在现代企业的数据基础设施中,往往存在一个明显的工程断层:底层拥有海量的数据和强大的计算集群,但顶层的业务应用在获取所需数据时,依然面临开发周期长、权限管控混乱、接口标准不一等问题。
要解决这一断层,单纯依赖某一个工具是无效的。企业需要构建一条标准化的**"数据产品化(Data Productization)"流水线**。本文将从技术实现的角度,拆解这条流水线的四个核心阶段:采集接入、协同治理、服务封装与开放分发。
一、 数据源接入:异构环境下的数据采集 (Data Ingestion)
一切数据架构的起点是采集。在复杂的企业环境中,数据采集组件需要解决多源异构和实时性的问题。
-
关系型数据同步 (CDC): 针对业务系统的 MySQL、PostgreSQL 或 Oracle,通常采用基于 Binlog/Redo Log 的 CDC(变更数据捕获)技术(如 Debezium、Flink CDC)。这种方式对源库无侵入,能够实现毫秒级的增量数据同步。
-
非结构化与日志采集: 对于埋点日志或文件流,依赖 Flume、Filebeat 等 Agent 采集组件,将数据统一推送到 Kafka 等消息中间件,进行流量削峰。
-
架构输出: 采集阶段的最终产物,是汇聚在 ODS 层(操作数据存储)或数据湖(Data Lake)中的原始明细数据。此时的数据尚未经过业务逻辑清洗,存在脏数据和格式不一致的问题。
二、 协同与治理:基于 Web SQL 的开发与探查层
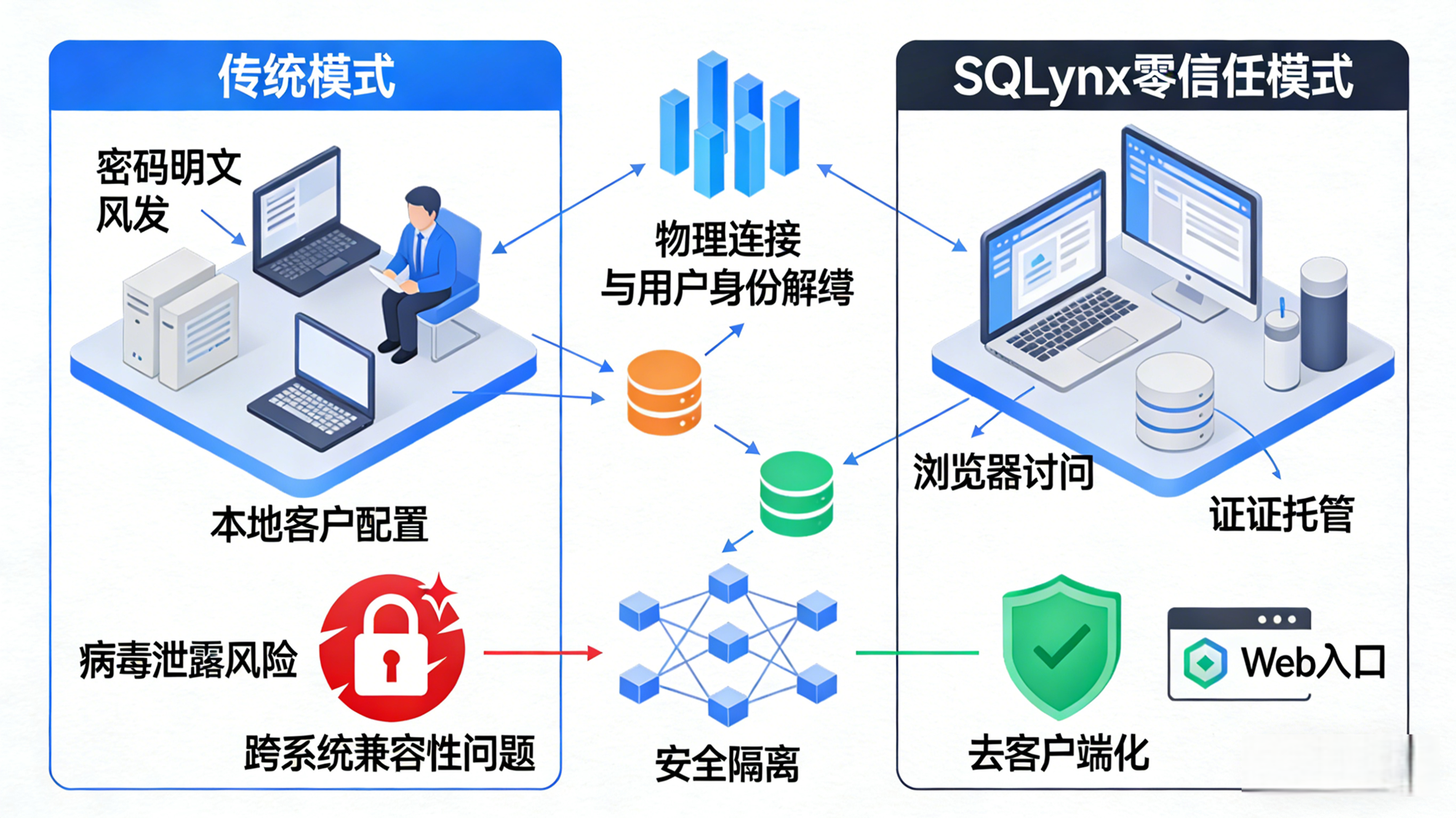
当数据进入数仓或数据湖后,数据工程师和 DBA 需要对其进行清洗、探查和建模。传统的本地客户端(如 Navicat、DBeaver)在多人协作和权限审计上存在明显短板。引入统一的 Web SQL 平台是这一阶段的架构演进方向。
-
统一入口与环境隔离: 研发人员无需在本地配置各种数据库驱动和 VPN 隧道。通过 Web 浏览器直接访问各层数据节点,平台后端统一管理数据库连接池和网络路由。
-
细粒度权限管控 (RBAC): 相比于在数据库底层直接建立无数个只读账号,Web SQL 平台在应用层接管了鉴权逻辑。可以精确控制某位开发者只能查询特定库、特定表,甚至针对敏感字段(如手机号)实行实时数据掩码(Dynamic Data Masking)。
-
操作审计与阻断: 所有执行的 SQL 语句均被结构化记录。通过内置的 SQL 解析引擎,可以在提交前拦截高危操作(如不带
WHERE条件的UPDATE),实现"事前防御"。
三、 服务封装:通过 SQL2API 实现敏捷交付
数据经过探查和建模(形成 DWS 汇总层或 ADS 应用层)后,需要交付给下游业务系统。传统的交付方式是后端工程师编写 Java/Go 代码,开发定制化的 RESTful 接口。这种模式存在大量的 CRUD 样板代码,交付效率低下。
SQL2API 技术在这里发挥了核心的"解耦"作用。它将数据的查询逻辑与接口的开发过程分离开来。
-
配置化生成接口: 数据研发人员只需在平台上编写验证过的原生 SQL,定义入参(如
?user_id=123)和出参格式。SQL2API 引擎会自动解析该 SQL 的 AST(抽象语法树),实时将其发布为一个标准的 HTTP API。 -
动态 Schema 映射: 引擎层自动读取数据库的元数据,将查询结果集序列化为标准 JSON 格式。如果底层表结构新增了字段,只需修改 SQL 配置,API 即可动态适配,实现零代码编译、零停机发布。
-
资源保护: SQL2API 引擎默认在底层执行分页逻辑和超时中断,防止恶意 API 调用耗尽数据库计算资源。
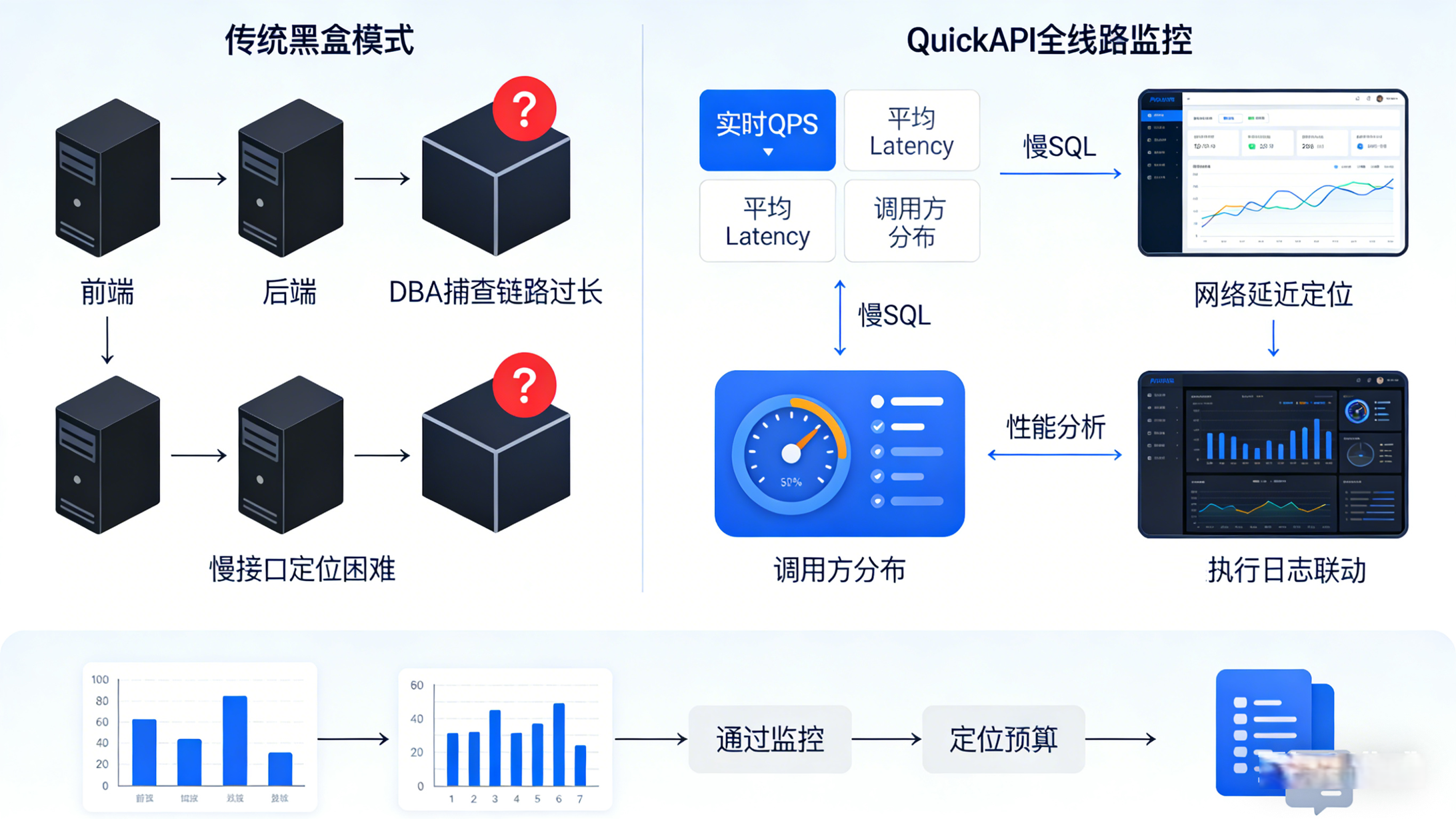
四、 开放与分发:构建数据 API 市场 (Data Marketplace)
当企业内部沉淀了成百上千个由 SQL2API 生成的数据接口后,如何管理这些接口的使用权和调用生命周期,就成为了新的课题。**数据市场(Data Marketplace)**或统一 API 网关是这条流水线的最后一公里。
-
接口注册与发现: 将 API 按照业务域(如"用户画像类"、"财务报表类")进行目录化注册,提供带有入参说明和在线 Mock 测试的 API 接口文档,方便前端或业务系统接入。
-
鉴权与限流机制: 数据市场作为统一网关,负责对调用方进行身份认证(Token/OIDC),并基于应用分配的配额实施速率限制(Rate Limiting,如 100 QPS)。
-
调用计量与可观测性: 完整记录每个 API 的调用次数、响应时长和传输字节数。这不仅为后续的系统性能优化提供了链路追踪数据,也为企业内部实行 Data FinOps(数据成本核算与内部结算)提供了精确的数据支撑。
总结
从底层的数据同步,到开发态的 Web SQL 治理,再到运行态的 SQL2API 封装与数据市场分发,这四个阶段共同构成了一套松耦合、高内聚的数据工程架构。
通过这种流水线式的改造,企业将数据流转的摩擦力降到了最低。数据工程师可以专注于编写高质量的 SQL 与数据建模,而下游业务侧则能以调用标准化 API 的方式,安全、高效地消费数据资产。这才是数据治理与开发效能提升的最终工程落地方式。