目录
[二、Transformer 输入](#二、Transformer 输入)
[2.1 Embedding](#2.1 Embedding)
[2.2 位置 Embedding](#2.2 位置 Embedding)
[PE 代码](#PE 代码)
[三、Self Attention](#三、Self Attention)
[3.1 Self Attention](#3.1 Self Attention)
[3.2 Multi-Head Attention](#3.2 Multi-Head Attention)
[3.3 Masked Self-Attention](#3.3 Masked Self-Attention)
[3.3.1 Causal Mask](#3.3.1 Causal Mask)
[3.3.2 Padding Mask](#3.3.2 Padding Mask)
[3.4 代码实现](#3.4 代码实现)
[四、Encoder 结构](#四、Encoder 结构)
[4.1 Add & Norm](#4.1 Add & Norm)
[4.2 Feed-Forward Network](#4.2 Feed-Forward Network)
[4.3 Encoder 流程](#4.3 Encoder 流程)
[4.4 代码实现](#4.4 代码实现)
[五、Decoder 结构](#五、Decoder 结构)
[5.1 Masked Self-Attention](#5.1 Masked Self-Attention)
[5.2 Encoder--Decoder Attention](#5.2 Encoder–Decoder Attention)
[5.3 Feed Forward Network](#5.3 Feed Forward Network)
[5.4 Decoder 总结](#5.4 Decoder 总结)
[5.5 Decoder 训练流程](#5.5 Decoder 训练流程)
[5.6 Decoder 推理流程](#5.6 Decoder 推理流程)
[5.7 Decoder 代码](#5.7 Decoder 代码)
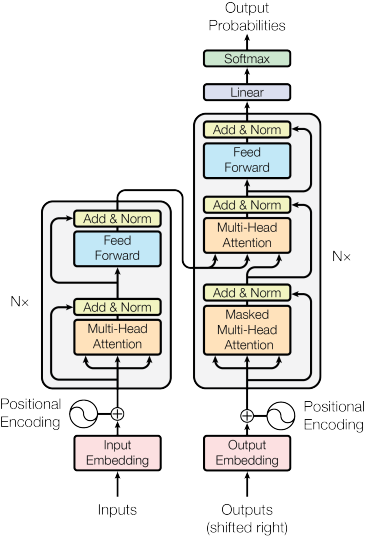
一、Transformer
处理一段话时,人类的理解方式不是严格从左到右 机械推进的。读到一句话的结尾时,我们会回想开头;看到一个代词时,我们会在前文寻找它指代的对象。也就是说,我们的大脑在处理序列 时会做全局关联。
早期神经网络并不是这样工作的。用于处理序列信息的RNN 把序列看成一条时间链 ,第一个输入产生一个状态,这个状态传给第二个时间,信息像接力棒一样传下去;后来的LSTM 引入门控结构改善了长期依赖问题,使模型在一定程度上能够记住更远的信息。但信息仍然必须沿着时间轴逐步传递。
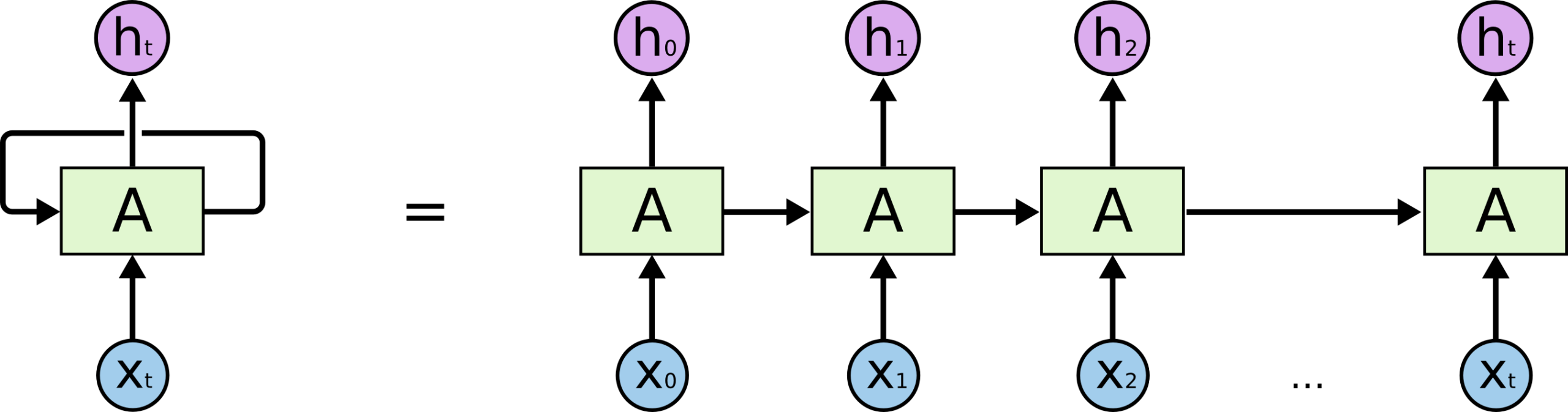
由于每一步都依赖前一步的结果,模型只能按顺序计算,无法发挥并行能力;而且远距离信息传递效率低,信息在传播过程中会被压缩和变形。
2017 年的论文 Attention Is All You Need 引入了 Transformer 架构,直接计算序列中任意两个位置之间的关系,序列建模不再依赖递归结构,也不依赖卷积结构,而是完全基于注意力机制。
二、Transformer 输入
以文字序列为例,对人来说,苹果 这个词天然带有意义。但对计算机而言,它只是一串字符编码 。计算机只能对数值进行计算,因此需要把离散符号转化为可计算的数学对象。即 transformer 中的词嵌入embedding
2.1 Embedding
最原始的编码方法是用整数给每个词编号,例如:
苹果 → 17
香蕉 → 42
但这种扁平化的结构很难表征语义关系 。为了让模型能够学习相似性 与关联性 等语义关系,需要把每个词映射到一个连续向量空间中。我们所需要的词向量就是一个矩阵查表操作
首先 定义一个大小为V 的词表,在词表中每个词元 token 会被分配一个整数编号,那么一句话 I have a dream 可能被编码为:101, 56, 982, 102
第二步,模型内部会定义一个可训练参数的Embedding矩阵
V 是词表大小,d 代表向量维度。这个矩阵就是词向量表 。其中的第 i 行,就是 token i 的向量表示。例如当输入 token id 为 17 时,模型直接取出矩阵 E 的第 17 行,就是该token的**词向量。**那么对于序列输入的句子,编码后自然是词向量组成的矩阵。
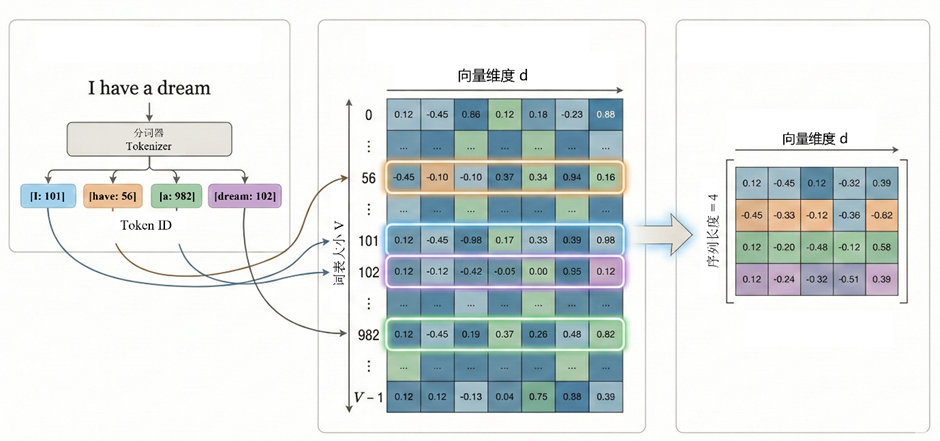
在训练过程中通过反向传播,梯度会更新矩阵 E 的对应行。于是经常一起出现的 token ,向量会逐渐接近;语义相似的 token会在空间中形成聚类,如此让向量逐渐学到语义结构。
代码实现
nn.Embedding(vocab, d_model) 在内部创建了一个可训练参数矩阵 W,形状是(vocab, d_model)
vocab:词表大小
d_model:词向量维度
self.d_model = d_model 把 d_model 保存下来
forward函数中,输入x是 token id,self.lut(x) 查表,把 x 里的每个 id 替换成对应的词向量,也就是取 W 的对应行,输出张量的形状为
(batch_size, seq_len, d_model)
* math.sqrt(self.d_model)是缩放操作
完整代码实现
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model # 存储模型的维度 d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)2.2 位置 Embedding
单纯的Embedding并不包含位置信息 。词向量堆叠成矩阵,看上去第几行就代表第几个位置,它们也确实是按照自然语言的顺序排列的。但transformer 并不按照先后顺序处理信息,它只关心谁和谁相关 ,不关心谁在前谁在后。
语言的意义高度依赖顺序。这一位置信息是十分重要的,比如
{狗, 咬了, 人}
如果不加位置信息,模型看到的只是四个向量集合,而自注意力只是计算两两相关程度,把句子改成:
{人, 咬了, 狗}
在没有位置编码的情况下,模型得到的相关性结构是完全一样的。
作者采用了正弦--余弦形式的位置编码。设模型维度为 d,位置 pos从 0 开始,维度下标i从 0 到 d/2-1。对每一个pos 的不同维度,每个位置的位置编码为
第 0/1 维是一对频率最高的 sin/cos;第 2/3 维频率稍低;越往后频率越低。每个位置 pos 会得到一组不同频率的相位编码,每一组有d项

对于包含n个token的句子输入,token embedding 矩阵X是n×d的,其中第 pos 行是第 pos 个 token的词向量。位置编码矩阵PE同样是n×d的,第 pos 行是这个位置的 d 维位置向量。将他们逐元素相加,得到embedding后的矩阵
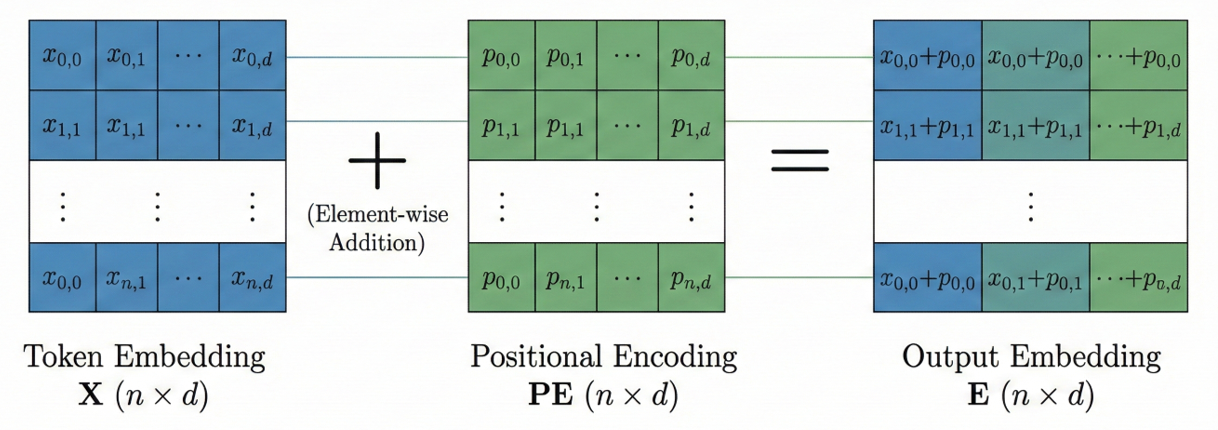
(逐元素相加)
原版 PE 是加在 Embedding 上的。这种做法强行改变了语义空间 ,且模型很难理解极远距离的关系。目前主流模型都抛弃了原版正弦编码,转向了 RoPE
PE 代码
在PositionalEncoding类中,定义参数d_model为embedding 维度;max_len是允许的最大句长
初始化 pe 矩阵,大小为**(max_len, d_model)**
pe = torch.zeros(max_len, d_model, device=DEVICE)每个位置的位置编码通过以下代码实现
div_term = torch.exp(
torch.arange(0., d_model, 2) * -(math.log(10000.0) / d_model)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0) 增加 batch 维度,pe矩阵形状从(max_len, d_model)变成**(1, max_len, d_model)**
forward函数的输入是Embedding 层输出矩阵x**(batch_size, seq_len, d_model)**
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)x.size(1) 是当前 batch 的句长 seq_len,self.pe:, :seq_len表示从pe矩阵中截取句子长度的那一部分,从max_len变为seq_len,形状为**(1, seq_len, d_model)**
最终将Embedding 输出矩阵与pe输出矩阵主元素相加,经过一层Dropout返回,输出为**(batch_size, seq_len, d_model)**
PositionalEncoding完整代码为
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=5000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len, d_model, device=DEVICE)
position = torch.arange(0., max_len, device=DEVICE).unsqueeze(1)
div_term = torch.exp(torch.arange(0., d_model, 2, device=DEVICE) * -(math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe) # 表示pe 不是可训练参数,不参与梯度更新
def forward(self, x):
x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False)
return self.dropout(x)三、Self Attention
机器理解文字,并不只是处理符号或字形。"dog"和"狗"在形式上完全不同,但它们在语义结构 中的角色是相同的:都可以作为主语、宾语,都可以和"跑""咬""吃"等动词建立类似的关系。语言是符号的表征,深层的上下文关系是一致的。
Tokenization 把连续文本拆成离散符号;Embedding 把这些符号映射到连续向量空间。在这个空间里,相同语义功能的词会逐渐靠近,因为它们在上下文 中出现的位置和关系是相似的。模型通过这样的上下文关系 学习它们的语义角色。在transformer中,Self-Attention 机制用来计算当前词在当前语境中的结构关系
3.1 Self Attention
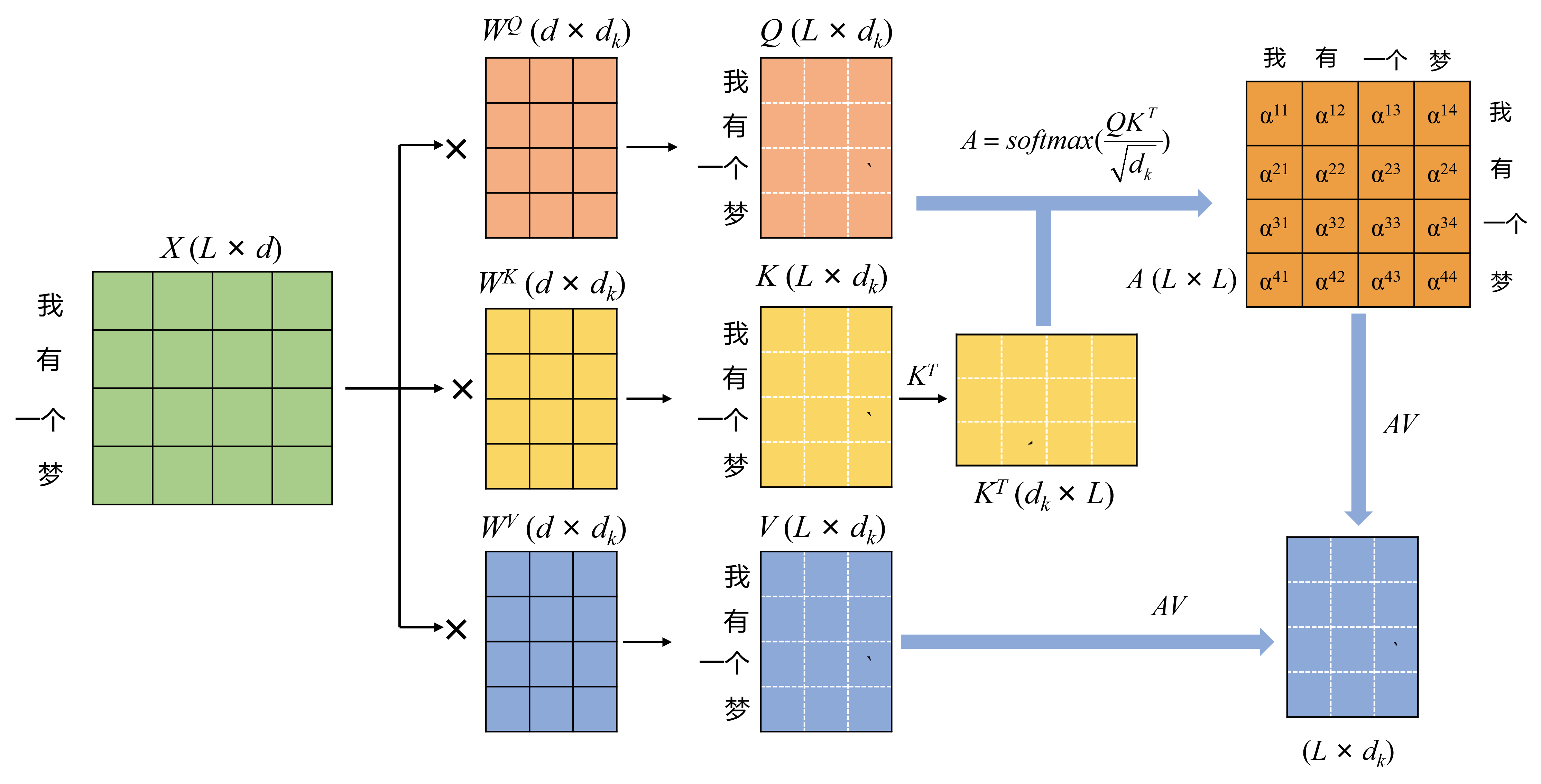
完成embedding之后,输入是一个n×d矩阵Z,n 是序列长度,d 是模型维度,每一行代表一个 token。模型内部定义三组可训练矩阵
,计算
得到矩阵Q,K,V,它们的每一行代表一个token的信息。
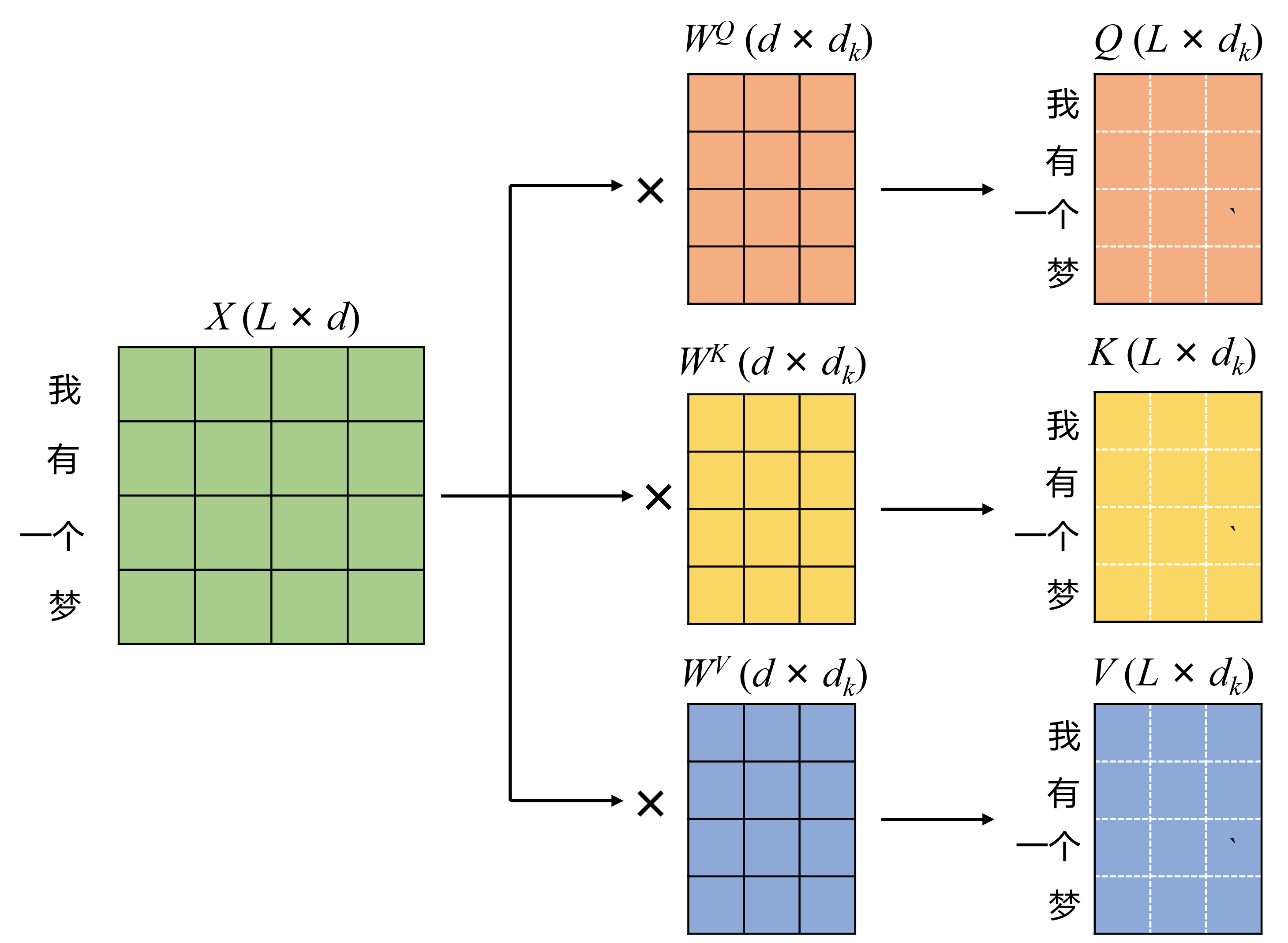
换句话说,对于每一个token,它同时有Q、K、V三个向量
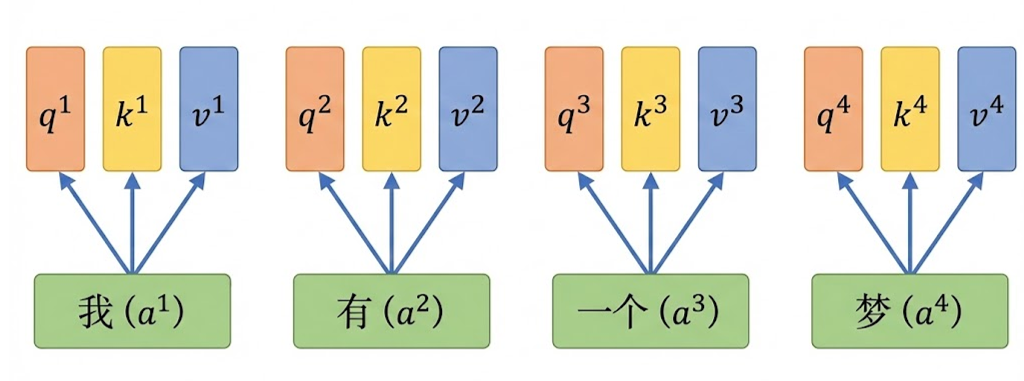
若要计算第一个token"我"与其他token 的相关性,可以用a1的q向量与对应的k向量相乘,例如计算我和有的相关性,计算q1点乘k2,得到一个权重数字。以此类推,对于4个token 的句子,每一个token都可以与4个token(包括自己)计算一个注意力权重,总共可以得到16个注意力权重
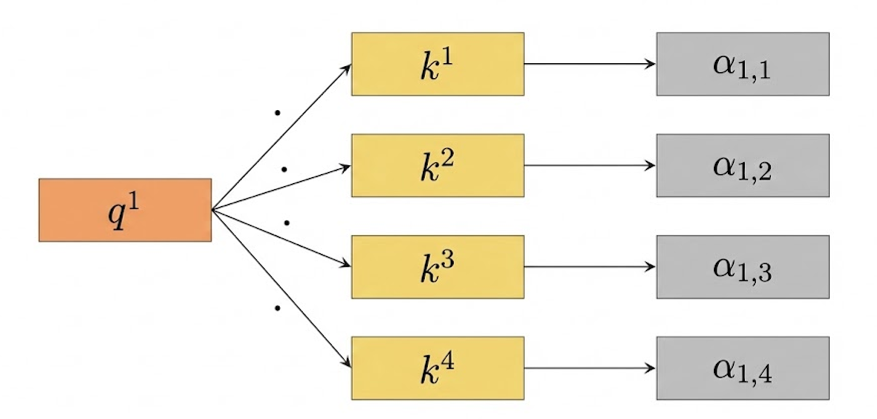
上述的向量相乘求相关性 的操作反映在矩阵上,计算即得到n×n的相关性矩阵。这个矩阵的第 (i,j) 个元素表示,第 i 个 token 的 Query,与第 j 个 token 的 Key的点积结果,反映位置 i 应该关注位置 j 的程度。
之后对这一相关性矩阵进行缩放 和softmax操作,得到处理后的相关性矩阵
最后拿着这个矩阵对V加权求和
得到的Z矩阵,第 i 行代表第 i 个 token根据注意力权重,对所有 token 的 Value 做加权平均。整个self-attention计算输入n 个向量,输出n 个新向量,每个输出向量都融合了全局信息。
3.2 Multi-Head Attention
既然一次注意力计算已经可以建立全局关系,为什么还需要 Multi-Head Attention?这是因为语言中的关系不是单一维度的。同一句话里,可能同时存在:
主谓关系
修饰关系
指代关系
时间顺序关系
语义相似关系
...
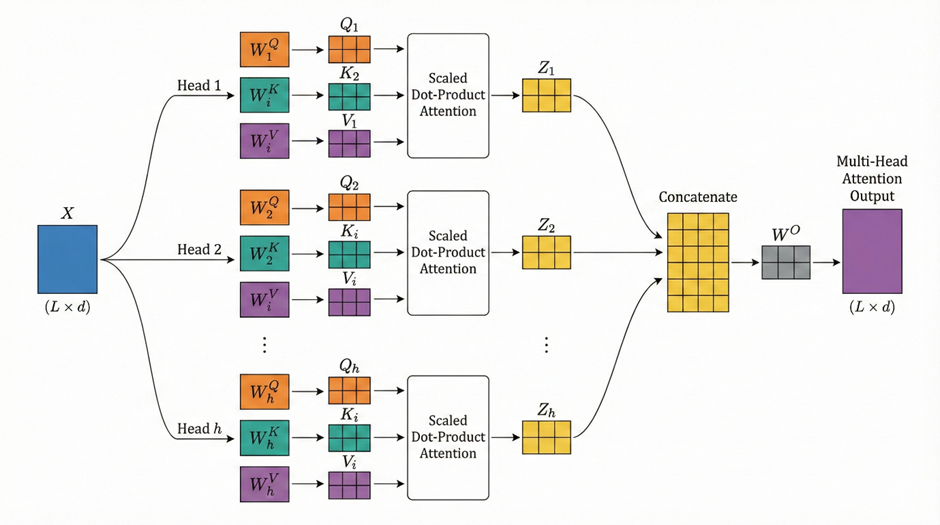
只使用一组Q、K、V矩阵,不同类型的关系挤在同一个空间里,表达能力会受限。所以通过Multi-Head Attention多头注意力,让模型在多个不同的表示子空间中,分别学习关系结构。
对多头注意力的直观认识是,有多组而不是一组QKV 。这一认识是完全正确的。对第i组QKV做上文所述的操作得到的Zi矩阵,用concat操作将它们拼接,最后再乘一个线性变换矩阵 Wo,就得到最终的多头注意力机制的输出结果,这一最终矩阵与输入矩阵的维度是一样的
3.3 Masked Self-Attention
3.3.1 Causal Mask
Self-Attention 默认是全局可见 的。在Encoder 中,每个 token 都可以看到整个序列,包括它后面的词。但在生成任务中,如果模型在预测第 t 个词时,已经看到了第 t+1 个词,那么训练过程就是在偷看答案 ,因此在 Decoder 中,必须强制模型只能利用当前位置之前的信息 。这个约束,就是通过 Mask 实现的。
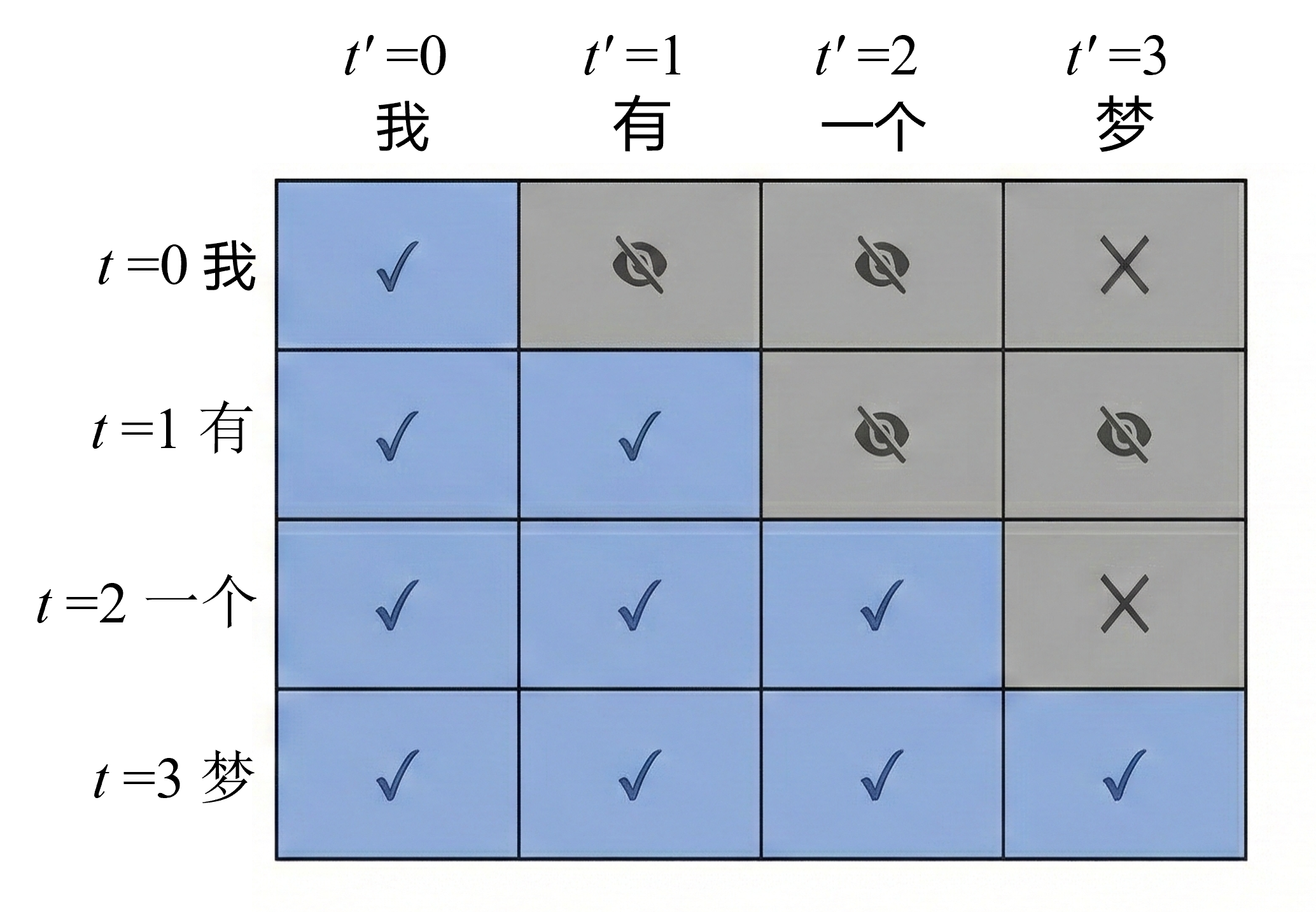
是一个 n×n 的相关性矩阵,第 i 行第 j 列表示位置 i 对位置 j 的关注强度。如果不加限制,任何位置都可以访问任何位置。Masked Self-Attention 的做法是,在 softmax 之前,把不允许关注的位置强制设为负无穷-∞。它在归一化后权重就是 0
可以写成:
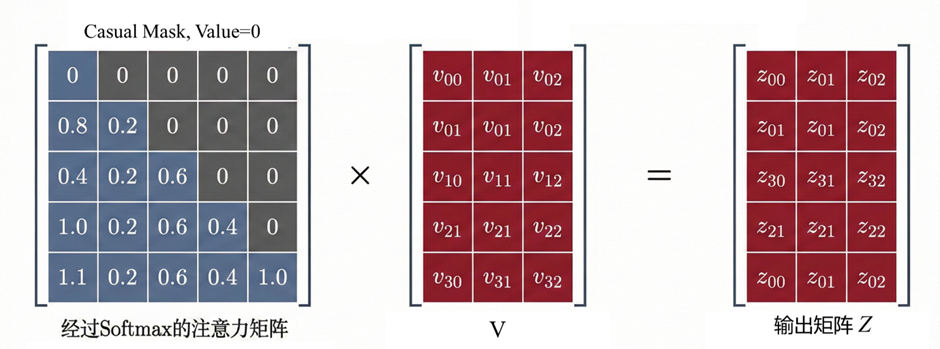
其中 M 是一个 mask 矩阵。在causal mask 中,M 是一个上三角为 -∞ 的矩阵,第 i 个位置只能关注自己和之前的位置,不能关注未来位置。
假设序列长度 n=4,相关性矩阵原本是:
加入 causal mask 后变成:
3.3.2 Padding Mask
还有一种常见的 mask 是 padding mask。当一个 batch 里句子长度不一致时,会用 padding补齐。这些 padding token 不应该参与注意力计算。同样要把对应位置加 -∞。
3.4 代码实现
在多头注意力里,张量被整理成:
query.shape = (B, H, Lq, Dk)
key.shape = (B, H, Lk, Dk)
value.shape = (B, H, Lk, Dv)
B:batch_size;H:头数(n_heads);L与D则分别为向量长度和维度;如果是self-attention,Lq=Lk=L
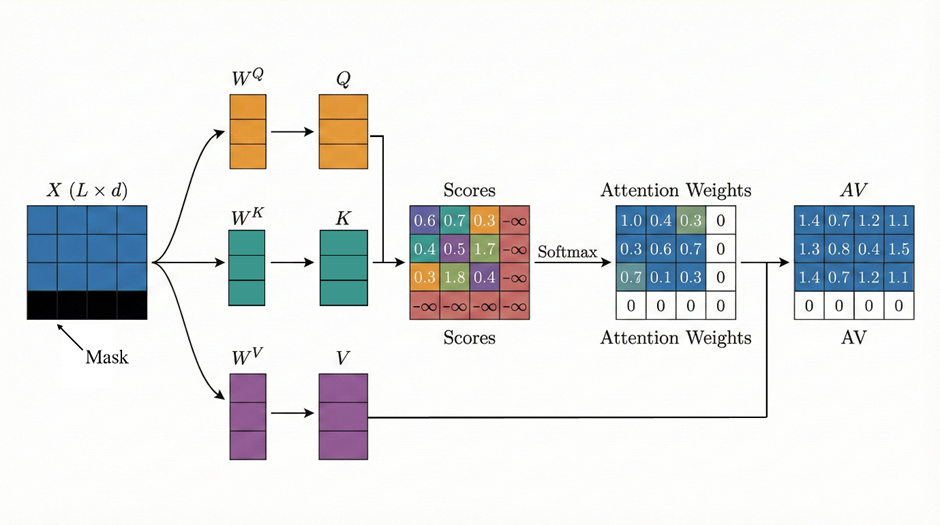
(1)实现 Attention 核心是三步
1.相似度矩阵score = QK^T
2.注意力权重weight = softmax(score)
3.加权求和输出out = weight V
代码:
def attention(query, key, value):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2,-1)) / math.sqrt(d_k) # (B, Lq, Lk)
p_attn = F.softmax(scores, dim=-1) # (B, Lq, Lk)
out = torch.matmul(p_attn, value) # (B, Lq, Dv)
return out, p_attn(2)其次可以加入 Mask机制,把某些 key 位置 j 从 softmax 的候选里删掉。在 softmax 前把那些位置的分数变成极小值(-1e9),softmax 后就≈0。
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)Encoder中使用padding mask处理长度不一致序列
Decoder中使用padding mask 处理填充部分,sequence mask防止偷看答案
Attention类代码:
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1) # 将query矩阵的最后一个维度值作为d_k
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn # 返回注意力矩阵跟value的乘积,以及注意力矩阵(3)进一步拓展到 MultiHeadedAttention,先确定每头维度 d_k, d_model 均分成 h 份
assert d_model % h == 0
self.d_k = d_model // h
self.h = h生成 4 个一模一样结构的d×d线性层WQ WK WV WO
self.linears = clones(nn.Linear(d_model, d_model), 4)其中
linears0:WQ
linears1:WK
linears2:WV
linears3:WO
输入X(B, L, d_model)经过线性层WQ(B, d_model, d_model)后 Q 的形状是 (B, L, d_model),
Q = Q.view(B, L, h, d_k)将其分头变成**(B, L, h, d_k)**
把 L 和 h 换一下顺序
Q = Q.transpose(1, 2) # (B, h, L, d_k)合并操作,并分别对QKV进行:
query, key, value = [
l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))
]得到**(B, h, L, d_k)**的QKV矩阵
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)用 attention()得到各个头的注意力矩阵及加权后的V (B, h, L, d_k)
最后拼接多头注意力**(B, L, d_model),并用WO全连接层(B, d_model, d_model)融合输出(B, L, d_model)**
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)多头注意力类:
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
mask = mask.unsqueeze(1) # 维度对齐
nbatches = query.size(0)
query, key, value = [l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)
x = x.transpose(1, 2).contiguous().view(nbatches, -1, self.h * self.d_k) # concat
return self.linears[-1](x)四、Encoder 结构
Transformer最初的应用场景是序列到序列seq2seq 任务,例如机器翻译。在翻译任务中,我们面对的是给定一个输入序列 ,生成一个输出序列 这样的问题。是一个理解-生成的过程。整体上看,Transformer的结构分为 Encoder和 Decoder,恰好对应这两个阶段
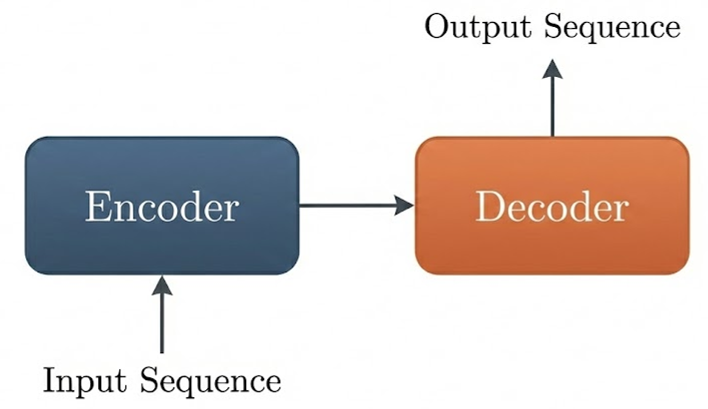
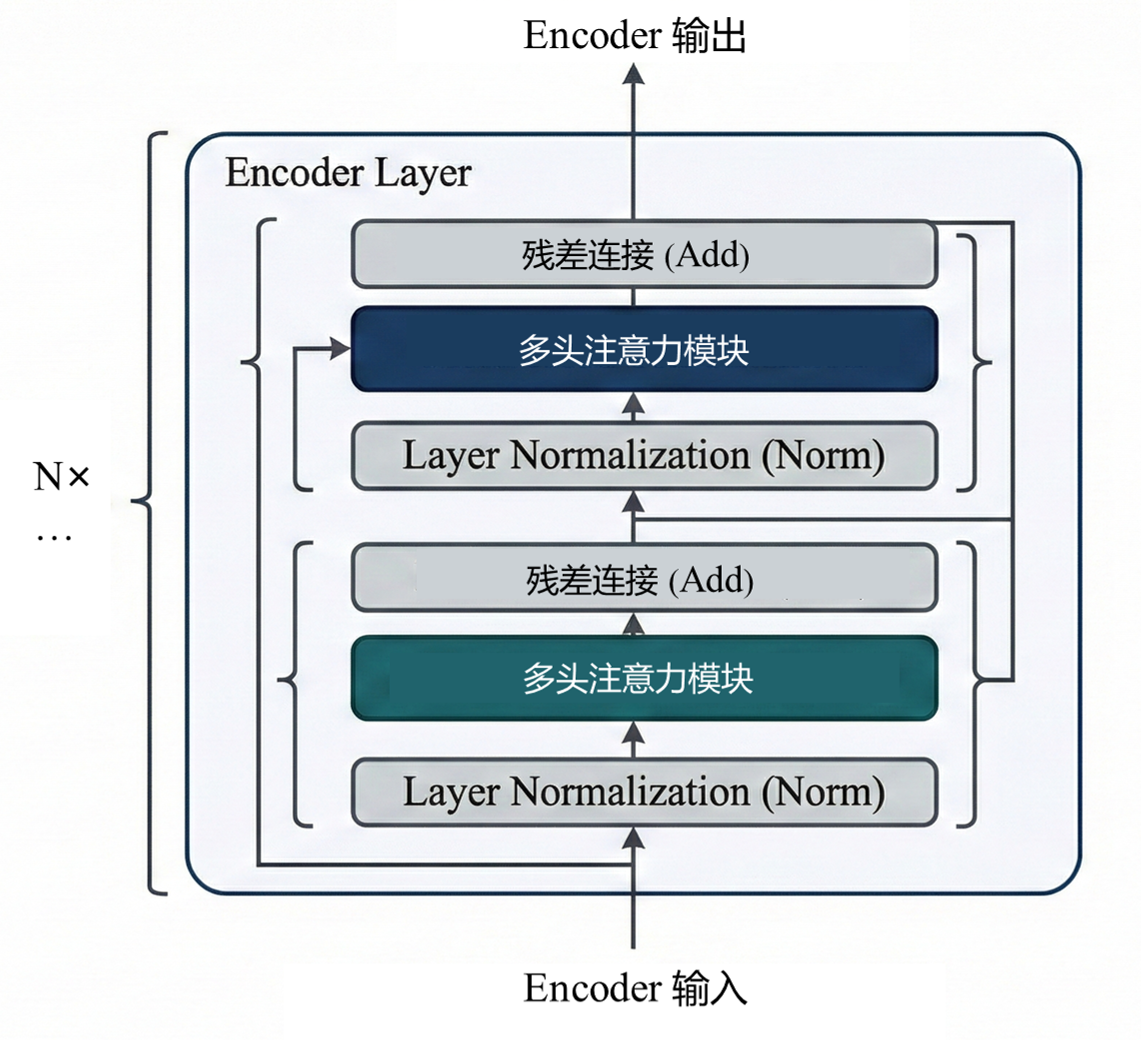
Encoder负责全局理解,输入是一串 token,输出是一个矩阵,这一矩阵已经融合了整句话的全局信息。Transformer 的 Encoder 由若干个完全相同的层堆叠而成,每一层 Encoder 包含两个核心子模块:
1)Multi-Head Self-Attention
2)Feed Forward Network
同时在每个子模块外都有残差连接和层归一化
4.1 Add & Norm
Add & Norm 层由 Add和 Norm两部分组成,add是残差连接x+Sublayer(x),将多头注意力模块的输出 与decoder原始输入相加作为新的输入,用于缓解深层网络训练困难,保持梯度稳定传播。
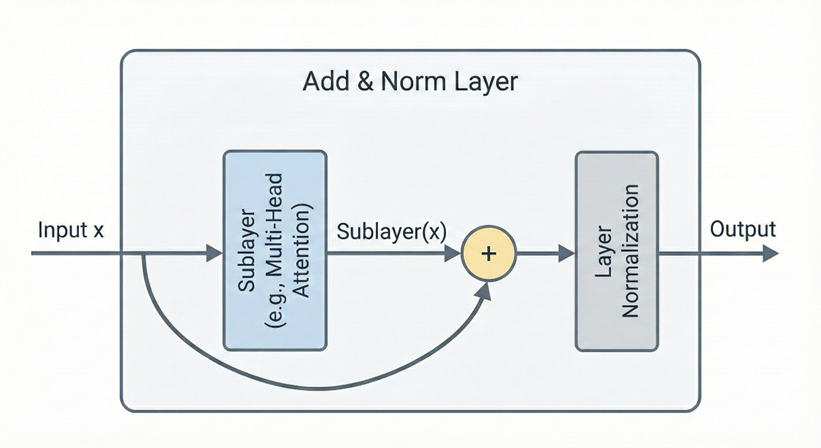
Norm指LayerNorm,它对每一个 token 向量,也就是n×d矩阵中的每一行单独做归一化。设一个 token 的特征向量是 ,把原始特征减去均值,除以标准差
再缩放与平移,引入了两个可学习的参数 和
:
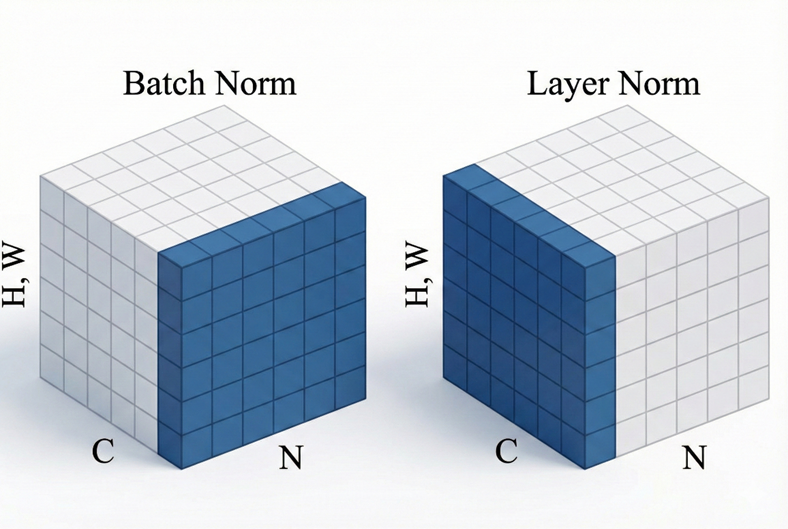
与resnet 的Batch Norm (BN) 相比,LN是横向的,它对同一个token 的所有特征做归一化,不依赖 Batch 的大小;而BN是在整个 Batch 里,对同一个特征维度做归一化。
Transformer中每个词的归一化只取决于自己,不受 Batch 中其他句子长短或内容的影响,且序列长度不一,更适合LN
Add & Norm层的输出可表示为
代码实现
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True) # 计算最后一个维度的均值
std = x.std(-1, keepdim=True) # 计算最后一个维度的标准差
return self.a_2 * (x - mean) / torch.sqrt(std ** 2 + self.eps) + self.b_2
class SublayerConnection(nn.Module):
def __init__(self, size, dropout):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(dropout)
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))4.2 Feed-Forward Network
FFN 是一个两层全连接网络,形式是:
这一层是逐位置计算的,不涉及 token 之间的交互,用于非线性特征变换
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w_1 = nn.Linear(d_model, d_ff)
self.w_2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w_2(self.dropout(F.relu(self.w_1(x)))) 4.3 Encoder 流程
原始输入完成embedding之后,得到一个n×d矩阵Z,这一矩阵经过多头自注意力机制,让每个 token 融合来自整个序列的上下文信息,输出仍为n×d矩阵Attention(Z)。之后经过Add & Norm层,矩阵大小不变
每个位置独立通过一个全连接网络,对每个 token 独立做两层线性变换,并再次进入Add & Norm层,输出与输入大小完全一致。最终一个这样的encoder模块输出为n×d矩阵。
整个Encoder由多个相同的encoder模块组成,前一模块的输出是后一模块的输入,它们顺序链接,直到最后一个 Encoder block输出最终的n×d矩阵
4.4 代码实现
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)self.sublayer0 在attention模块后,self.sublayer1 在 ffn之后,每个 SublayerConnection 里面有 LayerNorm,两处 LayerNorm 不应该共享参数,所以要两个独立的sublayer
第一行等价于
x = x + dropout( self.self_attn( norm(x), norm(x), norm(x), mask ) )即
y = norm(x)
z = self.self_attn(y, y, y, mask) (注意:传的是 norm 之后的 y)
z = dropout(z)
x = x + z (残差)
第二行等价为
x = x + dropout( feed_forward( norm(x) ) )lambda 把多参数函数包装成只接收一个 x 的函数
单层 Encoder 代码为
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)多层encoder模块串联
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)五、Decoder 结构
如果说Encoder 的任务是构建语义理解,那么 Decoder 的任务是在语义约束下生成序列。它不仅要理解输入,还要逐步产生输出 ,并保证因果顺序。
结构上,Decoder 也是由若干层堆叠而成,每一层包含三个子模块
1)Masked Multi-Head Self-Attention
2)Encoder--Decoder Attention
3)Position-wise Feed Forward Network
每个子模块外都包含 Residual + LayerNorm。
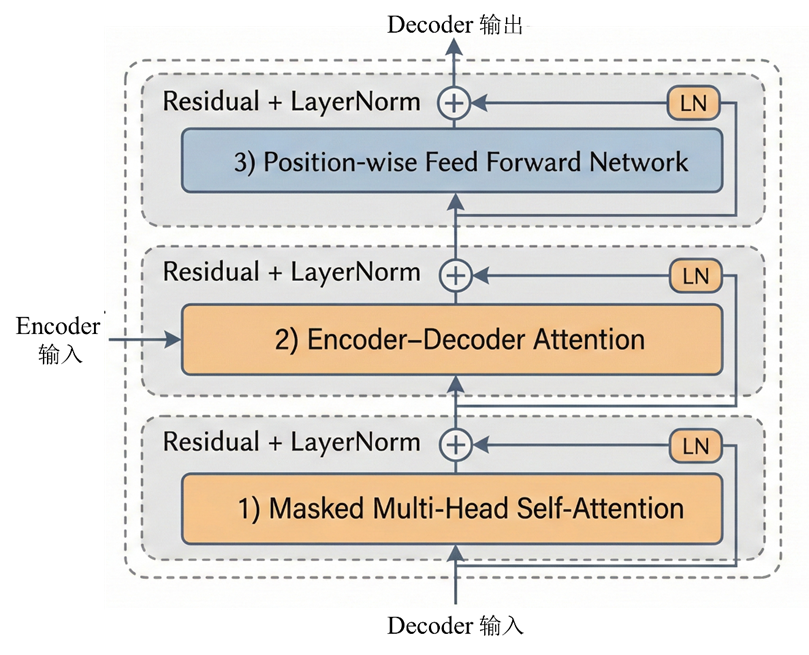
5.1 Masked Self-Attention
与普通 Self-Attention唯一的区别是加入了因果约束。这个约束决定了模型在生成第 t 个词时,不能访问 t 之后的位置。
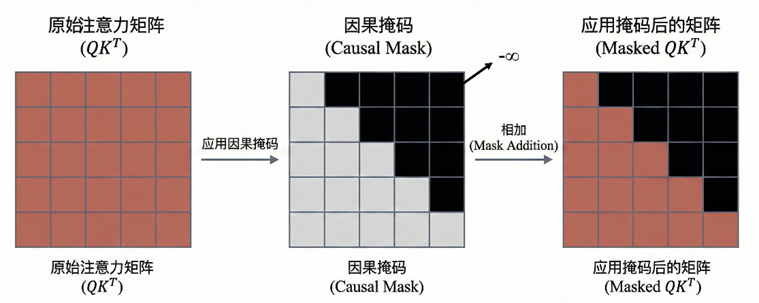
设输入为n×d的矩阵,Masked Self-Attention与普通 Self-Attention一样生成Q、K、V,计算相关性矩阵,矩阵的第 i 行第 j 列表示位置 i 对位置 j 的关注强度。
约束要求预测第 i 个词时,只能使用 0 到 i 的信息。引入 causal mask构造一个上三角矩阵 M,上三角的区域均为负无穷
计算
经过softmax,所以所有 j > i 的位置权重都会变成 0。
最后AV加权求和
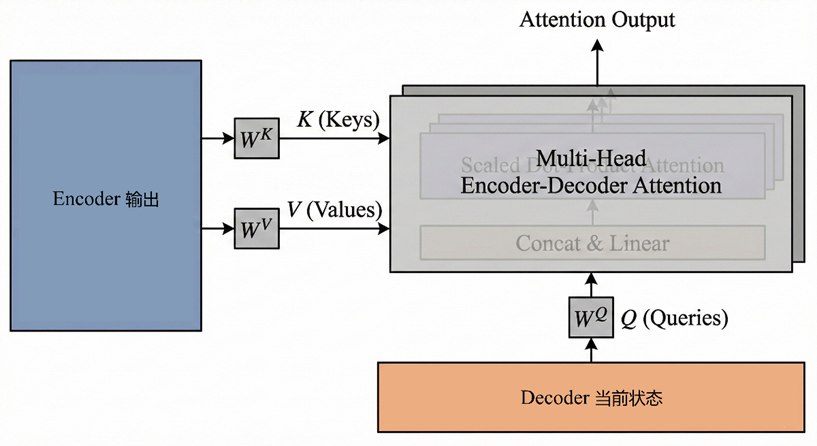
5.2 Encoder--Decoder Attention
Self-Attention,不论是单头还是多头,都是序列在和自己做注意力。
输入是同一个X,Encoder--Decoder Attention顾名思义,是encoder和decoder间的注意力。Q 来自 Decoder 当前状态,K 和 V 来自 Encoder 输出,即:
后续的计算方法与之前描述的一致。
Encoder 的 Self-Attention建立输入序列内部的全局关系;Decoder 的 Masked Self-Attention建立输出序列内部的因果关系;那么Encoder--Decoder Attention建立了输入与输出之间的对应关系。
5.3 Feed Forward Network
和 Encoder 相同,对每个位置独立进行两层线性变换增强非线性表达能力。
5.4 Decoder 总结
完整单层 Decoder 的计算流程可以写为:
1)Masked Self-Attention
2)Add & Norm
3)Encoder--Decoder Attention
4)Add & Norm
5)Feed Forward Network
6)Add & Norm
在整个过程中,输入输出形状始终保持n×d 的矩阵,每一层只是不断更新表示内容,而不改变矩阵结构。与Encoder一样,Decoder也是多层decoder模块堆叠而成
5.5 Decoder 训练流程
训练阶段整个目标序列可以一次性并行计算。
以机器翻译为例,假设目标序列是
<bos> 我 有 一个 梦 <eos>
原句为 i have a dream
设d = 4,encoder 的输出应为4×4的矩阵,4 个向量分别表示i、 have 、a 、dream的上下文语义表示。
训练时使用 teacher forcing,Decoder 输入是右移一位的序列
<bos> 我 有 一个 梦
标签是:
我 有 一个 梦 <eos>
位置编码后得到5×4矩阵输入Masked Self-Attention,注意力矩阵是5×5的。由于有 causal mask,每一位置只能看到自己以及之前的位置,该层输出仍为5×4矩阵
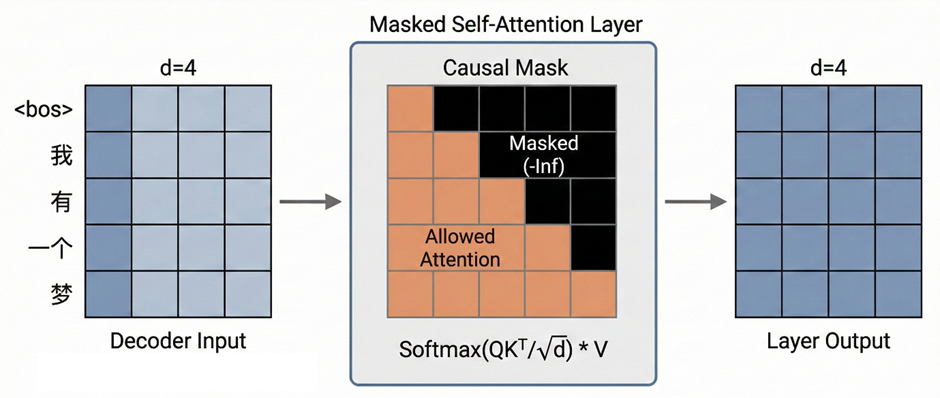
Encoder--Decoder Attention中,Query 来自D1,形状5×4,Key/Value 来自E,形状4×4,计算,表示5 个目标位置,分别对 4 个源位置做注意力。输出为5×4矩阵,矩阵的第i行表示目标序列第 i 个位置对源序列所有位置的注意力分布。即当生成第 i 个词时,关注源句中哪些词
后续经过FFN层,在输出层映射到词表,softmax 后得到5 个位置的词概率分布。
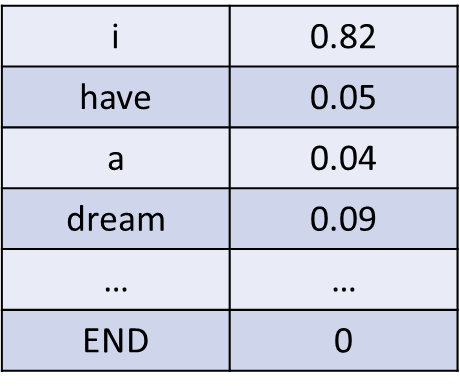
例如第二行代表"我",对应矩阵中的向量可能是
0.82, 0.05, 0.04, 0.09
分别对应
i have a dream
意思是,在生成"我"时82% 注意力放在 "i"、5% 在 "have"、4% 在 "a"、9% 在 "dream"
这样
位置1 → 预测"我"
位置2 → 预测"有"
位置3 → 预测"一个"
位置4 → 预测"梦"
位置5 → 预测"<eos>"
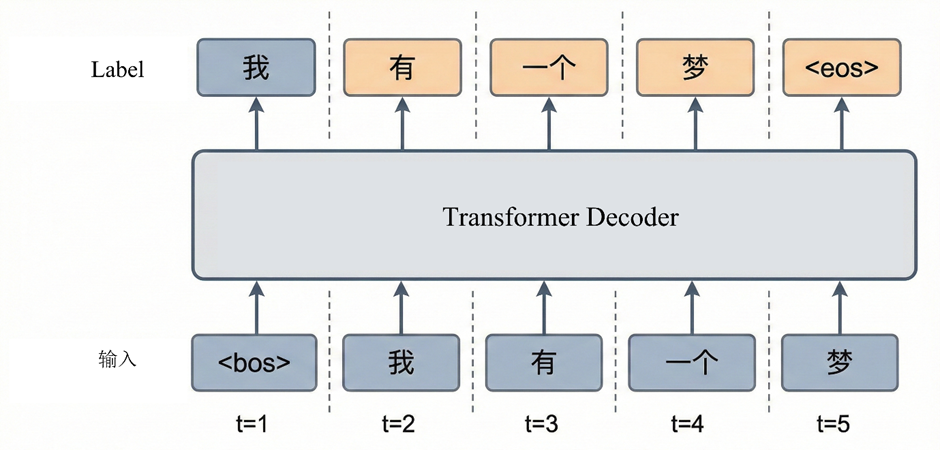
训练时一次性得到全部预测,然后与真实标签计算交叉熵损失。每层输入输出始终保持5×4
5.6 Decoder 推理流程
与训练不同,推理阶段每次只生成一个新词
源句(英文):i have a dream
目标句(中文):我 有 一个 梦
Encoder输出仍为4×4矩阵
第一步
初始Decoder 输入
<bos>
Embedding后得到1×4矩阵,经过若干层 Decoder最终输出仍为1×4矩阵,此时线性映射到词表,假设最大概率词是"我"
第二步
Decoder 输入变成:
<bos> 我
Embedding后得到2×4矩阵,再次经过若干层 Decoder,每层输入输出均为2×4。只取最后一个位置的概率分布,选择最大概率词"有"
重复同样流程,第三步输入
<bos> 我 有
......
直到生成 <eos> 为止
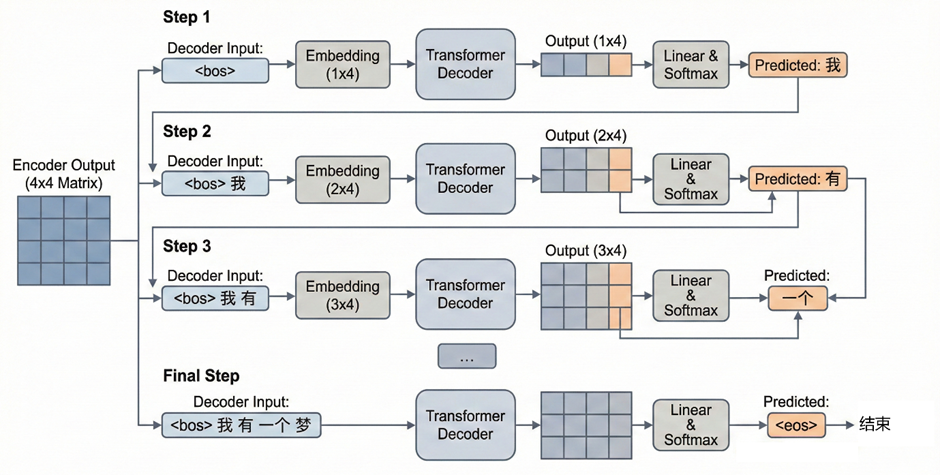
与训练不同的是,推理每次预测一个词、每次的输入是当前已生成的前缀
5.7 Decoder 代码
与Encoder相比,decoder从 2 个子层变成 3 个子层。顺序为Masked Self-Attention → Encoder-Decoder Attention → FFN ,每个都包在 **SublayerConnection(Pre-LN + 残差)**里。
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)src_mask:用来屏蔽源序列 padding,tgt_mask:同时包含 padding mask + causal mask
与encoder一致,decoder由多层堆叠而成,单层 Decoder 代码
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, src_mask, tgt_mask):
m = memory # encoder 输出
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)多层堆叠
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)输出层经过全连接层与softmax得到概率分布
class Generator(nn.Module):
def __init__(self, d_model, vocab):
super(Generator, self).__init__()
self.proj = nn.Linear(d_model, vocab)
def forward(self, x):
return F.log_softmax(self.proj(x), dim=-1)六、总结
从整体看,Transformer 由Encoder、Decoder两部分组成。Encoder 负责把输入序列转化为上下文相关的语义表示;Decoder 负责在该语义表示的条件下,逐步生成输出序列。实现从符号到语义、再到符号的转换
输入文本首先切分为 token 序列,token通过词嵌入变为embedding 向量,最后embedding + 位置编码得到初始矩阵n×d
Encoder中每一层包含
Multi-Head Self-Attention、Add & Norm、Feed Forward Network、Add & Norm
输入输出形状始终保持n×d
Decoder输入目标序列右移后的embedding 矩阵,每层包含
Masked Self-Attention、Encoder--Decoder Attention、Feed Forward Network,每个子模块后都有 Add & Norm
输入输出形状始终保持n×d
在输出层线性映射到词表,通过softmax 得到每个位置的词的概率分布
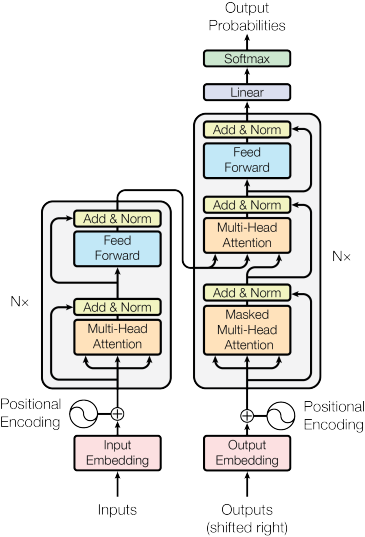
代码实现
定义了一个标准的 Transformer类,并实例化,放在设备里
class Transformer(nn.Module):
def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):
super(Transformer, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.src_embed = src_embed
self.tgt_embed = tgt_embed
self.generator = generator
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
def forward(self, src, tgt, src_mask, tgt_mask):
# encoder的结果作为decoder的memory参数传入,进行decode
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def make_model(src_vocab, tgt_vocab, N=6, d_model=512, d_ff=2048, h=8, dropout=0.1):
c = copy.deepcopy
attn = MultiHeadedAttention(h, d_model).to(DEVICE)
ff = PositionwiseFeedForward(d_model, d_ff, dropout).to(DEVICE)
position = PositionalEncoding(d_model, dropout).to(DEVICE)
model = Transformer(
Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout).to(DEVICE), N).to(DEVICE),
Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout).to(DEVICE), N).to(DEVICE),
nn.Sequential(Embeddings(d_model, src_vocab).to(DEVICE), c(position)),
nn.Sequential(Embeddings(d_model, tgt_vocab).to(DEVICE), c(position)),
Generator(d_model, tgt_vocab)).to(DEVICE)
# 初始化模型参数
# 遍历模型中的所有参数
for p in model.parameters():
# 判断参数是否为二维或更高维(例如权重矩阵,而不是偏置向量)
if p.dim() > 1:
nn.init.xavier_uniform_(p)
return model.to(DEVICE)七、运行
https://github.com/HaoYuanxinn/Transformer-Translation-Chinese-English-.git
运行环境
python3.10
pytorch==1.12.1 CUDA==11.3
Tqdm==4.67.1
Sentencepiece==0.2.1
Sacrebleu==2.5.1
Numpy==1.23.3
Matplotlib==3.10.8
数据集
使用WMT 2018 Chinese--English公开数据集。包括训练集(train.json)、开发集(dev.json)以及测试集(test.json)
训练方法
使用 get_corpus.py 对原始 JSON 做清洗与抽取。逐条读取样本,定位其中的中文句子与英文句子,将二者按行一一对齐输出,分别写入两个纯文本文件:
corpus.ch:每行一句中文
corpus.en:每行一句英文
tokenize.py用于生成分词器与词表,分别生成中英文分词器chn.model eng.model;中英文词表chn.vocab eng.vocab
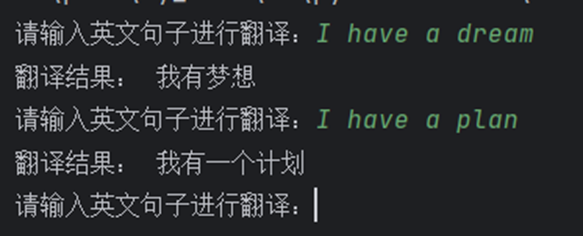
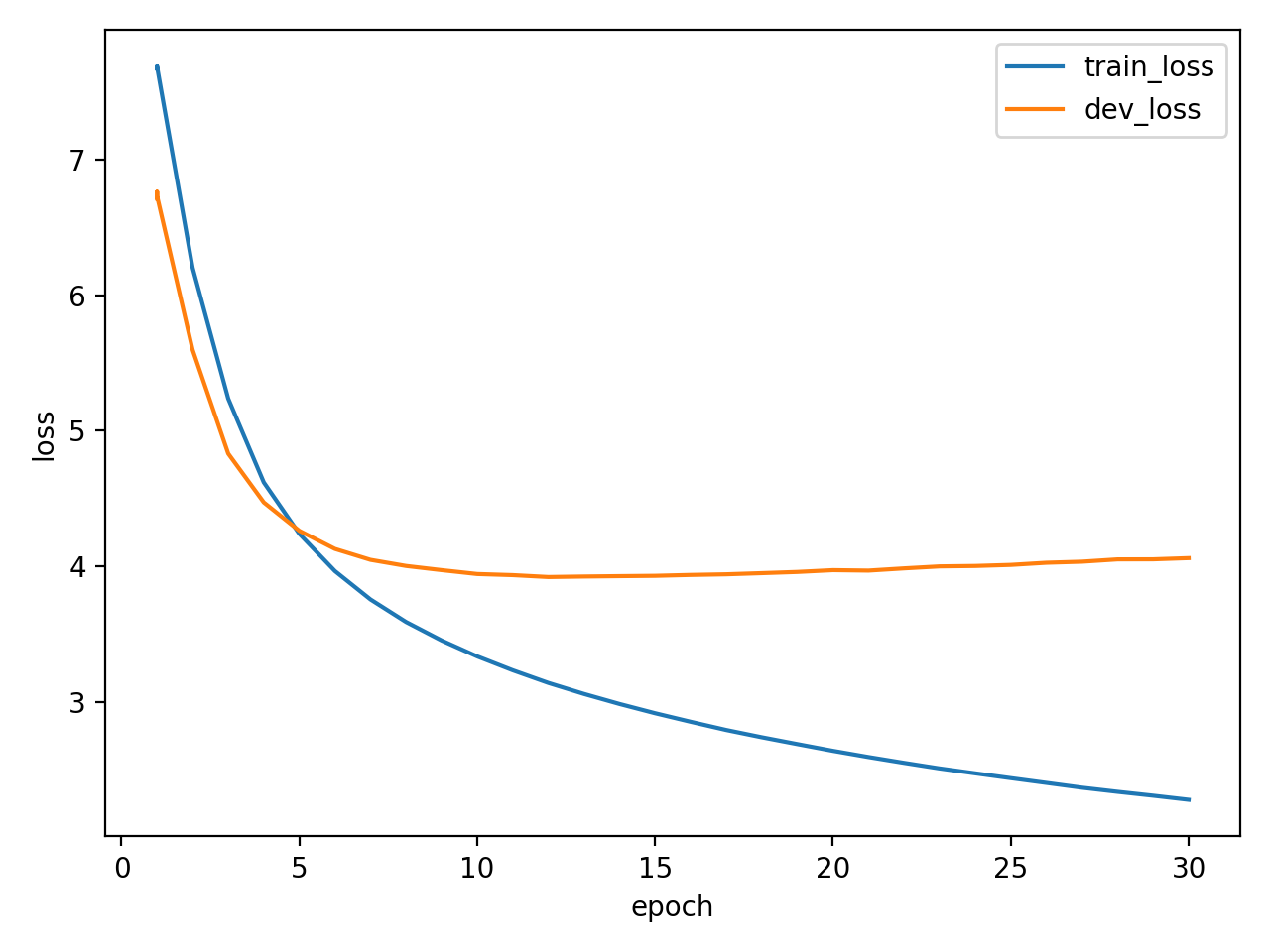
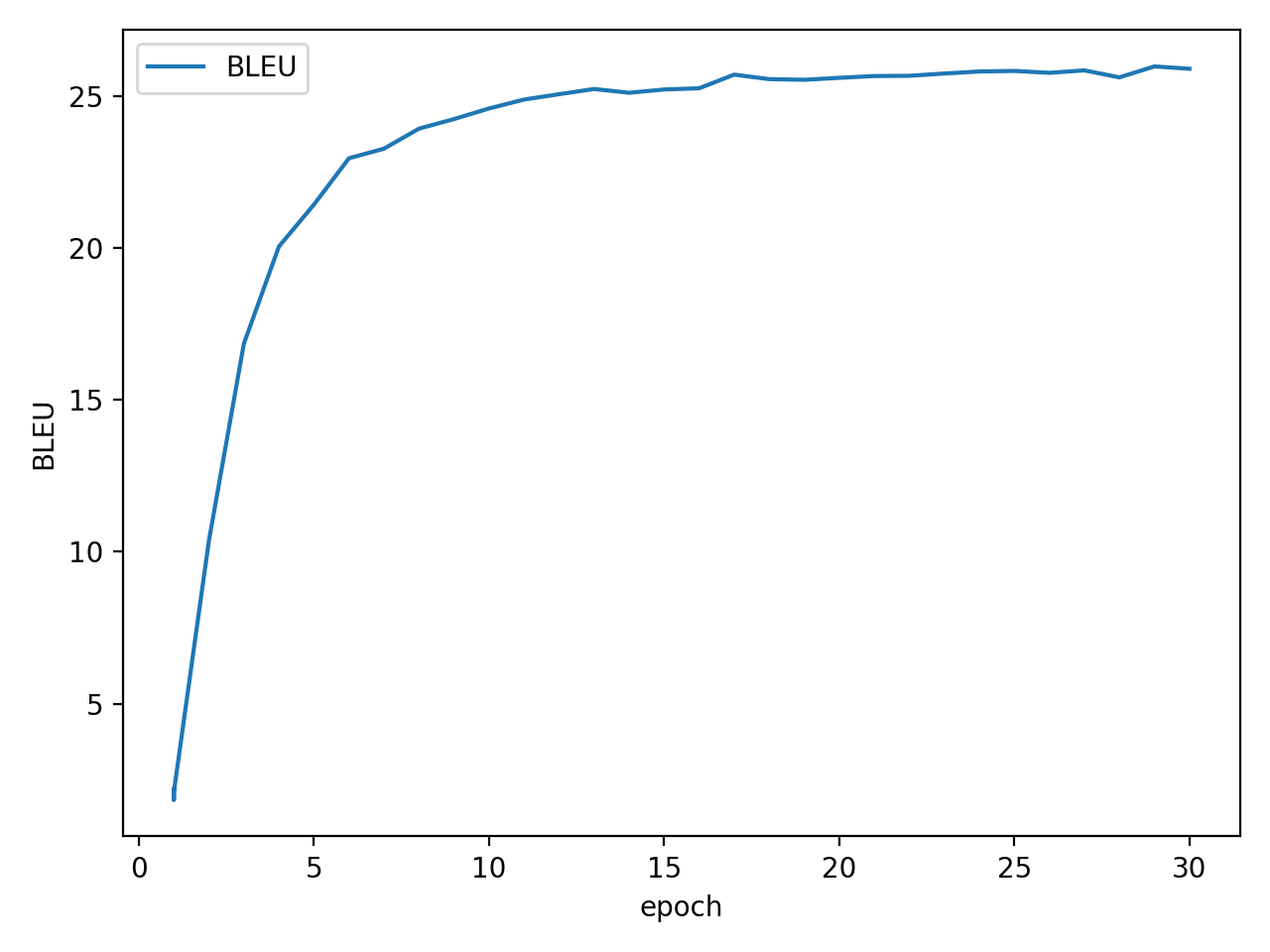
运行main.py模型开始训练
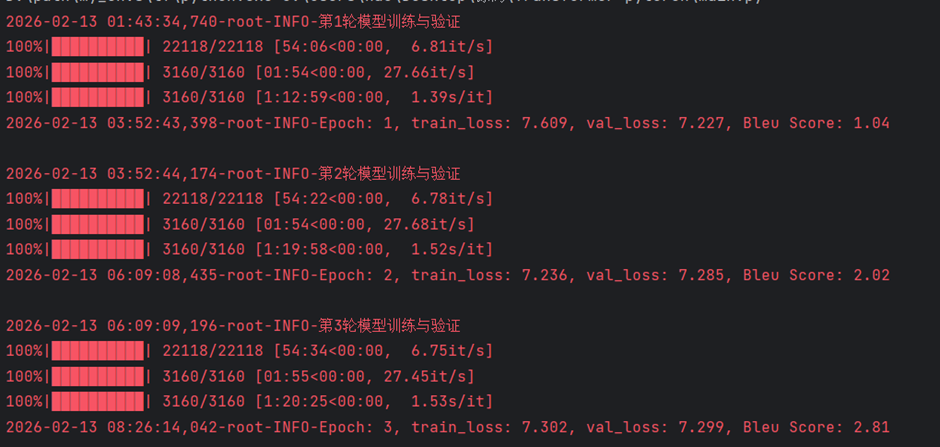
训练完成以后在 results 文件夹下生成对应的权重文件
运行translate.py开始推理,输入英文句子翻译