目录
[shmflg=IPC_CREAT | IPC_EXCL](#shmflg=IPC_CREAT | IPC_EXCL)
[反思: 为什么要让用户使用ftok生成key?](#反思: 为什么要让用户使用ftok生成key?)
1.回顾进程间通信的本质
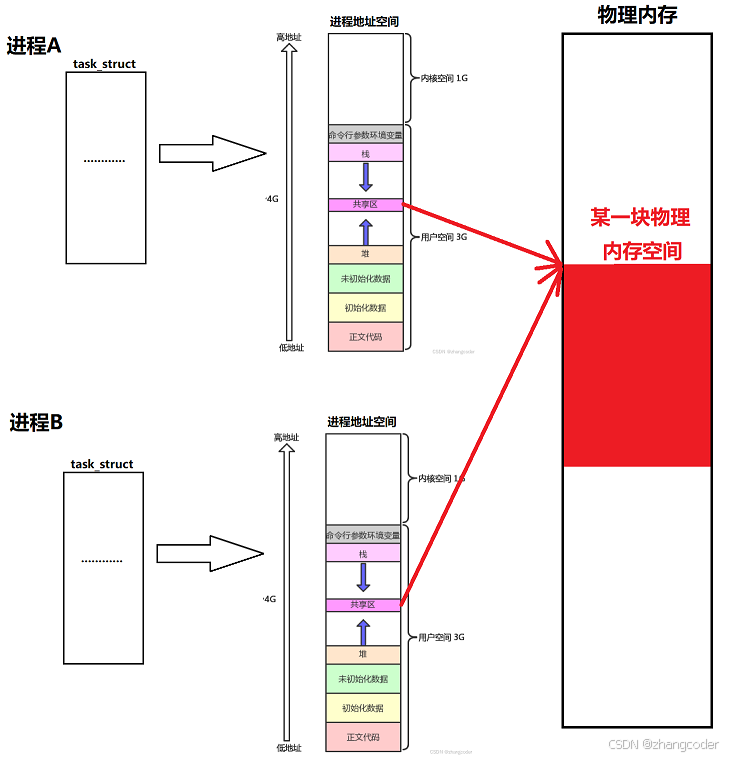
先让不同的进程,看到同一份资源,而且这个资源不能是某个进程独有的,因为进程之间具有独立性,各个进程的地址空间是隔离的
2.共享内存的原理
假设两个毫不相关的进程A和进程B需要使用共享内存通信,根据进程间通信的本质,需要让它们看到同一份共享内存资源
下图中的"某一块物理空间"就是共享内存,其通过页表映射到A和B进程地址空间的共享区,这样它们就能看到同一份共享内存资源
将共享内存全部映射到进程A和进程B地址空间的共享区,这样进程A和进程B使用一个起始地址就可以操作这块共享内存了
申请共享内存的方法
由上得知申请共享内存的方法:
1.申请内存
2.映射到两个进程的地址空间,即挂接 到进程地址空间
3.返回首地址
释放共享内存的方法
为了确保不出问题,需要先取消挂接共享内存到进程地址空间,再释放共享内存
注意事项
申请共享内存和释放共享内存进程无法直接参与(因为进程具有独立性),共享内存是由操作系统分配的,进程需要使用系统调用
3.相关的系统调用
shmget
shmget用于创建共享内存
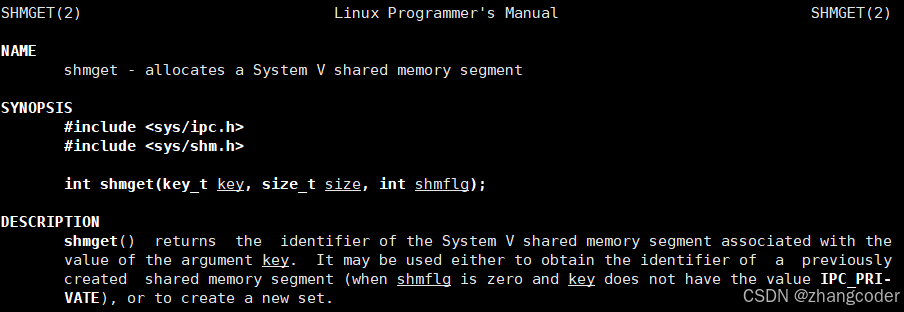

下面解释它的3个参数
★逻辑链
如何申请共享内存? 或者说申请共享内存的方法是什么? 答: 依靠shmflg
共享内存的大小? 答: 依靠size
操作系统中有大量的共享内存,申请共享内存后,如何保证尚未通信的进程能拿到同一个共享内存区域呢? 答: 依靠key
shmflg
说明共享内存如何创建和如何获取
shmflg=IPC_CREAT
如果申请的共享内存不存在,那么就创建
如果申请的共享内存存在,就获取 并返回
shmflg=IPC_CREAT | IPC_EXCL
在IPC_CREAT的基础上添加IPC_EXCL
如果申请的共享内存不存在,那么就创建
如果申请的共享内存存在,就出错返回
这样做的目的: 保证申请的共享内存是新的!
注: IPC_EXCL不单独使用
IPC_EXCL
根据https://stackoverflow.com/questions/62876903/what-is-ipc-excl-short-for的回答:
IPC_EXCL是I nterP rocess C ommunication EXCL usive的缩写,可以从opengroup网https://pubs.opengroup.org/onlinepubs/9699919799/basedefs/fcntl.h.html对O_EXCL的解释Exclusive use flag类比过来:

注: exclusive adj.独有的
key
共享内存的标识符,这保证了不同进程看到了同一个共享内存
在进程之间尚未通信时,需要让它们都找到同一个共享内存,那么它们就要拿到同一个key
换句话说,这里的key类似命名管道,让进程们都打开同一个路径下的同一个命名管道,就能通信了
key不需要手动生成,可以使用ftok系统调用:
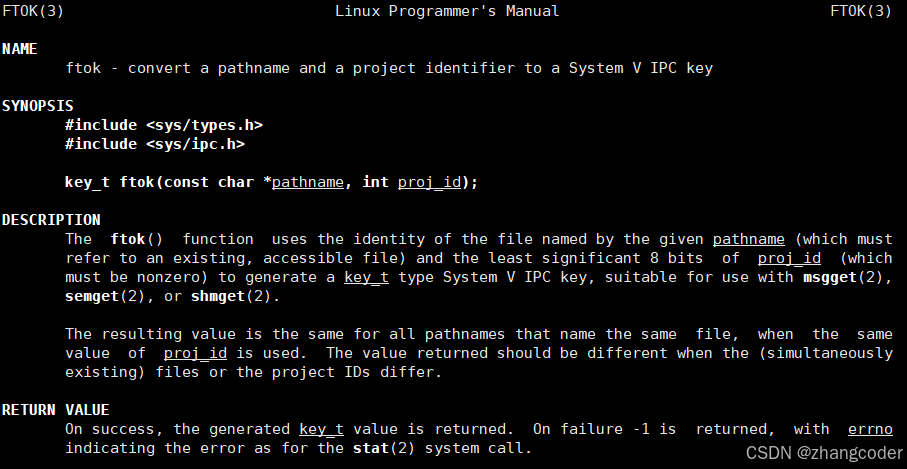
注意事项: pathname必须是真实存在的路径,proj_id不能为0
key的生成算法
在glibc-2.42的/sysvipc/ftok.c中定义了ftok函数:
cpp
key_t
ftok (const char *pathname, int proj_id)
{
struct __stat64_t64 st;
key_t key;
if (__stat64_time64 (pathname, &st) < 0)
return (key_t) -1;
key = ((st.st_ino & 0xffff) | ((st.st_dev & 0xff) << 16)
| ((proj_id & 0xff) << 24));
return key;
}借助了3个变量st.st_ino、st.st_dev、proj_id来尽量确保key的唯一性
struct __stat64_t64定义在/sysdeps/unix/sysv/linux/struct_stat_time64.h中:
cpp#if __TIMESIZE == 64 # define __stat64_t64 stat64 #else # include <struct___timespec64.h> struct __stat64_t64 { # define __struct_timespec struct __timespec64 # include <bits/struct_stat_time64_helper.h> }; #endif /* __TIMESIZE == 64 */struct __stat64_t64成员变量定义在/sysdeps/unix/sysv/linux/bits/中:
cpp/* Content of internal __stat64_t64 struct. */ __dev_t st_dev; /* Device. */ __ino64_t st_ino; /* file serial number. */ __mode_t st_mode; /* File mode. */ __nlink_t st_nlink; /* Link count. */ __uid_t st_uid; /* User ID of the file's owner. */ __gid_t st_gid; /* Group ID of the file's group. */ __dev_t st_rdev; /* Device number, if device. */ __off64_t st_size; /* Size of file, in bytes. */ __blksize_t st_blksize; /* Optimal block size for I/O. */ __blkcnt64_t st_blocks; /* Number 512-byte blocks allocated. */ #ifdef __USE_XOPEN2K8 # ifndef __struct_timespec # define __struct_timespec struct timespec # endif /* Nanosecond resolution timestamps are stored in a format equivalent to 'struct timespec'. This is the type used whenever possible but the Unix namespace rules do not allow the identifier 'timespec' to appear in the <sys/stat.h> header. Therefore we have to handle the use of this header in strictly standard-compliant sources special. */ __struct_timespec st_atim; __struct_timespec st_mtim; __struct_timespec st_ctim; # define st_atime st_atim.tv_sec # define st_mtime st_mtim.tv_sec # define st_ctime st_ctim.tv_sec # undef __struct_timespec #else /* The definition should be equal to the 'struct __timespec64' internal layout. */ # if __BYTE_ORDER == __BIG_ENDIAN # define __fieldts64(name) \ __time64_t name; __int32_t :32; __int32_t name ## nsec # else # define __fieldts64(name) \ __time64_t name; __int32_t name ## nsec; __int32_t :32 # endif __fieldts64 (st_atime); __fieldts64 (st_mtime); __fieldts64 (st_ctime); unsigned long int __glibc_reserved4; unsigned long int __glibc_reserved5; # undef __fieldts64 #endif1.st_ino的注释: file serial number,就是文件的inode编号,具有唯一性
2.st_dev的注释: st_dev,即设备号,具有唯一性
key的构成:
cpp
key = ((st.st_ino & 0xffff) | ((st.st_dev & 0xff) << 16)
| ((proj_id & 0xff) << 24));根据与运算和左移运算的规则:
-
st.st_ino构成key的低16位
-
st.st_dev构成key的中间8位
3.proj_id构成key的高8位

从图中可以得知: key是32位的
参考资料:
https://stackoverflow.com/questions/3155291/which-file-should-i-pass-as-pathname-argument-of-ftok
https://stackoverflow.com/questions/54492824/what-is-the-formula-used-to-produce-a-ftok-key
建议: 自己造的key可能和系统冲突,最好用ftok生成
结论: ftok系统调用生成key的算法和内核无关
反思: 为什么要让用户使用ftok生成key?
从上面的生成算法来看,key完全可以由操作系统生成,那为什么要让用户使用ftok生成key?
答: 进程通信是由程序员决定的,毕竟操作系统不知道哪几个进程要通信
如果进程A和进程B执行ftok传的pathname和proj_id参数都一样,那么它们生成的key也就一样,这样就能使用同一块共享内存进行通信了
size
共享内存的大小,单位字节
返回值
shmget如果执行成功,那么返回"a valid shared memory identifier",即一个有效的共享内存标识符,简称为shmid,如果执行失败,返回-1
★shmid和key的区别
一个是进程级别,一个是操作系统级别
++多个进程能访问同一块共享内存,是通过key,这个操作系统标识共享内存唯一导致的++
++而一个进程能创建多个共享内存,决定访问哪一块共享内存,是通过shmid决定的++
查看操作系统共享内存的方法
bash
ipcs -m
4.代码设计
目标: 设计进程A和进程B使用共享内存通信的代码
创建以下文件:
bash
shared_memory/
├── makefile
├── header.hpp
├── shm1.cpp
└── shm2.cppmakefile写入:
bash
all: shm1.out shm2.out
shm1.out:shm1.cpp
g++ -o $@ $^ -g -std=c++11
shm2.out:shm2.cpp
g++ -o $@ $^ -g -std=c++11
.PHONY:clean
clean:
rm -f shm1.out shm2.outget_key函数
封装一个取得key的函数,为了确保两个进程生成的key一样,ftok的pathname可以传入当前进程所处的目录,如果它们没有手动改变自己所处的目录的话
写入header.hpp中:
cpp
#include <sys/ipc.h>
#include <sys/shm.h>
#include <unistd.h>
#include <stdlib.h>
#define SIZE 1024
#define PROJ_ID 0x1234
key_t get_key()
{
char buffer[SIZE];
char* pathname=getcwd(buffer,sizeof(buffer));
if (pathname==nullptr)
{
perror("getcwd failed");
exit(1);
}
return ftok(pathname,PROJ_ID);
}shm1.cpp和shm2.cpp都写入:
cpp
#include <stdio.h>
#include "header.hpp"
int main()
{
printf("key=0x%X\n",get_key());
return 0;
}运行结果: 两个进程生成的key都一样
(开了两个终端,以此来说明两个进程毫不相关)

get_new_shared_memory函数
get_new_shared_memory内部调用get_key来生成
cpp
//使用IPC_EXCL来确保获得新的共享内存
int get_new_shared_memory()
{
key_t key=get_key();
//申请新的共享内存
int shmid=shmget(key,4096,IPC_CREAT|IPC_EXCL);
if (shmid==-1)
{
perror("shmget failed");
exit(2);
}
return shmid;
}测试代码:
shm1.cpp:
cpp
#include <stdio.h>
#include <iostream>
#include "header.hpp"
int main()
{
int shmid=get_new_shared_memory();
std::cout<<"shmid="<<shmid<<std::endl;
for(;;);
return 0;
}运行结果:
执行前:

执行中(shm1.out死循环未退出):

执行后(shm1.out结束运行):

发现进程没有关闭共享内存,结束后共享内存没有消失
结论: 操作系统不会主动关闭共享内存,即共享内存的生命周期是随内核的,用户不主动关闭,共享内存会一直存在,除非内核重启或者用户手动释放
如果shm1.out调用两次get_new_shared_memory(),第二次会报错:
cpp
#include <stdio.h>
#include <iostream>
#include "header.hpp"
int main()
{
int shmid1=get_new_shared_memory();
std::cout<<"shmid="<<shmid1<<std::endl;
int shmid2=get_new_shared_memory();
std::cout<<"shmid="<<shmid2<<std::endl;
for(;;);
return 0;
}运行结果:
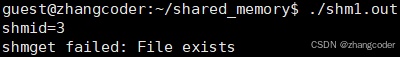
使用IPC_CREAT | IPC_EXCL确保申请的共享内存是新的
命令行关闭共享内存的方法
bash
ipcrm -M key
#或
ipcrm -m shmid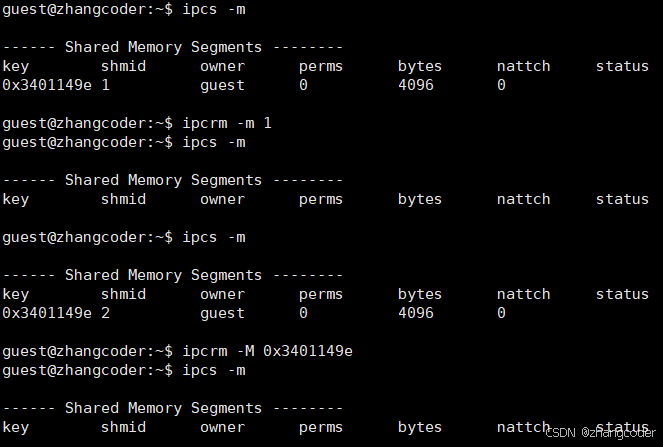
共享内存的权限
在shmget通过或运算添加权限标志,例如:
cpp
int shmid=shmget(key,4096,IPC_CREAT|IPC_EXCL|0666);运行结果:

共享内存的大小
修改大小:
cpp
int shmid=shmget(key,4097,IPC_CREAT|IPC_EXCL|0666);运行结果:

Shared Memory Segments表的bytes一列元素的大小和shmget的第二个参数size一样
尽管申请的大小不是4096的整数倍,但操作系统在底层实现时,会向上取整到4096的整数倍,一般情况下,x86的一个页的大小是4096字节,申请了4097个字节,操作系统会申请2个页的空间,这叫页对齐
证明: 可以看Linux 6.18.6的/ipc/shm.c的源码:
shmget系统调用,会调用内核的ksys_shmget函数:
cpp
long ksys_shmget(key_t key, size_t size, int shmflg)
{
struct ipc_namespace *ns;
static const struct ipc_ops shm_ops = {
.getnew = newseg,
.associate = security_shm_associate,
.more_checks = shm_more_checks,
};
struct ipc_params shm_params;
ns = current->nsproxy->ipc_ns;
shm_params.key = key;
shm_params.flg = shmflg;
shm_params.u.size = size;
return ipcget(ns, &shm_ids(ns), &shm_ops, &shm_params);
}经过层层调用会调到newseg,这个函数负责++创建一个新的共享内存段,肯定和页对齐有关++
cpp
/**
* newseg - Create a new shared memory segment
* @ns: namespace
* @params: ptr to the structure that contains key, size and shmflg
*
* Called with shm_ids.rwsem held as a writer.
*/
static int newseg(struct ipc_namespace *ns, struct ipc_params *params)
{
key_t key = params->key;
int shmflg = params->flg;
size_t size = params->u.size;
int error;
struct shmid_kernel *shp;
size_t numpages = (size + PAGE_SIZE - 1) >> PAGE_SHIFT;
struct file *file;
char name[13];
//后面代码省略
}重点看numpages
cpp
size_t numpages = (size + PAGE_SIZE - 1) >> PAGE_SHIFT;x86下,PAGE_SIZE为4096
PAGE_SHIFT定义在/tools/include/linux/mm.h
cpp
#define PAGE_SHIFT 12那么当size为4097时,(size + PAGE_SIZE - 1)为8192,即0b10000000000000,右移12位后,numpages为0b10,即十进制的2
结论: 向shmget传入的第2个参数size,操作系统在实际分配共享内存时,会向上对齐到一个页的整数倍后然后分配,即(LaTex公式: \lceil \frac{size}{pagesize}\rceil*pagesize )这种分配方式可以提高内存管理的效率,减少内存碎片,但进程只能用size那么多
让进程和共享内存联系起来
共享内存创建好了之后,需要让进程和共享内存联系起来
使用shmat系统调用:
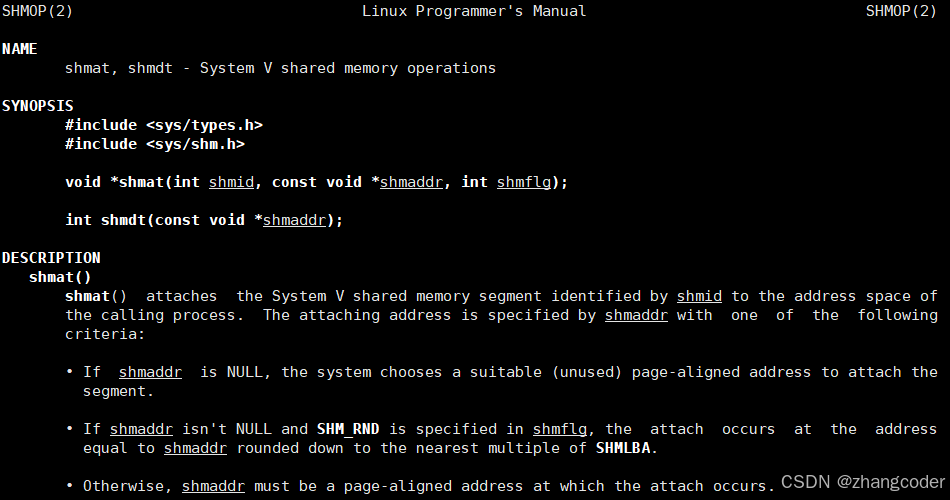
shamddr: 共享内存挂接 到共享区的什么位置,程序员不好指定,设为空指针,让操作系统决定
shmflg: 可以控制挂接的共享内存的权限,这里填0,和传入shmget的权限位保持一致
shmat返回值: 接受共享内存的起始地址,由于返回void*类型,这样可以方便程序员进行强制类型转换

测试单个进程挂接共享内存:
cpp
#include <stdio.h>
#include <iostream>
#include "header.hpp"
int main()
{
int shmid=get_new_shared_memory();
std::cout<<"shm1.out已经创建共享内存"<<std::endl;
sleep(4);
void* start_addr=shmat(shmid,nullptr,0);
if (start_addr==(void *) -1)
{
perror("shmat failed");
exit(3);
}
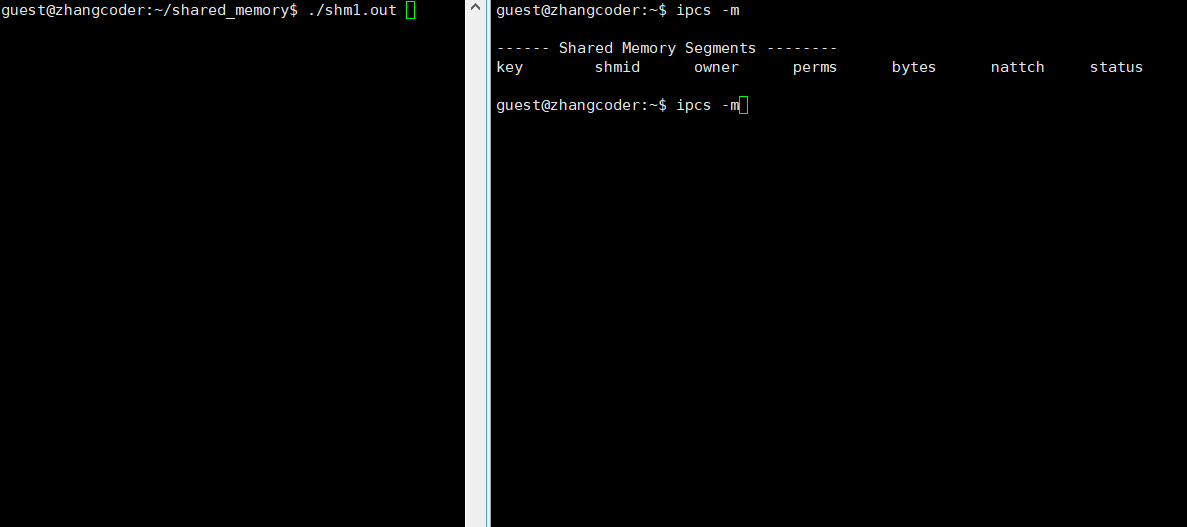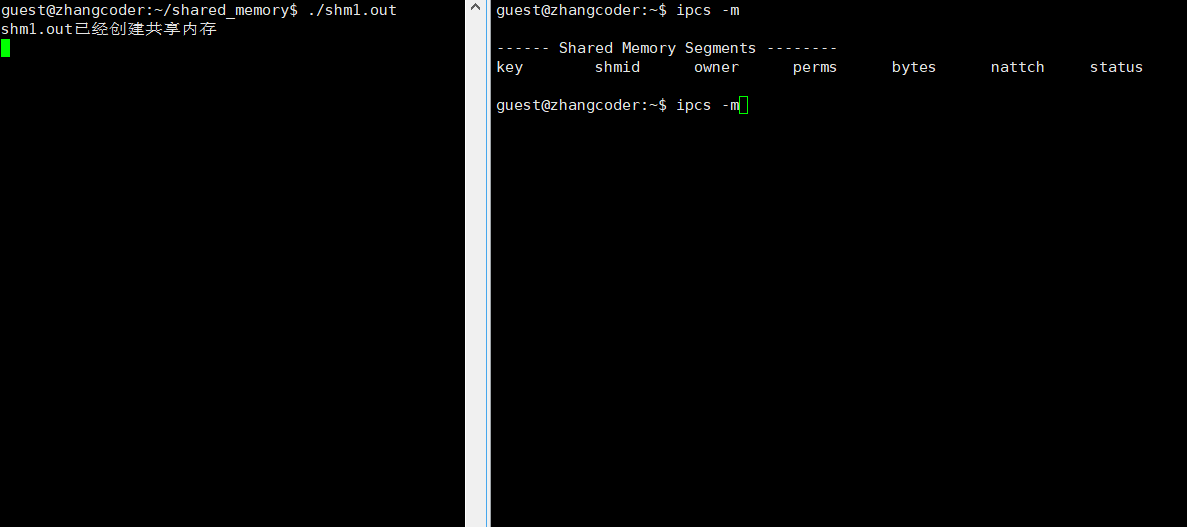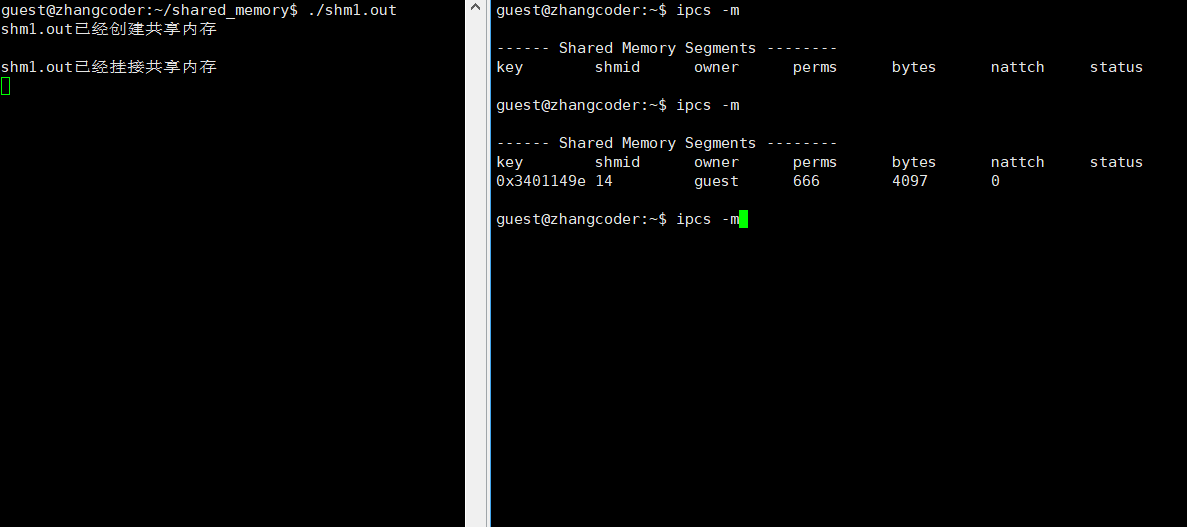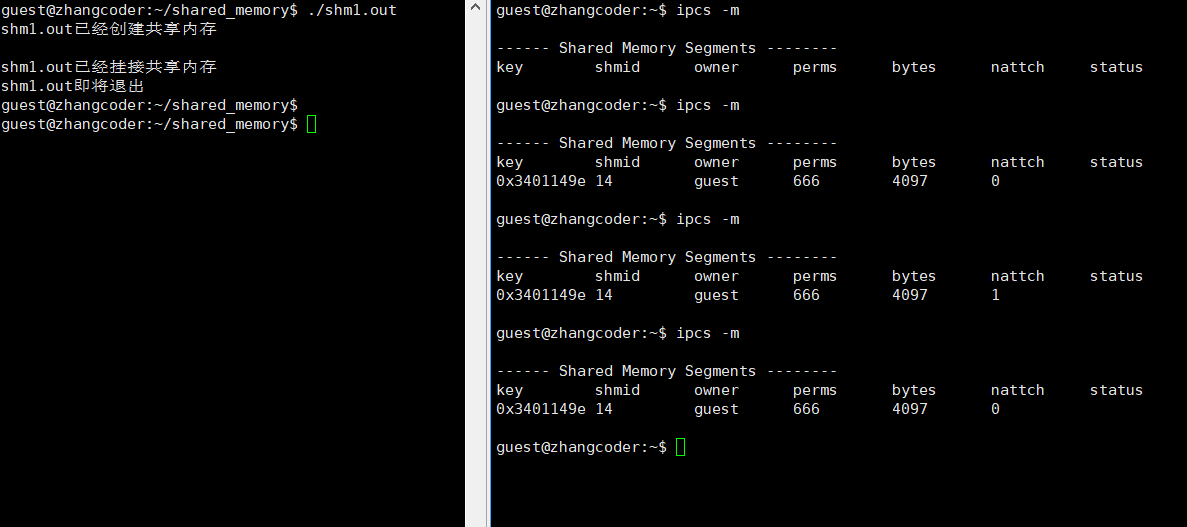
std::cout<<"shm1.out已经挂接共享内存"<<std::endl;
sleep(4);
std::cout<<"shm1.out即将退出"<<std::endl;
return 0;
}运行结果:

可以看到,只有nattch一列在变化:
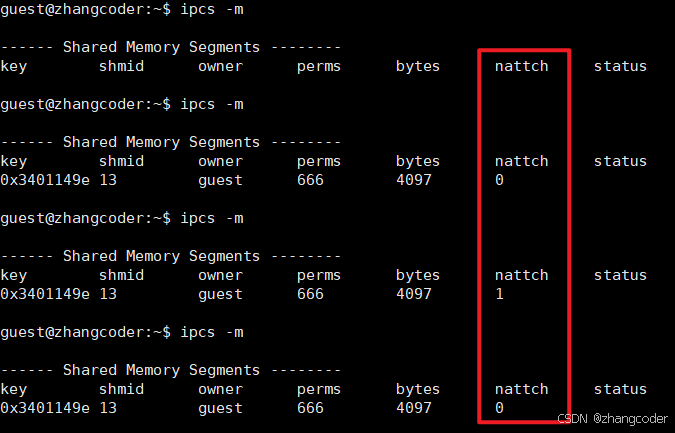
结论: nattch简单理解为: 标识共享内存的挂接数,即当前一共多少个进程挂接了这个共享内存,类似文件系统的引用计数
让进程去除共享内存的挂接
使用shmdt系统调用:
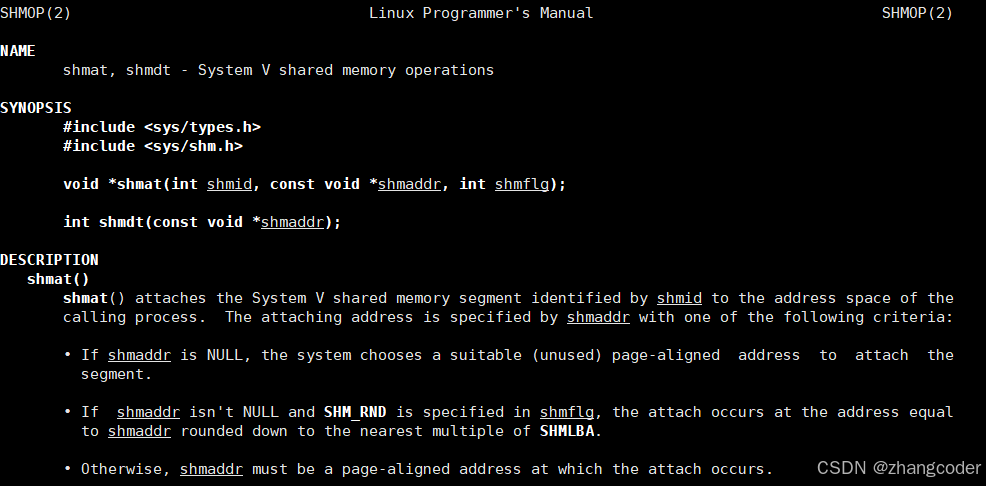
shmflg: 可以控制挂接的共享内存的权限,这里填0,和传入shmget的权限位保持一致
参数shmaddr为共享内存的起始地址,不需要交代空间大小,内核已经记录了大小

测试单个进程取消挂接共享内存:
shm1.cpp写入:
cpp
#include <stdio.h>
#include <iostream>
#include "header.hpp"
int main()
{
int shmid=get_new_shared_memory();
std::cout<<"shm1.out已经创建共享内存"<<std::endl;
sleep(4);
void* start_addr=shmat(shmid,nullptr,0);
if (start_addr==(void *) -1)
{
perror("shmat failed");
exit(3);
}
std::cout<<"shm1.out已经挂接共享内存"<<std::endl;
sleep(4);
if (-1==shmdt(start_addr))
{
perror("shmdt failed");
exit(4);
}
sleep(4);
std::cout<<"shm1.out即将退出"<<std::endl;
return 0;
}运行结果:
注意nattch变化:
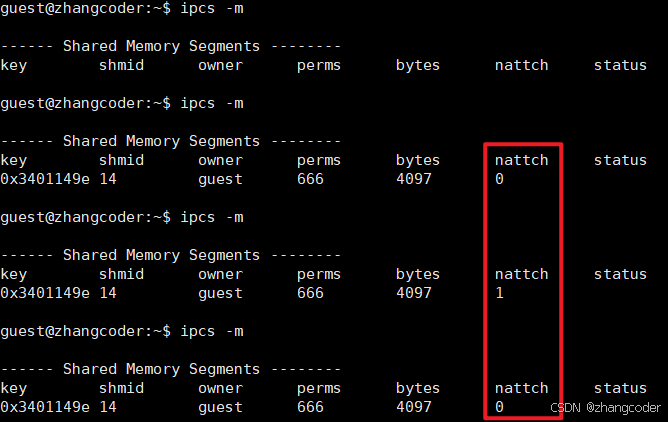
释放共享内存
使用shmctl(ctl是contrl的缩写)系统调用:
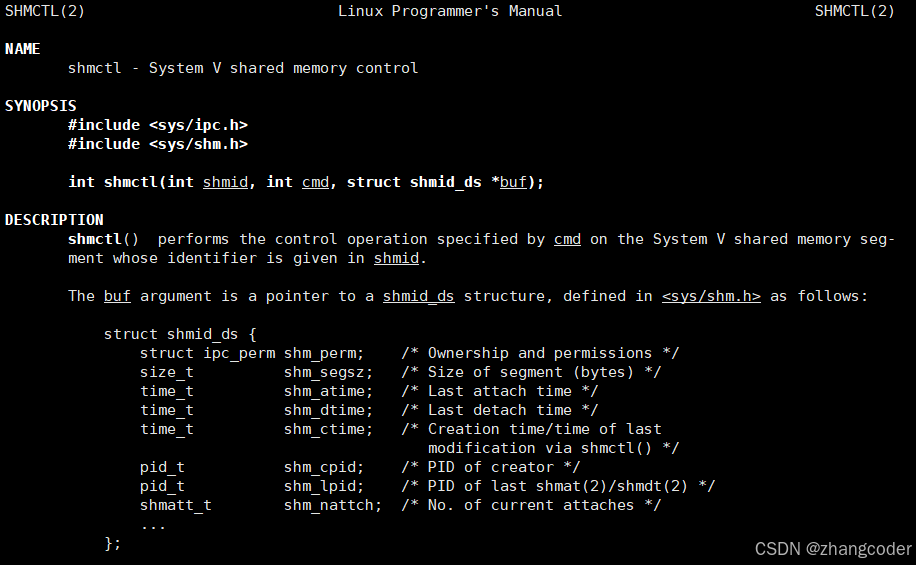

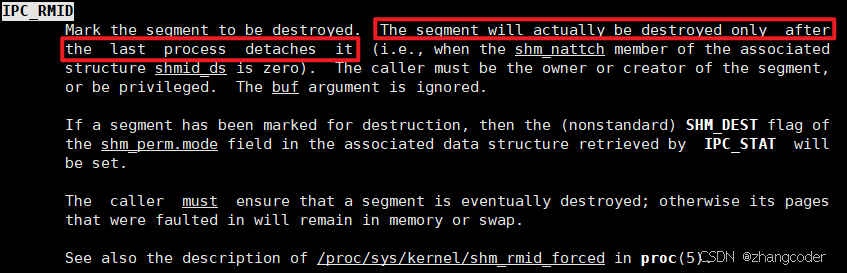
cmd是对共享内存进行的操作,删除共享内存可以用IPC_RMID,手册中的提示: 必须没有任何进程挂接到这个共享内存,才能删除这个共享内存
shmid_ds结构体
如何理解shmctl的第3个参数struct shmid_ds *buf?
操作系统中运行着大量的进程,这些进程或多或少都有使用共享内存通信,那么操作系统就要为这些进程申请共享内存,一旦共享内存变多,操作系统就需要管理这些共享内存,即++先描述再组织++
使用内核结构体描述共享内存:
cpp
struct shmid_ds {
struct ipc_perm shm_perm; /* Ownership and permissions */
size_t shm_segsz; /* Size of segment (bytes) */
time_t shm_atime; /* Last attach time */
time_t shm_dtime; /* Last detach time */
time_t shm_ctime; /* Creation time/time of last
modification via shmctl() */
pid_t shm_cpid; /* PID of creator */
pid_t shm_lpid; /* PID of last shmat(2)/shmdt(2) */
shmatt_t shm_nattch; /* No. of current attaches */
...
};
struct ipc_perm {
key_t __key; /* Key supplied to shmget(2) */
uid_t uid; /* Effective UID of owner */
gid_t gid; /* Effective GID of owner */
uid_t cuid; /* Effective UID of creator */
gid_t cgid; /* Effective GID of creator */
unsigned short mode; /* Permissions + SHM_DEST and
SHM_LOCKED flags */
unsigned short __seq; /* Sequence number */
};struct shmid_ds是用户态 的描述共享内存的属性的结构体,ds是data structure的缩写
删除的时候不管shmid_ds,传NULL即可,即:
cpp
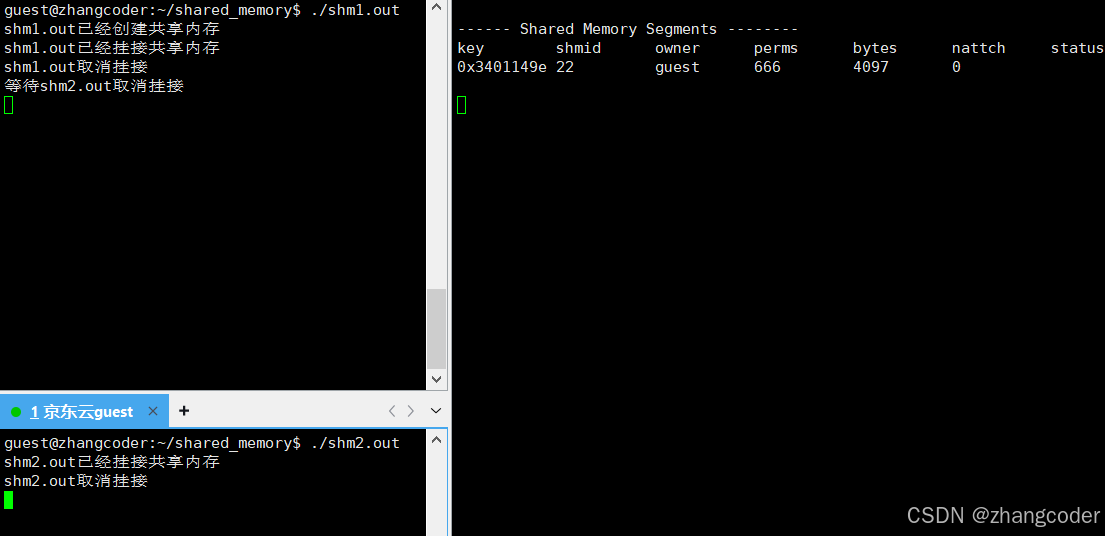
shmctl(shmid,IPC_RMID,nullptr);让两个进程挂接共享内存
目标: shm1.out负责创建,之后shm1.out和shm2.out都挂接到这个共享内存上
shm1.cpp写入:
cpp
#include <stdio.h>
#include <iostream>
#include "header.hpp"
int main()
{
int shmid=get_new_shared_memory();
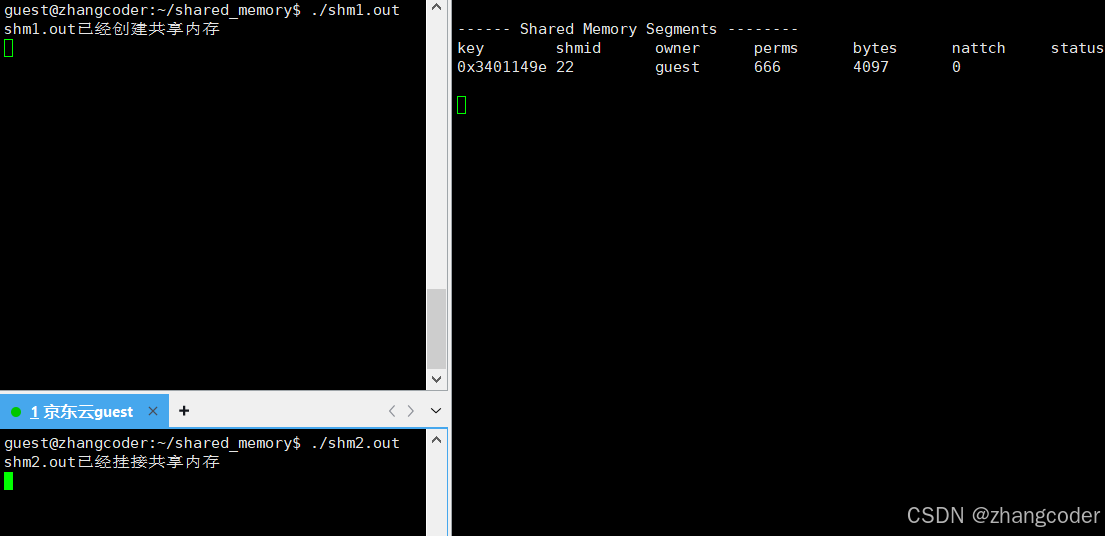
std::cout<<"shm1.out已经创建共享内存"<<std::endl;
sleep(4);
void* start_addr=shmat(shmid,nullptr,0);
if (start_addr==(void *) -1)
{
perror("shmat failed");
exit(3);
}
std::cout<<"shm1.out已经挂接共享内存"<<std::endl;
sleep(4);
if (-1==shmdt(start_addr))
{
perror("shmdt failed");
exit(4);
}
std::cout<<"shm1.out取消挂接"<<std::endl;
std::cout<<"等待shm2.out取消挂接"<<std::endl;
sleep(4);
if (-1==shmctl(shmid,IPC_RMID,nullptr))
{
perror("stmctl failed");
exit(5);
}
std::cout<<"shm1.out删除了共享内存"<<std::endl;
std::cout<<"shm1.out即将退出"<<std::endl;
sleep(2);
return 0;
}shm2.cpp写入:
cpp
#include <stdio.h>
#include <iostream>
#include "header.hpp"
int main()
{
sleep(1);
int shmid=get_old_shared_memory();
void* start_addr=shmat(shmid,nullptr,0);
if (start_addr==(void *) -1)
{
perror("shmat failed");
exit(3);
}
std::cout<<"shm2.out已经挂接共享内存"<<std::endl;
sleep(6);
if (-1==shmdt(start_addr))
{
perror("shmdt failed");
exit(4);
}
std::cout<<"shm2.out取消挂接"<<std::endl;
sleep(4);
std::cout<<"shm2.out即将退出"<<std::endl;
sleep(2);
return 0;
}注: get_old_shared_memory是获取已经创建过的共享内存
cpp
int get_old_shared_memory()
{
key_t key=get_key();
//获取旧的共享内存
int shmid=shmget(key,4097,IPC_CREAT|0666);
if (shmid==-1)
{
perror("shmget failed");
exit(2);
}
return shmid;
}
bash
#!/usr/bin/bash
for ((;;))
do
ipcs -m
sleep 0.3s
clear
done运行结果:
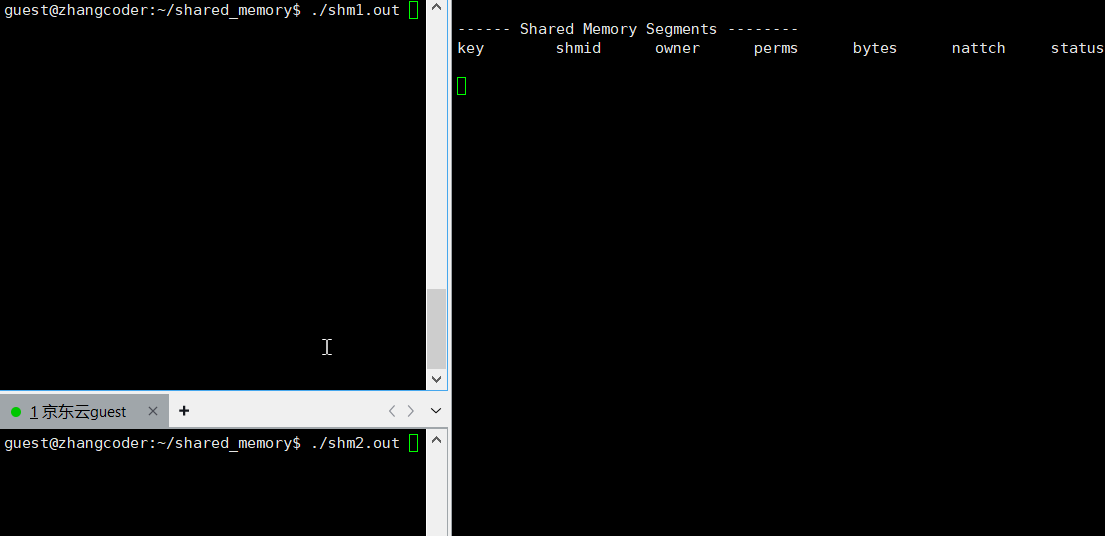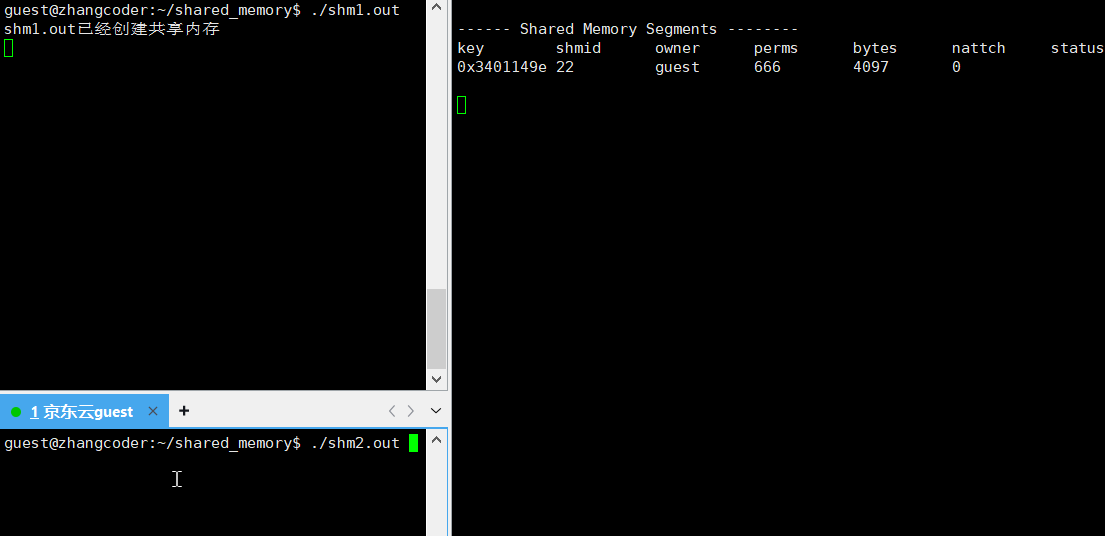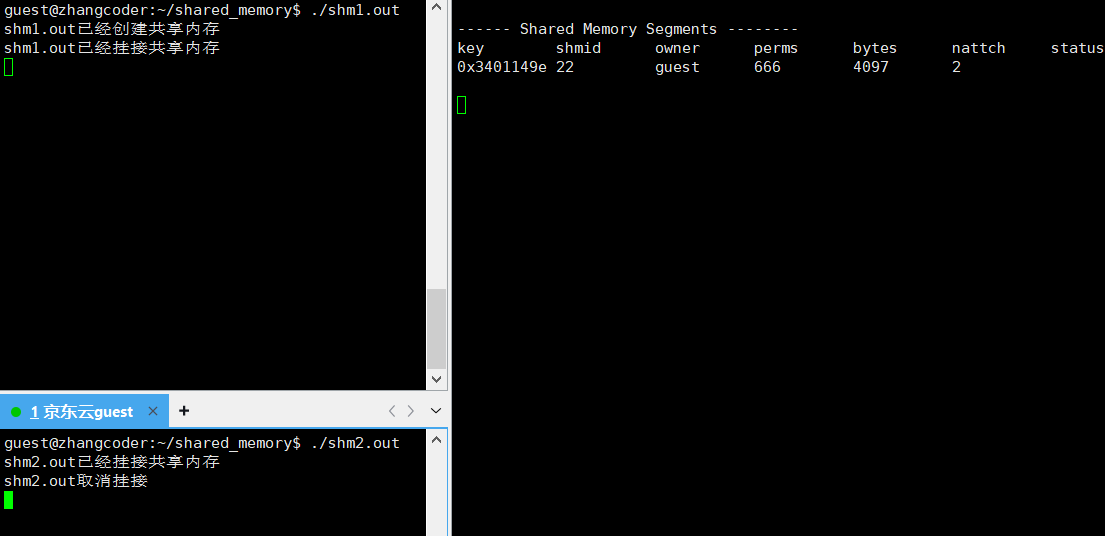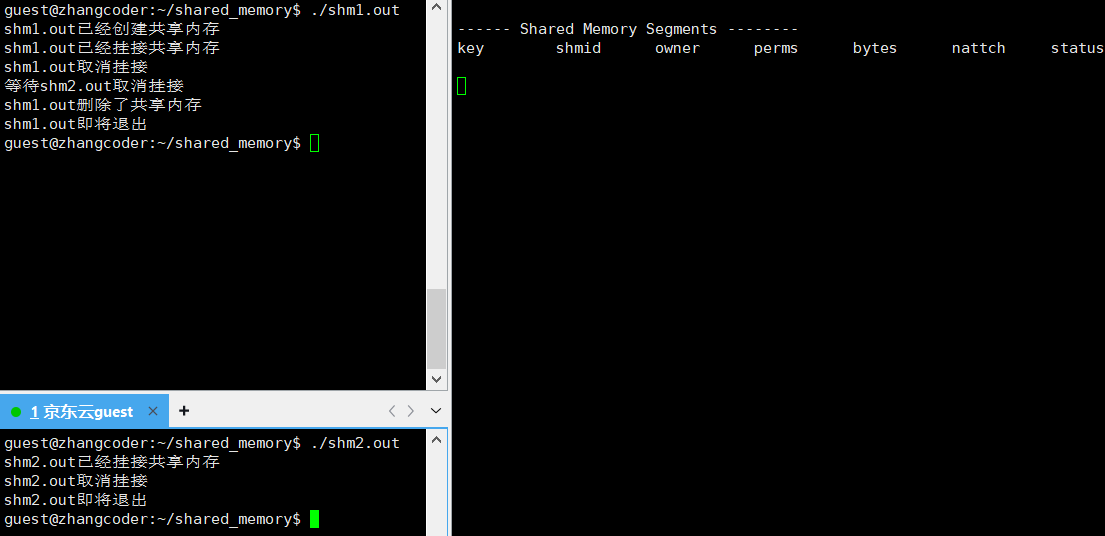
关键部分:
nattch==0:
nattch==1:
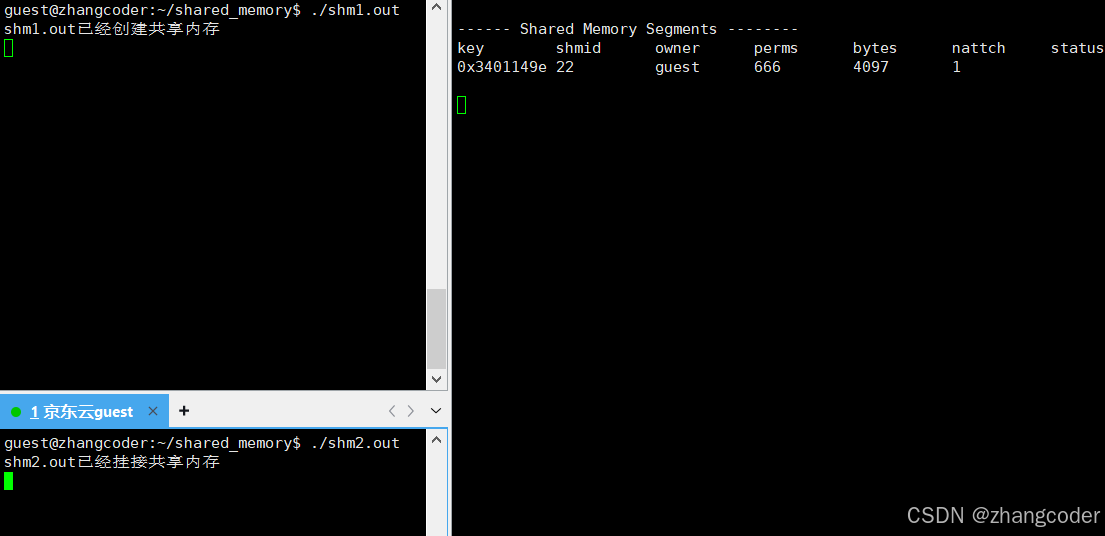
nattch==2:
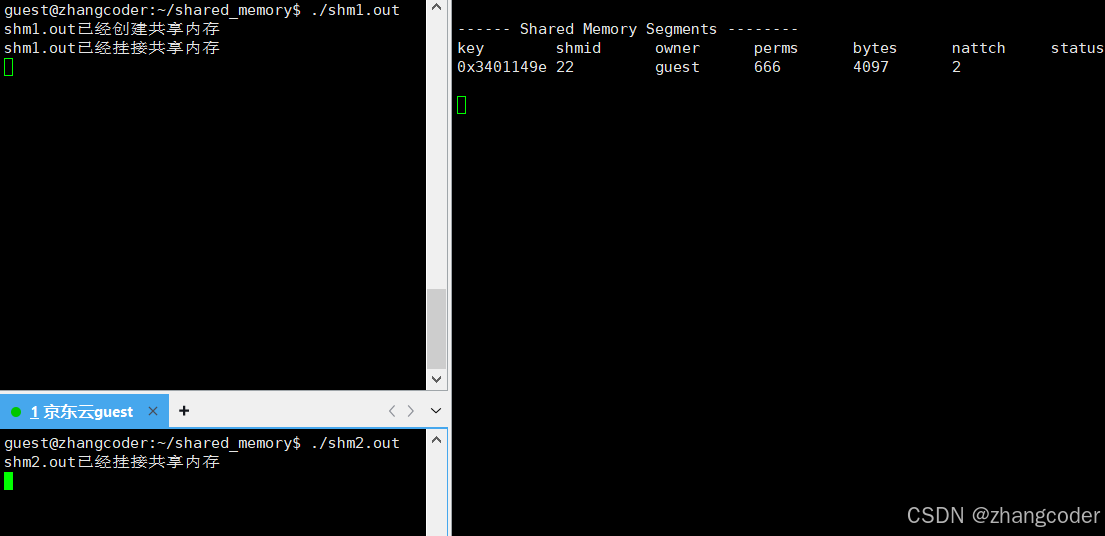
nattch==1:
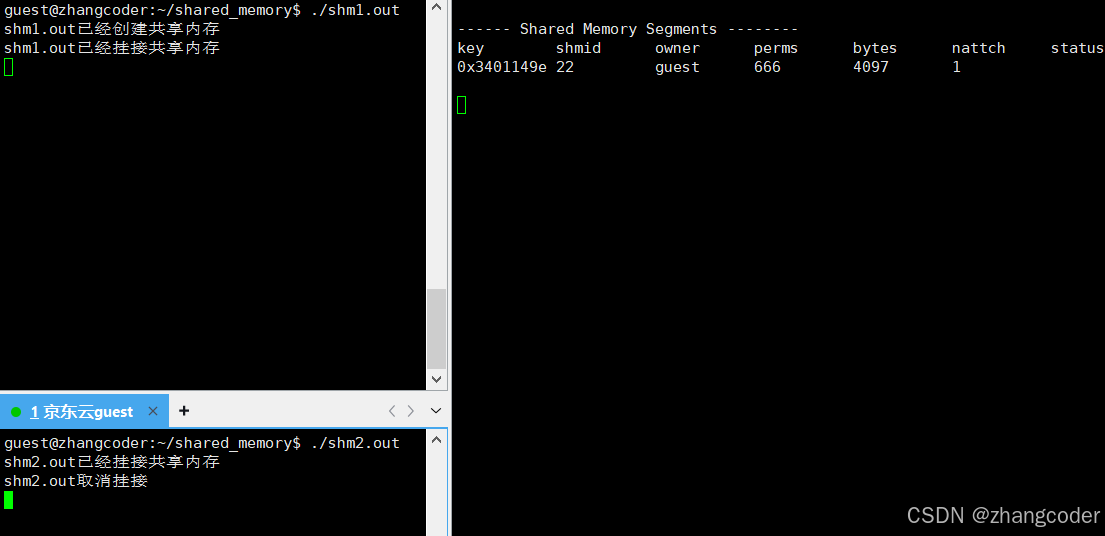
nattch==0:
让两个进程通信
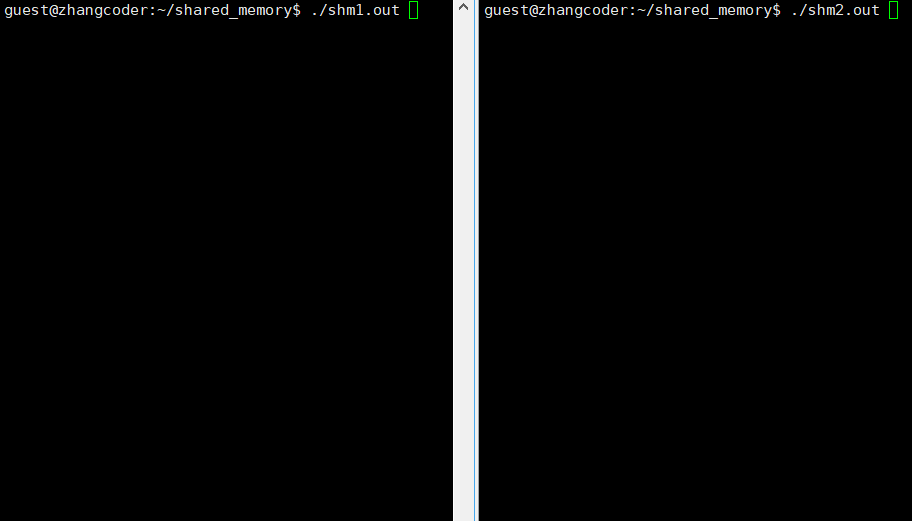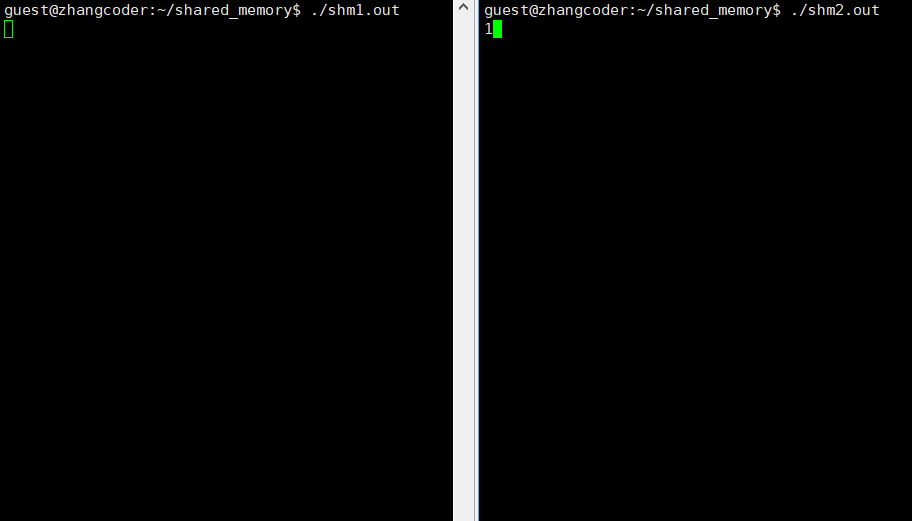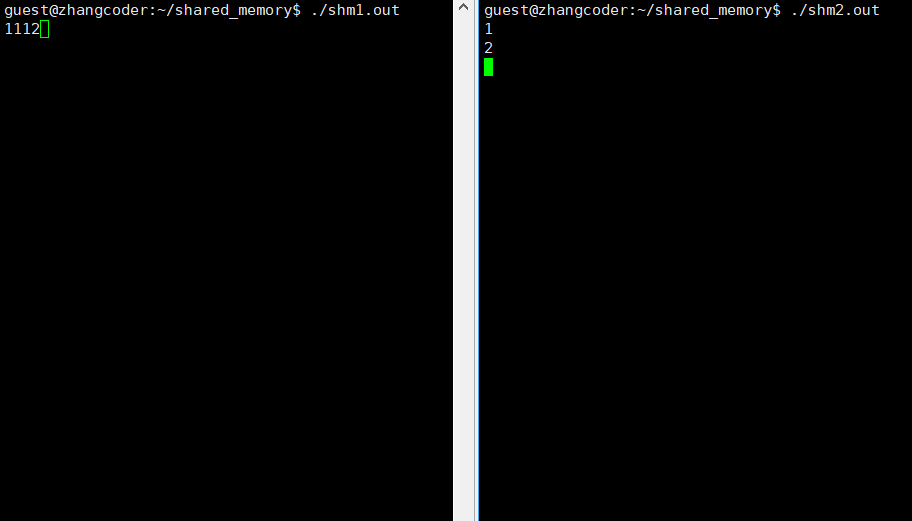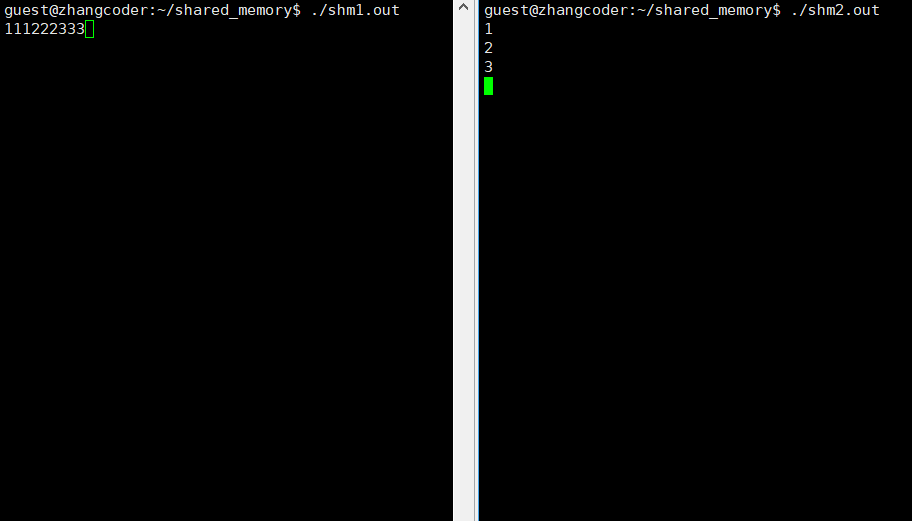
注意: 向共享内存中读写数据不需要系统调用,因为共享内存被操作系统映射到进程地址空间的共享区了,可以直接使用地址读写共享内存
shm2.cpp向共享内存写入用户输入的数据,shm1.cpp读取共享内存的数据
shm1.cpp写入:
cpp
#include <stdio.h>
#include <iostream>
#include "header.hpp"
int main()
{
//为了减小代码行数,系统调用的错误执行结果都没有判断
int shmid=get_new_shared_memory();
char* start_addr=(char*)shmat(shmid,nullptr,0);
for (;;)
{
sleep(1);
std::cout<<start_addr;
fflush(stdout);
}
shmdt(start_addr);
shmctl(shmid,IPC_RMID,nullptr);
return 0;
}shm2.cpp写入:
cpp
#include <stdio.h>
#include <iostream>
#include "header.hpp"
int main()
{
//为了减小代码行数,系统调用的错误执行结果都没有判断
int shmid=get_old_shared_memory();
char* start_addr=(char*)shmat(shmid,nullptr,0);
for (;;)
{
std::cin>>start_addr;
}
shmdt(start_addr);
return 0;
}运行结果:
本篇文章过长,到此结束,下篇继续讲