在 LLM 向"超长上下文"进军的路上,我们总是面临一个残酷的二选一:要么用全注意力(Full Attention)保证效果但显存爆炸,要么用线性注意力(Linear Attention)节省资源但牺牲精度。
今天介绍的 MiniCPM-SALA,由面壁智能(OpenBMB)与清华大学等机构联合推出。它不仅打破了这种两难困境,更提出了一套"以旧换新"的低成本训练方案。
- 核心亮点: 稀疏注意力与线性注意力的 1:3 混合架构。
- 性能怪兽: 单张 A6000D 显卡即可推理 1M token ,速度比全注意力快 3.5倍。
- 极致省钱: 利用持续训练(Continual Training),将现有 Transformer 模型"改造"为混合架构,训练成本仅为从头训练的 25%。
背景:长文本的"富贵病"
随着大模型应用从简单的问答转向处理整本技术手册、仓库级代码分析(Repository-scale code engineering),百万级(1M+)token 的处理能力成为了刚需 。
然而,传统的 Transformer 架构(Full Attention)患有一种"富贵病":
-
计算瓶颈: 计算复杂度随序列长度 呈二次方增长,即O(N2)\mathcal{O}(N^2)O(N2) 。
-
KV-Cache 显存黑洞: 对于 8B 参数的模型,存储 1M token 的 KV-Cache 可能需要数百 GB 显存,这在普通显卡上简直是天方夜谭 。
现有的解决方案通常是"偏科"的:
-
稀疏注意力 (Sparse Attention): 计算快了,但为了检索信息,还是得存完整的 KV-Cache,典型的"算得省,存得费" 。
-
线性注意力 (Linear Attention): 虽然把复杂度降到了 O(N)\mathcal{O}(N)O(N),但往往伴随着"有损压缩",导致模型变笨,捕捉不到长距离的细节 。
MiniCPM-SALA 的出现,就是为了让鱼和熊掌兼得。
架构揭秘:SALA 是什么?
MiniCPM-SALA 的名字来源于 S parse A ttention(稀疏注意力)和 L inear Attention(线性注意力)的结合 。
1. 1:3 的黄金比例
这就好比一支足球队,既需要满场飞奔的工兵(线性注意力),也需要关键时刻一击致命的前锋(稀疏注意力)。
MiniCPM-SALA 并没有简单地堆叠层数,而是采用了一种混合架构:
-
75% 的层使用线性注意力(Lightning Attention): 负责全局信息的快速吞吐,保证 O(N)\mathcal{O}(N)O(N) 的低显存占用 。
-
25% 的层使用稀疏注意力(InfLLM-V2): 负责高精度的长程检索,确保关键信息不丢失 。
这种设计既保留了线性注意力的全局效率,又引入了稀疏注意力的高保真建模能力。
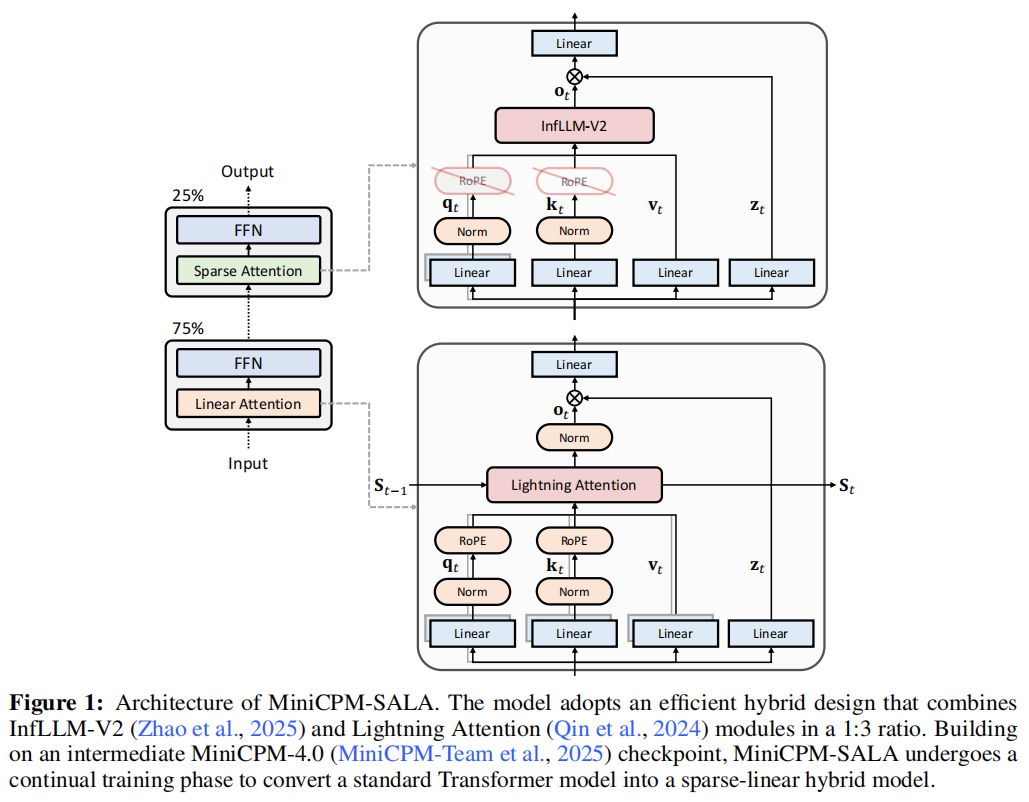
2. HyPE:混合位置编码 (Hybrid Positional Encoding)
为了让这两类注意力层"和平共处",团队设计了 HyPE 策略 :
-
线性层:使用 RoPE。 保证对相对位置的敏感性,维持语序逻辑 。
-
稀疏层:去掉 RoPE。 这是一个反直觉的设计。研究发现,RoPE 会导致长距离信息衰减。去掉它,反而能让稀疏注意力在超长上下文中更精准地"捞"回远古记忆 。
训练黑科技:拒绝从零开始
如果为了换架构就要重新预训练一个模型,那成本太高了。MiniCPM-SALA 展示了一种**"旧房改造"**的艺术。
研究团队没有从头训练(From Scratch),而是基于已经训练好的 MiniCPM-4.0(全注意力 Transformer)进行持续训练(Continual Training) 。
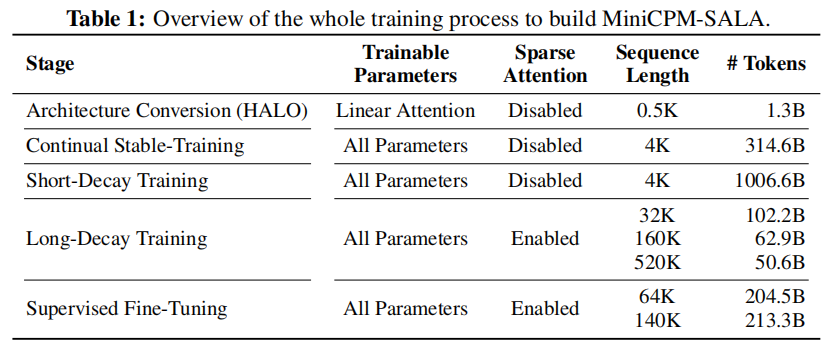
整个"变形"过程分为五步(HALO 框架):
-
架构转换 (Architecture Conversion): 将原本的 Softmax Attention 转换为 Linear Attention。保留部分层作为稀疏层(此时先不训练稀疏层)。
-
持续稳定训练 (Continual Stable-Training): 让转换后的线性层适应新身体,此时上下文较短(4K),暂时关闭稀疏注意力 。
-
短程衰减训练 (Short-Decay Training): 大量喂入高质量数据,巩固基础能力 。
-
长程衰减训练 (Long-Decay Training): 关键一步! 逐步将上下文拉长至 32K -> 160K -> 520K,并开启稀疏注意力。让模型学会如何配合使用两种注意力机制 。
-
有监督微调 (SFT): 针对长文本任务进行精调 。
实验结果:吊打全注意力?
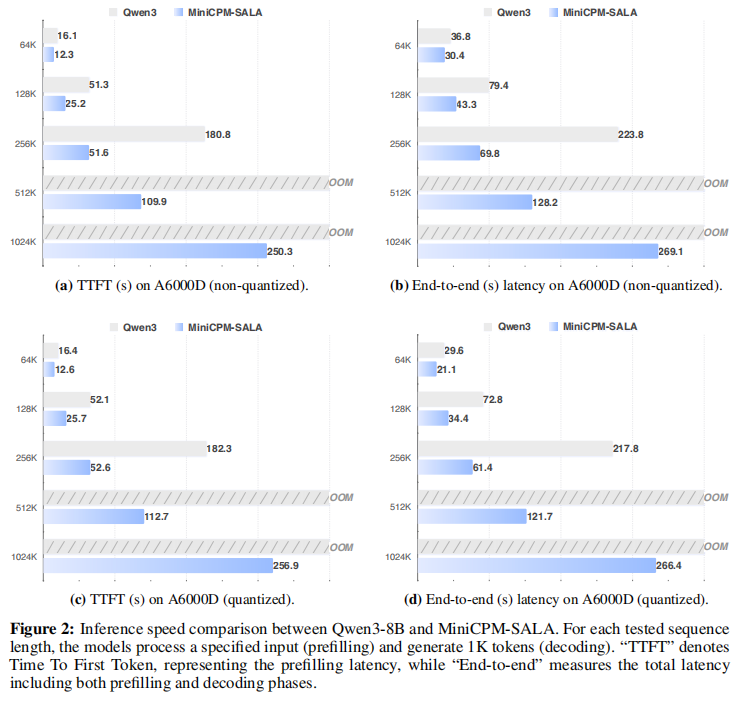
1. 推理速度与显存:单卡 1M 的奇迹
在长文本推理上,MiniCPM-SALA 展示了统治级的优势。
-
速度对比: 在 256K 长度下,相比同参数量的 Qwen3-8B,SALA 的推理速度(TTFT)快了 3.5倍 。
-
内存墙(Memory Wall): Qwen3-8B 在 512K 长度时就会因为显存耗尽(OOM)而崩溃。而 MiniCPM-SALA 即使在 1M (1024K) 长度下,依然能在单张 A6000D 上稳定运行 。
-
消费级显卡支持: 在显存较小的 RTX 5090 (32GB) 上,SALA 依然能跑通 1M 上下文,而全注意力模型在 128K 就已经 OOM 了 。
2. 能力评估:长短通吃
很多魔改架构的模型,长文本行了,短文本能力却崩了。MiniCPM-SALA 表现如何?
-
基准能力: 在 MMLU-Pro、HumanEval(代码)、AIME24(数学)等测试中,MiniCPM-SALA 的平均分(76.53)与 Qwen3-8B 等全注意力模型持平,甚至在部分数学任务上更优 。
-
长文本能力: 在 RULER 和 InfiniteBench 等长文本评测中,SALA 展现了强大的"大海捞针"能力。特别是在 2M (2048K) 的超长外推测试中,它依然保持了 81.6 的高分,证明了其架构的鲁棒性 。
总结
MiniCPM-SALA 给我们指明了一条通往 Efficient Long-Context 的新路径:
- 架构融合是未来: 没必要死磕全注意力,稀疏+线性的混合架构在长文本场景下性价比极高。
- Transformer 是可以"进化"的: 通过合理的训练策略,我们可以继承现有开源模型的"智慧",以极低的成本将其改造为适应长文本的新物种。
对于显卡资源有限,但又想尝试百万级上下文处理的开发者来说,MiniCPM-SALA 绝对是一个值得关注的开源利器。
论文标题: MiniCPM-SALA: Hybridizing Sparse and Linear Attention for Efficient Long-Context Modeling
项目地址: https://github.com/openbmb/minicpm