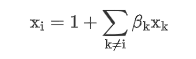为什么要做特征工程?
特征工程(Feature Engineering)是机器学习项目中最耗时、最依赖经验、但往往决定模型性能上限的关键步骤。机器学习模型(无论是线性模型、树模型还是神经网络)本质上只能理解数值和简单的模式,它无法直接"看懂"原始数据里的复杂含义。特征工程直接决定"信号 vs 噪声"比例,现实数据里 80% 是噪声(无关信息、冗余、错误),20% 是信号。 特征工程就是在放大信号、压制噪声。即使是深度学习,也只是自动学习特征组合,但它需要足够好的原材料才能学出好结果。
时间序列特征
- 切片原则 (常见窗口):
- 近30天 / 近60天 / 近90天 / 近180天 / 近360天
- 更细的:近7天、近14天、近45天、近120天等
- 更粗的:近1年、近2年、全部历史
- 切片方式 (最常见两种):
- 固定窗口:从观察点往前固定天数(如前30天、前60--90天)
- 滚动窗口:按月/按季度切(如申请前1个月、2个月、3个月)
缺失值处理
-
用户时间序列缺失值处理
-
优先考虑补零:大多数特征都是计数,缺失用0补充
-
可以填充-2、-1等
-
| 缺失值 | 处理 |
|---|---|
| 一般计数类特征 | 优先考虑用0填充 |
| 有风险趋势 | 按风险趋势填补 |
| 缺失数值过多 | 考虑新增是否缺失的特征列 |
| 有业务含义 | 填补业务默认值 |
特征组合
又叫特征交叉(Feature crossing),指不同特征之间基于常识、经验、数据挖掘技术进行分段组合实现特征构造,产生包含更多信息的新特征。
| 特征维度 | 男程序猿 | 女程序媛 |
|---|---|---|
| 青年 | 青年男程序猿 | 青年女程序媛 |
| 中年 | 中年男程序猿 | 中年女程序媛 |
代码实现
python
import pandas as pd
# 示例数据
df = pd.DataFrame({
'性别': ['男', '女', '男', '女', '男'],
'年龄段': ['青年', '中年', '青年', '中年', '中年'],
'职业': ['程序猿', '程序媛', '程序猿', '程序媛', '程序猿']
})
# 方法1:直接用 + 拼接(最直观)
df['特征组合1'] = df['性别'] + df['年龄段'] + df['职业']
print(df['特征组合1'])执行结果
python
0 男青年程序猿
1 女中年程序媛
2 男青年程序猿
3 女中年程序媛
4 男中年程序猿
Name: 特征组合1, dtype: object多值无序类别特征处理(把字符串 → 整数编号)
Onehot Encoding
代码实现
python
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 1. 创建模拟数据(假设我们有这些用户记录)
data = {
'用户ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'婚姻状态': ['未婚', '已婚', '离异', '未婚', '丧偶', '已婚', '离异', '未婚', '丧偶', '已婚'],
'是否逾期': [0, 1, 1, 0, 0, 1, 0, 0, 0, 1] # 0=正常,1=逾期
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
print("\n")
print("使用 pandas get_dummies 进行 One-Hot Encoding:")
df_pd_encoded = pd.get_dummies(df, columns=['婚姻状态'], prefix=['婚姻状态'], dtype=int)
print(df_pd_encoded)执行结果
python
原始数据:
用户ID 婚姻状态 是否逾期
0 1 未婚 0
1 2 已婚 1
2 3 离异 1
3 4 未婚 0
4 5 丧偶 0
5 6 已婚 1
6 7 离异 0
7 8 未婚 0
8 9 丧偶 0
9 10 已婚 1
使用 pandas get_dummies 进行 One-Hot Encoding:
用户ID 是否逾期 婚姻状态_丧偶 婚姻状态_已婚 婚姻状态_未婚 婚姻状态_离异
0 1 0 0 0 1 0
1 2 1 0 1 0 0
2 3 1 0 0 0 1
3 4 0 0 0 1 0
4 5 0 1 0 0 0
5 6 1 0 1 0 0
6 7 0 0 0 0 1
7 8 0 0 0 1 0
8 9 0 1 0 0 0
9 10 1 0 1 0 0Label Encoding
缺点:数据量少的情况下,某些数据可能有偏差
代码实现
python
import pandas as pd
from sklearn.preprocessing import LabelEncoder
# 1. 创建模拟数据(假设我们有这些用户记录)
data = {
'用户ID': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10],
'婚姻状态': ['未婚', '已婚', '离异', '未婚', '丧偶', '已婚', '离异', '未婚', '丧偶', '已婚'],
'是否逾期': [0, 1, 1, 0, 0, 1, 0, 0, 0, 1] # 0=正常,1=逾期
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
print("\n")
# 2. 使用 LabelEncoder 对 '婚姻状态' 进行编码
le = LabelEncoder()
df['婚姻状态_编码'] = le.fit_transform(df['婚姻状态'])
print("Label Encoding 后的数据:")
print(df)执行结果
python
原始数据:
用户ID 婚姻状态 是否逾期
0 1 未婚 0
1 2 已婚 1
2 3 离异 1
3 4 未婚 0
4 5 丧偶 0
5 6 已婚 1
6 7 离异 0
7 8 未婚 0
8 9 丧偶 0
9 10 已婚 1
Label Encoding 后的数据:
用户ID 婚姻状态 是否逾期 婚姻状态_编码
0 1 未婚 0 2
1 2 已婚 1 1
2 3 离异 1 3
3 4 未婚 0 2
4 5 丧偶 0 0
5 6 已婚 1 1
6 7 离异 0 3
7 8 未婚 0 2
8 9 丧偶 0 0
9 10 已婚 1 1WOE Encoding**(** 风控/信用评分中最常用、最经典的分箱方法之一**)**
WOE(Weight of Evidence) 反映单特征在好坏用户区分度的度量,WOE编码是一种用于二分类问题的编码方法,通过计算每个类别的证据权重来表示其与目标变量之间的关系。
优势:WOE越大,bad rate越高,也就是说,通过WOE变换,特征值不仅仅代表一个分类,还代表了这个分类的权重。WOE可以把相对于bad rate显现非线性的特征转换为线性的,且对波动不敏感。遇到异常数据亦能平稳表现。
应用场景:该方法通常用于分类建模中的特征工程,特别是在信用风险评估、营销模型和欺诈检测等领域。该方法的目标是将分类变量转换为数值变量,以便在统计建模中使用。
计算公式:
WOEᵢ = ln(好客户占比ᵢ / 坏客户占比ᵢ)
WOEᵢ = ln((Goodᵢ/Goodₜ) / (Badᵢ/Badₜ))
WOEᵢ = ln(Goodᵢ/Badᵢ) + ln(Badₜ/Goodₜ)
好用户比例/坏用户比例
| 婚姻状态 | Good | Bad | G-B | ln(G/B) | WOE |
|---|---|---|---|---|---|
| 未婚 | 30% | 20% | 10% | 0.405 | 0.405 |
| 已婚 | 40% | 10% | 30% | 1.386 | 1.386 |
| 离异 | 10% | 40% | -30% | -1.386 | -1.386 |
| 丧偶 | 20% | 30% | -10% | -0.405 | -0.405 |
| 总计 | 100% | 100% |
代码实现
python
import pandas as pd
import numpy as np
import toad
# 1. 创建示例数据(扩大样本量,使结果有意义)
np.random.seed(42)
n_samples = 1000
data = {
'用户ID': range(1, n_samples + 1),
'婚姻状态': np.random.choice(['未婚', '已婚', '离异', '丧偶'], n_samples, p=[0.4, 0.3, 0.2, 0.1]),
'年龄': np.random.randint(20, 60, n_samples),
'收入': np.random.randint(3000, 50000, n_samples),
'工作年限': np.random.randint(0, 30, n_samples),
'是否有房': np.random.choice(['是', '否'], n_samples, p=[0.6, 0.4]),
'是否有车': np.random.choice(['是', '否'], n_samples, p=[0.5, 0.5]),
'教育水平': np.random.choice(['初中', '高中', '大专', '本科', '硕士'], n_samples,
p=[0.1, 0.2, 0.3, 0.3, 0.1]),
}
# 创建目标变量(逾期标签),与特征有一定的相关性
df = pd.DataFrame(data)
# 根据特征构造逾期概率
df['逾期风险'] = (
0.3 * (df['婚姻状态'] == '离异').astype(int) +
0.2 * (df['婚姻状态'] == '丧偶').astype(int) +
0.1 * (df['婚姻状态'] == '未婚').astype(int) +
-0.2 * (df['婚姻状态'] == '已婚').astype(int) +
0.01 * (60 - df['年龄']) +
0.02 * (30 - df['工作年限']) +
-0.0001 * df['收入'] +
0.2 * (df['是否有房'] == '否').astype(int) +
0.1 * (df['是否有车'] == '否').astype(int) +
np.random.normal(0, 0.1, n_samples)
)
# 转换为二分类标签(0=好客户,1=坏客户)
df['bad_ind'] = (df['逾期风险'] > df['逾期风险'].quantile(0.7)).astype(int)
# 删除中间变量
df = df.drop('逾期风险', axis=1)
print("数据集形状:", df.shape)
print("\n目标变量分布:")
print(df['bad_ind'].value_counts(normalize=True))
print("\n前5行数据:")
print(df.head())
print("=" * 60)
print("方式1:分箱 + WOE 两步完成")
print("=" * 60)
# 1. 特征筛选(可选,但推荐)
# 计算IV值,筛选有预测能力的特征
quality_report = toad.quality(df, 'bad_ind', iv_only=True)
good_features = quality_report[quality_report['iv'] > 0.02].index.tolist()
good_features = [f for f in good_features if f != 'bad_ind'] # 排除目标变量
print(f"\n筛选后的特征(IV > 0.02): {good_features}")
# 2. 初始化分箱器
combiner = toad.transform.Combiner()
#设置分箱边界,等价于fit
# adj_bin = {'duration.in.month': [9, 12, 18, 33]}
# c2 = toad.transform.Combiner()
# c2.set_rules(adj_bin)
# 3. 分箱训练
# 方法:decisiontree(决策树分箱)、chi(卡方分箱)、quantile(等频)、step(等距)
combiner.fit(
df[good_features + ['bad_ind']], # 训练数据
y='bad_ind', # 目标变量
method='chi', # 卡方分箱(评分卡最常用)
min_samples=0.05, # 每箱最少样本比例
n_bins=5 # 最大分箱数
)
# 4. 查看分箱结果
print("\n分箱结果(婚姻状态):")
print(combiner.export()['婚姻状态'])
# 5. 应用分箱转换
df_binned = combiner.transform(df[good_features])
print("\n分箱后的数据(前5行):")
print(pd.concat([df_binned.head(), df['bad_ind'].head()], axis=1))
# 6. WOE转换
transformer = toad.transform.WOETransformer()
df_woe = transformer.fit_transform(df_binned, df['bad_ind'])
print("\nWOE编码后的数据(前5行):")
print(pd.concat([df_woe.head(), df['bad_ind'].head()], axis=1))执行结果
python
数据集形状: (1000, 9)
目标变量分布:
bad_ind
0 0.7
1 0.3
Name: proportion, dtype: float64
前5行数据:
用户ID 婚姻状态 年龄 收入 工作年限 是否有房 是否有车 教育水平 bad_ind
0 1 未婚 31 26561 27 否 是 大专 0
1 2 丧偶 35 27817 4 是 是 高中 0
2 3 离异 43 23281 16 是 是 大专 0
3 4 已婚 38 31671 4 是 否 大专 0
4 5 未婚 27 28364 3 否 否 高中 0
============================================================
分箱 + WOE 两步完成
============================================================
筛选后的特征(IV > 0.02): ['收入', '用户ID', '工作年限', '年龄', '婚姻状态', '教育水平']
分箱结果(婚姻状态):
[['已婚'], ['丧偶'], ['未婚'], ['离异']]
分箱后的数据(前5行):
收入 用户ID 工作年限 年龄 婚姻状态 教育水平 bad_ind
0 4 0 4 1 2 2 0
1 4 0 1 1 1 1 0
2 4 0 2 2 3 2 0
3 4 0 1 1 0 2 0
4 4 0 0 1 2 1 0
WOE编码后的数据(前5行):
收入 用户ID 工作年限 年龄 婚姻状态 教育水平 bad_ind
0 -5.501841 -0.661599 -0.100910 0.059509 -0.003396 0.028646 0
1 -5.501841 -0.661599 0.972461 0.059509 -0.048086 -0.192126 0
2 -5.501841 -0.661599 0.150398 -0.640779 0.503526 0.028646 0
3 -5.501841 -0.661599 0.972461 0.059509 -0.359656 0.028646 0
4 -5.501841 -0.661599 0.075898 0.059509 -0.003396 -0.192126 0区别对比
| 编码 | 优势 | 劣势 |
|---|---|---|
| Onehot Encoding | 简单易处理、稳定、无需归一化、不依赖历史数据 | 数据过于稀疏 |
| Label Encoding | 区分效果好,维度小 | 需统计历史数据、不稳定、需要归一化 |
| WOE Encoding | 区分效果好,维度小,不需要归一化 | 需统计历史数据、不稳定 |
特征变换(连续值变分类数值)
常用分箱方法:等频分箱、等距分箱 、卡方分箱、决策树分箱、聚类分箱
等频分箱

-
按数据的分布,均匀切分,每个箱体里的样本数基本一样
-
在样本少的时候泛化性较差
-
在样本不均衡时可能无法分箱
等距分箱

-
按数据的特征值的间距均匀切分,每个箱体的数值距离一样
-
一定可以分箱
-
无法保证箱体样本数均匀
卡方分箱( 风控/信用评分中最常用、最经典的分箱方法之一**)**
使用卡方检验确定最优分箱阈值
-
将数据按等频或等距分箱后,计算卡方值,将卡方值较小的两个相邻箱体合并
使得不同箱体的好坏样本比例区别放大,容易获得高IV
-
卡方分箱是利用独立性检验来挑选箱划分节点的阈值。卡方分箱的过程可以拆分为初始化和合并两步
-
初始化:根据连续变量值大小进行排序,构建最初的离散化
-
合并:遍历相邻两项合并的卡方值,将卡方值最小的两组合并,不断重复直到满足分箱数目要求
-

| 22-35 | (35-45] | (45-55] | (55-65] | 总计 |
|-------------|----------------|--------------|--------------|----------------|-----|
| good | 3 | 2 | 2 | 1 | 8 |
| bad | 1 | 2 | 2 | 3 | 8 |
| p | | | | | 50% |
| p(good+bad) | 2 | 2 | 2 | 2 | - |
| chi2 | (1-2)^2/2=1/2 | (2-2)^2/2=0 | (2-2)^2/2=0 | (3-2)^2/2=1/2 | - |
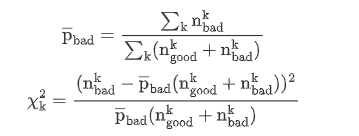
决策树分箱
本质 :用单变量决策树,以目标变量 y 为监督信号,对连续特征 x 进行最优切分,得到的分裂点就是分箱边界。
怎么做的?
- 把特征 x 和目标 y 一起喂给一棵单变量决策树(只用 x 一个特征)。
- 树会自动寻找最能区分 y(坏好/0 1)的切点(用 Gini/Entropy/卡方等作为分裂准则)。
- 树可以设置最大深度(max_depth)或最小叶子样本数(min_samples_leaf),控制最终箱子数量。
- 最终取树的叶子节点边界作为分箱切点。
优点
- 利用了目标变量 y:分出来的箱子与 y 的相关性最强(IV 值往往最高)。
- 自动处理非线性:找到的切点天然捕捉了 x 与 y 的非线性关系。
- 坏样本率趋势更单调:因为树本身就是在优化区分度。
- 对异常值鲁棒:极端值会被单独切成箱或合并。
缺点
- 计算量稍大(比等频/等距慢)。
- 容易过拟合:如果不限制树深度,可能会切出太多箱子。
- 需要目标 y:属于有监督分箱,不能用于无标签场景。
聚类分箱
本质:用无监督聚类算法(如 K-means、DBSCAN),把连续值聚成 k 个簇,每个簇就是一个箱子。
怎么做的?
- 把特征 x 的值(可以是标准化后的)喂给聚类算法。
- 算法自动把相似的数值聚成一类(基于距离)。
- 聚类完成后,把每个簇的范围作为分箱区间(通常取簇内 min/max 或质心附近)。
- 可以设置簇数 k(箱子数),或者用轮廓系数自动选 k。
优点
- 无监督:不需要目标 y,适合无标签场景。
- 能发现自然分组:如果数据本身有明显的聚类结构(比如收入天然分成低中高),聚类会自动找到。
- 对分布敏感:极端值可能单独成簇,天然抗噪。
缺点
- 聚类不稳定:K-means 受初始点影响大,不同随机种子结果可能不同。
- 需要选 k:箱子数不好控制,k 太小区分度低,k 太大箱子不稳定。
- 解释性一般:聚类边界可能不直观,不像等频/决策树那么"业务友好"。
- 与目标无关:分箱不一定和 y 相关,IV 值可能不如有监督方法高。
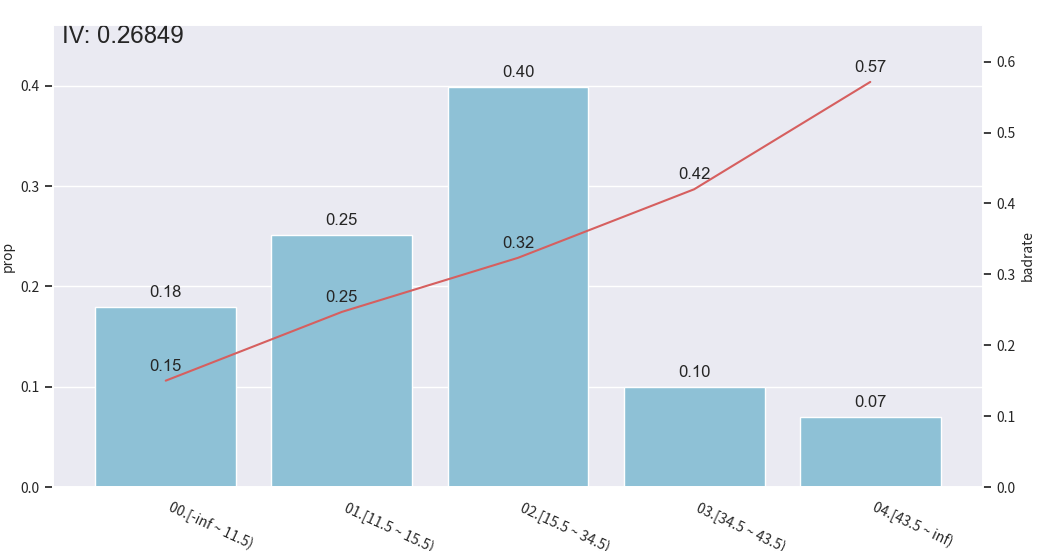
使用toad库进行分箱处理
python
import pandas as pd
import numpy as np
import toad
import matplotlib.pyplot as plt
from toad.plot import bin_plot
data = pd.read_csv('./data/germancredit.csv')
# data['creditability'] = data['creditability'].replace({'good': 0, 'bad': 1})
# 或者更稳妥:
data['creditability'] = data['creditability'].map({'good': 0, 'bad': 1})
for method in ['chi', 'dt', 'quantile', 'step', 'kmeans']:
c2 = toad.transform.Combiner()
c2.fit(
data[['duration.in.month', 'creditability']],
y='creditability',
method=method,
n_bins=5
)
bin_plot(
c2.transform(data[['duration.in.month', 'creditability']], labels=True),
x='duration.in.month',
target='creditability'
)
plt.show()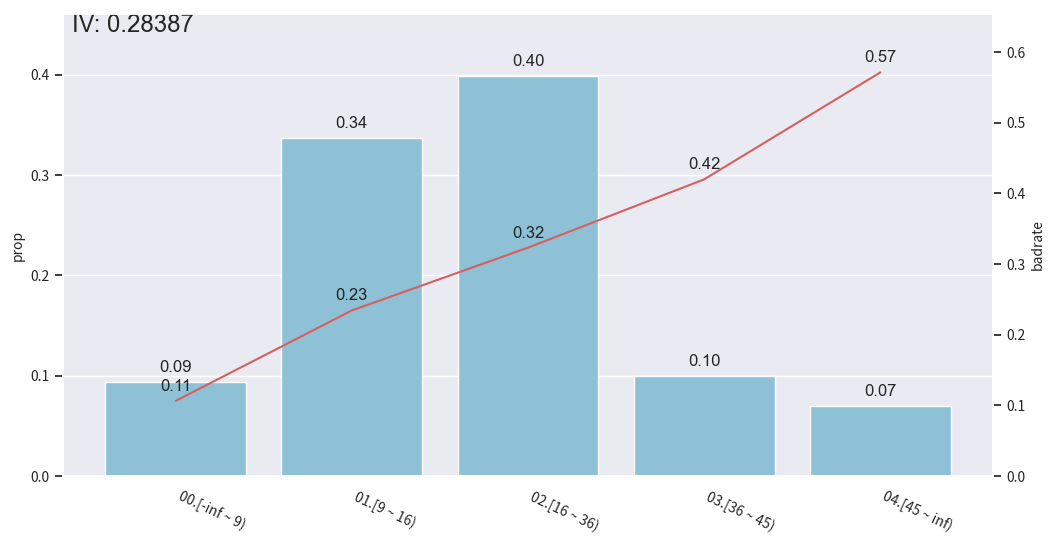
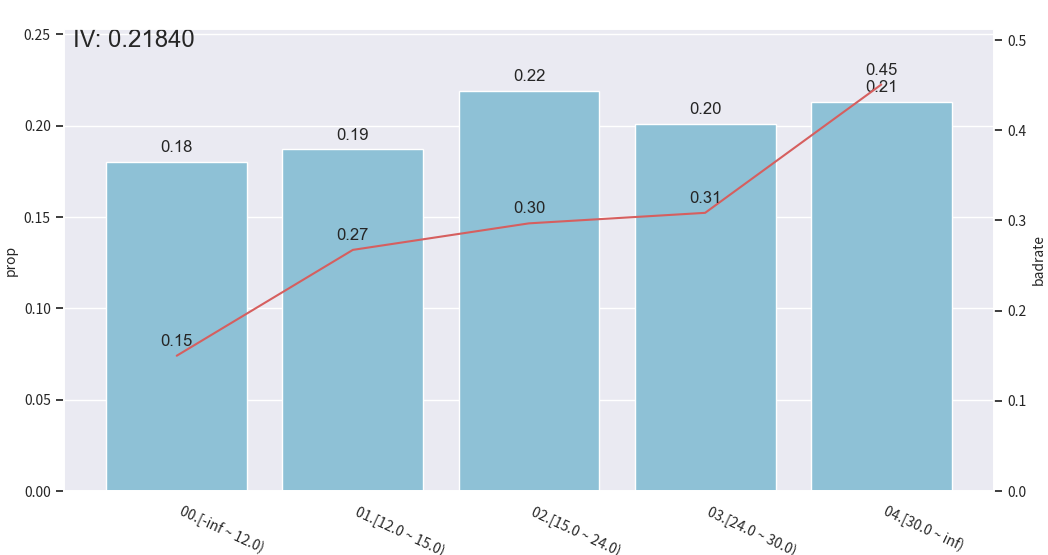
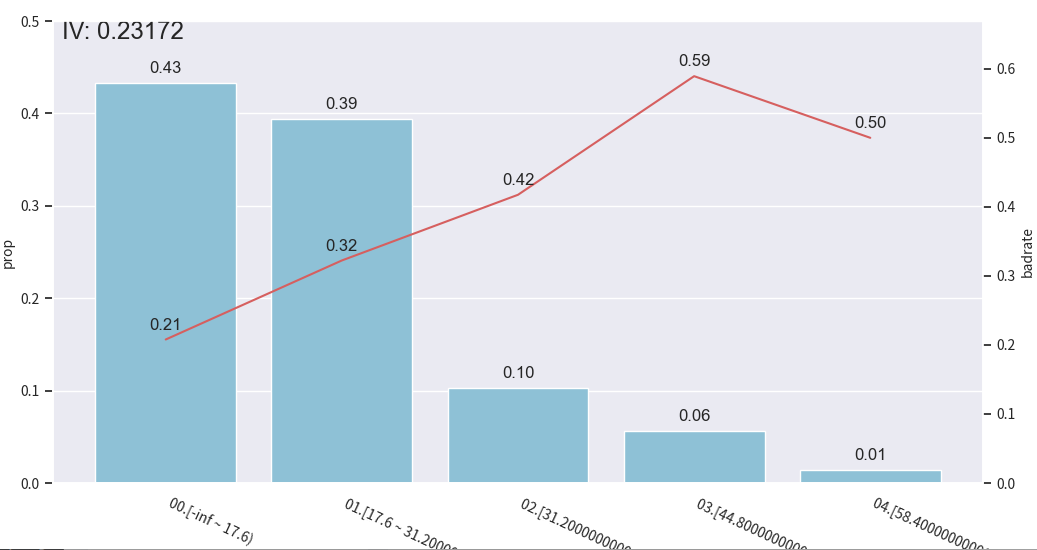
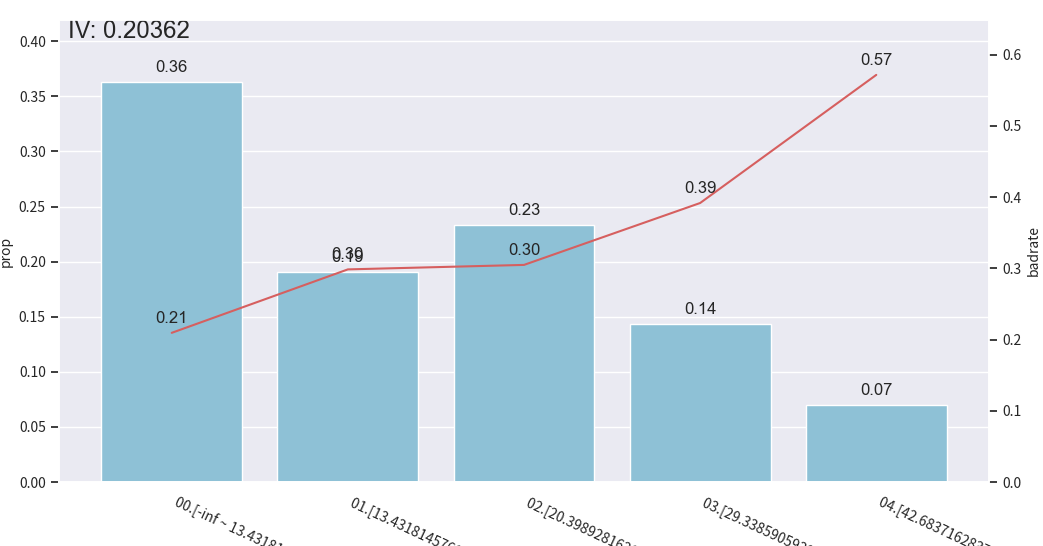
可解释性
模型的可解释性没有准确的定义,凡是可以协助人理解模型决策过程和结果的方法,都可称之为模型的可解释性。
我们常说一个模型是"黑盒"模型,就是指该模型可解释性差。模型的构建者和使用者无法准确梳理模型的决策依据。
如果某个模型可解释性好,则是说我们能通过某些方法理解模型结果产生的逻辑。
一般来说,算法越复杂,一般精度越好,可解释性越差。
按照可解释性的强弱关系,将算法分类如下:
-
第一梯度:线性回归、逻辑回归
-
第二梯度:集成学习(结果是多个树共同决定的)
-
第三梯度:支持向量机(把数据往高维空间映射,数据会失真)
什么是好特征
从几个角度衡量:覆盖度,区分度,相关性,稳定性
覆盖度
-
采集类,授权类,第三方数据在使用前都会分析覆盖度
-
采集类 :如APP list (Android 手机 90%)
-
授权类:如爬虫数据(20% 30%覆盖度)GPS (有些产品要求必须授权)
-
-
一般会在两个层面上计算覆盖度(覆盖度 = 有数据的用户数/全体用户数)
-
全体存量客户
-
全体有信贷标签客户
-
-
覆盖度可以衍生两个指标:缺失率,零值率
-
缺失率:一般就是指在全体有标签用户上的覆盖度
-
零值率:很多信贷类数据在数据缺失时会补零,所以需要统计零值率
-
-
业务越来越成熟,覆盖度可能会越来愈好,可以通过运营策略提升覆盖度
总结:覆盖度 = 非空的样本数/总的样本数。
代码
python
import pandas as pd
df = pd.DataFrame({
'A': [5, 91, 3],
'B': [90, 15, 66],
'C': [93, 27, 3],
'bad_ind': [0, 1, 0]
})
# 加一些缺失值模拟真实场景
df.loc[0, 'A'] = None
df.loc[1, 'B'] = None
df.loc[2, 'C'] = None
print("原始数据:")
print(df)
# 计算覆盖度
coverage = 1 - df.isna().mean()
coverage = df.notna().mean()
print("\n覆盖度(每列):")
print(coverage.sort_values(ascending=False))
print("\n覆盖度百分比:")
print((coverage * 100).round(2).astype(str) + '%')执行结果
python
原始数据:
A B C bad_ind
0 NaN 90.0 93.0 0
1 91.0 NaN 27.0 1
2 3.0 66.0 NaN 0
覆盖度(每列):
bad_ind 1.000000
A 0.666667
B 0.666667
C 0.666667
dtype: float64
覆盖度百分比:
A 66.67%
B 66.67%
C 66.67%
bad_ind 100.0%区分度
区分度是评估一个特征对好坏用户的区分性能的指标。
-
可以把单特征当做模型,使用AUC, KS来评估特征区分度
-
在信贷领域,常用Information Value (IV)来评估单特征的区分度
-
Information Value刻画了一个特征对好坏用户分布的区分程度
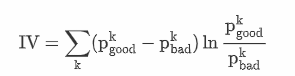
-
IV值越大,区分程度越大
-
IV值越小,区分程度越小
- IV值最后ln的部分跟WOE是一样的
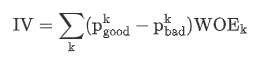
- IV计算举例(数据为了方便计算填充,不代表实际业务)
婚配 good bad p_good p_bad p_good-p_bad ln(p_g/p_bad) IV 未婚 40 30 50% 37.5% 0.125 0.2877 0.036 已婚 30 40 37.5% 50% -0.125 -0.2877 0.036 其他 10 10 12.5% 12.5% 0 0 0 总计 80 80 100% 100% - - 0.072 -
IV<0.02 区分度小 建模时不用 (xgboost,lightGMB 对IV值要求不高) IV 0.02,0.5 区分度大 可以放到模型里 IV > 0.5 单独取出作为一条规则使用,不参与模型训练
-
模型中尽可能使用区分度相对较弱的特征,将多个弱特征组合,得到评分卡模型
-
连续变量的IV值计算,先离散化再求IV,跟分箱结果关联很大(一般分3-5箱)
-
-
代码
python
import pandas as pd
import toad
df = pd.DataFrame({
'A': [5, 91, 3],
'B': [90, 15, 66],
'C': [93, 27, 3],
'bad_ind': [0, 1, 0] # 假设 0=good, 1=bad
})
quality = toad.quality(df, target='bad_ind')
# 打印结果(按 IV 降序排序)
print(quality.sort_values('iv', ascending=False))
# 只看 IV 大于 0.02 的特征
print(quality[quality['iv'] >= 0.02])
# 还可以导出到 Excel
quality.to_excel('feature_quality.xlsx')执行结果
python
iv gini entropy unique
C 1.039721 0.333333 0.462098 3.0
A 0.346574 0.000000 0.000000 3.0
B 0.346574 0.000000 0.000000 3.0
iv gini entropy unique
C 1.039721 0.333333 0.462098 3.0
A 0.346574 0.000000 0.000000 3.0
B 0.346574 0.000000 0.000000 3.0小结:
IV
- **含义:**衡量这个特征对好坏样本(bad_ind = 0/1)的整体区分能力。IV 值越高,说明这个特征把好用户和坏用户分得越开。
- IV < 0.02:区分度极弱,几乎无用,可删除
- 0.02 ≤ IV < 0.1:弱区分,可用但贡献小
- 0.1 ≤ IV < 0.3:中等偏强,常用特征
- 0.3 ≤ IV < 0.5:强区分,核心特征
- IV ≥ 0.5:极强区分,通常单独做规则(不进模型),否则容易过拟合
Gini
- **含义:**衡量特征在当前数据集上不纯度(即把样本分成好坏两类的混乱程度)。Gini 值越接近 0,说明这个特征把样本分得越纯(区分度越高);越接近 0.5,越混乱。
- Gini ≈ 0:极纯,几乎完美区分
- Gini ≈ 0.5:完全随机,没区分度
- C 的 Gini = 0.333333 → 中等偏好(有一定区分度)
- A 和 B 的 Gini = 0.000000 → 极纯(但样本太小导致的假象)
Entropy
- **含义:**和 Gini 类似,也是衡量不纯度的指标。Entropy 值越小,说明样本越纯(区分度越高);最大值为 1(完全混乱)。
- Entropy ≈ 0:极纯
- Entropy ≈ 1:完全随机
- C 的 Entropy = 0.462098 → 中等偏好
- A 和 B 的 Entropy = 0.000000 → 极纯(样本太小导致)
unique(唯一值数量)
- 含义:这个特征有多少个不同的取值。
- 如果 unique 很小(<10),可能是类别特征或高度离散的数值特征
- 如果 unique 很大(>100),可能是连续特征,需要分箱
- A、B、C 都是 3.0 → 每个特征只有 3 个不同值(因为数据只有 3 行,每个值都不一样)
相关性
对线性回归模型,有一条基本假设是自变量x1,x2,...,xp之间不存在严格的线性关系
-
先计算特征列之间相关性,把相关性高的列去掉
-
计算特征列和标签列之间相关性,把相关性低的列去掉
-
需要对相关系数较大的特征进行筛选,只保留其中对标签区分贡献度最大的特征,即保留IV较大的
-
皮尔逊相关系数,斯皮尔曼相关系数,肯德尔相关系数
-
如何选择:
-
考察两个变量的相关关系,首先得清楚两个变量都是什么类型的
- 连续型数值变量,无序分类变量、有序分类变量
-
连续型数值变量,如果数据具有正态性,此时首选Pearson相关系数,如果数据不服从正态分布,此时可选择Spearman和Kendall系数
-
两个有序分类变量相关关系,可以使用Spearman相关系数
-
一个分类变量和一个连续数值变量,可以使用kendall相关系数
-
总结:就适用性来说,kendall > spearman > pearson
-
代码
可以使用toad库来过滤大量的特征,高缺失率、低iv和高度相关的特征一次性过滤掉。
python
import pandas as pd
import toad
df = pd.DataFrame({
'A': [5, 91, 3],
'B': [90, 15, 66],
'C': [93, 27, 3],
'bad_ind': [0, 1, 0] # 假设 0=good, 1=bad
})
print(df.corr()) # 皮尔逊
print(df.corr('spearman')) # 斯皮尔曼
print(df.corr('kendall')) # 肯德尔
# data = pd.read_csv('./data/germancredit.csv')
# data.replace({'good': 0, 'bad': 1}, inplace=True)
# (1000,21)
# print(data.shape)
# 缺失率大于0.5,IV值小于0.05,相关性大于0.7来进行特征筛选
selected_data, drop_list = toad.selection.select(df, target='bad_ind', empty=0.5, iv=0.05, corr=0.7,
return_drop=True)
print('保留特征:', selected_data.shape[1], selected_data, '缺失删除:', len(drop_list['empty']), '低iv删除:',
len(drop_list['iv']),
'高相关删除:', len(drop_list['corr']), drop_list['corr'])执行结果
python
A B C bad_ind
A 1.000000 -0.943228 -0.240882 0.999802
B -0.943228 1.000000 0.549571 -0.949653
C -0.240882 0.549571 1.000000 -0.260153
bad_ind 0.999802 -0.949653 -0.260153 1.000000
A B C bad_ind
A 1.000000 -0.500000 0.5 0.866025
B -0.500000 1.000000 0.5 -0.866025
C 0.500000 0.500000 1.0 0.000000
bad_ind 0.866025 -0.866025 0.0 1.000000
A B C bad_ind
A 1.000000 -0.333333 0.333333 0.816497
B -0.333333 1.000000 0.333333 -0.816497
C 0.333333 0.333333 1.000000 0.000000
bad_ind 0.816497 -0.816497 0.000000 1.000000
(1000, 21)
保留特征: 3 A C bad_ind
0 5 93 0
1 91 27 1
2 3 3 0 缺失删除: 0 低iv删除: 0 高相关删除: 1 ['B']显示结果: 保留特征: 12 缺失删除: 0 低iv删除: 9 高相关删除: 0
小结:
Pearson 相关系数(皮尔逊,默认)
- A 与 bad_ind = 0.866025 → 强正相关(比 Pearson 低,但还是很强) A 值排名越高,bad_ind 排名越高(坏用户概率越高)。
- B 与 bad_ind = -0.866025 → 强负相关 B 值排名越高,bad_ind 排名越低(好用户概率越高)。
- C 与 bad_ind = 0.000000 → 完全无关 C 的排序和 bad_ind 没关系。
Spearman 相关系数(斯皮尔曼)
- A 与 bad_ind = 0.866025 → 强正相关(比 Pearson 低,但还是很强) A 值排名越高,bad_ind 排名越高(坏用户概率越高)。
- B 与 bad_ind = -0.866025 → 强负相关 B 值排名越高,bad_ind 排名越低(好用户概率越高)。
- C 与 bad_ind = 0.000000 → 完全无关 C 的排序和 bad_ind 没关系。
Kendall 相关系数(肯德尔)
- A 与 bad_ind = 0.816497 → 强正相关
- B 与 bad_ind = -0.816497 → 强负相关
- C 与 bad_ind = 0.000000 → 完全无关
**删除特征'B'。**当两个或多个特征高度相关(比如相关系数 > 0.7 或 0.8),它们携带的信息几乎一样。 模型(尤其是线性模型如逻辑回归、评分卡)会:
- 系数不稳定(一个小变化导致系数翻天覆地)
- 解释性变差(业务问"收入重要还是年收入重要?"答不上来)
- 过拟合风险增加(模型学到噪声)
**保留了无关特征'C'。**IV 阈值是 0.05,但数据 IV 异常高(样本太小)
- 在真实数据里,C 的 IV 应该很低(接近 0),但你只有 3 行样本,toad 计算 IV 时容易出现极端值(比如 C 的 IV 被算成 1.039721)。
- IV = 1.039721 > 0.05,所以没触发"IV < 0.05 删"的条件。
稳定性
特征稳定性主要通过计算不同时间段内同一类用户特征的分布的差异来评估
-
常用的特征稳定性的度量有Population Stability Index (群体稳定性指标,PSI)
-
当两个时间段的特征分布差异大,则PSI大
-
当两个时间段的特征分布差异小,则PSI小
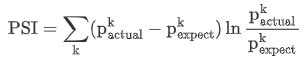
-
IV是评估好坏用户分布差异的度量
-
PSI是评估两个时间段特征分布差异的度量
-
都是评估分布差异的度量,并且公式其实一模一样,只是符号换了而已
代码
python
import pandas as pd
import numpy as np
import toad
import matplotlib.pyplot as plt
def calculate_psi_with_toad(df_expect, df_actual, feature, target='target', n_bins=10):
"""
用 toad 分箱 + 计算 PSI
df_expect: 参考分布(训练集)
df_actual: 新分布(测试集/新批次)
feature: 特征名
target: 目标列名(可选,用于分箱时监督)
n_bins: 分箱数量(默认 10)
"""
# 1. 用 toad 的 Combiner 对参考集进行分箱(用 chi 或 dt 都行)
combiner = toad.transform.Combiner()
combiner.fit(
df_expect[[feature, target]],
y=target,
method='chi', # 或 'dt' 'quantile'
n_bins=n_bins
)
# 2. 应用分箱规则到两个数据集(得到箱子标签)
df_expect_binned = combiner.transform(df_expect[[feature]], labels=True)
df_actual_binned = combiner.transform(df_actual[[feature]], labels=True)
# 3. 计算每个箱子的占比
expect_counts = df_expect_binned[feature].value_counts(normalize=True).sort_index()
actual_counts = df_actual_binned[feature].value_counts(normalize=True).sort_index()
# 统一索引(有些箱子可能在新集里为空)
all_bins = expect_counts.index.union(actual_counts.index)
expect_prop = expect_counts.reindex(all_bins, fill_value=0)
actual_prop = actual_counts.reindex(all_bins, fill_value=0)
# 加小 eps 避免 ln(0)
eps = 1e-10
expect_prop += eps
actual_prop += eps
# 4. 计算 PSI
psi = np.sum((actual_prop - expect_prop) * np.log(actual_prop / expect_prop))
# 5. 可视化对比(可选)
plt.figure(figsize=(10, 5))
plt.bar(range(len(all_bins)), expect_prop, alpha=0.5, label='Expect (Train)')
plt.bar(range(len(all_bins)), actual_prop, alpha=0.5, label='Actual (Test)')
plt.xticks(range(len(all_bins)), all_bins, rotation=45, ha='right')
plt.title(f'{feature} Distribution Comparison\nPSI = {psi:.4f}')
plt.xlabel('Bins')
plt.ylabel('Proportion')
plt.legend()
plt.tight_layout()
plt.show()
return psi, all_bins
# 准备两个小数据集(模拟 train 和 test)
df_train = pd.DataFrame({
'age': [25, 30, 35, 40, 45, 50, 55, 60],
'income': [5000, 6000, 7000, 8000, 9000, 10000, 11000, 12000],
'target': [0, 0, 0, 1, 0, 1, 1, 1] # 0=good, 1=bad
})
df_test = pd.DataFrame({
'age': [26, 32, 36, 42, 46, 52, 56, 62],
'income': [5200, 6200, 7200, 8200, 9200, 10200, 11200, 12200],
'target': [0, 0, 1, 1, 0, 1, 1, 0] # 模拟新批次
})
# 调用函数评估 'age' 特征的稳定性
psi_value, bins = calculate_psi_with_toad(
df_expect=df_train,
df_actual=df_test,
feature='age', # 要评估的特征
target='target', # 目标列(用于监督分箱)
n_bins=5 # 分箱数量
)
print(f"特征 'age' 的 PSI 值: {psi_value:.4f}")
print("分箱区间:", bins)执行结果
python
特征 'age' 的 PSI 值: 0.0000
分箱区间: Index(['00.[-inf ~ 40)', '01.[40 ~ 45)', '02.[45 ~ 50)', '03.[50 ~ inf)'], dtype='object', name='age')小结:
PSI = 0.0000 → 两个分布几乎完全一致,特征在参考集(expect/train)和新集(actual/test)之间的分布没有偏移,稳定性极高。
PSI 判断标准(风控/模型监控通用):
| PSI 值范围 | 含义 | 解释与建议 |
|---|---|---|
| PSI < 0.05 | 非常稳定 | 特征分布几乎没变,放心使用 |
| 0.05 ≤ PSI < 0.1 | 基本稳定 | 轻微偏移,可接受,继续观察 |
| 0.1 ≤ PSI < 0.25 | 轻微偏移,需要关注 | 可能有轻微漂移,建议定期监控 |
| 0.25 ≤ PSI < 0.5 | 中度偏移,风险较高 | 特征可能开始不稳定,考虑重新分箱或调查 |
| PSI ≥ 0.5 | 严重偏移,分布已漂移 | 特征很可能失效,建议替换或重新训练模型 |
多特征筛选
-
当我们构建了大量特征时,接下来的调整就是筛选出合适的特征进行模型训练
-
过多的特征会导致模型训练变慢,学习所需样本增多,计算特征和存储特征成本变高
-
常用的特征筛选方法
-
星座特征
-
Boruta
-
方差膨胀系数
-
递归特征消除
-
L1惩罚项
-
星座特征
-
星座是大家公认没用的特征,区分度低于星座的特征可以认为是无用特征
-
把所有特征加上星座特征一起做模型训练
-
拿到特征的重要度排序
-
多次训练的重要度排序都低于星座的特征可以剔除
-
Boruta
-
Boruta算法是一种特征选择方法,使用特征的重要性来选取特征
-
安装:pip install Boruta -i https://pypi.tuna.tsinghua.edu.cn/simple/
-
原理
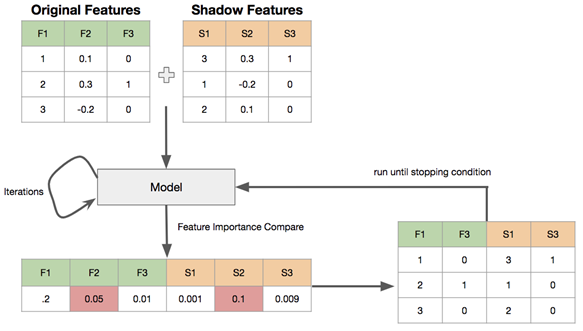
-
创建阴影特征 (shadow feature) : 对每个真实特征R,随机打乱顺序,得到阴影特征矩阵S,拼接到真实特征后面,构成新的特征矩阵N = R, S
-
用新的特征矩阵N作为输入,训练模型,能输出feature_importances_的模型,如RandomForest, lightgbm,xgboost都可以,得到真实特征和阴影特征的feature importances,
-
取阴影特征feature importance的最大值S_max,真实特征中feature importance小于S_max的,被认为是不重要的特征
-
删除不重要的特征,重复上述过程,直到满足条件
代码实现
python
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from boruta import BorutaPy
import warnings
# 忽略 boruta 的 FutureWarning(可选)
warnings.filterwarnings("ignore", category=FutureWarning)
# 1. 加载 iris 数据(多分类示例,实际风控通常是二分类)
iris = load_iris()
X = pd.DataFrame(iris.data, columns=iris.feature_names)
y = iris.target # 0,1,2 三类
print("原始特征:", X.columns.tolist())
print("样本数:", X.shape[0], "特征数:", X.shape[1])
print("\n")
# 2. 定义随机森林分类器(建议 class_weight='balanced' 如果是二分类不平衡)
rf = RandomForestClassifier(
n_jobs=-1, # 使用所有 CPU 核心
class_weight='balanced', # 处理类别不平衡(可选)
max_depth=5, # 限制深度,避免过拟合
random_state=42
)
# 3. 初始化 BorutaPy
# n_estimators='auto':自动决定树的数量(推荐)
# max_iter=100:最多迭代 100 次(可调大一些)
# perc=100:严格模式,只保留比 shadow 特征更好的
boruta_selector = BorutaPy(
rf,
n_estimators='auto',
verbose=2, # 打印详细过程(0=安静,1=简单,2=详细)
random_state=42,
max_iter=100,
perc=100 # 100=严格,90=宽松
)
# 4. 运行 Boruta
print("开始运行 BorutaPy...")
boruta_selector.fit(X.values, y)
# 5. 输出结果
# support_:True 表示被选中的重要特征
selected_features = X.columns[boruta_selector.support_].tolist()
print("\n=== BorutaPy 筛选结果 ===")
print("selected_features = ", selected_features)
print("\n总共筛选出重要特征数量:", len(selected_features) )
# 6. 可视化重要性排名(可选)
importances = boruta_selector.ranking_
feature_ranking = pd.DataFrame({
'feature': X.columns,
'ranking': importances
}).sort_values('ranking')
print("\n特征排名(ranking 越小越重要,1 表示确认重要):")
print(feature_ranking)执行结果
python
原始特征: ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
样本数: 150 特征数: 4
开始运行 BorutaPy...
Iteration: 1 / 100
Confirmed: 0
Tentative: 4
Rejected: 0
...
Iteration: 8 / 100
Confirmed: 4
Tentative: 0
Rejected: 0
BorutaPy finished running.
Iteration: 9 / 100
Confirmed: 4
Tentative: 0
Rejected: 0
=== BorutaPy 筛选结果 ===
selected_features = ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
总共筛选出重要特征数量: 4
特征排名(ranking 越小越重要,1 表示确认重要):
feature ranking
0 sepal length (cm) 1
1 sepal width (cm) 1
2 petal length (cm) 1
3 petal width (cm) 1方差膨胀系数(VIF)
-
方差膨胀系数 Variance inflation factor (VIF)
-
如果一个特征是其他一组特征的线性组合,则不会在模型中提供额外的信息,可以去掉
-
评估共线性程度
-