输入,输出Q值。
训练与优化
matlab
% 创建DDPG代理
agentOpts = rlDDPGAgentOptions('UseTD3',true,'SampleTime',0.01);
agent = rlDDPGAgent(actor,critic,agentOpts);
% 训练环境
env = rlFunctionEnv(@(state,action)quadrotor_env(state,action));
maxepisodes = 100;
maxsteps = 500;
trainingOpts = rlTrainingOptions('MaxEpisodes',maxepisodes,'MaxStepsPerEpisode',maxsteps,'Verbose',false);
experience = train(agent,env,trainingOpts);在这部分代码中,先创建了DDPG代理,然后定义了训练环境和训练选项,最后进行训练。训练过程中,DDPG代理会不断尝试不同的PD参数,根据环境反馈的奖励来调整策略,逐步找到更优的参数。
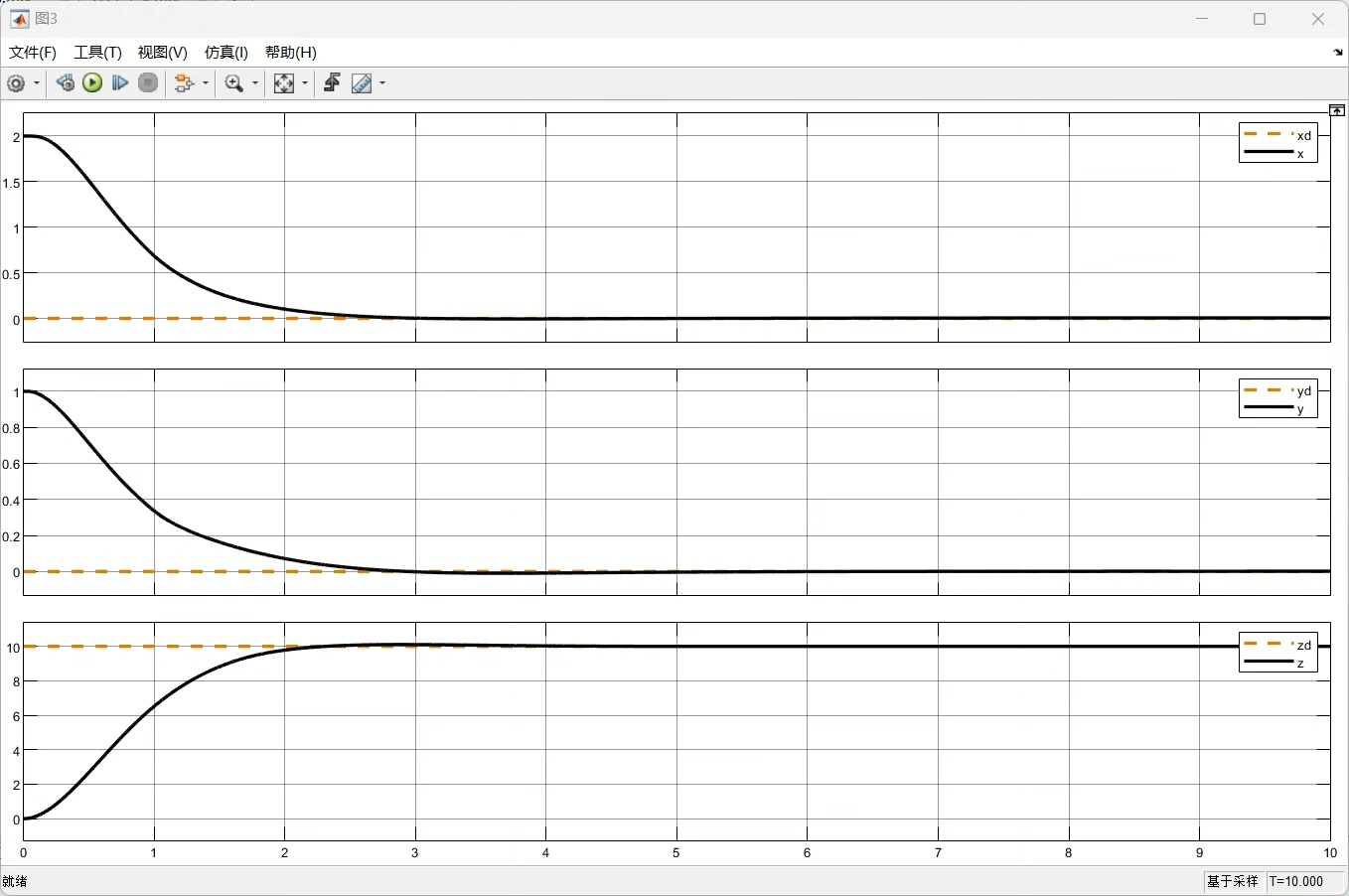
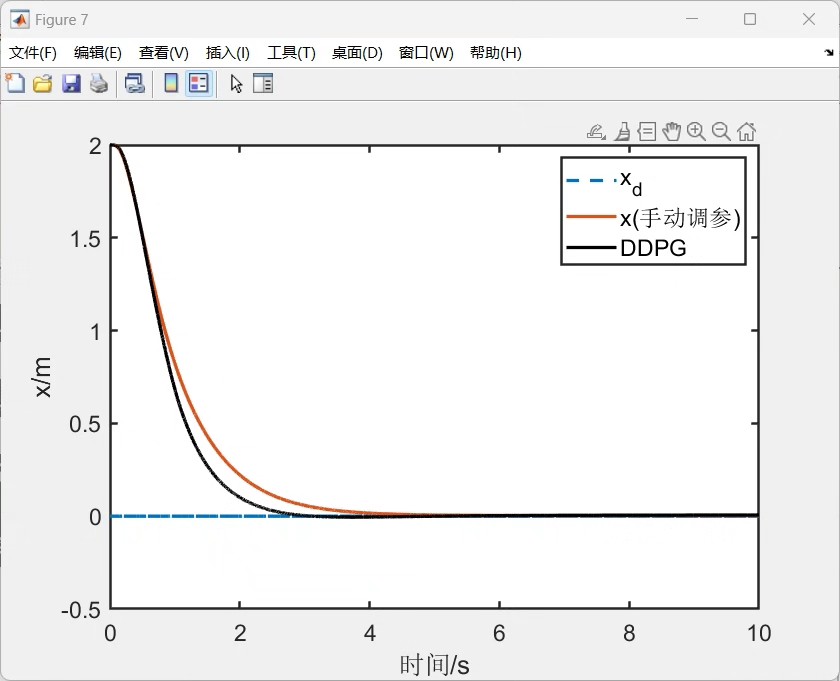
通过上述基于DDPG算法的Matlab实现,我们能有效地对四旋翼飞行器的PD控制参数进行自适应调节,提升飞行器在不同条件下的飞行性能。希望这篇博文能给研究四旋翼控制的小伙伴们一些启发。