HarmonyOS实战(解决方案篇)---企业AI资产利旧:如何将已有智能体快速接入鸿蒙生态
-
- 中小型企业的AI家底,怎么"接"进鸿蒙才划算?
- 一、怎么为数据牵线搭桥?关键看懂鸿蒙的"Agent通信协议"
-
- [1.1 基本通信模式](#1.1 基本通信模式)
- 1.2关键业务流程与时序
- [3. 定义的RPC方法(操作原语)](#3. 定义的RPC方法(操作原语))
- 二、实战案例:如何使用coze智能体对接鸿蒙
-
- [2.1. Coze事件与鸿蒙事件的对应关系](#2.1. Coze事件与鸿蒙事件的对应关系)
- [2.2 具体转换示例](#2.2 具体转换示例)
- [2.3 完整数据流转换示意图](#2.3 完整数据流转换示意图)
- [2.4 关键适配挑战与解决方案](#2.4 关键适配挑战与解决方案)
- [2.5 实际代码结构建议](#2.5 实际代码结构建议)
- 三、这么干,到底划不划算?算笔实在账
- 总结
中小型企业的AI家底,怎么"接"进鸿蒙才划算?

熟悉我的小伙伴应该知道,我们团队这两年搞了不少"数字资产"------说白了,就是一些还挺有用的AI程序。有能跟医生搭话帮忙问诊的"数字人",有能管一堆智能设备的"智慧云脑",还有能看懂病例的"AI分析员"。这些东西用起来效果不错,客户也挺买账,都是技术兄弟们熬了不少夜、公司花了不少钱攒出来的。
最近圈子里都在聊OpenClaw,说它现在大强大了。最近鸿蒙的小艺开放平台也支持了OpenClaw的接入。我马上也动心了,觉得这是个实操的好机会。
作为团队的负责人,在使用小艺开放平台的过程中,我发现了一个尖锐的问题。
在团队视角,难道要为了上鸿蒙,把这些现成的AI智能体重做一遍,走小艺的智能体上架? 再买新平台的token?再雇一队人重新开发?这成本账根本算不过来。我们这帮搞技术的也头大,活已经够多了,实在没精力再从头搞一套。
硬着头皮上肯定不行。经过思考和技术预研,我们的办法是,在现有的AI智能体和鸿蒙之间,搭一座"协议转换层" 。不用动我们原来的智能体结构,也不需要再GUI把工作流重新配置一遍。
只负责磨平协议层的差距,以中间件的形式就可以实现原有平台的利旧,比如云端的coze或者私有化部署的dify。
一、怎么为数据牵线搭桥?关键看懂鸿蒙的"Agent通信协议"
这份文档是鸿蒙操作系统(HarmonyOS)为第三方AI智能体(Agent)开发者提供的一套通信协议技术规范。它的核心目标是定义一套标准化的通信机制,让第三方开发的AI智能体能够无缝接入鸿蒙生态(特别是通过"小艺"这个核心智能助手),实现高效、安全、功能丰富的交互。
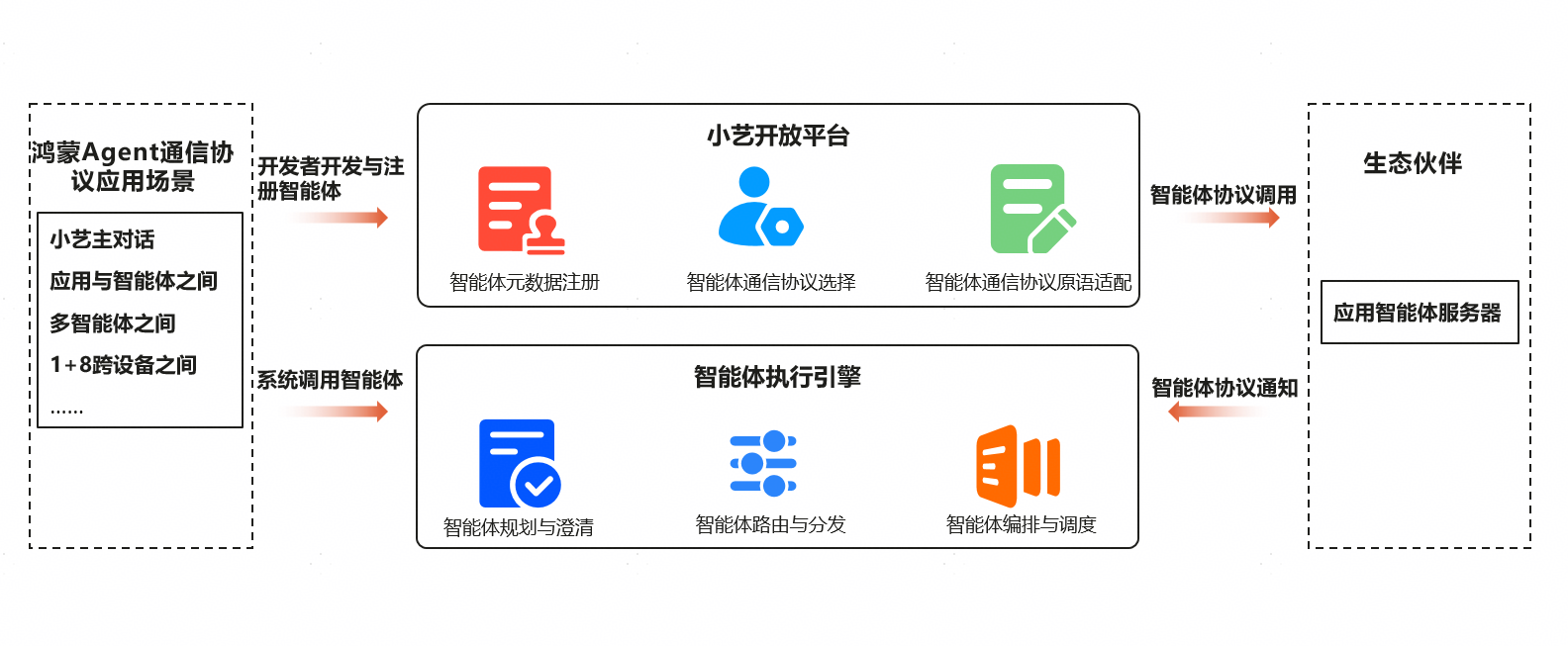
1.1 基本通信模式
- 协议基础 :采用 StreamableHTTP + JSON RPC 协议。这意味着通信基于HTTP/HTTPS,使用JSON格式传输数据,并且支持流式传输(Server-Sent Events, SSE)。
- 交互方式 :所有接口调用都通过同一个 Endpoint ,只使用 POST 方法。这种方式简化了服务器实现,无需维护长连接,并支持断线重连。
- 状态管理 :提供了两种方案:
- 推荐方案(基于Session) :服务器为每个对话会话分配一个唯一的
agent-session-id,客户端后续请求都携带此ID,便于服务器维护对话上下文。这类似于MCP协议的设计。 - 简化方案(无状态):每次请求都携带完整的认证凭证(如API Key),服务器无需管理会话状态。
- 推荐方案(基于Session) :服务器为每个对话会话分配一个唯一的
1.2关键业务流程与时序
文档用时序图清晰地展示了几个核心交互场景:
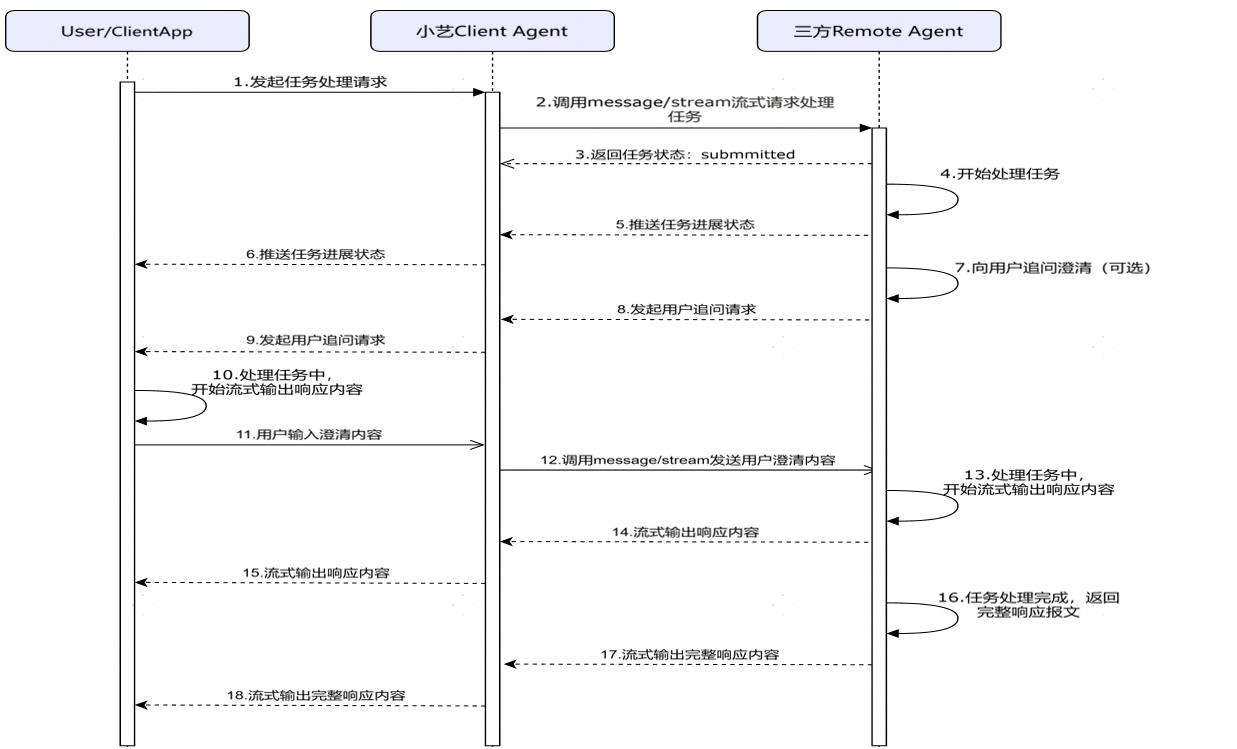
-
处理任务请求:
- 用户向小艺发起请求。
- 小艺客户端通过
message/streamRPC方法调用第三方智能体。 - 第三方智能体异步处理 ,并通过SSE流式返回结果,内容包括:
- 任务处理进度状态(如"正在思考"、"正在生成")。
- 可选的追问澄清(向用户提问以获得更准确信息)。
- 流式生成的内容(首Token产生后就开始返回)。
- 最终完整的响应。
- 要求第三方智能体基于
sessionId缓存对话上下文,以实现多轮对话。
-
管理与控制:
- 终止任务 :用户或系统可以通过
tasks/cancelRPC方法,要求第三方智能体停止当前正在处理的任务。 - 清除上下文 :通过
clearContextRPC方法,清除当前对话的历史记录,开始一个全新的话题。
- 终止任务 :用户或系统可以通过
-
用户账号与授权:
- 提供了一套基于华为账号的一键授权登录方案(OAuth)。
- 用户授权后,第三方智能体服务器可以安全地获取用户的手机号(需用户同意)。
- 授权成功后,会生成一个
agentLoginSessionId,用于后续请求中标识已登录用户,实现个性化服务。 - 小艺客户端会自动管理这个Session的生命周期(过期刷新、失效重授权)。
3. 定义的RPC方法(操作原语)
这是协议的核心API列表,规定了客户端和服务器之间可以进行的操作:
| 方法名 | 调用方式 | 功能描述 |
|---|---|---|
initialize |
阻塞式 | 初始化会话 。客户端发起,从服务器获取 sessionId。 |
notifications/initialized |
阻塞式 | 通知初始化完成。客户端告知服务器初始化流程完毕。 |
message/stream |
非阻塞/流式 | 核心对话方法。客户端发送用户消息,服务器流式返回处理结果(文本、状态、追问等)。 |
tasks/cancel |
阻塞式 | 任务取消。请求服务器停止当前任务。 |
clearContext |
阻塞式 | 清除上下文。请求服务器清空当前会话的历史记忆。 |
authorize |
阻塞式 | 授权通知 。客户端将用户授权成功的信息(agentLoginSessionId)告知服务器。 |
deauthorize |
阻塞式 | 取消授权通知。客户端通知服务器用户已取消授权。 |
push |
阻塞式 | 服务器主动推送。适用于长时间异步任务(如生成视频),完成后由服务器主动通知客户端。 |
简单来说,这份文档就是告诉开发者:"如果你想让你的AI服务在鸿蒙手机/设备上被小艺调用,你需要按照这个规范来构建你的服务器接口。" 这标志着鸿蒙在构建一个开放、统一、强大的分布式AI智能体生态方面迈出了关键一步。
这套协议的核心,是定义了八个基本的"对话动作":
- 握手(
initialize):鸿蒙第一次找过来,互相认识一下,建立一个连接通道。 - 传话(
message/stream) :这是最核心的。用户跟小艺说的话,会用这个动作传给我们。我们处理完,再把答案流式地传回去。 - 打断(
tasks/cancel):用户不想听了,小艺通知我们赶紧停下。 - 清空(
clearContext):用户想聊新话题了,把之前的聊天记录清掉。 - 登录/退出(
authorize/deauthorize):如果服务需要用户账号,就走这个流程。 - 主动上报(
push):我们有什么结果(比如一个长报告生成完了),可以主动推给小艺。
我们的协议适配网关就干一件事:准确翻译这些动作。它不负责智能,智能的部分还是交给我们原来的"数字人"和"分析员"。
二、实战案例:如何使用coze智能体对接鸿蒙
举个例子,我们有个很成熟的医疗数字人,本来是在医院App里用的。现在想让它能在鸿蒙侧回答问题。最简单的开发方式就是我们提供服务层接口,用户在应用内"问答"。但是这样就无法享受"系统级"对接的特性了。而如果要把coze、或者dify已经实现的知识库、智能体、工作流重新实现一遍,在投入产出上又有些得不偿失。
再或者我们确实需要上架一个鸿蒙侧的智能体,但是能否让主智能体通过调用三方智能体的能力,去减少重复的工作量呢?
你看,核心的需求是,业务逻辑、知识库、安全审查,全都不变,还是我们原来的那套经过验证的系统。 变的只是最外面的"传话方式"。对我们来说,最大的开发工作量就是写好那个负责拆包、打包的"桥"。
这里我以上段时间开发的一个出行类AI应用为大家解构一下整个对接逻辑。
在查询官网后,我发现,官网有完整的Coze流式响应示例、鸿蒙Agent对接示例 ,让我可以进行精确的事件映射分析 。同时也证实了我们之前的判断:SSE协议层天然兼容,但应用层事件语义需要转换。
2.1. Coze事件与鸿蒙事件的对应关系
| Coze事件类型 | Coze状态/内容 | 对应鸿蒙事件类型 | 转换规则 |
|---|---|---|---|
conversation.chat.created |
status: "created" |
TaskStatusUpdateEvent |
映射为 state: "submitted" |
conversation.chat.in_progress |
status: "in_progress" |
TaskStatusUpdateEvent |
映射为 state: "working" |
conversation.message.delta |
增量内容片段("2", "0", "星期三") |
TaskArtifactUpdateEvent |
核心转换 :append: true, lastChunk: false |
conversation.message.completed |
完整消息内容 | TaskArtifactUpdateEvent |
lastChunk: true, 可能需要发送最终汇总 |
conversation.chat.completed |
status: "completed" |
TaskStatusUpdateEvent |
state: "completed", final: true |
event:done |
[DONE] |
流结束信号 | 确保发送final: true的鸿蒙事件 |
2.2 具体转换示例
基于我们实际Coze流式数据,代理服务器需要做这样的实时转换:
python
def convert_coze_to_harmony(coze_event, coze_data, task_id, session_id):
"""将Coze的SSE事件转换为鸿蒙格式"""
if coze_event == "conversation.chat.created":
return {
"jsonrpc": "2.0",
"id": task_id,
"result": {
"taskId": task_id,
"kind": "status-update",
"final": False,
"status": {
"state": "submitted",
"message": {
"role": "agent",
"parts": [{"kind": "text", "text": "任务已接收"}]
}
}
}
}
elif coze_event == "conversation.chat.in_progress":
return {
"jsonrpc": "2.0",
"id": task_id,
"result": {
"taskId": task_id,
"kind": "status-update",
"final": False,
"status": {
"state": "working",
"message": {
"role": "agent",
"parts": [{"kind": "text", "text": "思考中..."}]
}
}
}
}
elif coze_event == "conversation.message.delta":
# 关键:流式内容转换
return {
"jsonrpc": "2.0",
"id": task_id,
"result": {
"taskId": task_id,
"kind": "artifact-update",
"append": True, # 增量追加
"lastChunk": False, # 不是最后一块
"final": False,
"artifact": {
"artifactId": f"artifact_{task_id}",
"parts": [{
"kind": "text",
"text": coze_data.get("content", "") # 提取Coze的content
}]
}
}
}
elif coze_event == "conversation.message.completed":
# 注意:这里有两个completed事件,需要区分
if coze_data.get("type") == "answer":
return {
"jsonrpc": "2.0",
"id": task_id,
"result": {
"taskId": task_id,
"kind": "artifact-update",
"append": True,
"lastChunk": True, # 这是回答的最后一块
"final": False,
"artifact": {
"artifactId": f"artifact_{task_id}_final",
"parts": [{
"kind": "text",
"text": coze_data.get("content", "")
}]
}
}
}
elif coze_event == "conversation.chat.completed":
return {
"jsonrpc": "2.0",
"id": task_id,
"result": {
"taskId": task_id,
"kind": "status-update",
"final": True, # 重要:标记整个流结束
"status": {
"state": "completed",
"message": {
"role": "agent",
"parts": [{"kind": "text", "text": "任务完成"}]
}
}
}
}
return None # 忽略不相关的事件(如verbose类型)2.3 完整数据流转换示意图
用户问"2025年10月1日是星期几" → 小艺 → 你的代理服务器
代理服务器的处理流程:
1. 收到鸿蒙协议请求,提取task_id="123", query="2025年..."
2. 调用Coze API (stream=true, conversation_id=映射的ID)
3. 实时转换Coze的SSE流:
Coze原始流事件 → 转换后的鸿蒙协议事件
───────────────────────────────────┼────────────────────────────────────
conversation.chat.created → TaskStatusUpdateEvent(state=submitted)
conversation.chat.in_progress → TaskStatusUpdateEvent(state=working)
conversation.message.delta("2") → TaskArtifactUpdateEvent("2", append=true)
conversation.message.delta("0") → TaskArtifactUpdateEvent("0", append=true)
... (多个delta事件) ...
conversation.message.delta("三") → TaskArtifactUpdateEvent("三", append=true)
conversation.message.completed → TaskArtifactUpdateEvent(lastChunk=true)
conversation.chat.completed → TaskStatusUpdateEvent(state=completed, final=true)
event:done → [流结束,无对应事件]2.4 关键适配挑战与解决方案
| 挑战 | 具体表现 | 解决方案 |
|---|---|---|
| 事件类型不匹配 | Coze有7种事件,鸿蒙主要用2种 | 建立事件映射表,过滤无用事件 |
| 状态语义差异 | Coze的in_progress vs 鸿蒙的working |
固定映射关系,保持一致 |
| 内容增量处理 | Coze每个delta可能只有1个字符 | 可考虑缓冲合并(如每3个字符发一次)以减少事件数量 |
| 最终状态确认 | Coze有message.completed和chat.completed |
确保只在chat.completed时发送final: true |
| 错误处理缺失 | Coze流中未展示错误事件 | 需要单独处理Coze的错误响应,转换为鸿蒙的error对象 |
2.5 实际代码结构建议
python
class CozeToHarmonyAdapter:
def __init__(self):
self.event_map = {
'conversation.chat.created': self._handle_created,
'conversation.chat.in_progress': self._handle_in_progress,
'conversation.message.delta': self._handle_delta,
'conversation.message.completed': self._handle_message_completed,
'conversation.chat.completed': self._handle_chat_completed
}
async def transform_stream(self, coze_stream, harmony_task_id):
"""主转换函数:消费Coze流,产出鸿蒙事件流"""
buffer = [] # 可选的内容缓冲区
async for line in coze_stream:
if line.startswith('event:'):
current_event = line.split(':', 1)[1].strip()
elif line.startswith('data:'):
data = json.loads(line[5:].strip())
# 调用对应的处理函数
handler = self.event_map.get(current_event)
if handler:
harmony_event = handler(data, harmony_task_id)
if harmony_event:
yield self._format_sse(harmony_event)
def _handle_delta(self, coze_data, task_id):
"""处理增量内容"""
content = coze_data.get('content', '')
if not content:
return None
# 可选:缓冲策略,累积一定内容再发送
self.buffer.append(content)
if len(self.buffer) >= 3 or len(''.join(self.buffer)) >= 10:
combined = ''.join(self.buffer)
self.buffer.clear()
return self._create_artifact_event(task_id, combined, False)
return None主要适配工作集中在:
- 事件语义转换:将Coze的7种事件映射到鸿蒙的2种核心事件
- 数据格式包装:将Coze的简单JSON包装为JSON-RPC 2.0格式
- 状态机对齐:确保Coze的状态流程符合鸿蒙的状态机定义
- 会话管理 :维护
conversation_id与鸿蒙sessionId的映射
这种适配的复杂度是可控的,因为:
- 有明确的------对应关系
- 不需要解析复杂的内容结构
- 主要是字段映射和格式包装
三、这么干,到底划不划算?算笔实在账
成本对比:
| 项目 | 推倒重来(重建) | 搭桥接入(利旧) | 对比结果 |
|---|---|---|---|
| 开发时间 | 至少6-9个月 | 2-3个月 | 节省至少4个月 |
| 开发人力 | 需要新组一个6-8人团队 | 现有团队出2-3人 | 人力成本省2/3 |
| AI资源费 | GPT等大模型API费用加倍 | 费用不变,复用原有额度 | 每月省数万至数十万 |
| 数据问题 | 历史数据迁移困难,易出错 | 数据完全继承,无缝衔接 | 零风险,零损失 |
| 运维压力 | 两套独立系统,运维翻倍 | 只多一个轻量网关,运维压力小 | 长期成本低 |
算笔经济账:
假设我们为鸿蒙重做一个数字人,最少投入:
- 人力成本:6人 × 6个月 ≈ 180万
- 云资源与API额外开支:约50万/年
- 总计:首年约230万
而现在"搭桥"的方案:
- 人力成本:3人 × 2.5个月 ≈ 37.5万
- 网关服务器费用:约5万/年
- 总计:首年约42.5万
里外里,一年就能省下近200万,而且还能提前好几个月上线。
总结
如果你的团队有类似的需求,可以按这个路子想想:
- 先盘家底:别急着开干。先把你们公司最核心、最赚钱、最稳定的AI服务列出来。这些就是优先"搭桥"的对象。
- 小步快走:别想着一口吃成胖子。先挑一个场景简单、但用户感知强的功能试水。比如,先把简单的QA问答接进去,让老板和用户快速看到效果,建立信心。
- "桥"要建好:这个协议适配网关是关键。它要稳定、要能监控、要方便扩展。这部分值得投入用好点的设计和架构,因为它以后可能要连接很多服务。
- 拥抱变化:鸿蒙的协议可能会更新,生态也会变。咱们的"桥"要设计得灵活点,以后换"接头暗号"也方便。
说到底,技术潮流一波接一波。但公司里那些真正解决了业务问题、产生了数据价值的AI资产,才是压舱石。我们的策略是:用最小的代价,让压舱石也能赶上新的潮流,而不是每次潮来了都换个新石头。
这座"桥"如果搭得好,它不只是通向鸿蒙,以后再来别的"新大陆",我们可能也能快速接上去看看。这,或许才是技术人应对变化的一种务实智慧。