1.为什么GPU偏爱2的幂次(POT)纹理
2.4的倍数是怎么来的
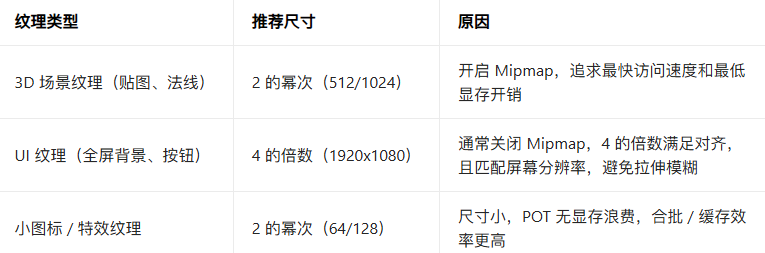
3.Unity中的实际选择建议
1.为什么GPU偏爱2的幂次(POT)纹理
4的倍数是现代GPU对非2次幂(NPOT)纹理的"最低兼容要求", 但"2的幂次(POT, 比如: 512, 1024)"依然是性能最优解
GPU的纹理存储和访问, 核心围绕"纹理块(Texel Block)"和"Mipmap"设计, 这两个核心机制天生"适配 2的幂次"
1).显存块对齐的底层逻辑
GPU读取纹理时, 不是逐个像素读, 而是按固定大小的"块"读取, 比如: 4x4、8x8像素为一个块, 这是为了利用缓存, 减少显
存访问次数
a.2的幂次纹理(512 x 512): 所有块能完美填满纹理尺寸, 没有"碎片", GPU读取时直接按块寻址, 无需额外计算
b.4 的倍数但非2次幂的纹理, 比如: 516 x 516, 516 = 4 × 129, 虽然每个块的起始地址是4的倍数(满足最低对齐), 但纹
理整体尺寸不是2的幂次, GPU 在计算"块的索引"时需要额外的取模、偏移计算, 比原生POT多了一层开销
2).Mipmap的关键影响
Mipmap是纹理的多级缩放版本(比如: 512 -> 256 -> 128 -> 64 -> ... -> 1), 是提升纹理缓存命中率的核心
a.2的幂次纹理: Mipmap层级是"完整且无缝"的, 每个层级的尺寸都是前一级的1/2, GPU计算Mipmap层级时只需简单的位运
算(效率最高)
b.4的倍数但非2次幂的纹理, 比如: 1920 x 1080, 4的倍数但不是2的幂次
✅ 如果关闭Mipmap: GPU 能按4的倍数对齐访问, 勉强满足基本性能
❌ 如果开启Mipmap: GPU会自动把纹理"补齐"到最近的2次幂尺寸(1920 -> 2048, 1080 -> 1024), 导致显存占用增加
2048 x 1024比1920 x 1080多占用约 10% 显存, Mipmap计算时需要额外的坐标转换, 访问速度比原生POT慢
2.4的倍数是怎么来的
a.早期GPU(DX9、老OpenGL 时代)完全不支持非2次幂纹理, 必须强制 POT
b.现代GPU(DX11/12、Vulkan、Metal、移动端 GLES3.0+)为了"适配UI, 视频帧"等"非 POT"场景, 放宽了限制:
最低要求: 纹理宽/高必须是4的倍数, 比如: 1920 x 1080、516 x 516, 否则GPU会强制补齐到最近的4的倍数, 比如
510 x 510 -> 512 x 512, 造成显存浪费 + 性能损耗
最优要求: 依然是2的幂次(512x512、1024x1024), 无补齐, 无额外计算, 访问速度最快
3.Unity中的实际选择建议