Redis(Remote Dictionary Server)是开源、高性能、基于内存的键值(Key-Value)型NoSQL数据库 ,也是互联网架构中最主流的缓存中间件,支持数据持久化、多数据结构、分布式高可用,核心定位是加速读写、分担数据库压力、实现分布式协同,是后端、缓存、分布式系统的必备组件。
Redis的基础理论
一、Redis核心基础:定位与底层优势
- 存储模式
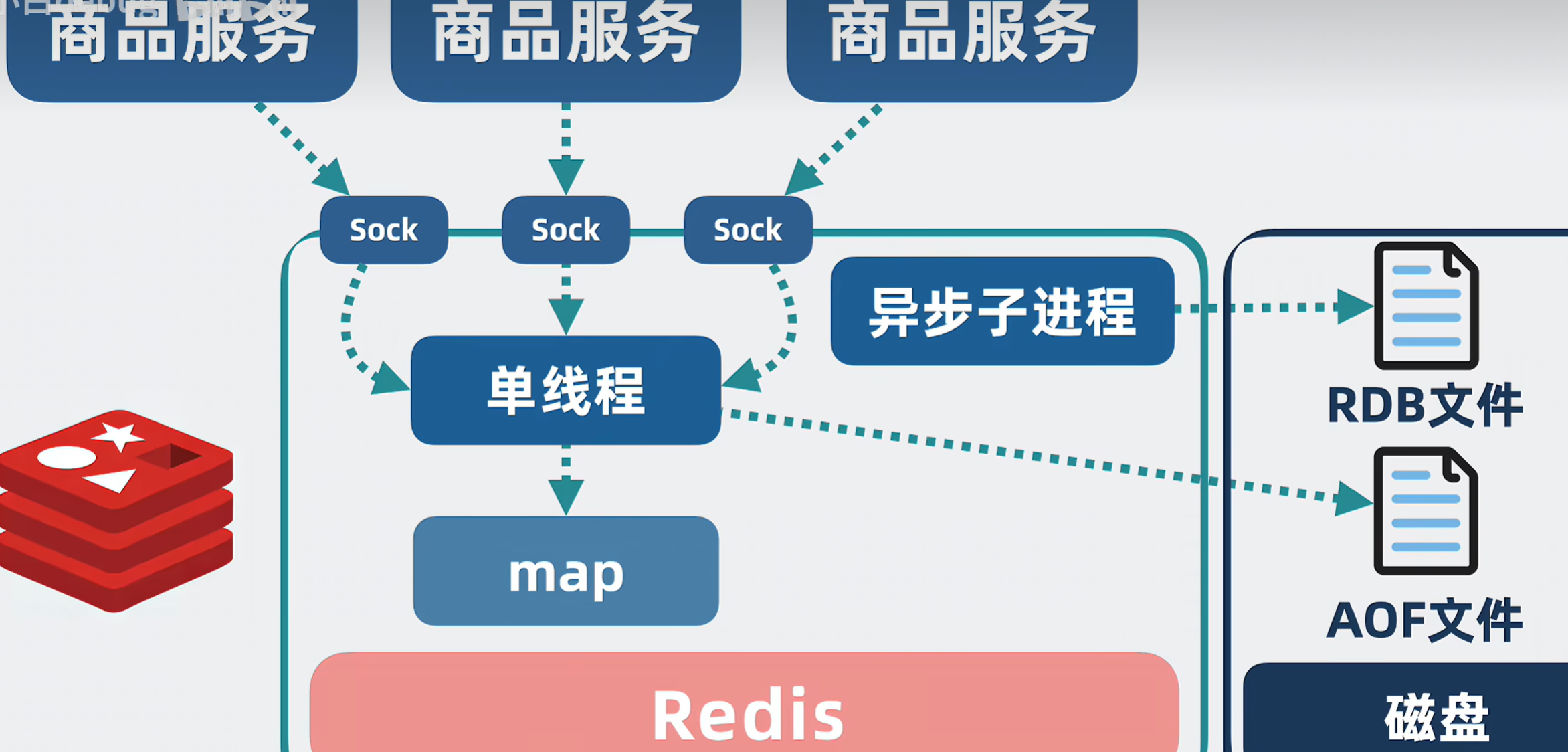
以内存存储为核心,读写速度极快(读11万次/秒、写8万次/秒),支持磁盘持久化防止数据丢失,兼顾速度与可靠性。 - 单线程+IO多路复用
Redis 6.0前核心命令处理为单线程 ,避免多线程锁竞争与上下文切换;采用IO多路复用(epoll/select/kqueue),单线程可并发处理海量网络请求,是高性能的核心原因。
Redis 6.0引入多线程IO,仅网络读写并行,命令执行仍单线程,不破坏原子性。 - 核心定位
纯缓存、分布式共享存储、分布式锁、消息队列、计数器、限流组件等,是全能型中间件 。
二、核心数据结构
Redis支持10+种数据结构,覆盖绝大多数业务场景:
- String(字符串)
最基础结构,value为字符串/数字/二进制,最大512MB。
命令:SET/GET/INCR/DECR/INCRBY,支持原子自增 。
场景:分布式计数器、用户信息缓存、接口限流、Session共享。 - Hash(哈希)
键值对集合,适合存储对象 (如用户信息、商品详情)。
命令:HSET/HGET/HGETALL/HINCRBY,内存占用比String更低。
场景:用户信息缓存、商品属性存储。 - List(列表)
双向链表,有序可重复,支持头尾快速操作。
命令:LPUSH/RPUSH/LPOP/RPOP/LRANGE。
场景:简单消息队列、关注列表、时间线。 - Set(集合)
无序不可重复,支持交集/并集/差集。
命令:SADD/SMEMBERS/SINTER/SUNION。
场景:去重、共同关注、抽奖、好友推荐。 - ZSet(有序集合)
带score权重的有序集合,自动排序。
命令:ZADD/ZRANGE/ZRANK/ZINCRBY。
场景:排行榜、热度排序、延时任务。 - 高级结构
- Bitmap:位存储,极省内存,适合二状态场景(签到、是否在线)。
- HyperLogLog:基数统计,极小内存实现海量数据去重计数(UV统计)。
- Geospatial:地理坐标,计算距离、附近人/店。
- Stream:持久化消息队列,支持消费组、消息回溯,替代专业MQ轻量场景。
- Bitmap、布隆过滤器:解决缓存穿透、海量数据存在性判断。
三、关键特性:过期与内存管理
- 过期策略
- 定时过期:设置Key过期时间(
EXPIRE/PEXPIRE)。 - 惰性删除:访问Key时检查是否过期,过期删除。
- 定期删除:每秒随机抽取部分Key清理过期数据,平衡性能与内存。
- 定时过期:设置Key过期时间(
- 内存淘汰机制(8种)
内存满时自动清理数据,核心策略:volatile-lru:淘汰设置过期的最近最少使用Key(最常用)。allkeys-lru:淘汰所有Key中最近最少使用。volatile-random:随机淘汰过期Key。noeviction:不淘汰,直接报错(默认)。
业务首选volatile-lru,兼顾缓存命中率与内存安全。
四、数据持久化:防止内存数据丢失
Redis支持两种持久化,可组合使用:
- RDB(快照)
定时将内存数据全量写入磁盘,文件小、恢复快、性能影响小。
缺点:宕机丢失最后一次快照后的数据。 - AOF(日志)
记录每一条写命令,实时追加,数据安全性极高。
三种刷盘策略:always(每命令)、everysec(每秒,推荐)、no(操作系统控制)。
缺点:文件大、恢复慢、轻微影响性能。 - 混合持久化(Redis 4.0+)
RDB全量+AOF增量,结合两者优点,生产环境标配。
五、分布式高可用方案
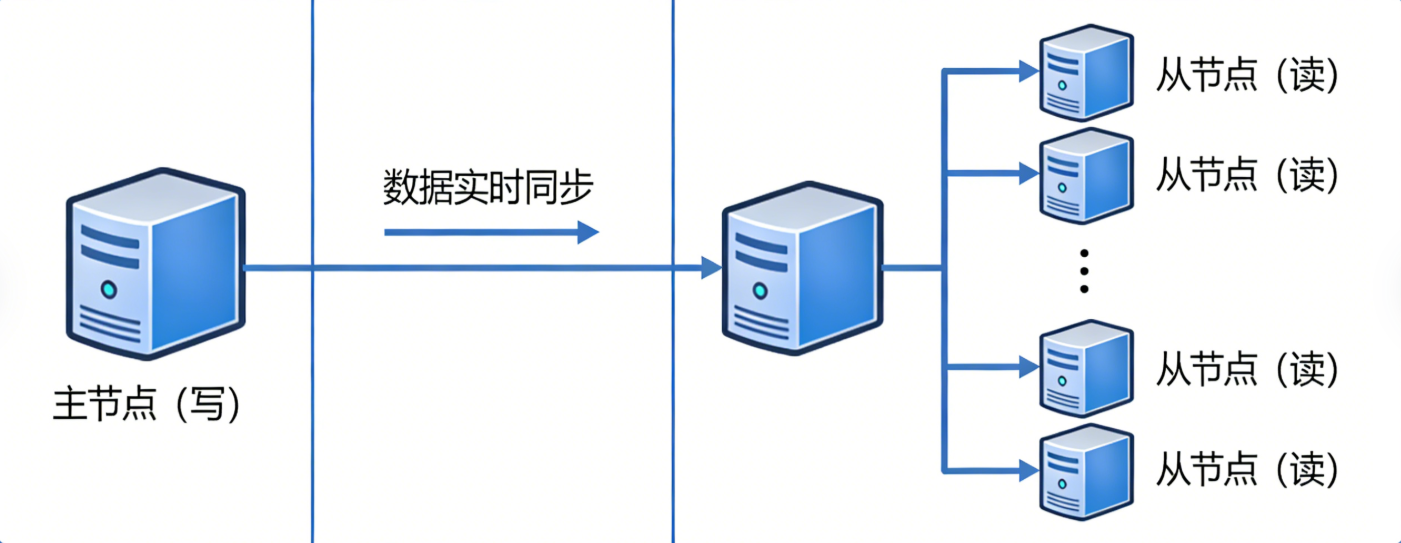
单机Redis存在单点故障、内存上限、性能瓶颈,需分布式架构:
-
主从复制
主节点写,从节点读,实现读写分离 ,分担读压力,数据实时同步。
-
哨兵(Sentinel)
监控主从节点,主节点宕机自动故障转移,选举新主节点,保证高可用,无人工干预。
-
Redis Cluster(集群)
分布式分片架构,将数据分散到多个主节点,突破单机内存限制,支持水平扩展。
核心:哈希槽(16384个) ,Key通过CRC16算法映射到槽,分配到对应节点。
支持高可用、分片存储、故障转移,是大型分布式系统首选。
六、缓存三大经典问题与解决方案
缓存使用中最易踩坑的三大问题,是面试与生产核心:
- 缓存穿透
问题:查询不存在的数据,缓存不命中,直接查数据库,压垮DB。
方案:空值缓存、布隆过滤器过滤非法Key。 - 缓存击穿
问题:热点Key过期,大量请求同时击穿到数据库。
方案:互斥锁、热点Key永不过期、逻辑过期。 - 缓存雪崩
问题:大量Key同时过期/Redis宕机,请求全部打向数据库。
方案:过期时间随机、集群高可用、多级缓存、服务熔断降级。
七、高级特性:事务、Lua、管道
- 事务
支持MULTI/EXEC/DISCARD/WATCH,弱事务:不保证原子性,命令排队执行,出错不回滚。 - Lua脚本
核心优势:原子性执行,多条命令一次性执行,避免并发问题,是分布式锁、限流的核心实现方式。 - 管道(Pipeline)
批量发送命令,减少网络IO次数,提升批量操作性能10倍以上。
八、应用场景
- 分布式锁:解决分布式系统并发安全问题。
- 接口限流:计数器/滑动窗口/漏斗算法。
- Session共享:替代单机Session,集群互通。
- 延时任务:ZSet实现订单超时未支付自动取消。
- 消息队列:List/Stream实现轻量MQ。
- 热点数据缓存:商品详情、首页数据、用户信息,降低DB压力。
Redis应用
一、Redis命令行使用
Redis命令行是操作Redis的最基础方式,也是代码调用的底层逻辑,先掌握命令行才能更好理解代码操作的本质。
1. 环境准备与基础连接
(1)启动/停止Redis服务
bash
# Linux/macOS 启动(指定配置文件,项目用)
redis-server /etc/redis/redis.conf
# 前台启动(测试用,关闭终端即停止)
redis-server
# 停止Redis服务(优雅关闭,保证数据持久化)
redis-cli shutdown
# Windows 启动(解压后)
redis-server.exe redis.windows.conf(2)连接Redis客户端
bash
# 本地默认连接(IP=127.0.0.1,端口=6379,数据库=0)
redis-cli
# 远程连接(指定IP、端口、密码、数据库)
redis-cli -h 192.168.1.100 -p 6379 -a your_password -n 1
# 连接后验证是否成功
127.0.0.1:6379> PING # 返回PONG则连接正常
PONG
# 退出客户端
127.0.0.1:6379> QUIT
# 或快捷键:Ctrl+C2. 通用核心命令(Key级操作)
所有数据结构的Key都适用,是高频使用的基础命令:
| 命令 | 示例 | 说明 |
|---|---|---|
KEYS |
KEYS user:* |
匹配Key(如所有以user:开头的Key),生产禁用(阻塞单线程) |
SCAN |
SCAN 0 MATCH user:* COUNT 10 |
迭代遍历Key(生产推荐,非阻塞),0是游标,COUNT是每次遍历数量 |
EXISTS |
EXISTS username |
判断Key是否存在,返回1=存在,0=不存在 |
DEL |
DEL username user:1 |
删除指定Key,可批量删除,返回删除成功的数量 |
RENAME |
RENAME username uname |
重命名Key,若目标Key存在则覆盖 |
RENAMENX |
RENAMENX username uname |
重命名Key(仅目标Key不存在时生效) |
EXPIRE |
EXPIRE username 300 |
设置Key过期时间(单位:秒),返回1=成功 |
PEXPIRE |
PEXPIRE username 300000 |
设置过期时间(单位:毫秒) |
TTL |
TTL username |
查看剩余过期时间(-1=永不过期,-2=已过期) |
PTTL |
PTTL username |
查看剩余过期时间(毫秒) |
PERSIST |
PERSIST username |
移除Key的过期时间(变为永不过期) |
TYPE |
TYPE username |
查看Key对应的数据结构类型(string/hash/list等) |
SELECT |
SELECT 1 |
切换数据库(Redis默认16个库,0-15,相互隔离) |
INFO |
INFO replication |
查看Redis状态信息(replication=主从,memory=内存等) |
3. 各数据结构核心命令(按使用频率排序)
(1)String(字符串,最常用)
Redis中String是二进制安全的,可存储字符串、数字、二进制数据(如图片),最大512MB。
bash
# 基础设置/获取
SET username "zhangsan" # 普通设置
SET username "lisi" NX # 仅Key不存在时设置(分布式锁核心)
SET username "wangwu" XX # 仅Key存在时设置
SET age 25 EX 60 # 设置值并指定60秒过期
SETEX email 300 "zhangsan@test.com" # 等价于SET+EXPIRE
MSET addr "beijing" phone "13800138000" # 批量设置
MGET username addr phone # 批量获取
# 数值操作(原子性,计数器核心)
INCR visit_count # 自增1(仅数字值有效)
INCRBY visit_count 10 # 自增指定值(+10)
DECR age # 自减1
DECRBY age 5 # 自减指定值(-5)
INCRBYFLOAT score 0.5 # 浮点型自增
# 字符串操作
APPEND username "_test" # 追加字符串(如zhangsan→zhangsan_test)
STRLEN username # 获取字符串长度
SUBSTR username 0 3 # 截取子串(索引0到3,左闭右闭)(2)Hash(哈希,存储对象)
适合存储结构化数据(如用户信息、商品属性),比String更节省内存,支持单独操作字段。
bash
# 基础设置/获取
HSET user:1 name "zhangsan" age 25 gender "male" # 批量设置字段
HSETNX user:1 email "zhangsan@test.com" # 仅字段不存在时设置
HGET user:1 name # 获取单个字段值
HGETALL user:1 # 获取所有字段和值(返回[key1,val1,key2,val2])
HMSET user:2 name "lisi" age 30 # 批量设置(旧命令,仍可用)
HMGET user:1 name age # 批量获取指定字段
# 数值操作
HINCRBY user:1 age 1 # 字段值自增1
HINCRBYFLOAT user:1 score 0.5 # 浮点型自增
# 字段管理
HKEYS user:1 # 获取所有字段名
HVALS user:1 # 获取所有字段值
HLEN user:1 # 获取字段数量
HEXISTS user:1 gender # 判断字段是否存在
HDEL user:1 gender # 删除指定字段(3)List(列表,双向链表)
有序、可重复,支持头尾快速操作(O(1)),适合做简单消息队列、时间线等。
bash
# 插入元素
LPUSH msg_queue "msg1" "msg2" # 左侧插入(头插)
RPUSH msg_queue "msg3" "msg4" # 右侧插入(尾插)
LPUSHX msg_queue_empty "msg5" # 仅列表存在时左侧插入
RPUSHX msg_queue_empty "msg6" # 仅列表存在时右侧插入
# 取出元素
LPOP msg_queue # 左侧弹出(头删)
RPOP msg_queue # 右侧弹出(尾删)
BLPOP msg_queue 10 # 阻塞式左侧弹出(等待10秒,无数据返回nil)
BRPOP msg_queue 10 # 阻塞式右侧弹出(消息队列核心)
# 查看/修改
LRANGE msg_queue 0 -1 # 查看所有元素(0=第一个,-1=最后一个)
LINDEX msg_queue 1 # 获取指定索引的元素(索引从0开始)
LLEN msg_queue # 获取列表长度
LSET msg_queue 1 "new_msg2" # 修改指定索引的元素
LTRIM msg_queue 0 2 # 裁剪列表(仅保留索引0-2的元素)(4)Set(集合,无序不可重复)
基于哈希表实现,支持交集、并集、差集,适合去重、共同关注、抽奖等场景。
bash
# 增删查
SADD hobby "basketball" "football" "swim" # 添加元素(自动去重)
SMEMBERS hobby # 查看所有元素
SISMEMBER hobby "running" # 判断元素是否存在(1=存在,0=不存在)
SREM hobby "swim" # 删除指定元素
SPOP hobby # 随机弹出一个元素(抽奖核心)
SRANDMEMBER hobby 2 # 随机获取2个元素(不弹出)
SCARD hobby # 获取集合元素数量
# 集合运算(核心)
SADD hobby:zhangsan "basketball" "music"
SADD hobby:lisi "basketball" "reading"
SINTER hobby:zhangsan hobby:lisi # 交集(共同爱好:basketball)
SUNION hobby:zhangsan hobby:lisi # 并集(所有爱好)
SDIFF hobby:zhangsan hobby:lisi # 差集(张三有但李四没有的)
SINTERSTORE hobby:common hobby:zhangsan hobby:lisi # 交集结果存入新集合(5)ZSet(有序集合,带权重排序)
Set的升级版,每个元素关联一个score(浮点型),自动按score排序,适合排行榜、延时任务等。
bash
# 增删查
ZADD score_rank 95 "zhangsan" 90 "lisi" 98 "wangwu" # 添加元素(score+值)
ZADD score_rank XX INCR 96 "zhangsan" # 仅元素存在时,score自增1
ZRANGE score_rank 0 -1 # 按score升序查看所有元素
ZRANGE score_rank 0 -1 WITHSCORES # 带score查看
ZREVRANGE score_rank 0 2 WITHSCORES # 按score降序查看前3名(排行榜核心)
ZSCORE score_rank "zhangsan" # 获取指定元素的score
ZREM score_rank "lisi" # 删除指定元素
ZCARD score_rank # 获取元素数量
# 排名/范围操作
ZRANK score_rank "zhangsan" # 升序排名(从0开始)
ZREVRANK score_rank "zhangsan" # 降序排名(从0开始)
ZINCRBY score_rank 2 "zhangsan" # 元素score自增2
ZRANGEBYSCORE score_rank 90 95 WITHSCORES # 按score范围查询(90≤score≤95)
ZCOUNT score_rank 90 95 # 统计score范围内的元素数量(6)高级结构(Bitmap/HyperLogLog)
bash
# Bitmap(位存储,极省内存,二值场景)
SETBIT sign:zhangsan 0 1 # 第0天签到(1=签到,0=未签)
SETBIT sign:zhangsan 1 0 # 第1天未签
GETBIT sign:zhangsan 0 # 查看第0天是否签到
BITCOUNT sign:zhangsan # 统计签到天数(1的数量)
# HyperLogLog(基数统计,UV统计核心)
PFADD uv:20240213 "user1" "user2" "user3" # 添加用户
PFCOUNT uv:20240213 # 统计去重后的用户数(基数)
PFMERGE uv:202402 uv:20240213 uv:20240214 # 合并多个HyperLogLog4. 命令行使用注意事项
- 生产环境禁用
KEYS *、FLUSHDB、FLUSHALL:这些命令会阻塞Redis单线程,导致服务卡顿; - 批量操作优先用
MSET/MGET/HMSET/HMGET:减少网络IO次数,提升效率; - 过期时间建议显式设置:避免Key永久堆积占用内存;
- 大Key(如超过100MB的String、百万元素的List)要拆分:避免单次操作阻塞服务。
二、代码层面使用Redis(Python示例)
Python操作Redis最主流的库是redis-py,支持所有Redis命令,语法与命令行高度一致,新手易上手。
1. 环境准备
bash
# 安装redis-py库
pip install redis # 基础版
pip install redis[hiredis] # 推荐(集成hiredis,提升性能)2. 完整代码示例
python
import redis
from redis.exceptions import RedisError
# ====================== 1. 建立连接(推荐连接池,生产级) ======================
# 配置连接池
pool = redis.ConnectionPool(
host="localhost", # Redis服务地址
port=6379, # 端口
password="", # 密码(无则留空)
db=0, # 使用的数据库编号
decode_responses=True, # 自动将返回值从bytes转为字符串(新手友好)
max_connections=100, # 连接池最大连接数
socket_timeout=5 # 连接超时时间(秒)
)
# 从连接池获取连接
r = redis.Redis(connection_pool=pool)
# ====================== 2. 核心操作示例 ======================
try:
# ---------- String操作 ----------
# 设置值+过期时间
r.set("username", "zhangsan", ex=300)
print("String - 获取username:", r.get("username")) # 输出:zhangsan
# 原子计数器
r.incr("visit_count")
print("String - 访问次数:", r.get("visit_count")) # 输出:1
# 批量设置/获取
r.mset({"addr": "beijing", "phone": "13800138000"})
print("String - 批量获取:", r.mget("username", "addr", "phone")) # 输出:['zhangsan', 'beijing', '13800138000']
# ---------- Hash操作 ----------
# 设置用户信息
r.hset("user:1", mapping={"name": "lisi", "age": 30, "gender": "male"})
# 获取单个字段
print("Hash - 用户1姓名:", r.hget("user:1", "name")) # 输出:lisi
# 获取所有字段
print("Hash - 用户1所有信息:", r.hgetall("user:1")) # 输出:{'name': 'lisi', 'age': '30', 'gender': 'male'}
# 字段自增
r.hincrby("user:1", "age", 1)
print("Hash - 用户1年龄+1:", r.hget("user:1", "age")) # 输出:31
# ---------- List操作(消息队列) ----------
# 插入消息
r.lpush("msg_queue", "msg1", "msg2", "msg3")
# 查看所有消息
print("List - 所有消息:", r.lrange("msg_queue", 0, -1)) # 输出:['msg3', 'msg2', 'msg1']
# 阻塞式取出消息(队列核心)
msg = r.brpop("msg_queue", timeout=10) # 超时10秒
print("List - 取出消息:", msg) # 输出:('msg_queue', 'msg1')
# ---------- Set操作(去重/交集) ----------
# 添加爱好
r.sadd("hobby:zhangsan", "basketball", "music", "reading")
r.sadd("hobby:lisi", "basketball", "swim", "running")
# 共同爱好(交集)
common_hobby = r.sinter("hobby:zhangsan", "hobby:lisi")
print("Set - 共同爱好:", common_hobby) # 输出:{'basketball'}
# ---------- ZSet操作(排行榜) ----------
# 添加成绩
r.zadd("score_rank", {"zhangsan": 95, "lisi": 90, "wangwu": 98})
# 降序取前2名(带分数)
top2 = r.zrevrange("score_rank", 0, 1, withscores=True)
print("ZSet - 排行榜前2名:", top2) # 输出:[('wangwu', 98.0), ('zhangsan', 95.0)]
# ---------- 通用Key操作 ----------
# 判断Key是否存在
print("通用 - username是否存在:", r.exists("username")) # 输出:1
# 设置过期时间
r.expire("addr", 60)
# 查看剩余过期时间
print("通用 - addr剩余过期时间:", r.ttl("addr")) # 输出:60左右
except RedisError as e:
print(f"Redis操作异常: {e}")
finally:
# 连接池模式下,无需手动关闭连接(自动归还到池)
pass3. Python操作注意事项
- 连接池是生产必备:避免频繁创建/销毁连接,提升性能;
decode_responses=True:新手建议开启,避免处理b'zhangsan'这类字节串;- 异常捕获:必须捕获
RedisError(覆盖网络异常、服务宕机、命令错误等); - 批量操作优先用
mset/hmget:减少网络往返次数。
三、代码层面使用Redis(C++示例)
C++操作Redis的主流库是hiredis(官方推荐的C客户端),轻量、高性能,需手动编译安装。
1. 环境准备(Linux/macOS)
bash
# 安装依赖
sudo apt update && sudo apt install -y gcc make libssl-dev # Ubuntu/Debian
# 或
brew install openssl # macOS
# 下载并安装hiredis
git clone https://github.com/redis/hiredis.git
cd hiredis
make && sudo make install
# 配置动态库路径(避免运行时找不到库)
sudo ldconfig2. 完整代码示例
cpp
#include <iostream>
#include <string>
#include <vector>
#include <hiredis/hiredis.h>
// 释放Redis回复对象的工具函数
void freeRedisReply(redisReply* reply) {
if (reply != nullptr) {
freeReplyObject(reply);
}
}
// 执行Redis命令的封装函数
redisReply* executeRedisCommand(redisContext* ctx, const char* format, ...) {
va_list args;
va_start(args, format);
redisReply* reply = (redisReply*)redisvCommand(ctx, format, args);
va_end(args);
// 检查命令执行是否失败
if (ctx->err) {
std::cerr << "Redis命令执行失败: " << ctx->errstr << std::endl;
freeRedisReply(reply);
return nullptr;
}
return reply;
}
int main() {
// ====================== 1. 建立Redis连接 ======================
// 连接参数:地址、端口、超时时间(秒,微秒)
struct timeval timeout = {5, 0}; // 5秒超时
redisContext* ctx = redisConnectWithTimeout("127.0.0.1", 6379, timeout);
// 检查连接是否成功
if (ctx == nullptr || ctx->err) {
if (ctx) {
std::cerr << "Redis连接失败: " << ctx->errstr << std::endl;
redisFree(ctx);
} else {
std::cerr << "Redis连接失败: 内存分配错误" << std::endl;
}
return -1;
}
std::cout << "Redis连接成功!" << std::endl;
redisReply* reply = nullptr;
try {
// ====================== 2. 核心操作示例 ======================
// ---------- String操作 ----------
// 设置值:SET username zhangsan EX 300
reply = executeRedisCommand(ctx, "SET %s %s EX %d", "username", "zhangsan", 300);
if (reply && reply->type == REDIS_REPLY_STATUS && strcmp(reply->str, "OK") == 0) {
std::cout << "String - SET成功" << std::endl;
}
freeRedisReply(reply);
// 获取值:GET username
reply = executeRedisCommand(ctx, "GET %s", "username");
if (reply && reply->type == REDIS_REPLY_STRING) {
std::cout << "String - 获取username: " << reply->str << std::endl; // 输出:zhangsan
}
freeRedisReply(reply);
// 原子计数器:INCR visit_count
reply = executeRedisCommand(ctx, "INCR %s", "visit_count");
if (reply && reply->type == REDIS_REPLY_INTEGER) {
std::cout << "String - 访问次数: " << reply->integer << std::endl; // 输出:1
}
freeRedisReply(reply);
// ---------- Hash操作 ----------
// 设置用户信息:HSET user:1 name lisi age 30 gender male
reply = executeRedisCommand(ctx, "HSET %s %s %s %s %d %s %s",
"user:1", "name", "lisi", "age", 30, "gender", "male");
freeRedisReply(reply);
// 获取单个字段:HGET user:1 name
reply = executeRedisCommand(ctx, "HGET %s %s", "user:1", "name");
if (reply && reply->type == REDIS_REPLY_STRING) {
std::cout << "Hash - 用户1姓名: " << reply->str << std::endl; // 输出:lisi
}
freeRedisReply(reply);
// 获取所有字段:HGETALL user:1
reply = executeRedisCommand(ctx, "HGETALL %s", "user:1");
if (reply && reply->type == REDIS_REPLY_ARRAY) {
std::cout << "Hash - 用户1所有信息: ";
for (size_t i = 0; i < reply->elements; i += 2) {
std::cout << reply->element[i]->str << "=" << reply->element[i+1]->str << " ";
}
std::cout << std::endl; // 输出:name=lisi age=30 gender=male
}
freeRedisReply(reply);
// ---------- ZSet操作(排行榜) ----------
// 添加成绩:ZADD score_rank 95 zhangsan 90 lisi 98 wangwu
reply = executeRedisCommand(ctx, "ZADD %s %f %s %f %s %f %s",
"score_rank", 95.0, "zhangsan", 90.0, "lisi", 98.0, "wangwu");
freeRedisReply(reply);
// 降序取前2名:ZREVRANGE score_rank 0 1 WITHSCORES
reply = executeRedisCommand(ctx, "ZREVRANGE %s %d %d WITHSCORES", "score_rank", 0, 1);
if (reply && reply->type == REDIS_REPLY_ARRAY) {
std::cout << "ZSet - 排行榜前2名: ";
for (size_t i = 0; i < reply->elements; i += 2) {
std::cout << reply->element[i]->str << "(" << reply->element[i+1]->str << ") ";
}
std::cout << std::endl; // 输出:wangwu(98) zhangsan(95)
}
freeRedisReply(reply);
// ---------- 通用Key操作 ----------
// 判断Key是否存在:EXISTS username
reply = executeRedisCommand(ctx, "EXISTS %s", "username");
if (reply && reply->type == REDIS_REPLY_INTEGER) {
std::cout << "通用 - username是否存在: " << (reply->integer ? "是" : "否") << std::endl; // 输出:是
}
freeRedisReply(reply);
} catch (const std::exception& e) {
std::cerr << "程序异常: " << e.what() << std::endl;
freeRedisReply(reply);
redisFree(ctx);
return -1;
}
// ====================== 3. 释放资源 ======================
redisFree(ctx);
return 0;
}3. 编译与运行
bash
# 编译代码(指定hiredis库)
g++ -o redis_cpp_demo redis_cpp_demo.cpp -lhiredis
# 运行程序
./redis_cpp_demo4. C++操作注意事项
- 内存管理:
redisReply必须手动调用freeReplyObject释放,否则内存泄漏; - 连接释放:
redisContext使用完必须调用redisFree释放; - 类型检查:执行命令后需检查
reply->type(如REDIS_REPLY_STRING、REDIS_REPLY_ARRAY),避免访问空指针; - 跨平台:Windows下需手动编译hiredis(推荐用vcpkg安装:
vcpkg install hiredis)。
核心关键点回顾
- 命令行操作:是所有代码操作的基础,核心按「通用Key命令+各数据结构命令」分类记忆,生产禁用阻塞式命令;
- Python操作 :用
redis-py库,优先用连接池,语法与命令行高度一致,新手易上手,需捕获RedisError; - C++操作 :用
hiredis库,需手动管理内存(回复对象、连接),编译时需链接-lhiredis,性能更优,适合高性能场景。
拓展建议
- 生产环境中,Redis建议配置密码、开启持久化(RDB+AOF)、搭建主从/哨兵集群;
- Python可结合
pipeline(管道)批量执行命令,进一步提升性能; - C++可封装
RedisClient类,简化连接、命令执行、资源释放的逻辑。