本文属于【Azure 架构师学习笔记】系列。
本文属于【Azure AI】系列。
接上文 【Azure 架构师学习笔记 】- Azure AI(4)-数据工程在AI系统中的设计(ADF+ADLS+Azure ML)
前言
本文开始接触一下另外一个服务:Azure 认知服务(Cognitive Services)。
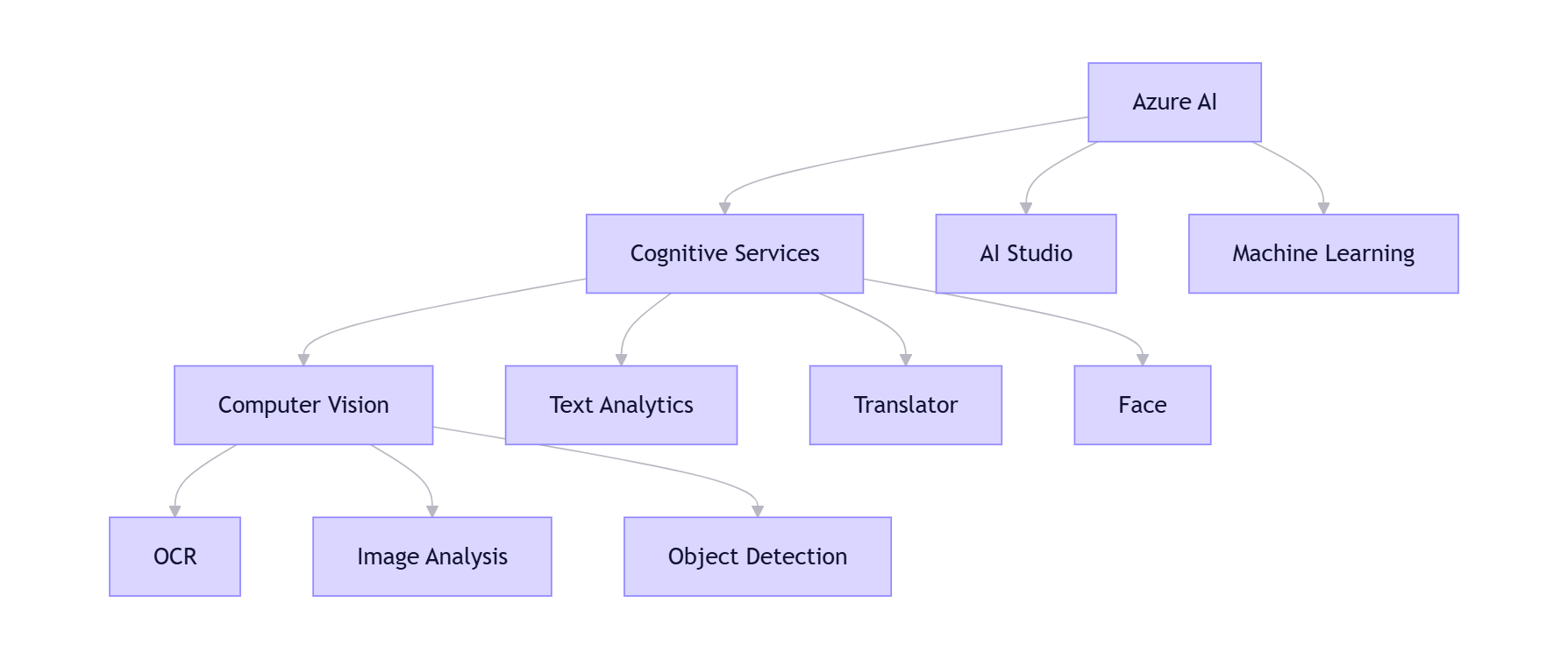
从上图可以看到
- Azure AI = Azure 的 AI 服务总称(包含认知服务+高级AI)
- 认知服务 = Azure AI 的基础服务层(预训练模型,开箱即用)
- Azure AI Vision = 认知服务中的计算机视觉子集(包含OCR、图像分析等)
Azure Computer Vision服务在2026年已经演变为一个统一的、多模态的图像分析平台。它的核心能力可以概括为以下几个层面:
- 光学字符识别:不只是提取文字
o 强大的OCR引擎:底层的读取OCR引擎构建在多个深度学习模型之上,由基于脚本的通用模型提供支持,提供了真正的全球语言支持,对印刷体和手写体都有很高的识别率 。
o 与生成式AI的集成:这是2026年的一个重大变化。OCR功能可以被集成到Azure OpenAI服务中。例如,当你使用GPT-4 Turbo with Vision模型时,可以开启"视觉增强"选项,让AI助手不仅能"看"图片,还能通过图像分析API获取图片中可读文本和物体的精确位置,从而进行更深入的分析 。 - 图像分析:让AI理解图片内容
o 这是Computer Vision更广泛的能力,包括:
图像标记:根据图片内容自动生成标签列表,例如"户外"、"沙滩"、"狗"。
目标检测:定位并框出图片中的物体,如人、车辆、产品。
图像描述:自动生成一句描述图片内容的人类可读文本。
名人/地标识别:识别图片中的知名人物和地标。
智能裁剪:为缩略图自动找到最佳的裁剪区域。 - 空间分析:处理视频流中的人、移动和互动,适用于零售、安全等场景。例如,统计顾客在货架前的停留时间,或检测社交距离。
创建 Azure Computer Vision 资源
可以参考前文terraform脚本创建的方式Azure 架构师学习笔记】 - Azure AI(1)- 概述,或者用portal创建。
- 登录 Azure 门户
- 点击 "创建资源",搜索 Computer Vision
- 选择 "Computer Vision",点击 创建
- 填写基本信息:
订阅:选择你的订阅
资源组:新建或选择已有
区域:建议选 East US 或 Southeast Asia(延迟较低)
名称:任意
定价层:免费层 F0(每月 20 次免费调用,足够学习)或标准层 S1
点击 "审阅+创建" → "创建"
获取密钥和终结点
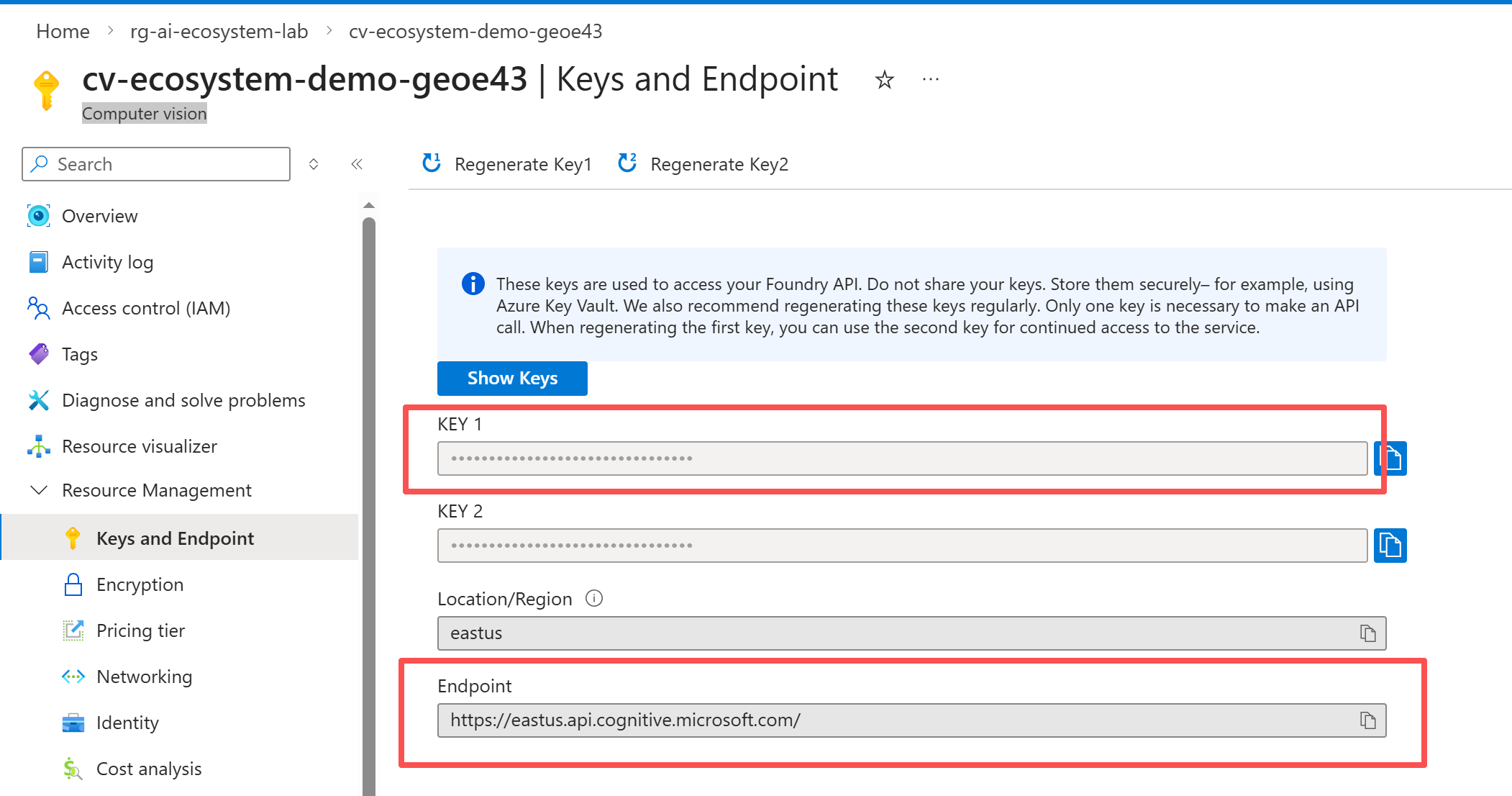
实操
接下来我们做一个极其简单的演示:
输入:本地图片文件(如 sample.jpg)
输出:从图片中提取的文本(OCR)
代码
运行时请更新必要的包,并确保KEY, Endpoint等可用。
python
pip install azure-cognitiveservices-vision-computervision msrest
python
import os
import time
from azure.cognitiveservices.vision.computervision import ComputerVisionClient
from msrest.authentication import CognitiveServicesCredentials
VISION_ENDPOINT = "你的endpoint"
VISION_KEY = "你的密码"
def ocr_local_image(image_path):
"""从本地图片提取文字"""
client = ComputerVisionClient(
endpoint=VISION_ENDPOINT,
credentials=CognitiveServicesCredentials(VISION_KEY)
)
# 1. 提交本地图片
with open(image_path, "rb") as f:
read_response = client.read_in_stream(f, raw=True)
# 2. 获取操作 ID
operation_location = read_response.headers["Operation-Location"]
operation_id = operation_location.split("/")[-1]
# 3. 轮询结果
while True:
result = client.get_read_result(operation_id)
if result.status.lower() not in ["notstarted", "running"]:
break
time.sleep(1)
# 4. 提取文字
texts = []
if result.status == "succeeded":
for page in result.analyze_result.read_results:
for line in page.lines:
texts.append(line.text)
return "\n".join(texts) if texts else "未识别到文字"
if __name__ == "__main__":
image_path = r"本地图片完整路径" # 你的本地图片
if not os.path.exists(image_path):
print(" 图片不存在")
else:
print(" 识别中...")
result = ocr_local_image(image_path)
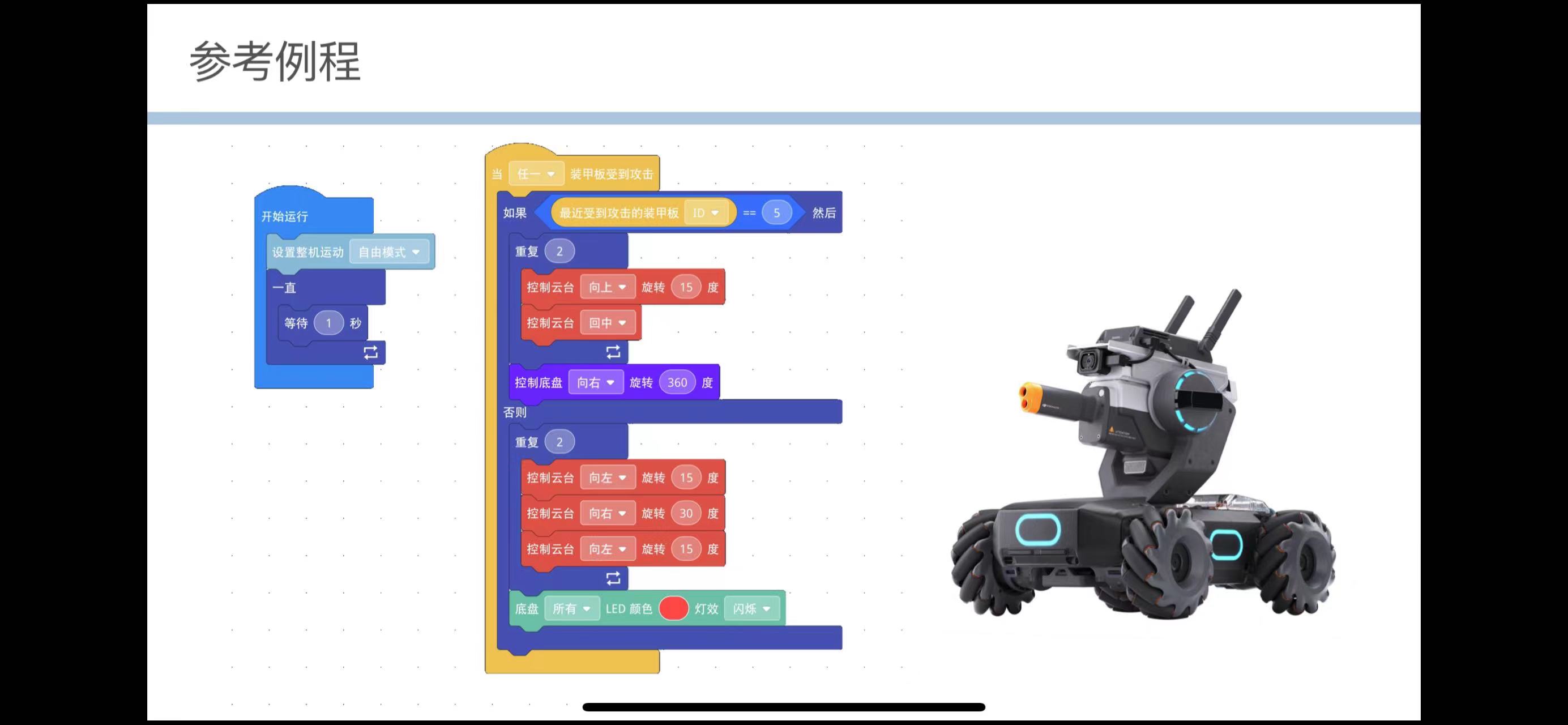
print(" 结果:\n", result)测试图片:
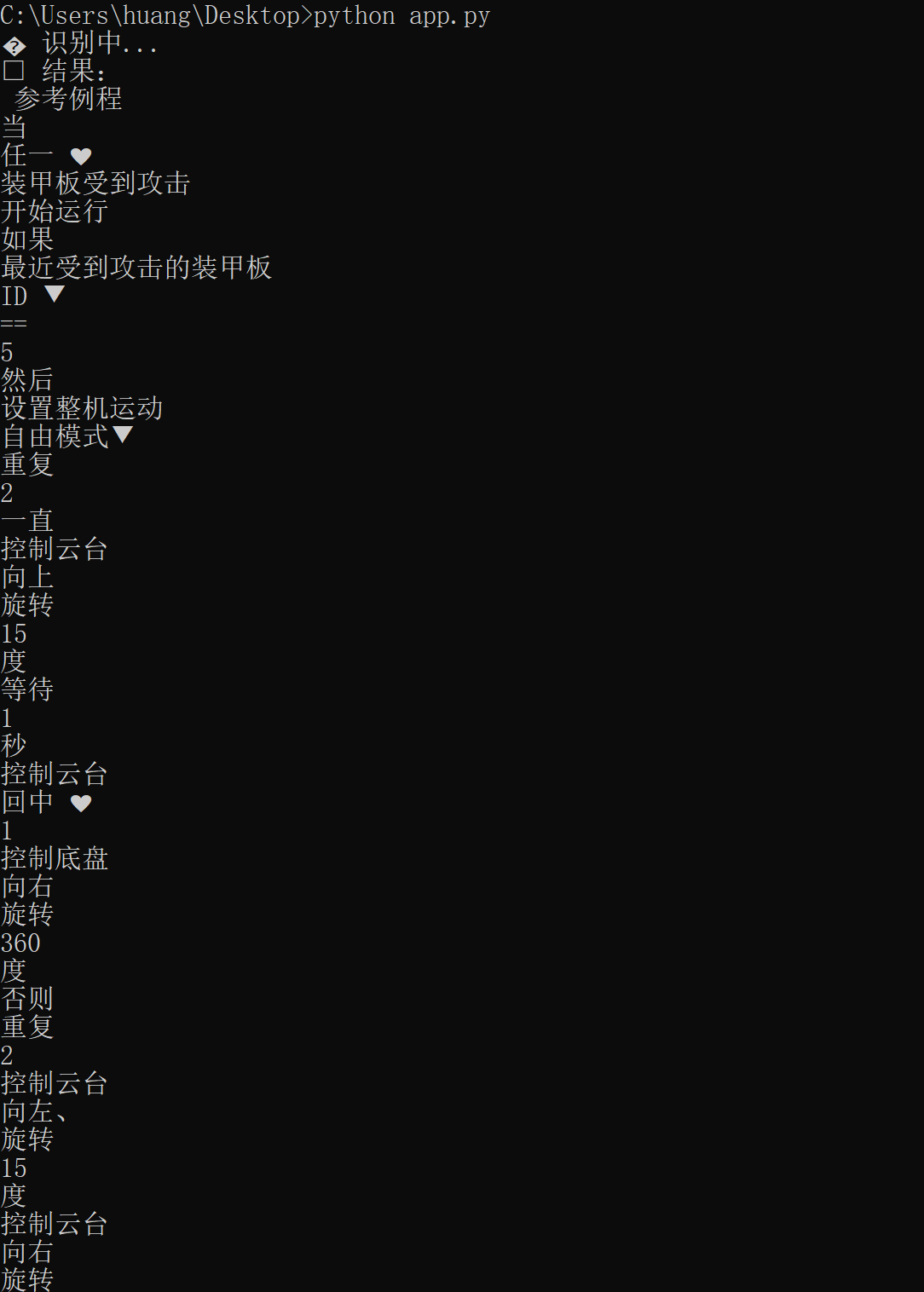
运行结果:
小结
认知服务现在叫 Azure AI 服务,创建的 Computer Vision 就是它的一部分。
你可以创建一个多服务资源,用一个密钥调用多个 AI 能力。上面的例子中,我们可以通过一个Azure AI Service来完成。
下一步计划探索 Document Intelligence(文档智能)。