Seedance2.0生成AI视频的具体技术原理是什么?
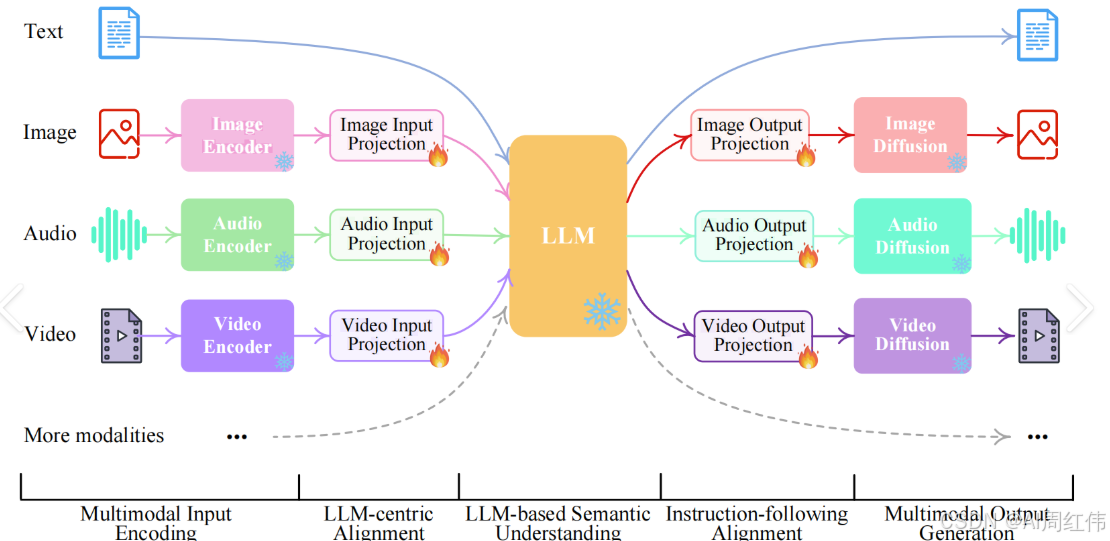
Seedance 2.0作为字节跳动即梦平台的新一代AI视频生成模型,其技术原理核心在于多模态对齐、时空扩散模型与导演级分镜控制的结合,实现了从文本、图像、音频到多镜头视频的连贯生成,将创意直接转化为工业级视听叙事内容。
自媒体的AI时刻到了

一、技术架构:多模态对齐与时空扩散模型
Seedance 2.0的底层架构基于多模态对齐技术,支持文本、图像、视频、音频四类输入的统一编码。通过跨模态特征融合模块,模型将不同素材映射到同一语义空间:
- 文本描述解析为动作、场景、运镜等结构化参数;
- 参考图像/视频提取角色特征(如服装、外貌)和运动轨迹(如舞蹈动作);
- 音频输入转换为节奏、语调特征,驱动口型与音效同步生成。
生成过程采用时空扩散模型,分两步实现高保真视频合成:
1. 空间生成:基于首帧图像或提示词生成关键帧,通过U-Net结构保证角色、环境的一致性;
2. 时序扩展:引入时间注意力机制预测帧间运动,确保物理合理性(如雨水溅射、布料摆动)。
二、分镜控制:导演级叙事逻辑的内嵌
与单镜头生成模型不同,Seedance 2.0的核心突破是内嵌多镜头叙事引擎:
- 分镜脚本解析:将用户提示词(如"0-3秒特写→4-8秒全景切换")转化为镜头序列逻辑;
- 运镜与转场优化:通过运动笔刷技术模拟专业摄影轨迹(推拉摇移、希区柯克变焦),并自动匹配转场特效;
- 角色一致性保持:利用跨帧特征绑定技术,确保同一角色在多个镜头中的外貌、动作连贯性。
案例佐证:用户仅需上传一张角色图+一段舞蹈参考视频,模型即可生成多角度运镜的连贯舞蹈片段,规避传统AI视频的"角色跳跃"问题。

三、原生音画同步:跨模态生成协同
Seedance 2.0的音频生成非后期合成,而是通过端到端音画协同训练实现:
- 语音合成:输入文本或音频参考,生成带方言/情感的对话(如四川口音点单场景);
- 音效匹配:根据画面动态生成物理音效(如打斗碰撞声、雨声);
- 节拍对齐:音频频谱与画面节奏联动,实现BGM卡点与口型精准同步。
测试显示,其生成视频的音画同步误差低于0.1秒,达到影视工业标准。
四、行业级应用与未来挑战
技术优势:
效率革新:15秒视频生成仅需30-90秒,成本降至传统制作的千分之一;

可控性跃迁:支持"@素材名"指令精确控制参考素材用途(如"1复刻运镜")。
现存局限:
长视频依赖分段生成:超过15秒需手动拼接,连贯性可能受损;
复杂逻辑偶发错误:如多角色互动时可能出现动作逻辑偏差。
行业冲击:
影视流程重构:导演可通过AI快速预演分镜,替代实拍测试;
创作平权化:普通人凭脑洞生成电影级短片,短剧、广告行业面临产能过剩。