π0.5 基于π0 模型升级,采用统一Transformer架构,核心是分层推理 、离散+连续动作融合表示,是首个实现开放世界复杂家庭任务泛化的端到端VLA模型。
推理机制:分层推理 ,先根据全局任务指令和场景观测预测高层语义子任务 ,再基于高层子任务生成低层连续动作块,二者由同一模型实现,区别于传统的双模型分离设计。动作表示:融合离散token (预训练阶段,训练效率高)与连续流匹配(后训练/推理阶段,支持精细动作、实时推理),通过联合损失函数优化,兼顾训练效率与实际控制效果。
论地地址:π0.5:a Vision-Language-Action Model with Open-World Generalization
开源地址:https://github.com/Physical-Intelligence/openpi
1、模型架构
如下图所示,是π0.5后训练&推理阶段 的核心流程,聚焦"全局任务→子任务→连续动作"的分层控制。
思路流程要点如下:
1.1、输入组件:任务指令+场景观测
- 高层提示(high-level prompt):全局任务指令(如"clean the bedroom")
- 场景图像:真实环境的视觉观测(如卧室场景图)
- 噪声(noise):用于流匹配算法的去噪过程,辅助生成连续动作
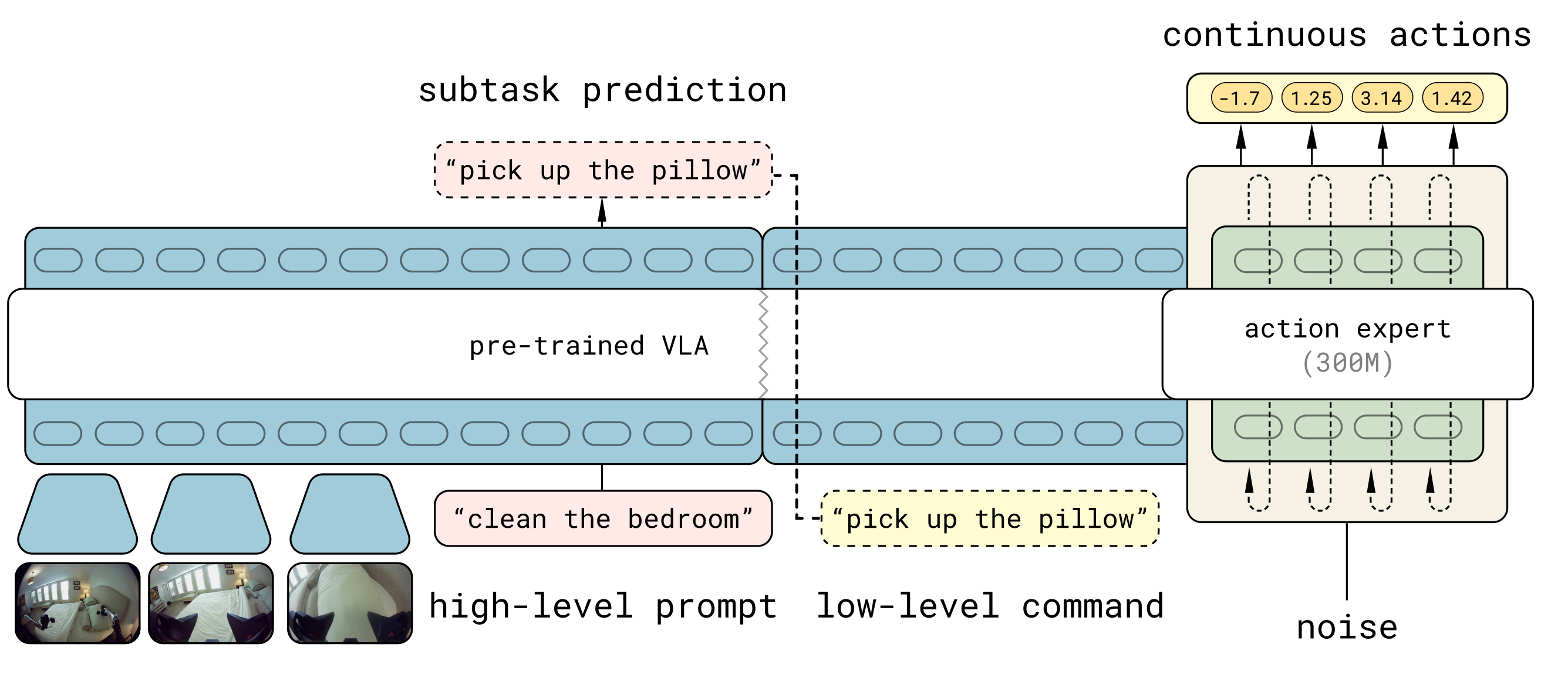
1.2、核心模块
- 预训练VLA:承接预训练阶段的VLA模型,负责高层任务的子任务拆解
- 动作专家(action expert,300M参数):独立模块,专门处理连续机器人动作的生成
1.3、处理流程(分层推理+连续动作生成)
① 高层子任务拆解 :预训练VLA基于"高层提示+场景图像",完成子任务预测(subtask prediction),将全局任务拆解为可执行的低层指令(low-level command,如"pick up the pillow")
② 低层连续动作生成 :动作专家接收"低层指令+场景信息+噪声",通过流匹配算法(逐步去噪)生成精细的连续机器人动作
1.4、输出结果
连续动作参数(如"-1.7、1.25"等数值),对应机器人的关节角度、底座速度等控制量,直接用于硬件的端到端控制。
1.5、π0.5 与 π0区别
π0.5 与 π0 的推理流程核心区别可从推理层次、架构设计、任务拆解、输入处理、动作生成逻辑等维度分析。
回顾看一下π0的架构:
| 对比维度 | π0推理流程特征 | π0.5推理流程特征 |
|---|---|---|
| 推理层次 | 单层扁平逻辑,直接从"全局指令+场景图像+机器人状态"生成动作("任务→动作") | 分层推理逻辑,遵循 "全局任务→高层子任务推理→低层连续动作生成" 的链式流程,先预测高层子任务再生成动作 |
| 架构设计 | 双专家分离:VLM专家与动作专家是分离模块,仅共享注意力层交互 | 统一模型一体化推理:同一VLA模型完成"高层子任务推理+低层动作生成",动作专家为模型分支模块 |
| 任务拆解能力 | 无自主分解能力,仅能处理训练覆盖的短时序简单任务,长时程任务规划能力弱 | 显式子任务预测,可自主拆解全局复杂任务,适配10-15分钟长时程任务的连续决策 |
| 输入处理 | 机器人状态以连续向量形式输入,通过线性投影转化为嵌入后与视觉-语言特征拼接 | 机器人状态离散化为文本Token,作为语言指令的一部分输入模型,适配语义推理逻辑 |
| 动作生成逻辑 | 直接基于"全局指令+场景图像"生成动作,动作与任务的关联依赖模型隐式学习 | 基于"预测的高层子任务+场景图像"生成动作,动作与当前子任务强绑定,控制合理性提升 |
2、π0.5架构设计思路
2.1、核心目标
设计单一统一的Transformer架构 ,实现高层语义子任务预测 与低层连续动作生成 的一体化推理,同时支持多模态输入输出 与异构多源数据的灵活处理,打破传统VLA模型"双模型分离推理"的冗余设计,实现知识共享与推理效率提升。
2.2、具体实现
-
多模态输入输出定义
模型的核心输入为观测 o t o_t ot (多相机图像+机器人本体状态:关节角度、夹爪姿态、躯干高度、底座速度)+全局任务语言指令 ℓ \ell ℓ (如"清洁厨房");
核心输出为高层文本子任务 ℓ ^ \hat{\ell} ℓ^ (如"拿起盘子",可为子任务预测/视觉语言问答结果)+低层连续动作块 a t : t + H a_{t:t+H} at:t+H ,同时支持图像描述、目标定位等视觉语言任务的输出。
本体状态被离散化为文本token输入模型,实现多模态输入的统一token化处理。
-
核心概率分布分解
模型将联合预测分布拆解为高层子任务分布 与低层动作分布 的乘积,公式为:(
在第4节会详细讲解的)
π θ ( a t : t + H , ℓ ^ ∣ o t , ℓ ) = π θ ( a t : t + H ∣ o t , ℓ ^ ) π θ ( ℓ ^ ∣ o t , ℓ ) \pi_{\theta}\left(a_{t: t+H}, \hat{\ell} | o_{t}, \ell\right)=\pi_{\theta}\left(a_{t: t+H} | o_{t}, \hat{\ell}\right) \pi_{\theta}\left(\hat{\ell} | o_{t}, \ell\right) πθ(at:t+H,ℓ^∣ot,ℓ)=πθ(at:t+H∣ot,ℓ^)πθ(ℓ^∣ot,ℓ)该分解是分层推理 的核心数学基础:低层动作生成仅依赖高层子任务,而非原始全局指令,让模型先完成"任务拆解"再执行"动作生成",适配长时程复杂任务的规划需求。
-
Transformer架构的灵活拓展
模型的Transformer骨干支持多类型token输入(文本离散token、图像块token、流匹配连续动作token),并通过三大机制实现模态差异化处理:
- 模态专属编码器:图像块经视觉编码器处理,文本token经词嵌入矩阵处理,连续动作token经线性投影融入嵌入空间;
- 模态专属专家权重 :不同类型token在Transformer中由独立的专家权重处理,尤其是动作token由专属的动作专家权重处理(继承π0设计),提升模态处理的针对性;
- 灵活注意力机制 :突破传统LLM的因果注意力 限制,采用双向注意力处理图像块、文本指令、连续动作token,仅对离散动作token保留自回归因果注意力,提升多模态信息融合效率。
-
输出分支设计
Transformer的输出被分为文本token输出分支 与动作输出分支:
- 文本分支输出子任务/问答的logits,用于自回归解码生成高层文本;
- 动作分支由独立的动作专家生成连续动作token,经线性投影转化为流匹配向量场,最终生成连续动作块(动作专家规模远小于骨干网络,兼顾效率)。
2.3、关键细节
- 模型的输入token为混合类型 (离散+连续),输出分支相互独立,且损失仅作用于有效输出token( M + H ≤ N M+H ≤N M+H≤N,M为文本token数,H为动作token数);
- 注意力矩阵通过token类型标识 ρ ( x i ) \rho(x_i) ρ(xi)控制注意力交互,确保不同模态token的合理交互,为后续"离散-连续动作表示融合"的注意力掩码设计奠定基础。
2.4、设计意义
- 首次实现同一模型 完成VLA模型的
高层推理与低层动作生成,解决了双模型分离设计的知识割裂、推理冗余 问题,让预训练的通用知识能同时服务于子任务拆解和动作生成; - 灵活的多模态输入输出设计,让模型能处理机器人动作数据、视觉语言网络数据、人类语言指令数据等异构数据,为后续"多源数据协同训练"提供架构支撑;
- 概率分布的分层分解,让模型具备长时程任务的规划能力,能自主将"清洁厨房"这类全局任务拆解为一系列可执行的子任务,适配真实家庭的复杂操作需求。
3、离散-连续动作表示的融合
3.1、核心目标
解决VLA模型训练效率 与推理效果的核心矛盾:离散动作token训练效率高但推理实时性差,连续流匹配动作表示推理精细、实时性好但训练效率低。
通过混合表示+联合损失,融合二者优势,实现"高效预训练+高质量实时推理"。
3.2、具体实现
-
两种动作表示的分工
- 离散token :用于预训练阶段 ,将连续机器人动作压缩为离散token,采用自回归下一个token预测的方式训练,与大模型训练逻辑一致,实现异构多源数据的高效协同训练;
- 连续流匹配表示 :用于后训练+推理阶段 ,继承π0的流匹配技术,模型预测流匹配向量场,通过逐步去噪生成连续动作块,支持精细的机器人控制与实时推理。
-
流匹配技术的核心原理(继承π0)
给定带噪动作 a t : t + H τ , ω = τ a t : t + H + ( 1 − τ ) ω a_{t: t+H}^{\tau, \omega}=\tau a_{t: t+H}+(1-\tau) \omega at:t+Hτ,ω=τat:t+H+(1−τ)ω( ω ∼ N ( 0 , I ) \omega \sim N(0, I) ω∼N(0,I)为高斯噪声, τ ∈ 0 , 1 \tau \in0,1 τ∈0,1为流匹配时间索引),模型训练目标为预测流匹配向量场 ω − a t \omega-a_{t} ω−at,通过逐步去噪(τ从0到1)生成干净的连续动作。
-
联合损失函数的设计
模型通过联合损失 同时优化离散token预测与连续流匹配预测,解决两种表示的融合问题,损失函数为:(
详细的公式分析请查看第5节)
E D , τ , ω H ( x 1 : M , f θ ℓ ( o t , ℓ ) ) + α ∥ ω − a t : t + H − f θ a ( a t : t + H τ , ω , o t , ℓ ) ∥ 2 \mathbb{E}_{\mathcal{D}, \tau, \omega}\left H\\left(x_{1: M}, f_{\\theta}\^{\\ell}\\left(o_{t}, \\ell\\right)\\right)+\\alpha\\left\\\| \\omega-a_{t: t+H}-f_{\\theta}\^{a}\\left(a_{t: t+H}\^{\\tau, \\omega}, o_{t}, \\ell\\right)\\right\\\| \^{2}\\right ED,τ,ωH(x1:M,fθℓ(ot,ℓ))+α ω−at:t+H−fθa(at:t+Hτ,ω,ot,ℓ) 2其中:
- H ( ⋅ ) H(\cdot) H(⋅)为交叉熵损失,优化文本token(含离散动作token)的自回归预测;
- ∥ ⋅ ∥ 2 \|\cdot\|^2 ∥⋅∥2为均方误差损失,优化流匹配向量场的预测;
- α \alpha α为损失平衡参数 ,预训练阶段 α = 0 \alpha=0 α=0(仅优化离散token),后训练阶段 α = 10.0 \alpha=10.0 α=10.0(联合优化)。
-
注意力掩码的关键设计
通过注意力矩阵掩码 ,让离散动作token与连续流匹配动作token互不关注 ,避免两种表示之间的信息泄漏,确保训练过程中两种表示的独立优化,推理时再实现无缝衔接。
3.3、关键细节
- 预训练阶段仅用离散token,后训练阶段加入流匹配动作专家(随机权重初始化),逐步将离散的通用动作知识转化为连续的精细操作能力;
- 推理时,模型先通过自回归解码 生成高层文本子任务,再基于子任务,通过10步流匹配去噪生成连续动作块,兼顾推理效率与动作精细度。
3.4、设计意义
- 解决了VLA模型的核心技术矛盾(训练效率vs推理效果),是π0.5能实现"280k步大规模预训练+高效实时推理"的关键;
- 离散token的使用让预训练能兼容机器人动作数据、视觉语言数据等异构数据,实现多源数据的统一token化训练;
- 连续流匹配的使用让模型能生成高维、精细的连续动作(18-19DoF),适配移动操作器的复杂控制需求,避免离散token的动作量化误差。
3.5、预训练框架
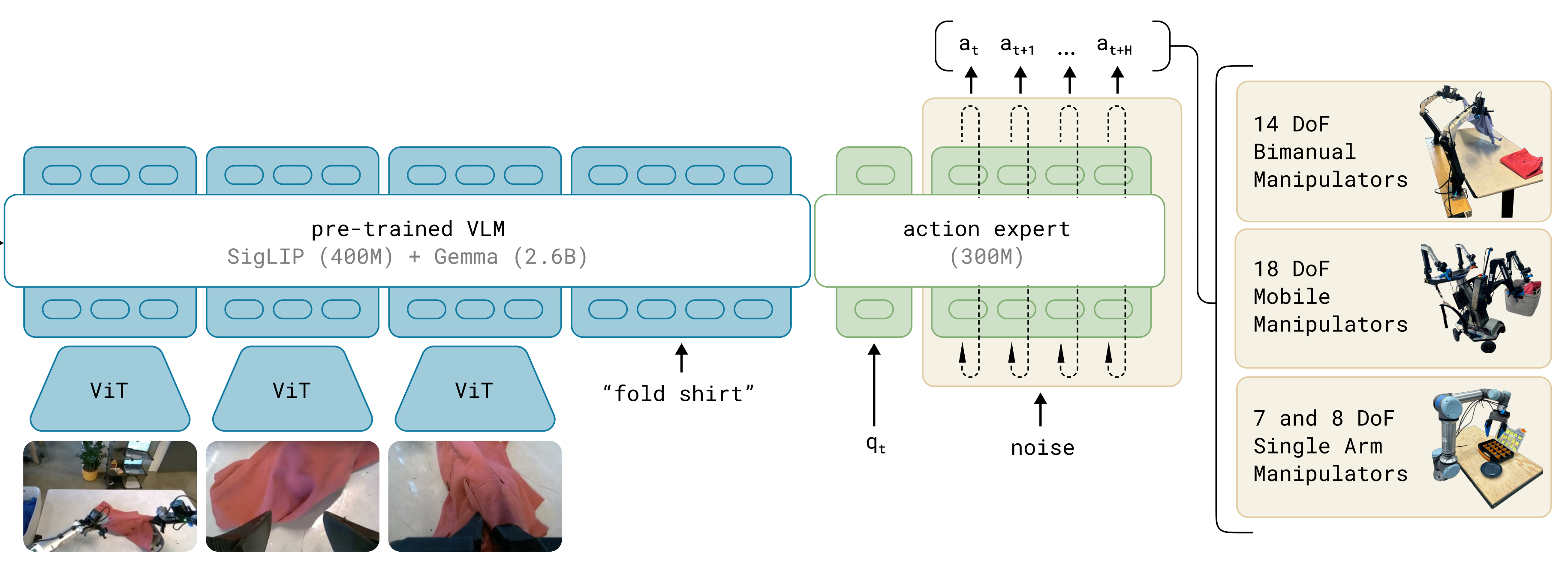
如下图所示,是π0.5预训练阶段 的核心流程,聚焦VLA通用知识的离散化学习
π0.5预训练阶段,思路流程要点如下:
1. 输入组件:多模态数据+任务指引
- 多模态数据源(左侧):提供视觉信息,包含不同来源图像
- 任务特定提示(右侧):提供语言形式的任务指令/请求,包含:高层任务(如"clean the kitchen")、子任务(如"pick up the pillow")、功能请求(如"caption the image""localize the gripper")
2. 核心处理模型
预训练VLM,由下面两部分组成:
- SigLIP(400M):负责处理视觉图像,提取视觉特征
- Gemma(2.6B) :负责处理语言文本,提供语言语义能力
二者组成的视觉-语言骨干架构,实现多模态信息的融合。
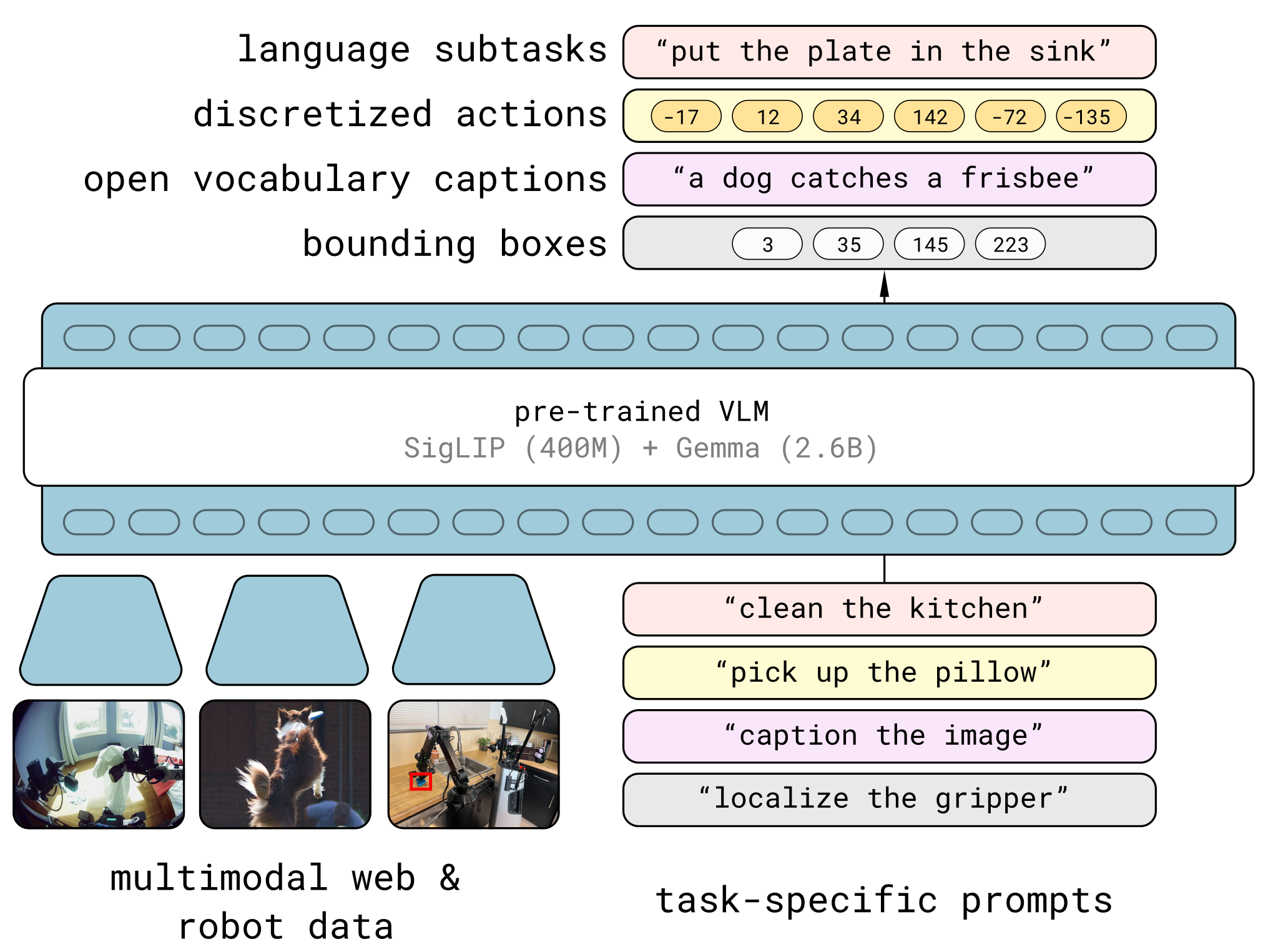
3. 处理逻辑:多模态输入→离散令牌序列学习
模型将"多模态图像 + 任务特定提示"统一转化为离散令牌序列 ,通过自回归下一个令牌预测任务,学习"视觉-语言-动作-目标"之间的关联,实现跨模态通用知识的融合。
4. 输出结果:离散化的多模态知识
生成四类离散化输出,对应预训练学习到的通用能力:
- 语言子任务(如"put the plate in the sink"):任务拆解知识
- 离散动作(如"-17、12"等令牌):机器人基础操作知识
- 开放词汇描述(如"a dog catches a frisbee"):视觉-语言语义知识
- 边界框(如"3、35"等坐标):目标定位知识
4、π0.5架构核心公式分析
π0.5的架构,核心设计目标是打造**单一统一的Transformer架构**,打破传统VLA模型"高层推理与低层动作生成双模型分离"的冗余设计,实现**高层语义子任务预测**和**低层连续动作生成**的一体化推理;
同时通过灵活的多模态处理设计,支撑异构多源数据的训练与开放世界泛化。
- 核心目标 :用一个Transformer模型 同时完成V LA的多模态输入处理 、高层语义子任务的文本推理 、低层机器人连续动作的生成 ,实现三者的知识共享,解决双模型分离的知识割裂、推理冗余 问题,适配清洁厨房/卧室这类长时程复杂任务的规划与执行需求。
4.1、核心公式解析
π0.5架构的核心公式为联合概率分布的分层分解式 ,也是整个架构设计的逻辑起点,先放完整公式:
π θ ( a t : t + H , ℓ ^ ∣ o t , ℓ ) = π θ ( a t : t + H ∣ o t , ℓ ^ ) π θ ( ℓ ^ ∣ o t , ℓ ) \pi_{\theta}\left(a_{t: t+H}, \hat{\ell} | o_{t}, \ell\right)=\pi_{\theta}\left(a_{t: t+H} | o_{t}, \hat{\ell}\right) \pi_{\theta}\left(\hat{\ell} | o_{t}, \ell\right) πθ(at:t+H,ℓ^∣ot,ℓ)=πθ(at:t+H∣ot,ℓ^)πθ(ℓ^∣ot,ℓ)
(一)公式中所有符号的精准释义(结合论文预备知识+架构定义)
先把公式中每个符号的含义讲透,这是理解公式的基础,其中部分基础符号继承自论文预备知识章节,π0.5做了小幅拓展:
| 符号 | 类型 | 具体含义 | 补充说明 |
|---|---|---|---|
| π θ \pi_{\theta} πθ | 模型分布 | 由参数 θ \theta θ表征的π0.5模型的概率分布 | θ \theta θ是模型的所有可训练权重(Transformer骨干+动作专家等) |
| a t : t + H a_{t:t+H} at:t+H | 输出:低层动作 | 模型在 t t t时刻预测的连续动作块 ,涵盖 t t t到 t + H t+H t+H共 H H H步的机器人动作 | 继承预备知识的"动作块"设计,π0.5中 H = 49 H=49 H=49(动作视野50),动作是18-19DoF的连续值(机械臂+底座+躯干) |
| ℓ ^ \hat{\ell} ℓ^ | 输出:高层子任务 | 模型在 t t t时刻预测的高层语义子任务文本(token化表示) | 如全局指令是"清洁厨房", ℓ ^ \hat{\ell} ℓ^可是"拿起盘子""打开橱柜",也可作为视觉语言任务的输出(如图像描述、VQA答案) |
| o t o_{t} ot | 输入:观测 | 模型在 t t t时刻的多模态观测 | 包含4台相机的图像+机器人本体状态(关节角度、夹爪姿态、底座速度等),本体状态被离散化为文本token输入 |
| ℓ \ell ℓ | 输入:全局指令 | 人类给出的高层全局语言任务指令(token化表示) | 如"清洁厨房""把衣服放进洗衣篮",是模型的核心任务指引 |
| $ | $ | 条件概率符号 | 表示"在......条件下"的条件概率 |
(二)公式的分层分解逻辑:从"联合预测"到"先推理、后动作"
公式左侧是模型的联合预测分布 : π θ ( a t : t + H , ℓ ^ ∣ o t , ℓ ) \pi_{\theta}(a_{t:t+H}, \hat{\ell} | o_{t}, \ell) πθ(at:t+H,ℓ^∣ot,ℓ)表示在当前观测 o t o_t ot和全局指令 ℓ \ell ℓ的条件下,模型同时预测出正确动作块 a t : t + H a_{t:t+H} at:t+H和正确高层子任务 ℓ ^ \hat{\ell} ℓ^的概率。
π0.5将这个联合概率 拆解为两个条件概率的乘积 ,这是整个架构分层推理 的核心数学设计,拆解的核心逻辑是:让低层动作的生成,仅依赖模型预测的高层子任务 ℓ ^ \hat{\ell} ℓ^,而非原始的全局指令 ℓ \ell ℓ。
我们把拆解后的两个条件概率单独解读,理解其分工:
-
第一部分: π θ ( ℓ ^ ∣ o t , ℓ ) \boldsymbol{\pi_{\theta}(\hat{\ell} | o_{t}, \ell)} πθ(ℓ^∣ot,ℓ)------高层子任务推理分布
- 含义:在当前观测 o t o_t ot和全局指令 ℓ \ell ℓ的条件下,模型预测出**合理高层子任务 ℓ ^ \hat{\ell} ℓ^**的概率。
- 核心作用:实现**"全局任务拆解",让模型根据当前的场景( o t o_t ot)和最终目标( ℓ \ell ℓ),自主判断下一步该做什么具体子任务,这是长时程复杂任务的规划核心**。
- 推理方式:模型通过自回归解码 生成文本token形式的 ℓ ^ \hat{\ell} ℓ^,属于语言语义推理,依赖模型的视觉-语言知识和任务拆解能力。
-
第二部分: π θ ( a t : t + H ∣ o t , ℓ ^ ) \boldsymbol{\pi_{\theta}(a_{t:t+H} | o_{t}, \hat{\ell})} πθ(at:t+H∣ot,ℓ^)------低层动作生成分布
- 含义:在当前观测 o t o_t ot和模型预测的高层子任务 ℓ ^ \hat{\ell} ℓ^的条件下,模型生成**合理连续动作块 a t : t + H a_{t:t+H} at:t+H**的概率。
- 核心作用:实现**"子任务执行",让模型根据当前场景( o t o_t ot)和具体子任务( ℓ ^ \hat{\ell} ℓ^),生成能完成该子任务的机器人连续动作,这是机器人操作的控制核心**。
- 推理方式:由模型的动作专家 模块生成连续动作token,通过流匹配去噪得到最终动作,属于连续动作控制,依赖模型的机器人操作知识。
4.2、公式的具象化举例:用"清洁厨房"理解推理过程
用论文的核心任务**"清洁厨房"**做具象化举例,让公式的推理逻辑更直观,贴合真实的机器人操作场景:
- 输入:全局指令 ℓ = \ell= ℓ="清洁厨房" ,当前观测 o t = o_t= ot="厨房台面上有盘子,水槽为空,橱柜关闭";
- 第一步:模型计算 π θ ( ℓ ^ ∣ o t , ℓ ) \pi_{\theta}(\hat{\ell} | o_{t}, \ell) πθ(ℓ^∣ot,ℓ),在观测和全局指令下,预测出合理的高层子任务 ℓ ^ = \hat{\ell}= ℓ^="拿起盘子";
- 第二步:模型计算 π θ ( a t : t + H ∣ o t , ℓ ^ ) \pi_{\theta}(a_{t:t+H} | o_{t}, \hat{\ell}) πθ(at:t+H∣ot,ℓ^),在观测和"拿起盘子"的子任务下,生成对应的连续动作块 a t : t + H = a_{t:t+H}= at:t+H="机械臂移动到盘子上方→夹爪闭合→机械臂抬起盘子";
- 完成该子任务后,模型更新观测 o t + H o_{t+H} ot+H,重复上述两步,继续预测下一个子任务(如"把盘子放进水槽")并生成对应动作,直到完成全局指令"清洁厨房"。
核心亮点 :如果直接让模型从全局指令 ℓ = \ell= ℓ="清洁厨房"生成动作,模型无法直接完成长时程规划;而通过公式的分层分解,模型将复杂的全局任务拆解为一系列简单的子任务,逐个执行,大幅降低了推理难度,这也是π0.5能完成10-15分钟长时程任务的关键。
4.3、支撑公式落地的架构核心模块设计
公式定义了"先推理、后动作"的分层逻辑,而π0.5的架构通过多模态输入输出定义 、灵活的Transformer拓展 、双分支输出设计三大模块,将这个数学逻辑落地为实际的模型结构,三个模块均围绕公式的分层推理展开,缺一不可。
(一)模块1:多模态输入输出的统一定义
为了支撑公式的条件概率计算,π0.5对输入 和输出 做了多模态、token化的统一定义,让图像、语言、动作、机器人状态能在同一个Transformer中处理:
- 输入层 :将观测 o t o_t ot (图像+机器人本体状态)和全局指令 ℓ \ell ℓ (语言)全部转化为token序列 ,实现多模态输入的统一:
- 相机图像:通过视觉编码器转化为图像块token(连续值);
- 全局指令 ℓ \ell ℓ:通过词嵌入矩阵转化为文本离散token;
- 机器人本体状态:离散化为文本离散token,融入语言指令的token序列中。
- 输出层 :直接对应公式的两个输出------高层子任务 ℓ ^ \hat{\ell} ℓ^ (文本token)和低层动作块 a t : t + H a_{t:t+H} at:t+H(连续动作token),让模型的输出与公式的预测目标完全一致。
设计意义:统一的token化输入,让模型能在同一个架构中计算公式的条件概率,无需为不同模态设计独立的子模型,实现了知识共享。
(二)模块2:Transformer骨干的灵活拓展
π0.5的Transformer骨干在传统VLA模型的基础上做了三大关键拓展 ,使其能处理多模态token,并适配公式的分层推理,核心是让不同模态的token得到差异化处理,同时实现高效的信息融合:
- 模态专属编码器 :不同类型的输入token由独立的编码器处理,再投影到同一嵌入空间,保证处理的针对性:
- 图像块token→视觉编码器;
- 文本token( ℓ \ell ℓ+本体状态)→词嵌入矩阵;
- 后续推理的连续动作token→线性投影层(继承π0的设计)。
- 模态专属专家权重 :Transformer内部为不同类型的token配备独立的专家权重 ,尤其是动作token由专属的「动作专家」权重处理 :
- 文本token的推理(计算 π θ ( ℓ ^ ∣ o t , ℓ ) \pi_{\theta}(\hat{\ell} | o_{t}, \ell) πθ(ℓ^∣ot,ℓ))由LLM骨干专家权重处理,侧重语义推理;
- 动作token的生成(计算 π θ ( a t : t + H ∣ o t , ℓ ^ ) \pi_{\theta}(a_{t:t+H} | o_{t}, \hat{\ell}) πθ(at:t+H∣ot,ℓ^))由动作专家权重处理,侧重连续动作控制;
- 两者共享Transformer的注意力机制,实现知识互通。
- 灵活的注意力机制 :突破传统LLM的因果注意力 限制,采用**"双向注意力+因果注意力"混合模式**,适配多模态信息融合和分层推理:
- 对图像块token、文本token( ℓ \ell ℓ+本体状态)、连续动作token :采用双向注意力,让token之间能相互交互,充分融合场景观测和任务指令的信息,为高层子任务推理提供支撑;
- 对离散动作token(预训练阶段) :保留因果注意力,保证自回归预测的合理性。
设计意义:Transformer的三大拓展,让模型能高效处理多模态输入,同时为公式的两个条件概率计算分配了专属的处理权重,实现"推理"与"动作"的分工协作,又不割裂知识。
(三)模块3:双分支输出设计
模型的Transformer骨干输出端,直接对应公式的两个预测目标,设计了文本token输出分支 和动作输出分支 ,实现高层推理 与低层动作生成的物理分离、逻辑联动:
- 文本token输出分支 :
- 输出:高层子任务/视觉语言任务的文本tokenlogits;
- 推理:通过自回归解码 生成离散的文本token序列,即高层子任务 ℓ ^ \hat{\ell} ℓ^;
- 核心作用:完成公式中的高层子任务推理,为动作生成提供具体的任务指引。
- 动作输出分支 :
- 核心组件:独立的动作专家模块(继承π0设计,规模远小于Transformer骨干);
- 输入:当前观测 o t o_t ot的嵌入+高层子任务 ℓ ^ \hat{\ell} ℓ^的文本嵌入;
- 输出:流匹配向量场 ,通过10步去噪生成连续的动作块 a t : t + H a_{t:t+H} at:t+H;
- 核心作用:完成公式中的低层动作生成 ,仅以 ℓ ^ \hat{\ell} ℓ^为任务指引,不直接依赖原始全局指令 ℓ \ell ℓ,严格遵循公式的分层逻辑。
关键细节 :两个输出分支的损失仅作用于各自的有效token( M + H ≤ N M+H ≤N M+H≤N, M M M为文本token数, H H H为动作token数),避免了不同任务的损失相互干扰,保证模型训练的稳定性。
4.4、π0.5架构设计的核心优势(对比传统VLA模型)
π0.5的单一统一架构+公式的分层分解,相比传统VLA模型的双模型分离设计(一个模型做高层推理,一个模型做低层动作),具备三大核心优势,也是其能实现开放世界泛化和长时程任务的关键:
- 知识共享,泛化能力更强:所有的视觉-语言-动作知识都存储在同一个Transformer模型中,高层子任务推理的语义知识能直接为低层动作生成提供支撑(如识别"盘子"的语义知识,能指导机械臂精准抓取盘子),避免了双模型的知识割裂,大幅提升模型的开放世界泛化能力。
- 推理高效,适配长时程任务:公式的分层分解让模型将复杂的全局任务拆解为简单的子任务,逐个执行,降低了单步推理的难度;同时单一模型的推理无需跨模型传递信息,推理效率远高于双模型设计,能支撑10-15分钟的长时程连续操作。
- 架构简洁,训练效率更高 :单一Transformer架构仅需训练一套参数 θ \theta θ,无需训练两个独立的模型,大幅降低了训练的计算成本;同时多模态数据能在同一个架构中做协同训练,让模型从异构多源数据中高效学习通用知识。
5、离散-连续动作表示融合(公式详细分析)
5.1、核心设计目标
VLA模型在机器人控制中,动作表示始终存在难以调和的核心矛盾,而π0.5的离散-连续融合设计正是为了解决这一矛盾:
- 离散动作token(如FAST) :将高维连续机器人动作压缩为离散token,可直接沿用大模型自回归下一个token预测 的训练方式,训练效率极高 ,适合大规模异构数据的预训练,但推理时需昂贵的自回归解码,实时性差 ,且动作存在量化误差,难以实现精细的机器人控制;
- 连续动作表示(流匹配/扩散) :直接对机器人的连续动作分布建模,能生成高维、精细的连续动作 ,推理时无需自回归解码,实时性好 ,适配机器人硬件控制,但训练效率低,无法支撑大规模异构数据的预训练。
5.2、流匹配连续动作表示的基础公式(带噪动作构造)
π0.5的连续动作表示完全继承自π0的流匹配(Flow Matching)技术,而联合损失函数的核心是优化流匹配的向量场预测 ,因此理解带噪动作的构造公式是理解核心损失公式的前提(这是流匹配的基础,论文中也先给出了该公式)。
1. 带噪动作构造公式
a t : t + H τ , ω = τ ⋅ a t : t + H + ( 1 − τ ) ⋅ ω a_{t: t+H}^{\tau, \omega}=\tau \cdot a_{t: t+H}+(1-\tau) \cdot \omega at:t+Hτ,ω=τ⋅at:t+H+(1−τ)⋅ω
该公式的作用是为原始干净的连续动作块添加高斯噪声,构造带噪动作,流匹配的核心是让模型学习"从带噪动作逐步去噪还原为干净动作"的向量场,而非直接预测干净动作。
2. 公式逐符号精准释义
| 符号 | 类型 | 具体含义 | 补充说明 |
|---|---|---|---|
| a t : t + H τ , ω a_{t:t+H}^{\tau, \omega} at:t+Hτ,ω | 连续动作(带噪) | t t t时刻的带噪连续动作块 ,涵盖 t t t到 t + H t+H t+H共 H H H步动作 | π0.5中 H = 49 H=49 H=49(动作视野50),动作是18-19DoF的连续值(机械臂+底座+躯干) |
| τ \tau τ | 标量(流匹配时间索引) | 流匹配的去噪时间步 ,取值范围 τ ∈ 0 , 1 \tau \in 0,1 τ∈0,1 | τ = 0 \tau=0 τ=0时,带噪动作完全是噪声; τ = 1 \tau=1 τ=1时,带噪动作就是原始干净动作 |
| a t : t + H a_{t:t+H} at:t+H | 连续动作(干净) | 机器人专家演示的原始干净连续动作块(模型的目标输出) | 来自机器人实采数据,是流匹配去噪的最终目标 |
| ω \omega ω | 随机变量(高斯噪声) | 服从标准正态分布的高斯噪声, ω ∼ N ( 0 , I ) \omega \sim \mathcal{N}(0, I) ω∼N(0,I) | I I I为单位矩阵,噪声维度与干净动作块 a t : t + H a_{t:t+H} at:t+H完全一致 |
3. 公式核心逻辑
流匹配的去噪过程是 τ \tau τ从0逐步增加到1 的过程:
-
当 τ = 0 \tau=0 τ=0时, a t : t + H 0 , ω = ω a_{t:t+H}^{0, \omega}=\omega at:t+H0,ω=ω,动作完全是噪声;
-
随着 τ \tau τ增大,噪声的权重 ( 1 − τ ) (1-\tau) (1−τ)降低,干净动作的权重 τ \tau τ升高;
-
当 τ = 1 \tau=1 τ=1时, a t : t + H 1 , ω = a t : t + H a_{t:t+H}^{1, \omega}=a_{t:t+H} at:t+H1,ω=at:t+H,带噪动作还原为干净动作。
模型的核心训练目标 并非直接预测干净动作,而是预测流匹配的向量场 ω − a t : t + H \omega - a_{t:t+H} ω−at:t+H ------即让模型学习"带噪动作需要朝着哪个方向、以多大的幅度调整,才能逐步还原为干净动作",这是流匹配的核心思想,也是后续联合损失函数中均方误差项的优化目标。
5.3、核心重点:联合损失函数解析
π0.5通过单一联合损失函数 同时优化离散token的自回归预测 和连续流匹配的向量场预测 ,实现离散-连续动作表示的融合训练;该函数也是π0.5预训练 和后训练 阶段损失函数切换的核心依据 (通过调节参数 α \alpha α实现)。
1. 联合损失函数完整公式
E D , τ , ω H ( x 1 : M , f θ ℓ ( o t , ℓ ) ) + α ∥ ω − a t : t + H − f θ a ( a t : t + H τ , ω , o t , ℓ ) ∥ 2 \mathbb{E}_{\mathcal{D}, \tau, \omega}\left H\\left(x_{1: M}, f_{\\theta}\^{\\ell}\\left(o_{t}, \\ell\\right)\\right)+\\alpha\\left\\\| \\omega-a_{t: t+H}-f_{\\theta}\^{a}\\left(a_{t: t+H}\^{\\tau, \\omega}, o_{t}, \\ell\\right)\\right\\\| \^{2}\\right ED,τ,ωH(x1:M,fθℓ(ot,ℓ))+α ω−at:t+H−fθa(at:t+Hτ,ω,ot,ℓ) 2
该公式的核心是两个损失项的加权和 :第一项是交叉熵损失 ,优化离散token(文本/动作token)的预测;第二项是L2均方误差损失 ,优化流匹配向量场的预测;通过期望 E \mathbb{E} E对数据集、流匹配时间步、高斯噪声做整体期望,保证训练的鲁棒性。
2. 公式逐符号/逐部分精准解析
为了清晰理解,我们将公式拆分为期望部分 、交叉熵损失项 、均方误差损失项 、权重参数四部分分别解析,同时结合论文上下文说明各部分的落地意义:
(1)期望部分: E D , τ , ω ⋅ \mathbb{E}_{\mathcal{D}, \tau, \omega}\\cdot ED,τ,ω⋅
- E \mathbb{E} E:数学期望,代表对括号内的损失项在所有采样维度上取平均值,让损失更稳定,避免单样本/单采样的随机性;
- 下标 D , τ , ω \mathcal{D}, \tau, \omega D,τ,ω:期望的采样维度,即对训练数据集 D \mathcal{D} D 、流匹配时间步 τ \tau τ 、**高斯噪声 ω \omega ω**三个维度做联合采样并计算损失均值;
- D \mathcal{D} D:π0.5的训练数据集(预训练为异构多源数据,后训练为聚焦移动操作的高质量数据);
- τ \tau τ:流匹配时间索引,论文中采用Beta分布采样(而非均匀采样),侧重低时间步的学习,提升去噪效率;
- ω \omega ω:标准高斯噪声,每次训练都随机采样,让模型学习对不同噪声的去噪能力。
(2)第一损失项:交叉熵损失 H ( x 1 : M , f θ ℓ ( o t , ℓ ) ) H\left(x_{1: M}, f_{\theta}^{\ell}\left(o_{t}, \ell\right)\right) H(x1:M,fθℓ(ot,ℓ))
核心作用 :优化离散token的自回归预测 ,包括离散动作token 和文本token (如高层子任务、图像描述),是预训练阶段的唯一损失项。
- H ( ⋅ , ⋅ ) H(\cdot, \cdot) H(⋅,⋅):交叉熵损失(Cross-Entropy Loss),分类任务的经典损失,用于衡量模型预测的离散token分布 与真实的离散token分布之间的差异,差异越小,模型预测越准确;
- x 1 : M x_{1:M} x1:M:真实的离散token序列 ,长度为 M M M,包括离散动作token、高层子任务文本token、目标定位边界框token等;
- f θ ℓ ( o t , ℓ ) f_{\theta}^{\ell}\left(o_{t}, \ell\right) fθℓ(ot,ℓ):模型基于当前观测 o t o_t ot和** 全局语言指令 ℓ \ell ℓ** ,预测的离散tokenlogits (未经过softmax的概率得分);
- θ \theta θ:π0.5模型的所有可训练权重;
- 上标 ℓ \ell ℓ:代表语言/离散token分支(language/logits),与动作专家分支做区分。
(3)第二损失项:L2均方误差 α ∥ ω − a t : t + H − f θ a ( a t : t + H τ , ω , o t , ℓ ) ∥ 2 \alpha\left\| \omega-a_{t: t+H}-f_{\theta}^{a}\left(a_{t: t+H}^{\tau, \omega}, o_{t}, \ell\right)\right\| ^{2} α ω−at:t+H−fθa(at:t+Hτ,ω,ot,ℓ) 2
核心作用 :优化流匹配向量场的预测,训练模型学习从带噪动作还原为干净动作的"调整方向和幅度",是后训练阶段新增的损失项,用于学习连续动作表示。
- ∥ ⋅ ∥ 2 \|\cdot\|^2 ∥⋅∥2:L2范数的平方,即均方误差(MSE) ,用于衡量模型预测的向量场 与真实的向量场之间的连续值差异;
- ω − a t : t + H \omega - a_{t:t+H} ω−at:t+H:真实的流匹配向量场,即带噪动作需要朝着该方向调整,才能逐步还原为干净动作(流匹配的核心目标);
- f θ a ( a t : t + H τ , ω , o t , ℓ ) f_{\theta}^{a}\left(a_{t: t+H}^{\tau, \omega}, o_{t}, \ell\right) fθa(at:t+Hτ,ω,ot,ℓ):模型基于带噪动作 a t : t + H τ , ω a_{t:t+H}^{\tau, \omega} at:t+Hτ,ω 、当前观测 o t o_t ot 、全局语言指令 ℓ \ell ℓ ,预测的流匹配向量场 ;
- 上标 a a a:代表动作专家分支(action expert),是π0.5中专门处理连续动作的独立模块,规模远小于Transformer骨干;
- a t : t + H τ , ω a_{t:t+H}^{\tau, \omega} at:t+Hτ,ω:前文解析的带噪动作块,是动作专家分支的核心输入之一(模型基于带噪动作预测去噪的向量场)。
(4)权重参数: α ∈ R \alpha \in \mathbb{R} α∈R
核心作用 :调节交叉熵损失 和均方误差损失 的相对权重 ,是实现π0.5预训练 和后训练 损失切换的关键参数,论文中明确给出了两个阶段的取值:
- 预训练阶段 : α = 0 \alpha=0 α=0,此时均方误差项完全失效,损失函数仅保留交叉熵损失,模型仅优化离散token的预测(动作token+文本token),实现高效的大规模预训练;
- 后训练阶段 : α = 10.0 \alpha=10.0 α=10.0,此时两个损失项同时生效,模型联合优化离散token预测和连续流匹配向量场预测,实现从离散动作表示到连续动作表示的过渡。
3. 损失函数的核心逻辑
该联合损失函数的设计遵循**"主次分明、阶段化切换"**的原则:
- 预训练阶段以离散token预测 为主( α = 0 \alpha=0 α=0),充分发挥离散表示的训练效率优势,让模型从异构多源数据中学习通用的视觉-语言-动作知识;
- 后训练阶段加入流匹配向量场预测 ( α = 10.0 \alpha=10.0 α=10.0),在保留离散token预测能力(避免语义/任务知识遗忘)的同时,让模型学习精细的连续动作表示,适配机器人硬件控制;
- 两个损失项分别对应模型的离散token分支 和连续动作专家分支,相互独立又加权融合,实现离散-连续动作表示的无缝衔接。
5.4、离散-连续动作表示的阶段化分工(训练+推理)
π0.5的离散-连续融合并非简单的"同时训练",而是基于预训练/后训练/推理的阶段化分工 ,让两种表示在不同阶段发挥各自的优势,这也是联合损失函数通过 α \alpha α调节的核心落地场景,具体分工如下:
1. 预训练阶段:仅用离散动作token
- 损失设置: α = 0 \alpha=0 α=0,联合损失仅保留交叉熵损失;
- 动作表示:将所有机器人的连续动作通过FAST token化算法 压缩为离散token,与文本token、图像块token统一为离散token序列;
- 训练方式:沿用大模型的自回归下一个token预测,训练模型学习异构多源数据的通用知识;
- 核心目标:高效学习,无需考虑实时推理,重点积累视觉-语言-动作的通用知识。
2. 后训练阶段:离散+连续联合优化
- 损失设置: α = 10.0 \alpha=10.0 α=10.0,联合损失同时优化交叉熵(离散)和均方误差(连续);
- 动作表示:新增流匹配连续动作表示,动作专家模块随机权重初始化,逐步学习向量场预测;同时保留FAST离散token,避免预训练知识遗忘;
- 训练方式:对高质量的移动操作数据做精细训练,聚焦机器人实际控制的连续动作学习;
- 核心目标:将预训练的通用离散知识,转化为适配机器人硬件的连续动作控制能力。
3. 推理阶段:仅用连续流匹配动作表示
- 动作表示:完全舍弃离散token,模型基于流匹配做连续动作生成;
- 推理流程:
- 模型先通过自回归解码生成高层语义子任务 ℓ ^ \hat{\ell} ℓ^(如"拿起盘子");
- 基于子任务 ℓ ^ \hat{\ell} ℓ^、当前观测 o t o_t ot,动作专家模块对带噪动作做10步流匹配去噪(论文设定),逐步还原为干净的连续动作块;
- 以50Hz的频率输出连续动作,直接控制机器人硬件(机械臂、底座、躯干);
- 核心目标:实现精细、实时的端到端机器人控制,适配真实家庭环境的操作需求。
5.5、关键支撑设计:注意力掩码(避免信息泄漏)
为了让离散-连续动作表示的融合训练更稳定,π0.5在Transformer的注意力机制 中设计了专门的注意力掩码,这是论文中提到的关键细节,也是联合损失函数能有效优化的重要保障:
通过注意力矩阵 A ( x 1 : N ) A(x_{1:N}) A(x1:N)严格限制:离散动作token与连续流匹配动作token****互不关注 (即注意力权重为0),避免两种动作表示之间的信息泄漏。
设计原因:
如果两种表示相互关注,模型会在训练中"走捷径"------比如从离散token中直接推导连续动作,而非真正学习流匹配的向量场预测,导致连续动作表示的学习失效,无法实现精细的机器人控制。
效果:
让离散和连续动作表示在同一模型中独立学习、互不干扰 ,同时通过联合损失函数实现优势融合,既保留了预训练的通用知识,又学到了高质量的连续动作控制能力。
5.6、具象化举例:以「拿起盘子」为例理解公式与设计落地
用π0.5的核心任务**"拿起盘子"**做具象化举例,让抽象的公式和设计落地为具体的机器人操作过程,更易理解:
-
预训练阶段 : α = 0 \alpha=0 α=0,损失仅为 H ( x 1 : M , f θ ℓ ( o t , ℓ ) ) H(x_{1:M}, f_{\theta}^{\ell}(o_t, \ell)) H(x1:M,fθℓ(ot,ℓ))
- 真实离散token x 1 : M x_{1:M} x1:M:token化后的"拿起盘子"离散动作序列+"拿起盘子"文本token;
- 模型输入 o t o_t ot:相机拍摄的"台面上有盘子"的图像+全局指令 ℓ \ell ℓ="清洁厨房";
- 模型预测: f θ ℓ ( o t , ℓ ) f_{\theta}^{\ell}(o_t, \ell) fθℓ(ot,ℓ)输出离散tokenlogits,交叉熵损失优化模型让预测token与真实token一致,模型学习"看到盘子+清洁厨房指令→生成拿起盘子的离散token"的通用知识。
-
后训练阶段 : α = 10.0 \alpha=10.0 α=10.0,损失为交叉熵+均方误差
- 离散部分:与预训练一致,优化"拿起盘子"的离散token预测,避免知识遗忘;
- 连续部分:损失为 10 × ∥ ω − a t : t + H − f θ a ( a t : t + H τ , ω , o t , ℓ ) ∥ 2 10 \times \|\omega - a_{t:t+H} - f_{\theta}^{a}(a_{t:t+H}^{\tau, \omega}, o_t, \ell)\|^2 10×∥ω−at:t+H−fθa(at:t+Hτ,ω,ot,ℓ)∥2
- 真实向量场: ω − a t : t + H \omega - a_{t:t+H} ω−at:t+H(带噪动作还原为"拿起盘子"干净连续动作的调整方向);
- 模型输入:带噪动作 a t : t + H τ , ω a_{t:t+H}^{\tau, \omega} at:t+Hτ,ω+"台面上有盘子"的观测 o t o_t ot+"清洁厨房"的指令 ℓ \ell ℓ;
- 模型预测: f θ a ( ⋅ ) f_{\theta}^{a}(\cdot) fθa(⋅)输出预测的向量场,均方误差损失优化模型让预测向量场与真实向量场一致,模型学习"带噪动作→朝着正确方向调整→生成拿起盘子的连续动作"的控制能力。
-
推理阶段:
- 模型先预测高层子任务 ℓ ^ \hat{\ell} ℓ^="拿起盘子";
- 动作专家模块采样高斯噪声 ω \omega ω,构造带噪动作 a t : t + H 0 , ω = ω a_{t:t+H}^{0, \omega}=\omega at:t+H0,ω=ω( τ = 0 \tau=0 τ=0);
- 经过10步流匹配去噪( τ \tau τ从0逐步到1),模型逐步预测向量场并调整带噪动作,最终还原为干净的连续动作块 a t : t + H a_{t:t+H} at:t+H(如"机械臂移动到盘子上方→夹爪闭合→机械臂抬起");
- 以50Hz的频率输出连续动作,直接控制机器人完成"拿起盘子"的操作。
下面这张图展示了π0.5 预训练与后训练阶段的异构多源数据体系,清晰呈现了模型训练所用的各类数据类型及对应的任务场景。

这张图展示了π0.5预训练与后训练阶段的异构多源数据体系,清晰呈现了模型训练所用的各类数据类型及对应的任务场景,核心内容如下:
预训练阶段(Pre-training)数据源
图中左侧至中间模块为预训练数据,覆盖跨机器人形态、跨场景、跨任务类型的异构数据:
- Laboratory cross-embodiment(实验室跨体数据):实验室环境下不同形态机器人(单/双臂、静/动底座)完成的任务(如Sort drawer、Fold laundry),含Open X-Embodiment开源数据,提供通用操作原语。
- Diverse mobile manipulator(多样化移动操作器数据):移动操作器在家庭场景完成的日常任务(如Shirt in basket、Make bed),是锚定家庭任务的核心数据(对应MM数据)。
- Diverse non-mobile manipulator(多样化非移动操作器数据):非移动机械臂完成的室内/家庭任务(如Item in drawer、Fold linen),补充跨环境的操作经验(对应ME数据)。
- High-level subtask(高层子任务数据):含家庭场景图像、任务问题、目标边界框标注、子任务文本(如move to closet),是人工标注的任务拆解与目标定位数据(对应HL数据)。
- Multi-modal web data(多模态网络数据):网络图像的描述、问答数据(如描述大象前腿、识别派的类型),补充通用视觉-语言语义知识(对应WD数据)。
后训练阶段(Post-training)
图中右侧 Verbal instruction(口头指令数据) 为后训练新增数据:展示人类通过口头指令远程控制机器人的场景(如Put cup in sink),含任务策略的重标注,用于提升模型子任务推理与人类意图的对齐度(对应VI数据)。
π0.5"预训练学通用(多源异构数据)、后训练做特化(人类口头指令数据)"的训练数据体系,覆盖实验室/家庭场景、移动/非移动机器人、标注/网络数据等类型,支撑模型的开放世界泛化与长时程任务能力。
6、模型效果
如下图所示,展示3个完全未参与训练的真实家庭(Home 1-3)中,π0.5 的任务执行过程:
-
每个家庭对应人类给出的高层指令(如 "把物品放进抽屉""把餐具放进水槽");
-
π0.5 自主预测高层子任务(HL prediction),并执行对应的机器人操作步骤(如 "拉开抽屉→拿起工具→放入抽屉""拿起盘子→放进水槽");

如下图所示,在模拟家庭测试环境中,π0.5的表现同时优于 π₀ 与 π₀-FAST+Flow
其中,π₀-FAST+Flow(π₀ 的一个变体版本,结合了离散动作令牌与流匹配动作表示)
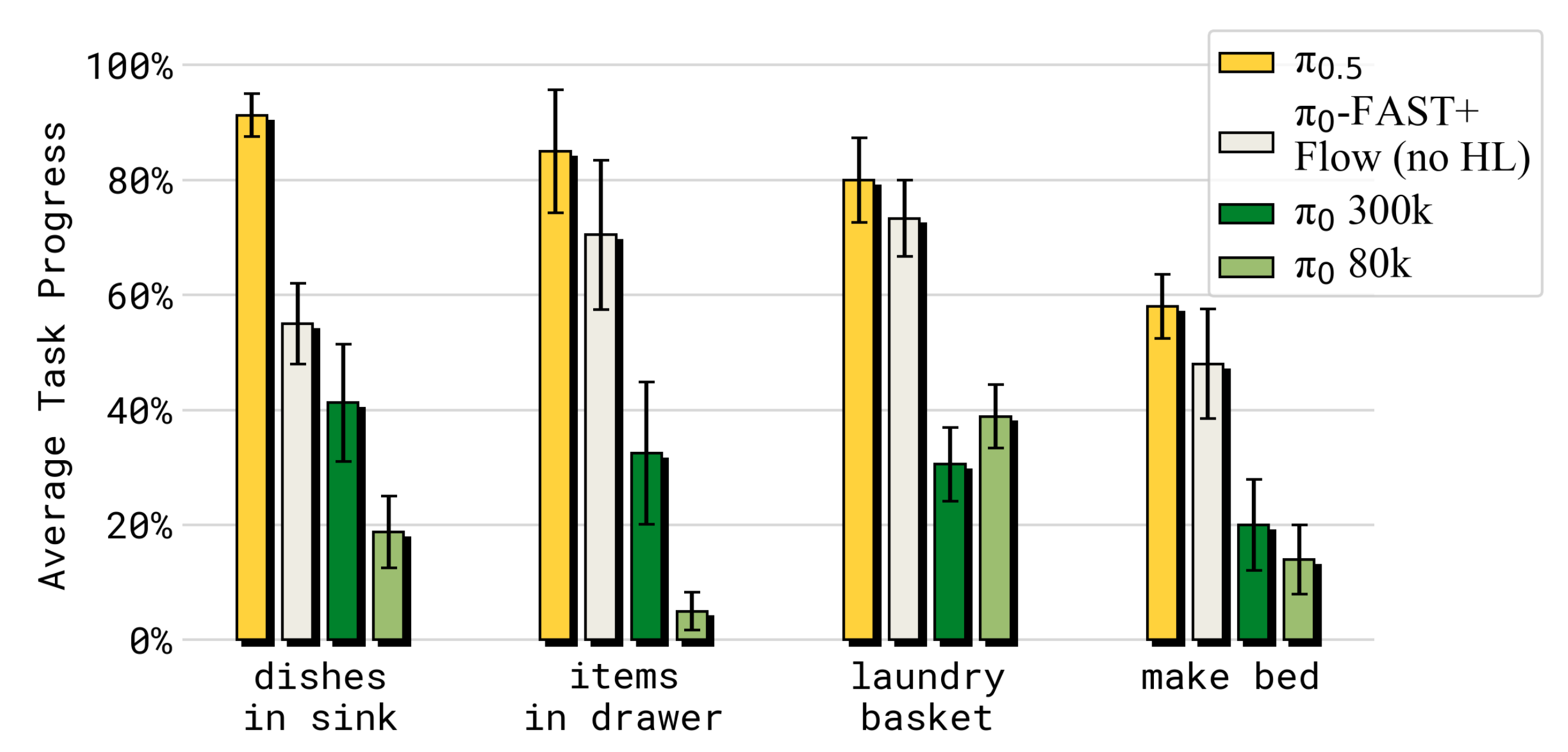
分享完成~