在Java集合框架中,Collection和Map是两大核心接口,它们并列存在而非继承关系 。许多开发者混淆两者,导致在实际开发中选择错误的集合类型。本文将从JDK 1.8+源码底层深度剖析Collection和Map接口的所有实现类,揭示其算法逻辑,并总结最佳实践与避坑指南。所有内容均基于官方源码,确保技术准确性。
一、Java集合框架核心关系图
Collection和Map是Java集合框架的两个独立顶层接口,它们没有继承关系,而是并列存在。以下是完整的继承关系图: Collection:
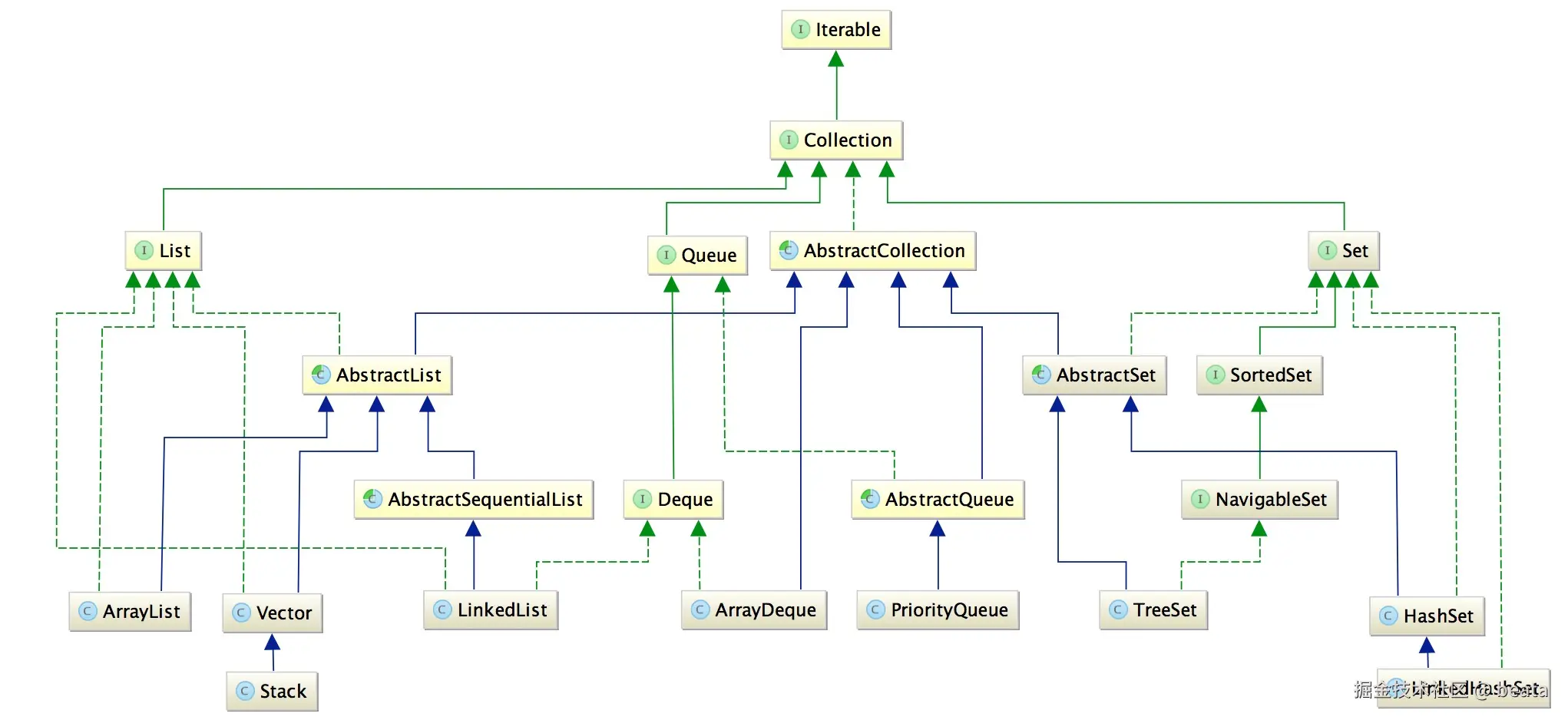
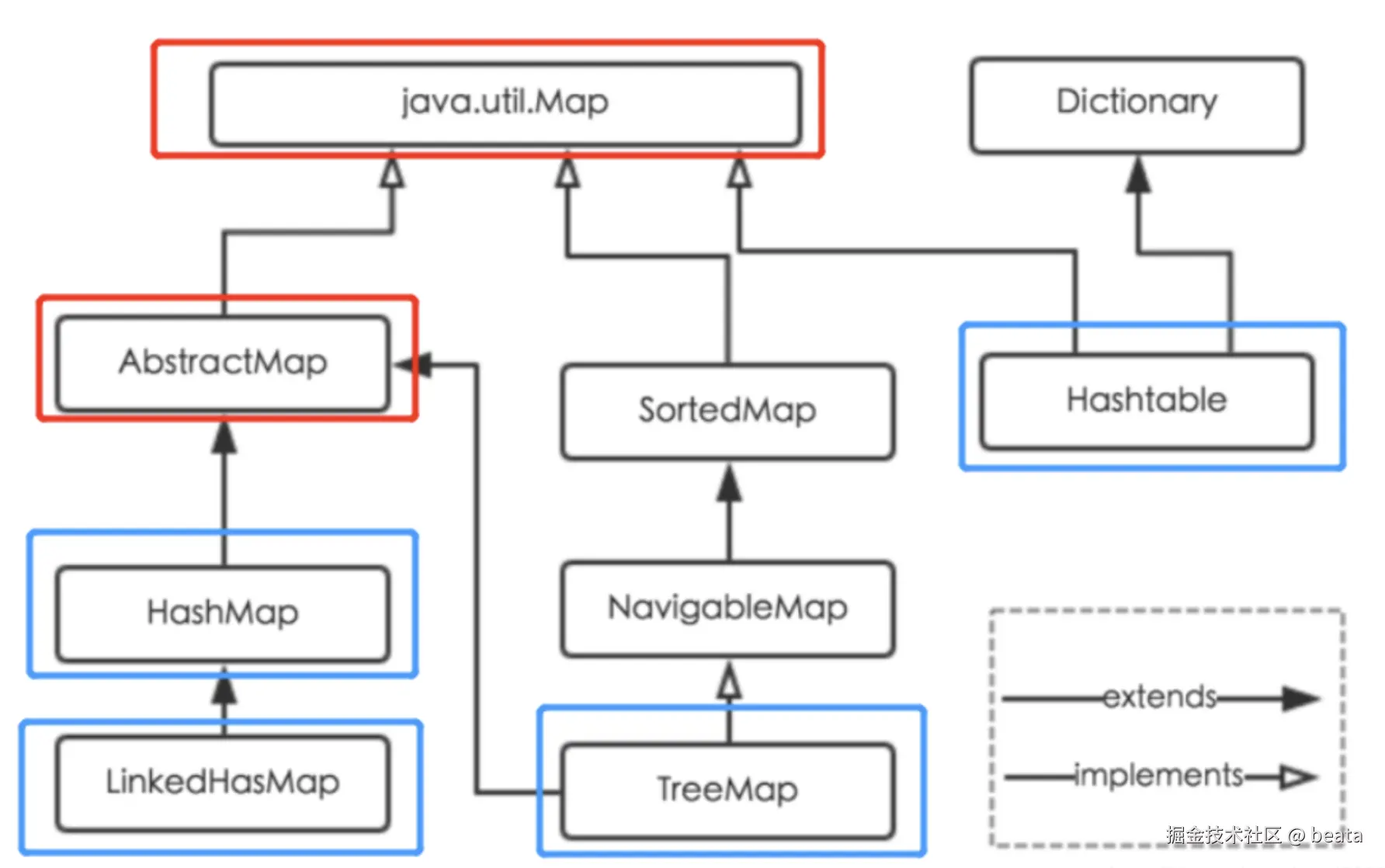
关键区分:
Collection:存储单个元素的集合(如列表、集合、队列)。Map:存储键值对的映射表(如字典、关联数组)。- 重要结论 :
Map不继承Collection,两者是Java集合框架的双分支。
二、Collection接口实现类底层详解
1. ArrayList:基于数组的动态集合
核心结构 :transient Object[] elementData;(默认容量10)
java
public class ArrayList<E> extends AbstractList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
private transient Object[] elementData;
private int size;
public boolean add(E e) {
ensureCapacityInternal(size + 1);
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacity) {
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // 扩容1.5倍
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
}算法逻辑:
- 扩容 :默认容量10,扩容时
newCapacity = oldCapacity * 1.5 - 时间复杂度 :
add(E e):均摊 O(1)(扩容时O(n))get(int index):O(1)(数组随机访问)remove(int index):O(n)(需移动后续元素)
- 适用场景 :随机访问频繁(如遍历、按索引查询)
2. LinkedList:基于双向链表的集合
核心结构 :private static class Node<E> { E item; Node<E> next; Node<E> prev; }
java
public class LinkedList<E> extends AbstractSequentialList<E> implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
public boolean add(E e) {
linkLast(e);
return true;
}
private void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
}
}算法逻辑:
- 链表操作 :每个节点包含
prev和next指针 - 时间复杂度 :
add(E e):O(1)(尾部添加)get(int index):O(n)(需遍历)remove(int index):O(n)(需定位节点)
- 适用场景 :频繁插入/删除(尤其是头部/尾部)
3. HashSet:基于 HashMap 的无序集合
核心结构 :private transient HashMap<E,Object> map;(key 为集合元素,value 为 PRESENT)
java
public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cloneable, java.io.Serializable {
private transient HashMap<E,Object> map;
private static final Object PRESENT = new Object();
public HashSet() {
map = new HashMap<>();
}
public boolean add(E e) {
return map.put(e, PRESENT) == null; // 实际调用HashMap的put
}
}算法逻辑:
- 哈希冲突处理 :使用
HashMap的链表+红黑树(JDK 8+) - 时间复杂度 :
add(E e):均摊 O(1)contains(E e):均摊 O(1)
- 关键点 :元素必须正确重写
hashCode()和equals() - 适用场景 :去重、快速查找
4. LinkedHashSet:基于 LinkedHashMap 的有序集合
核心结构 :private transient LinkedHashMap<E,Object> map;(继承自 HashSet)
java
public class LinkedHashSet<E> extends HashSet<E> {
public LinkedHashSet() {
super(16, 0.75f, true); // accessOrder=true
}
}算法逻辑:
- 有序性 :通过
LinkedHashMap的accessOrder(访问顺序)或insertOrder(插入顺序) - 时间复杂度 :与
HashSet相同(均摊 O(1)) - 适用场景 :插入顺序或访问顺序的去重集合(如LRU缓存)
5. TreeSet:基于 TreeMap 的有序集合
核心结构 :private transient TreeMap<E,Object> m;(key 为集合元素,value 为 PRESENT)
java
public class TreeSet<E> extends AbstractSet<E> implements NavigableSet<E>, Cloneable, java.io.Serializable {
private transient NavigableMap<E,Object> m;
public TreeSet() {
m = new TreeMap<>();
}
public boolean add(E e) {
return m.put(e, PRESENT) == null; // 实际调用TreeMap的put
}
}算法逻辑:
- 红黑树实现 :元素需实现
Comparable或提供Comparator - 时间复杂度 :
add(E e):O(log n)contains(E e):O(log n)
- 适用场景 :排序、范围查询 (如
headSet(),subSet())
6. PriorityQueue:基于堆的优先队列
核心结构 :transient Object[] queue;(数组实现的二叉堆)
java
public class PriorityQueue<E> extends AbstractQueue<E> implements java.io.Serializable {
private transient Object[] queue;
private int size;
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
siftUp(i, e); // 堆调整(上浮)
return true;
}
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = queue[parent];
if (comparator.compare(x, (E)e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
}算法逻辑:
- 最小堆 :默认最小优先级(
comparator可自定义) - 时间复杂度 :
offer(E e):O(log n)poll():O(log n)
- 适用场景 :任务调度、Top-K问题
7. ArrayDeque:基于循环数组的双端队列
核心结构 :transient Object[] elements;(数组+头尾指针)
java
public class ArrayDeque<E> extends AbstractCollection<E> implements Deque<E>, java.io.Serializable {
transient Object[] elements;
private int head;
private int tail;
public boolean add(E e) {
if (e == null)
throw new NullPointerException();
elements[tail] = e;
if (tail == elements.length - 1)
tail = 0;
else
tail++;
if (head == tail)
doubleCapacity();
return true;
}
}算法逻辑:
- 循环数组 :
head和tail指针维护队列 - 扩容 :容量翻倍(
newCapacity = oldCapacity * 2) - 时间复杂度 :
addFirst(E e):O(1)addLast(E e):O(1)
- 适用场景 :高性能双端队列(如实现栈、队列)
8. Vector 和 Stack:过时实现(避免使用!)
Vector:线程安全(synchronized方法),扩容为2倍(oldCapacity * 2)Stack:继承Vector,过时(建议用ArrayDeque代替)
避坑提示 :在JDK 1.2后,
Vector和Stack已被标记为过时。现代Java应使用Collections.synchronizedList()或ConcurrentLinkedQueue。
三、Map接口实现类底层详解
1. HashMap:基于哈希表的无序映射
核心结构 :transient Node<K,V>[] table;(数组+链表/红黑树)
java
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
// ...
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // 8
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}算法逻辑:
- 哈希计算 :
hash = key.hashCode() ^ (key.hashCode() >>> 16) - 冲突处理:链表(<8个节点) + 红黑树(≥8个节点)
- 扩容 :容量翻倍(
newCapacity = oldCapacity * 2) - 时间复杂度 :
put(K key, V value):均摊 O(1)(链表)/ O(log n)(红黑树)get(K key):均摊 O(1)
- 关键点 :键必须重写
hashCode()和equals()
2. LinkedHashMap:基于 HashMap 的有序映射
核心结构 :transient Entry<K,V> head;(双向链表维护顺序)
java
public class LinkedHashMap<K,V> extends HashMap<K,V> {
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false; // 插入顺序
}
@Override
void afterNodeAccess(Node<K,V> e) {
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b != null)
b.after = a;
else
head = a;
if (a != null)
a.before = b;
else
last = b;
if (last != null)
last.after = p;
p.before = last;
p.after = null;
tail = p;
++modCount;
}
}
}算法逻辑:
- 有序性 :通过
before/after指针维护插入顺序(accessOrder=false)或访问顺序(accessOrder=true) - 时间复杂度 :与
HashMap相同(均摊 O(1)) - 适用场景 :LRU缓存 (设置
accessOrder=true)
3. TreeMap:基于红黑树的有序映射
核心结构 :private transient Entry<K,V> root;(红黑树节点)
java
public class TreeMap<K,V> extends AbstractMap<K,V> implements NavigableMap<K,V>, Cloneable, java.io.Serializable {
static final class Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
// ...
}
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
do {
parent = t;
cmp = compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}算法逻辑:
- 红黑树 :自动平衡,保证
O(log n)操作 - 排序 :元素需实现
Comparable或提供Comparator - 时间复杂度 :
put(K key, V value):O(log n)get(K key):O(log n)
- 适用场景 :排序键值对、范围查询(如时间区间统计)
4. Hashtable:线程安全的哈希映射(已过时)
核心结构 :transient Entry<K,V>[] table;(与 HashMap 类似,但加锁)
java
public class Hashtable<K,V> extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable {
private transient Entry<K,V>[] table;
public synchronized V put(K key, V value) {
if (value == null)
throw new NullPointerException();
Entry<K,V> entry = getEntry(key);
if (entry != null) {
V oldValue = entry.value;
entry.value = value;
return oldValue;
} else {
addEntry(hash(key), key, value, table.length);
return null;
}
}
private void addEntry(int hash, K key, V value, int index) {
Entry<K,V> e = table[index];
table[index] = new Entry<>(hash, key, value, e);
if (++count >= threshold)
resize(2 * table.length);
}
}算法逻辑:
- 线程安全 :所有方法用
synchronized修饰(锁粒度粗,性能差) - 扩容 :容量翻倍(
newCapacity = oldCapacity * 2) - 时间复杂度 :与
HashMap相同(O(1)),但性能低10倍+ - 避坑 :已过时 ,现代Java应使用
ConcurrentHashMap
四、Collection vs Map 核心对比
| 特性 | Collection 接口 | Map 接口 |
|---|---|---|
| 数据结构 | 单元素集合(List/Set/Queue) | 键值对映射(Key-Value) |
| 核心方法 | add(E e), remove(E e), size() |
put(K key, V value), get(K key) |
| 是否允许重复 | List:允许;Set:不允许 | Key:不允许;Value:允许 |
| 底层实现 | 数组/链表/红黑树 | 哈希表/红黑树 |
| 典型场景 | 存储列表、集合、队列 | 存储配置、缓存、关联数据 |
| 线程安全 | Collections.synchronizedList() |
ConcurrentHashMap(非 Hashtable) |
| 遍历方式 | iterator(), forEach() |
keySet(), entrySet(), values() |
| 关键设计原则 | 元素操作 | 键值对操作 |
关键差异:
Collection操作元素 (如list.remove("a")),Map操作键值对 (如map.remove("key"))。
五、最佳实践与避坑指南
✅ 最佳实践(按场景推荐)
| 操作场景 | 推荐集合 | 原因 |
|---|---|---|
| 单元素集合 | ArrayList |
随机访问 O(1),缓存友好 |
| 频繁头尾插入/删除 | LinkedList |
O(1) 头尾操作 |
| 自动去重 + 快速查找 | HashSet |
均摊 O(1) 查找 |
| 保留插入顺序的去重 | LinkedHashSet |
插入顺序,性能略低于 HashSet |
| 排序 + 范围查询 | TreeSet |
O(log n) 操作,自动排序 |
| 优先级任务调度 | PriorityQueue |
O(log n) 插入/删除 |
| 高性能双端队列 | ArrayDeque |
比 LinkedList 更快(无指针开销) |
| 键值对快速查找 | HashMap |
均摊 O(1) 查找,无序 |
| 保留插入顺序的键值对 | LinkedHashMap |
LRU缓存实现(accessOrder=true) |
| 排序键值对 | TreeMap |
O(log n) 操作,自动按键排序 |
| 线程安全的键值对 | ConcurrentHashMap |
高性能并发(Hashtable 已过时) |
⚠️ 避坑指南(高频错误)
Collection 避坑点
-
Vector用于多线程- ❌ 错误:
Vector的synchronized锁粒度粗,性能极低。 - ✅ 正确:
Map<String, String> map = new ConcurrentHashMap<>();或ConcurrentLinkedQueue
- ❌ 错误:
-
循环中直接
remove()-
❌ 错误:
for (E e : list) list.remove(e)→ConcurrentModificationException。 -
✅ 正确:用
Iterator遍历:javaIterator<E> it = list.iterator(); while (it.hasNext()) { if (condition) it.remove(); }
-
Map 避坑点
-
HashMap键未重写hashCode()/equals()- ❌ 错误:
new Person("A")和new Person("A")被视为不同键。 - ✅ 正确:确保自定义类重写
hashCode()和equals()(推荐Lombok@EqualsAndHashCode)。
- ❌ 错误:
-
误用
Hashtable代替ConcurrentHashMap- ❌ 错误:
Hashtable的synchronized导致性能低下。 - ✅ 正确:
Map<String, String> map = new ConcurrentHashMap<>();
- ❌ 错误:
-
迭代时修改 Map
-
❌ 错误:
for (Map.Entry<String, String> e : map.entrySet()) map.remove(e.getKey()); -
✅ 正确:用
Iterator或removeIf():javamap.entrySet().removeIf(e -> e.getKey().equals("target"));
-
-
TreeMap未实现Comparable- ❌ 错误:
TreeMap<CustomObject, String>→ClassCastException。 - ✅ 正确:提供
Comparator或让类实现Comparable。
- ❌ 错误:
-
忽略
HashMap的扩容- ❌ 错误:默认容量16,频繁添加触发扩容(影响性能)。
- ✅ 正确:初始化时指定容量:
new HashMap<>(1024)。
六、总结
关键原则
-
Collection vs Map:
Collection处理元素 (如List),Map处理键值对 (如HashMap)。- Map 不继承 Collection,这是Java集合框架的基石设计。
-
选择集合的黄金法则:
- 需要元素操作 → 选
Collection实现类。 - 需要键值关联 → 选
Map实现类。 - 线程安全 :用
ConcurrentHashMap代替Hashtable。
- 需要元素操作 → 选
-
性能与正确性:
HashMap/HashSet:必须重写hashCode()和equals()。TreeMap/TreeSet:必须保证键的排序 (Comparable或Comparator)。ConcurrentHashMap:避免在迭代时修改 (用computeIfPresent等方法)。
终极避坑口诀 :
"Collection 单元素,Map 键值对;
HashMap 重 hashCode,
TreeMap 重 Comparable;
Hashtable 已过时,
ConcurrentHashMap 是主力。"
参考资料
- JDK 1.8 源码
- 《Effective Java》第3版:Item 30-33(集合相关)
- Java集合框架官方文档:Java Collections Framework
- Java并发包文档:ConcurrentHashMap
作者 :架构师Beata
日期 :2026年2月13日 声明 :本文基于网络文档整理,如有疏漏,欢迎指正。转载请注明出处。
互动:如有任何问题?欢迎在评论区分享!