⚠️ 免责声明 本文仅用于网络安全技术交流与学术研究。文中涉及的技术、代码和工具仅供安全从业者在获得合法授权的测试环境中使用。任何未经授权的攻击行为均属违法,读者需自行承担因不当使用本文内容而产生的一切法律责任。技术无罪,请将其用于正途。干网安,请记住,"虽小必牢"(虽然你犯的事很小,但你肯定会坐牢)。
加密流量: 不解密情况下通过流特征识别恶意载荷
你好,我是陈涉川,欢迎你来到我的专栏。在上一章中,我们探讨了如何利用 LLM 辅助安全分析师进行交互式威胁狩猎。然而,所有的分析都建立在"我们能看见数据"的前提下。
现实是残酷的。根据 Google 的透明度报告和 Firefox 的遥测数据,互联网上超过 90% 的 Web 流量已经通过 HTTPS/TLS 加密。随着 TLS 1.3 的普及和 ECH(Encrypted Client Hello)的推进,传统的基于特征码匹配(Signature-based)的 DPI(深度包检测)设备正逐渐变成"瞎子"。
我们是否必须为了安全而牺牲隐私,强行解密所有流量?或者,是否存在一种方法,能在不打开信封的情况下,仅凭信封的材质、重量、投递频率和书写笔迹,就能判断里面装的是情书还是炭疽粉末?
本章将带你进入**加密流量分析(ETA, Encrypted Traffic Analysis)**的领域。我们将利用统计学、侧信道分析和机器学习,重构黑暗中的微光。
引言:至暗时刻与隐形战争
网络安全防御体系长期以来依赖于"可见性"。IDS(入侵检测系统)和 WAF(Web 应用防火墙)的核心逻辑是:拦截流量 -> 解码协议 -> 匹配恶意字符串(如 alert(1) 或 /etc/passwd)。
然而,加密技术的普及打破了这一平衡。
对于黑客而言,加密是完美的掩护。C2(命令与控制)通信隐藏在 HTTPS 隧道中,数据窃取伪装成正常的 AWS S3 上传流量,Webshell 的交互混杂在海量的 TLS 握手中。
防御者的困境(The Defender's Dilemma):
- 盲区扩大: 防火墙看不到加密隧道内部的攻击载荷(Payload)。
- 解密成本高昂: 配置中间人(MITM)解密网关不仅需要管理复杂的证书信任链,还会导致 30%-50% 的网络延迟和 CPU 开销。
- 隐私与合规: 在 GDPR 和个人隐私保护法下,解密员工访问银行或医疗网站的流量可能触犯法律。
- 技术壁垒: TLS 1.3 引入了 前向安全性(PFS, Perfect Forward Secrecy) ,即使你拥有服务器的私钥,也无法解密之前抓获的流量包。此外,证书锁定(Certificate Pinning) 技术使得移动 App 能够拒绝非官方服务器的连接,导致 MITM 解密直接失效。
因此,我们必须换一种思路:不解密,只分析特征。
这就像在现实生活中,警察不需要拆开嫌疑人的每一个包裹,仅凭他每天凌晨 3 点出门、包裹的形状总是长条形、且每次寄往同一地点,就足以判定高度可疑。在网络世界里,这被称为 侧信道分析(Side-Channel Analysis)。
第一章:加密协议的"指纹"------握手阶段的元数据泄露
尽管 TLS 旨在保护数据机密性,但在加密通道建立之前,客户端和服务器必须进行一次明文的协商,这就是 TLS 握手(Handshake)。在这个阶段,攻击者无法隐藏所有的痕迹。
1.1 Client Hello:攻击工具的"自报家门"
当一个客户端(无论是 Chrome 浏览器,还是 Python 编写的恶意脚本)发起 HTTPS 请求时,它发送的第一个包是 Client Hello。
这个包里包含了很多看似随机但实则固定的配置信息:
- Cipher Suites(加密套件列表): 客户端支持哪些加密算法(如 TLS_AES_128_GCM_SHA256)。
- TLS Extensions(扩展字段): 客户端支持哪些特性(如 server_name, supported_groups, ec_point_formats)。
- TLS Version: 支持的最高协议版本。
关键洞察:
不同的软件栈(Software Stack)对这些参数的选择 和排列顺序是不同的。
- Chrome 浏览器: 会支持最新的加密套件,且扩展字段非常丰富,甚至包含为了防止指纹识别而随机插入的 GREASE (Generate Random Extensions And Sustain Extensibility) 值。
- Metasploit / Cobalt Strike: 默认使用老旧的 OpenSSL 库编译,它们支持的加密套件往往过时,且排列顺序是固定的。
- Golang 恶意软件: Go 语言的标准库 crypto/tls 有非常独特的握手特征,与 C/C++ 库截然不同。
1.2 JA3 指纹:将配置转化为哈希
为了利用这种差异,Salesforce 的研究员提出了 JA3 指纹 算法。
JA3 生成逻辑:
它将 Client Hello 包中的以下五个字段提取出来,转为十进制字符串,并用 , 分隔:
SSLVersion, Cipher, SSLExtension, EllipticCurve, EllipticCurvePointFormat
例如:
771,4865-4866-4867,0-5-10-11,23-24-25,0
然后,对这个字符串进行 MD5 哈希,得到一个 32 位的指纹:
e7d705a3286e19ea42f587b344ee6865 (标准的 Tor 客户端指纹)
JA3S(Server 指纹):
同样地,服务器响应的 Server Hello 也可以生成 JA3S 指纹。
通过结合 JA3 和 JA3S,我们可以识别出特定的 C2 通信模式。例如,Metasploit 的 HTTPS Payload 发出的请求是 JA3=X,而其对应的监听器(Listener)响应的 JA3S=Y。这对组合在正常流量中极少出现。
1.3 JA3 的局限性与对抗
虽然 JA3 曾是神兵利器,但黑客也学会了反击。
- Cipher Stunting(加密套件随机化): 现代攻击工具(如 Covenant)允许用户自定义 Client Hello 的参数,甚至随机化 Cipher Suites 的顺序,从而每次生成不同的 JA3 哈希。
- JA3 碰撞: 许多基于 Electron 开发的合法应用(如 Slack, Discord)本质上是浏览器,它们的 JA3 指纹可能与基于 Chrome 内核的恶意软件完全一致。
- TLS 1.3 的 ECH: 随着 Encrypted Client Hello 的推进,连 SNI(服务器名称指示,即域名)都将被加密。虽然底层的 Cipher Suites 还在,但信息的丰富度在下降。
因此,仅靠静态的握手特征是不够的。我们需要观察流量的动态行为。
1.4 盲区中的盲区------QUIC 与 HTTP/3 的挑战
如果说 TLS 1.3 是给流量加了锁,那么 QUIC (HTTP/3) 则是把锁扔进了黑盒子里。 随着 Google 和 Meta 的大力推广,互联网上约 30%-50% 的流量已经从 TCP 切换到了 UDP 基础上的 QUIC 协议。这对 ETA 构成了全新的挑战:
- 元数据加密(Metadata Encryption): 在 TCP 中,尽管负载加密了,但 ACK 确认号、序列号是明文的,分析师可以据此推断网络质量和丢包率。而在 QUIC 中,连数据包编号(Packet Number)都是加密的,防御者甚至无法区分这是重传包还是新数据包。
- 连接迁移(Connection Migration): 传统流量分析依赖"五元组"绑定一个会话。但在 QUIC 中,用户从 Wi-Fi 切换到 4G 网络(IP 改变),连接 ID(Connection ID)却保持不变。传统的基于 IP 的流切分工具会把同一个会话误判为两个断裂的流,导致上下文丢失。
- 填充风暴(Padding): QUIC 协议强制要求初始握手包必须填充到至少 1200 字节(为了防止放大攻击)。这直接抹平了不同客户端在握手初期的"小包特征",让指纹识别变得更加困难。 对策: 针对 QUIC,我们需要提取 Connection ID 的熵值 以及 UDP 数据报的到达间隔(IAT)分布,这些物理层特征比应用层特征更难被混淆。
第二章:流特征工程(Flow Feature Engineering)------数据包的"摩斯密码"
当握手完成,加密数据开始传输。虽然我们看不到内容(Payload),但我们能看到一个个数据包(Packet)像子弹一样飞过。这些子弹的大小(Size) 、**方向(Direction)和时间间隔(Inter-Arrival Time, IAT)**构成了流量的 DNA。
2.1 序列特征(Sequential Features)
在一个 TCP 流(Flow)中,前 N 个数据包的大小序列往往暴露了应用层协议的类型。
案例分析:
- Google 搜索: 请求包小(几十字节),响应包极大(搜索结果),且突发性强。
- 视频流(YouTube): 握手后,紧接着是满载的 MTU(1500 字节)下行数据包序列,持续且稳定。
- SSH 反向隧道(Reverse SSH): 交互式特征明显。你敲一个字符,发送一个包;服务器回显一个字符,接收一个包。数据包极小(60-100 字节),且 IAT 不均匀(取决于人的打字速度)。
- Webshell (菜刀/蚁剑): * 请求:通常较大(包含 Base64 编码的恶意脚本代码)。
- 响应:大小不一,取决于执行结果(whoami 只有几字节,cat /etc/passwd 有几千字节)。
特征向量化:
我们可以提取每个流的前 20 个数据包的大小(Packet Length)和方向(Direction,+1 代表出站,-1 代表入站),构建特征向量:
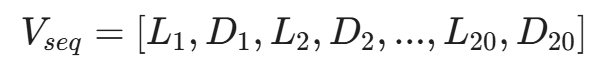
其中 L_i 是第 i 个包的长度,D_i 是方向。
2.2 时间特征(Temporal Features)与 IAT
IAT (Inter-Arrival Time) 指的是两个连续数据包到达的时间差。
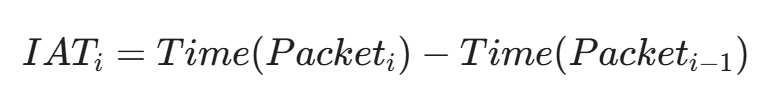
IAT 是区分"机器行为"和"人类行为"的关键。
- 机器自动化(C2 心跳): 恶意软件定期(如每 5 秒)向服务器发送心跳包。其 IAT 的方差(Variance)极小,呈现出精确的周期性。
- 文件下载: 受到带宽限制,数据包会以网络允许的最大速率到达,IAT 极短且服从泊松分布或帕累托分布。
- 人工操作: 人的反应时间是毫秒级的,且具有随机性。
2.3 统计特征(Statistical Features)
除了序列,我们还可以计算整个流的统计指标:
- 字节分布(Byte Distribution): 虽然 Payload 是加密的,看起来像随机噪声,但不同加密算法或压缩算法处理后的熵值(Entropy)可能有微小差异。
- 流持续时间(Flow Duration): 短连接 vs 长连接。
- 突发性(Burstiness): 定义一个"突发"为一组短时间内连续传输的数据包。计算突发的数量、平均大小和间隔。恶意软件的数据外泄(Exfiltration)往往表现为定期的、块状的数据突发。
第三章:基于传统机器学习的分类模型
在深度学习流行之前,安全业界主要使用经典的机器学习算法(如随机森林、XGBoost)来处理这些统计特征。这种方法具有可解释性强 、训练速度快的优势,至今仍在许多防火墙设备中使用。
3.1 经典 ML 管道架构
- 流量切分(Flow Slicing): 使用五元组(SrcIP, SrcPort, DstIP, DstPort, Protocol)将 PCAP 文件切分为单独的流。设置超时时间(如 120秒)来断开长流。
- 特征提取(Feature Extraction): 使用工具(如 Cisco Joy, CICFlowMeter)计算每个流的 80+ 个统计特征(如 Packet Length Mean, IAT Std, Max, Min, Skewness, Kurtosis)。
- 数据清洗: 去除 TCP 重传包、空包(ACK without payload),归一化数值范围。
- 模型训练: 使用标记好的数据集(良性流量 vs 恶意流量)训练分类器。
3.2 决策树与随机森林(Random Forest)
随机森林非常适合处理这种表格型数据(Tabular Data)。它能告诉我们哪些特征最重要(Feature Importance)。
特征重要性排名示例:
- Fwd Packet Length Max: 出站包的最大长度(该值若接近 MTU 上限如 1460/1500 字节,通常暗示了存在大文件传输或满载的数据流,而非简单的交互式命令)。
- Flow IAT Std: 流的时间间隔标准差(区分周期性心跳与随机访问)。
- Init Window Bytes: TCP 初始窗口大小(操作系统的指纹)。
- Total Length of Bwd Packets: 入站总流量(区分下载行为)。
通过这几百棵决策树的投票,我们可以以极高的准确率(>99%)区分出"正常 Web 浏览"和"比特币挖矿流量",因为后者通常表现为持续的高 CPU 占用导致的 IAT 模式和固定的 Stratum 协议包大小。
3.3 局限性:不仅要区分黑白,还要区分"应用"
传统的二分类(恶意 vs 良性)在实际运营中不够用。安全团队需要知道:
- 这是 TLS 流量,但它是 Skype、Tor 还是 VPN?
- 这是 Dropbox 流量,但它是上传文件(高风险)还是下载文件(低风险)?
这就引出了 流量指纹识别(Traffic Fingerprinting) 的概念。
然而,传统 ML 依赖于人工选取的统计特征(Hand-crafted Features)。如果攻击者刻意通过 Traffic Shaping(流量整形)------比如在恶意数据包中加入随机填充(Padding)来改变包大小,或者故意引入延迟来改变 IAT------传统 ML 模型的准确率会急剧下降。
这就是为什么我们需要深度学习,让模型自己去学习原始数据包中的隐蔽模式。
第四章:从统计学到图像识别------将流量视为"图片"
如果我们将流量数据包的大小和时间看作像素点,那么一段流量就是一张图片。利用计算机视觉(CV)领域的卷积神经网络(CNN),我们可以捕捉到人类专家难以定义的局部模式。
4.1 流量图示化(Traffic Imaging)
一种流行的方法是将原始流量字节转换为灰度图。
由于我们无法解密,我们直接取 TCP 载荷的前 N 个字节(包含 TLS 握手后的密文)。
- 将每个字节的值(0-255)映射为像素的灰度值。
- 将前 784 个字节排列成 28 \times 28 的矩阵(类似 MNIST 手写数字集)。
虽然这对人类来说是一片噪点,但 CNN 能够从中学习到加密算法产生的伪随机纹理 以及未加密头部的结构特征。
更高级的映射:流交互图(Flow Interaction Graph)
我们不只看字节,而是将包大小和时间映射到二维空间。
- X 轴:数据包序号。
- Y 轴:数据包大小。
- 颜色/符号:数据包方向。
在这张"图"上:
- HTTPS 网页浏览: 呈现出稀疏的、不规则的脉冲。
- DDoS 攻击(如 HTTPS Flood): 呈现出密集的、高度重复的直线或矩形块。
- 勒索软件通信: 呈现出特定的握手图案,随后是高强度的单向传输。
4.2 1D-CNN:处理序列数据
相比于 2D 图片,网络流量本质上更像是一维的时间序列。
我们可以使用一维卷积神经网络(1D-CNN)直接在数据包序列上滑动。
输入层:
Shape: (N, 3) (注:在 PyTorch 中通常需转置为 (3, N) 以匹配 Conv1d 输入要求)。
其中 N 是流中的包数量(例如 100)。
3 代表三个通道(Channels):Packet\\_Size, IAT, Direction。
卷积层:
卷积核(Kernel)在时间轴上滑动,捕捉局部依赖关系。
例如,一个大小为 3 的卷积核可能会学习到模式:小包, 小包, 大包,这可能对应于 TLS 握手中的 ClientHello -> ServerHello -> Certificate 序列。
池化层(Pooling):
提取最显著的特征,并对微小的时间抖动保持不变性(Translation Invariance)。
通过堆叠多层 1D-CNN,模型可以识别出极其复杂的层级特征,例如:"在前 5 秒内出现了 3 次 TLS 握手重置,且每次重置后的第一个包大小递增"------这是典型的 Password Spraying(密码喷洒) 攻击特征。
第五章:深度学习模型实战------LSTM 与 Attention 的应用
CNN 擅长捕捉局部特征,而 RNN(循环神经网络)及其变体 LSTM(长短期记忆网络)擅长捕捉长期依赖关系。在加密流量中,第 1 个包(握手)和第 100 个包(数据传输)之间可能存在逻辑联系。
5.1 LSTM 处理长流
许多恶意行为是多阶段的。
- 阶段一: C2 建立连接(握手特征)。
- 阶段二: 下发指令(小包,长 IAT)。
- 阶段三: 数据回传(大包序列,短 IAT)。
普通的 ML 模型只看统计均值,会把这三个阶段混在一起,导致特征被平均化,从而漏报。
LSTM 网络拥有"记忆单元(Memory Cell)",它可以记住阶段一的特征,并在阶段三发生时,结合之前的记忆做出判断:"虽然阶段三看起来像文件下载,但考虑到阶段一的特殊握手特征,判定为数据窃取。"
模型架构:
Input (Sequence of Packets) -> Embedding Layer -> Bi-LSTM Layer -> Attention Layer -> Fully Connected Layer -> Softmax (Malware Family)
5.2 Attention 机制:关注关键包
在成千上万个数据包中,并不是每一个都同等重要。
Attention(注意力)机制 允许模型动态地赋予每个数据包不同的权重。
- 对于识别 TLS 版本,Attention 会聚焦在前几个握手包。
- 对于识别心跳行为,Attention 会聚焦在序列中那些具有特定 IAT 的包。
这种机制不仅提高了准确率,还赋予了深度学习模型一定的可解释性。我们可以可视化 Attention 权重图,告诉分析师:"模型判定这是恶意流量,主要是因为它关注到了第 5、第 7 和第 12 个数据包的异常组合。"
5.3 打开黑盒------可解释性 AI (XAI) 在流量取证中的应用
在 SOC (安全运营中心) 中,如果 AI 仅仅抛出一个 Probability: 0.99 的红框,安全分析师是不敢直接阻断业务流量的。他们会问:"凭什么?" 为了让 AI 成为助手而非黑箱,我们需要引入可解释性技术(Explainable AI, XAI)。
- SHAP (SHapley Additive exPlanations) 值分析: SHAP 能够告诉我们,对于当前这条特定的流 ,哪个特征对"判定为恶意"贡献最大。
- 模型输出: "恶意概率 98%"。
- SHAP 解释: "主要因为 Payload_Variance(载荷方差)极低(贡献度 +0.4),且 Server_Hello 的 JA3S 指纹匹配已知 C2(贡献度 +0.3)。虽然 Dst_Port 是 443(通常为良性),但不足以抵消上述特征。"
- 集成梯度(Integrated Gradients)可视化: 对于基于 CNN/LSTM 的深度学习模型,我们可以使用集成梯度技术,将权重映射回原始的数据包序列。 系统可以生成一张"热力图",高亮显示流中的第 7、8、9 个数据包。分析师一看便知:"哦,模型关注的是这三个连续的 1500 字节满载包,且间隔只有 2 毫秒,这是典型的数据渗出(Exfiltration)行为。" 价值: XAI 不仅建立了信任,还能帮助我们发现模型的"偷懒"行为(Shortcut Learning)。例如,我们可能发现模型判定恶意仅仅是因为"源 IP 来自某个特定国家",这显然是不可靠的,需要修正。
第六章:技术挑战------对抗样本与模型老化
尽管 AI 看起来很美好,但在对抗激烈的网络安全领域,它面临着巨大的挑战。
6.1 对抗性机器学习(Adversarial ML)
如果黑客知道我们在用 AI 检测流量,他们会怎么做?
他们会生成 对抗样本(Adversarial Examples)。
只需要在正常的攻击流量中插入几个精心设计的"扰动包"(Perturbation Packets)------比如插入 3 个大小为 0 的 TCP ACK 包,或者人为将某个包的发送延迟 100ms。
对于人类来说,流量逻辑没变。但对于神经网络,这微小的输入变化可能导致输出结果从"恶意(99%)"瞬间翻转为"正常(10%)"。
6.2 概念漂移(Concept Drift)
网络流量模式是动态变化的。
- 新的浏览器版本发布,TLS 握手特征变了。
- 新的 CDN 上线,IP 分布变了。
- 新的攻击工具出现,通信协议变了。
一个在一个月前训练出的准确率 99% 的模型,如果不对其进行在线学习(Online Learning)或定期重训练(Retraining),一个月后准确率可能跌至 60%。
第七章:工程实战------构建高性能流量特征提取流水线
理论上的特征很美,但在 10Gbps 的骨干网流量面前,如何实时提取这些特征而不丢包,是一个巨大的工程挑战。直接用 Python 的 Scapy 处理 PCAP 包是不现实的,它的性能太慢。
我们需要工业级的网络流量分析器:Zeek (原名 Bro)。
7.1 Zeek:网络安全领域的"瑞士军刀"
Zeek 是一个开源的网络安全监控系统。与 IDS 不同,它不只是匹配签名,而是将网络流量解析为结构化的日志(Logs)。
Zeek 的优势:
- 协议解析能力: 它能自动解析 SSL/TLS、HTTP、DNS 等协议,即使在非标准端口上。
- 脚本化(Scriptable): 它拥有自己的脚本语言,允许我们自定义逻辑来提取特定的流特征。
- 高性能: 基于 C++ 编写,在大流量环境下表现稳定。
7.2 实战脚本:提取 TLS 指纹与流统计
我们需要编写一个 Zeek 脚本,同时记录 JA3 指纹和前 20 个数据包的大小序列。
# encrypted_analysis.zeek
@load base/protocols/ssl
@load base/protocols/conn
module ETA;
export {
# 定义日志记录结构
type Info: record {
ts: time &log;
uid: string &log;
id: conn_id &log;
# 静态特征
ja3: string &log &optional;
ja3s: string &log &optional;
server_name: string &log &optional;
# 动态特征 (序列)
pkt_lengths: vector of int &log &default=vector();
pkt_intervals: vector of interval &log &default=vector();
};
}
# 初始化日志流
redef Log::default_logdir = "/var/log/zeek";
global log_eta: event(rec: Info);
# 事件:新的 SSL/TLS 握手
event ssl_client_hello(c: connection, version: count, record_version: count, possible_ts: time, client_random: string, session_id: string, ciphers: index_vec, comp_methods: index_vec)
{
if ( ! c?$eta ) {
c$eta = Info($ts=network_time(), $uid=c$uid, $id=c$id);
}
# 提取 JA3 (需加载 ja3 插件)
if ( c$ssl?$ja3 ) c$eta$ja3 = c$ssl$ja3;
}
# 事件:数据包到达
event new_packet(c: connection, p: pkt_hdr)
{
if ( ! c?$eta ) return;
# 只记录前 20 个包
if ( |c$eta$pkt_lengths| < 20 ) {
# 记录包大小 (方向用正负表示)
local len = p$len;
if ( ! p$is_orig ) len = -len; # 响应包为负
c$eta$pkt_lengths += len;
# 计算 IAT
if ( |c$eta$pkt_intervals| > 0 ) {
# 简化逻辑:这里需要记录上一个包的时间戳
# interval = current_time - last_time
}
}
}
# 事件:连接结束,写入日志
event connection_state_remove(c: connection)
{
if ( c?$eta ) Log::write(ETA::LOG, c$eta);
}运行这个脚本后,Zeek 会生成 eta.log,其中每一行都是一个 JSON 对象,包含了我们训练 AI 所需的所有"原材料"。
工程注意:在生产环境中,监听 new_packet 事件会带来巨大的 CPU 开销。上述脚本仅适用于离线 PCAP 分析或低流量环境。在万兆(10Gbps)即时分析中,建议使用 Zeek 的 C++ 插件(Packet Brick)或仅在 ssl_application_data 层面进行统计。
第八章:模型构建------多模态混合神经网络
我们面对的是两种截然不同的数据类型:
- 类别型数据(Categorical): JA3 哈希、Cipher Suites、ALPN(应用层协议协商)。
- 序列型数据(Sequential): 包大小序列、IAT 序列。
单一的模型(如仅用 CNN 或仅用 Random Forest)无法同时利用这两类信息的优势。我们需要构建一个 多模态(Multi-Modal) 的深度学习模型。
8.1 宽与深(Wide & Deep)架构的变体
我们将借鉴推荐系统中的 Wide & Deep 架构思想,设计一个 双塔模型(Two-Tower Model)。
- 左塔(Static Tower): 处理握手元数据。
- 输入:Cipher Suites ID 列表、Extension ID 列表。
- 处理:Embedding 层(将离散 ID 映射为密集向量)。
- 右塔(Dynamic Tower): 处理流序列。
- 输入:Packet Size Sequence (20, 1), IAT Sequence (20, 1)。
- 处理:Bi-LSTM 或 1D-CNN。
8.2 PyTorch 代码实现
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class EncryptedTrafficModel(nn.Module):
def __init__(self, num_ciphers, embedding_dim, hidden_dim, num_classes):
super(EncryptedTrafficModel, self).__init__()
# --- Left Tower: Static Features (Cipher Suites) ---
# 假设我们将 Cipher Suite ID 映射到了 0-num_ciphers 之间
self.cipher_embedding = nn.Embedding(num_ciphers, embedding_dim)
# Global Average Pooling 用于处理不定长的 Cipher List
# --- Right Tower: Dynamic Features (Packet Sizes) ---
# 输入维度: 1 (Packet Length)
self.lstm = nn.LSTM(input_size=1,
hidden_size=hidden_dim,
num_layers=2,
batch_first=True,
bidirectional=True)
# --- Fusion Layer ---
# Embedding + LSTM Output (Bidirectional = 2 * hidden)
self.fusion_dim = embedding_dim + (2 * hidden_dim)
self.fc1 = nn.Linear(self.fusion_dim, 128)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(128, num_classes) # Softmax
def forward(self, cipher_ids, packet_seq):
# 1. Process Static Features
# cipher_ids shape: [batch, max_ciphers]
emb = self.cipher_embedding(cipher_ids) # [batch, max_ciphers, emb_dim]
# 取平均值作为该流的 Cipher 特征表示
static_feat = torch.mean(emb, dim=1) # [batch, emb_dim]
# 2. Process Dynamic Features
# packet_seq shape: [batch, seq_len, 1]
lstm_out, _ = self.lstm(packet_seq)
# 取 LSTM 最后一个时间步的输出
dynamic_feat = lstm_out[:, -1, :] # [batch, 2*hidden_dim]
# 3. Fusion
combined = torch.cat((static_feat, dynamic_feat), dim=1)
x = F.relu(self.fc1(combined))
x = self.dropout(x)
x = self.fc2(x)
return x
# 模型实例化
# num_ciphers=500, embedding_dim=32, hidden_dim=64, num_classes=2 (Benign/Malicious)
model = EncryptedTrafficModel(500, 32, 64, 2)8.3 训练策略与损失函数
- 损失函数: 使用 Focal Loss 而非标准的 Cross Entropy Loss。
- 原因: 恶意流量(正样本)在总流量中占比极低(可能只有 0.1%)。Focal Loss 能降低模型对易分类样本(正常流量)的关注度,强迫模型专注于难分类的恶意样本。
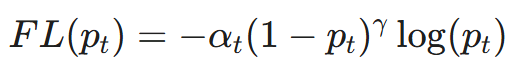
- 优化器: AdamW (带权重衰减的 Adam),防止过拟合。
第九章:解决样本荒------自监督学习(Self-Supervised Learning)
在实际部署中,最大的痛点不是模型结构,而是标签(Labels)。
我们有海量的加密流量(无标签),但只有极少量的确诊恶意样本(有标签)。
如果在只有 100 个恶意样本的情况下训练深度学习模型,必然过拟合。
解决方案:自监督学习 (SSL)。
这就像 GPT 预训练一样:先让模型在海量无标签数据上"自己学习"流量的通用特征,然后再用少量有标签数据进行"微调"。
9.1 对比学习(Contrastive Learning)与 SimCLR
我们将目光转向计算机视觉领域的 SimCLR 框架。其核心思想是:同一个样本的两个不同增强版本,在特征空间中应该靠得很近。
应用于流量分析 (Flow-SimCLR):
- 数据增强(Data Augmentation): 给定一个正常的流序列 S,我们生成两个变体:
- S_1:随机 Mask 掉 10% 的包大小(设为 0)。
- S_2:随机对包的时间戳增加微小的抖动(Jitter)。
- 预训练任务:
- 输入:S_1 和 S_2。
- 目标:最大化 S_1 和 S_2 的 Embedding 相似度(Cosine Similarity),同时最小化 S_1 与其他流 S_{other} 的相似度。
- 损失函数:InfoNCE Loss。
通过这种方式,模型学会了什么样的序列波动是"正常的网络抖动",什么样的模式是"本质特征"。这个预训练好的 Encoder 已经极其强大。
9.2 ET-BERT:基于 Transformer 的流量预训练
这是目前学术界最前沿的方法。
我们将数据包视为"单词"(Token),将流视为"句子"。
- Tokenization: 将两个连续的十六进制字节(Hex pair)作为一个 Token。
- Pre-training: 使用 Masked Language Modeling (MLM) 任务。随机遮挡流中的某些字节,让 BERT 模型预测被遮挡的内容。
ET-BERT 在大规模无标签流量上预训练后,只需要几十个恶意样本进行 Fine-tuning,就能达到 99% 的检测率,彻底解决了样本稀缺问题。
实战演练数据集推荐:
- CIC-IDS2017 / CSE-CIC-IDS2018:包含大量现代攻击流量(DDoS, Botnet, Web Attack)且有完整 PCAP。
- Stratosphere IPS (CTU-13):包含大量真实的恶意软件和僵尸网络流量。
- USTC-TFC2016:专门用于加密流量分类研究的数据集,包含 10 类恶意软件和 10 类正常应用
第十章:无监督学习------发现未知的"零日"威胁
如果出现了一种全新的恶意软件(0-Day),它从未在训练集中出现过,基于监督学习的模型会失效。
我们需要 异常检测(Anomaly Detection)。
10.1 自动编码器(Autoencoder, AE)
核心假设: 正常流量是相似的,可以通过低维特征重构;异常流量是独特的,难以重构。
训练过程:
- 仅使用正常的业务流量(HTTP, DNS, Outlook 等)训练 Autoencoder。
- 模型学习如何将正常流量压缩(Encode)再解压(Decode)。
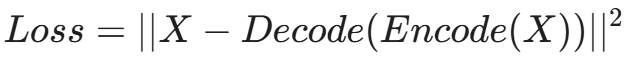
检测过程:
- 新流量 X_{new} 进来。
- 计算重构误差(Reconstruction Error):Error = || X_{new} - X'_{new} ||。
- 判定:
- 如果 X_{new} 是正常的 Web 流量,模型很熟悉,Error 很小。
- 如果 X_{new} 是一种从未见过的 C2 隧道(例如利用了 DNS over HTTPS 的变种),模型没见过这种模式,试图重构时会产生巨大的 Error。
- 如果 Error > Threshold,报警。
这种方法不需要任何黑样本,是发现 0-Day 攻击的最佳手段。
10.2 图神经网络(GNN)------从"单兵作战"到"群体识别"
前文提到的所有方法(CNN, LSTM, BERT)都聚焦于单条流 (Single Flow)的特征。但在高级持续性威胁(APT)中,攻击者往往同时控制着成百上千个僵尸节点。 单条流看起来是正常的,但它们组成的"网络拓扑"是异常的。 我们需要利用 图神经网络(Graph Neural Networks, GNN) 来构建流量图谱。
构图逻辑:
- 节点(Nodes): 内部主机 IP、外部服务器 IP、域名。
- 边(Edges): 它们之间的通信连接。边的属性包含我们提取的流特征(如数据包大小、IAT、JA3 指纹)。 图算法的应用:
- 社区发现(Community Detection): 正常的流量图往往是树状或星状的(用户访问 Google, Facebook)。而 Botnet 的流量图往往呈现出高度密集的"网状结构"或"集中式辐射结构"(所有受害主机在同一时间段向同一个 C2 发送了心跳)。GNN 可以通过聚合邻居节点的信息,识别出这些异常的子图结构。
- 半监督节点分类: 如果我们确认图中有一个节点是恶意的(已知 C2),GNN 可以通过边将"恶意特征"传播(Message Passing)给与之通信的其他节点。即使其他节点使用的是加密流量且特征不明显,但因为它们"通过特定的频率连接了恶意节点",模型依然能将其标记为可疑。 核心优势: GNN 使得防御者从"显微镜"(分析单个包)升级到了"上帝视角"(俯瞰整个网络拓扑),让利用 DGA(域名生成算法)和 Fast-Flux(快速变换 IP)的攻击者无处遁形。
第十一章:对抗与防御------加密流量的猫鼠游戏
随着 AI 防御能力的提升,黑客也在进化。他们开始使用 Adversarial Traffic Shaping(对抗性流量整形)。
11.1 攻击手法
- MTU Padding(填充): 恶意软件故意将所有数据包填充到 1400 字节以上,消除"包大小"这一特征的辨识度。
- Dummy Packets(假包): 在关键的握手序列中插入无意义的垃圾包(Chaff),破坏序列特征。
- Timing Perturbation(时序扰动): 在发送数据前随机休眠 0-500ms,破坏 IAT 特征。
11.2 防御策略
- 鲁棒特征工程: 使用对填充不敏感的特征。例如,不只看包的大小,而是看 Burst Size(突发块总大小)。无论你怎么填充,总传输的数据量(熵)是很难隐藏的。
- 对抗训练(Adversarial Training): 在训练阶段,主动生成对抗样本(如随机插入假包),告诉模型:"这也是恶意流量"。
- 多视角验证: 不仅看流量特征,还结合 端点行为(EDR) 。
- 流量视角:看起来像正常的 HTTPS。
- 端点视角:这个 HTTPS 连接是由 powershell.exe 发起的,且父进程是 word.exe。
- 结论:即使流量特征被伪装了,结合端点上下文依然可以确诊。
第十二章:加密的终局------ECH 与未来的可见性
TLS 1.3 的普及已经让防御者头疼,而 ECH (Encrypted Client Hello) 则是真正的"至暗时刻"。
12.1 ECH 的冲击
在传统的 TLS 1.3 中,虽然证书是加密的,但 SNI(Server Name Indication,即你访问的域名 www.google.com)是明文的。这是因为服务器需要知道你访问哪个域名才能返回正确的证书。
防火墙依然可以通过 SNI 做简单的域名阻断。
ECH 机制:
客户端在发送 Client Hello 之前,先通过 DNS 获取服务器的公钥(ESNI Keys),然后直接加密整个 Client Hello 消息。
值得注意的是,ECH 必须配合加密 DNS(如 DoH 或 DoT)使用,否则防御者依然可以通过明文的 DNS 查询请求获知用户访问的目标域名。
结果: 防火墙连你访问的是 google.com 还是 pornhub.com 都看不到了。JA3 指纹也可能会失效(或者变得单一化)。
12.2 后 ECH 时代的检测方向
当元数据(Metadata)完全消失,我们将不得不完全依赖 行为分析(Behavioral Analysis)。
- 流量图谱(Traffic Graph): 不再关注单个连接,而是关注连接之间的拓扑关系。一个 IP 同时连接了 Gmail, Slack 和一个未知的 AWS IP,且流量比例异常。
- 主动探测(Active Probing): 当发现可疑连接时,防火墙主动向目标服务器发起连接,尝试探测其响应特征。
- 去中心化检测: 既然网络层看不到了,检测能力必须下沉到 端点(Endpoint) 或 浏览器内部。这就是为什么 Chrome 和 Microsoft Edge 开始内置更强的安全扫描机制。
结语:在"不可知"的深渊中凝视微光
加密流量分析(ETA)代表了网络安全攻防的一次范式转移:从确定性的内容审查(Inspection)转向了概率性的行为推理(Inference)。
过去,安全是建立在"看见"之上的;而现在,安全必须适应"盲视"。TLS 1.3 和 ECH 的普及虽然剥夺了防御者查看载荷的权力,但却无法抹除攻击者在时间与空间维度上留下的物理痕迹。正如量子力学中我们无法同时确定粒子的位置和动量,在加密网络中,我们或许无法确知数据的内容,但我们依然可以精准地捕获攻击的意图。
本章得出的核心启示在于:
- 隐私与安全的非零和博弈:我们无需通过解密(MITM)来侵犯隐私以换取安全。侧信道分析证明,数据包的大小、频率和时序本身就是一种高保真的语言。
- AI 是唯一的解题钥匙:面对海量的加密流和毫秒级的对抗,人类的认知带宽已达极限。只有深度学习能从数以亿计的数据包中,提取出那些人类肉眼不可见的、甚至连攻击者自己都未曾察觉的隐式特征。
- 数据的马太效应:未来的 ETA 竞争,本质上是数据质量的竞争。谁拥有更丰富的良性应用指纹库和更鲜活的恶意流量样本,谁就能训练出足以对抗"概念漂移"的鲁棒模型。
当黑暗成为常态,防御者不应诅咒黑暗,而应学会感知黑暗中的气流。随着网络战的边界在 ECH 的迷雾中重塑,我们的防御体系也正从单纯的"城墙(防火墙)"进化为具备感知能力的"神经网络"。
下期预告:第 28 篇《合规自动化: AI在资产发现与数据合规治理中的角色》
我们的【AI 驱动的智能与自动化安全运营】模块即将迎来最后一篇。
在解决了外部的攻击(WAF/IDS)和内部的威胁(UEBA/加密流量)之后,我们面临一个更现实、更让 CISO 头疼的问题:合规(Compliance)。
- 你真的知道你的云上有多少个 S3 存储桶是公开的吗?
- 你能在一分钟内回答"我们的客户数据存放在哪些服务器上"吗?
- 面对 GDPR、CCPA 或等保 2.0 的审计,你是通过 Excel 表格手动填报,还是有一个 AI 系统自动扫描并生成报告?
在下一篇中,我们将探讨 AI 如何遍历企业的数字资产,自动识别敏感数据(PII),并实现持续的合规性监控(CSPM/SSPM)。
敬请期待 第 28 篇《合规自动化: AI在资产发现与数据合规治理中的角色》。
陈涉川
2026年02月12日