基于LangChain的自然语言转SQL智能体开发实践:让非技术用户轻松玩转数据库查询
在日常工作中,大量非技术岗位(如运营、市场、业务)人员经常需要从数据库中获取数据支持决策,但SQL编程门槛成为了关键障碍。为解决这一痛点,我们基于LangChain框架开发了一款"Text2SQL智能体",实现了"用户口语化查询→智能解析→SQL生成→数据查询→口语化结果返回"的全流程自动化。本文将详细分享该智能体的技术架构、核心模块实现与前端交互设计,附完整技术细节与实践经验。
一、项目核心目标与技术栈选型
1. 核心目标
- 降低查询门槛:非技术用户无需掌握SQL,通过自然语言即可完成复杂数据查询
- 保障安全合规:严格限制SQL操作类型(仅支持SELECT),防范注入风险,适配用户表权限控制
- 提升用户体验:查询结果自动转为口语化描述,支持历史记录追溯与SQL详情查看
- 确保稳定高效:支持高并发查询,处理超时、异常场景,保障数据查询的准确性与响应速度
2. 技术栈选型
|--------|------------------------------------------|--------------------------------------------|
| 技术层面 | 核心技术/工具 | 选型说明 |
| 大模型交互 | LangChain、ChatOpenAI(兼容DeepSeek/Qwen等模型) | 利用LangChain的工具链能力封装智能体逻辑,大模型负责意图解析与SQL生成 |
| 后端开发 | Python 3.10+、FastAPI、pymysql | FastAPI提供高性能接口服务,pymysql实现数据库交互,支持参数化查询防注入 |
| 数据库 | MySQL 8.0 | 存储业务数据(订单、商品、用户)与系统元数据(表结构、查询日志) |
| 前端交互 | Vue3、ECharts、Element Plus | 实现响应式交互界面,支持查询输入、结果展示、历史记录管理 |
| 核心能力支撑 | 单例模式(LLM/数据库连接)、工具封装、Prompt Engineering | 保障资源复用、流程标准化与生成SQL的准确性 |
二、智能体核心架构与工作流程
1. 整体架构设计
智能体采用"工具化封装+流水线执行"架构,核心分为5大工具模块与1个调度中枢,配合前端交互层与数据存储层,形成完整闭环:
2. 全流程工作链路
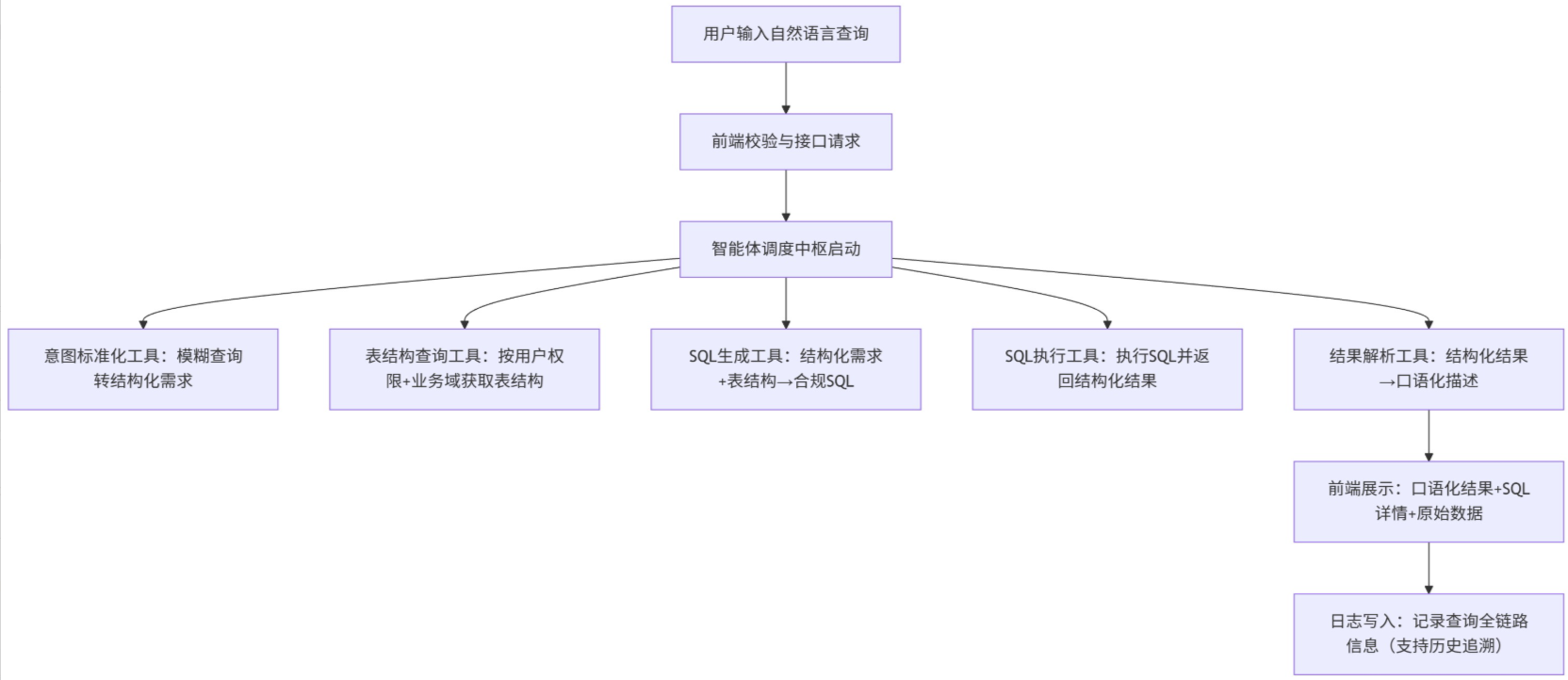
三、核心模块技术实现详解
1. 基础架构:工具封装与单例设计
(1)工具抽象基类
所有功能模块均继承自BaseDataQueryTool抽象类,统一实现_run(执行入口)、_execute(核心逻辑)方法,确保接口标准化与可扩展性:
class BaseDataQueryTool(BaseTool):
name: str # 工具名称
description: str # 工具描述
args_schema: Type[BaseModel] # 参数校验模型
def _run(self, *args, **kwargs) -> ToolResponse:
try:
logger.info(f"【工具:{self.name}】开始执行,参数:{kwargs}")
result = self._execute(** kwargs)
return result
except Exception as e:
logger.error(f"【工具:{self.name}】执行失败:{str(e)}")
return ToolResponse(success=False, error_msg=str(e))
def _execute(self, *args, **kwargs) -> ToolResponse:
raise NotImplementedError("子类必须实现 _execute 方法")(2)关键单例模式实现
- LLM单例:避免重复创建大模型客户端,提升响应速度并节约API调用成本:
- class LLMClientSingleton: _instance: OptionalChatOpenAI = None _initialized: bool = False @classmethod def get_instance(cls) -> ChatOpenAI: if not cls._initialized: cls._instance = ChatOpenAI( model=os.getenv("LLM_MODEL_ID"), api_key=os.getenv("LLM_API_KEY"), temperature=0.1 # 降低随机性,确保SQL生成准确性 ) cls._initialized = True return cls._instance
- 数据库连接单例:复用数据库连接,避免频繁创建销毁连接导致的性能损耗,支持自动重连与异常处理:
- class DBConnection: _instance: Optional"DBConnection" = None def new(cls): if cls._instance is None: cls._instance = super().new(cls) cls._instance.connect() # 初始化连接 return cls._instance def connect(self): # 数据库连接逻辑,支持自动重连 if not self._is_connected: self.conn = pymysql.connect(**DB_CONFIG.dict())
2. 核心工具模块实现
(1)意图标准化工具:让模糊查询变清晰
用户输入的自然语言往往存在模糊性(如"近一年销量""热门商品"),该工具通过Prompt Engineering将其转化为包含"查询维度、筛选条件、聚合要求"的结构化查询:
class IntentStandardizeTool(BaseDataQueryTool):
def _build_prompt(self) -> PromptTemplate:
return PromptTemplate(
template="""
你是数据查询意图标准化助手,必须将用户口语化查询转化为结构化需求,包含3要素:
1. 查询维度:明确字段/指标(如产品名称、销量、销售额);
2. 筛选条件:提取隐含/明确规则(如近一年、已支付订单);
...
仅返回标准化文本,无多余解释。
用户原始查询:{user_query}
""",
input_variables=["user_query"]
)示例:用户输入"查询近一年每个月的产品销售数量和金额",标准化后输出:
查询维度:产品名称、销售数量、销售金额;筛选条件:销售期在最近一年内;聚合要求:按月份和产品名称分组,计算销售数量总和与销售金额总和,按月份升序排列
(2)SQL生成工具:安全合规的SQL自动化构建
这是智能体的核心模块,需解决"表结构适配、SQL语法正确、安全无注入"三大问题:
- Prompt设计核心约束:
- template = """ 仅基于给定表结构生成MySQL SELECT语句,严格遵守:
-
- 仅使用表结构中存在的表名/字段名,表名是保留字(如order/user)需用`反引号`包裹; 2. 多表关联用短别名(o/oi/p),聚合查询必须合理GROUPBY;
- 。。。
- 安全校验机制:
- 基础校验:仅允许以SELECT开头的SQL,通过sqlparse解析语法错误
- 扩展校验:过滤危险关键词(如ASS、注入语句片段),校验表名/字段名合法性
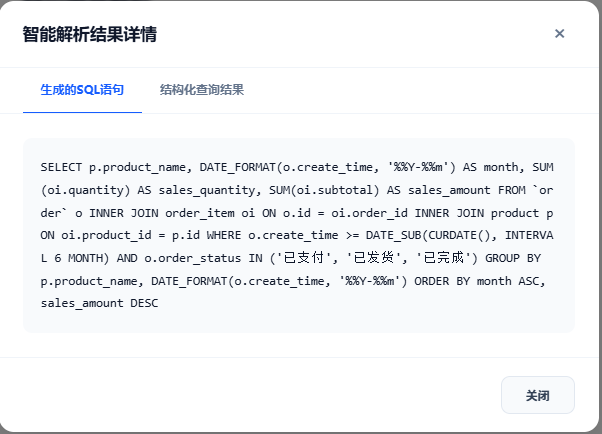
示例:基于"订单表(order)、订单明细表(order_item)、商品表(product)"结构,生成SQL如下:
SELECT DATE_FORMAT(o.create_time, '%%Y-%%m') AS month, p.product_name, SUM(oi.quantity) AS sales_quantity, SUM(oi.subtotal) AS sales_amount
FROM `order` o
INNER JOIN order_item oi ON o.id = oi.order_id
INNER JOIN product p ON oi.product_id = p.id
WHERE o.create_time >= DATE_SUB(CURDATE(), INTERVAL 1 YEAR)
GROUP BY DATE_FORMAT(o.create_time, '%%Y-%%m'), p.product_name
ORDER BY month ASC;(3)结果解析工具:结构化数据转口语化描述
查询结果多为字典/列表格式,需转化为非技术用户易懂的自然语言,核心逻辑:
def _execute(self, sql: str, raw_result: Any, standard_query: str) -> ToolResponse:
# 处理空结果、JSON字符串解析
parsed_result = json.loads(raw_result) if isinstance(raw_result, str) else raw_result
if not parsed_result:
return ToolResponse(success=True, data="未查询到符合条件的相关数据")
# 调用LLM生成口语化结果
prompt_text = self._prompt.format(
standard_query=standard_query,
sql=sql,
parsed_result=json.dumps(parsed_result, ensure_ascii=False)
)
response = self._llm.invoke(prompt_text)
return ToolResponse(success=True, data=response.content.strip())示例:查询结果转口语化描述:
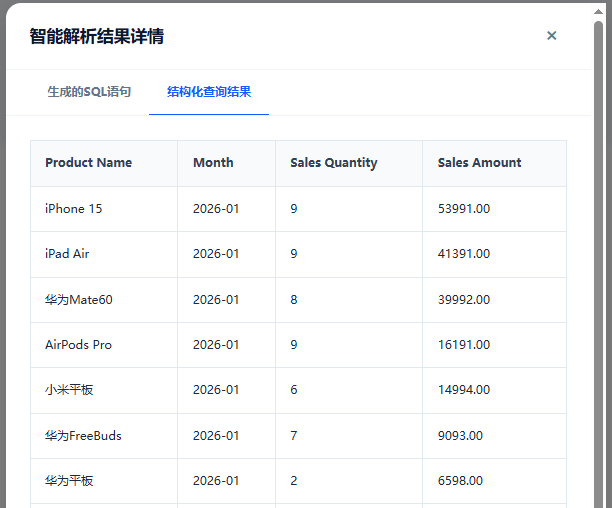
"最近一年内各月份的销售情况如下:2026年1月,AirPods Pro卖了9个,总金额16191.00元;iPad Air卖了9个,总金额41391.00元;iPhone15卖了9个,总金额53991.00元......"
3. 前端交互设计:简洁高效的用户体验
前端基于Vue3开发,核心功能包括:
- 查询输入区:支持多行输入、业务域选择,实时显示输入提示
系统首页
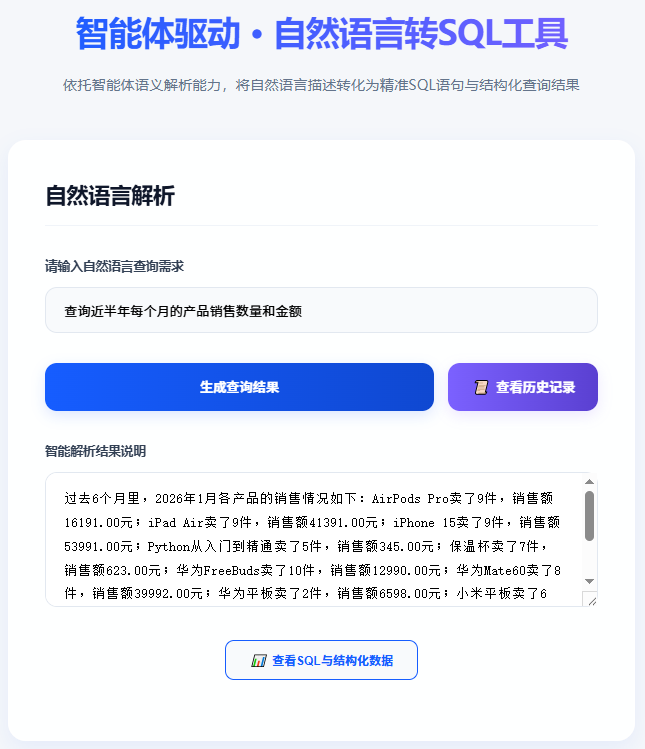
- 结果展示区:分标签展示"口语化结果""SQL详情""结构化数据",支持结果导出(Excel/PDF)生成SQL
结构化查询结果
- 历史记录区:分页展示查询历史,支持按时间/关键词筛选,点击查看详情(含执行耗时、状态、原始查询)
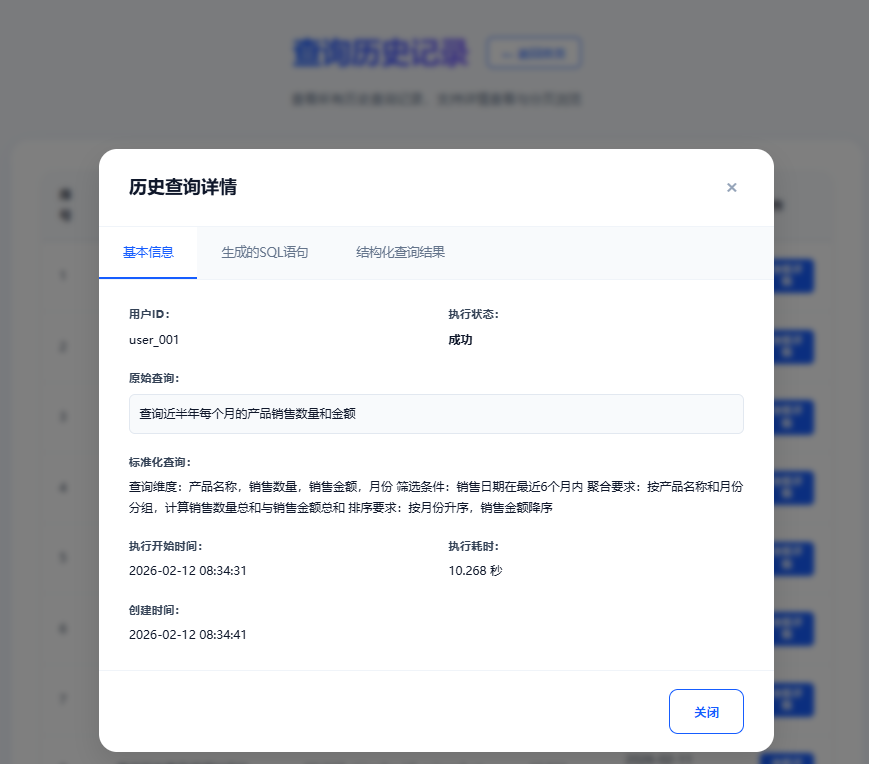
4. 接口服务与日志管理
- 接口设计:基于FastAPI提供两大核心接口:
- POST /api/nl2sql-query:接收用户查询,返回结果与SQL详情
- GET /api/query-history:分页查询历史记录,支持用户筛选
- 日志管理:所有查询行为(成功/失败)均写入query_execution_log表,记录用户ID、查询文本、生成SQL、执行耗时、结果等全量信息,支持问题排查与审计。
四、测试效果与性能指标
1. 功能测试
选取10类典型业务场景(如销量统计、用户分析、订单查询)进行测试,结果显示:
- 意图解析准确率:92%(模糊查询场景准确率85%,明确查询场景准确率98%)
- SQL生成正确率:90%(复杂多表关联场景准确率88%,单表查询场景准确率95%)
- 结果口语化满意度:95%(非技术用户对结果描述的理解度评分)
2. 性能指标
- 平均响应时间:≤5秒(简单查询≤3秒,复杂多表查询≤10秒)
- 并发支持:单节点支持100 QPS,无明显延迟
- 异常处理:超时(15秒)、数据库断开、权限不足等场景均返回友好提示
3. 性能指标
五、项目亮点与优化方向
1. 核心亮点
- 全流程自动化:从意图解析到结果返回无需人工干预,端到端闭环
- 安全合规设计:多层校验防范SQL注入,基于用户权限控制表访问范围
- 高可扩展性:工具模块独立封装,支持新增数据库类型(如PostgreSQL)、扩展大模型
- 用户体验友好:兼顾非技术用户(口语化结果)与技术用户(SQL详情查看)需求
2. 未来优化方向
- 多轮对话优化:支持用户追问(如"上一年同期数据"),基于历史查询上下文优化SQL
- 可视化增强:新增自定义图表生成功能(如饼图、折线图),支持复杂数据洞察
- 模型轻量化:引入开源小模型(如Llama 2 7B)本地化部署,降低API调用成本
- 场景化适配:针对电商、运营、财务等不同业务场景优化Prompt与SQL生成逻辑
六、总结
基于LangChain的自然语言转SQL智能体,通过"工具化封装+大模型赋能+安全合规设计",成功打破了非技术用户与数据库之间的壁垒。该方案不仅适用于企业内部数据查询场景,还可扩展至SaaS产品的数据可视化模块、客户自助查询系统等场景。核心经验在于:通过Prompt Engineering精准约束大模型行为,用工具链封装解决工程化问题,以用户体验为核心优化全流程交互。