1.Thread Cache 部分
我们基本的框架已经搭建完了,但是有一个问题现在,就是假设现在的thread cache里面归还回来了大量的内存,导致_freelist的桶里面都挂的很长很满了,这样下去我们的系统早晚崩溃,所以我们还要设计一个函数来解决这个问题:整体思路不难,这里直接放代码了
void ThreadCache::Deallocate(void* ptr, size_t size)
{
assert(ptr);
assert(size <= MAX_BYTES);
//找对映射的自由链表桶,对象插入进入
size_t index = SizeClass::Index(size);
_freeLists[index].Push(ptr);
// 当链表长度大于一次批量申请的内存时就开始还一段list给central cache
if (_freeLists[index].Size() >= _freeLists[index].MaxSize())
{
ListTooLong(_freeLists[index], size);
}
}
void ListTooLong(FreeList& list, size_t size)
{
void* start = nullptr;
void* end = nullptr;
list.PopRange(start, end, list.MaxSize()); //这个函数start指向要归还的_freelist
CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}具体看一下那个PopRange函数的实现方法:
void PopRange(void*& start, void*& end, size_t n)
{
//链表操作,自己画个图就明白了
assert(n <= _size);
start = _freelist;
end = start;
for (size_t i = 0; i < n; i++)
{
end = NextObj(end);
}
_freelist = NextObj(end);
NextObj(end) = nullptr;
_size -= n;
}这里为了方便管理,我们可以在freelist类中加上_size的私有成员,用于实时记录size大小,之后记得把所有的pop或者push都维护一下这个_size,记得维护这个后加进来的变量!!!,这里代码就先不给出了,很简单!
2.Central Cache部分
thread cache的内存回到cental cache时,我们要将其合并,但是此时返回的obj对象我们还不知道其隶属于那个span,所以要先写一个函数来实现这个功能:
Span* PageCache::MapObjectToSpan(void* obj)
{
PAGE_ID id = ((PAGE_ID)obj >> PAGE_SHIFT);
auto ret = _idSpanMap.find(id); //<PAGE_ID, Span*>
if (ret != _idSpanMap.end())
{
return ret->second;
}
else
{
//肯定能找到,找不到就是你前面哪里错了
assert(false);
return nullptr;
}
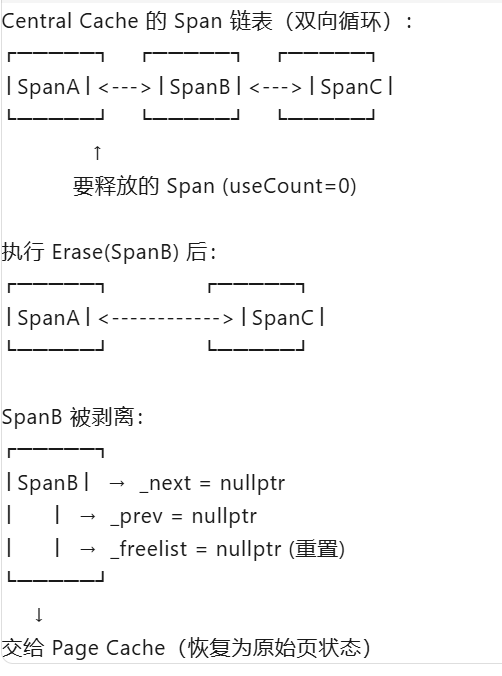
}找到这个对象后,头插法归还到 Span 的自由链表,当pagecache==0时,说明span的切分出去的所有小块内存都回来了,这个span就可以再回收给page cache,pagecache可以再尝试去做前后页的合并.
在归还前有个细节操作要注意:先将该span剥离出来, 从 Central Cache 对应 size class 的双向循环链表 中移除,清空 _freelist,
因为当 _useCount == 0 时,说明这个 Span 的所有小块内存都已经归还了 。此时:Span 即将被移交给 Page Cache ,Page Cache 管理的是整页的、未切分的大块内存, 不需要再维护小块的自由链表了,实际上,这个 Span 的所有内存块(包括刚归还的)都还在 Span 管理的物理内存范围内。清空 _freelist 只是重置管理结构 ,内存本身并没有丢失。随后将 Span 从 Central Cache 的链表中彻底剥离 ,变成孤立节点,前后变为空:

示意图:
之后归还的时候记得切换锁~
代码如下:
void CentralCache::ReleaseListToSpans(void* start, size_t size)
{
size_t index = SizeClass::Index(size);
_spanLists[index]._mtx.lock();
while (start)
{
void* next = NextObj(start);
Span* span = PageCache::GetInstance()->MapObjectToSpan(start);
//头插法归还到 Span 的自由链表
NextObj(start) = span->_freelist;
span->_freelist = start;
span->_useCount--;
// 说明span的切分出去的所有小块内存都回来了
// 这个span就可以再回收给page cache,pagecache可以再尝试去做前后页的合并
if (span->_useCount == 0)
{
_spanLists[index].Erase(span);
span->_freelist = nullptr;
span->_next = nullptr;
span->_Prev = nullptr;
// 释放span给page cache时,使用page cache的锁就可以了
// 这时把桶锁解掉
_spanLists[index]._mtx.unlock();
PageCache::GetInstance()->_pageMX.lock();
PageCache::GetInstance()->ReleaseSpanToPageCache(span);
PageCache::GetInstance()->_pageMX.unlock();
_spanLists[index]._mtx.lock();
}
start = next;
}
_spanLists[index]._mtx.unlock();
}3.Span Cache部分
当陆陆续续的一块一块的span都回来时,我们需要将其进行合并,未合并之前的span可能会存在内碎片和外碎片,内碎片倒是无所谓,大不了就是暂时回不来,等用它的线程结束了他就回来了就能进行分配了,但是外碎片却很棘手,因为这会导致一个问题产生,就是假设你想申请8byte的空间,系统显示也有8byte,但是就是开不出来因为不连续,成外碎片了,因此我们要间相邻的外碎片以及与空闲的大块span合并到一起!
代码思路就是:
采用双向边界合并策略回收内存页:首先向前遍历合并相邻空闲页,再向后遍历合并,通过页号哈希表快速定位邻接块,最终将合并后的连续大内存块按页数分类插入链表,并更新边界映射,代码比较简单而且写了详细的注释,这里不多说了~
代码如下:
void PageCache::ReleaseSpanToPageCache(Span* span)
{
// 对span前后的页,尝试进行合并,缓解内存碎片问题(主要是外碎片的问题)
//向前合并
while (1)
{
PAGE_ID prevId = span->_pageId - 1;
auto ret = _idSpanMap.find(prevId);
if (ret == _idSpanMap.end())
{
//没找到,前面页号没有,不合并了
break;
}
// 前面相邻页的span在使用,不合并了
Span* prevSpan = ret->second;
if (prevSpan->_IsUse == true)//正在使用
{
break;
}
// 合并出超过128页的span没办法管理,不合并了
if (prevSpan->_n + span->_n > NPAGES - 1)
{
break;
}
//下面就可以合并了
span->_pageId = prevSpan->_pageId;
span->_n += prevSpan->_n;
//记得将原来的prevspan删掉,已经合并了
_spanList[prevSpan->_n].Erase(prevSpan);
delete prevSpan;
}
//向后合并
while (1)
{
PAGE_ID nextId = span->_pageId + span->_n;
//这里区分前后,前只需-1即可获取前面的prevId,后则需要跨过本段span的页数,
//pageid可以理解为这一大块的id都是_pageid,而_n是页数
auto ret = _idSpanMap.find(nextId);
if (ret == _idSpanMap.end())
{
break;
}
//找到了
Span* nextspan = ret->second;
if (nextspan->_IsUse == true)
break;
if (nextspan->_n + span->_n > NPAGES - 1)
break;
//此时可以合并了
span->_n += nextspan->_n;
_spanList[nextspan->_n].Erase(nextspan);
delete nextspan;
}
//此时前后页合并完成了,进行整理
_spanList[span->_n].PushFront(span);
span->_IsUse = false;
_idSpanMap[span->_pageId] = span; //// 起始页映射
_idSpanMap[span->_pageId+span->_n - 1] = span;// 结束页映射
}4.细节修订,开辟size大小
如果我们一次性开辟小于256k,则直接走这三个cache就行,那要是大于呢?我们要对这种情况进行代码编写和处理:
注:这里的new 和delete先看上面的被注释掉的版本,下面的那个一会会说为什么这么改!!
第一处要改造的地方是获取k页span那里:
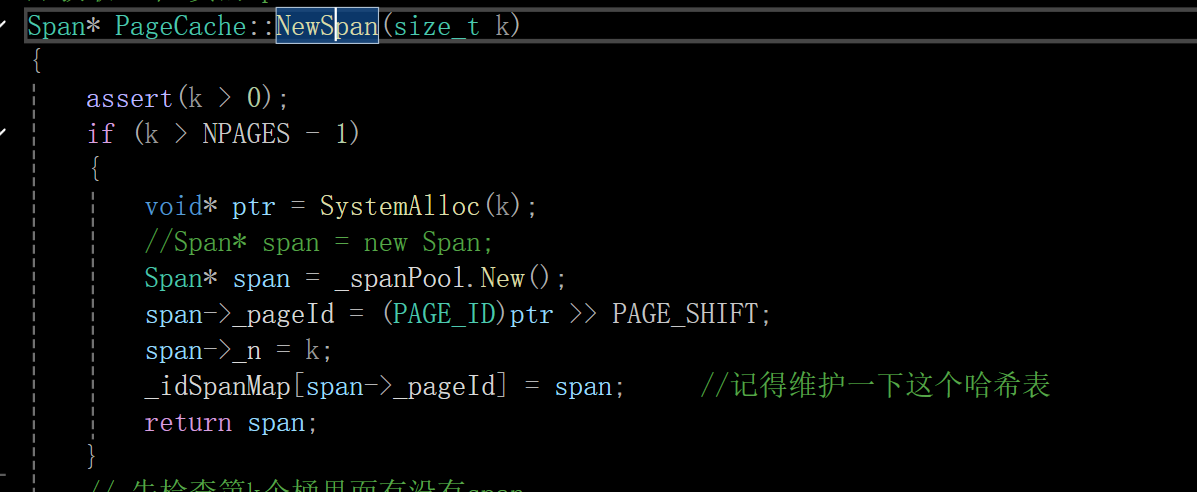
就是当k大于最大页数129-1=128时,要处理一下
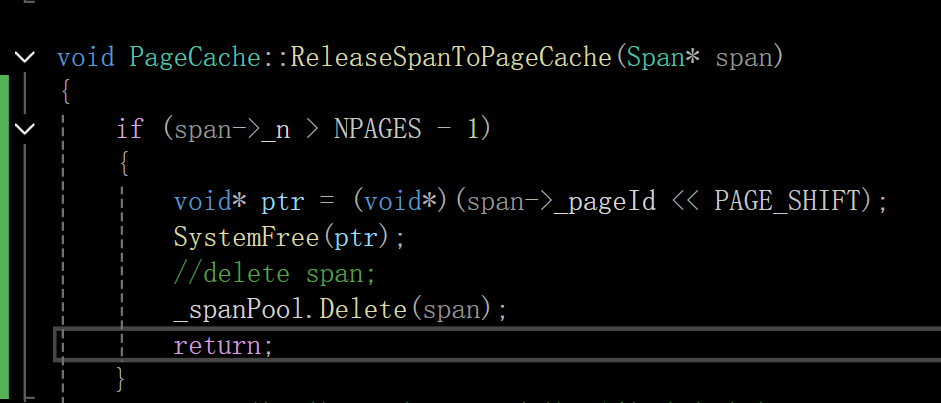
释放那里也要对这个进行改一下:
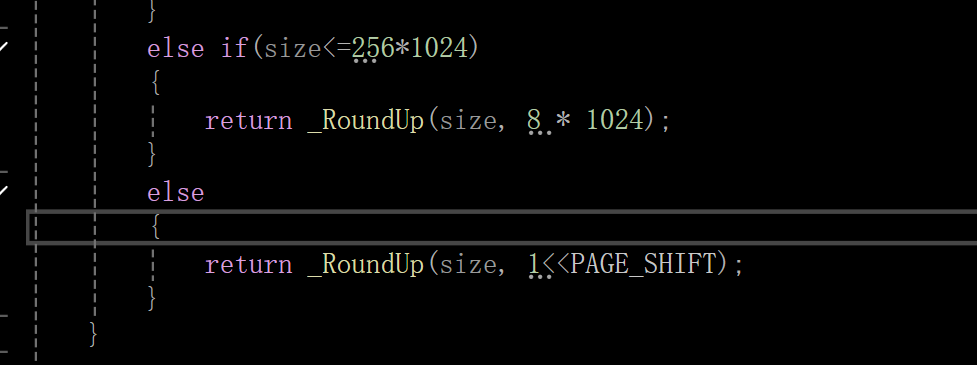
之后分配函数roundUP函数那里也要搞一下,加上这个情况:
之后再并行测试那里也加一下:
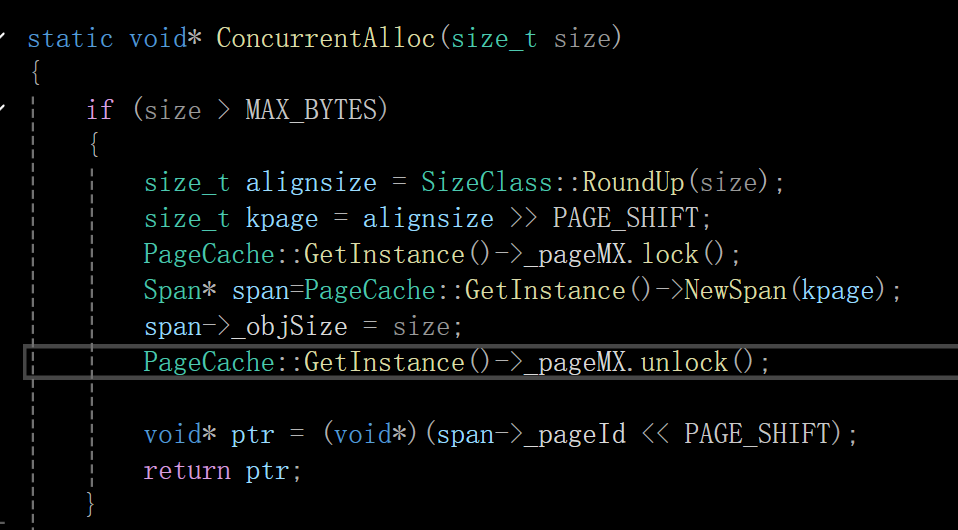
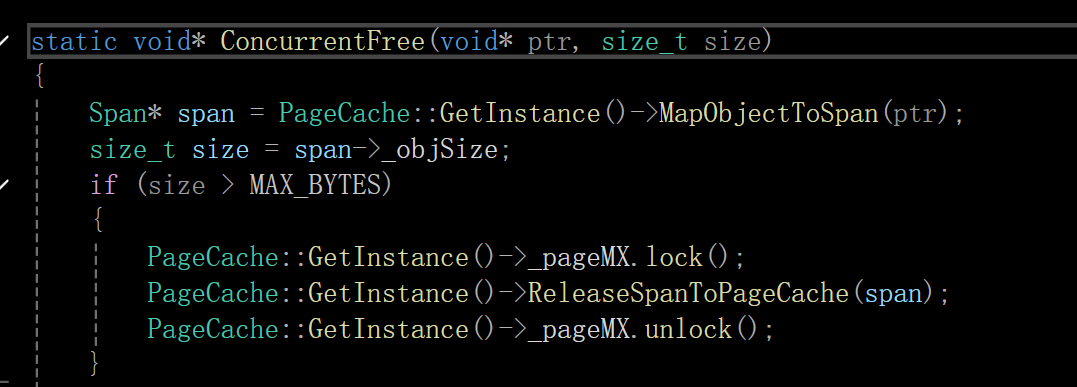
5.摆脱new 和 delete的依赖
我们这个内存池还有一些问题,就是这个是仿照tcmalloc来设计的,而tcmalloc设计的初衷就是要彻底摆脱对底层 malloc 的依赖,实现自包含的高性能内存管理 。因此TCMalloc 要替代 malloc,内部不能调用 malloc, 否则就会造成左右脑互博的局面,就像现在部分xxn一样,既要独立又要自由,这是不可取的!!!
但是我们的项目里用的都是new 和 delete 啊,所以要进行整改,正好我们前面写过定长内存池的代码,我们可以通过引入定长内存池,在我new span或者delete span的时候进行改造,这样就能避免对malloc的依赖,因为定长内存池的内存我们是直接用systemalloc直接从系统要的!
这里回顾一下定长内存池的New函数和Delete函数
NEW:
T* New()
{
//先定义obj对象
T* obj = nullptr;
//申请内存,先从freelist上面申请,不够了再去开大块空间
if (_freelist)
{
//有还回来的空间,且空间足够所需,
//"头删"一块内存给obj对象
void* next = *(void**)_freelist;
obj = (T*)_freelist;
_freelist = next;
}
else
{
// 剩余内存不够一个对象大小时,则重新开大块空间
if (_remainbytes < sizeof(T))
{
_remainbytes = 128*1024;//向大内存申请空间
//_memory = (char*)malloc(_remainbytes);
_memory = (char*)SystemAlloc(_remainBytes >> 13);
if (_memory == nullptr)//检测申请成功与否
{
throw std::bad_alloc();
}
}
//内存现在申请成功了,准备给Obj对象分配
obj = (T*)_memory;
size_t ObjSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);
//解释objsize:
// 空间返回给用户,是给用户使用。用户给我们,我们是用这块空间的前4个或者8个字节,然后指向后面的一个节点空间
//那如果T是char 这块空间就会不够用了,所以一定要有这个大小,然后才可以实现我们的这个思想。
_memory += ObjSize;
_remainbytes -= ObjSize;
}
// 定位new,显示调用T的构造函数初始化
new(obj)T;
return obj;
}Delete:
void Delete(T* obj)
{
// 显示调用析构函数清理对象
// 1. 显式调用析构函数(清理对象内部资源)
// 2. 内存不释放,而是归还到内存池的自由链表
obj->~T();
//归还的内存以头插的方式由freelist管理
//头插
*(void**)obj = _freelist;
_freelist = obj;
}我们在span cache这里引入定长内存池,之后把所有的new都换成通过_spanpool来调用自己的New函数,delete同理
如下图:

