域
基本概念
域不能算是自定义功能,但自定义功能的使用或多或少都与域相关,有一些还会创建自己的域,因此将域相关的内容写在这里作为补充。
在大型的项目中,变量、函数和类等等都是是大量存在的,如果全都写成全局的,可能会导致很多冲突,也会让命名变得复杂。所以,C++除了局部域、全局域以外,还新增了类域、命名空间域等各种域,用于将各种声明和定义的默认作用范围限制在各个域内。域的本质是影响编译器在编译时查找某个声明和定义出处的逻辑。局部域和全局域除了会影响编译查找逻辑,还会影响变量的生命周期,命名空间域和类域则不会。
命名空间域
C++允许用户自己来定义 域,这种域名为命名空间域,在命名空间域中的所有定义和声明的作用范围都会限制在其内部,如果想在外部访问命名空间域内的变量、函数等。需要使用:: 操作符,如下,"cout"和"endl"都是定义在名为std的命名空间域中的。大多数的域都是用该操作符访问其内部的成员的。
cpp
std::cout << "1" << std::endl;定义命名空间域需要使用关键字namespace,如下,命名空间域只能定义在全局,但是可以像下面这样嵌套定义。
cpp
namespace Test{
//花括号以内是该域的范围
namespace t1{
};
};如下,编译器在编译时能找到的所有同名命名空间域会被视为是同一个命名空间域,即使是在不同文件中。不过要注意只有命名空间域才有这种特性,其它的域是没有的。
cpp
#include<cstdio>
namespace Test {
int te() {
return 3;
}
};
namespace Test {
void ou() {
printf("%d", te());//直接调用
}
};
int main() {
Test::ou();
return 0;
}如果不想一直打操作符 : : ,可以在当前域中用using直接将整个命名空间域展开,这样在当前域中就可以直接访问其该命名空间域中的变量、函数等。展开的生效范围会被域限制,也就是在当前域外部是无法直接访问该命名空间域的,如下
cpp
void innerFunc() {
using namespace MyLib; // 只在innerFunc中有效
//这里可以使用MyLib的内容
}
void otherFunc() {
// ❌ 这里不能直接使用MyLib的内容
// 因为using namespace只在函数innerFunc中
}也可以使用using只展开命名空间域内部的一个成员,如下
cpp
using N::b;函数
C++中的函数新增了缺省参数和函数重载,并且支持模板,适用性更高。
缺省参数
缺省参数就是在声明或定义函数时给参数指定一个默认的值,名为缺省值 ,如果调用函数时没有传入相应的参数,那么该参数就会使用缺省值。如下,func函数的参数a缺省值为10,如果传参时没有传入实参,那么参数a的值就为10。像这样所有参数都有缺省值的叫全缺省 ,只给了一部分缺省值的叫半缺省。
cpp
void func(int a=10) {
printf("%d", a);
}半缺省的函数中,没有缺省值的参数要写前面,有缺省值的写后面,否则会出错。像下面这样的错误写法就会报错。
cpp
void func(int a=10,int b) {
printf("%d", a);
}如果函数的声明和定义是分离的,缺省值必须在函数声明处给出,不能两边都有缺省值。
函数重载
C++支持同一作用域中出现同名函数,但是要求这些同名函数的参数有所不同,可以是个数不同、种类不同,甚至可以是顺序不同,这样调用时才能确定是在调用哪一个。只有返回值不同是不行的。
cpp
void f(int a, char b)//参数顺序不同
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}模板
模板概念
C++的模板是一种支持泛型编程的语言特性,允许编写与类型无关的通用代码。核心就是将类型视为参数 ,使得一段代码可以适用于不同的数据类型,提高代码的复用性。下面以函数模板的使用为例子,类模板的用法是类似的。模板相关内容后面讲类时还会再补充。
类型参数
例如我们想写一个将两变量相加的函数Add,无论是int类型、float类型还是long long类型,实现的方式都是一样的,如果每个类型都写一份函数就显得很多余,这时就可以使用模板,如下,第一行的意思就是这个函数被定义为一个函数模板,还未确定的类型用Type表示,Type就是模板参数 ,由于是用于确定类型,所以Type是模板参数中的类型参数 。在编译时,编译器会根据调用Add时的传入的参数推导出Type的类型,进而实例化出对应的Add函数。
如果传入的都是int类型,那么Type就表示int,如果传入的参数类型不同则会出错,因为这个Add函数虽然没有说明a和b具体是什么类型,但二者的类型显然是一样的,都是"Type"类型。
cpp
template<typename Type>
Type Add(Type a,Type b) {
Type answer= a + b;
return answer;
}声明类型参数除了用typename,也可以用class
cpp
template<class Type>
Type Add(Type a,Type b) {
Type answer= a + b;
return answer;
}如果想要参数a和b是不同的,就需要多个类型参数,如下。不过这样的参数显然就不适合用来做两数相加了。
cpp
template<typename TypeOne,typename TypeTwo>
bool func(TypeOne a, TypeTwo b) {
(void)a;
(void)b;
return false;
}即使有多个类型参数,也可以传入同类型的参数,也就是调用上面的func时,参数a和b可以是同类型的,如下。
由于前面的函数Add和func的参数类型不同(func有两种类型的参数),如果将它们改成同名的话可以构成函数重载,编译器可以将其区分开,所以下面的代码也是可以正常运行的
cpp
template<class Type>
Type func(Type a, Type b) {
Type answer = a + b;
return answer;
}
template<typename TypeOne, typename TypeTwo>
bool func(TypeOne a, TypeTwo b) {
(void)a;
(void)b;
return false;
}
int main() {
int n = 1, m = 2;
char c1 = 'a', c2 = '9' - '0';
func(func(n,m), func(c1,c2));//重载+类型推导
return 0;
}不过这样的代码可以说是恶意满满。
前面这样由编译器根据参数自动推导类型,完成函数模板实例化的叫做隐式实例化,如果函数模板没有参数或者无法推导,亦或者我们需要使用特定的类型,那么就需要我们在调用时指定是什么类型。如下,如果有多个类型参数,指定时按顺序指定,逗号隔开即可。
cpp
template<typename T>
T create() {
T k = 3;
return k;
}
int main() {
int x = create<int>(); // 必须显式指定
double y = create<double>(); // 必须显式指定
return 0;
}非类型参数
在模板中除了将类型作为参数,还可以将常量作为参数,这种模板参数被称为非类型参数,例如下面的代码中,通过声明int类型的常量Size来确定指定数组元素个数。
cpp
template<int Size,typename T>
int func() {
T temp[Size];
return sizeof(temp);
}
int main() {
cout << func<5, int>() << endl;
return 0;
}除了声明像int、char这样简单类型的常量,还可以声明指针、引用、枚举等类型的常量。但是浮点数、类对象 以及字符串是不允许作为非类型模板参数的。
默认模板参数
和函数参数可以指定缺省值一样,模板参数也可以指定默认值,被称为默认模板参数。如下
cpp
template<int Size = 10, typename T = int >
int func() {
T temp[Size];
return sizeof(temp);
}在对应模板参数没有指定时,就会使用默认模板参数,同样,要从右往左给出默认模板参数,即有写默认模板参数的放右边,没有的放左边。
函数模板特化
我们使用模板的目的是希望代码能适应更多的情况,但是有一些情况确实需要特殊处理,那么就需要使用模板特化 。例如下面的比较函数comp,对于大多数简单类型都能适用,但是如果传入的是两个int指针,要比较int指针指向的值,原来的comp函数模板肯定是做不到的,所以要专门实现一个针对传入指针这种情况的版本,这就是函数模板特化,下面第二个就是针对int指针的特化。
cpp
template<typename Type>
bool comp(Type a,Type b) {
return a > b;
}
//对comp函数模板进行特化,针对int指针
template<>
bool comp<int*>(int* a,int* b) {
return *a > *b;
}像上面这样,针对特殊情况,为所有模板参数都指定具体类型(或者常量值)的叫做全特化 ,只指定一部分的或者对模板参数进行某种"修饰"的(如类型参数T特化为T*、T&等)叫偏特化 。函数模板只有全特化,没有偏特化,类模板才有。如果需要偏特化的效果,直接用函数重载就好了。
在函数模板特化时要注意,特化后的函数模板 的参数、返回值应和原来的函数模板能匹配得上,比如原来的comp函数模板的两个参数是相同的,如果特化后变成不同的了,或者少了一个、多了一个,亦或者返回值改了等等,都会让编译器认为这是两个不同的函数模板,进而出现编译错误。
函数模板分离编译
一个程序(项目)由若干个源文件共同实现,而每个源文件单独编译 生成目标文件,最后将所有目标文件链接起来形成单一的可执行文件的过程称为分离编译模式。我们知道,函数模板需要在编译时,让编译器根据调用情况,用函数模板实例化出具体的函数才能使用,只靠函数模板的声明是无法实例化出具体的函数的。
以前面的comp函数模板为例,如果调用comp的代码和comp的定义放在两个不同的源文件(比如分别放在main.cpp和mytem.cpp,示意代码如下),由于每个源文件是单独编译的,编译main.cpp时,编译器看到了调用函数模板的代码comp(5,3),想要实例化出函数add<int>,但是只有声明没有定义,无法实例化。而编译mytem.cpp时,编译器只看到了comp的定义,没看到调用它的代码,也就没有实例化请求,所以不会实例化。最终,在链接时,链接器找不到add<int>的定义,于是报错。
cpp
// mytem.cpp
#include "mytemplate.h"
template<typename Type>
bool comp(Type a,Type b) {
return a > b;
}
// mytem.h
#pragma once
template<typename Type>
bool comp(Type a,Type b); // 只有声明,没有定义
// main.cpp
#include "mytem.h"//头文件展开后只能拿到声明
int main() {
comp(5, 3); // 需要add<int>,但定义看不到!
return 0;
}常见的解决办法有两个,推荐的做法是把函数模板的定义直接写在头文件中,另一个做法是在函数模板定义所在的文件中,通过代码显示实例化出需要的版本,也就是让编译器直接生成指定的版本,如下
cpp
// 显式实例化需要的版本
template int add<int>(int, int);
template double add<double>(double, double);枚举
C++中的枚举相较于C语言的有所改进,但定义格式是差不多的,多了个class(或者struct)。并且实例化枚举类型的对象时不需要再加上enum
cpp
// 或 enum struct Color { RED, GREEN, BLUE }; // 两者等价
enum class Color
{
RED,
GREEN,
BLUE
};
Color c;最关键的区别是C++的枚举(C++11以后)有域的限制。定义枚举时,相当于创建了一个新的域,例如上面的枚举就相当于创建了一个名为Color的域。使用枚举成员时,需要指明哪个域,如下
cpp
if (c1 == Color::BLUE);
Color c2 = Color::RED;// 正确,必须指定作用域
// Color c3 = RED; // 错误:RED 未在此作用域声明其次,C++的枚举不再支持隐式类型转化,即使都是整形也不能直接赋值。
cpp
// int i = c; // 错误
int i = static_cast<int>(c); // 必须显式转换 最后,C++支持显示指定底层类型。在C语言中,枚举成员的底层类型是由编译器决定的,可能是int、char等,但在C++中可以自行决定
cpp
enum Color : unsigned char { // 指定为unsigned char
RED,
GREEN,
BLUE
};
enum class ErrorCode : short int{ // 指定为短整型
SUCCESS = 0,
ERROR = 1
};类
基础
类就是结构体的升级版,关键字class和struct都可以用来定义类,类中可以定义成员函数。在下面的例子中,public和private是访问限定符 ,public修饰的成员在类外可以直接被访问,即公开 的,protected和private修饰的成员在类外不能直接被访问,即私有的。例如成员_show和成员函数Init外部可以直接访问,但末尾的array等被private修饰的成员则不行。protected的用法涉及到继承概念,后面再讲。
访问权限作用域从该访问限定符出现的位置开始直到下一个访问限定符出现时为止,如果后面没有访问限定符,作用域就一直到类结束。class定义的类中,成员没有被访问限定符修饰时默认为private,struct的默认为public。
cpp
#include<iostream>
using namespace std;
class Stack
{
public:
int _show;
// 成员函数
void Init(int n = 4)
{
array = (int*)malloc(sizeof(int) * n);
if (nullptr == array)
{
perror("malloc申请空间失败");
return;
}
capacity = n;
top = 0;
}
void Push(int x)
{
array[top++] = x;
}
int Top()
{
assert(top > 0);
return array[top - 1];
}
void Destroy()
{
free(array);
array = nullptr;
top = capacity = 0;
}
private:
//成员变量
int* array;
size_t capacity;
size_t top;
}; 类定义了一个新的作用域,类的所有成员都在类的作用域中,在类外定义成员函数时,需要使用作用域操作符 : : 指明成员属于哪个类域。类域影响的是编译的查找规则,下面的程序中Init如果不指定类域Stack,编译器会把Init当成全局函数,那么编译时,找不到array等成员的声明/定义在哪里,就会报错。指定类域Stack,编译器就是知道Init是成员函数,当前域找不到的array等成员,就会到类域中去查找。
cpp
#include<iostream>
using namespace std;
class Stack
{
public:
void Init(int n = 4);
private:
int* array;
size_t capacity;
size_t top;
};
// 声明和定义分离,需要指定类域
void Stack::Init(int n)
{
array = (int*)malloc(sizeof(int) * n);
if (nullptr == array)
{
perror("malloc申请空间失败");
return;
}
capacity = n;
top = 0;
}直接在类的内部实现的成员函数,编译器会自动将其视为inline函数,即被inline修饰的函数。inline是一个关键字,会建议编译器将函数内联展开,也就是将调用处的代码直接替换为函数体本身。inline只是一个建议,是否内联展开由编译器自行决定。
类实例化出的对象(即用类定义的变量,指针、引用除外)存储时也符合内存对齐的规则。对象中只会存储成员变量,不存储成员函数,所以计算方式和结构体是一样的。如果类中一个成员变量都没有,该类实例化出的对象也会占据1字节的空间,以表示该对象存在。
this指针
类中的成员函数无需传参却能够访问类内部的成员变量,是因为成员函数的第一个参数是隐藏的this指针,它是当前类类型的指针,无法修改。成员函数访问成员变量或调用成员函数本质都是通过this指针完成的。成员函数定义时不能在参数中写this指针,但可以在函数内部显式地使用this指针,如下
cpp
#include<iostream>
using namespace std;
class Date
{
public:
void Init(int year, int month, int day)
{
_year = year;
this->_month = month;
this->_day = day;
}
private:
int _year;
int _month;
int _day;
};
int main(){
Date dd;
dd.Init(2026,1,20);
return 0;
}上面的代码中,Data类的对象dd调用成员函数Init时,Init中的this指针指向的就是对象dd。前面提到,类的成员函数并不存储在类对象中,成员函数的存在也不依赖于类对象。例如调用成员函数(虚函数除外)时,如果不访问成员变量,可能类对象不存在也不会出错。就如下面的代码,它是可以正常运行的
cpp
#include<iostream>
using namespace std;
class A
{
public:
void Print()
{
cout << "A::Print()" << endl;
}
private:
int _a;
};
int main()
{
A* p = nullptr;
p->Print();
return 0;
}当然,这样的用法是错误的,这是未定义行为。
操作符重载
++、--、()等符号就是操作符,也叫运算符,C++语言允许我们定义类对象使用操作符的效果,比如下面的代码中在全局重载了操作符++,对Test类对象data使用++时就会执行重载的功能。本质上就是定义了一个特殊的函数,有着特殊的函数名和调用方式。例如下面的++data,本质就是operator++(data)。
操作符重载至少要有一个类类型的参数,不能改变内置类型对象使用该操作符的含义,如int operator++(int x);
cpp
#include<iostream>
using namespace std;
class Test {
public:
Test(int* np)
:_p(np)
{}
int* _p;
};
Test& operator++(Test& a) {//前置++重载
(*(a._p))++;
return a;
}
int main() {
int n = 3;
Test data(&n);
++data; //data作为参数传入++重载
cout << n << endl;
return 0;
}C++规定,对于可以重载的操作符,类对象使用时必须调用对应的操作符重载,否则会编译报错。以下五个操作符不能重载。语法中没有的操作符也不能重载。
cpp
. // 成员访问
.* // 成员指针访问
:: // 作用域解析
?: // 三元条件
sizeof // 大小重载操作符函数的参数个数和该操作符作用的操作对象数量一样多。一元操作符有一个参数,二元操作符就有两个。二元操作符的左侧操作对象会传给第一个参数,右侧操作对象传给第二个参数。
如果一个重载操作符函数是成员函数,则它的第一个操作对象默认传给隐式的this指针,因此操作符重载作为成员函数时,参数比操作对象少一个。运算符重载以后,其优先级和结合性与对应的内置类型运算符保持一致。
定义在类内部的操作符重载使用方式是一样的,不过第一个参数会被this指针占用。
cpp
#include<iostream>
using namespace std;
class Test {
public:
Test(int* np)
:_p(np)
{}
Test& operator++() {//前置++重载
(*(a._p))++;
return a;
}
int* _p;
};
int main() {
int n = 3;
Test data(&n);
++data; //data作为参数传入++重载
cout << n << endl;
return 0;
}以下四个操作符的重载必须是类内的成员函数(非静态)。
cpp
= //与对象创建和生命周期紧密相关,需要访问私有成员
[] //需要访问对象内部状态,实现边界检查等
() //实现函数对象,必须绑定到具体对象实例
-> //访问对象成员,语义上必须与对象关联重载<<和>>时,需要重载为全局函数,因为重载为成员函数的话,this指针会抢占第一个形参位置,第一个形参位置是左侧运算对象,调用时就变成了 类对象<<cout ,不符合使用习惯和可读性。重载为全局函数,把ostream 或 istream放到第一个形参位置就可以了,第二个形参位置当类类型对象。
有些操作符有前置和后置两种用法,如++。C++规定,后置操作符重载时增加一个int哑元参数,也就是只写个int,不写参数名,用于区分是前置操作符重载还是后置操作符重载。如下
cpp
Test& operator++(Test& a, int) {//后置++重载
(*(a._p))++;
return a;
}操作符 -> 重载
->操作符的重载比较特殊,它的返回值必须是可以使用->操作符的类型,即指向类类型的指针或同样定义了->操作符重载的类对象。这是因为编译器会在调用->重载的代码处再加一个->。例如下面的代码。你看到的是data->_p,实际上是data-> -> _p,如果第二个->也是重载的,那还会再加一个,变成3个->,直到可以直接使用->。如果下面代码里的operator->返回的是也Test类型,那么由于该类型有重载->,如果编译的话就会不停地加->,所以编译器会直接报错。
cpp
#include<iostream>
using namespace std;
class Test {
public:
Test(int n)
:_p(n)
{}
Test* operator->() {
return this;
}
int _p;
};
int main() {
int n = 3;
Test data(n);
cout << data->_p << endl;
return 0;
}这么做是因为操作符->本身就比较不同,原本的->操作符是访问类类型指针的一个成员,如下,pd->_p 返回的是pd指针指向的类对象中,名为_p的成员。关键就在于它是返回名为_p的成员,没有类型,只有一个名字_p。而操作符重载的目的 就是为了让类也可以使用由我们定义的、类似操作符的功能,但是像->操作符这样通过一个名字找变量的功能并不容易直接实现,所以它的重载才出现了这种比较奇特的规则。
cpp
Test data;
Test* pd = &data;
pd->_p默认成员函数
基本概念
默认成员函数 是当用户没有显式实现时,编译器会自动生成的成员函数。这种函数共有6个,分别是构造函数、析构函数、拷贝构造、赋值运算符=重载、取地址重载和const对象取地址重载,后两个很少需要我们自己实现,我们主要关心前4个。
构造函数
构造函数主要用于类对象实例化时完成成员变量的初始化,或者做一些准备工作,比如打开文件。构造函数最主要的优点是它会在类实例化时自动调用。
构造函数的声明与其它函数有所不同,如下。它的名字只能和类名相同,不能写返回值,void也不能写。如果类中没有定义构造函数,C++编译器会自动生成一个没有参数的默认构造函数,如果用户定义了构造函数则不再生成。将构造函数公开才能直接实例化对象,但有些情况下也会将构造函数设为私有,比如要确保这个类只能实例化出一个对象时。另外,除一些特殊情况外,构造函数是可以重载的。
cpp
class Test {
public:
Test(int n) {
_size = n;
}
int _size;
};
int main(){
Test t(3);//调用构造
return 0;
}无需传入参数就能调用的构造函数就是**默认构造函数,**如无参构造函数、全缺省构造函数以及编译器默认生成的构造函数,都是默认构造函数。默认构造函数只能存在一个,否则编译器不知道调用哪个。
编译器默认生成的构造函数对内置类型成员变量(int、char等)的初始化没有要求,可能会初始化,也可能不会。而对于自定义类型成员变量,则会调用其默认构造函数,如果没有就会报错。
初始化列表
这种没有默认构造函数的成员变量需要通过初始化列表初始化,在当前类的构造函数的函数体中是不行的,因为在执行构造函数前就需要完成对成员变量的构造。示例代码如下。这种要求是C++为例保证对象自诞生起就处于一个完整、可用的状态,简单来说就是开辟完空间就要及时初始化,防止用户使用这种内部存在随机值的畸形对象。此外,引用成员变量、const成员变量也必须放在初始化列表位置进行初始化,否则会报错。
cpp
class Test {
public:
Test(int n) {
_size = n;
}
int _size;
int data =0;
};
class ForTest {//正确
public:
ForTest(int n, int m)
:_t(n),
_capacity(m)
{}
Test _t;
int _capacity;
};
class ForTest {//错误示例
public:
ForTest(int n, int m)
{
_t(n); //这个被当成调用()操作符重载
_capacity = m; //这个其实是赋值
}
Test _t;
int _capacity;
};初始化列表写在构造函数声明后面,冒号开头,逗号隔开,括号里放初始值,结尾不要有多余的逗号。每个成员变量在初始化列表中只能出现一次,语法理解上初始化列表可以认为是每个成员变量定义初始化的地方。
C++11支持在成员变量声明的位置给缺省值,如下。这个缺省值主要是给没有在初始化列表初始化的成员使用的。 不过还是尽量使用初始化列表初始化,因为不在初始化列表初始化的成员也会走初始化列表,如果这个成员在声明位置给了缺省值,初始化列表会用这个缺省值初始化。如果没有给缺省值,对于没有在初始化列表初始化的内置类型成员,是否初始化取决于编译器,C++并没有规定。而初始化列表初始化的自定义类型成员会调用这个成员类型的默认构造函数,如果没有默认构造会编译错误。
cpp
class Test {
public:
Test(int n) :_size(n)
{}
int _size;
int data =0; //给缺省值
};初始化列表中按照成员变量在类中声明顺序进行初始化,跟成员在初始化列表出现的的先后顺序无关。建议初始化列表的顺序与声明顺序保持一致。
隐式类型转换
隐式类型转换是指编译器在不需要类型转换操作符的情况下,自动将一种数据类型转换为另一种数据类型。C++支持将任意类型隐式转换为类类型对象,需要有相关类型为参数的构造函数,一般用于函数传参或者返回值。例如要将int类型变量转换为Test类类型对象,那么Test就要有以int类型为参数的构造函数,如下。
cpp
class Test {
public:
Test(int n) :_size(n)
{}
Test(int n,char c):_size(n),_data(c)
{}
int _size;
char _data = 'a'; //给缺省值
};
Test func1() {
return 1; //隐式类型转换
}
Test func2() {
return {1,'f'};//C++11以后才支持多参数转换
}
int main() {
func1();
func2();
return 0;
}类类型的对象之间也可以隐式转换,需要相应的构造函数支持。原理是差不多的,这里不再演示。
显示类型转换(补充)
既然提到了隐式类型转换,就顺便补充一下显示类型转换。在C++中提供了多种显示类型转换的方式,我们只讲比较简单的两个。绝大多数情况下,使用static_cast即可,static_cast用法如下
cpp
int i = 42;
double d = static_cast<double>(i); // 整型转浮点
float f = 3.14f;
int n = static_cast<int>(f); // 浮点转整型(截断)
char c = 'A';
int ascii = static_cast<int>(c); // 字符转整型如果要移除或者添加const,则使用const_cast,不过这个比较危险,慎用。
cpp
// 移除const
const int ci = 10;
int* modifiable = const_cast<int*>(&ci);
*modifiable = 20; // 危险:修改原本是const的值是未定义行为
// 添加const
int i = 100;
const int* pc = const_cast<const int*>(&i);
// *pc = 200; // 错误:不能通过const指针修改析构函数
析构函数与构造函数相反,它会在对象的生命周期结束时自动调用,主要功能是回收对象在栈区以外的资源,如new或malloc申请的堆区空间等,存放在栈区的对象本身是自动销毁回收的,不需要我们操心。
析构函数的声明更加简单,它的函数名是类名前面加上~,没有参数也没有返回值,一个类只能由一个析构函数,如果用户没有定义,则系统会自动生成默认的析构函数,这种生成的析构函数会调用自定义类型成员的析构函数,对内置类型成员不做处理。不过即使我们定义了析构函数,一样会调用自定义类型成员的析构函数。
cpp
class Test {
public:
Test(int* np)
:_p(np)
{
}
~Test() {//析构函数
_p = nullptr;
}
int* _p;
};析构函数可以显示调用,但是即使调用过了,在对象生命周期结束时一样会再调用。一般不会这么多次一举,资源双重释放的后果大家都清楚,不多赘述了。
如果要在构造函数或者析构函数中操作外部的资源(如关闭文件、管道等),一定要细心,因为很多情况都会调用构造函数和析构函数,要注意防止外部资源被意外更改。尤其是析构函数,一般都是隐式调用,出了问题更不容易发现。
拷贝构造函数
拷贝构造函数是构造函数的一个重载,一般用于通过类对象构造类对象,或者涉及类对象的函数传参或返回。例如下面这段代码,要将Test类的一个对象Date作为参数传入函数func,根据函数传参的本质,函数func需要复制一份Data而不是直接使用,这需要用一个Test类对象(实参)来构造另一个Test类对象(形参),此时就是拷贝构造函数登场的时候。返回自定义类型对象时也是同理。
cpp
class Test {
public:
Test(int* np)
:_p(np)
{}
Test(Test& oth) {//拷贝构造
_p = oth._p;
}
int* _p;
};
void func(Test tt) {
(void)tt;
}
int main() {
int n = 3;
Test Data(&n);
func(Data);
return 0;
}如果用户没有定义拷贝构造,编译器一样会自动生成拷贝构造,其对内置类型会使用值拷贝(就是一个字节一个字节地拷贝,也叫浅拷贝),对于自定义类型成员变量则会调用它的拷贝构造。一般而言,如果类对象会使用外部的资源,并且不希望与其它对象共享时,拷贝构造函数就需要将这些外部资源也复制或申请一份,例如用于维护栈、队列等数据结构的类,其对象需要自己独占资源。
拷贝构造函数只能有一个参数 ,而且该参数必须是该 类 类型的引用,否则调用拷贝构造函数本身又需要调用拷贝构造函数,这样下去没完没了,编译器也不允许我们这样写。
赋值运算符重载
赋值运算符重载的参数可以是任意类型,但只有支持用当前类类型的对象进行赋值的运算符重载才是默认成员函数,下面说的赋值运算符重载也特指这一种。
赋值运算符重载用于完成两个已经存在的对象通过赋值符=进行拷贝赋值。赋值运算符重载要返回当前类类型的引用,以支持链式赋值。它的参数建议写成const当前类类型引用,否则调用时传参需要拷贝,影响效率。
cpp
class Test {
public:
Test(int n)
:_p(n)
{}
Test& operator=(Test& a) {//赋值运算符重载
_p=a._p;
return *this;
}
int _p;
};和拷贝构造函数类似,赋值运算符重载没有显式实现时,编译器会自动成一个默认赋值运算符重载,对内置类型成员变量会进行值拷贝,对于自定义类型成员变量则会调用它的赋值重载函数。同样,如果类对象会使用外部的资源,并且不希望与其它对象共享时,就需要我们自己实现赋值运算符重载,以进行深拷贝(将指向的资源也进行拷贝)。
零碎知识汇总
静态成员
类内部用static修饰的成员变量被称为静态成员变量,静态成员变量一定要在类外初始化,因为同一个类的所有对象访问的是同一个静态成员变量,它存放在静态区,不属于某一个对象。也不能在静态成员变量的声明位置给缺省值,因为给缺省值本质是在初始化列表中用缺省值初始化,而它不属于某一个对象,不能走初始化列表,否则每个对象创建时,它都要再初始化一遍,显然不合理。
用static修饰的成员函数就是静态成员函数,它没有this指针。在静态成员函数种可以访问静态成员,但不能访问非静态的,因为没有this指针。而非静态的成员函数则可以访问任意的静态成员。在类外部,除了通过类对象访问静态成员外,还可以通过域访问操作符访问,但静态成员也会受到public、private等访问限定符的限制。
cpp
class A
{
// 静态成员函数
static void func(int a) {
(void)a;
}
private:
static int _a1; //静态成员变量
};友元
如果想在类外部访问某一个类的私有和保护成员,就需要在该类中添加友元声明。例如下面在B类中添加了函数func的友元声明,func成为了B类的友元函数。友元函数可以在类定义的任何地方声明,不受类访问限定符的限制。
cpp
class B
{
// 友元声明,让函数func可以访问私有成员
friend void func( const B& bb);
private:
int _b1 = 3;
int _b2 = 4;
};
void func( const B& bb)
{
cout << bb._b1 << endl;
}除了声明友元函数,也可以声明友元类。友元类中的成员函数都可以是另一个类的友元函数,都可以访问另一个类中的私有和保护成员。友元类的关系是单向的,不具有交换性,比如A类是B类的友元,但是B类不是A类的友元。友元类关系不能传递,如果A是B的友元, B是C的友元,但是A不是C的友元。友元不适合经常使用,因为会增加耦合度,破坏封装。
cpp
class B
{
// 友元声明
friend class A;
private:
int _b1 = 1;
int _b2 = 2;
};
class A
{
public:
void func1(const B& bb)
{
cout << bb._b1 << endl;
}
};内部类
定义在类内部的类就是内部类,包裹着内部类的就是外部类,内部类默认是外部类的友元类。前面提到类会创建一个自己的域,那么内部类就是在这个域内定义的一个类,受到外部类的类域限制。此外,内部类还会受到外部类的访问限定符的限制,如果定义为private或protected,外面就不能直接通过域访问操作符: :访问。内部类一般就是专门定义给外部类使用的。
cpp
class A
{
private:
static int _k;
int _h = 1;
public:
class B // B默认就是A的友元
{
public:
void foo(const A& a)
{
cout << _k << endl; //访问私有非静态成员
cout << a._h << endl; //访问私有静态成员
}
int _b1;
};
};匿名对象
在下面的代码中,直接用类型名加括号这种方式定义的对象就是匿名对象,没有名字,生命周期只在当前一行,括号里面就是传入构造函数的参数。一般当作一种临时变量使用,例如函数传参时临时构造一个匿名对象传入,在写算法题时经常会用到。
cpp
class Test {
public:
Test(int n):_p(n)
{}
int _p;
};
int main() {
Test(3);//匿名对象,现做现用,执行下一行就没了
Test t(3);//有名对象,可以持续存在
return 0;
}类模板
基本功能
类模板的声明和函数模板差不多,都是在定义前面加上一行template声明。类型参数、非类型参数和默认模板参数等基本功能的使用格式和效果也是相似的,只不过一个是函数一个是类罢了,这里不再重述,可以参考下面这个简单的代码。其次,类模板也有分离编译的问题,解决方式和函数模板是一样的,将定义也写到头文件中(推荐),或者在定义的位置显式实例化,具体方法在下面的代码中也有演示。
cpp
template<typename T = int, int N = 5>
class FixedArray {
private:
T data[N]; // 使用非类型参数定义数组大小
};
template class FixedArray<char, 16>;//演示:显式实例化出特定的类,注意是类不是对象
int main() {
// 使用所有默认参数
FixedArray<> arr1;
//部分使用
FixedArray<char> str;
//两个对象类型不同
//arr1 = str;//错误:赋值运算符重载的参数不匹配
return 0;
}类模板特化
类模板既可以全特化也可以偏特化,全特化没什么好说的,基本和函数模板的全特化差不多,就是为特定的一组模板参数实现特定的类,即特殊要求特别处理,可以参考下面的代码。我们主要后面主要讲偏特化。
cpp
#include<iostream>
#include<string>
using namespace std;
template<typename T, int ID>
class TV {
public:
void info() {
cout << "Generic TV" << endl;
}
};
// 针对string类型、ID=0的全特化
template<>
class TV<string, 0> {
public:
void info() {
cout << "Special TV for strings (ID=0)" << endl;
}
};
int main() {
TV<int, 1> test;
test.info(); // 输出: Generic TV
TV<string, 0> test1;
test1.info(); // 输出: Special TV for strings (ID=0)
return 0;
}偏特化有两种表现形式,一种是特化一部分模板参数,例如下面的例子中,将Data类第二个参数特化为int类型。
cpp
template<class T1, class T2>
class Data
{
public:
Data() { cout << "Data<T1, T2>" << endl; }
private:
T1 _d1;
T2 _d2;
};
// 将第二个参数特化为int
template <class T1>
class Data<T1, int>
{
public:
Data() { cout << "Data<T1, int>" << endl; }
private:
T1 _d1;
int _d2;
};另一种偏特化方式是不给出具体的类型参数,但将类型参数限制为指针或引用,例如下面代码是将上面的Data类的参数分别限制为指针和引用。
cpp
//两个参数偏特化为指针类型
template <typename T1, typename T2>
class Data <T1*, T2*>
{
public:
Data() { cout << "Data<T1*, T2*>" << endl; }
private:
T1 _d1;
T2 _d2;
};
//两个参数偏特化为引用类型
template <typename T1, typename T2>
class Data <T1&, T2&>
{
public:
Data(const T1& d1, const T2& d2)
: _d1(d1)
, _d2(d2)
{
cout << "Data<T1&, T2&>" << endl;
}
private:
const T1& _d1;
const T2& _d2;
};
void test2()
{
Data<double, int> d1; // 调用特化的int版本
Data<int, double> d2; // 调用基础的模板
Data<int*, int*> d3; // 调用特化的指针版本
Data<int&, int&> d4(1, 2); // 调用特化的指针版本
}
int main() {
test2();
return 0;
}模板模板参数
类模板的类型参数可以是另一个类模板,这种参数被称为模板模板参数,它的参数列表就写在它自己前面即可,声明格式如下
cpp
// 普通模板参数 模板模板参数(一个带有两个模板参数的模板)
template<class T, template<typename,typename> class Container>
class Wrapper1;如果看着比较乱的话可以参考下面的划分。

使用示例如下。
cpp
template<typename T>
class AC {
T data [30];
};
template<typename T, template<typename> class Cont>
class Wrapper {
private:
Cont<int> i;// 使用模板模板参数声明成员变量
Cont<char> c;
Cont<T> t;
};
int main() {
Wrapper<int, AC> test;
return 0;
}注意vector有两个模板参数,第二个是分配器allocator(它也是类模板),虽然vector声明时有为分配器定义默认模板参数,但是我们在类模板内定义时还是得显式地声明出来,因为编译器只看到Container声明了两个模板参数,它可不管你这那的。
cpp
#include<vector>
using namespace std;
template<class T, template<typename,typename> class Container>
class Wrapper1 {
Container<int, allocator<int> > ct1; //显式声明Container的第二个模板参数
Container<char, allocator<char> > ct2;
Container<T, allocator<T> > ct3;
};
int main() {
Wrapper1<int,vector> t;
return 0;
}继承
基本概念
工人和司机是人类的一种身份,而有些事情并不关心他们是什么身份,例如当他们去看电影时,电影院只关心他们有没有买票。同样也有些事情需要用到他们的身份,比如他们去工作的时候,他们的领导就得区分工人和司机。可以发现,管理工人和司机时,我们有时候需要抛开身份共同管理,有时候又需要单独管理某个身份。
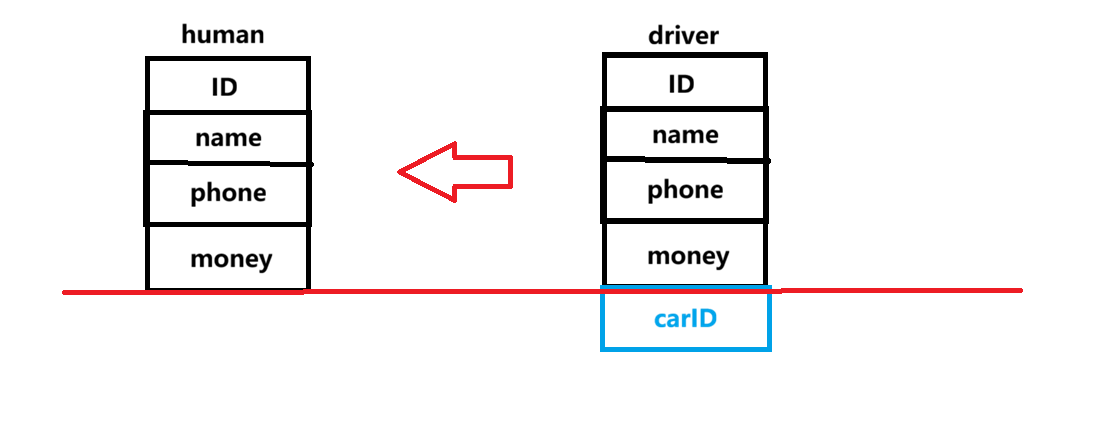
从C++编程的角度看,如果用两个类分别描述工人和司机,那么在电影院看来有些多余,如果只用一个类描述他们,在他们的领导看来简直无理取闹,工人和司机怎么能混着用。其次,由于身份的不同,工人和司机也会有自己独有的属性,如工人有工位,司机有车牌号,这些属性并不通用。如果要让代码既能共同管理工人和司机,又能区分他们,并且让他们有各自的属性,就需要使用**继承。**继承格式如下

首先我们写一个名为人类(human)的类,再用工人(worker)类和司机(driver)类继承这个人类类,在他们各自的类中补充自己独有的属性,如下,具体的格式说明在后面。这样工人类的对象和司机类的对象不仅有人类的属性,还有自己独有的属性。
cpp
class human
{
public:
long long int ID; //身份证
char name[16]; //名字
long long int phone;//电话
short int money; //零钱
};
class worker : public human //工人类继承人类类,会拥有人类类中的属性(public的)
{
int workstationID; //工位号
};
class driver : public human
{
char carId[16]; //车牌号
};其次,工人类对象和司机类对象就既可以相互区分,又能当作人类类对象使用。如下
cpp
char* Driving(driver& d) //开车,让司机来
{
return d.carId;
}
bool BuyTickets(human& consumer)//买票,是个人就行
{
if (consumer.money >= 40) {
consumer.money -= 40;
return true;
}
return false;
}
int main() {
worker w;
w.money = 389;
//Driving(w);//错误:无法用worker类型的值初始化driver&类型的引用(非常量限定)
BuyTickets(w);
human* hp=&w; //指针
human& hh=w; //引用
human h = static_cast<human>(w);//类型转换
return 0;
}像human这样被继承的类就叫基类 ,也叫父类,driver、worker这样的则叫作派生类,也叫子类。从前面的例子我们可以看到,派生类对象可以赋值给基类的指针(需要取地址)或引用。这种操作也被称为切割,因为基类指针或引用指向的就是派生类中基类那部分,就好像派生类的成员被切掉了。
但是基类对象不能赋值给派生类对象,毕竟缺少派生类的成员。如果要禁用继承,在类声明处加上final关键字,或者将构造函数设为私有即可,因为派生类必须调用基类的构造函数才能实例化。
cpp
class Base final
{
};派生类也可以访问基类的成员函数,如下
cpp
// 基类
class Base {
public:
void showMessage() {
cout << "这是基类的成员函数" << endl;
}
};
// 派生类
class Derived : public Base {
public:
void callBaseFunction() {
// 可调用继承自基类的成员函数
showMessage();
}
};
int main() {
Derived obj;
// 派生类对象可直接调用继承的函数
obj.showMessage();
return 0;
}关于继承有几个要注意的点,首先友元关系不能继承 ,基类的友元不能访问派生类的私有和保护成员。其次静态成员在整个继承体系内都是唯一的,例如在基类中定义了一个静态成员变量val,那么无论派生出多少派生类,都只有一个val。
继承类模板
继承类模板时,需要注意以下几点。首先派生类必须声明模板参数,供基类使用。
cpp
template<typename T>
class Base {
public:
T value;
};
// 正确:派生类模板化,并传递给基类
template<typename T>
class Derived : public Base<T> { // 必须使用Base<T>,不能直接Base
// ...
};在派生类中使用基类模板成员变量或函数时,需要显式写出this->或者指定基类的类域
cpp
template<typename T>
class Derived : public Base<T> {
public:
void show() {
// 错误:直接使用value可能编译失败
// cout << value;
// 正确方法1:使用this->
cout << this->value;
// 正确方法2:显式指定作用域
cout << Base<T>::value;
}
};在声明派生类成员变量或函数时要正确使用基类类型,Base是模板而不是具体类型,Base<T>才是
cpp
template<typename T>
class Derived : public Base<T> {
public:
// 错误:Base是模板,不是具体类型
// Base GetBase();
// 正确:使用Base<T>作为返回类型
Base<T> GetBase();
};最后,在继承时也可以指定继承特定实例化的基类模板
cpp
// 继承固定类型的基类模板实例
class DerivedInt : public Base<int> {
// 直接使用Base<int>,不需要再模板化
};基类成员访问限制
派生类中包含了基类所有成员的声明,就如上面的worker类里面其实包含了human类中的money、name等所有成员的声明。而对于基类中被private修饰的私有成员,派生类中虽然也有,但是是不可见的。基类成员在派生类中的属性与访问限定符和继承方式有关,上面的例子都是public继承,实际应用中一般也都是用public继承。
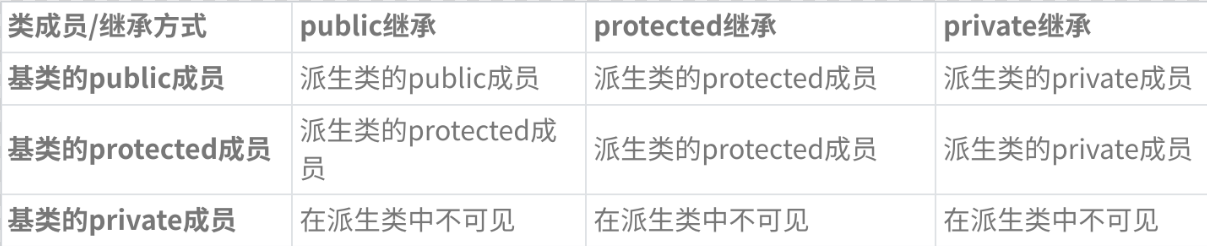
使用关键字class时默认的继承方式是private,使用struct时默认的继承方式是public,不过最好显式的写出继承方式。另外,访问限定符protected的作用就是让派生类可以访问protected成员,但在类外部不能访问。
隐藏
我们知道类会创建一个自己的域,而基类的域和派生类的域是相互独立的。如果派生类和基类中有同名成员,那么派生类的成员将屏蔽对基类同名成员的直接访问。就像我们在函数中定义了与全局变量同名的局部变量时,会优先使用局部变量,屏蔽全局变量。
尤其要注意成员函数的隐藏,与函数重载不同,只要函数名相同就构成隐藏。其次,被隐藏的成员可以通过将派生类对象赋值给基类指针或引用来访问。在实际写代码时,在继承体系内尽量不要定义同名的成员,容易混淆。
派生类的默认成员函数
派生类的默认成员函数与其它普通的类有所不同,派生类的构造函数必须调用基类的构造函数来初始化基类的那部分成员,如果基类没有默认的构造函数,则必须在派生类构造函数的初始化列表中显式调用。
派生类的赋值重载也必须调显式用基类的赋值重载完成基类的赋值。其次,由于派生类的赋值重载隐藏了基类的赋值重载,所以要显式调用基类的赋值重载式时,需要指定基类作用域。正确的派生类赋值重载写法如下
cpp
Derived& operator=(const Derived& other) {
if (this != &other) { // 1. 自赋值检查
Base::operator=(other); // 2. 显式调用基类赋值,Base就是基类的类名
extra = other.extra; // 3. 拷贝派生类成员
}
return *this; // 4. 返回当前对象引用
}完整代码如下
cpp
// 基类
class Base {
public:
int value;
// 赋值重载
Base& operator=(const Base& other) {
if (this != &other) {
value = other.value;
}
return *this;
}
};
// 派生类
class Derived : public Base {
public:
int extra;
// 派生类赋值重载
Derived& operator=(const Derived& other) {
if (this != &other) {
// 调用基类赋值重载
Base::operator=(other);
extra = other.extra;
}
return *this;
}
};派生类的对象初始化时会先调用基类构造再调用派生类构造,销毁时则是反过来,会先调用派生类的析构函数,然后再调用基类的析构函数,也就是先清理派生类成员再清理基类成员。
多继承
只继承一个基类的继承关系为单继承,继承两个或以上基类的继承关系为多继承。多继承的派生类对象存储时,先继承的基类成员放前面,后继承的基类成员接在其后面,最后放派生类的成员。
如果多继承的派生类继承的两个类是由同一个基类派生出来的,那么就会出现菱形继承,如下图左。在这种继承关系中,最开始的基类Person的成员在多继承的派生类Assistant的对象中就会存在两份,如下图右边就是Assistant对象的内存分布示意图,来自Person类的成员变量_name有两份,如果此时要访问_name,编译器就不知道要访问哪个。因此在实际工程中,如非必要,慎用多继承。
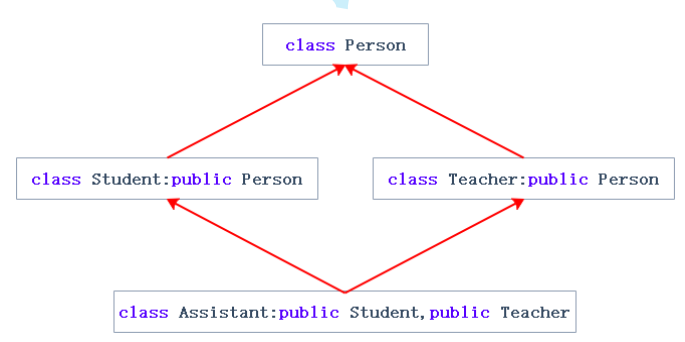
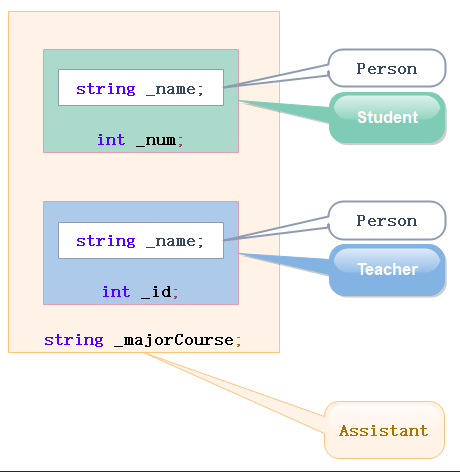
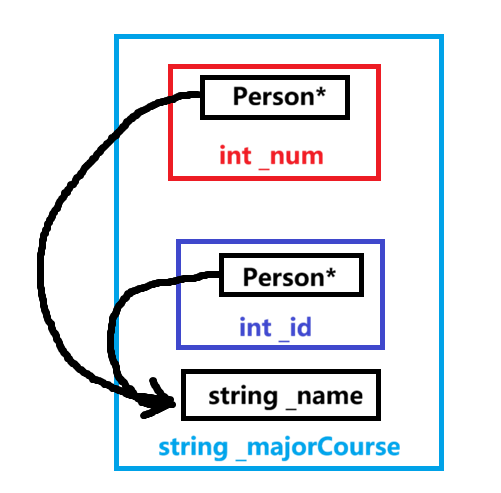
为了解决菱形继承问题,C++提供了虚继承。在普通的菱形继承中,派生类会包含基类的所有成员,这就导致Assistant类的对象中包含了两个Person对象。而使用菱形虚拟继承后,Assistant类的对象中,Student类对象和Teacher类对象中不会直接保存完整的Person对象,而是Person对象的指针,二者的指针会指向同一个Person对象,菱形虚拟继承结构和Assistant类对象存储结构示意图如下。下面的存储结构示意图中,基类Person是放在了最后,但实际中并不一定,看编译器怎么选,可能放最后,可能放前面,也可能放中间。
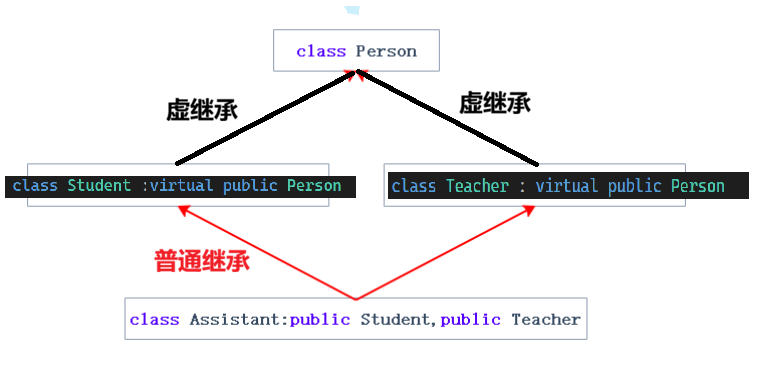
如果要实现菱形虚拟继承,判断什么时候使用虚继承的方法是:**谁要继承最开始的基类,谁就要使用虚继承,其它的使用普通继承。**例如上面的例子中,Student和Teacher就应该使用虚继承去继承基类Person。这是为了让基类指针类型保持一致,否则最终的派生类对象中仍会出现两份基类对象。
而对于没有多继承的其它中间派生类,如上面的Student和Person,它们的对象在初始化时也会包含指向内部基类对象的指针,虽然看起来多次一举,但是并不影响它们的使用。
多态
基本概念
多态简单来说就是多种形态,这个概念主要与函数相关。多态分为编译时多态和运行时多态,也叫静态多态和动态多态。编译时多态主要就是指前面讲的函数重载和函数模板,相同的函数名通过不同的参数来匹配不同的功能。由于这种参数匹配是在编译时完成的,所以被称为编译时多态,即静态多态。隐藏也是一种编译时多态。
运行时多态就是指同一个函数会根据不同的对象进行不同的行为,俗称看人下菜碟。例如同样是买票,虽然都是人,但普通人买票是全价,学生有优惠,军人优先买票。不同的身份有不同的待遇。实现运行时多态就是让一个继承关系下不同类的对象,调用同一函数时,产生不同的行为。比如Student继承了Person,Person对象买票全价,Student对象则有优惠。下面我们讲的多态指的就是运行时多态。
实现多态需要使用虚函数 ,我们看下面这张示意图,在右边的函数中,两个对象Mike和Johnson最终都会被当作Person类调用成员函数BuyTicket(买票),如果BuyTicket是普通的函数,由于两个对象都被当成Person类,调用BuyTicket时永远只会调用基类的那个,所以要实现多态的函数要定义为虚函数。被virtual修饰的类成员函数就是虚函数。非成员函数不能加virtual修饰。
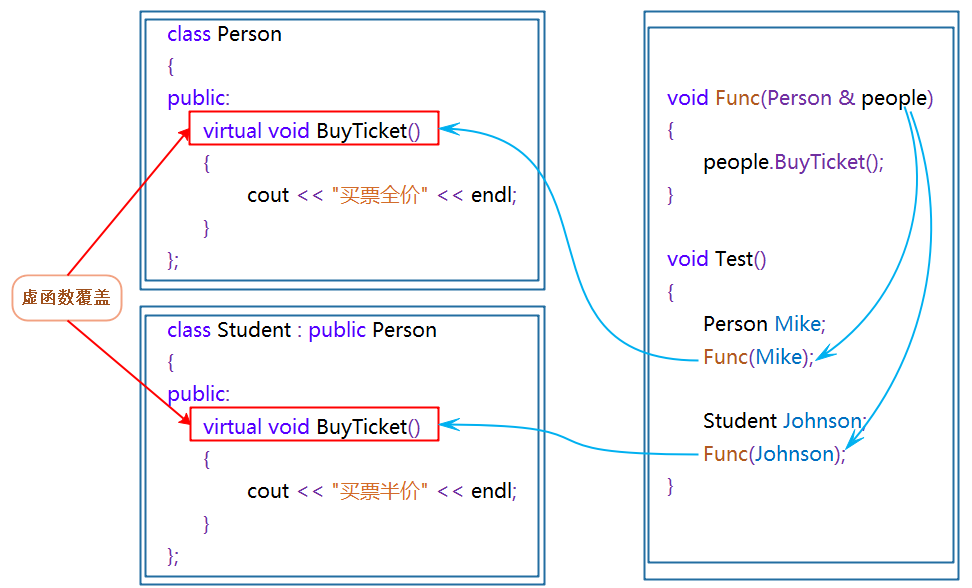
实现多态还需要让虚函数达成重写(覆盖) ,即派生类的虚函数和基类的虚函数的返回类型、参数列表、函数名完全相同。这是为了确保这些虚函数是同一个 函数的不同实现,之前讲的函数重载其实本质上是不同的函数,所以编译器才需要通过参数区分。如果派生类的虚函数返回值与基类的不同,函数名、参数列表相同,则构成协变,虽然也能用上图的方式调用,实现多态的功能,但意义不大。
同名函数的三种关系如下。
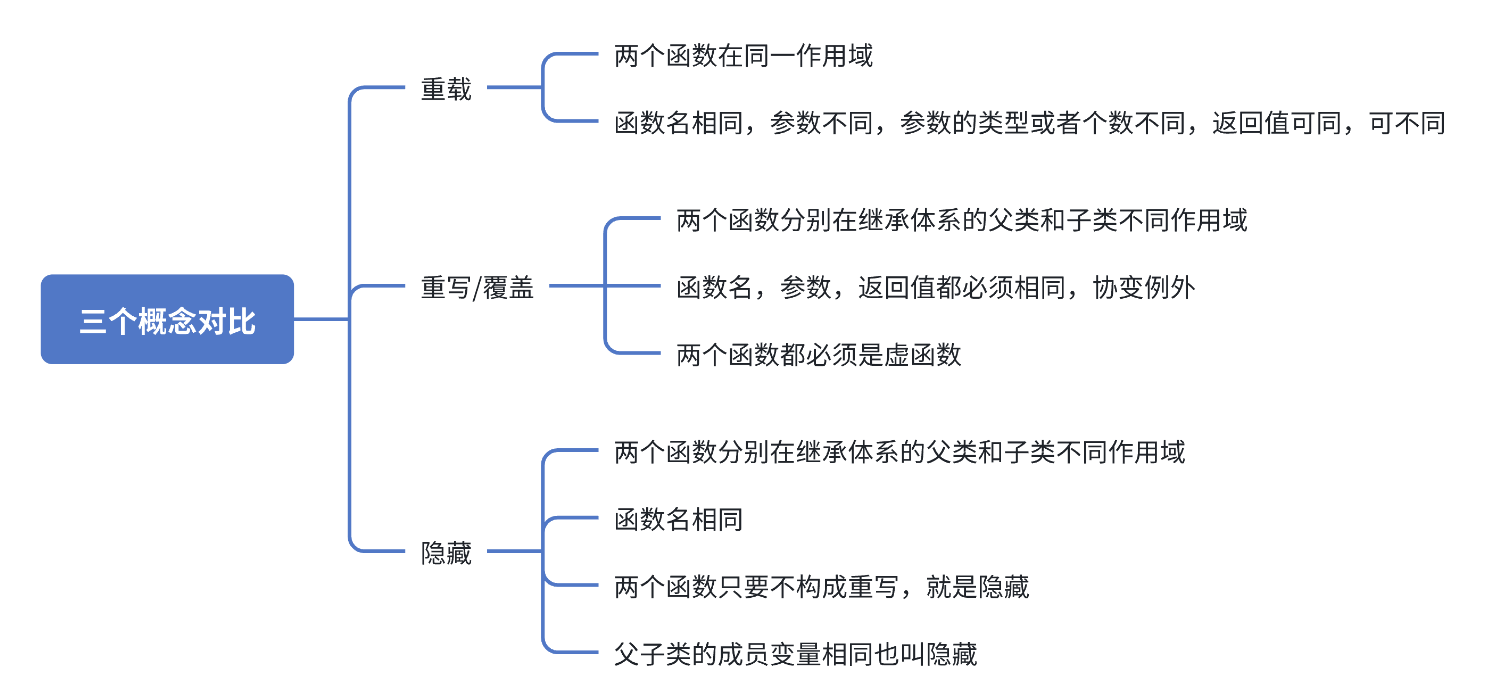
另外,派生类的函数不加virtual关键字时,也可以构成重写,但是这种写法不是很规范。
如果基类的虚构函数为虚函数,那么派生类的析构函数只要有定义就会与基类的析构函数构成重写,尽管二者连函数名都不同。事实上,析构函数的函数名在编译后都会变成destructor,所以二者其实是同名的函数。
最后,实现多态还需要用基类的指针或引用来调用对应的虚函数,因为只有基类的指针或引用才既能指向基类对象又能指向派生类对象。
override和final关键字
override关键字用于检测虚函数是否重写失败,因为重写失败时编译器默认不会报错。为了防止程序因此在运行时没能实现预期的结果,就需要使用override关键字检测。
cpp
virtual void Drive() override
{
cout << "override" << endl;
}final关键字则用于禁用重写
cpp
virtual void Drive() final
{
cout << "final" << endl;
}纯虚函数和抽象类
在虚函数的声明后面加上=0,则该虚函数就会变成纯虚函数 ,包含纯虚函数的类即为抽象类,抽象类不能实例化对象,只能作为基类被继承。如果派生类继承后不重写纯虚函数,那么派生类也会成为抽象类,也无法实例化出对象。
cpp
class Shape { // 抽象类
public:
virtual double area() = 0; // 纯虚函数
};
class Circle : public Shape {
public:
double area() override { // 必须实现
return 3.14 * radius * radius;
}
private:
double radius;
};多态原理
类中所有虚函数的地址都会被放到虚函数表 中,它本质是一个数组,在编译时生成。虚函数表的存储位置C++没有明确规定,一般是在代码段。每个含有虚函数的类都有自己的虚函数表,因此,含有虚函数的类中会存在至少一个虚函数表指针(_vfptr,在类对象中占一个字节),相同类的所有对象通过虚函数表指针访问同一张虚函数表。
派生类的虚函数表是以基类的虚函数表内容为基础创建的(两表相互独立,只是内容有所关联),因此派生类和基类的虚函数表的内容本来应该是相同的,但若是派生类中重写了基类的虚函数,则编译期生成派生类的虚函数表时,虚函数表中原本要填入基类对应的虚函数地址的位置,就会改为用重写的虚函数地址填入。如果派生类有自己的虚函数,也会写在同一张表中,其函数地址会在接在已有的虚函数的后面。
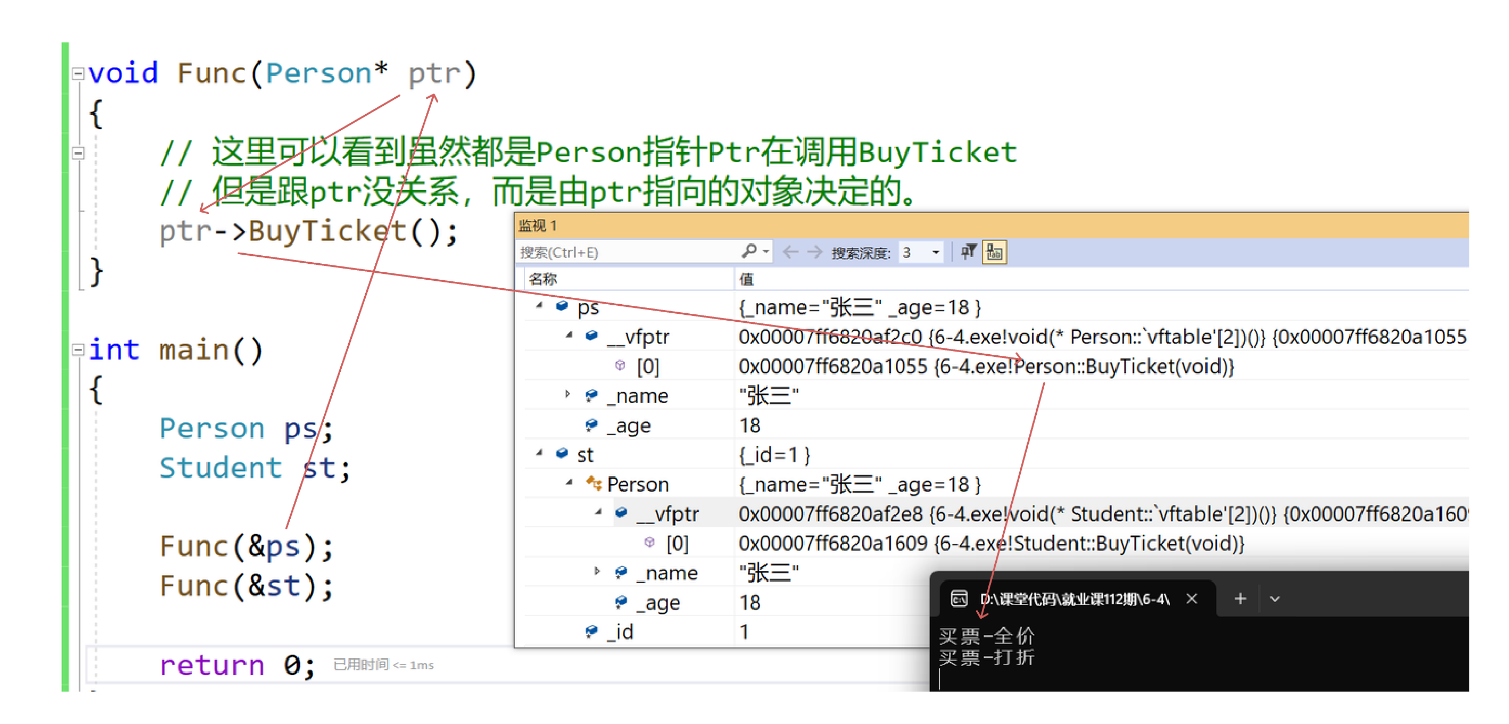
虚函数调用需要通过类对象的虚函数表指针访问虚函数表得到其地址,多态的原理就是相同的虚函数在不同类的虚函数表中函数地址不同,使得不同类的类对象被当作基类调用虚函数时执行的功能不同,如下。
类定义如下
cpp
class Person {
public:
virtual void BuyTicket() { cout << "买票-全价" << endl; }
private:
string _name;
};
class Student : public Person {
public:
virtual void BuyTicket() { cout << "买票-打折" << endl; }
private:
string _id;
};Person类对象调用虚函数的情况如下
Student类对象调用虚函数的情况
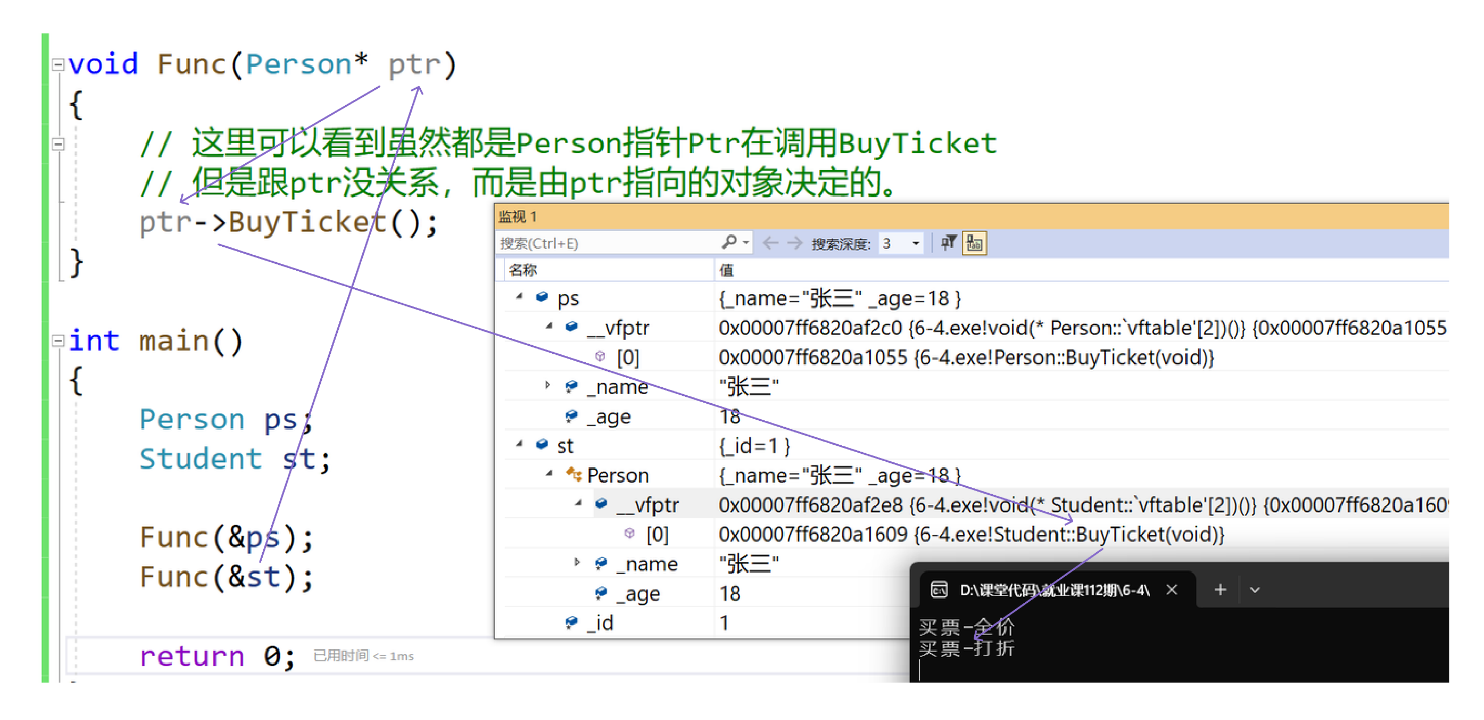
像上面这样满足多态条件的函数调用是运行时绑定(动态绑定) ,即运行时根据对象的虚函数表找到要调用的函数的地址。其它的函数调用则是编译时绑定(静态绑定),在编译时就能确定调用函数的地址。
虚函数表指针也是类的成员,也会被继承。一般情况下,派生类继承的基类中有虚函数表指针时自己就不会再生成一个。但是要注意的这里继承下来的基类部分虚函数表指针和基类对象的虚函数表指针不是同⼀个,就像基类对象的成员和派生类对象中的基类对象成员也独立的。
lambda表达式
lambda表达式就是一种匿名函数对象。和之前讲的匿名对象类似,用于临时构造一个函数对象。lambda表达式的基本结构如下,具体用法稍后再说。它可以被对象接收,由于它本身没有类型,一般是用auto或者模板参数定义的对象去接收。如果没有对象接收lambda表达式,那它和其它临时变量一样,执行到下一行就没了。

lambda表达式从捕获列表开始,用于捕获外部当前可用的局部变量 供lambda使用,静态变量和全局变量不需要捕获也能访问。捕获分为值捕获和引用捕获,直接在捕获列表中写要捕获的变量名就是值捕获。使用值捕获 时,一般只是使用捕获的变量的值,默认是不能修改值捕获的变量的,除非加上mutable。加上mutable后,lambda表达式内就可以修改值捕获的变量的拷贝,不会影响原本的变量,如下
cpp
int x = 5;
auto lambda = [x]() {//直接写变量名就是值捕获
// x = 10; // 错误!默认值捕获是 const 的
};
auto lambda2 = [x]() mutable {
x = 10; // 正确!mutable 允许修改副本
// 注意:这只是修改副本,不影响外部 x
};如果要值捕获外部的所有局部变量,就将捕获列表写成 =,这种方式叫做隐式值捕获 ,上面代码所示的则为显式值捕获。
引用捕获就是在捕获的变量名前面加上&,这种捕获即为显式引用捕获 。如果要引用捕获外部所有的局部变量,将捕获列表写成\&即可,这种方式叫做隐式引用捕获。如果不捕获也不能省略方括号 ,因为编译器是根据它来判断后面的代码是否为lambda的。
cpp
int main() {
int x = 5, y = 3;
auto lambda2 = [&x, &y]() mutable {
x = 10; //会影响外部的x、y
y = 0;
};
return 0;
}隐式捕获和显式捕获可以混合使用,但是必须把要显式捕获变量写后面,并且要注意使用了隐式引用捕获就不能再用显式引用捕获,多次一举还会报错,隐式值捕获同理,如下
cpp
int main() {
int a = 1, b = 2, c = 3, d = 4;
auto f1 = [&, a]() { /* a 显式值捕获,其它隐式引用捕获 */ };
auto f2 = [=, &b]() { /* b 显式引用捕获,其它隐式值捕获 */ };
//auto f3 = [&, &a]() { };//错误:显式捕获与默认设置匹配
//auto f4 = [=, a]() { };//错误:同上
return 0;
}也可以显式地为多个变量指定捕获方式,如下
cpp
int main() {
int a = 1, b = 2, c = 3, d = 4;
auto f = [&a,b,&c,d]() { };
return 0;
}接着是lambda的参数列表,这个没什么好说的,函数的参数列表怎么用这里就怎么用,如果不需要参数可以连圆括号()都省略掉,返回类型也是如此,用法和函数相同,不返回可以把箭头省略掉。花括号内{ }就是函数体,即使函数体为空花括号也不能省略。
本文到此结束,篇幅较长,如有错漏欢迎指出。