📖标题:Unmasking Reasoning Processes: A Process-aware Benchmark for Evaluating Structural Mathematical Reasoning in LLMs
🌐来源:arXiv, 2602.00564v1
🌟摘要
最近的大型语言模型(LLM)在许多已建立的数学推理基准上都达到了接近饱和的精度,这引起了人们对其诊断真正推理能力的担忧。这种饱和很大程度上源于现有数据集中基于模板的计算和浅层算术分解的主导地位,这低估了多约束协调、建设性逻辑综合和空间推理等推理技能。为了弥补这一差距,我们引入了REASONINGMATH-PLUS,这是一个由150个精心策划的问题组成的基准,旨在评估结构推理。每个问题都强调相互作用约束下的推理、建设性解决方案的形成或非平凡的结构洞察力,并用最小推理框架进行注释,以支持细粒度的过程级评估。除了数据集,我们还引入了HCRS(基于危险感知链的规则得分),这是一个确定性的步骤级评分函数,并在带注释的推理轨迹上训练了一个过程奖励模型(PRM)。经验上,虽然领先的模型获得了相对较高的最终答案准确性(高达5.8/10),但基于HCRS的整体评估产生的分数要低得多(平均4.36/10,最佳5.14/10),表明只有答案的指标会高估推理的稳健性。
🛎️文章简介
🔸研究问题:如何有效评估大语言模型在数学推理中是否具备真实的结构性推理能力,而非仅依赖模板计算或浅层算术分解?
🔸主要贡献:论文提出REASONINGMATH-PLUS基准与HCRS+PRM双轨评估框架,首次实现基于最小推理骨架的过程级、结构敏感型数学推理诊断。
📝重点思路
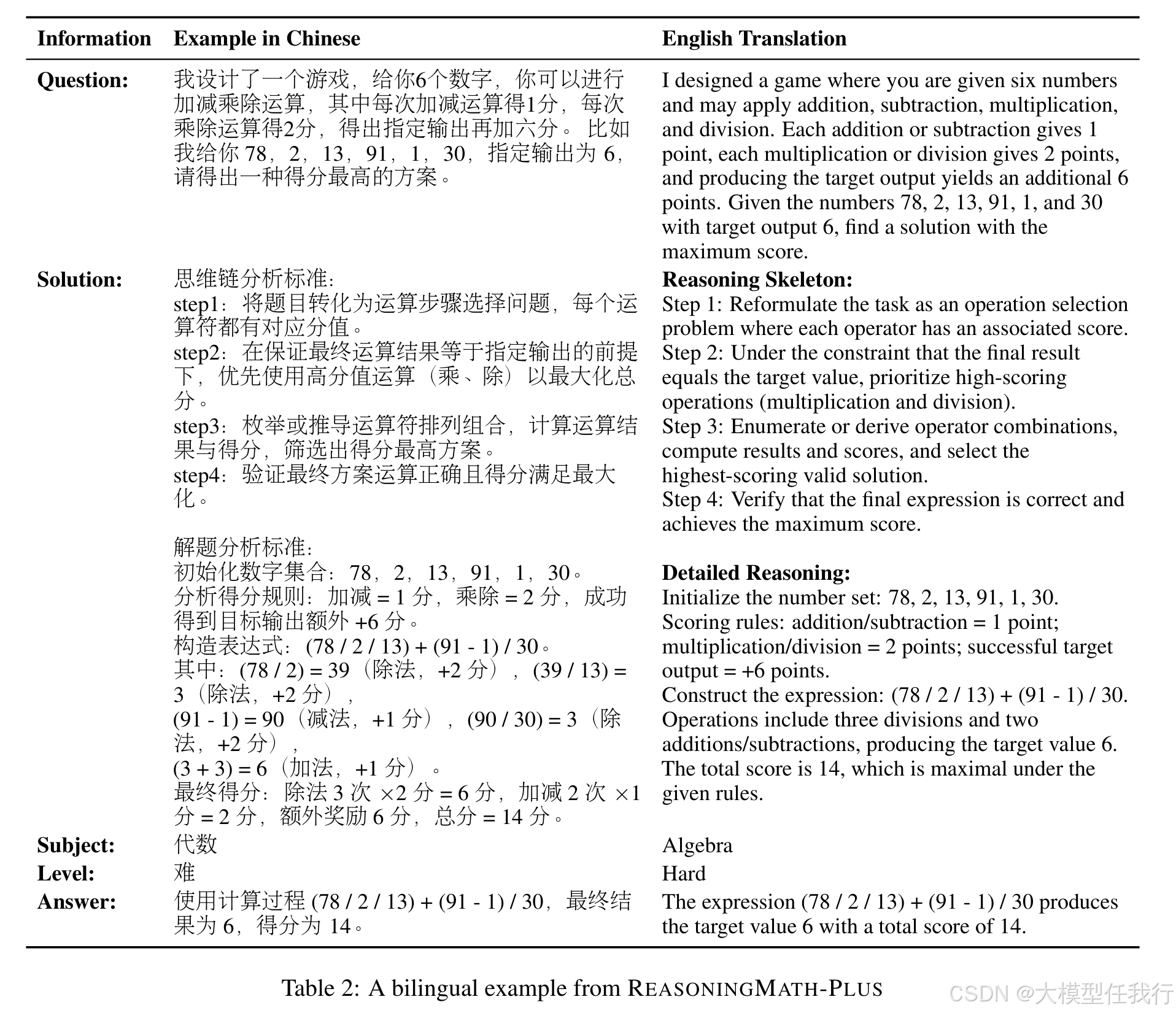
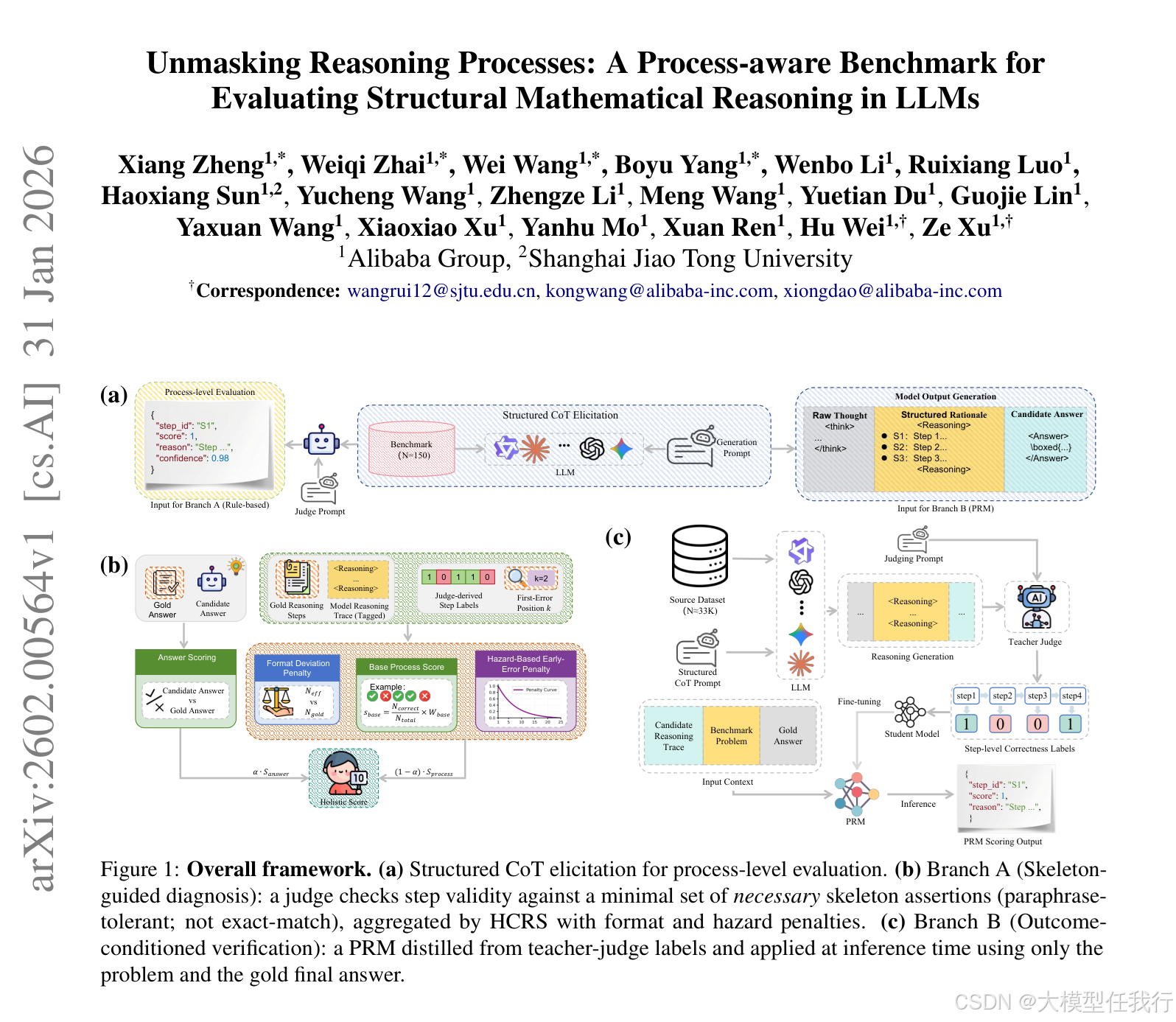
🔸设计150道强调多约束协同、构造性推演和非平凡结构洞察的数学题,每道题附人类编写的最小推理骨架(2--10步),作为过程评估的稳定锚点。
🔸提出HCRS(Hazard-aware Chain-based Rule Score):一种确定性步骤级评分函数,融合格式偏差惩罚与"首错位置加权"的危害惩罚,严惩早期逻辑断裂。
🔸训练Process Reward Model(PRM):在33K人工标注的步骤有效性数据上微调,支持无骨架条件下的结果导向型步骤验证。
🔸采用双语平行发布(中/英)与学科标签体系,兼顾跨语言公平性与领域可解释性分析。
🔎分析总结
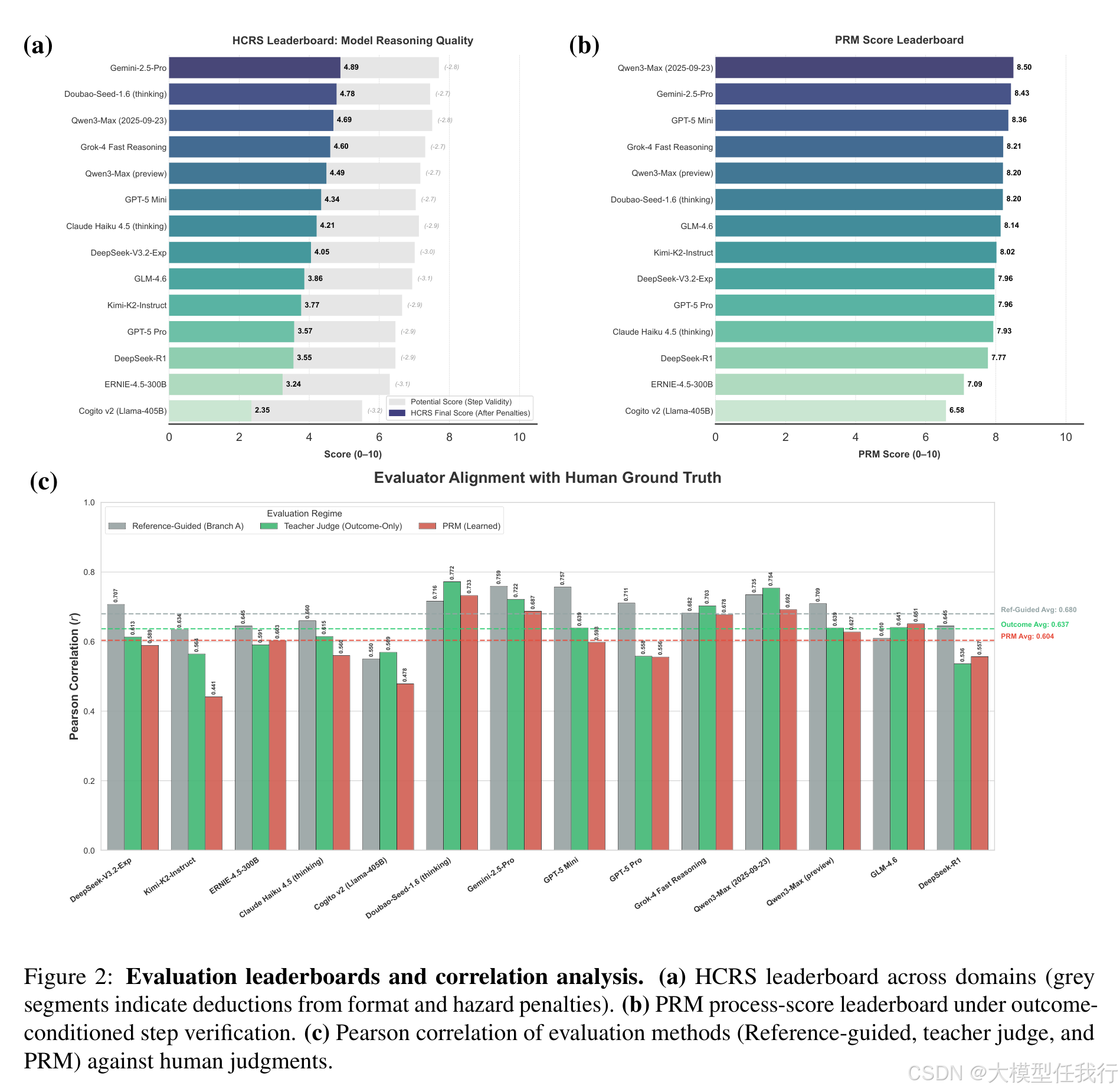
🔸实证显示,主流模型最终答案准确率可达5.8/10,但HCRS整体过程分仅4.36/10(最高5.14),证实答案正确性严重高估推理稳健性。
🔸6.63%的答案正确样本被HCRS判为低分(≤3),揭示大量"幸运猜测"现象,传统指标无法识别此类推理失效。
🔸HCRS惩罚项使中游模型在组合数学等结构敏感任务上性能明显收缩,而Gemini-2.5-Pro保持最稳定表现,说明其优势源于扎实的步骤一致性。
🔸HCRS规则可迁移至PRM等学习型评估器,在无黄金骨架时仍提升其与人工判断的相关性(Pearson从0.604→0.633)。
💡个人观点
论文将"推理结构"显式建模为可验证的最小骨架,并据此定义步骤级评分函数,把推理过程本身作为核心评测对象。
🧩附录