引言:异步解耦的基石
在分布式系统中,我们常面临这样的挑战:服务间紧耦合与同步调用阻塞。例如,订单服务在完成交易后,若需同步调用库存、物流、积分等多个下游服务,任何一环的延迟或失败都将阻塞整个链路,损害用户体验,且服务间升级迭代相互掣肘,系统僵化。
RabbitMQ 正是为破解此难题而生的"消息代理"。它如同一个智能、可靠的邮局,在服务间构筑了一个异步通信层,让服务只需专注于"投递"与"收取"消息,彼此独立演进,从而实现了系统的解耦、弹性与可扩展性。
1.架构分析
1.1 核心价值:不只是消息转发
RabbitMQ 的核心价值远不止于消息转发,它定义了一套基于 AMQP 协议的标准化通信范式,带来三大核心优势:
- 削峰填谷:面对瞬时流量洪峰,消息可在队列中暂存,让后端服务按自身能力匀速消费,避免系统被击垮。
- 应用解耦:服务间通过消息通信,而非直接调用。任一服务的变更、重启或扩容,均不影响其他服务,极大提升了系统的可维护性与弹性。
- 异步提速:生产者发出消息后即可返回,无需等待消费者处理完成,从而大幅缩短核心链路响应时间,提升用户体验。
1.2 四大组件协同工作
1.2.1 总览
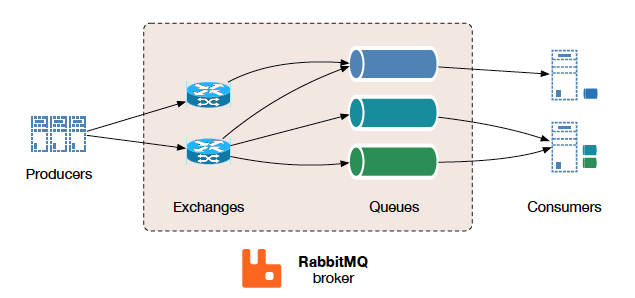
RabbitMQ 的消息流转并非简单的"发-存-收",而是基于一套精密的四组件协作模型:
bash
[Producer] --> (消息 + routing_key) --> [Exchange]
|
(根据路由规则)
|
[Consumer] <-- [Queue] <--(Binding)-- [Exchange]这里我们介绍一下一些核心概念:
- 生产者:消息的创造者,将消息发送到交换机,并携带一个 routing_key。
- 交换机:消息路由的决策中心,不存储消息,仅根据自身类型和绑定规则,决定将消息投递到哪些队列。这是RabbitMQ灵活性的核心。
- 队列:消息的存储容器,本质是位于Broker上的缓冲区,等待消费者拉取。消息在此持久化,确保不丢失。
- 消费者:消息的处理者,从队列中获取消息并进行业务处理。
绑定:连接交换机与队列的路由规则,定义了什么样的消息应该进入哪个队列。
关键在于"交换机"的引入,它让生产者与具体队列彻底解耦。生产者只需关心"把消息发给哪个交换机、带什么标签",而"消息最终去哪"由服务端的路由规则动态决定。
1.2.2 交换机的四种类型:路由策略的多样性
根据不同的路由策略,RabbitMQ提供了四种交换机类型,以适应不同场景:
| 类型 | 路由规则 | 典型场景 |
|---|---|---|
| Direct | 精确匹配。消息的 routing_key 必须与绑定的 binding_key 完全一致。 |
点对点任务分发,如将特定订单消息路由到指定处理队列。 |
| Topic | 模式匹配。支持 * (匹配一个单词) 和 # (匹配多个单词) 通配符。 |
灵活的事件通知,如将 system.error 日志路由到所有错误处理队列。 |
| Fanout | 广播。忽略 routing_key,将消息复制并路由到所有绑定的队列。 |
系统公告、需要多个下游服务同时处理同一消息的场景。 |
| Headers | 头部匹配。根据消息头(Headers)中的键值对进行匹配,不依赖 routing_key。 |
极特殊的路由需求,因配置复杂,生产中较少使用。 |
1.2.3 高并发基石:信道与连接模型
RabbitMQ采用 "TCP连接 + 多信道" 的模型来支撑高并发:
- TCP连接:是应用程序与Broker之间的物理长链接,创建成本较高。
- 信道:是建立在TCP连接之上的虚拟轻量级链接。所有具体的消息操作(声明队列、发布/消费消息)都通过信道进行。
一个TCP连接上可以创建多个信道。这种设计实现了连接复用,多个线程可共享同一连接,通过各自独立的信道安全通信,避免了频繁创建TCP连接的开销,是性能的关键保障。
1.2.4 可靠性保障:从生产到消费的守护
RabbitMQ通过一套组合机制,确保消息不丢失:
1.生产者到Broker:通过 发布确认 机制,生产者可异步确认消息是否已被Broker成功接收并持久化。
2.Broker内部存储:
- 队列持久化:声明队列时设置为持久化,Broker重启后队列不丢失。
- 消息持久化:发送消息时设置 deliveryMode=2,Broker会将消息写入磁盘。其存储设计将所有队列的持久化消息顺序写入同一文件,通过索引维护映射,兼顾了IO效率与可靠性。
3.Broker到消费者:这是关键环节,通过ACK机制保证:
- 自动ACK:消息被消费者获取即视为成功。若消费者崩溃,消息永久丢失。
- 手动ACK:消费者处理完消息后必须显式发送ACK。若消费者崩溃,Broker未收到ACK,会将消息重新投递。这是实现"至少一次"消费的标配,但要求业务逻辑实现幂等性以应对可能的重复消费。
1.2.5 小结
RabbitMQ以其清晰的"生产者 -> 交换机 -> 队列 -> 消费者"架构,通过异步化、解耦、流量缓冲和可靠投递,成为构建弹性分布式系统的关键中间件。
然而,能力与复杂度并存:
- 它引入了最终一致性模型,需处理消息时序、重复消费等问题。
- 绝对的可靠性(持久化、手动ACK)会牺牲部分性能(磁盘IO、网络往返)。
- 其灵活的路由(Topic/Fanout)与队列模型,不同于Kafka的流式分区模型,在超大规模日志、流处理场景下可能并非最优。
因此,选择RabbitMQ,意味着你选择了一个在任务分发、事件驱动、应用解耦场景下成熟、稳定且高度灵活的异步通信方案,但同时也必须对其引入的复杂性(如死信处理、监控、集群部署)有充分的认知和设计。
2.同行比较
在分布式系统架构中,消息队列是异步通信的核心组件。面对市面上主流的三款消息中间件,很多开发者常常陷入"选择困难症"。它们各有千秋,没有绝对的好坏,只有是否适合你的业务场景。本文将深入对比 RabbitMQ、Kafka 和 RocketMQ,助你做出精准的技术选型。
2.1 核心定位与设计哲学
RabbitMQ (通用消息代理):基于 AMQP 协议,核心定位是灵活路由。它像一位"邮局管理员",擅长根据复杂的路由规则(Direct、Topic、Fanout、Headers)将消息精准投递到指定队列。设计优先级为 功能灵活性 > 极致性能,适合企业级应用集成和中小吞吐量场景。
Kafka (分布式流处理平台):最初为解决 LinkedIn 的日志处理问题而生,核心定位是高吞吐。它像一条"数据高速公路",擅长处理海量数据流(如日志、监控数据),吞吐量可达百万级 TPS。设计优先级为 吞吐量 > 低延迟,适合大数据和实时流处理场景。
RocketMQ (金融级消息中间件):由阿里开源,核心定位是金融级高可靠。它像一位"银行柜员",在保证高吞吐的同时,对事务消息、顺序消息和低延迟有极致要求。设计优先级为 高可靠 + 高吞吐,适合电商交易、金融支付等核心业务。
2.2 核心特性横向对比
| 维度 | RabbitMQ | Kafka | RocketMQ |
|---|---|---|---|
| 吞吐量 | 万级 QPS (单节点1-2万) | 百万级 QPS (单机可达50万+) | 十万级 QPS (单机可达10万+) |
| 延迟 | 最低 (微秒级) | 较高 (毫秒级,批量发送机制导致) | 较低且稳定 (毫秒级,金融级优化) |
| 顺序消息 | 仅单队列有序 | 分区(Partition)内有序 | 支持全局/分区严格顺序 |
| 事务消息 | 支持(Confirm机制) | 支持(0.11+版本,但性能差) | 核心优势,性能优越 |
| 路由灵活性 | 极高 (多种交换机类型) | 弱 (无复杂路由) | 中等 (基于Topic和Tag) |
| 消息堆积能力 | 弱 (内存依赖强) | 极强 (磁盘顺序IO,TB级堆积) | 强 (磁盘+内存混合存储) |
| 生态与社区 | 成熟稳定,支持多协议 | 大数据生态第一 (Flink/Spark) | 国内最火,Java生态首选 |
2.3 深度差异解析
1 架构与存储机制
- RabbitMQ:采用 Broker-Exchange-Queue 模型。消息先到交换机,再路由到队列。存储机制依赖内存和磁盘随机IO,导致高吞吐场景下性能受限。
- Kafka:采用 Topic-Partition 模型。消息直接写入分区,采用顺序IO和零拷贝技术,极大提升了磁盘读写效率,这是其高吞吐的底层原因。
- RocketMQ:采用 CommitLog + ConsumeQueue 模型。所有消息顺序写入 CommitLog,再通过索引文件快速定位,兼顾了顺序IO的高效和随机读的灵活性。
2.性能瓶颈
- RabbitMQ:瓶颈在于单队列的并发能力和内存限制。当消息堆积时,内存耗尽会触发流控,甚至导致服务崩溃。
- Kafka:瓶颈在于分区数量。单个Partition只能被一个Consumer消费,若分区数不足,消费能力无法线性扩展。
- RocketMQ:瓶颈在于Broker节点的负载均衡。NameServer作为轻量级注册中心,在高并发下需关注网络抖动问题。
2.4 典型应用场景
1.选 RabbitMQ 的场景
- 企业级应用集成:需要复杂的路由规则,如根据消息头(Headers)进行路由。
- 简单任务队列:如邮件发送、短信验证码、用户注册通知。这些场景吞吐量要求不高,但需要低延迟和快速响应。
- 微服务解耦:中小规模的微服务架构,需要灵活的消息投递机制。
2 选 Kafka 的场景
- 日志收集与聚合:处理海量应用日志、用户行为埋点数据。
- 实时流处理:与 Flink、Spark Streaming 集成,进行实时计算、风控或监控。
- 大数据管道:作为数据源将数据导入 Hadoop 或数据仓库。
3.选 RocketMQ 的场景
- 金融级交易:如订单创建、支付回调、资金扣减。需要严格的事务消息保证最终一致性。
- 电商核心链路:如秒杀系统、库存扣减。需要高并发、低延迟且保证消息顺序。
- 高可靠业务:对消息不丢失、不重复有极高要求的业务场景。
总结:RabbitMQ 是灵活的"瑞士军刀",适合中小规模、路由复杂的场景。
Kafka 是"数据管道之王",适合大数据、高吞吐的流处理场景。
RocketMQ 是"金融级选手",适合高并发、强一致性的核心业务场景。
选型口诀:要灵活路由选 RabbitMQ,要大数据吞吐选 Kafka,要金融级可靠选 RocketMQ。
额外阅读材料:
- 消息队列RocketMQ是什么?和Kafka有什么区别?架构是怎么样的?7分钟快速入门
- kafka为什么这么快?RocketMQ哪里不如Kafka?
- 图解 kafka 架构 | kafka 为什么那么快?
- 图解 RocketMQ 结构|存储架构|生产、消费消息
3.小demo
3.1 安装
这里之前写了一篇博客,安装了rabbitmq,然后用go语言写了个简单的小demo: rabbitMQ安装与简单demo, 关于go 的安装可看: Go语言学习心路
注意下erlang与rabbitmq的版本对应 https://rabbitmq.org.cn/docs/which-erlang
rabbitmq下载太慢,可以去huawei的镜像网站下载 https://mirrors.huaweicloud.com/rabbitmq-server/v4.2.0/
3.2 案例
todo... 等我新装系统的电脑先装下环境... 我再写一个好理解的demo来适用下rabbitmq.