hadoop
高可靠性
高扩展性
高效性
高容错性
Hadoop组成
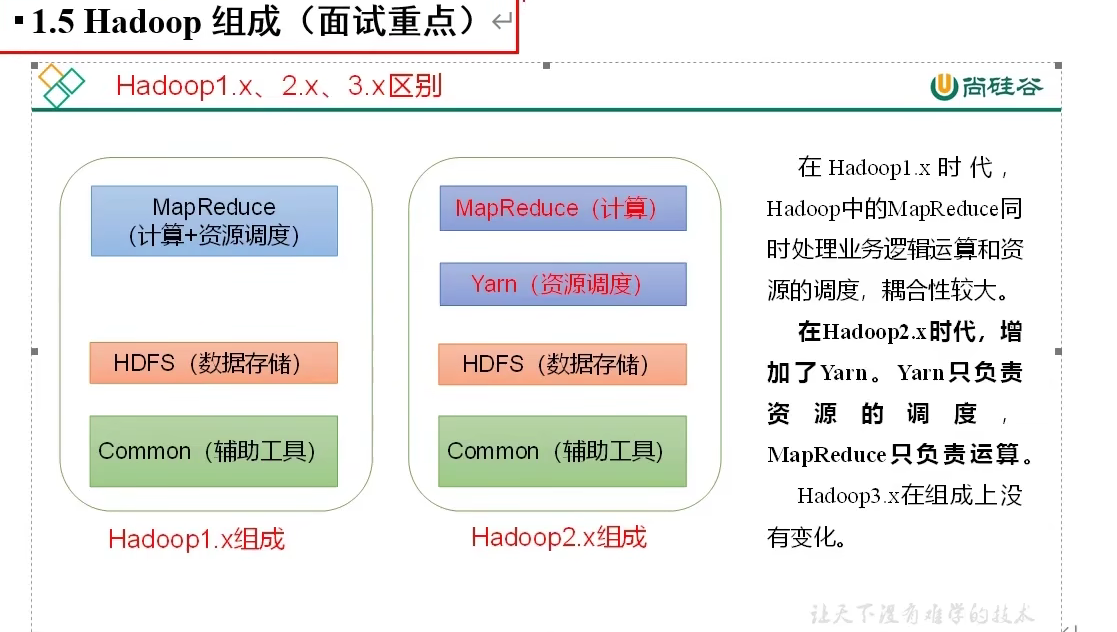
HDFS 分布式存储,用来存数据的
yarn概述
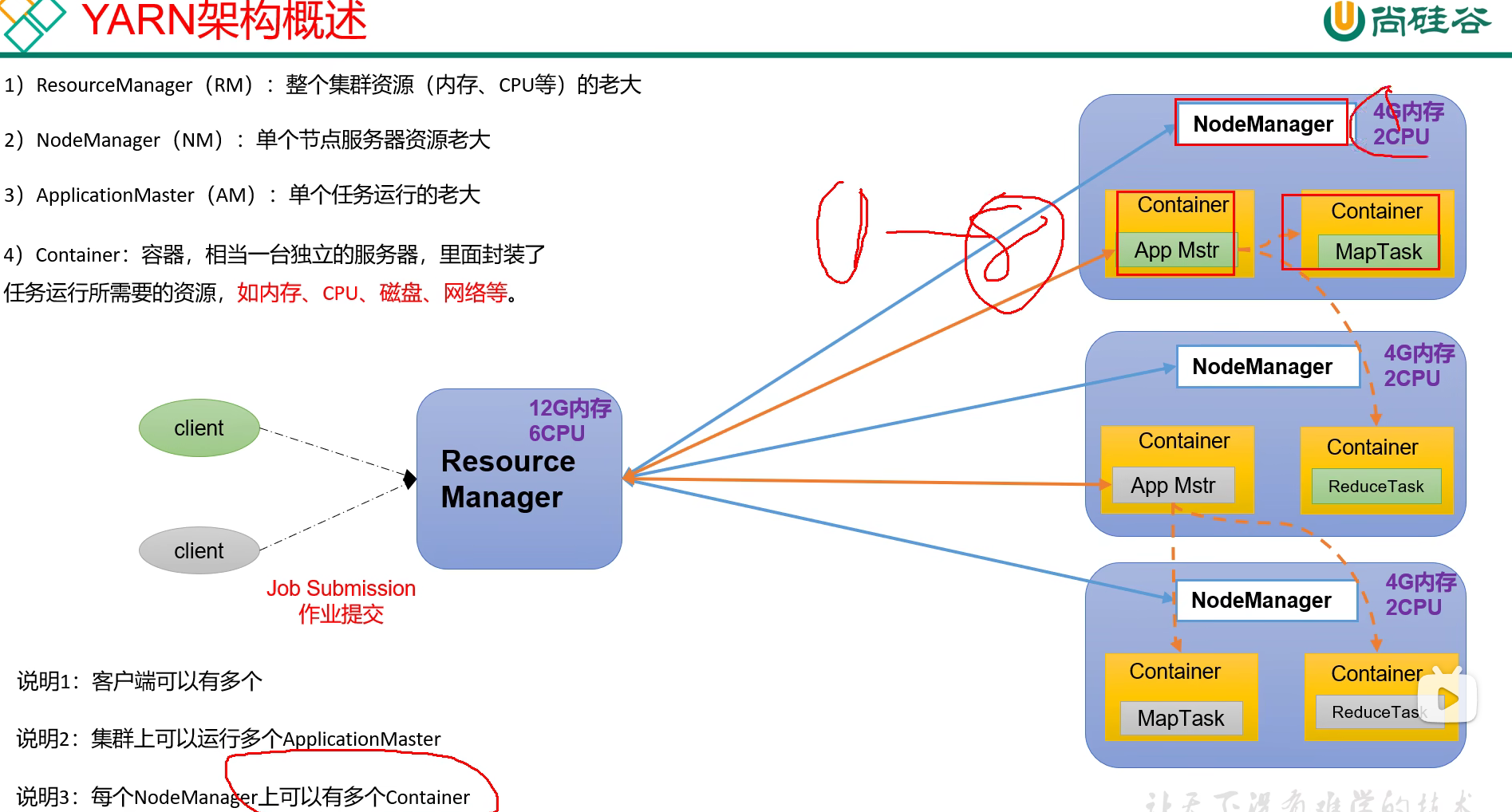
mapreduce概述

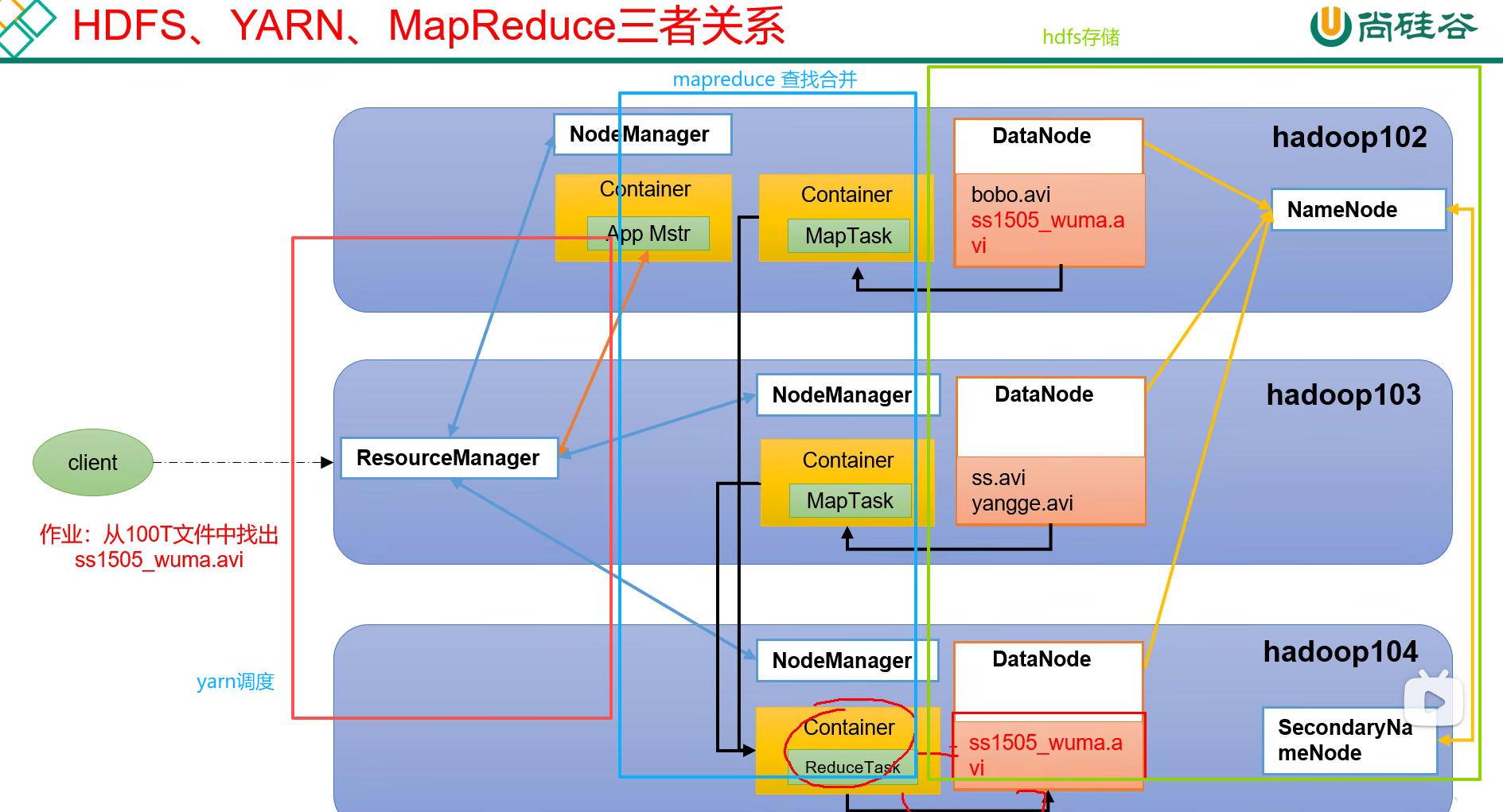
NameNode相当于目录,告诉文件在哪个datanode
配置虚拟机网络
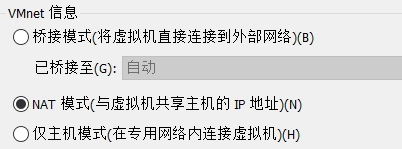
共享 IP:虚拟机通过主机的 IP 地址访问外部网络,外部网络看到的是主机的 IP,而非虚拟机的 IP。不是指它俩ip一样
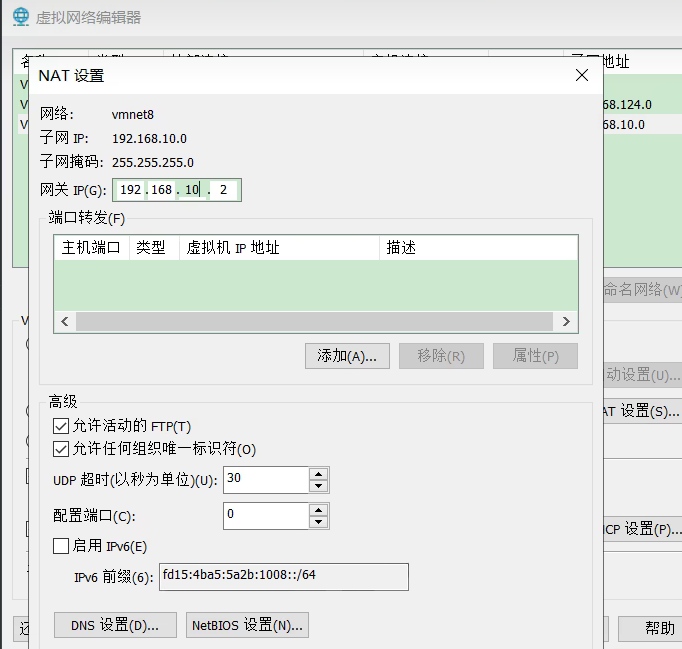
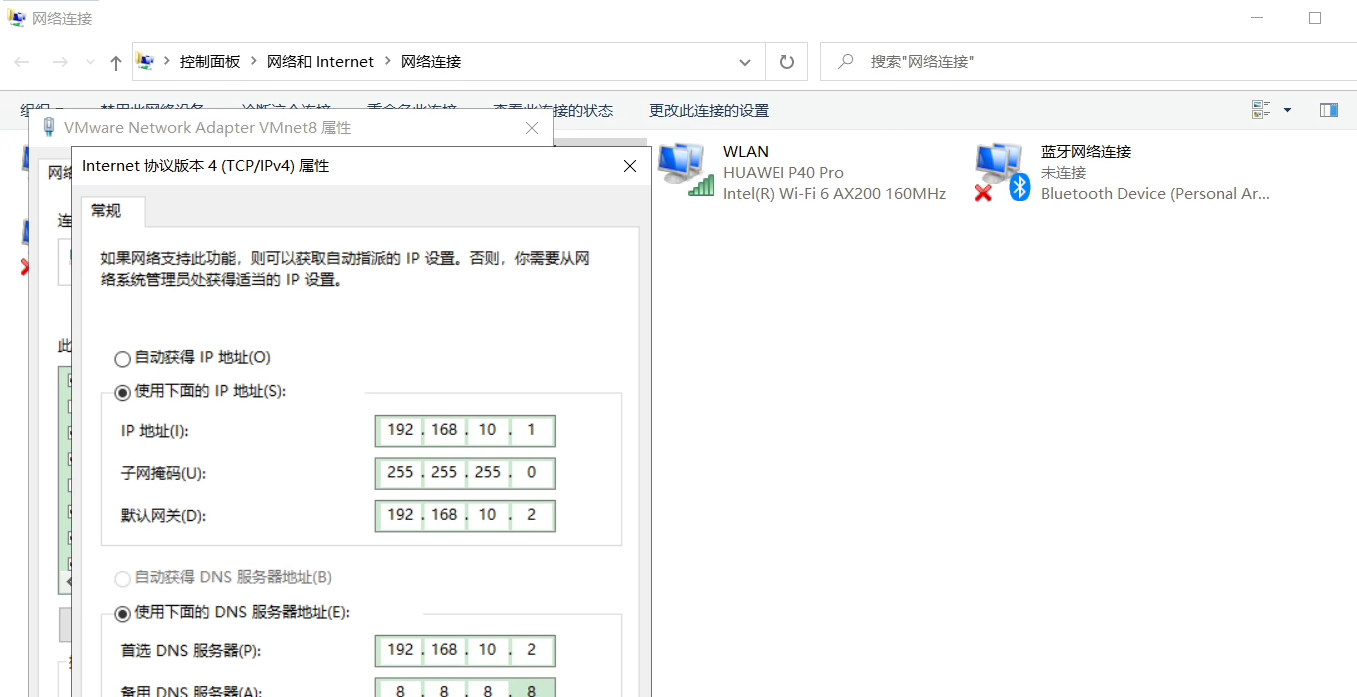
没有vnet8 打开虚拟机的虚拟网络设置

配置
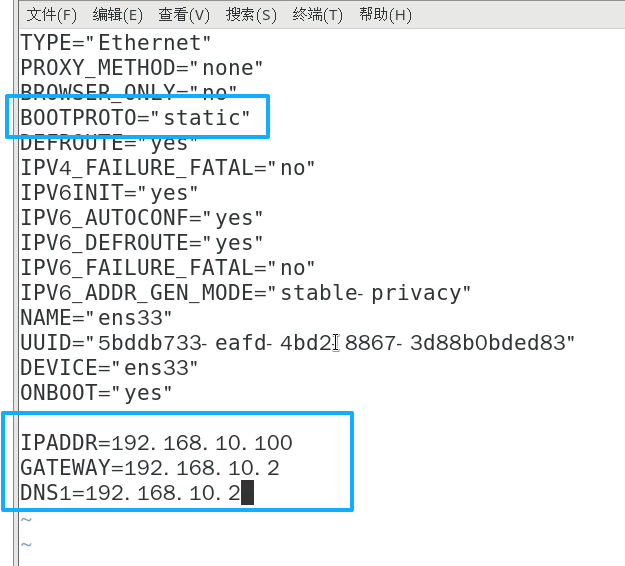
bash
vim etc/hostname
主机 ip映射
bash
vim /etc/hosts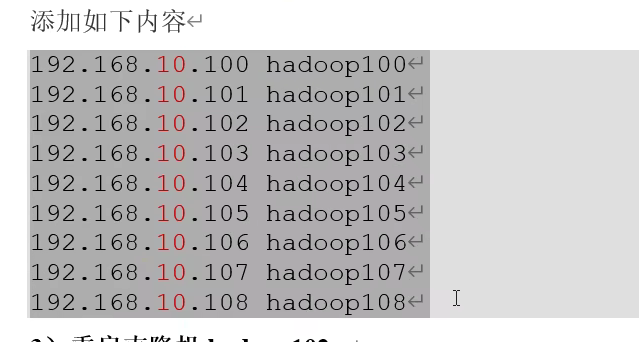
重启

可以ping一下网络



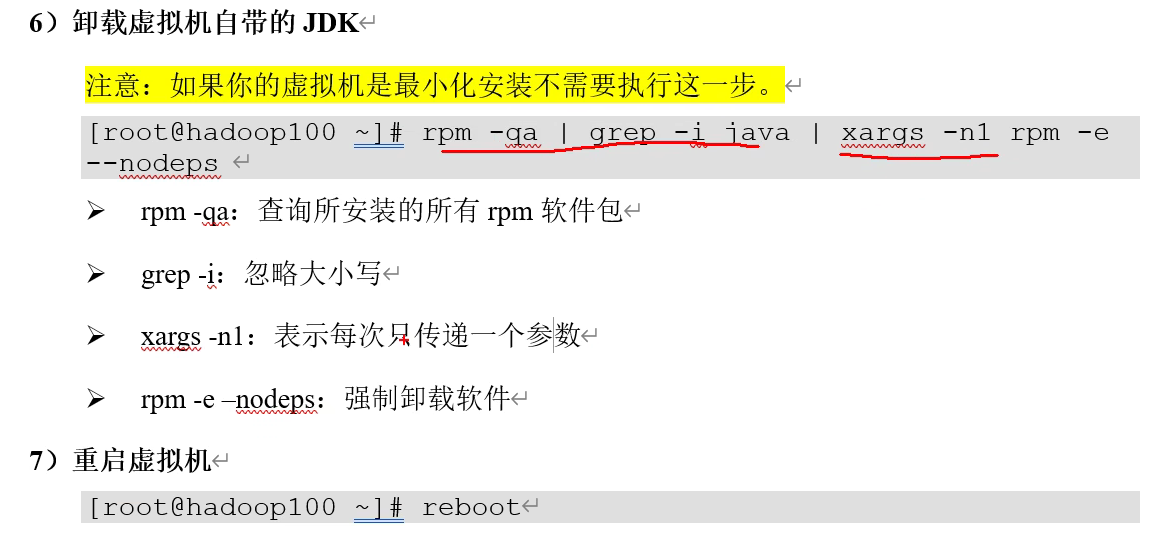
这时候atguigu 遇到权限不够可以尝试一下sudo
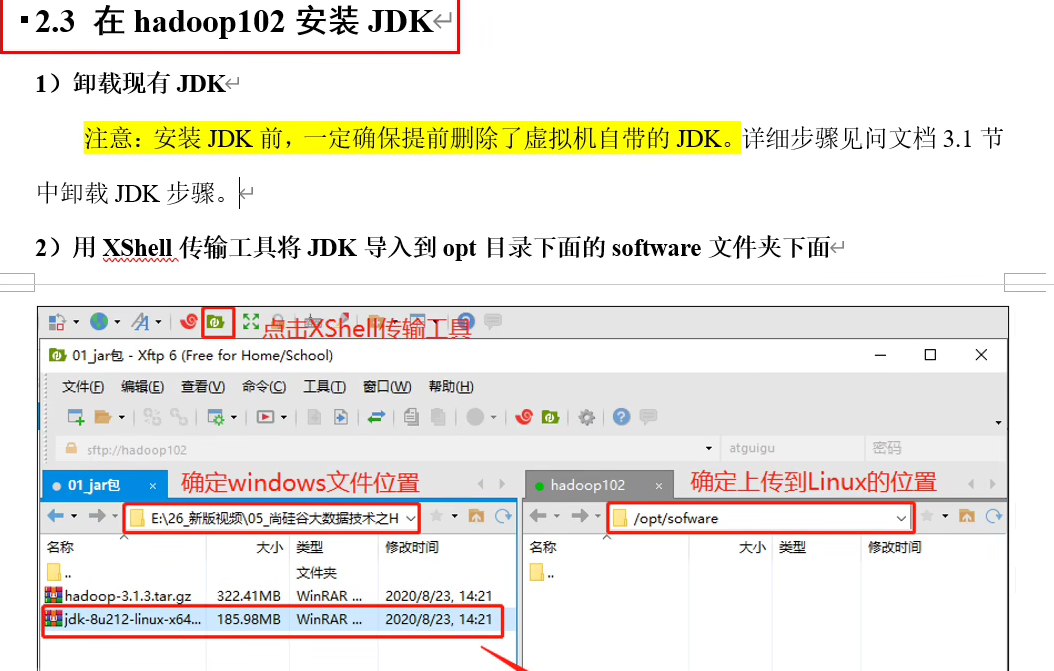
安装jdk
bash
tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/配置环境变量
bash
cd /etc/profile.dvim my_env.sh


安装Hadoop
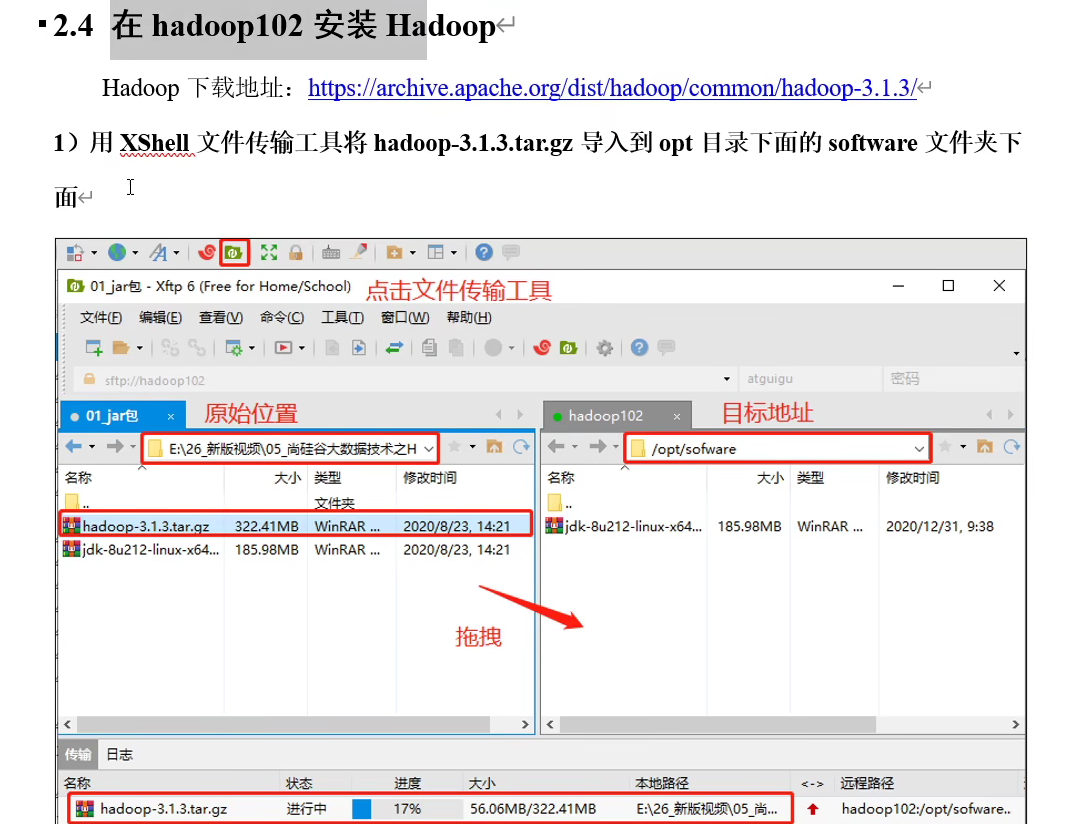
添加环境变量

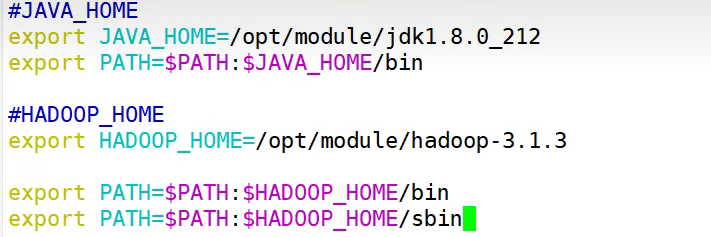
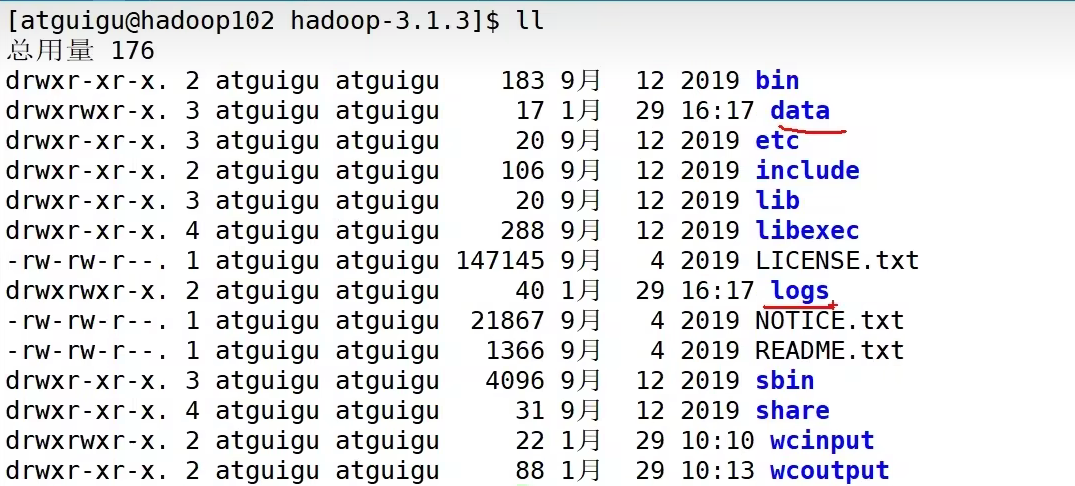
hadoop里的各种文件
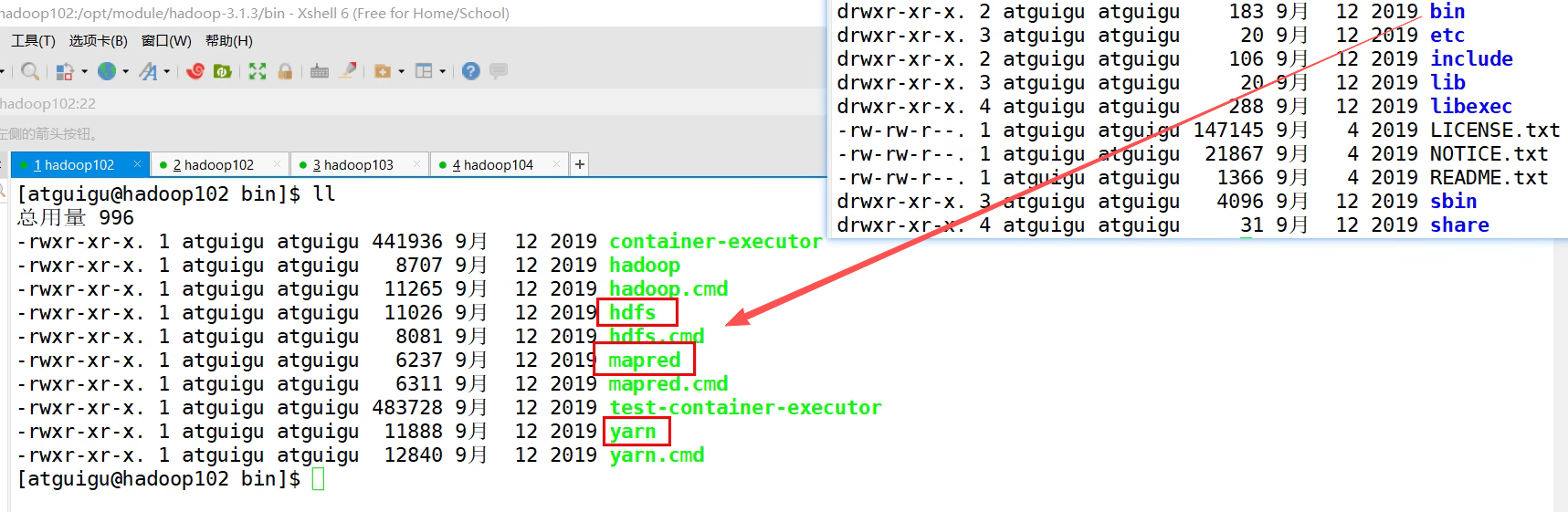
hadoop/etc有各种配置文件
lib/native
启动
hadoop运行模式



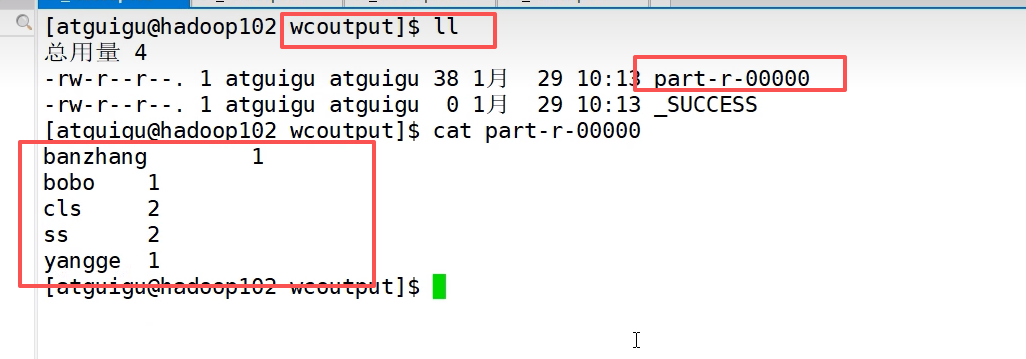
word.txt里
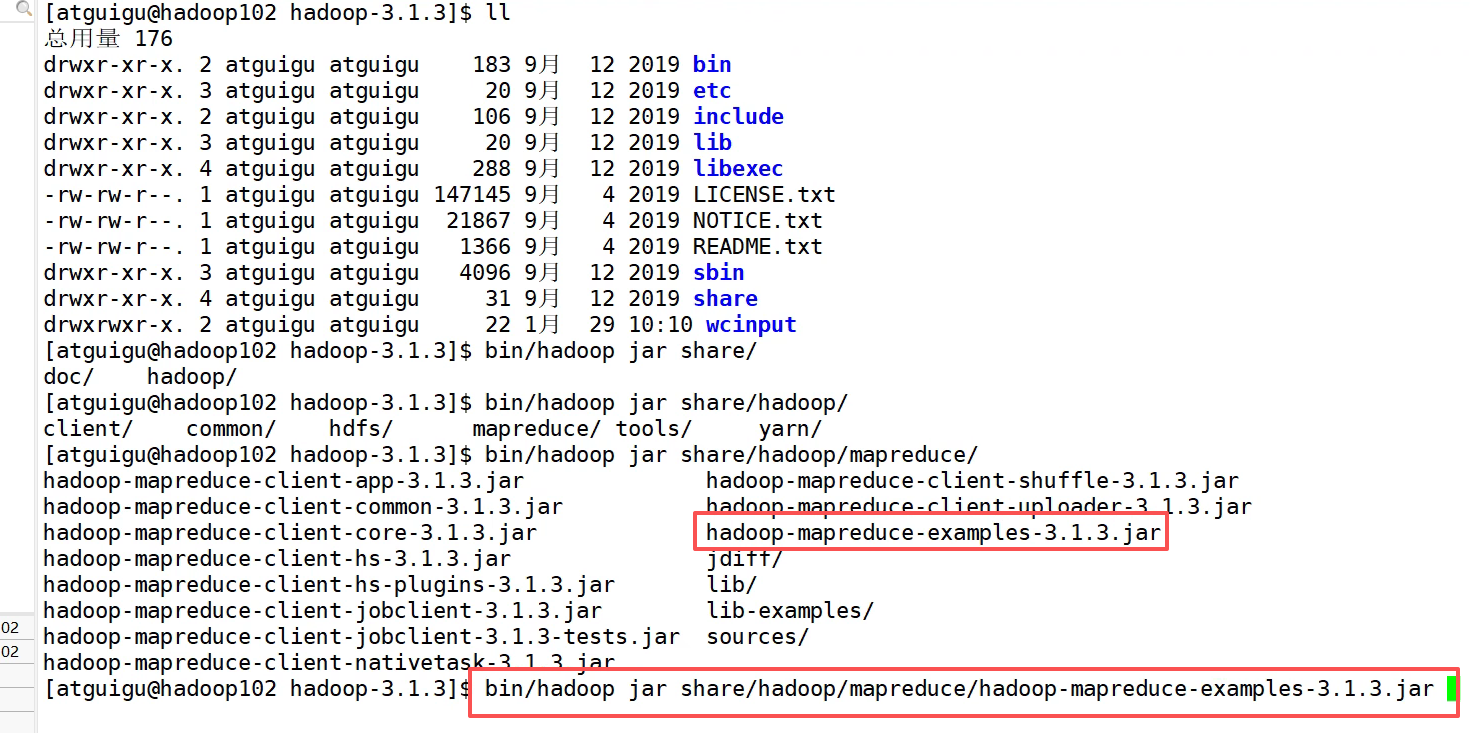
运行实例


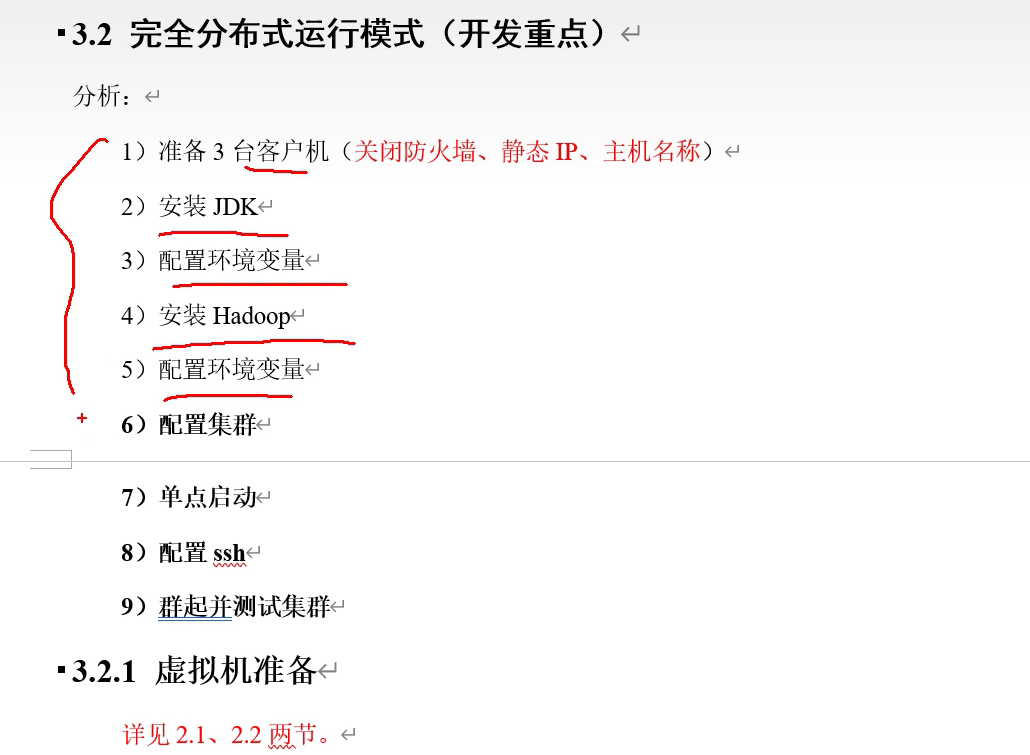
完全分布式运行模式
xsync分发脚本

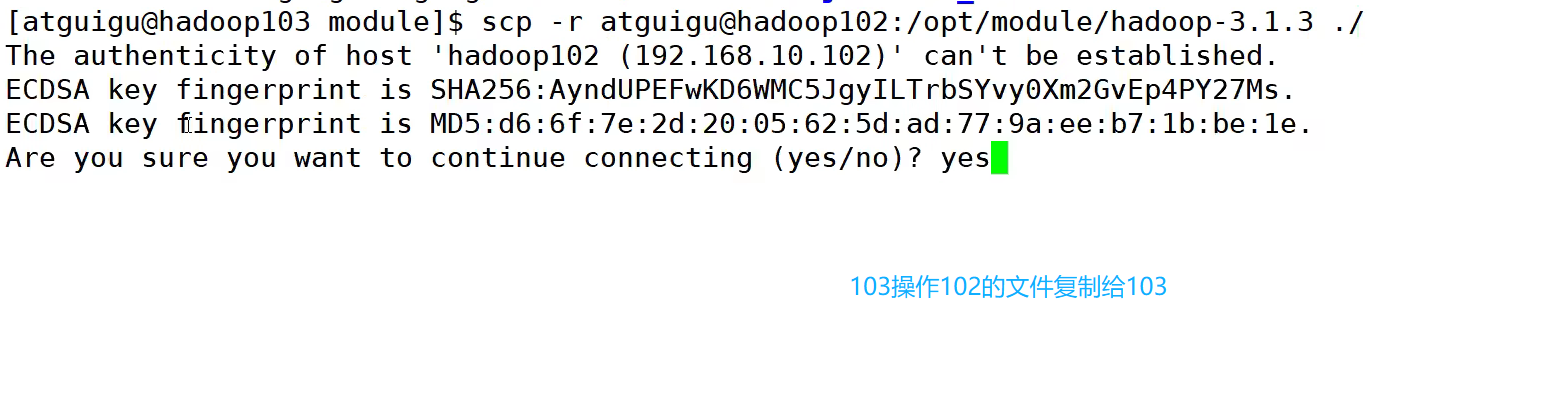
还可以在103 复制102给101

xsync集群分发脚本
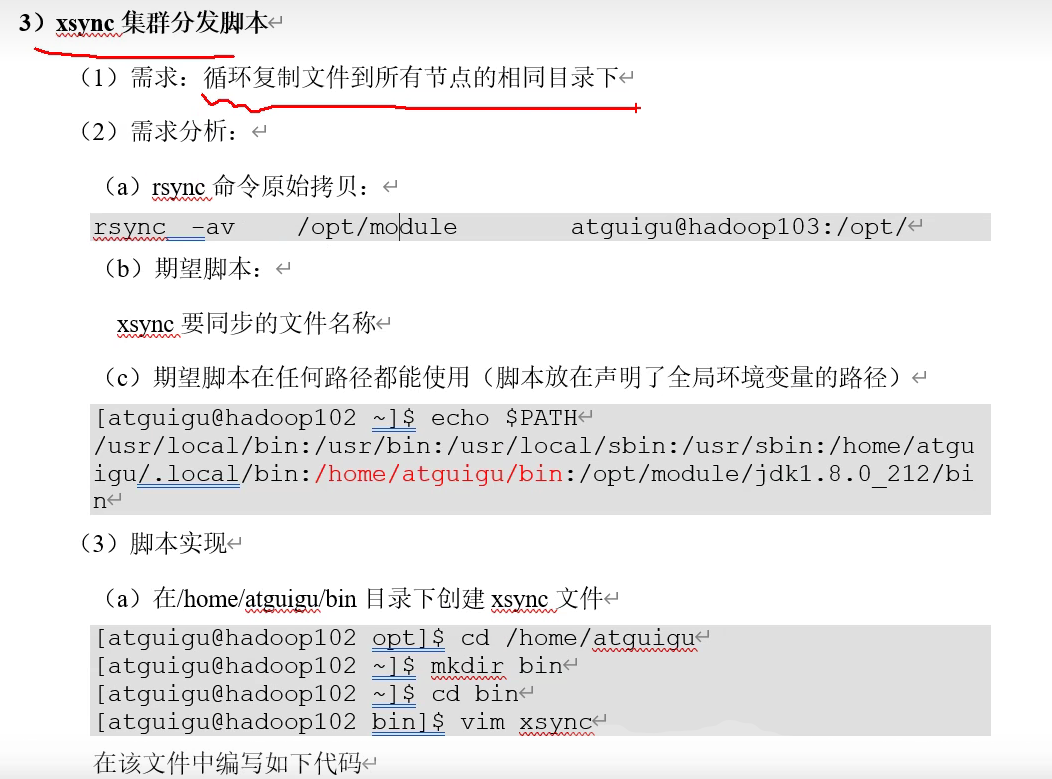
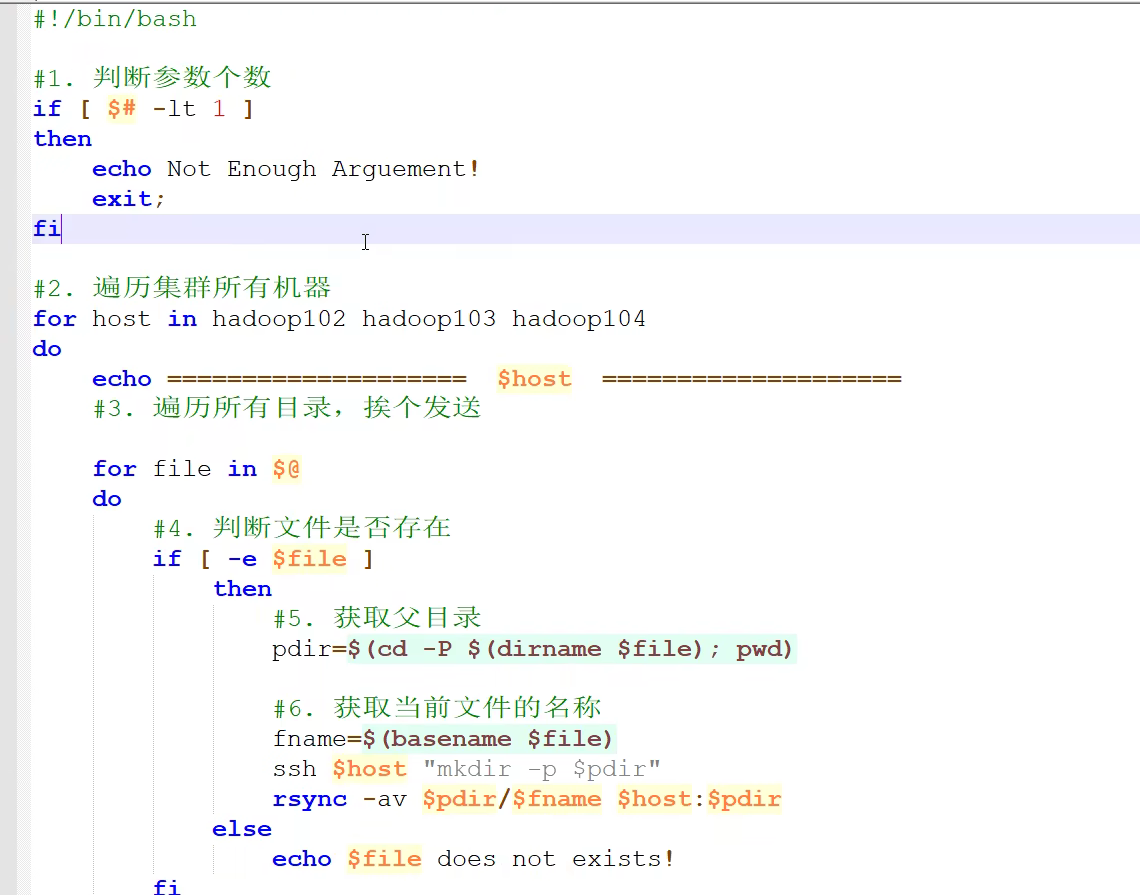
xsync a.txt b.txt c.txt #为3,@为a.txt,b.txt,c.txt
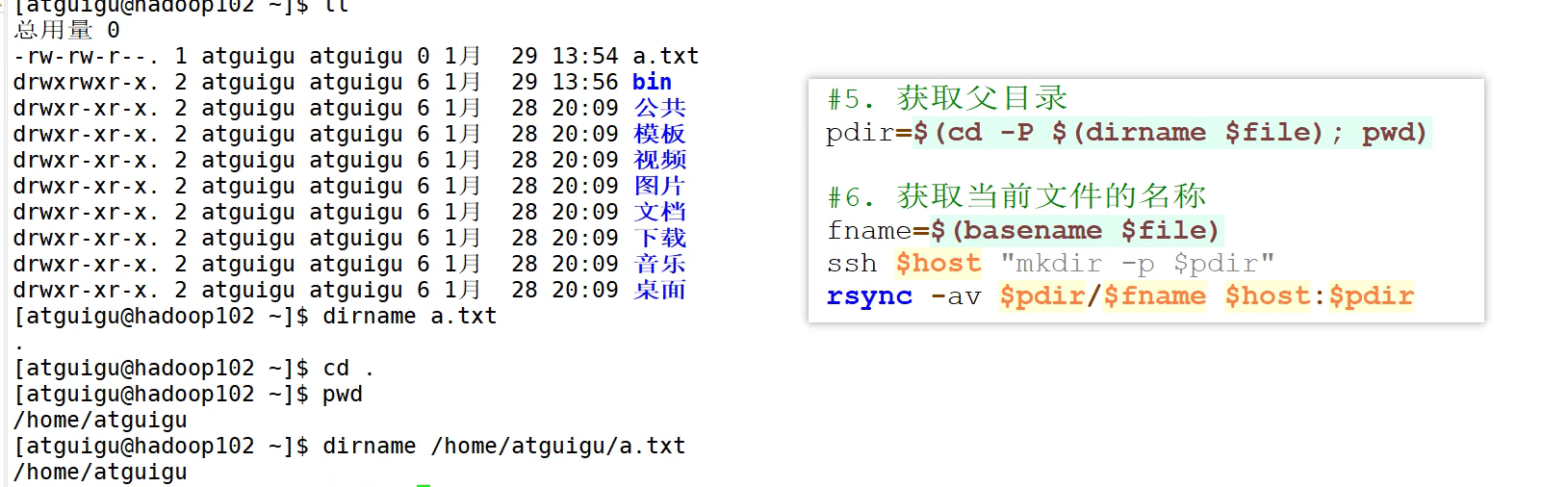
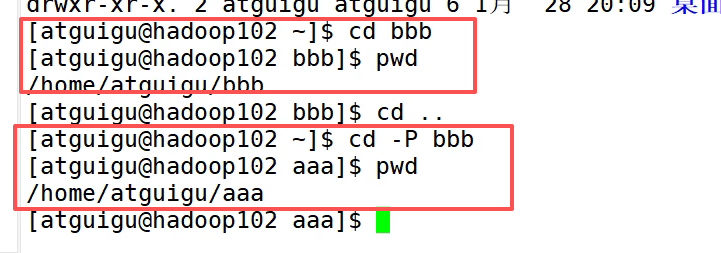
-P是防止进入软连接
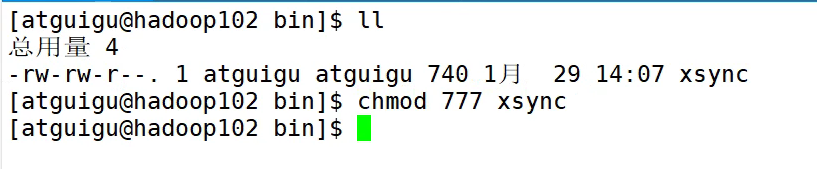
mkdir -p xxx去除已存在提示
注意分发后,source /etc/profile 目的是加载环境变量文件
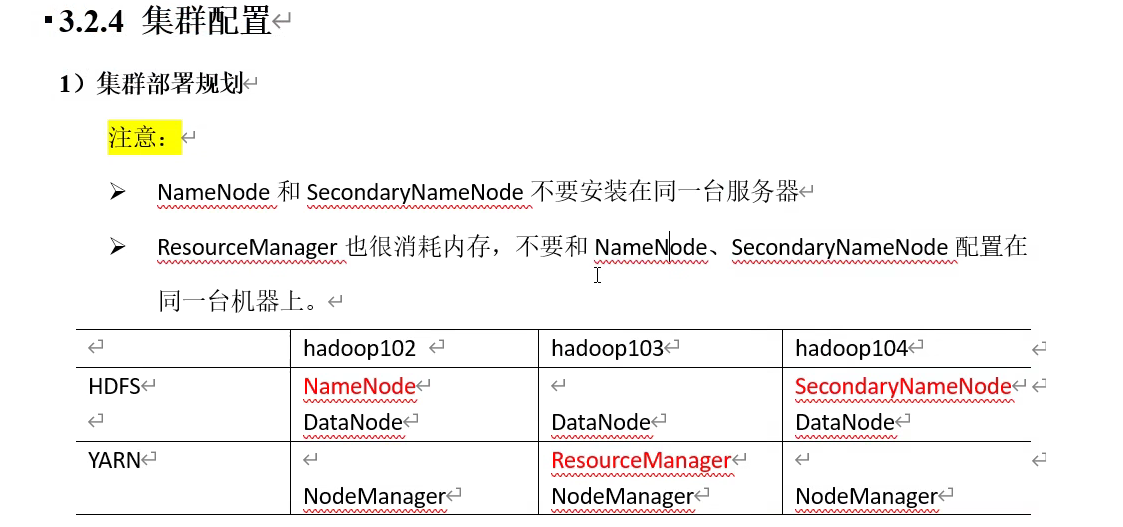
集群

vim core-site.xml NameNode

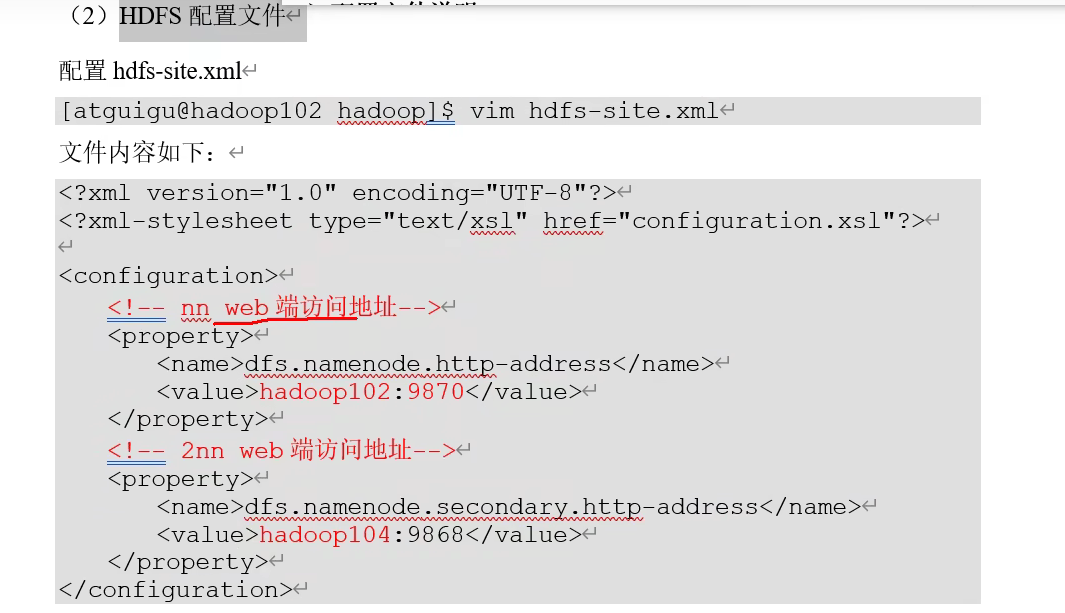
bash
<property>
<name>dfs.replication</name>
<!-- 配置存储份数,比如改为2 末默认3-->
<value>2</value>
<description>HDFS 默认数据块副本数</description>
</property>




停止namenode节点 Hadoop 2.x 常用 hadoop-daemon.sh stop namenode
Hadoop 3.x 推荐写法 hdfs --daemon stop namenode

初始化后

dfs/name/current/version

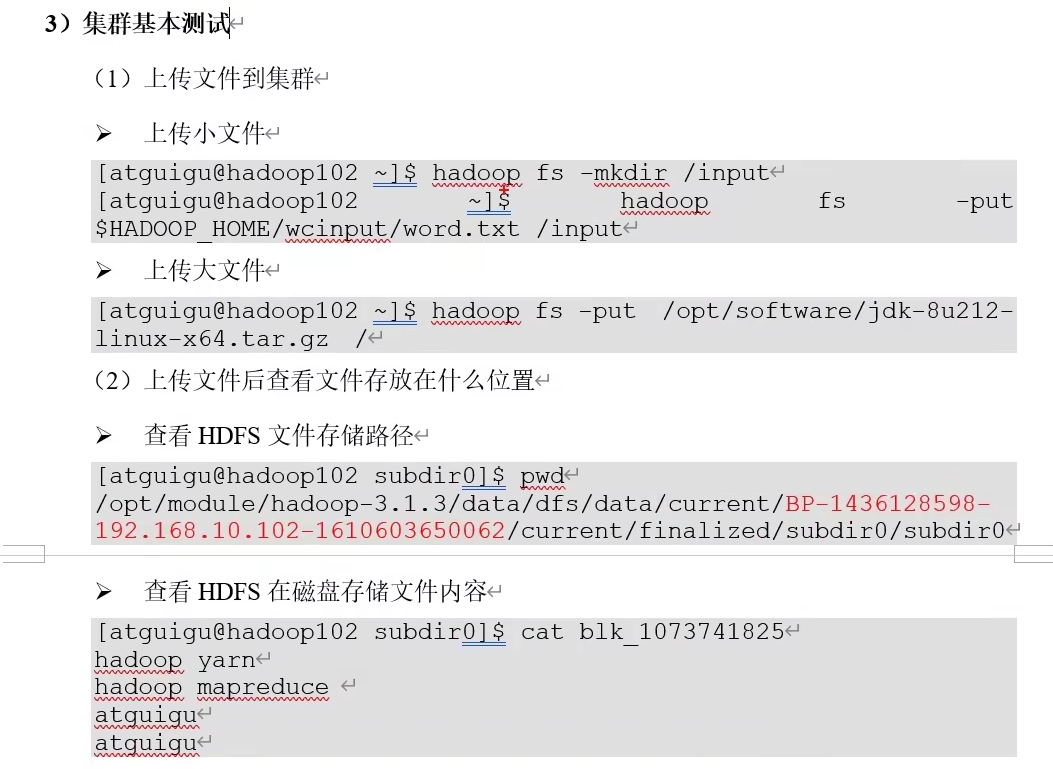
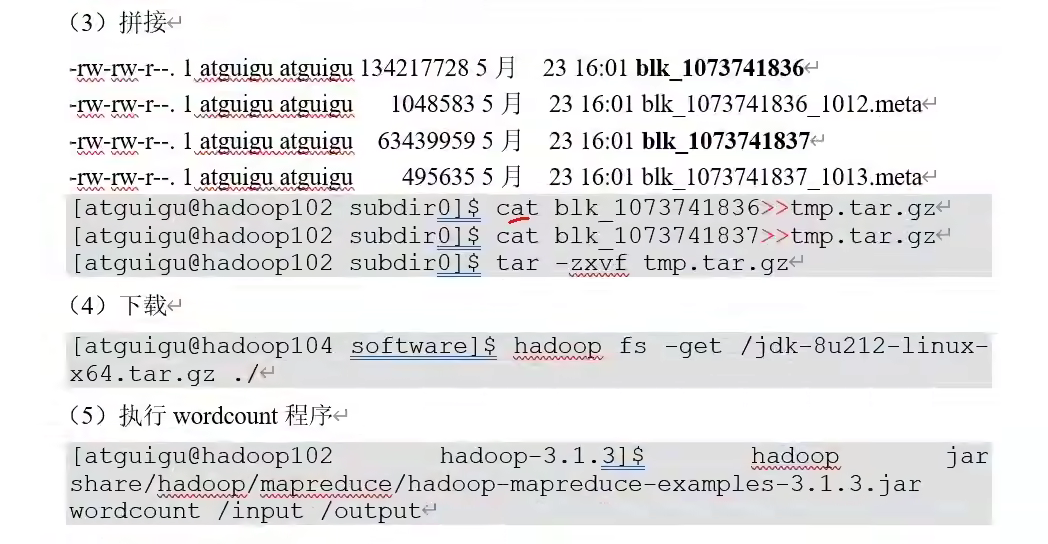


文件存储在

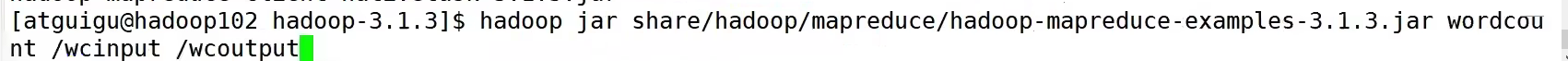
这里wcinput要是hadoop fs -mkdir创建的
P32