note
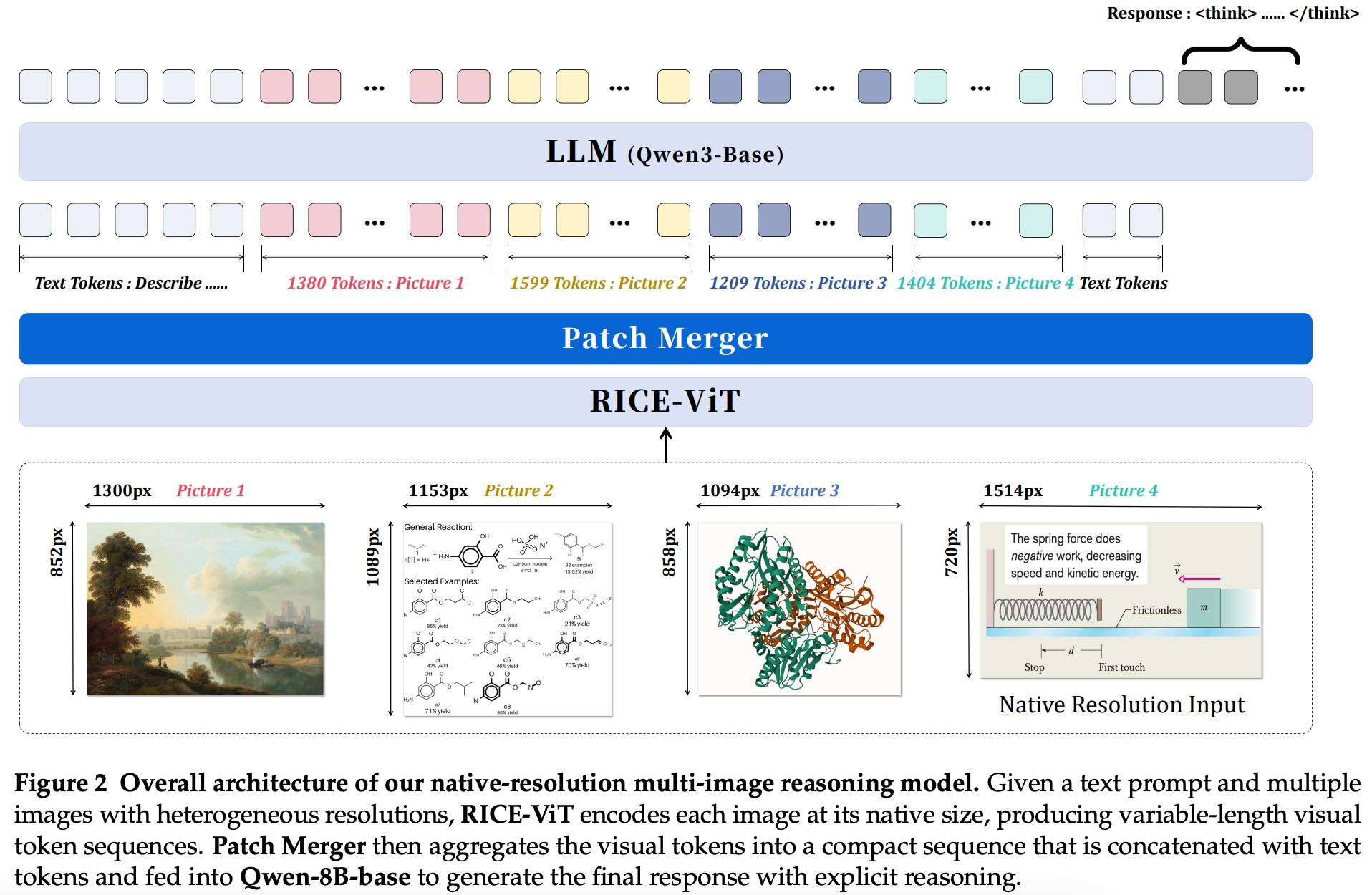
- Innovator-VL架构上,视觉编码器RICE-ViT【区域感知表示学习的ViT变体,融合全局和局部视觉线索,优化目标与OCR区域表示,适配科学图像的符号、标注、空间局部模式等细粒度结构,相比CLIP/SigLIP,在分割、密集检测等视觉任务表现更优】+投影层PatchMerger压缩视觉token+语言模型Qwen3-8B-Base【在STEM、逻辑推理、长上下文理解上表现优异】
文章目录
一、Innovator-VL模型
【科学领域多模态大模型进展】之前讲过interns1多模态模型,这个系列继续看一个新的模型Innovator-VL: A Multimodal Large Language Model for Scientific Discovery,https://arxiv.org/pdf/2601.19325,Homepage: https://InnovatorLM.github.io/Innovator-VL,Github: https://InnovatorLM/Innovator-VL,Instruct Model: https://nnovatorLab/Innovator-VL-8B-Instruct,Thinking Model: https://InnovatorLab/Innovator-VL-8B-Thinking,instruct Data: https://InnovatorLab/Innovator-VL-Instruct-46M,RL Data: https://InnovatorLab/Innovator-VL-RL-172K,核心看几点:
1)架构上,视觉编码器RICE-ViT【区域感知表示学习的ViT变体,融合全局和局部视觉线索,优化目标与OCR区域表示,适配科学图像的符号、标注、空间局部模式等细粒度结构,相比CLIP/SigLIP,在分割、密集检测等视觉任务表现更优】+投影层PatchMerger压缩视觉token+语言模型Qwen3-8B-Base【在STEM、逻辑推理、长上下文理解上表现优异】。
2)训练流程上采用预训练→有监督微调(SFT)→强化学习(RL)的分阶段训练策略:
- step1.预训练语言-图像对齐(LLaVA-1.5,558k样本)+高质量中期训练(85M样本),全参数训练
- step2.有监督微调(SFT)46M样本,含通用多模态/思维链推理/科学理解数据,人工参与数据构建,做冷启动
- step3.强化学习(RL)172K数据集,采用偏差驱动选择,筛选Pass@N与Pass@1差距大的样本,保留中等难度实例。使用GSPO优化算法,分层奖励系统(格式+准确率);
3)训练数据上,少样本(<500万科学样本)、高质量、人工参与、领域覆盖广,STEM&Code占比最高(RL阶段56.4%),含化学/物理/生物/数学等科学领域,方式为合成生成+真实来源,领域专家审核,迭代优化与质量控制。