LLM基础知识
大语言模型的概念
大语言模型(Large Language Model,LLM)是指具有大规模参数和复杂计算结构的机器学习模型。这些模型通常由深度神经网络构建而成,拥有数十亿甚至数千亿个参数,旨在理解和生成人类语言。LLM的工作原理是将输入文本拆分成最小语义单元(Token),去预测文本的下一个词的生成概率,并选择概率最大的词汇。并不断循环这个过程,直至出现阶数标识或达到队列最大长度。
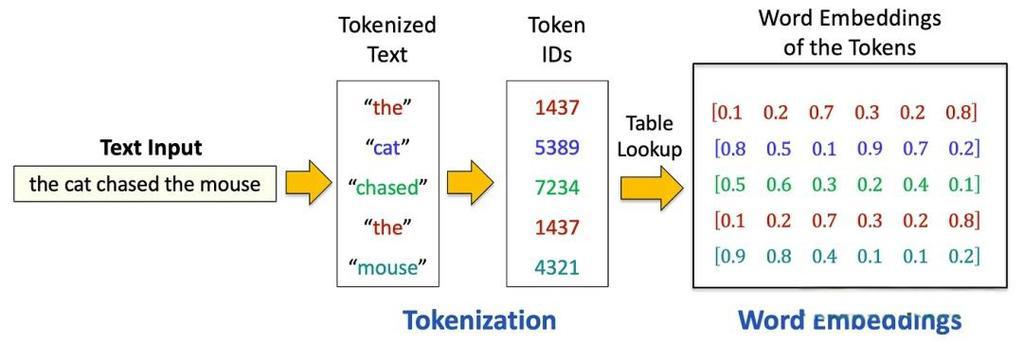
通常,LLM值包含数百亿(或更多)参数的语言模型,这些模型在大量的文本数据行进行训练,例如国外的由GTP-3、GTP-4、PaLM、Galactica和LLaMA等,国内的有DeepSeek、ChatGLMS、文心一言、通义千问、讯飞星火等。
发展历程
- 第一阶段:设计一系列的自监督训练目标(MLM、NSP等),设计新颖的模型架构(Transformer),遵循Pre-training和Fine-tuning范式,典型代表是BERT、GTP、XLNet等;
- 第二阶段:逐步扩大模型参数的训练语料模型,探索不同类型的架构。典型代表是BART、T5、GPT-3等;
- 第三阶段:走向AIGC时代,模型参数规模不如千万亿,模型架构为自回归架构,大模型走向对话式、生成式、多模态时代,更加注重与人类交互进行对齐,实现可靠、安全、无毒的模型,典型代表是InstructionGPT、ChatGPT、Bard、GPT-4等。
大模型的三大架构
- Encoder-only架构:擅长理解、编码和分类信息,比如判断一段文本的情感倾向(积极还是消极)或者主题分类。代表模型:BERT。
- Encoder-Decoder架构:擅长处理需要理解输入然后生成相关输出的任务,比如翻译或问答系统。代表模型:BART。
- Decoder-only架构:擅长创造性的写作,比如写小说或自动生成文章。它更多关注于从已有的信息(开头)扩展出新的内容。代表模型:ChatGPT、文心一言、通义千问。
大模型的特点
LLM具有多种显著特点,这些特点使它们在自然语言处理和其他领域中引起了广泛的兴趣和研究。以下是LLM的一些主要特点:
- 巨大的规模:LLM通常具有巨大的参数规模,可以达到数十亿甚至数千亿个参数。这使得它们能够捕捉更多的语言知识和复杂的语法结构。
- 预训练和微调:LLM采用了预训练和微调的学习方法。它们首先在大规模文本数据上进行预训练(无标签数据),学会了通用的语言表示和知识,然后通过微调(由标签数据)适应特定问题,从而在各种NLP任务中表现出色。
- 上下文感知:LLM在处理文本时具有强大的上下文感知能力,能力理解和生成依赖于前文的文本内容。这使得它们在对话、文章生成和情境理解方面表现出色。
- 多语言支持:LLM可以用于多种语言,不仅限于英语。它们的多语言能力使得跨文化和跨语言的应用变得更加容易。
- 多模态支持:一些LLM已经扩展到支持多模态数据,包括文本、图像和语音。这意味着它们可以理解和生成不同媒体类型的内容,实现更多样化的应用。
- 涌现能力:LLM表现出令人惊讶的涌现能力,即在大规模模型中出现但在小模型中不明显的性能提升。这使得它们能够处理更复杂的任务和问题。
- 多领域应用:LLM已经被广泛应用于文本生成、自动翻译、信息检索、摘要生成、聊天机器人、虚拟助手等多个领域,对人们的日常生活和工作产生了深远的影响。
- 伦理和风险问题:尽管LLM具有出色的能力,但它们也引起了伦理和风险问题,包括生成有害内容、隐私问题、认知偏差等。因此,研究和应用LLM需要谨慎。
大模型的能力
- 生成:聊天助手、写作助手、知识问答助手;
- 总结:会议内容总结、文档总结、邮件总结;
- 提取:文章关键词提取、文档命名实体提取;
- 分类:敏感内容审核、情感分析、评价分类;
- 检索:文本预计检索、图片语义检索;
- 改写:文本纠错、文本润色、文本翻译;
LLM的影响
LLM已经在许多领域产生了深渊的影响。在自然语言处理领域,它可以帮助计算机更好地理解和生成文本,包括写文章、回答问题、翻译语言。在信息检索领域,它可以改进搜索引擎,让我们更轻松地找到所需的信息。在计算机视觉领域,研究人员还在努力让计算机理解图像和文字,以改善多媒体交互。
最重要的是,LLM的出现让人们重新思考了通用人工智能(AGI)的可能性。AGI是一种像人类一样思考和学习的人工智能。LLM被认为是AGI的一种早起形式,这引发了对未来人工智能发展的许多思考和计划。
总之,大语言模型是一种具有强大语言处理能力的技术,已经在多个领域展示了潜力。它们为自然语言理解和生成任务提供了强大的工具,同时也引发了对其伦理和风险问题的关注。这些特点使LLM成为了当今计算机科学和人工智能领域的重要研究和应用方向。