向 Elasticsearch 添加数据主要通过 API 接口进行,而执行 PUT 命令最常用的界面是 Kibana 的 Dev Tools(开发工具) 。此外,也可以使用命令行工具如 curl 或各种编程语言的客户端。
推荐界面:Kibana Dev Tools
Kibana 是 Elasticsearch 官方提供的开源分析和可视化平台,其中的 Dev Tools 功能是与 Elasticsearch 交互最舒适、最直观的方式之一。
Kibana Dev Tools 操作指南
访问 Kibana 的 Web 界面(通常为 http://<服务器IP>:5601),在左侧导航栏点击 Dev Tools 图标进入交互界面。该工具提供语法高亮、自动补全和实时响应功能。如下图所示:
创建Elasticsearch索引
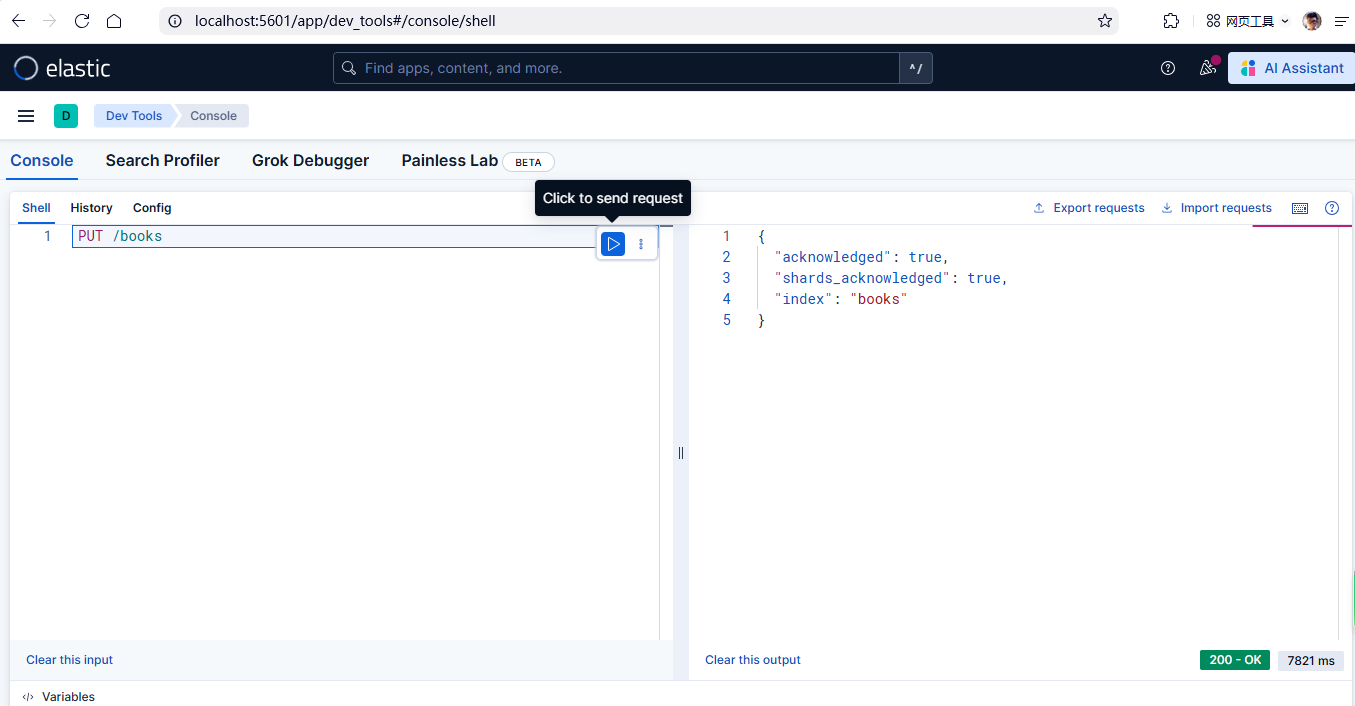
在Elasticsearch中创建名为books的索引,可以通过HTTP PUT请求实现。以下为具体操作和示例:
请求示例
PUT /books成功响应
json
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "books"
}如下图所示:
响应字段说明
acknowledged: 表示请求是否被集群接受(布尔值)。shards_acknowledged: 表示所有分片是否已就绪(布尔值)。index: 返回创建的索引名称。
可选参数
创建索引时可指定自定义配置,例如分片数和副本数:
json
PUT /books
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}验证索引
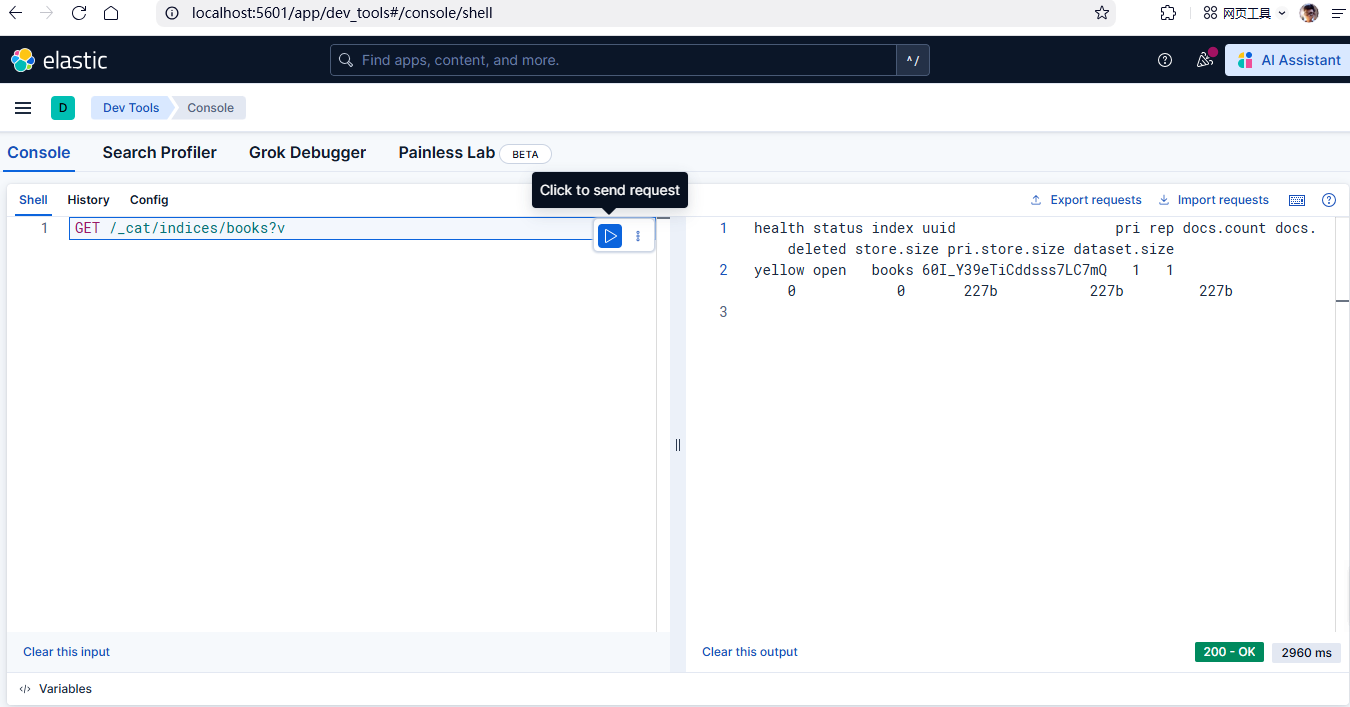
通过以下命令检查索引是否存在:
GET /_cat/indices/books?v如下图所示:
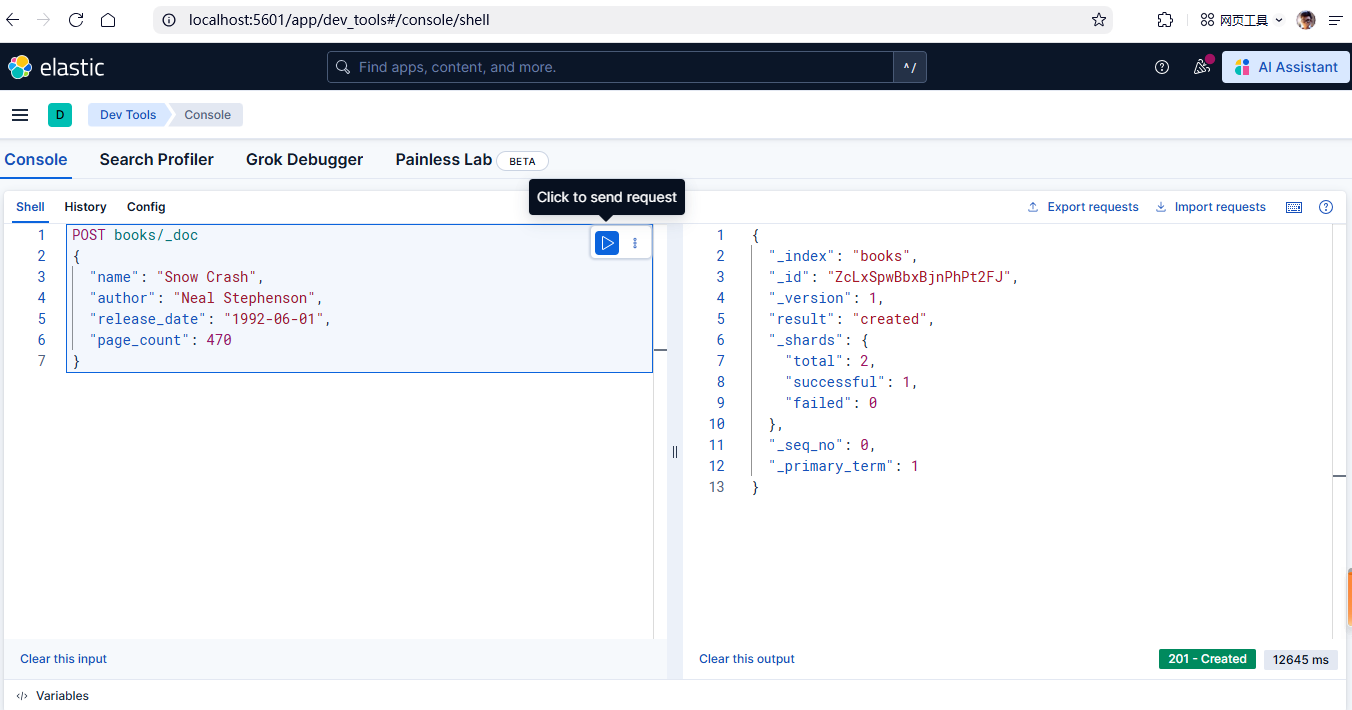
添加单个文档到 Elasticsearch 索引
使用 POST 请求向 books 索引中添加单个文档。如果索引不存在,Elasticsearch 会自动创建它。
POST books/_doc
{
"name": "Snow Crash",
"author": "Neal Stephenson",
"release_date": "1992-06-01",
"page_count": 470
}响应元数据说明
Elasticsearch 返回的响应包含文档的元数据信息:
{
"_index": "books",
"_id": "O0lG2IsBaSa7VYx_rEia",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 2,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}元数据字段解释
_index:文档所属的索引名称,此处为 books。
_id:Elasticsearch 自动生成的唯一文档标识符。
_version:文档版本号,初始值为 1,每次更新递增。
result:操作结果,created 表示文档创建成功。
_shards:分片操作信息:
total:索引的总分片数。successful:成功执行操作的分片数。failed:操作失败的分片数,0 表示无失败。
_seq_no:分片级别的序列号,每次操作递增。
_primary_term:主分片分配计数器,主分片重新分配时递增。
如下图所示:
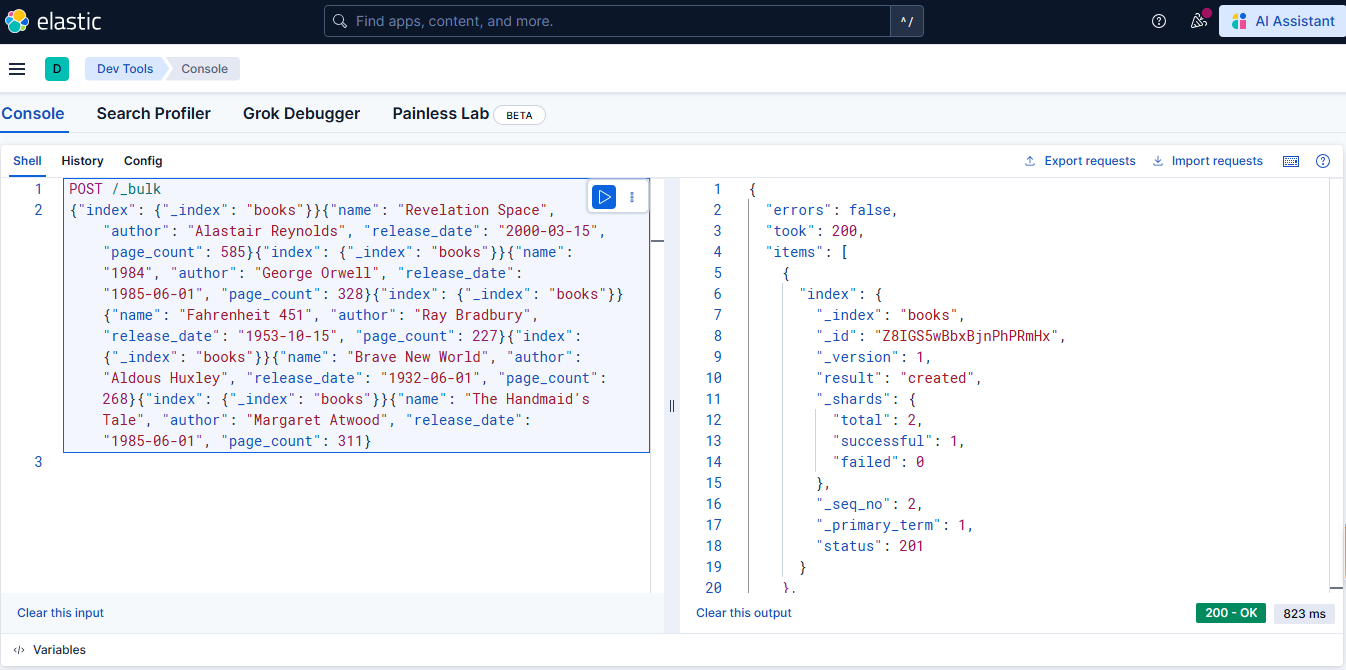
使用 _bulk 端点批量添加文档
批量操作通过 Elasticsearch 的 _bulk 端点实现,允许在单个请求中执行多个索引、更新或删除操作。数据格式必须为换行分隔的 JSON (NDJSON)。
请求示例:
json
POST /_bulk
{ "index" : { "_index" : "books" } }
{"name": "Revelation Space", "author": "Alastair Reynolds", "release_date": "2000-03-15", "page_count": 585}
{ "index" : { "_index" : "books" } }
{"name": "1984", "author": "George Orwell", "release_date": "1985-06-01", "page_count": 328}批量操作格式规范
每行必须包含一个操作说明(如 index、update 或 delete)或文档数据。操作行与数据行交替出现,以换行符分隔。
操作行示例:
json
{ "index": { "_index": "books", "_id": "1" } }文档数据行示例:
json
{"field1": "value1", "field2": "value2"}响应解析
成功响应包含 errors 字段(false 表示无错误)和每个操作的详细结果。关键字段:
took:操作耗时(毫秒)。items:每个子操作的执行状态(如_id、_version、result)。
响应示例片段:
json
{
"errors": false,
"took": 29,
"items": [
{
"index": {
"_index": "books",
"_id": "QklI2IsBaSa7VYx_Qkh-",
"result": "created",
"status": 201
}
}
]
}注意事项
- 数据格式:严格遵循 NDJSON 格式,每行末尾需换行,最后一行也需换行结束。
- 性能优化:批量大小建议根据文档体积调整,过大的请求可能导致超时。
- 错误处理 :检查
errors字段及每个子操作的status字段,部分失败时需单独处理。
高级用法
自定义文档 ID:
json
{ "index": { "_index": "books", "_id": "custom_id_123" } }
{"name": "Dune", "author": "Frank Herbert"}混合操作类型:
json
{ "index": { "_index": "books" } }
{"name": "Neuromancer"}
{ "delete": { "_index": "books", "_id": "old_id" } }
{ "update": { "_index": "books", "_id": "update_id" } }
{"doc": { "page_count": 400 }}如下图所示:
如果格式不对,可能会报错
例如:错误类型为action_request_validation_exception,状态码为400(Bad Request)。
常见触发场景
- 请求体为空或未包含必要参数
- API端点配置错误导致请求未正确传递
- 请求格式不符合接口规范要求
- 必填字段缺失或字段值为空
如下图所示:
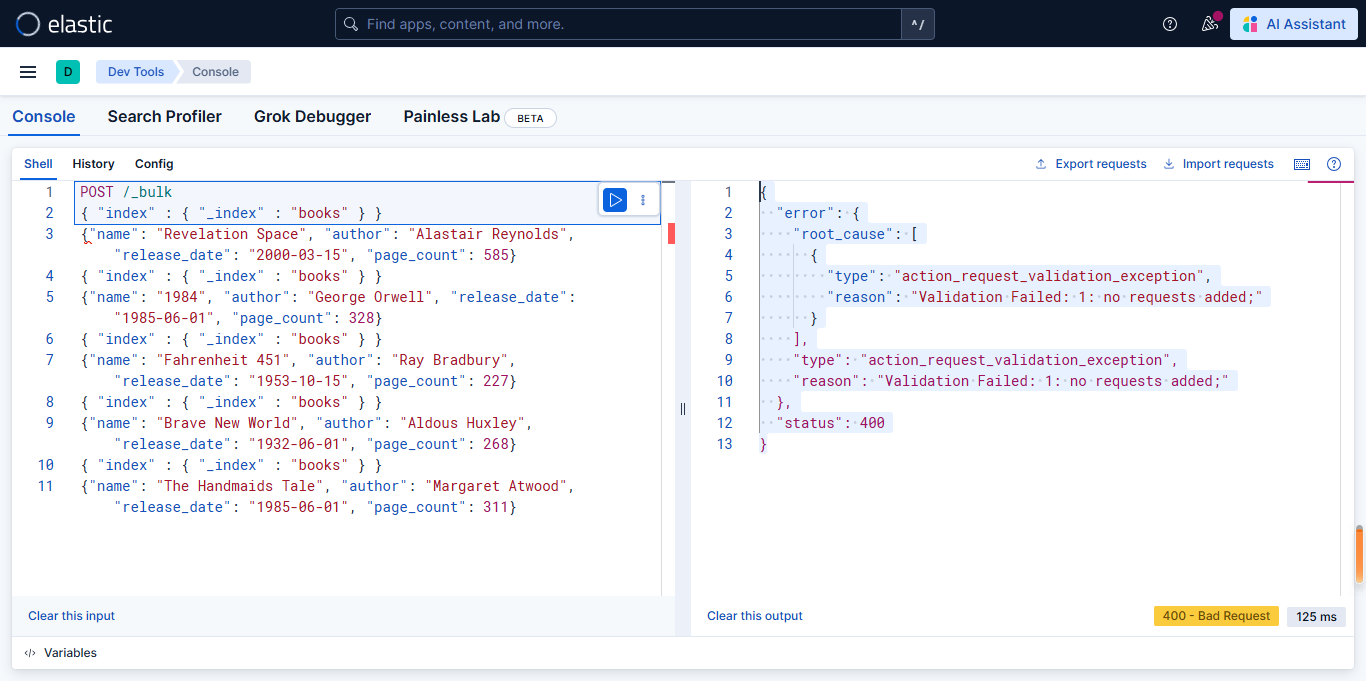 上图的原因是该post请求格式多了换行符导致。
上图的原因是该post请求格式多了换行符导致。
动态映射的工作原理
Elasticsearch 的动态映射功能允许自动检测和添加新字段的映射。当向索引添加包含新字段的文档时,Elasticsearch 会根据字段值推断数据类型并创建相应的映射规则。
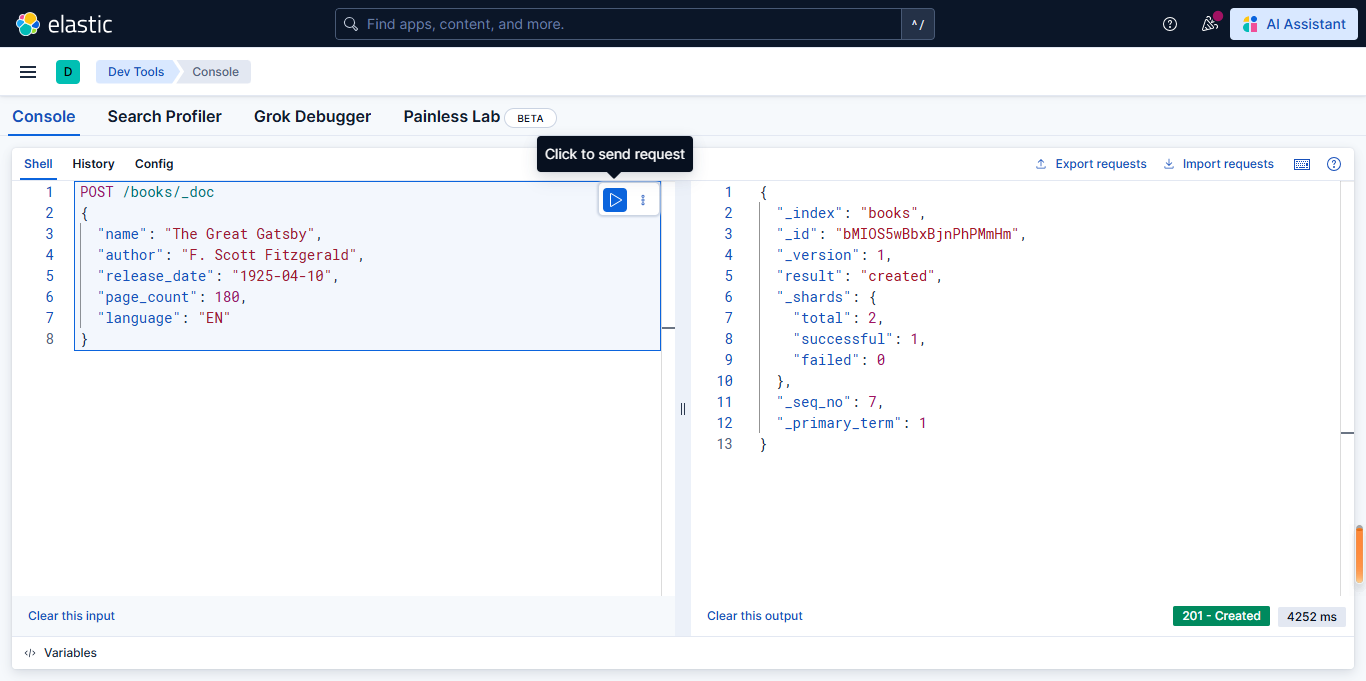
添加新文档触发动态映射
向 books 索引添加包含新字段的文档:
json
POST /books/_doc
{
"name": "The Great Gatsby",
"author": "F. Scott Fitzgerald",
"release_date": "1925-04-10",
"page_count": 180,
"language": "EN"
}如下图所示:
查看生成的映射
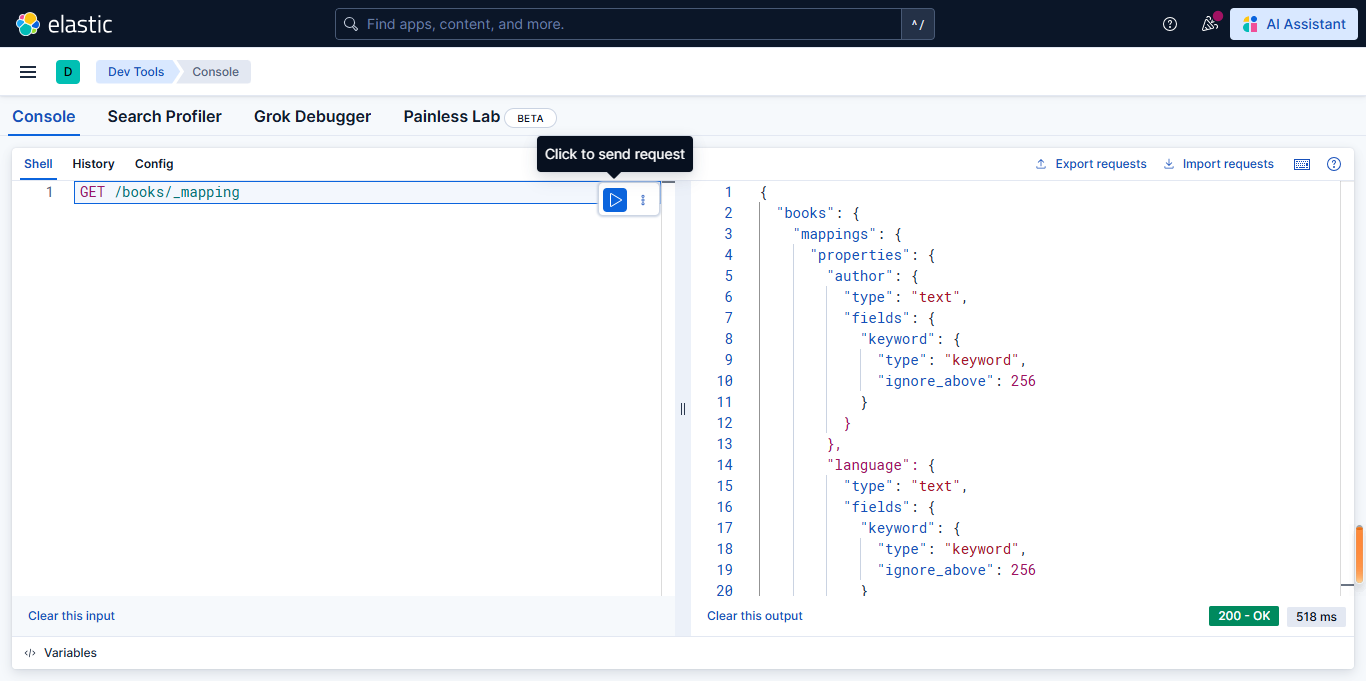
使用以下 API 查看索引的当前映射:
json
GET /books/_mapping动态映射的响应示例
响应展示了 Elasticsearch 自动推断的字段数据类型:
json
{
"books": {
"mappings": {
"properties": {
"author": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"language": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"page_count": {
"type": "long"
},
"release_date": {
"type": "date"
}
}
}
}
}如下图所示:
数据类型推断规则
Elasticsearch 根据字段值自动选择数据类型:
- 文本字段(如
name、author)默认映射为text类型,并附带keyword子字段。 - 数值字段(如
page_count)映射为long类型。 - 日期字段(如
release_date)映射为date类型。
动态映射的优缺点
优点
- 无需预先定义映射,简化数据摄入流程。
- 适合快速原型开发或数据结构频繁变化的场景。
缺点
- 可能产生不符合预期的数据类型推断。
- 后期修改映射需要重建索引(部分场景可通过
reindex解决)。
显式映射的定义与实现
显式映射允许在创建索引时明确指定字段的数据类型和属性,确保文档结构符合预期。以下是如何创建并管理显式映射的详细说明。
创建显式映射索引
通过以下请求创建一个名为my-explicit-mappings-books的索引,并定义字段的显式映射:
json
PUT /my-explicit-mappings-books
{
"mappings": {
"dynamic": false,
"properties": {
"name": { "type": "text" },
"author": { "type": "text" },
"release_date": { "type": "date", "format": "yyyy-MM-dd" },
"page_count": { "type": "integer" }
}
}
}dynamic: false:关闭动态映射。未定义的字段不会被索引或搜索,但仍会存储在_source中。properties:定义字段及其数据类型和属性。例如:name和author字段设置为text类型,支持全文搜索。release_date字段为date类型,并指定日期格式。page_count字段为integer类型。
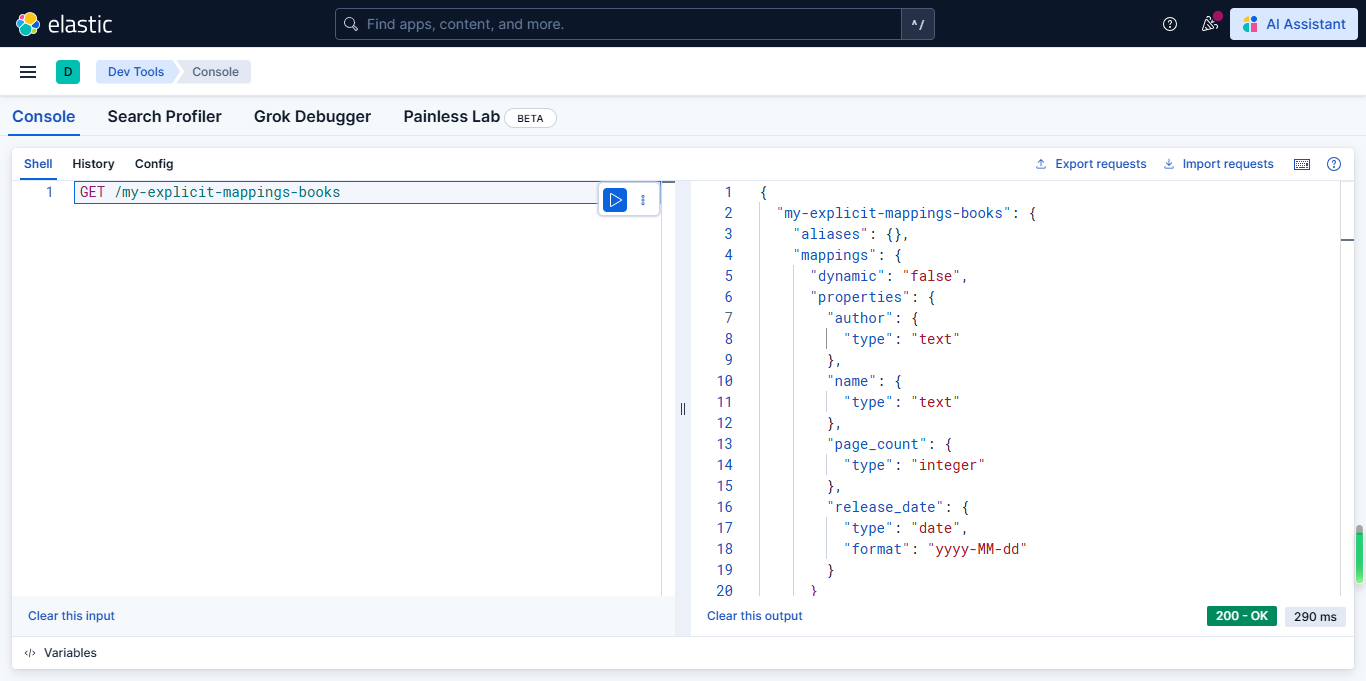
成功响应示例
操作成功后,Elasticsearch返回以下响应:
json
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "my-explicit-mappings-books"
}查询如下图所示:
显式映射的特点
- 严格性:文档必须符合定义的映射结构,未定义的字段无法被索引或搜索。
- 灵活性 :可通过更新映射API修改现有映射,或在索引设置中结合动态映射(如设置
dynamic: true部分字段)。
更新显式映射
若需添加新字段或修改现有字段,使用PUT _mapping API:
json
PUT /my-explicit-mappings-books/_mapping
{
"properties": {
"new_field": { "type": "keyword" }
}
}动态与显式映射结合
通过设置dynamic: true,可以在保留显式映射的同时允许动态添加字段:
json
PUT /my-explicit-mappings-books
{
"mappings": {
"dynamic": true,
"properties": {
"name": { "type": "text" }
}
}
}此时,未定义的字段会被动态推断并添加到映射中。