因为我们已经在学习记录2中学习了在MP网页中直接下载数据的方法,所以我们就不多讨论了,我们学习一下material project的api,这对于批量调取和自动化有很关键的作用。
1.基础用法(print)
通常有mp_api和pymatgen调用,我研究了一段时间决定用mp_api进行调用,然后使用Pymatgen进行处理与保存
首先,需要有一个mp_api,可以直接pip,pymatgen也是
python
pip install mp_api接下来,最常使用的代码为
python
from mp_api.client import MPRester
with MPRester("your_api_key_here") as mpr:
# do stuff with mpr...其中your_api_key_here需要改为在material project中获得的的idkey
后续就可以添加自己的需求
首先最基本的,直接查询某种物质,我们在学习记录2中有过简单的提及,我们这里了解一下api版本,我们还是以AlN为例,当我们使用官网查询时,需要手动输入化学式

然后我们找到了mp-661的AlN,我们就可以再官网看到相关的数据
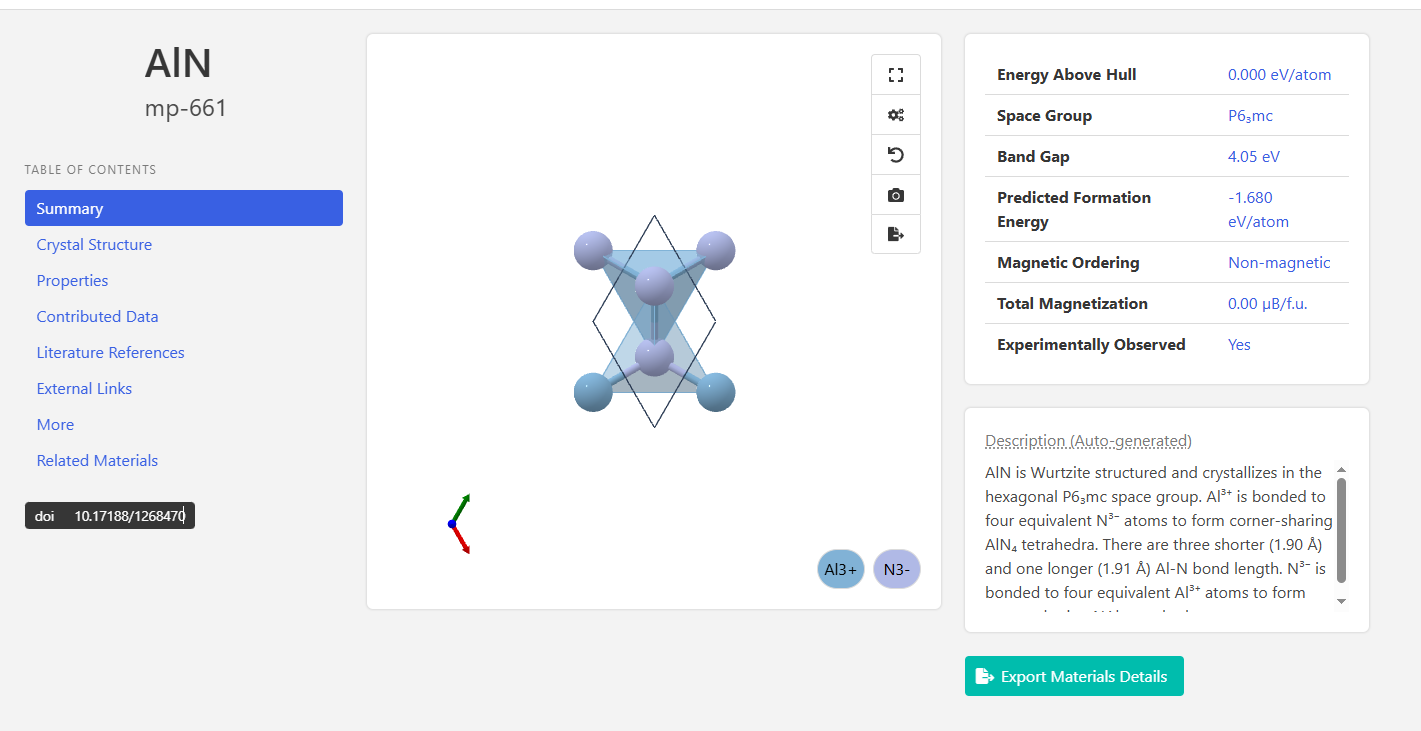
那如果我不想用官网查,我想用api调取呢?那这个时候就需要用到**mpr.materials.summary.search**函数,用这个函数就可以进行数据的调取,至于调取的内容,我们就可以根据自己的需要进行调整,比如我们想要查看mp-661数据
python
from mp_api.client import MPRester
with MPRester("你的key") as mpr:
docs = mpr.materials.summary.search(material_ids=["mp-661"])
for material in docs:
print(material)
print(f"Material ID: {material.material_id}")
print(f"Formula: {material.formula_pretty}")首先***material_ids="mp-661"***代表的就是我们我们搜索的数据的编号,即我们想要获取编号为mp-661的数据,并将搜索到的结果以列表形式写进docs,当然,由于每个物质的编号都是独一无二的,所以获取到的结果也只有一个,docs里也只有一个结果。
接下来***for material in docs:***就不用多说,就是把docs包含的物质挨个跑一遍
***print(material)***就是直接把for循环的当前的物质的相关数据打印出来,由于我们没有做任何调取的限制,我们会把能带,密度,光学性质等等全部打印出来,就会非常庞大,如
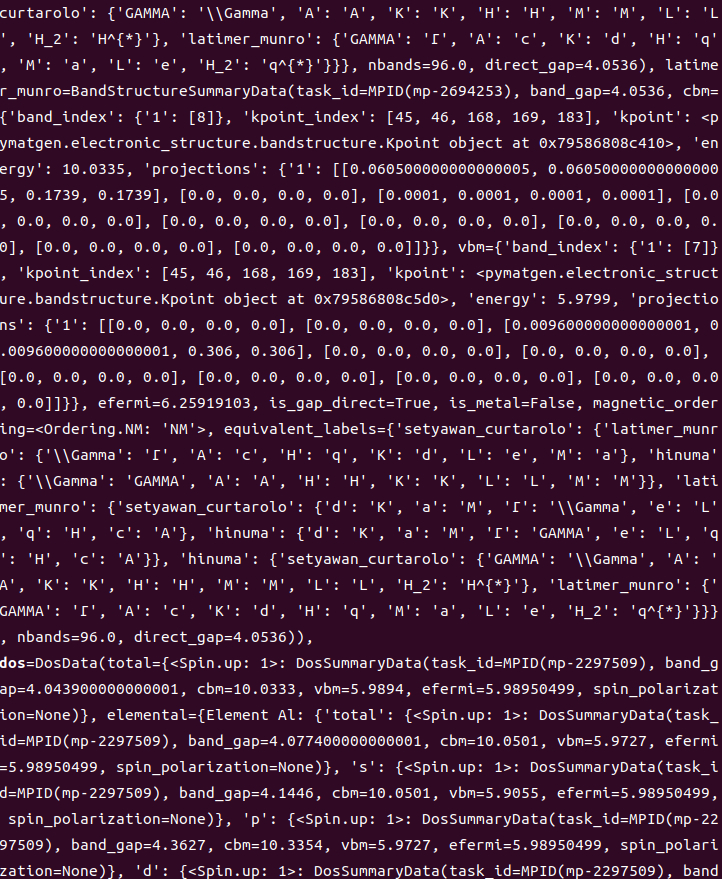
print(f"Material ID: {material.material_id}") 就是把当前物质的编号打印出来,方便我们后续进行手动查阅,那就会输出为Material ID: mp-661
print(f"Formula: {material.formula_pretty}") 为把当前物质的化学式打印出来,那就会输出为Formula: AlN
这就是最基本的调取方式了,我们可以在此基础上进行改进,比如我现在只想要structure,我只想看AlN的结构,其他内容我都不敢兴趣,该怎么办呢,就可以进行以下改进
python
#原
docs = mpr.materials.summary.search(material_ids=["mp-661"])
#改进后
docs = mpr.materials.summary.search(material_ids=["mp-661"], fields=["structure"])我们就是在后面添加了一个fields="structure",就是明确了我们需要的参数,则只会输出structure了,注意,由于我们只获取了structure,我们代码最后的输出编号和输出化学式会发生报错,因为我们没有获取这部分参数
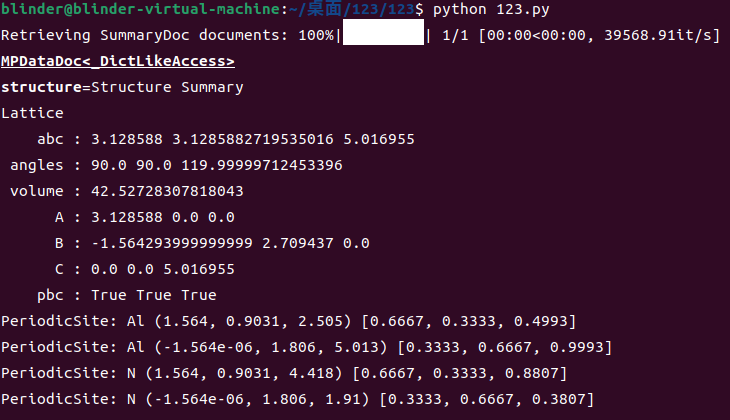
输出的structure如上图,你会注意到,后面跟着另一大串东西,这一大串东西就是我们本次调取没有获取的参数,那你也可以反向理解为api能获取的所有参数,那你就可以根据自己的需求在这一大堆东西里面找自己需要的然后进行获取了。
python
Fields not requested:
['builder_meta', 'nsites', 'elements', 'nelements', 'composition', 'composition_reduced', 'formula_pretty', 'formula_anonymous', 'chemsys', 'volume', 'density', 'density_atomic', 'symmetry', 'material_id', 'deprecated', 'deprecation_reasons', 'last_updated', 'origins', 'warnings', 'property_name', 'task_ids', 'uncorrected_energy_per_atom', 'energy_per_atom', 'formation_energy_per_atom', 'energy_above_hull', 'is_stable', 'equilibrium_reaction_energy_per_atom', 'decomposes_to', 'xas', 'grain_boundaries', 'band_gap', 'cbm', 'vbm', 'efermi', 'is_gap_direct', 'is_metal', 'es_source_calc_id', 'bandstructure', 'dos', 'dos_energy_up', 'dos_energy_down', 'is_magnetic', 'ordering', 'total_magnetization', 'total_magnetization_normalized_vol', 'total_magnetization_normalized_formula_units', 'num_magnetic_sites', 'num_unique_magnetic_sites', 'types_of_magnetic_species', 'bulk_modulus', 'shear_modulus', 'universal_anisotropy', 'homogeneous_poisson', 'e_total', 'e_ionic', 'e_electronic', 'n', 'e_ij_max', 'weighted_surface_energy_EV_PER_ANG2', 'weighted_surface_energy', 'weighted_work_function', 'surface_anisotropy', 'shape_factor', 'has_reconstructed', 'possible_species', 'has_props', 'theoretical', 'database_IDs']2.保存调取数据(pymatgen,pd)
大多数时候,我们调取数据其实是为了拿到cif或者POSCAR结构文件进行vasp或者MS运算,所以我们不光要把数据打印下来,我们还要保存调取到的数据,那这个时候一般使用pymatgen会比较好
那废话不多说,我们继续从AlN入手,直接给出保存cif的代码
python
from mp_api.client import MPRester
from pymatgen.io.cif import CifWriter
API_KEY = "INST77l4U0NpD1e4cPN8kXBodi877HRQ"
with MPRester(API_KEY) as mpr:
docs = mpr.materials.summary.search(material_ids=["mp-661"], fields=["structure","material_id"])
for material in docs:
print(material)
print(f"Material ID: {material.material_id}")
#print(f"Formula: {material.formula_pretty}")
structure = material.structure
cif_writer = CifWriter(structure)
cif_writer.write_file(f"{material.material_id}.cif")其实也很好理解,首先structure = material.structure是把当前物质的structure参数赋值,随后使用CifWriter进行cif写入的初始化,最后保存
注:我们本次调取的数据除了structure以外还有编号,方便我们给文件进行命名,但是由于我们没有获取化学式,所以要把打印化学式的部分注释掉,不然会报错
运行后输出的内容如下
python
# generated using pymatgen
data_AlN
_symmetry_space_group_name_H-M 'P 1'
_cell_length_a 3.12858800
_cell_length_b 3.12858827
_cell_length_c 5.01695500
_cell_angle_alpha 90.00000000
_cell_angle_beta 90.00000000
_cell_angle_gamma 119.99999712
_symmetry_Int_Tables_number 1
_chemical_formula_structural AlN
_chemical_formula_sum 'Al2 N2'
_cell_volume 42.52728308
_cell_formula_units_Z 2
loop_
_symmetry_equiv_pos_site_id
_symmetry_equiv_pos_as_xyz
1 'x, y, z'
loop_
_atom_site_type_symbol
_atom_site_label
_atom_site_symmetry_multiplicity
_atom_site_fract_x
_atom_site_fract_y
_atom_site_fract_z
_atom_site_occupancy
Al Al0 1 0.66666700 0.33333300 0.49928700 1
Al Al1 1 0.33333300 0.66666700 0.99928700 1
N N2 1 0.66666700 0.33333300 0.88071300 1
N N3 1 0.33333300 0.66666700 0.38071300 1不仅如此呢,我们还可以保存为POSCAR文件,代码如下
python
from mp_api.client import MPRester
from pymatgen.io.vasp import Poscar
API_KEY = "INST77l4U0NpD1e4cPN8kXBodi877HRQ"
with MPRester(API_KEY) as mpr:
docs = mpr.materials.summary.search(material_ids=["mp-661"], fields=["structure","material_id"])
for material in docs:
print(material)
print(f"Material ID: {material.material_id}")
#print(f"Formula: {material.formula_pretty}")
structure = material.structure
poscar = Poscar(structure)
poscar.write_file(f"{material.material_id}.POSCAR")其实结构差不多的,只是最开始import的库与函数名发生了变化,但是结构和用法并没有任何区别
运行后输出的内容如下
python
Al2 N2
1.0
3.1285880000000001 0.0000000000000000 0.0000000000000000
-1.5642939999999990 2.7094369999999999 0.0000000000000000
0.0000000000000000 0.0000000000000000 5.0169550000000003
Al N
2 2
direct
0.6666670000000000 0.3333330000000000 0.4992870000000000 Al
0.3333330000000000 0.6666670000000000 0.9992869999999990 Al
0.6666670000000000 0.3333330000000000 0.8807130000000000 N
0.3333330000000000 0.6666670000000000 0.3807129999999990 N如果我们想要保存其他数据怎么办呢?能带宽度,密度等参数可以保存为csv,从而进行相关参数设置,示例代码如下
python
from mp_api.client import MPRester
import pandas as pd
API_KEY = "INST77l4U0NpD1e4cPN8kXBodi877HRQ"
material_properties = []
with MPRester(API_KEY) as mpr:
docs = mpr.materials.summary.search(
chemsys=["Ga-N", "Al-N", "In-N"],
band_gap=(3, None)
)
for mat in docs:
prop_dict = {
"material_id": mat.material_id, # MP唯一ID
"formula": mat.formula_pretty, # 规整化学式
"band_gap(eV)": mat.band_gap, # 带隙值
"density(g/cm³)": mat.density, # 密度
"nsites": mat.nsites, # 晶胞中原子总数
}
material_properties.append(prop_dict)
df = pd.DataFrame(material_properties)
df.to_csv("mp_materials_properties.csv", index=False, encoding="utf-8")
print("属性已导出到 mp_materials_properties.csv")首先我们看到docs = mpr.materials.summary.search(chemsys="Ga-N", "Al-N", "In-N",band_gap=(3, None)),我们修改了获取的数据,不再获取简单的编号数据,而是给出更加细致的要求
首先***chemsys="Ga-N", "Al-N", "In-N"***是指的我们想要的物质的元素组成,这次调取的就是由Ga与N组成的和Al与N组成的和ln与N组成的物质
随后的***band_gap=(3, None)***指的是我们想要的物质的能带要求,本次调取的就是能带宽度从3到无穷大的物质,
只有同时满足以上两个条件的物质才会被调取
随后把我们想要的参数给赋值出来,最后使用pd将上述数据保存为csv文件
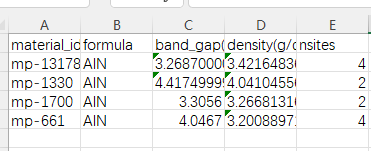
基本使用pymatgen和pandas就能满足你大部分的数据保存了,其他的功能只需要从这些基本用法进行举一反三即可。
3.其他用法示例
以下的都只是搞了获取,没有保存或打印,需要自己加,仅供学习参考
查找具有介电数据的所有条目的材料项目 ID
python
from mp_api.client import MPRester
from emmet.core.summary import HasProps
with MPRester("your_api_key_here") as mpr:
docs = mpr.materials.summary.search(has_props=[HasProps.dielectric], fields=["material_id"])
mpids = [doc.material_id for doc in docs]仅包含 Si 和 O 的所有材料的带隙
python
from mp_api.client import MPRester
with MPRester("your_api_key_here") as mpr:
docs = mpr.materials.summary.search(chemsys="Si-O", fields=["material_id", "band_gap"])
mpid_bgap_dict = {doc.material_id: doc.band_gap for doc in docs}包含至少 Si 和 O 的所有材料的化学式
python
from mp_api.client import MPRester
with MPRester("your_api_key_here") as mpr:
docs = mpr.materials.summary.search(elements=["Si", "O"], fields=["material_id", "band_gap", "formula_pretty"])
mpid_formula_dict = {doc.material_id: doc.formula_pretty for doc in docs}具有 ABC3 形式的所有三元氧化物的材料 ID
python
from mp_api.client import MPRester
with MPRester("your_api_key_here") as mpr:
docs = mpr.materials.summary.search(chemsys="O-*-*", formula="ABC3", fields=["material_id"])
mpids = [doc.material_id for doc in docs]具有大带隙(>3eV)的稳定材料(在 GGA/GGA+U 凸包上)
python
from mp_api.client import MPRester
with MPRester("your_api_key_here") as mpr:
docs = mpr.materials.summary.search(band_gap=(3, None), is_stable=True, fields=["material_id"])
stable_mpids = [doc.material_id for doc in docs]4.参考文献
我只是把一些比较基本的用法给出来了,最好还是去看这些官方文档哦,88
Getting Started | Materials Project Documentation![]() https://docs.materialsproject.org/downloading-data/using-the-api/getting-startedMaterials Project API - ReDoc
https://docs.materialsproject.org/downloading-data/using-the-api/getting-startedMaterials Project API - ReDoc![]() https://api.materialsproject.org/redoc#section/API-KeyMaterials Project API - Swagger UI
https://api.materialsproject.org/redoc#section/API-KeyMaterials Project API - Swagger UI![]() https://api.materialsproject.org/docs#/
https://api.materialsproject.org/docs#/