本文分享使用 RLinf 框架对 π₀ 和π₀.₅ 进行强化学习微调。
支持PPO和GRPO等强化学习算法。
示例覆盖从环境输入、核心算法、训练脚本配置到评估与可视化的完整流程,并提供可复现的命令和配置片段。
RLinf开源地址:https://github.com/RLinf/RLinf
1、基础准备
从LIBERO仿真环境获取数据,数据结构为:
- Images :包含主视角图像和腕部视角图像,均为RGB 张量
[batch_size, 224,224, 3] - States:在LIBERO当中是末端执行器的位姿(位置 + 姿态)以及夹爪状态;在ManiSkill3当中是机器人关节角度
- Task Descriptions:自然语言指令
- Rewards:任务成功/失败的稀疏奖励
本文的强化微调,使用两种最常用的强化学习算法:
PPO(Proximal Policy Optimization)
- 使用 GAE(Generalized Advantage Estimation)进行优势估计
- 基于比率的策略裁剪
- 价值函数裁剪
- 熵正则化
GRPO(Group Relative Policy Optimization)
- 对于每个状态/提示,策略生成 G 个独立动作
- 以组内平均奖励为基线,计算每个动作的相对优势
2、环境搭建
1. 下载 RLinf 代码
bash
git clone https://github.com/RLinf/RLinf.git
cd RLinf2. 安装依赖
使用 Docker 镜像运行,支持国内加速镜像:
bash
docker run -it --rm --gpus all \
--shm-size 20g \
--network host \
--name rlinf \
-v .:/workspace/RLinf \
docker.1ms.run/rlinf/rlinf:agentic-rlinf0.1-maniskill_libero通过镜像内置的 switch_env 工具,切换到对应的虚拟环境:
bash
source switch_env openpi3、模型下载
开始训练前需下载对应预训练模型,以下为LIBERO 环境 Spatial、Object、Goal 类型任务的下载方式,其他环境模型下载方式可参考官方指引。
3.1、下载方式
方式1:git clone
bash
git lfs install
git clone https://huggingface.co/RLinf/RLinf-Pi0-LIBERO-Spatial-Object-Goal-SFT方式2:huggingface-hub
bash
# 先安装 huggingface-hub
pip install huggingface-hub
# 在使用huggingface-hub下载,但需要科学上网
hf download RLinf/RLinf-Pi0-LIBERO-Spatial-Object-Goal-SFT --local-dir RLinf-Pi0-LIBERO-Spatial-Object-Goal-SFT方式3:ModelScope(推荐,速度快速)
直接从ModelScope下载:https://www.modelscope.cn/models/RLinf/RLinf-Pi0-SFT-Spatial-Object-Goal
当前提供了5个模型:
3.2、预训练模型列表
下载完成后,需在配置文件中正确指定模型路径。
π0 模型列表
| 环境 | 任务说明 | SFT Model | Flow-SDE | Flow-Noise |
|---|---|---|---|---|
| LIBERO | Spatial, Object, Goal | huggingface SFT Model | - | - |
| LIBERO | Long | huggingface SFT Model | - | - |
| ManiSkill3 | 多任务 | huggingface 38.4% | huggingface 78.8% | huggingface 77.8% |
| MetaWorld | MT50 | huggingface 50.8% | huggingface 78.1% | huggingface 85.8% |
| CALVIN | ABC-D | huggingface 57.5% | huggingface 61.7% | huggingface 59.9% |
π0.5 模型列表
| 环境 | 任务说明 | SFT Model | Flow-SDE | Flow-Noise |
|---|---|---|---|---|
| LIBERO | Spatial, Object, Goal, Long | huggingface SFT Model | - | - |
| ManiSkill3 | 多任务 | huggingface 40.1% | huggingface 90.9% | huggingface 89.7% |
| MetaWorld | MT50 | huggingface 43.8% | huggingface 70.7% | huggingface 66.1% |
| CALVIN | ABC-D | huggingface 61.3% | huggingface 87.0% | huggingface 84.5% |
4、修改配置参数
相关的配置文件在:RLinf/examples/embodiment/config 目录下
以libero-10为例,π₀和π₀.₅对应不同算法的配置文件路径:
- π₀+ PPO:
examples/embodiment/config/libero_10_ppo_openpi.yaml - π₀+ GRPO:
examples/embodiment/config/libero_10_grpo_openpi.yaml - π₀.₅+ PPO:
examples/embodiment/config/libero_10_ppo_openpi_pi05.yaml - π₀.₅+ GRPO:
examples/embodiment/config/libero_10_grpo_openpi_pi05.yaml
4.1、运行关键参数配置
可灵活配置env、rollout、actor三个组件的GPU使用方式,核心参数为component_placement和pipeline_stage_num。
方式1:分块使用GPU(流水线重叠)
yaml
cluster:
num_nodes: 1
component_placement:
env: 0-3
rollout : 4-7
actor: 0-7
rollout:
pipeline_stage_num: 2 # 实现rollout与env流水线重叠,提升效率方式2:完全共享GPU
yaml
cluster:
num_nodes: 1
component_placement:
env,rollout,actor : all方式3:完全分离GPU(无需offload)
yaml
cluster:
num_nodes: 1
component_placement:
env: 0-1
rollout : 2-5
actor: 6-74.2、模型关键参数配置
1 基础模型参数
yaml
openpi:
noise_level : 0.5 # flow_sde 的默认噪声强度
noise_logvar_range : [0.08, 0.16] # flow_noise 的默认可学习噪声范围
action_chunk : ${actor.model.num_action_chunks}
num_steps : ${actor.model.num_steps} # 设置流匹配步数
train_expert_only : True
action_env_dim : ${actor.model.action_dim}
noise_method : "flow_sde" # 可选flow_sde/flow_noise,指定加噪方式
add_value_head : False
pi05 : False # 设置为True时启用π0.5模型
value_after_vlm: False # 控制critic位置,True接VLM输出,False接action expert输出2 算法配置
支持flow-sde和flow-noise两种微调方案,核心参数差异如下,完整配置可参考对应yaml文件:
- flow-sde:参考
libero_spatial_ppo_openpi.yaml - flow-noise:参考
maniskill_ppo_openpi.yaml
yaml
algorithm:
entropy_bonus: 0.0 # flow-sde设为0.0,flow-noise设为0.005
openpi:
noise_method : "flow_sde" # [flow_sde,flow_noise] 噪声注入方式
noise_level : 0.5 # flow-sde 的噪声强度
noise_logvar_range : [0.08, 0.16] # flow-noise 的可学习噪声范围
joint_logprob : False # flow-sde设为False,flow-noise设为True噪声注入方式说明:
- flow-sde:通过ode-sde转换引入噪声
- flow-noise:引入噪声网络注入噪声
3 LoRA设置
对VLM部分进行参数高效微调时启用,当前不支持梯度检查点:
yaml
model:
is_lora : True # 启用LoRA
lora_rank : 8 # LoRA秩数
gradient_checkpointing : False # 必须保持False⭐ 4 最小测试案例 ⭐
针对OOM报错或低资源场景,可参考libero_spatial_ppo_openpi_quickstart.yaml,相比标准配置的核心修改:
| 配置项 | 标准值 | 测试值 |
|---|---|---|
| rollout_epoch | 8 | 2 |
| total_num_envs | 64 | 32 |
| micro_batch_size | 128 | 64 |
| global_batch_size | 2048 | 256 |
| lr | 5e-6 | 1e-6 |
| actor.enable_offload | False | True |
| rollout.enable_offload | False | True |
性能说明:4张H100 GPU上,相同时间内标准参数与测试参数性能基本持平,测试参数单轮优化更快,但收敛速度更慢。
OOM问题额外解决方案
-
rollout阶段OOM
- 渲染引擎从
egl替换为osmesa total_num_envs从32减为16,同时rollout_epoch从2增为4(保证每轮rollout环境总数一致)- 检查并开启
actor.enable_offload=True
- 渲染引擎从
-
actor阶段OOM
micro_batch_size从64减为32,保持global_batch_size=256不变- 检查并开启
rollout.enable_offload=True
备注 :需保证global_batch_size是micro_batch_size × GPU数量的整数倍,避免批次不匹配。
5 模型评估
提供两种评估方式,适用于不同场景需求:
- RLinf统一评估脚本 :参考VLA评估文档,支持并行环境评估 ,速度快,仅输出整体任务成功率。 备注:Metaworld 暂时不支持
env.eval.auto_reset=True,不建议使用此方式。 - 单个脚本文件评估 :参考示例README.md,与openpi官方评估脚本一致,支持输出每个子任务成功率,速度较慢。
6. 视频生成
开启训练过程视频保存,配置如下:
yaml
video_cfg:
save_video: True
info_on_video : True
video_base_dir : ${runner.logger.log_path}/video/train7. WandB 集成
支持将日志同步至WandB,配置如下:
yaml
runner:
task_type : embodied
logger :
log_path: "../results"
project_name : rlinf
experiment_name: "libero_10_ppo_openpi"
logger_backends: ["tensorboard"] # 可选:tensorboard, wandb, swanlab5、基于 PPO 实现 π0 强化微调
选择一个模型权重,比如是:RLinf-Pi0-LIBERO-Spatial-Object-Goal-SFT
配置文件是:libero_spatial_ppo_openpi_quickstart.yaml
先修改配置文件的model_path,替换为真实权重路径,比如:"/guopu/RLinf_project/RLinf-Pi0-LIBERO-Spatial-Object-Goal-SFT"
通过以下命令启动训练:
bash
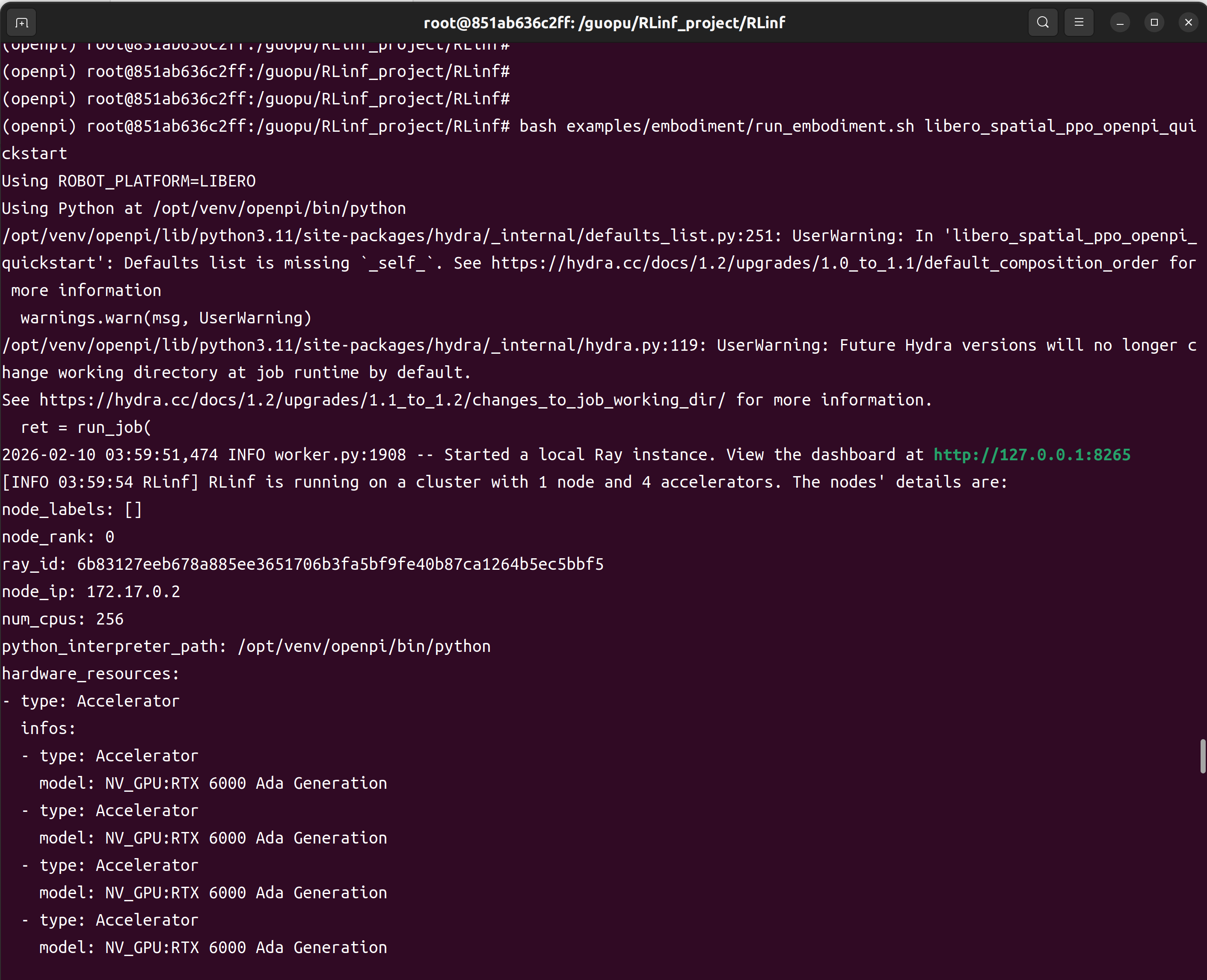
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_openpi_quickstart显卡资源:A6000 48G * 4张
开始执行命令时,如下图所示:
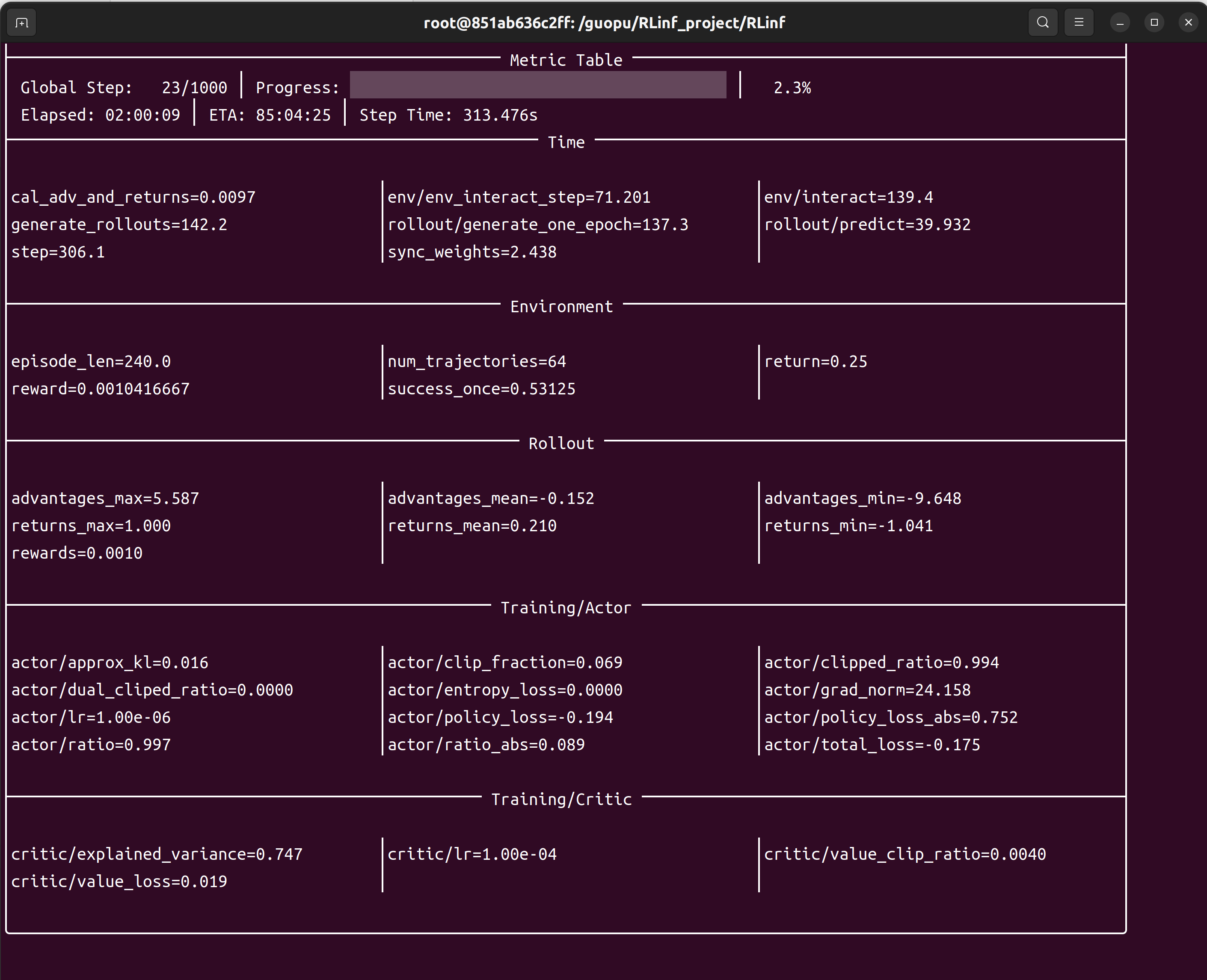
运行过程,如下图所示:
训练过程的日志保存在logs中:
- tensorboard 存放日志文件
- video 存放微调示例的视频
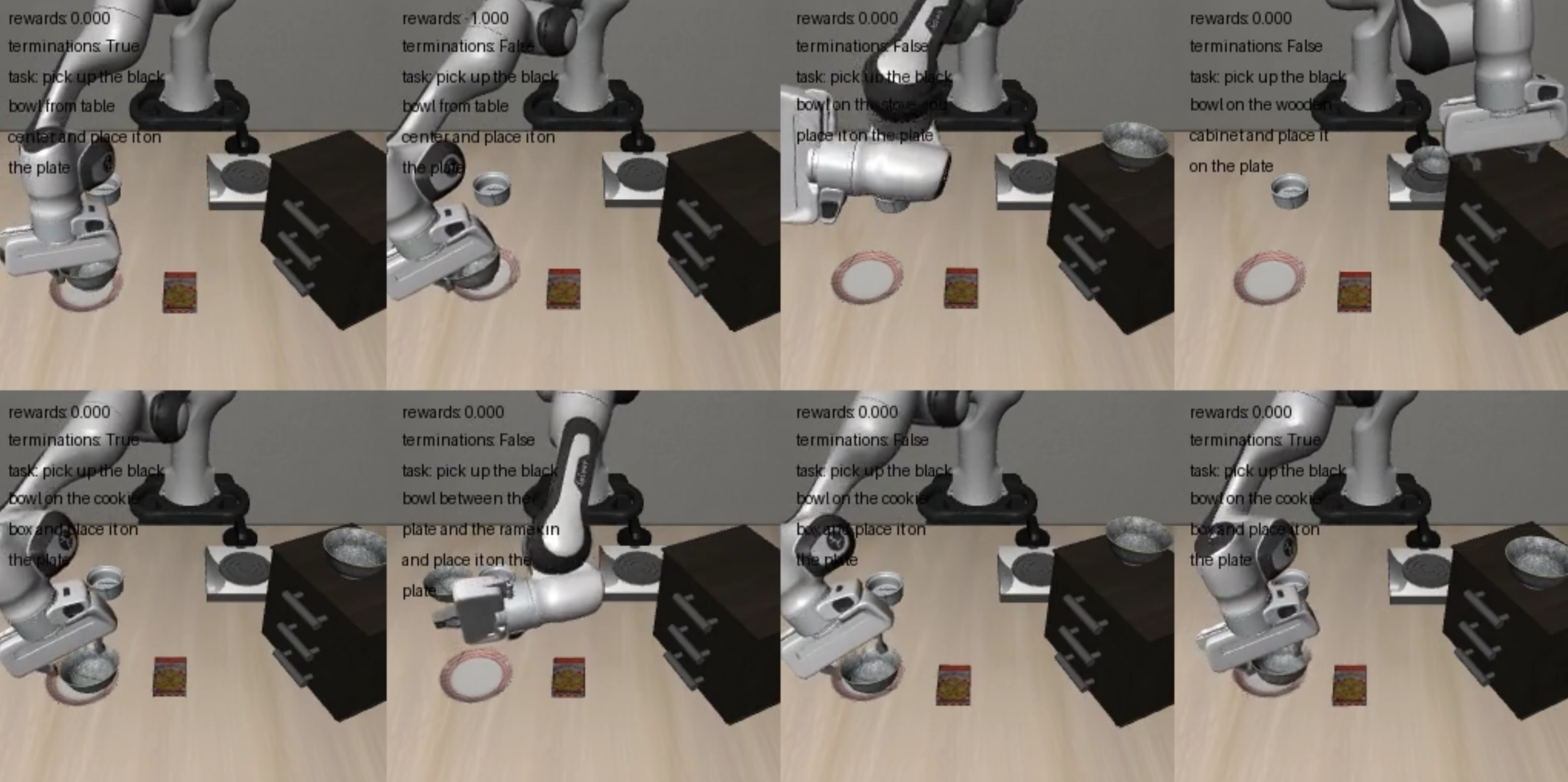
微调示例,如下图所示:
启动TensorBoard查看训练日志:
bash
tensorboard --logdir ./logs --port 6006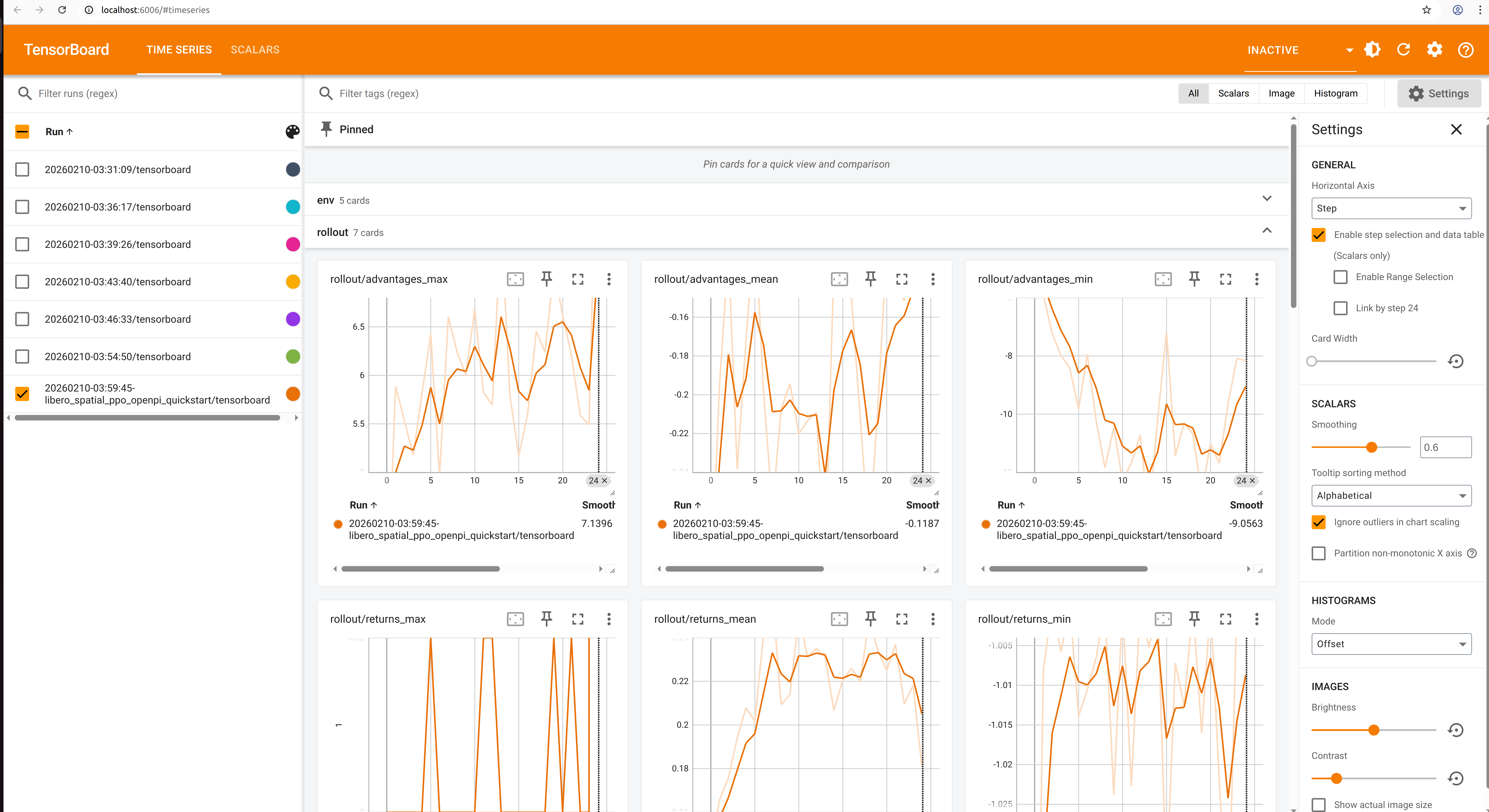
6、基于 GRPO 实现 π0 强化微调
选择一个模型权重,比如是:RLinf-Pi0-LIBERO-Spatial-Object-Goal-SFT
配置文件是:libero_spatial_grpo_openpi.yaml
通过以下命令启动训练:
bash
bash examples/embodiment/run_embodiment.sh libero_spatial_grpo_openpi训练过程的日志保存在logs中:
- tensorboard 存放日志文件
- video 存放微调示例的视频
启动TensorBoard查看训练日志:
bash
tensorboard --logdir ./logs --port 60067、基于 PPO 实现 π0.5 强化微调
选择一个模型权重,比如是:RLinf-Pi05-SFT
配置文件是:libero_spatial_ppo_openpi_pi05.yaml
通过以下命令启动训练:
bash
bash examples/embodiment/run_embodiment.sh libero_spatial_ppo_openpi_pi05启动TensorBoard查看训练日志:
bash
tensorboard --logdir ./logs --port 60068、基于 GRPO 实现 π0.5 强化微调
选择一个模型权重,比如是:RLinf-Pi05-SFT
配置文件是:libero_spatial_grpo_openpi_pi05.yaml
通过以下命令启动训练:
bash
bash examples/embodiment/run_embodiment.sh libero_spatial_grpo_openpi_pi05启动TensorBoard查看训练日志:
bash
tensorboard --logdir ./logs --port 60069. 关键监控指标
训练指标
actor/loss:策略损失actor/value_loss:价值函数损失(PPO)actor/grad_norm:梯度范数actor/approx_kl:更新前后策略 KL 值actor/pg_clipfrac:策略损失裁减比例actor/value_clip_ratio:价值损失裁剪比例(PPO)
Rollout 指标
rollout/returns_mean:平均回合回报rollout/advantages_mean:平均优势值
环境指标
env/episode_len:平均回合长度env/success_once:任务完成率
10. 训练结果
下面是官网的测试结果,参考一下:
π0 在 LIBERO 环境中的训练结果
| Model | Spatial | Object | Goal | Long | Average | Δ Avg. |
|---|---|---|---|---|---|---|
| π₀ (few-shot) | 65.3% | 64.4% | 49.8% | 51.2% | 57.6% | --- |
| π₀ +GRPO | 97.8% | 97.8% | 83.2% | 81.4% | 90.0% | +32.4 |
| π₀ +PPO | 98.4% | 99.4% | 96.2% | 90.2% | 96.0% | +38.4 |
π0.5 在 LIBERO 环境中的训练结果
| Model | Spatial | Object | Goal | Long | Average | Δ Avg. |
|---|---|---|---|---|---|---|
| π₀.₅ (few-shot) | 84.6% | 95.4% | 84.6% | 43.9% | 77.1% | --- |
| π₀.₅ +GRPO | 97.4% | 99.8% | 91.2% | 77.6% | 91.5% | +14.4 |
| π₀.₅ +PPO | 99.6% | 100% | 98.8% | 93.0% | 97.9% | +20.8 |
用了强化学习后,π₀和π₀.₅ 提升都挺大的。
分享完成~