一、下载部署
官网:https://skywalking.apache.org/
bash
version: '3.3'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch-oss:7.4.2
container_name: elasticsearch
ports:
- "9200:9200"
privileged: true
environment:
#集群发现模式为单节点模式
- discovery.type=single-node
#分配给ES的JVM内存锁定在物理内存,防止到swap交换分区影响速度
- bootstrap.memory_lock=true
#初始内存堆和最大内存堆
- "ES_JAVA_OPTS=-Xms2048m -Xmx2048m"
#内存锁定权限放行es层面,配合bootstrap.memory_lock=true系统层面开启,两者结合使用
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- /opt/skywalking/es01:/usr/share/elasticsearch/data
elastichd:
image: containerize/elastichd:latest
container_name: elasticsearch-hd
ports:
- "9800:9800"
skywalking-oap-server:
image: apache/skywalking-oap-server:9.7.0
container_name: skywalking-oap-server
depends_on:
- elasticsearch
links:
- elasticsearch
ports:
- "11800:11800"
- "12800:12800"
- "9090:9090"
privileged: true
environment:
#使用数据为es和链接地址
SW_STORAGE: elasticsearch
SW_STORAGE_ES_CLUSTER_NODES: elasticsearch:9200
#安全防护机制触发,限制了请求解析的语法令牌数量(默认15,000)
SW_CORE_GRAPHQL_MAX_TOKENS: "30000"
#健康检查
SW_HEALTH_CHECKER: default
#开启prometheus接收的健康指标
SW_TELEMETRY: prometheus
#jvm限制最大最小2G
JAVA_OPTS: "-Xms2048m -Xmx2048m"
#持续化和清理天数
SW_CORE_RECORD_DATA_TTL: 2
SW_CORE_METRICS_DATA_TTL: 2
skywalking-ui:
image: apache/skywalking-ui:9.7.0
container_name: skywalking-ui
depends_on:
- skywalking-oap-server
links:
- skywalking-oap-server
ports:
- "8080:8080"
environment:
SW_OAP_ADDRESS: http://skywalking-oap-server:12800
SW_ZIPKIN_ADDRESS: http://skywalking-oap-server:9412二、启动、验证UI界面,调用接口
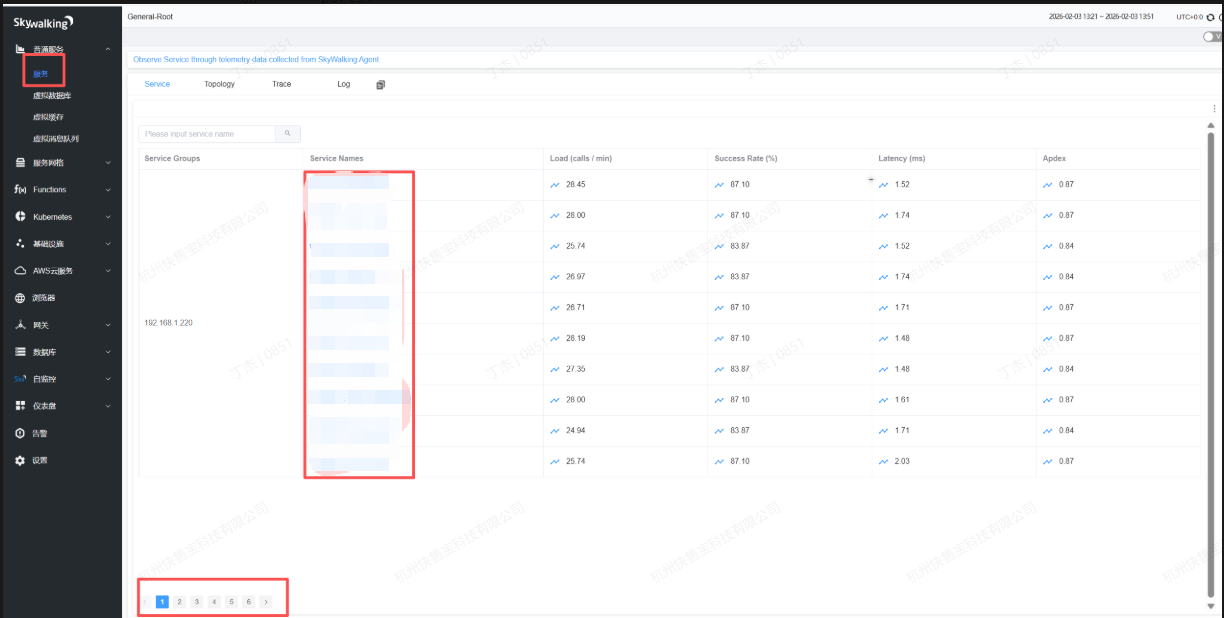
所有服务显示
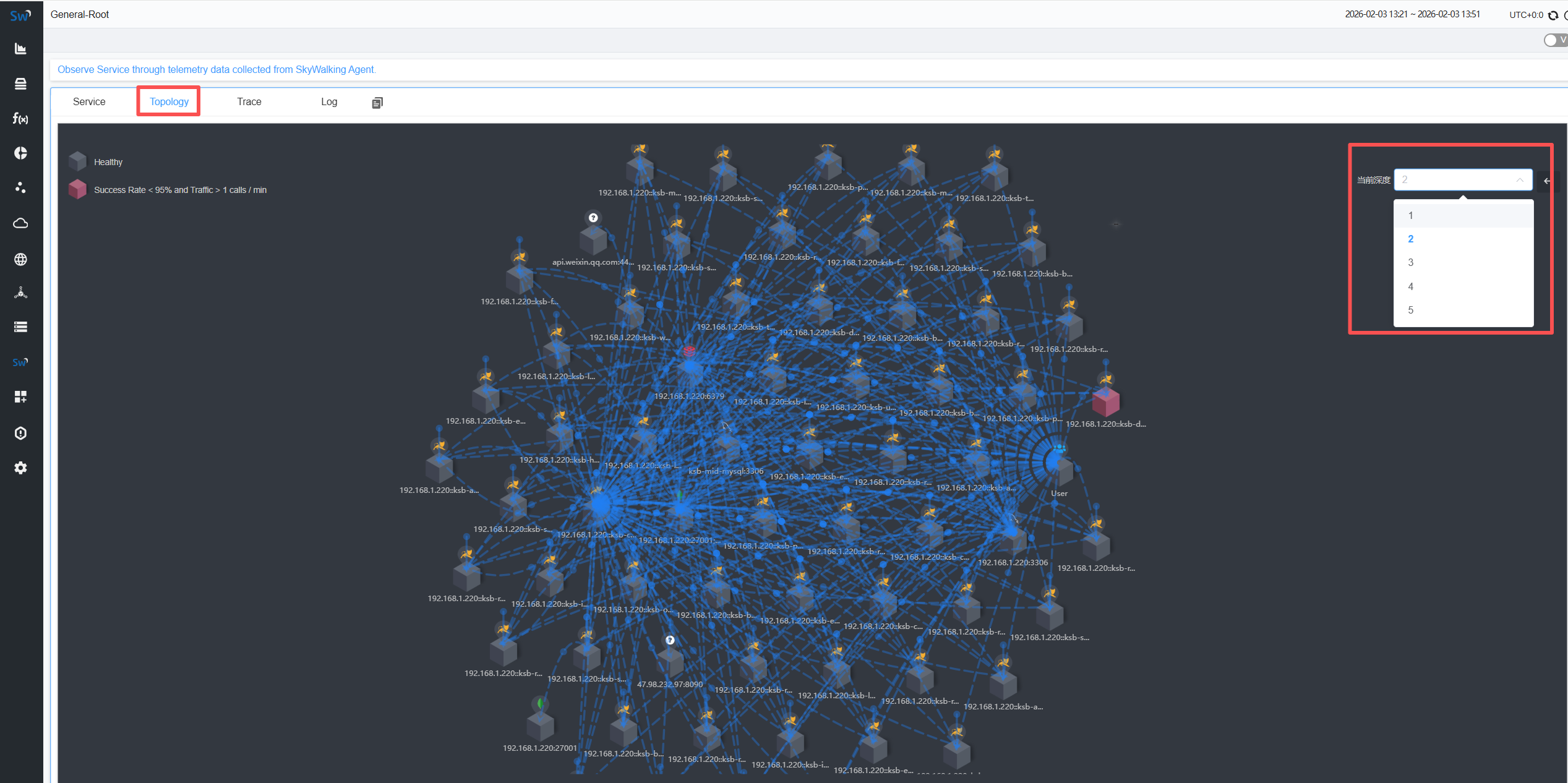
全局拓扑图
服务调用链的层级
深度 1:通常是最顶层的入口服务如网关、前端接口
深度 2:是入口服务直接调用的第一层依赖服务
深度 3:是第一层依赖服务再调用的下一层服务,以此类推
进入单服务页面
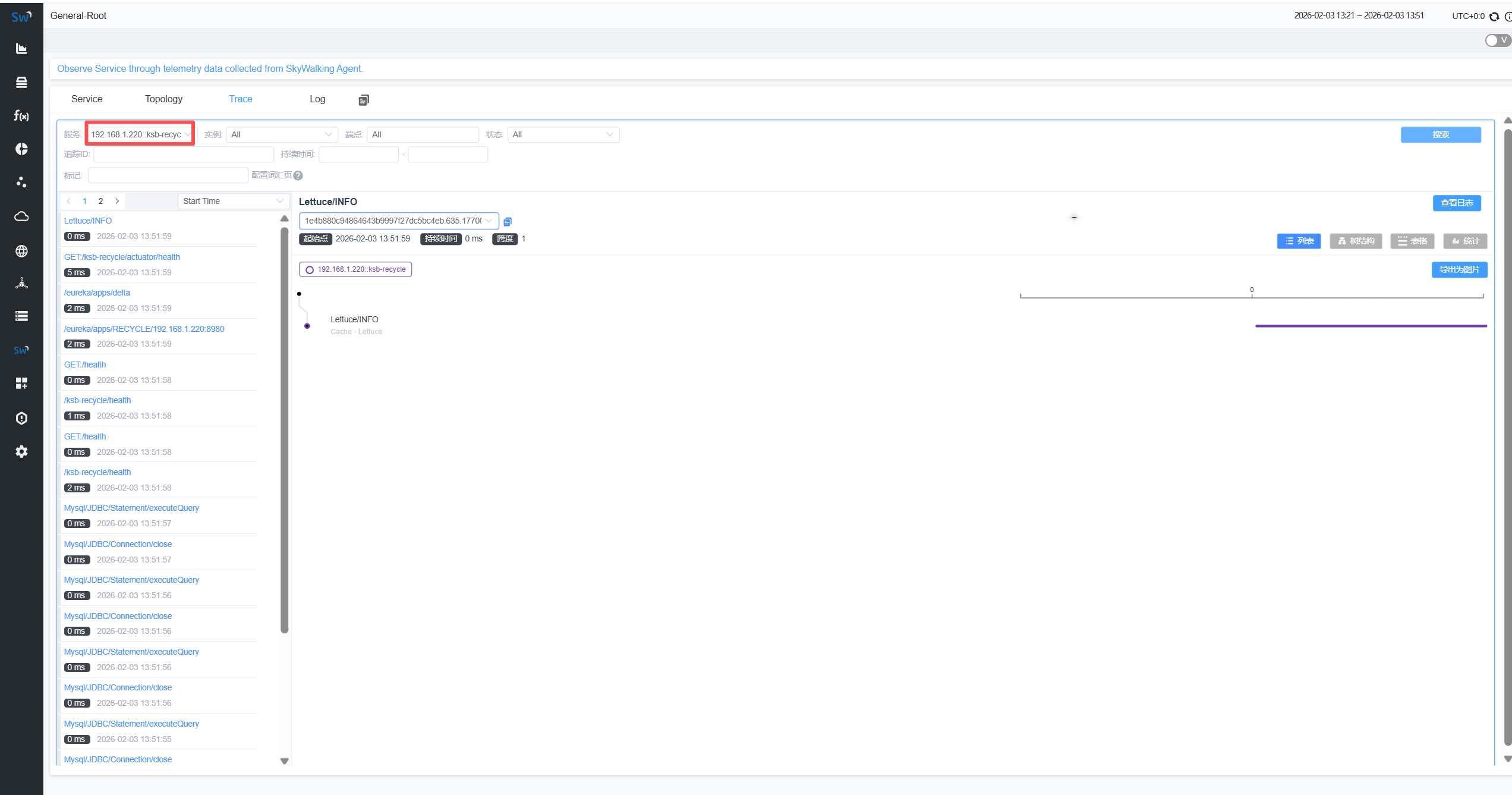 从全局service下进入
从全局service下进入
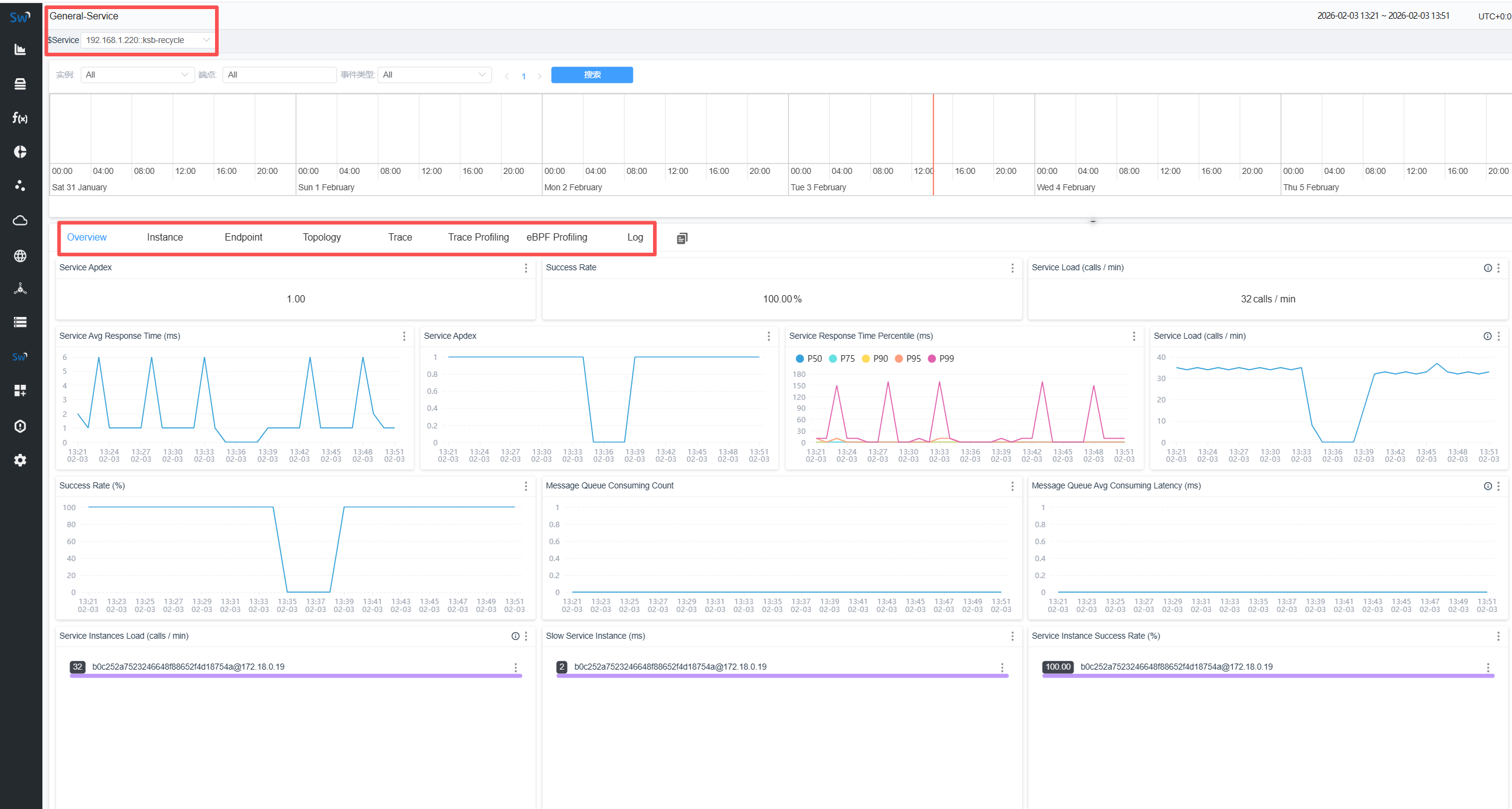
-
Overview服务的全局健康看板,
-
Instance 当服务部署了多实例时,这个标签页帮你定位是全局问题还是个别实例的问题。
-
Endpoint 这是定位具体问题的关键,能精准到单个接口的表现
-
Topology 展示当前服务与其他服务的依赖关系,帮你判断问题是来自自身还是依赖。
-
Trace(调用链)完整的调用链路追踪,深入到单次请求的内部执行细节。
-
Trace Profiling(调用链剖析)深度性能分析工具,排查复杂的性能问题。
-
eBPF Profiling(eBPF剖析)无需修改代码,就能对服务进行无侵入的性能分析。
-
Log 需要代码安装插件接入,直接在 SkyWalking 中查看服务的日志,与调用链关联分析。
1、请求接口查看数据

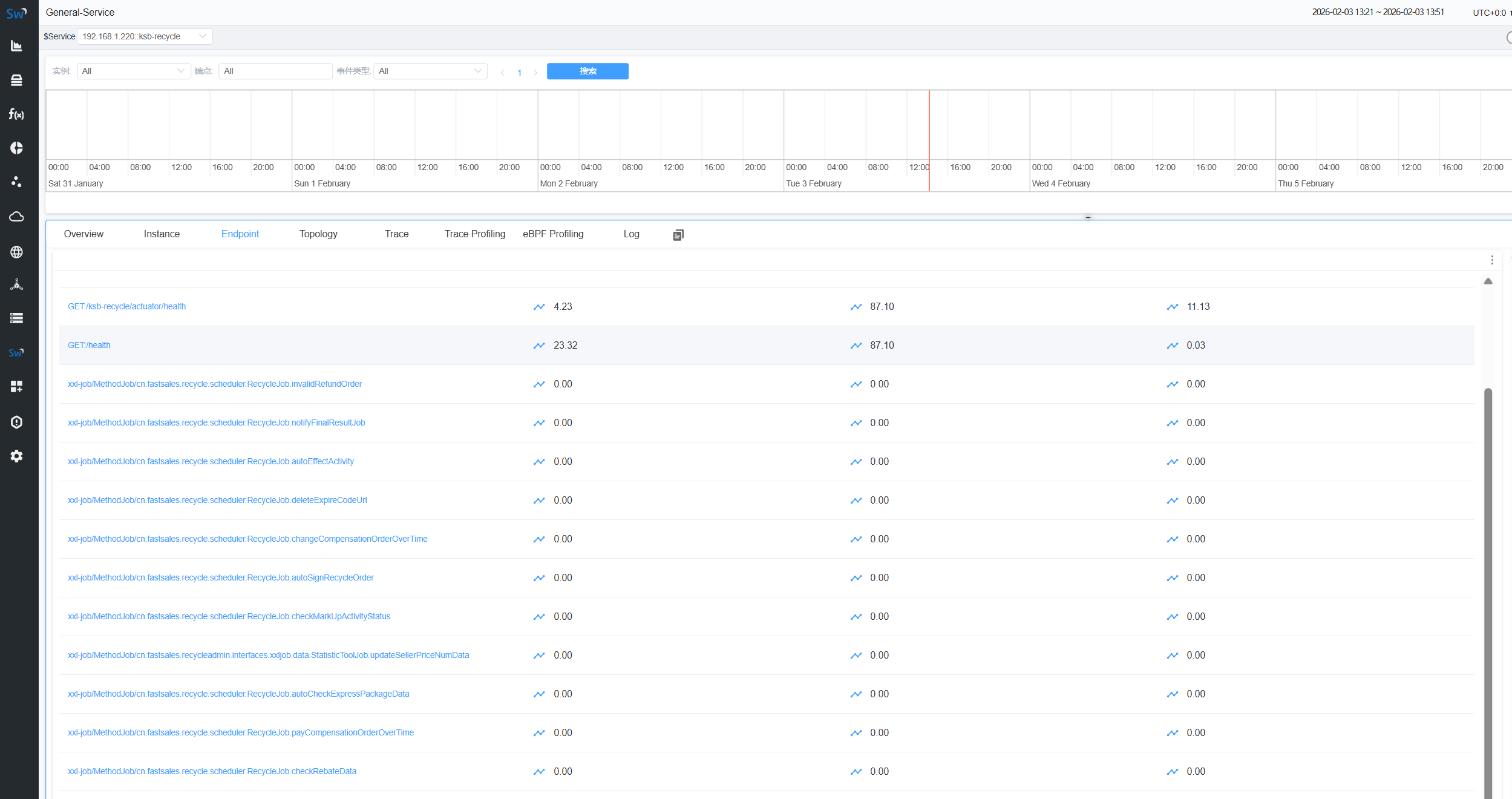
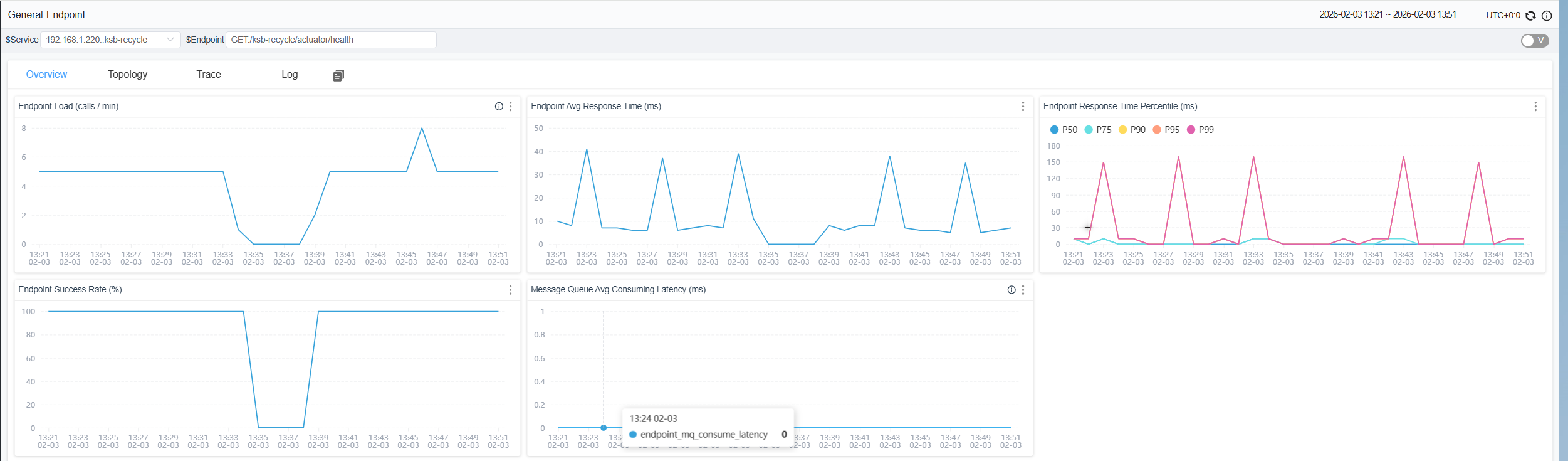
三、创建任务
想要进行性能刨析,我们必须创建一个任务
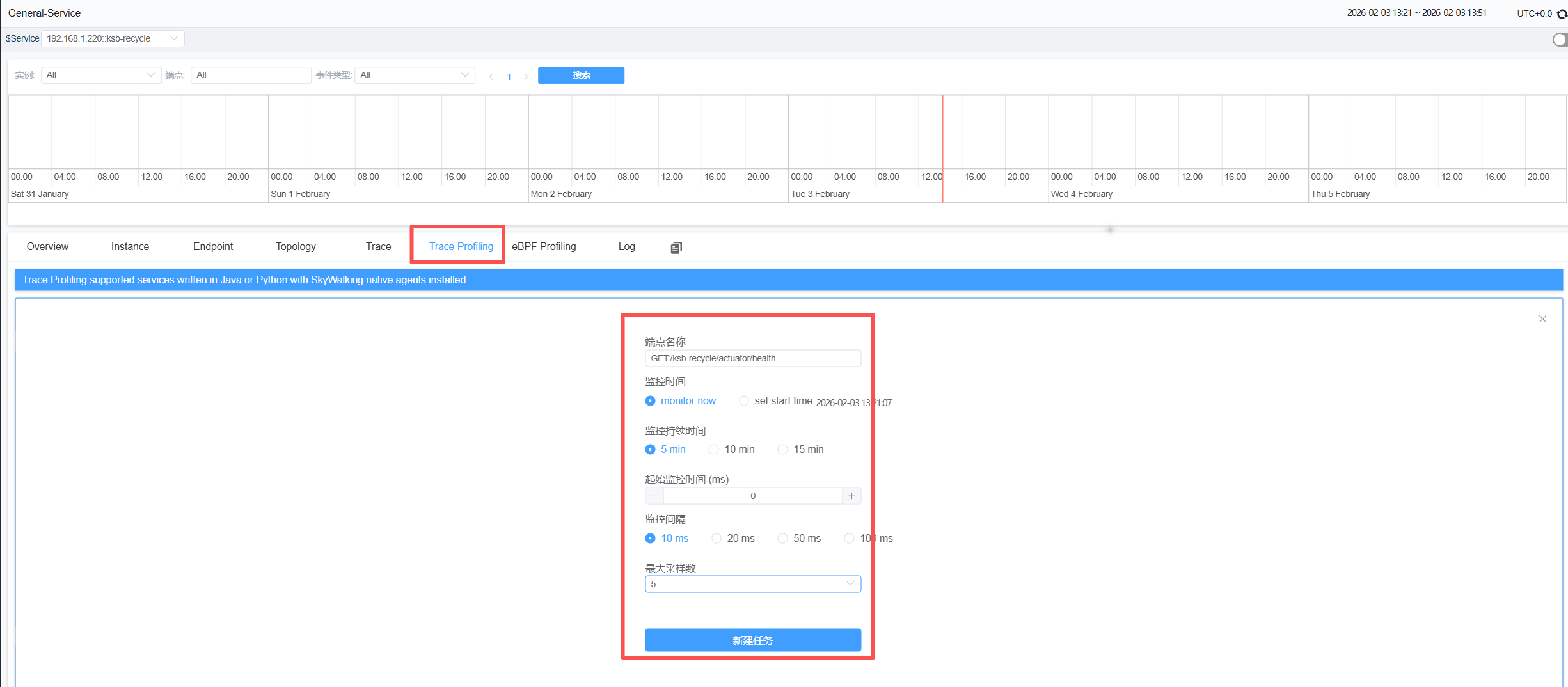
选择指定的服务。
输入端点名称,这里的端点名称通常是第一个片段(Segment)的操作名,在追踪页面的追踪(Trace)视图里可以找到。
选择监控时间,可以从现在开始,也可以从未来的任何时间开始。
选择监视持续时间,可以设置监视的时间窗口,以查找到合适的请求进行性能刨析。
监控间隔,提供了一个过滤器机制,如果给定端点响应的请求很快,它就不会性能刨析,可以确保性能刨析的数据是预期的数据。
最大采样数,表示探针收集的最大数据集,它有助于减少内存和网络负载。
即使性能刨析对目标系统的性能影响非常有限,但它仍然是一个额外的负载,以上设置可以使性能影响可控。另外,在任何时刻,每个服务只能执行一个性能刨析任务。
1、分析结果
等待性能刨析的任务完成后,对应的片段(Segment)就会在右侧展示出来。点击某个片段(Segment),可以更详细地看到各个片段(Segment)的耗时
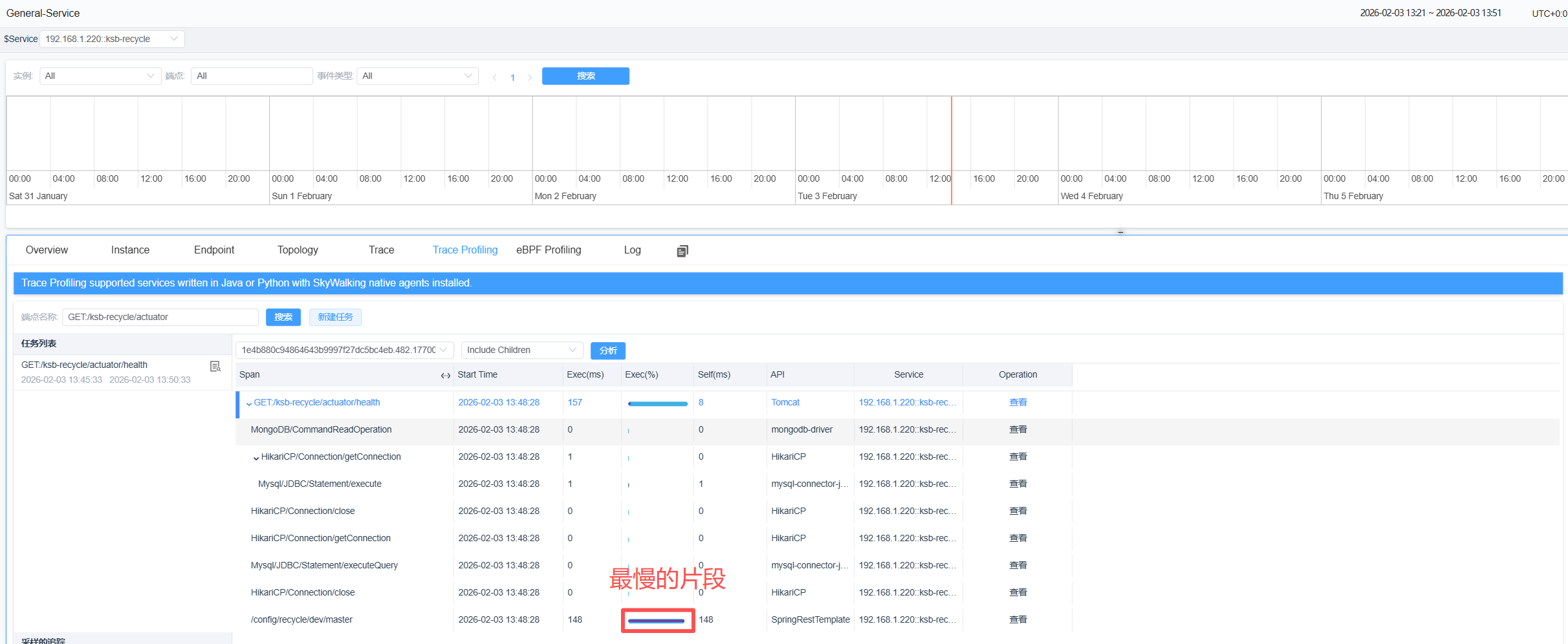
从上图可以看到最慢的片段(Segment)。点击分析按钮,可以看到基于方法栈的分析结果,包括对应的类名、方法名、代码行数、耗时等信息,最慢的方法栈被高亮显示
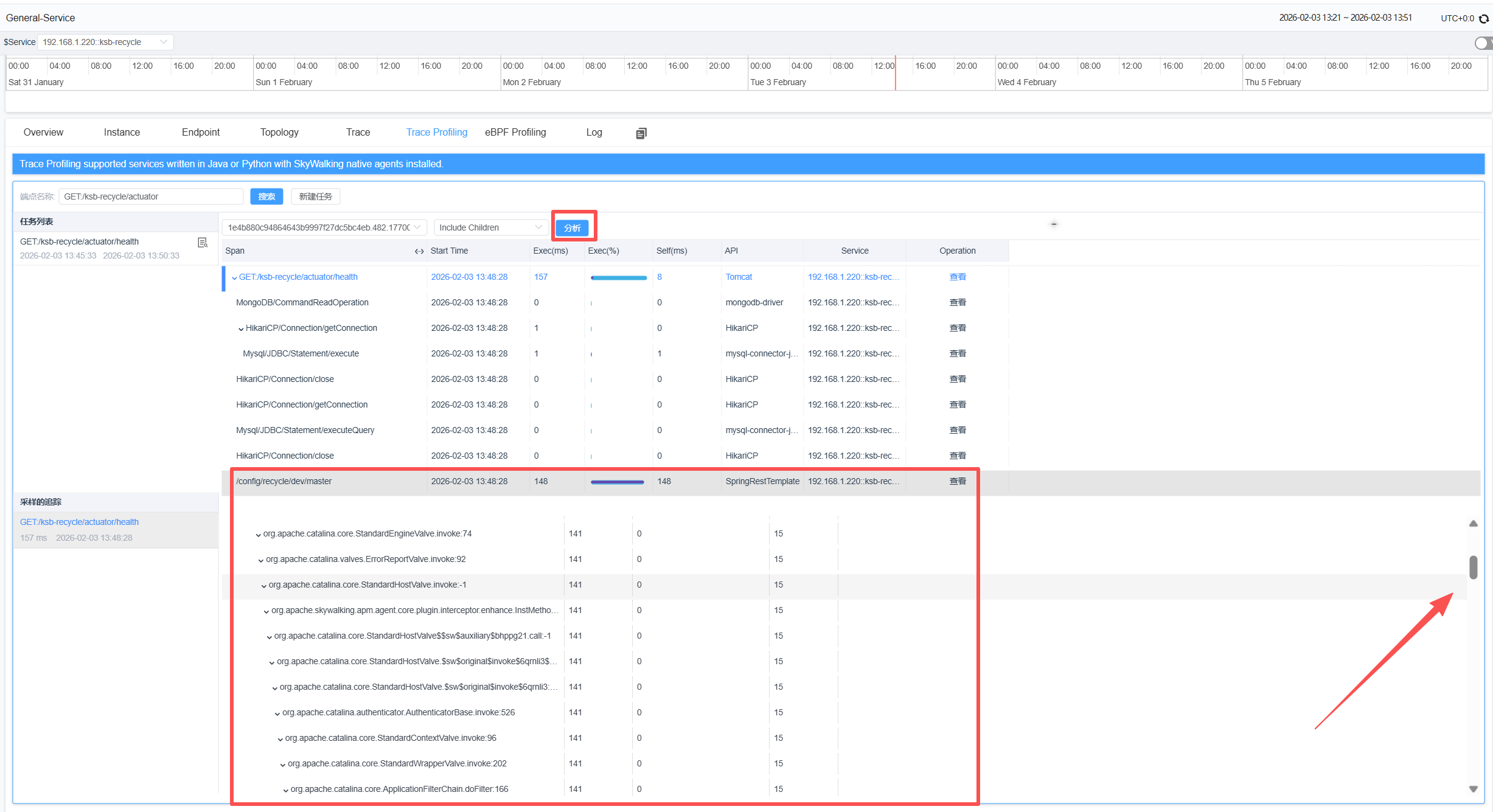
2、性能剖析的优势
精确的问题定位,直接找到代码方法和代码行;
无需反复的增删埋点,大大减少了人力开发成本;
不用承担过多埋点对目标系统和监控系统的压力和性能风险;
按需使用,平时对系统无消耗,使用时的消耗稳定可控。
四、自定义仪表盘
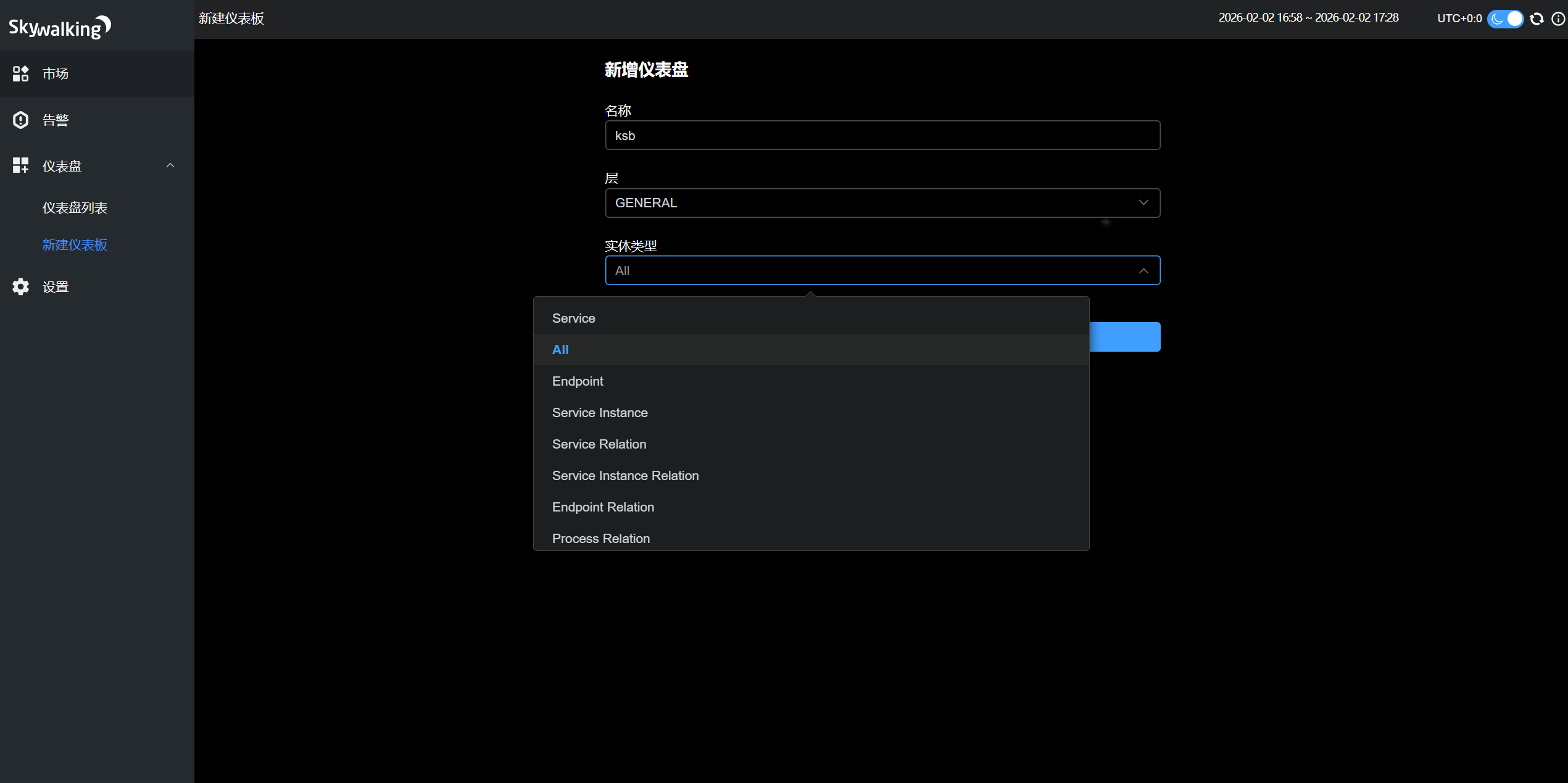
1、创建全局总览仪表盘
层:general
实体类型: all
看到所有 50-60 个服务的健康度、调用量和成功率。
在 Topology标签页可以看到整个系统的完整依赖关系,非常适合做全局容量评估和架构梳理。
2、创建单独仪表盘
层:general
实体类型:service
为这些服务创建:核心业务服务订单、支付、流量入口网关、性能敏感和问题频发的服务
查看单个服务的详细指标,如接口耗时、实例状态。
方便快速定位特定服务的性能瓶颈或错误根源。
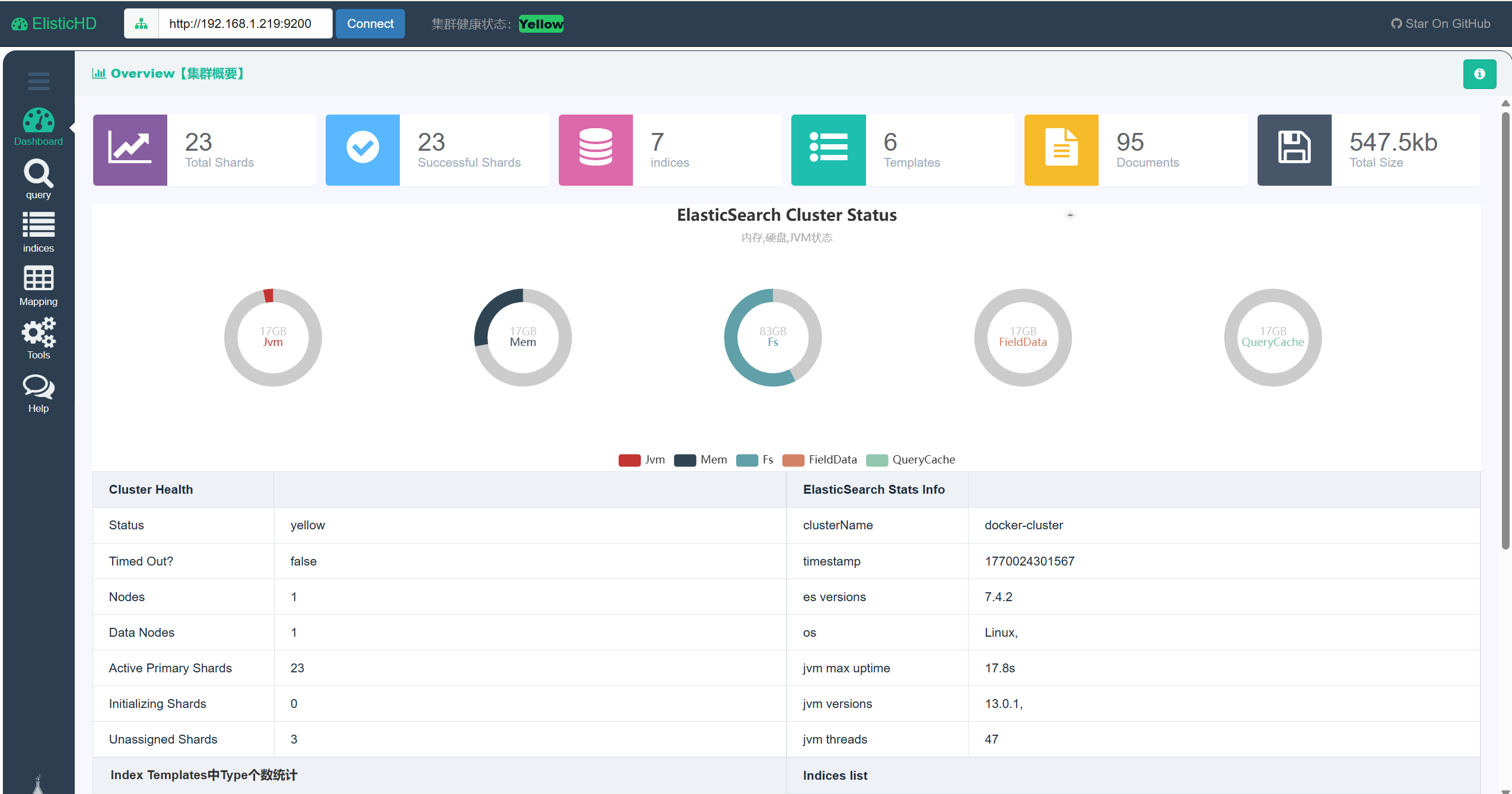
五、页面es数据库可视化
六、接入日志
1、引入依赖
在logback-spring.xml中配置
bash
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>${skywalking.version}</version>
</dependency>
bash
<!-- skywalking采集日志 -->
<appender name="grpc-log" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>- [%tid] -%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(%level){blue} %clr(${PID}){magenta} %clr([%thread]){orange} %clr(%logger){cyan} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}</pattern>
</layout>
</encoder>
</appender>