前言
本文分析KRaft模式下Controller的运作模式:
- Controller节点启动:有哪些组件,如何基于Raft日志恢复元数据;
- Kafka集群如何建立:初始Leader(Active Controller)如何定义,如何加入其他Standby Controller做failover;
- KRaft状态机:如何选主,如何复制,如何发现新Leader;
注:
- 基于4.1.1版本;
一、部署
1-1、Controller集群
- Controller配置
properties
# 角色
process.roles=controller
# 节点id
node.id=1
# controller发现 引导server列表
controller.quorum.bootstrap.servers=localhost:9093,localhost:9095,localhost:9097
# controller端口
listeners=CONTROLLER://:9093
advertised.listeners=CONTROLLER://localhost:9093
controller.listener.names=CONTROLLER
# 数据目录
log.dirs=/tmp/kafka/controller1- 格式化数据目录
节点1,使用--standalone:
shell
$ bin/kafka-storage.sh format -t 自定义集群id \
--standalone -c config/controller1.properties
Formatting dynamic metadata voter directory /tmp/kafka/controller1 with metadata.version 4.1-IV1.其他节点,使用--no-initial-controllers:
shell
$ bin/kafka-storage.sh format -t 自定义集群id \
-c config/controller2.properties --no-initial-controllers
Formatting metadata directory /tmp/kafka/controller2 with metadata.version 4.1-IV1.- 启动Controller
查看Controller集群状态,节点1是Leader ,其他节点是Observer。
shell
$ bin/kafka-metadata-quorum.sh --bootstrap-controller=localhost:9093 describe --replication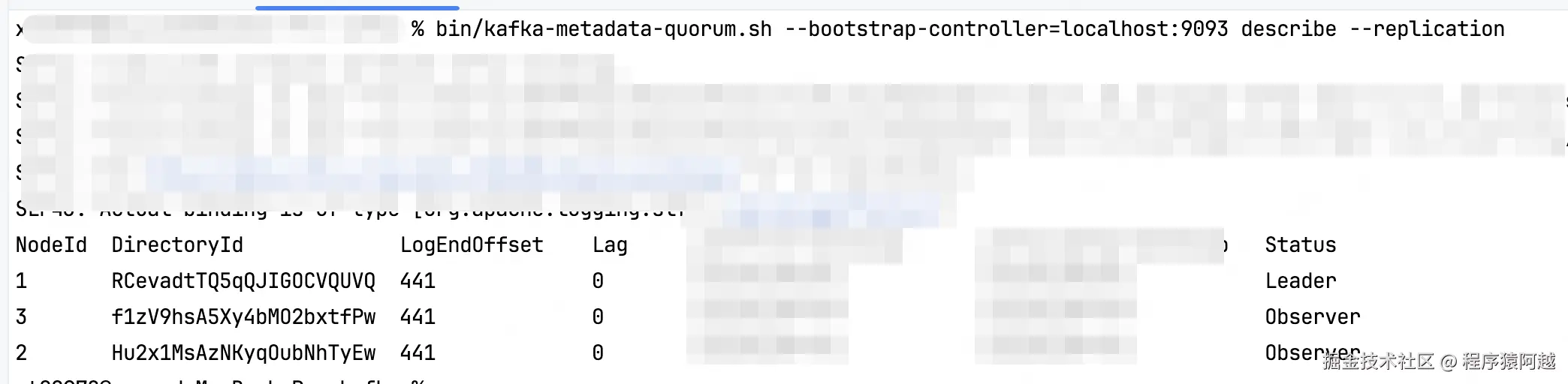
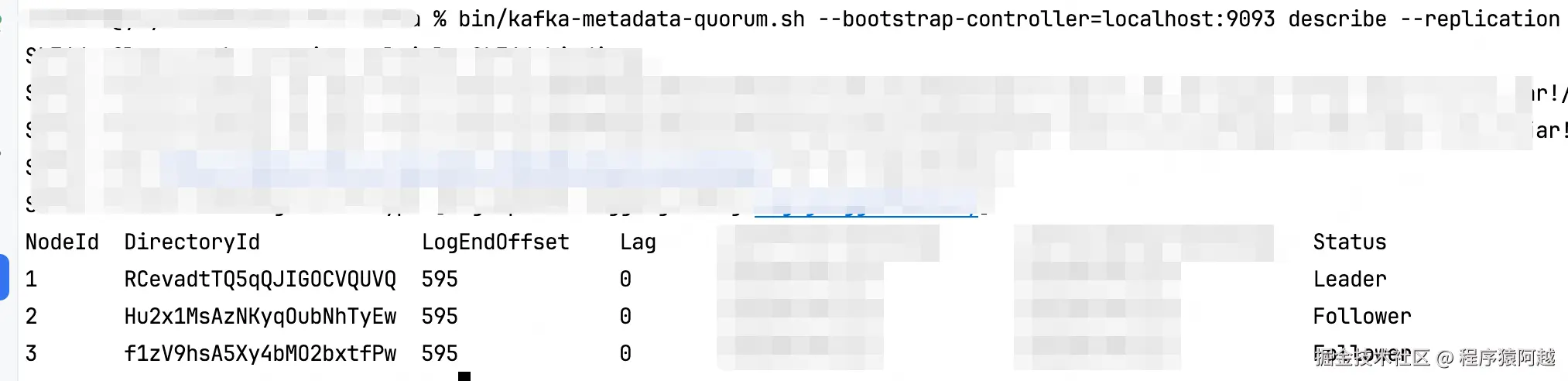
- 除节点1的其他节点加入Controller集群
shell
$ bin/kafka-metadata-quorum.sh --command-config config/controller2.properties \
--bootstrap-controller localhost:9093 add-controller查看Controller集群状态:除节点1的其他节点从Observer 变为Follower。
1-2、Broker集群
- Broker配置
properties
# 角色为broker
process.roles=broker
# 节点id
node.id=4
# controller发现 引导server列表
controller.quorum.bootstrap.servers=localhost:9093,localhost:9095,localhost:9097
# broker端口
listeners=PLAINTEXT://:9092
inter.broker.listener.name=PLAINTEXT
advertised.listeners=PLAINTEXT://localhost:9092
controller.listener.names=CONTROLLER
# 数据目录
log.dirs=/tmp/kafka/server1- 格式化数据目录
shell
bin/kafka-storage.sh format -t 自定义集群id \
-c config/server1.properties --no-initial-controllers- 启动Broker
Broker角色在KRaft中为Observer,会参与日志复制,但不参与投票。
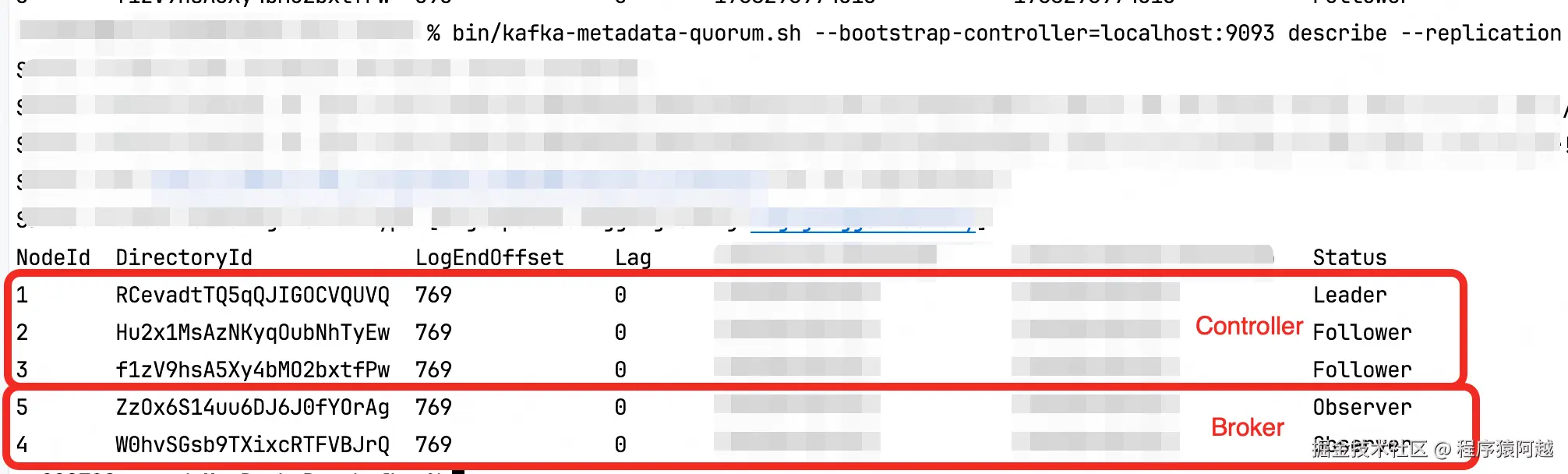
1-3、kafka-storage.sh做了什么
shell
% tree {controller{1,2},server1}
controller1
├── __cluster_metadata-0
│ └── 00000000000000000000-0000000000.checkpoint
├── bootstrap.checkpoint
└── meta.properties
controller2
├── bootstrap.checkpoint
└── meta.properties
server1
├── bootstrap.checkpoint
└── meta.properties对于普通controller和broker节点,创建bootstrap.checkpoint 和meta.properties。
bootstrap.checkpoint:snapshot格式,FEATURE_LEVEL_RECORD,记录当前节点不同特性的版本,如metadata.version=27,定义了元数据日志的格式版本=27。
shell
$ bin/kafka-dump-log.sh --cluster-metadata-decoder --files /tmp/kafka/controller1/bootstrap.checkpoint
Dumping /tmp/kafka/controller1/bootstrap.checkpoint
KRaft bootstrap snapshot
baseOffset: 0 lastOffset: 0 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: true deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1768720177924 size: 83 magic: 2 compresscodec: none crc: 2491040892 isvalid: true
| offset: 0 CreateTime: 1768720177924 keySize: 4 valueSize: 11 sequence: -1 headerKeys: [] SnapshotHeader {"version":0,"lastContainedLogTimestamp":0}
baseOffset: 1 lastOffset: 4 count: 4 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: false deleteHorizonMs: OptionalLong.empty position: 83 CreateTime: 1768720177934 size: 197 magic: 2 compresscodec: none crc: 1732347163 isvalid: true
| offset: 1 CreateTime: 1768720177934 keySize: -1 valueSize: 23 sequence: -1 headerKeys: [] payload: {"type":"FEATURE_LEVEL_RECORD","version":0,"data":{"name":"metadata.version","featureLevel":27}}
| offset: 2 CreateTime: 1768720177934 keySize: -1 valueSize: 39 sequence: -1 headerKeys: [] payload: {"type":"FEATURE_LEVEL_RECORD","version":0,"data":{"name":"eligible.leader.replicas.version","featureLevel":1}}
| offset: 3 CreateTime: 1768720177934 keySize: -1 valueSize: 20 sequence: -1 headerKeys: [] payload: {"type":"FEATURE_LEVEL_RECORD","version":0,"data":{"name":"group.version","featureLevel":1}}
| offset: 4 CreateTime: 1768720177934 keySize: -1 valueSize: 26 sequence: -1 headerKeys: [] payload: {"type":"FEATURE_LEVEL_RECORD","version":0,"data":{"name":"transaction.version","featureLevel":2}}
baseOffset: 5 lastOffset: 5 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: true deleteHorizonMs: OptionalLong.empty position: 280 CreateTime: 1768720177934 size: 75 magic: 2 compresscodec: none crc: 4224914075 isvalid: true
| offset: 5 CreateTime: 1768720177934 keySize: 4 valueSize: 3 sequence: -1 headerKeys: [] SnapshotFooter {"version":0}meta.properties:节点元数据,这在早期版本也存在。
properties
# 集群id
cluster.id=EH-fzsXoRS21dHvso6xQZw
# 目录id(一个broker可以使用多个log.dir)
directory.id=PxqaAhtAR6K8gYpwuKUEmw
# 节点id
node.id=1
# 版本
version=1首个controller节点,使用--standalone,会额外生成元数据checkpoint。
通过kafka-dump-log.sh查看,记录KRaftVoters ,代表投票节点集合,仅包含自己。
shell
% bin/kafka-dump-log.sh --cluster-metadata-decoder \
--files /tmp/kafka/controller1/__cluster_metadata-0/00000000000000000000-0000000000.checkpoint
Dumping /tmp/kafka/controller1/__cluster_metadata-0/00000000000000000000-0000000000.checkpoint
Snapshot end offset: 0, epoch: 0
baseOffset: 0 lastOffset: 2 count: 3 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: true deleteHorizonMs: OptionalLong.empty position: 0 CreateTime: 1768720177940 size: 166 magic: 2 compresscodec: none crc: 1528265210 isvalid: true
| offset: 0 CreateTime: 1768720177940 keySize: 4 valueSize: 11 sequence: -1 headerKeys: [] SnapshotHeader {"version":0,"lastContainedLogTimestamp":1768720177938}
| offset: 1 CreateTime: 1768720177940 keySize: 4 valueSize: 5 sequence: -1 headerKeys: [] KRaftVersion {"version":0,"kRaftVersion":1}
| offset: 2 CreateTime: 1768720177940 keySize: 4 valueSize: 55 sequence: -1 headerKeys: [] KRaftVoters {"version":0,"voters":[{"voterId":1,"voterDirectoryId":"RCevadtTQ5qQJIGOCVQUVQ","endpoints":[{"name":"CONTROLLER","host":"localhost","port":9093}],"kRaftVersionFeature":{"minSupportedVersion":0,"maxSupportedVersion":1}}]}
baseOffset: 3 lastOffset: 3 count: 1 baseSequence: -1 lastSequence: -1 producerId: -1 producerEpoch: -1 partitionLeaderEpoch: 0 isTransactional: false isControl: true deleteHorizonMs: OptionalLong.empty position: 166 CreateTime: 1768720177943 size: 75 magic: 2 compresscodec: none crc: 285640245 isvalid: true
| offset: 3 CreateTime: 1768720177943 keySize: 4 valueSize: 3 sequence: -1 headerKeys: [] SnapshotFooter {"version":0}二、Controller数据流概览
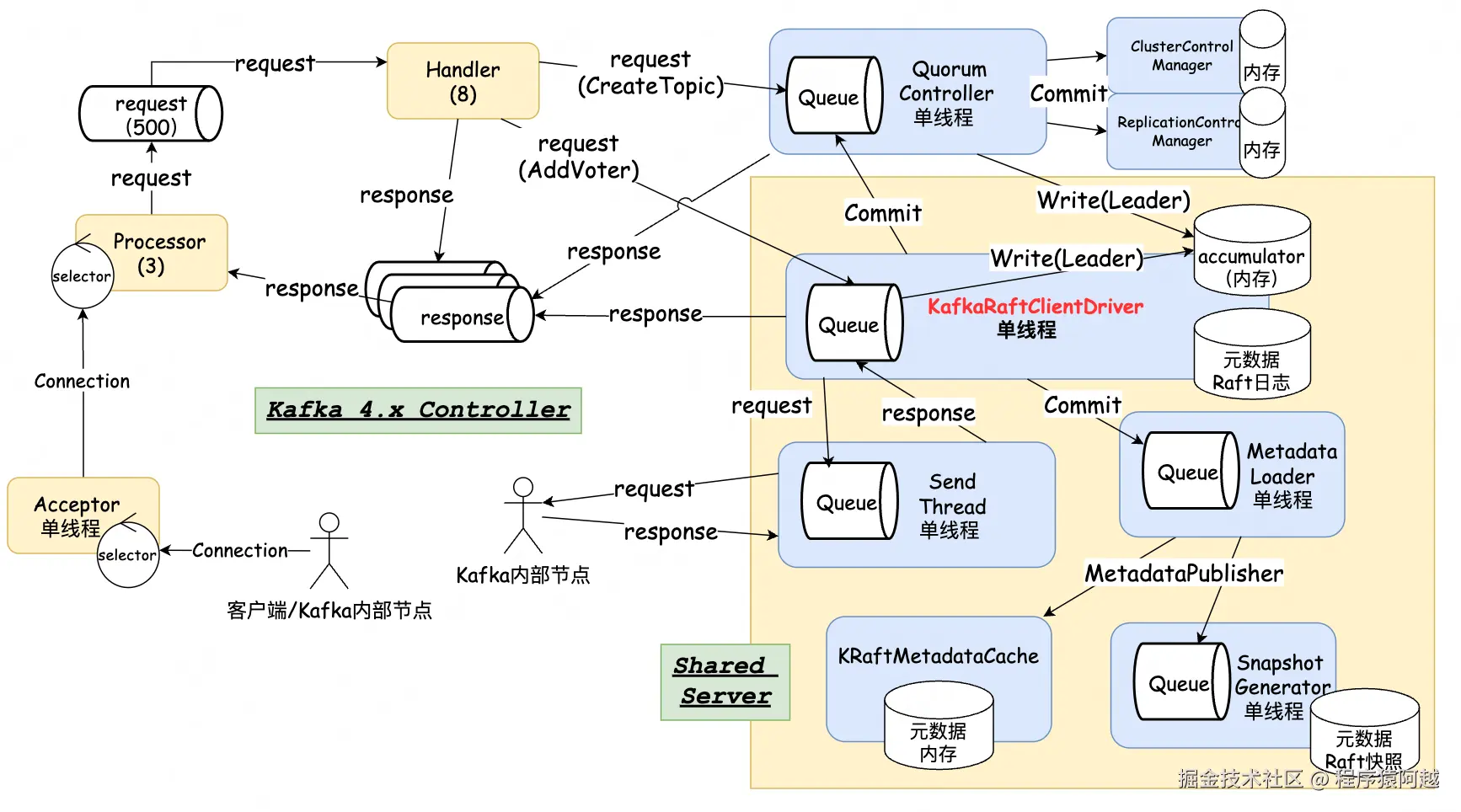
通讯层(和早期版本一样) :
- Acceptor:1个线程,建立Connection,注册到Processor;
- Processor:3个线程,处理IO读写,将业务请求写入一个request队列,一个Connection对应同一个Processor,每个Processor有一个response队列;
- Handler:8个线程,处理请求;
QuorumController:Controller角色,单线程,处理如CreateTopic请求,后续文章再详细看流程;
SharedServer:Controller和Broker角色共享组件,包含所有KRaft组件;
- KafkaRaftClientDriver:单线程,处理Raft请求响应;
- MetadataLoader:单线程,当Raft写请求被提交,读Raft日志或快照,通过Publisher发布;
- KRaftMetadataCache:内存元数据;
- SnapshotGenerator:单线程,条件触发Raft快照;
三、Controller启动
3-1、主流程
KafkaRaftServer.startup:区分角色启动,所有角色都依赖SharedServer。
scala
private val sharedServer = new SharedServer(...)
private val broker: Option[BrokerServer] =
if (config.processRoles.contains(ProcessRole.BrokerRole)) {
Some(new BrokerServer(sharedServer))
} else { None }
private val controller: Option[ControllerServer] =
if (config.processRoles.contains(ProcessRole.ControllerRole)) {
Some(new ControllerServer(sharedServer,
KafkaRaftServer.configSchema, bootstrapMetadata,
))
} else { None }
override def startup(): Unit = {
// process.roles=controller 启动
controller.foreach(_.startup())
// process.roles=broker 启动
broker.foreach(_.startup())
}ControllerServer.startup:
- 启动KRaft组件;
- 启动QuorumController;
- MetadataLoader恢复元数据到内存;
- 开启socketServer,可以接收请求;
- 注册当前Controller到Leader Controller;
这里关注1、3。
scala
val sharedServer: SharedServer
// QuorumController
var controller: Controller = _
var controllerApis: ControllerApis = _
val metadataPublishers: util.List[MetadataPublisher] =
new util.ArrayList[MetadataPublisher]()
var socketServer: SocketServer = _
var registrationManager: ControllerRegistrationManager = _
var registrationChannelManager: NodeToControllerChannelManager = _
def startup(): Unit = {
// 1. 启动Raft组件
sharedServer.startForController(listenerInfo)
// 2. 启动QuorumController
val controllerBuilder = {
// ....
new QuorumController.Builder(config.nodeId, sharedServer.clusterId)
}
ontroller = controllerBuilder.build()
// controller请求处理入口
controllerApis = new ControllerApis(...)
// 3. MetadataLoader 恢复元数据到内存
FutureUtils.waitWithLogging(logger.underlying, logIdent,
"the controller metadata publishers to be installed",
sharedServer.loader.installPublishers(metadataPublishers),
startupDeadline, time)
// 4. 开启socketServer,可以接收请求
val socketServerFuture =
socketServer.enableRequestProcessing(authorizerFutures)
// 5. 注册Controller到Leader
val controllerNodeProvider =
RaftControllerNodeProvider(raftManager, config)
registrationChannelManager = new NodeToControllerChannelManagerImpl(...)
registrationChannelManager.start()
registrationManager.start(registrationChannelManager)
}3-2、KRaft组件介绍
3-2-1、LocalLog
controller的数据目录如下,原来存储在ZooKeeper的元数据,都存放在topic=__cluster_metadata的0号分区中。
segment :log文件变为Raft日志,格式和普通消息一致;
checkpoint :Raft快照。例如7164-1.checkpoint,包含元数据全量快照,快照中最后一条Raft日志的offset=7164,epoch=1;
quorum-state :Raft节点状态,包括Leader的id和epoch;
shell
controller1 % tree .
.
├── __cluster_metadata-0
│ ├── 00000000000000000000-0000000000.checkpoint
│ ├── 00000000000000000000.index
│ ├── 00000000000000000000.log
│ ├── 00000000000000000000.timeindex
│ ├── 00000000000000007164-0000000001.checkpoint
│ ├── leader-epoch-checkpoint
│ ├── partition.metadata
│ └── quorum-state
├── bootstrap.checkpoint
└── meta.propertiesLocalLog:分区数据。
java
public class UnifiedLog {
private final LocalLog localLog;
}
public class LocalLog {
// n个segment
private final LogSegments segments;
// TopicPartition
private final TopicPartition topicPartition;
// LogEndOffset LEO
private volatile LogOffsetMetadata nextOffsetMetadata;
}3-2-2、SharedServer
SharedServer是Broker和Controller角色的公共部分 ,管理KafkaRaftManager的启动和停止。
SharedServer.start:
scala
var raftManager: KafkaRaftManager[ApiMessageAndVersion] = _
var loader: MetadataLoader = _
var snapshotEmitter: SnapshotEmitter = _
var snapshotGenerator: SnapshotGenerator = _
private def start(listenerEndpoints: Endpoints): Unit = synchronized {
// 1. 启动RaftManager
val _raftManager = new KafkaRaftManager[ApiMessageAndVersion](
// ...
)
raftManager = _raftManager
_raftManager.startup()
// 构造MetadataLoader,安装SnapshotGenerator用于后续快照生成
val loaderBuilder = new MetadataLoader.Builder()
// ...
loader = loaderBuilder.build()
snapshotEmitter = new SnapshotEmitter.Builder().
// ...
build()
snapshotGenerator = new SnapshotGenerator.Builder(snapshotEmitter).
// ...
build()
loader.installPublishers(Arrays.asList(snapshotGenerator)).get()
// 2. 注册MetadataLoader为Listener,监听Raft日志Commit
_raftManager.register(loader)
started = true
}3-2-3、KafkaRaftManager
KafkaRaftManager管理Raft组件:
1)KafkaMetadataLog:元数据日志,封装___cluster_metadata的0号分区的LocalLog;
2)netChannel:与集群内部成员通讯的客户端;
3)KafkaRaftClientDriver :单线程,使用KafkaRaftClient处理raft业务;
scala
// KafkaMetadataLog 在 UnifiedLog(LocalLog) 上层,封装关于元数据日志的操作
override val replicatedLog: ReplicatedLog = buildMetadataLog()
// SendThread线程 发送请求/接收响应
private val netChannel = buildNetworkChannel()
// KafkaRaftClientDriver raft业务处理
override val client: KafkaRaftClient[T] = buildRaftClient()
private val clientDriver = new KafkaRaftClientDriver[T](...)
def startup(): Unit = {
// 初始化RaftClient
client.initialize(...)
// 启动 SendThread线程 向 集群成员 发送请求/接收响应
netChannel.start()
// 启动 KafkaRaftClientDriver 单线程处理raft业务
clientDriver.start()
}
private def buildMetadataLog(): KafkaMetadataLog = {
KafkaMetadataLog(
// __cluster_metadata的0号分区
topicPartition,
...)
}
private def buildRaftClient(): KafkaRaftClient[T] = {
new KafkaRaftClient(netChannel,...)
}
private def buildNetworkChannel(): KafkaNetworkChannel = {
val (listenerName, netClient) = buildNetworkClient()
new KafkaNetworkChannel(listenerName, netClient, ...)
}3-2-4、KafkaRaftClient
KafkaRaftClient是KRaft中最重要的组件,维持KRaftControlRecordStateMachine 和QuorumState两个状态。
java
public final class KafkaRaftClient<T> implements RaftClient<T> {
// 当前节点id
private final OptionalInt nodeId;
private final String clusterId;
// 如果是controller角色,controller端点
private final Endpoints localListeners;
// 与集群成员通讯的客户端
private final NetworkChannel channel;
// 元数据日志
private final ReplicatedLog log;
// append future
private final FuturePurgatory<Long> appendPurgatory;
// fetch future
private final FuturePurgatory<Long> fetchPurgatory;
// LinkedBlockingQueue阻塞队列
private final RaftMessageQueue messageQueue;
// raft监听,比如raft commit,回调相关listener(MetadataLoader等)
private final Map<Listener<T>, ListenerContext> listenerContexts =
new IdentityHashMap<>();
// 根据raft日志和snapshot,管理投票者集合VoterSetHistory
private volatile KRaftControlRecordStateMachine partitionState;
// raft节点状态,如Leader、Follower、Candidate等
private volatile QuorumState quorum;
// voter相关请求处理
private volatile AddVoterHandler addVoterHandler;
private volatile RemoveVoterHandler removeVoterHandler;
private volatile UpdateVoterHandler updateVoterHandler;
}KRaftControlRecordStateMachine :管理Voter投票者集合 ,即Controller节点集合。
Kafka的Controller可以动态新增和移除,如AddVoter写入元数据Raft日志成功,则加入投票者集合。
java
public final class KRaftControlRecordStateMachine {
// 元数据Raft日志
private final ReplicatedLog log;
// 投票者集合
private final VoterSetHistory voterSetHistory;
// KRaft版本
private final LogHistory<KRaftVersion> kraftVersionHistory = new TreeMapLogHistory<>();
// 元数据日志的LEO
private volatile long nextOffset = STARTING_NEXT_OFFSET;
}
public final class VoterSetHistory {
// 元数据raft日志offset -> 当时的voter集合
private final LogHistory<VoterSet> votersHistory =
new TreeMapLogHistory<>();
}
public final class TreeMapLogHistory<T> implements LogHistory<T> {
private final NavigableMap<Long, T> history = new TreeMap<>();
}
public final class VoterSet {
// controller的node.id -> controller信息
private final Map<Integer, VoterNode> voters;
}
public static final class VoterNode {
// controller的node.id
private final ReplicaKey voterKey;
// controller的通讯地址
private final Endpoints listeners;
private final SupportedVersionRange supportedKRaftVersion;
}
public final class ReplicaKey implements Comparable<ReplicaKey> {
private final int id;
private final Optional<Uuid> directoryId;
}QuorumState :管理Raft节点状态转移,当前Raft节点状态为EpochState。
java
public class QuorumState {
// 当前节点id
private final OptionalInt localId;
// 存储QuorumState,在quorum-state文件
private final QuorumStateStore store;
// Controller节点集合
private final KRaftControlRecordStateMachine partitionState;
// Controller端点
private final Endpoints localListeners;
// 当前节点状态
private volatile EpochState state;
}EpochState包含以下实现:

这两个状态均通过Raft日志维护。
KRaft最大的特点是:传统Raft采用Leader主动发送AppendEntries RPC(推) ,KRaft采用Follower发送消息拉取请求FetchRequest(拉) 。
KafkaRaftClientDriver:单线程执行Raft请求响应。
java
public class KafkaRaftClientDriver<T> extends ShutdownableThread {
private final KafkaRaftClient<T> client;
@Override
public void doWork() {
client.poll();
}
}
// KafkaRaftClient#poll
// LinkedBlockingQueue阻塞队列
private final RaftMessageQueue messageQueue;
public void poll() {
// 1. 根据raft节点状态做不同处理,如leader写log,follower发送fetch请求
long pollStateTimeoutMs = pollCurrentState(startPollTimeMs);
// 2. 处理收到的请求和响应
RaftMessage message = messageQueue.poll(pollTimeoutMs);
if (message != null) {
handleInboundMessage(message, endWaitTimeMs);
}
}3-3、Raft状态恢复
KafkaRaftClient.initialize:
- 恢复KRaftControlRecordStateMachine,即投票者集合,即controller节点集合;
- 恢复QuorumState,当前raft节点状态和选举情况;
- 如果自己是唯一的投票者 ,节点状态=Unattached(初始状态)/Follower/Resigned,自己立即成为Leader;
这正是kafka-storage.sh对于首个controller节点加standalone参数的原因。
java
// 元数据日志
private final ReplicatedLog log;
// 根据raft日志和snapshot,管理投票者集合VoterSetHistory
private volatile KRaftControlRecordStateMachine partitionState;
// raft节点状态,如Leader、Follower、Observer等
private volatile QuorumState quorum;
public void initialize(
Map<Integer, InetSocketAddress> voterAddresses,
QuorumStateStore quorumStateStore,
Metrics metrics,
ExternalKRaftMetrics externalKRaftMetrics) {
// controller.quorum.voters静态controller节点列表,忽略
VoterSet staticVoters = voterAddresses.isEmpty() ?
VoterSet.empty() :
VoterSet.fromInetSocketAddresses(channel.listenerName(), voterAddresses);
// 1. partitionState = controller节点集合(voter)
partitionState = new KRaftControlRecordStateMachine(staticVoters);
partitionState.updateState();
// 2. QuorumState 当前raft节点状态和选举状态
quorum = new QuorumState(nodeId,
nodeDirectoryId, partitionState, quorumStateStore
// ...
);
// 传入raft元数据日志最后一个offset和epoch
quorum.initialize(new OffsetAndEpoch(log.endOffset().offset(), log.lastFetchedEpoch()));
long currentTimeMs = time.milliseconds();
// 3. 根据当前状态,做变更
if (quorum.isLeader()) {
throw new IllegalStateException("Voter cannot initialize as a Leader");
} else if (quorum.isOnlyVoter()
&& (quorum.isUnattached() || quorum.isFollower() || quorum.isResigned())) {
// 如果集群只有自己一个投票者
// UnattachedState||FollowerState||ResignedState 立即成为leader
transitionToProspective(currentTimeMs);
} else if (quorum.isCandidate()) {
// CandidateState 如果自己参与竞选(投票给自己了),
// 看是否有获取过半投票,如果有则成为leader
onBecomeCandidate(currentTimeMs);
} else if (quorum.isFollower()) {
// FollowerState 异常完成所有fetch和append请求 忽略
onBecomeFollower(currentTimeMs);
}
}3-3-1、投票者集合(Controller角色节点)
KRaftControlRecordStateMachine.updateState:先读raft元数据快照,再读raft元数据日志。
java
public void updateState() {
maybeLoadSnapshot();
maybeLoadLog();
}KRaftControlRecordStateMachine.maybeLoadSnapshot/maybeLoadLog:
把KRAFT_VOTERS记录恢复到内存voterSetHistory,key=KRAFT_VOTERS类型数据的offset,value=voter集合,最大offset对应的voter集合,即为当前controller集群。
java
private void maybeLoadSnapshot() {
if ((nextOffset == STARTING_NEXT_OFFSET || nextOffset < log.startOffset()) && log.latestSnapshot().isPresent()) {
RawSnapshotReader rawSnapshot = log.latestSnapshot().get();
// Raft快照是全量数据,清空内存重放
synchronized (kraftVersionHistory) {
kraftVersionHistory.clear();
}
synchronized (voterSetHistory) {
voterSetHistory.clear();
}
try (SnapshotReader<?> reader = RecordsSnapshotReader.of(...)) {
// 快照最后一条数据的offset
OptionalLong currentOffset = OptionalLong.of(reader.lastContainedLogOffset());
// 迭代快照中 的 消息批次
while (reader.hasNext()) {
Batch<?> batch = reader.next();
handleBatch(batch, currentOffset);
}
// LEO = 快照最后一条数据的offset + 1
nextOffset = reader.lastContainedLogOffset() + 1;
}
} else if (nextOffset == STARTING_NEXT_OFFSET) {
nextOffset = SMALLEST_LOG_OFFSET;
}
}
// 读日志
private void maybeLoadLog() {
while (log.endOffset().offset() > nextOffset) {
LogFetchInfo info = log.read(nextOffset, Isolation.UNCOMMITTED);
try (RecordsIterator<?> iterator = new RecordsIterator<>()) {
while (iterator.hasNext()) {
Batch<?> batch = iterator.next();
// 处理消息批次
handleBatch(batch, OptionalLong.empty());
nextOffset = batch.lastOffset() + 1;
}
}
}
}
// 理解为treemap,key=voter日志的offset,value=voter集合
private final VoterSetHistory voterSetHistory;
private void handleBatch(Batch<?> batch, OptionalLong overrideOffset) {
int offsetDelta = 0;
for (ControlRecord record : batch.controlRecords()) {
long currentOffset = overrideOffset.orElse(batch.baseOffset() + offsetDelta);
switch (record.type()) {
case KRAFT_VOTERS:
VoterSet voters = VoterSet.fromVotersRecord((VotersRecord) record.message());
synchronized (voterSetHistory) {
voterSetHistory.addAt(currentOffset, voters);
}
break;
case KRAFT_VERSION:
// ...
break;
default:
// 忽略其他raft日志
break;
}
++offsetDelta;
}
}3-3-2、Raft节点状态
QuorumState.initialize:初始化Raft节点状态
- 从quorum-state 文件恢复ElectionState,首次启动文件不存在,初始leader任期=0,leader=空,voters=KRaftControlRecordStateMachine的投票者集合;
- 如果自己是Leader,进入ResignedState ,需要发送EndQuorumEpoch,重新开启一轮选举;
- 如果自己不是Leader但是投票给自己了,进入CandidateState;
- 如果别人是Leader,进入FollowerState;
- 如果不满足上述条件,集群处于未知状态,进入UnattachedState初始状态,新节点从这个状态开始;
- 持久化新的ElectionState到quorum-state;
每次raft节点状态变更,都会更新quorum-state文件,保存了leader任期等状态。Raft状态流转见下文。
java
public void initialize(OffsetAndEpoch logEndOffsetAndEpoch) throws IllegalStateException {
// 读取quorum-state文件,恢复ElectionState
ElectionState election = readElectionState();
final EpochState initialState;
if (election.epoch() < logEndOffsetAndEpoch.epoch()) {
// leader任期 小于 写入raft日志数据的最大leader任期
initialState = new UnattachedState(...);
} else if (localId.isPresent() && election.isLeader(localId.getAsInt())) {
// 之前自己是leader => ResignedState
initialState = new ResignedState(...);
} else if (
localId.isPresent() &&
election.isVotedCandidate(ReplicaKey.of(localId.getAsInt(), localDirectoryId))
) {
// 之前投票给自己了 => CandidateState
initialState = new CandidateState(...);
} else if (election.hasLeader()) {
// 别人是leader => FollowerState
VoterSet voters = partitionState.lastVoterSet();
Endpoints leaderEndpoints = voters.listeners(election.leaderId());
initialState = new FollowerState(...);
} else {
// 其他 => UnattachedState
initialState = new UnattachedState(...);
}
// 持久化初始状态 到quorum-state文件
durableTransitionTo(initialState);
}
private ElectionState readElectionState() {
ElectionState election;
election = store
.readElectionState()
.orElseGet(
// quorum-state文件不存在,初始状态
() -> ElectionState.withUnknownLeader(0, partitionState.lastVoterSet().voterIds())
);
return election;
}
public final class ElectionState {
// 任期
private final int epoch;
// leader
private final OptionalInt leaderId;
// 选票=投票给谁
private final Optional<ReplicaKey> votedKey;
// 投票者集合(controller节点集合)
private final Set<Integer> voters;
}
private void durableTransitionTo(EpochState newState) {
// newState.election=ElectionState
store.writeElectionState(newState.election(), partitionState.lastKraftVersion());
memoryTransitionTo(newState);
}3-4、恢复元数据
节点启动恢复元数据和正常KRaft写类似。
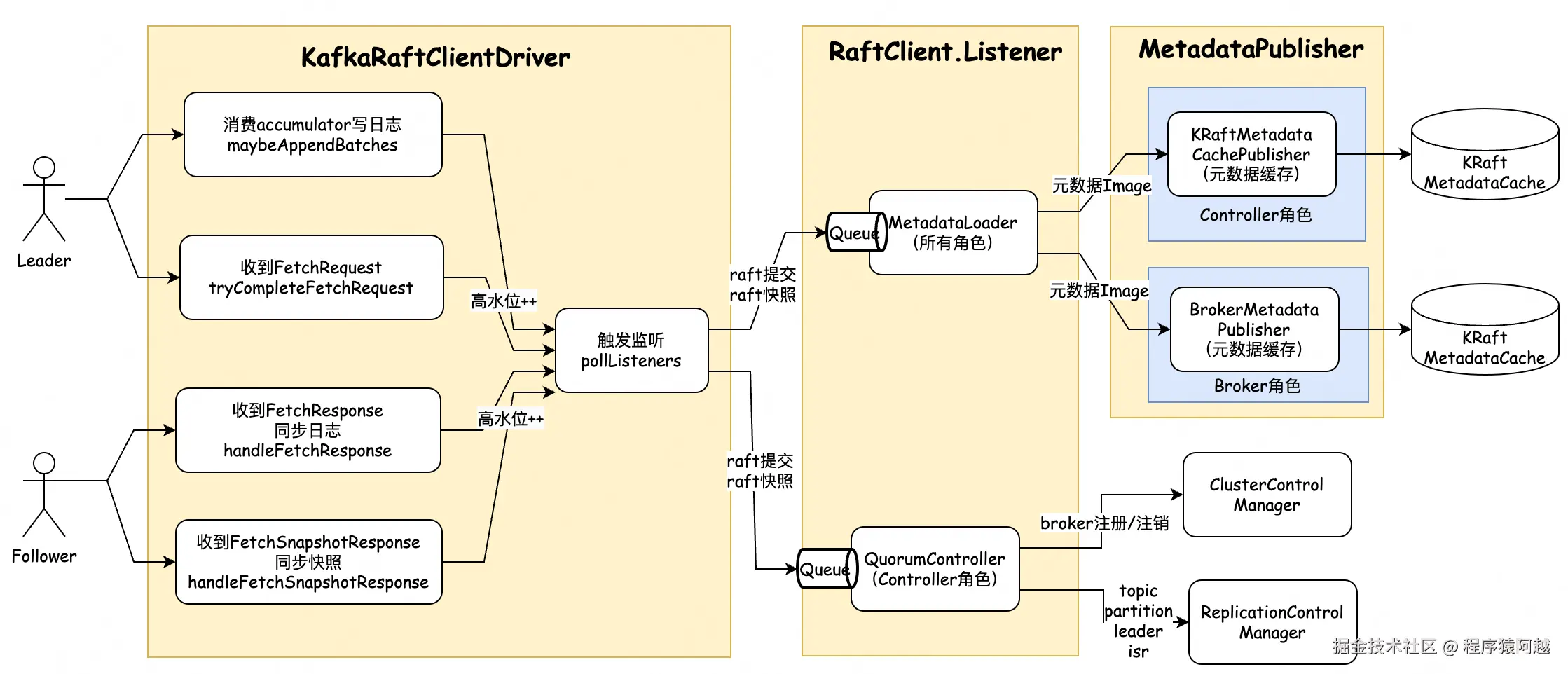
3-4-1、KafkaRaftClient触发RaftClient.Listener
ControllerServer.startup:controller启动,QuorumMetaLogListener 和MetadataLoader首次作为Listener加入,将Raft日志恢复到内存,触发内存元数据初始化。
scala
def startup(): Unit = {
// 1. 启动Raft组件,MetadataLoader会注册为Listener
sharedServer.startForController(listenerInfo)
// 2. 启动QuorumController,QuorumMetaLogListener注册为Listener
val controllerBuilder = {
new QuorumController.Builder(config.nodeId, sharedServer.clusterId)
//...
}
controller = controllerBuilder.build()
metadataPublishers.add(metadataCachePublisher)
// ...
metadataPublishers.add(new AclPublisher(...))
// 3. 等待 MetadataLoader 恢复元数据到内存
FutureUtils.waitWithLogging(logger.underlying, logIdent,
"the controller metadata publishers to be installed",
sharedServer.loader.installPublishers(metadataPublishers), startupDeadline, time)
}
public final class QuorumController implements Controller {
private final QuorumMetaLogListener metaLogListener;
private final RaftClient<ApiMessageAndVersion> raftClient;
private QuorumController() {
this.raftClient.register(metaLogListener);
}
// 内部类,实现Listener实际调用QuorumController
class QuorumMetaLogListener implements
RaftClient.Listener<ApiMessageAndVersion> {
}
}KafkaRaftClient.poll:Raft线程主循环,发现高水位(topic=cluster_metadata&partition=0)升高,触发Listener回调。
高水位变化:Follower通过Fetch请求从Leader同步HW;Leader通过过半Voter复制提升HW。新Leader选举通过会立即写入一条控制消息(KafkaRaftClient.onBecomeLeader,比如standalone情况Controller立即成为Leader,触发HW升高),过半复制后HW升高。
java
public void poll() {
if (!isInitialized()) {
throw new IllegalStateException();
}
// 1. 根据角色做不同处理,如leader写log,follower发送fetch请求
long pollStateTimeoutMs = pollCurrentState(startPollTimeMs);
// 2. 处理收到的请求和响应
RaftMessage message = messageQueue.poll(pollTimeoutMs);
if (message != null) {
handleInboundMessage(message, endWaitTimeMs);
}
// 3. 如果元数据raft日志的hw升高,触发Listener
pollListeners();
}
// raft节点状态,如Leader、Follower、Observer等
private volatile QuorumState quorum;
// 待注册的listener
private final ConcurrentLinkedQueue<Registration<T>> pendingRegistrations;
private void pollListeners() {
// 处理待注册的listener
while (true) {
Registration<T> registration = pendingRegistrations.poll();
if (registration == null) {
break;
}
processRegistration(registration);
}
// 如果listener目前看到的hw低于当前的hw,触发listener
quorum.highWatermark().ifPresent(highWatermarkMetadata ->
updateListenersProgress(highWatermarkMetadata.offset())
);
// ...
}
// 处理待注册的listener
private void processRegistration(Registration<T> registration) {
Listener<T> listener = registration.listener();
Registration.Ops ops = registration.ops();
if (ops == Registration.Ops.REGISTER) {
listenerContexts.putIfAbsent(listener, new ListenerContext(listener)))
}
}
// 注册监听,实际处理在Raft线程中
public void register(Listener<T> listener) {
pendingRegistrations.add(Registration.register(listener));
wakeup();
}KafkaRaftClient.updateListenersProgress:当高水位变化,比对Listener看到的nextOffset,触发handleLoadSnapshot或handleCommit,传入Reader用于读取raft日志或快照。
java
private void updateListenersProgress(long highWatermark) {
for (ListenerContext listenerContext : listenerContexts.values()) {
// 如果listener的offset小于hw,且还没有读过快照,先加载快照
listenerContext.nextExpectedOffset().ifPresent(nextExpectedOffset -> {
if (nextExpectedOffset < highWatermark &&
// 初始状态-1
(nextExpectedOffset == -1 ||
nextExpectedOffset < log.startOffset()) &&
latestSnapshot().isPresent()
) {
listenerContext.fireHandleSnapshot(latestSnapshot().get());
}
});
// 如果listener的offset小于hw,读raft日志
listenerContext.nextExpectedOffset().ifPresent(nextExpectedOffset -> {
if (nextExpectedOffset < highWatermark) {
LogFetchInfo readInfo = log.read(nextExpectedOffset, Isolation.COMMITTED);
listenerContext.fireHandleCommit(nextExpectedOffset, readInfo.records);
}
});
}
}
private final class ListenerContext implements CloseListener<BatchReader<T>> {
// listener实现,如MetadataLoader/QuorumMetaLogListener
private final RaftClient.Listener<T> listener;
// 当前listener看到的leader和任期
private LeaderAndEpoch lastFiredLeaderChange = LeaderAndEpoch.UNKNOWN;
// 当前listener看到的offset
private long nextOffset = -1;
// 上次的handleCommit传入的reader
private BatchReader<T> lastSent = null;
}
public interface RaftClient<T> extends AutoCloseable {
interface Listener<T> {
void handleCommit(BatchReader<T> reader);
void handleLoadSnapshot(SnapshotReader<T> reader);
default void handleLeaderChange(LeaderAndEpoch leader) {}
default void beginShutdown() {}
}
}3-4-2、Listener1-MetadataLoader
MetadataLoader是SharedServer的一部分,Controller和Broker角色都通过该组件将Raft日志加载到内存元数据。
MetadataLoader.handleLoadSnapshot:raft快照会先加载,入队eventQueue。
KafkaEventQueue是一个带队列的消费线程,append追加一个任务,计算全量元数据image 和增量元数据delta,由MetadataPublisher发布。
java
private final KafkaEventQueue eventQueue;
private final MetadataBatchLoader batchLoader;
public void handleLoadSnapshot(SnapshotReader<ApiMessageAndVersion> reader) {
eventQueue.append(() -> {
// 增量变化delta = 老全量image
MetadataDelta delta = new MetadataDelta.Builder().
setImage(image).
build();
// 增量变化delta = 老全量image + reader读snapshot
SnapshotManifest manifest = loadSnapshot(delta, reader);
// 新全量image = 增量变化delta + 老全量image
MetadataImage image = delta.apply(manifest.provenance());
batchLoader.resetToImage(image);
// 发布 增量变化delta 新全量image
maybePublishMetadata(delta, image, manifest);
});
}
private void maybePublishMetadata(MetadataDelta delta, MetadataImage image, LoaderManifest manifest) {
this.image = image;
for (MetadataPublisher publisher : publishers.values()) {
publisher.onMetadataUpdate(delta, image, manifest);
}
}MetadataImage:全量元数据,不可变对象。原来存储在ZooKeeper的所有ZNode,在KRaft里的内存形式。
java
public final class MetadataImage {
private final MetadataProvenance provenance;
private final FeaturesImage features;
// 集群元数据 - broker集群 / controller节点
private final ClusterImage cluster;
// topic元数据 topic 分区assignment/isr/ leader
private final TopicsImage topics;
private final ConfigurationsImage configs;
// Producer ID生成
private final ProducerIdsImage producerIds;
}
public final class ClusterImage {
// broker节点
private final Map<Integer, BrokerRegistration> brokers;
// controller节点
private final Map<Integer, ControllerRegistration> controllers;
}
public class BrokerRegistration {
private final int id;
private final long epoch;
private final Map<String, Endpoint> listeners;
// ...
}
public class ControllerRegistration {
private final int id;
private final Map<String, Endpoint> listeners;
}
public final class TopicsImage {
private final ImmutableMap<Uuid, TopicImage> topicsById;
private final ImmutableMap<String, TopicImage> topicsByName;
}
public final class TopicImage {
private final String name;
private final Uuid id;
private final Map<Integer, PartitionRegistration> partitions;
}
public class PartitionRegistration {
public final int[] replicas;
public final Uuid[] directories;
public final int[] isr;
public final int[] removingReplicas;
public final int[] addingReplicas;
public final int[] elr;
public final int[] lastKnownElr;
public final int leader;
public final LeaderRecoveryState leaderRecoveryState;
public final int leaderEpoch;
public final int partitionEpoch;
}MetadataDelta:本次发布的增量元数据变更,需要通过 当前元数据 + Raft快照或提交日志,计算得到。
java
public final class MetadataDelta {
// 老全量元数据
private final MetadataImage image;
// 集群元数据变更 - broker集群 / controller节点
private ClusterDelta clusterDelta = null;
// topic元数据变更 topic 分区assignment/isr/ leader
private TopicsDelta topicsDelta = null;
// ... 其他
}
public final class ClusterDelta {
// 老cluster元数据
private final ClusterImage image;
// 变更的broker
private final HashMap<Integer, Optional<BrokerRegistration>> changedBrokers = new HashMap<>();
// 变更的controller
private final HashMap<Integer, Optional<ControllerRegistration>> changedControllers = new HashMap<>();
}MetadataLoader.handleCommit:raft快照加载完成后,加载普通raft日志,处理方式类似,通过全量+增量方式发布。
java
public void handleCommit(BatchReader<ApiMessageAndVersion> reader) {
eventQueue.append(() -> {
while (reader.hasNext()) {
Batch<ApiMessageAndVersion> batch = reader.next();
// 增量变化delta = 老全量image + reader读日志
long elapsedNs = batchLoader.loadBatch(batch, currentLeaderAndEpoch);
}
// 新全量image = 增量变化delta + 老全量image
// 发布 增量变化delta 新全量image
batchLoader.maybeFlushBatches(currentLeaderAndEpoch, true);
});
}MetadataPublisher有很多实现,如KRaftMetadataCachePublisher更新内存metadataCache,至此内存中包含全量元数据。
scala
class KRaftMetadataCachePublisher(
val metadataCache: KRaftMetadataCache
) extends MetadataPublisher {
override def onMetadataUpdate(
delta: MetadataDelta,
newImage: MetadataImage,
manifest: LoaderManifest
): Unit = {
metadataCache.setImage(newImage)
}
}
class KRaftMetadataCache(
val brokerId: Int,
val kraftVersionSupplier: Supplier[KRaftVersion]
) extends MetadataCache with Logging {
private var _currentImage: MetadataImage = MetadataImage.EMPTY
def setImage(newImage: MetadataImage): Unit = {
_currentImage = newImage
}
}3-4-3、Listener2-QuorumController
QuorumMetaLogListener,Controller角色使用,是QuorumController的内部类,用于实现RaftClient.Listener,监听raft日志提交和快照生成。
QuorumController.QuorumMetaLogListener.handleCommit:如日志提交,appendRaftEvent会把任务加入自己的KafkaEventQueue,单线程将Raft日志应用到内存。
后续逻辑待后续文章分析,如KRaft创建Topic。
java
class QuorumMetaLogListener implements
RaftClient.Listener<ApiMessageAndVersion> {
@Override
public void handleCommit(BatchReader<ApiMessageAndVersion> reader) {
appendRaftEvent("handleCommit[baseOffset=" + reader.baseOffset() + "]",
() -> {
try {
boolean isActive = isActiveController();
// 读元数据日志
while (reader.hasNext()) {
Batch<ApiMessageAndVersion> batch = reader.next();
long offset = batch.lastOffset();
int epoch = batch.epoch();
List<ApiMessageAndVersion> messages = batch.records();
if (isActive) {
// 如果自己是leader,会在raft写之前应用到内存(比较特殊),不用replay
offsetControl.handleCommitBatch(batch);
} else {
// 自己是follower,replay,将raft日志应用到内存
int recordIndex = 0;
for (ApiMessageAndVersion message : messages) {
long recordOffset = batch.baseOffset() + recordIndex;
replay(message.message(), Optional.empty(), recordOffset);
recordIndex++;
}
offsetControl.handleCommitBatch(batch);
}
}
} finally {
reader.close();
}
});
}
private final ClusterControlManager clusterControl;
private final ReplicationControlManager replicationControl;
private void replay(ApiMessage message, Optional<OffsetAndEpoch> snapshotId, long offset) {
MetadataRecordType type = MetadataRecordType.fromId(message.apiKey());
switch (type) {
// 注册broker
case REGISTER_BROKER_RECORD:
clusterControl.replay((RegisterBrokerRecord) message, offset);
break;
// 注销broker
case UNREGISTER_BROKER_RECORD:
clusterControl.replay((UnregisterBrokerRecord) message);
break;
// 创建topic
case TOPIC_RECORD:
replicationControl.replay((TopicRecord) message);
break;
// topic分区变更
case PARTITION_RECORD:
replicationControl.replay((PartitionRecord) message);
break;
// ...
}
}四、集群初始化
4-1、Leader发现
节点A,通过kafka-storage.sh standalone格式化,启动后作为唯一Voter,立即成为Leader(见3-3)。现在看其他节点B,如何发现Leader,从而开始复制元数据日志。
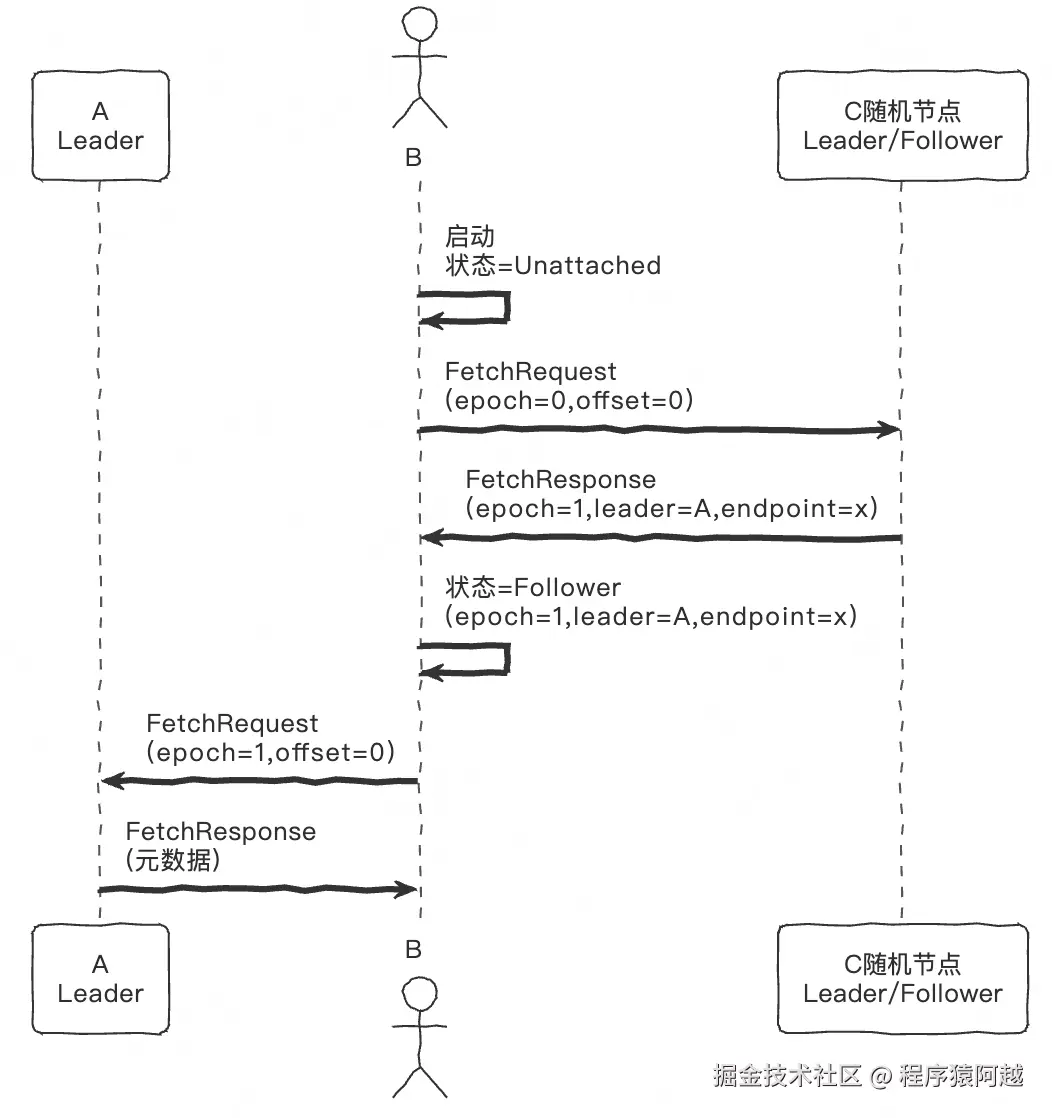
- QuorumState.initialize:新节点B ,不满足其他任何条件,从UnattachedState未知状态启动;
- KafkaRaftClient.pollUnattachedCommon:新节点B ,向controller.quorum.bootstrap.servers的随机节点发起FetchRequest;
- KafkaRaftClient.handleFetchRequest:随机节点C (如果集群里只有A,最终A会收到请求)收到请求。KafkaRaftClient#tryCompleteFetchRequest,校验请求中的leader任期 和当前内存中的leader任期 相等 且 自己是leader,否则直接返回异常FetchResponse,告知当前leader任期、id、端点;
- KafkaRaftClient.maybeHandleCommonResponse:新节点B,发现响应leader任期大于当前内存任期,自己主动成为follower;
注:大部分情况,通过Fetch请求获取Leader;特殊情况,通过Leader主动下发的BeginQuorumEpoch请求得知Leader。
4-2、新增RaftVoter
发现Leader后,新节点成为Observer(特殊的Follower,不在Voter集合),只能复制数据,无法参与选举。
Controller角色,通过kafka-metadata-quorum.sh add-controller成为Voter,可以参与选举。
选举成功,作为Raft Leader,成为Active Controller;否则作为Raft Follower,作为Standby Controller,随时准备接替下线的Leader。
简化流程如下:
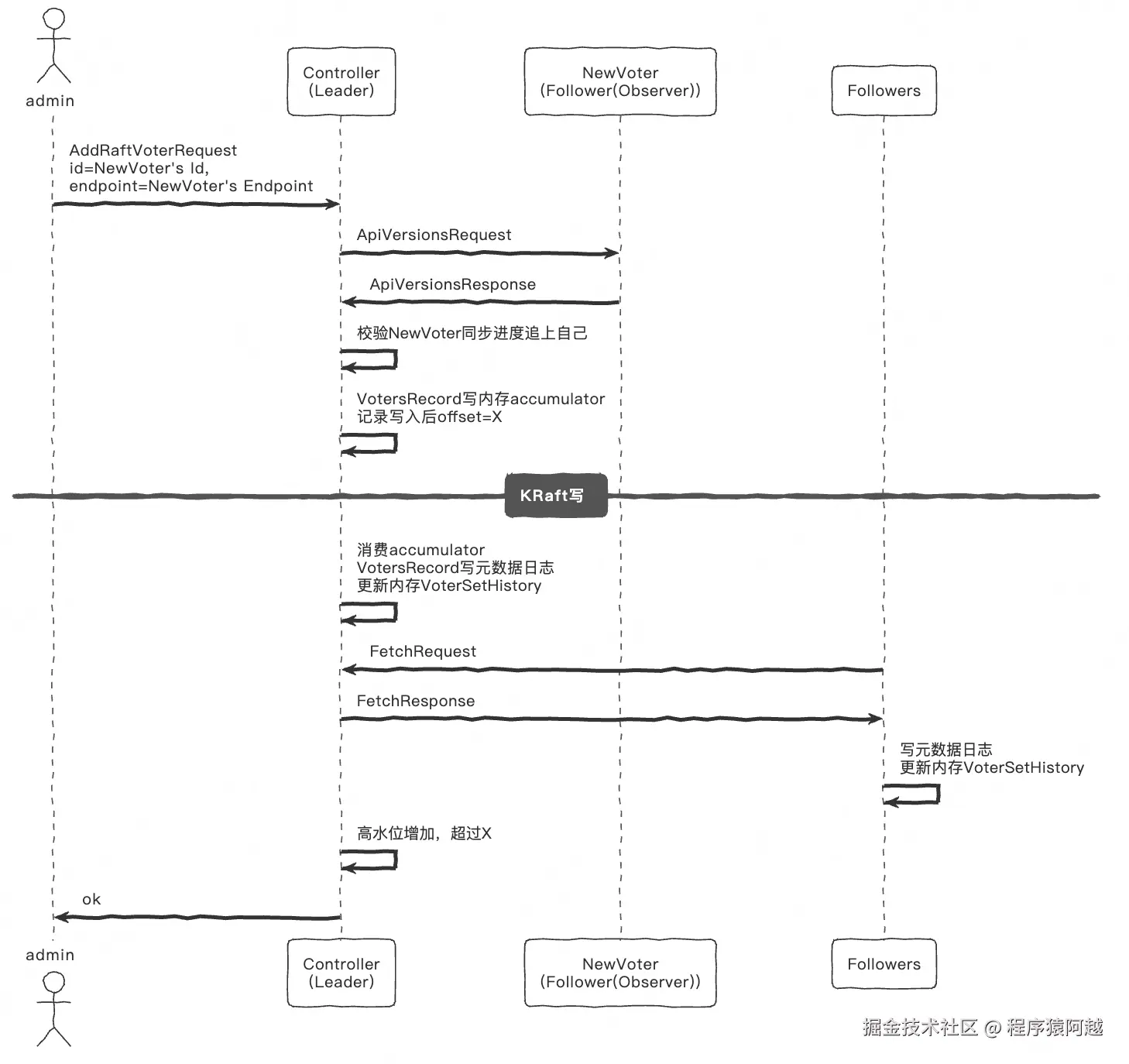
KafkaAdminClient.addRaftVoter:admin,发送AddRaftVoter,包含node.id和listener通讯端点。
AdminClientRunnable.makeMetadataCall:admin可以通过两种方式获取元数据
- 如果--bootstrap-controller,走Controller角色节点,发送DescribeClusterRequest,获取集群元数据,直接获取Controller节点与其通讯;
- 如果--bootstrap-server,走Broker角色节点,发送MetadataRequest,找负载最小Broker节点,AddRaftVoter可以被Broker角色处理,Broker会转发给Controller;
KafkaRaftClient.handleAddVoterRequest:Controller,收到AddRaftVoter ,发送ApiVersionsRequest给新Voter,确认支持KRaft;
DefaultApiVersionManager.apiVersionResponse:新Voter,收到ApiVersionsRequest,从内存获取相关数据,响应Controller;
AddVoterHandler.handleApiVersionsResponse:Controller,收到ApiVersionsResponse,检查该Voter一小时内发送过fetch 且曾经追上过自己的LEO ,将VotersRecord写内存accumulator,缓存本次AddRaftVoter写入后的offset=X,提交到Raft线程处理;
VotersRecord写入流程:
- KafkaRaftClient.maybeAppendBatches:Controller,消费accumulator写日志,更新内存VoterSetHistory.addAt(比较特殊,非高水位升高后应用到内存,直接更新);
- Follower(其他Voter),发送Fetch同步日志,更新内存VoterSetHistory.addAt;
- LeaderState.maybeUpdateHighWatermark:Controller,增加高水位;
- AddVoterHandler.highWatermarkUpdated:Controller,判断高水位超过X,响应AddRaftVoter完成;
五、KRaft状态流转
5-1、KRaft状态机
KafkaRaftClient.pollCurrentState:每个节点的Raft线程会根据当前状态走不同逻辑。根据Kafka节点角色不同,分为Controller和Broker两种状态流转。
java
private long pollCurrentState(long currentTimeMs) {
if (quorum.isLeader()) {
// 当前 epoch 的 leader
return pollLeader(currentTimeMs);
} else if (quorum.isCandidate()) {
// 候选人状态,正在进行正式选举
return pollCandidate(currentTimeMs);
} else if (quorum.isProspective()) {
// 预投票状态,在正式选举前先进行 pre-vote
return pollProspective(currentTimeMs);
} else if (quorum.isFollower()) {
// 当前 epoch 的 follower
return pollFollower(currentTimeMs);
} else if (quorum.isUnattached()) {
// 初始状态或不知道 leader 的状态
return pollUnattached(currentTimeMs);
} else if (quorum.isResigned()) {
// Leader 优雅关闭时的中间状态
return pollResigned(currentTimeMs);
}
}Controller角色:在Voter集合中,可以投票,可以成为Leader。
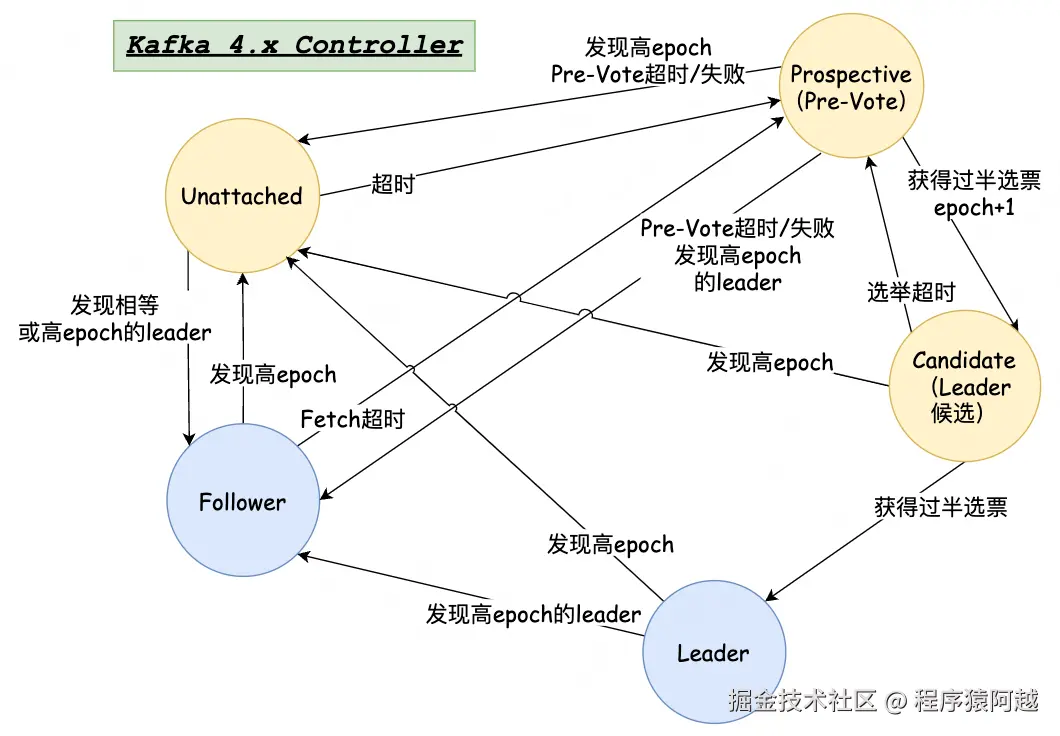
- Unattached:Leader未知的初始状态,当其他状态发现高任期(往往是发送请求后,收到响应KafkaRaftClient.maybeHandleCommonResponse),主动进入该状态;
- Prospective :Pre-Vote状态,Pre-Vote机制通过增加一个预投票阶段,不增加任期的情况下发起选举,防止网络分区中的节点不必要地增加任期号,从而在网络恢复时减少对集群的干扰,提高系统的整体可用性;
- Candidate:Leader候选者状态,Pre-Vote收到过半Voter的选票,任期+1进入正式选举;
- Leader :Candidate收到过半选票,正式成为Leader,成为Active Controller,可以接收控制请求,支持Follower复制元数据;
- Follower :发现高任期的Leader(往往是发送请求后,收到响应KafkaRaftClient.maybeHandleCommonResponse),成为Standby Controller,持续从Leader复制日志;
- Resigned:Leader优雅下线的中间状态,如果发现高epoch的新Leader进入Follower,如果发现高epoch进入Unattached;(忽略)
Broker角色:Observer(Learner),不在Voter集合中,不参与选举投票,只复制日志。
broker只会在Unattached 和Follower 状态之间转移,pollFollower和pollUnattached通过是否在Voter集合中区分不同逻辑。
java
private long pollFollower(long currentTimeMs) {
FollowerState state = quorum.followerStateOrThrow();
if (quorum.isVoter()) {
// 在voterset中,controller角色 follower
return pollFollowerAsVoter(state, currentTimeMs);
} else {
// 不在voterset中,broker角色 observer(learner)
return pollFollowerAsObserver(state, currentTimeMs);
}
}
private long pollUnattached(long currentTimeMs) {
UnattachedState state = quorum.unattachedStateOrThrow();
if (quorum.isVoter()) {
return pollUnattachedAsVoter(state, currentTimeMs);
} else {
return pollUnattachedCommon(state, currentTimeMs);
}
}每次状态转换,都会将raft节点状态(主要是leader和任期)持久化到quorum-state,重启后从该状态恢复(见3-3-2)。
shell
$ cat __cluster_metadata-0/quorum-state
{"leaderId":1,"leaderEpoch":2,"votedId":-1,"votedDirectoryId":"AAAAAAAAAAAAAAAAAAAAAA","data_version":1}5-2、Leader状态
KafkaRaftClient.pollLeader:Leader状态会做3个事情
1)如果刚成为leader,开启broker的会话(心跳)超时检测(ReplicationControlManager.maybeFenceOneStaleBroker),broker.session.timeout.ms=9000;
2)如果长时间(controller.quorum.fetch.timeout.ms=2000ms*1.5=3s)未收到过半Voter的fetch,主动进入Resigned状态,Leader下线;
3)Raft写流程,消费Accumulator内存中的Raft数据记录,真实写入元数据日志,更新内存;
4)每1s,向其他Voter发送BeginQuorumEpochRequest,一方面主动通知其他Voter自己的任期和id,让其他Voter成为Follower;另一方面,如果Voter返回高任期,自己转移Unattached,如果同时返回leaderId,转移Follower;
java
private long pollLeader(long currentTimeMs) {
LeaderState<T> state = quorum.leaderStateOrThrow();
// 1. 如果刚成为leader,触发Listener.handleLeaderChange
maybeFireLeaderChange(state);
// 2. timeUntilCheckQuorumExpires=0,代表长时间未收到过半voter的fetch,主动下线
long timeUntilCheckQuorumExpires = state.timeUntilCheckQuorumExpires(currentTimeMs);
if (shutdown.get() != null || state.isResignRequested()
|| timeUntilCheckQuorumExpires == 0) {
transitionToResigned(state.nonLeaderVotersByDescendingFetchOffset());
return 0L;
}
// 3. Raft写:消费内存BatchAccumulator,写元数据log,更新内存,feature过半ack,触发内存更新
long timeUntilFlush = maybeAppendBatches(state, currentTimeMs);
// 4. 定时发送BeginQuorumEpochRequest给其他Voter
// controller.quorum.fetch.timeout.ms=2000ms/2=1s
long timeUntilNextBeginQuorumSend = maybeSendBeginQuorumEpochRequests(
state,
currentTimeMs
);
}主要看第3步Raft写流程(结合Follower Fetch触发HW升高)。
KafkaRaftClient.maybeAppendBatches:所有的raft数据写入,都会先写到accumulator累积器,由raft线程单线程消费。
java
private long maybeAppendBatches(LeaderState<T> state,
long currentTimeMs) {
List<BatchAccumulator.CompletedBatch<T>> batches
= state.accumulator().drain();
Iterator<BatchAccumulator.CompletedBatch<T>> iterator = batches.iterator();
while (iterator.hasNext()) {
BatchAccumulator.CompletedBatch<T> batch = iterator.next();
// 1. 消费内存accumulator中的record写log,当完成过半ack-future,更新内存元数据
appendBatch(state, batch, currentTimeMs);
}
// 2. 处理LEO变更导致的HW变更,log刷盘
flushLeaderLog(state, currentTimeMs);
}
private void appendBatch(LeaderState<T> state,
BatchAccumulator.CompletedBatch<T> batch,
long appendTimeMs) {
int epoch = state.epoch();
// 1. leader写log
// 如果包含如VotersRecord,直接更新内存中的VoterSetHistory
LogAppendInfo info = appendAsLeader(batch.data);
OffsetAndEpoch offsetAndEpoch = new OffsetAndEpoch(info.lastOffset(), epoch);
// 2. leader 过半ack Future
CompletableFuture<Long> future = appendPurgatory.await(
// 写入批次的最后一个offset + 1,即当时的LEO
offsetAndEpoch.offset() + 1, Integer.MAX_VALUE);
future.whenComplete((commitTimeMs, exception) -> {
// 3. future完成,代表hw超过本次写入offset,leader可以执行commit
// MetadataLoader.handleCommit更新内存中的metadata MetadataLoader->Publishers
batch.records.ifPresent(records ->
maybeFireHandleCommit(batch.baseOffset, epoch, batch.appendTimestamp(), batch.sizeInBytes(), records)
);
});
}
private void flushLeaderLog(LeaderState<T> state, long currentTimeMs) {
// 处理LEO变化
updateLeaderEndOffsetAndTimestamp(state, currentTimeMs);
// segment刷盘
log.flush(false);
}KafkaRaftClient.updateLeaderEndOffsetAndTimestamp:Leader写入,可能直接触发高水位增加,比如只有Leader一个Voter。
java
private void updateLeaderEndOffsetAndTimestamp(LeaderState<T> state, long currentTimeMs) {
// Leader当前的LEO
final LogOffsetMetadata endOffsetMetadata = log.endOffset();
// 1. 更新Leader副本的LEO,并尝试增加高水位HW
if (state.updateLocalState(endOffsetMetadata, partitionState.lastVoterSet())) {
// 2. 返回true,代表高水位增加,处理和HW相关操作
onUpdateLeaderHighWatermark(state, currentTimeMs);
}
// 3. 因为LEO增加,拉起hold住的follower的fetch请求,可以继续拉取数据
fetchPurgatory.maybeComplete(endOffsetMetadata.offset(), currentTimeMs);
}
private void onUpdateLeaderHighWatermark(LeaderState<T> state,
long currentTimeMs) {
state.highWatermark().ifPresent(highWatermark -> {
// 更新底层kafka log的hw
log.updateHighWatermark(highWatermark);
// raft写过半ack,可能是add-voter操作,响应admin成功
addVoterHandler.highWatermarkUpdated(state);
removeVoterHandler.highWatermarkUpdated(state);
// raft写过半ack,触发后续流程,比如MetadataLoader更新内存元数据
appendPurgatory.maybeComplete(highWatermark.offset(), currentTimeMs);
// 响应fetch请求,因为HW变化
fetchPurgatory.completeAll(currentTimeMs);
// 触发其他Listener
updateListenersProgress(highWatermark.offset());
});
}LeaderState.maybeUpdateHighWatermark:当过半Voter的副本LEO > 当前HW,更新HW = 当过半Voter的副本LEO。
java
// 副本id(brokerId)和 副本状态
private Map<Integer, ReplicaState> voterStates = new HashMap<>();
// HW
private Optional<LogOffsetMetadata> highWatermark = Optional.empty();
private boolean maybeUpdateHighWatermark() {
// 副本按照offset降序
ArrayList<ReplicaState> followersByDescendingFetchOffset = followersByDescendingFetchOffset()
.collect(Collectors.toCollection(ArrayList::new));
// 获取第 voters.size / 2 的副本 的 offset
int indexOfHw = voterStates.size() / 2;
Optional<LogOffsetMetadata> highWatermarkUpdateOpt = followersByDescendingFetchOffset.get(indexOfHw).endOffset;
if (highWatermarkUpdateOpt.isPresent()) {
LogOffsetMetadata highWatermarkUpdateMetadata = highWatermarkUpdateOpt.get();
long highWatermarkUpdateOffset = highWatermarkUpdateMetadata.offset();
if (highWatermarkUpdateOffset > epochStartOffset) {
// epochStartOffset是leader的起始offset(当时的LEO)
// LeaderState.appendStartOfEpochControlRecords成为leader后会写入LeaderChangeMessage,
// 触发HW增加超过epochStartOffset
if (highWatermark.isPresent()) {
LogOffsetMetadata currentHighWatermarkMetadata = highWatermark.get();
if (highWatermarkUpdateOffset > currentHighWatermarkMetadata.offset()
|| (highWatermarkUpdateOffset == currentHighWatermarkMetadata.offset() &&
!highWatermarkUpdateMetadata.metadata().equals(currentHighWatermarkMetadata.metadata()))) {
highWatermark = highWatermarkUpdateOpt;
return true;
}
return false;
} else {
highWatermark = highWatermarkUpdateOpt;
return true;
}
}
}
return false;
}
public static class ReplicaState implements Comparable<ReplicaState> {
// brorkerId
private ReplicaKey replicaKey;
private Endpoints listeners;
// 同步进度
private Optional<LogOffsetMetadata> endOffset;
// 上次fetch时间
private long lastFetchTimestamp;
// 上次fetch时,leader的LEO
private long lastFetchLeaderLogEndOffset;
// 上次追上leader的LEO的时间
private long lastCaughtUpTimestamp;
private boolean hasAcknowledgedLeader;
}5-3、Follower状态
5-3-1、Follower发送Fetch请求
KafkaRaftClient.pollFollower:
- 如果fetch响应超时(controller.quorum.fetch.timeout.ms=2000ms),controller角色,进入Prospective状态,准备参与选举;broker角色,请求bootstrap节点,尝试重新发现Leader;
- 如果请求超时(controller.quorum.request.timeout.ms=2000),请求bootstrap节点,尝试重新发现Leader;
- 其他,正常发送Fetch或FetchSnapshot请求给Leader;
java
private long pollFollower(long currentTimeMs) {
FollowerState state = quorum.followerStateOrThrow();
if (quorum.isVoter()) {
// 在voterset中,controller角色 follower
return pollFollowerAsVoter(state, currentTimeMs);
} else {
// 不在voterset中,broker角色 observer(learner)
return pollFollowerAsObserver(state, currentTimeMs);
}
}
private long pollFollowerAsVoter(FollowerState state, long currentTimeMs) {
GracefulShutdown shutdown = this.shutdown.get();
final long backoffMs;
if (shutdown != null) {
backoffMs = 0;
} else if (state.hasFetchTimeoutExpired(currentTimeMs)) {
// 1. fetch超时(controller.quorum.fetch.timeout.ms=2000ms) Follower -> Prospective
// 2s内没收到过fetchResponse
transitionToProspective(currentTimeMs);
backoffMs = 0;
} else if (state.hasUpdateVoterPeriodExpired(currentTimeMs)) {
// ...
} else {
// 请求超时controller.quorum.request.timeout.ms=2000,发送给任意bootstrap节点,尝试发现新leader
// 否则发送fetch给leader
backoffMs = maybeSendFetchToBestNode(state, currentTimeMs);
}
}
private long pollFollowerAsObserver(FollowerState state, long currentTimeMs) {
if (state.hasFetchTimeoutExpired(currentTimeMs)) {
// 1. fetch超时(controller.quorum.fetch.timeout.ms=2000ms)
// 发送fetch给任意bootstrap节点,重新发现leader
return maybeSendFetchToAnyBootstrap(currentTimeMs);
} else {
// 请求超时(controller.quorum.request.timeout.ms=2000),发送给任意bootstrap节点,尝试发现新leader
// 否则发送fetch给leader
return maybeSendFetchToBestNode(state, currentTimeMs);
}
}5-3-2、Leader处理Fetch请求
KafkaRaftClient.tryCompleteFetchRequest:Leader处理Fetch请求
- validateLeaderOnlyRequest,校验request.epoch=当前leader.epoch 且 自己是leader,否则返回当前epoch和leader,让客户端转换为Unattached或Follower;
- validateOffsetAndEpoch,校验请求中,fetchOffset = Follower的LEO即下一个写入offset 和lastFetchedEpoch = Follower当前写入最后一条数据的epoch;
- 正常拉数据,响应Follower;
java
private FetchResponseData tryCompleteFetchRequest(ListenerName listenerName,
short apiVersion,
ReplicaKey replicaKey,
FetchRequestData.FetchPartition request,
long currentTimeMs) {
// 1. 校验request.epoch=当前leader.epoch && 自己是leader
Optional<Errors> errorOpt = validateLeaderOnlyRequest(request.currentLeaderEpoch());
if (errorOpt.isPresent()) {
return buildEmptyFetchResponse(listenerName, apiVersion, errorOpt.get(), Optional.empty());
}
long fetchOffset = request.fetchOffset();
int lastFetchedEpoch = request.lastFetchedEpoch();
LeaderState<T> state = quorum.leaderStateOrThrow();
Optional<OffsetAndEpoch> latestSnapshotId = log.latestSnapshotId();
final ValidOffsetAndEpoch validOffsetAndEpoch;
if (fetchOffset == 0 && latestSnapshotId.isPresent() &&
!latestSnapshotId.get().equals(BOOTSTRAP_SNAPSHOT_ID)) {
// follower的offset为0,是新副本,且leader有快照,让follower先同步快照
validOffsetAndEpoch = ValidOffsetAndEpoch.snapshot(latestSnapshotId.get());
} else {
// 2. 校验fetchOffset和lastFetchedEpoch
validOffsetAndEpoch = log.validateOffsetAndEpoch(fetchOffset, lastFetchedEpoch);
}
final Records records;
if (validOffsetAndEpoch.kind() == ValidOffsetAndEpoch.Kind.VALID) {
// 3. 正常拉数据,更新HW
LogFetchInfo info = log.read(fetchOffset, Isolation.UNCOMMITTED);
if (state.updateReplicaState(replicaKey, currentTimeMs, info.startOffsetMetadata)) {
onUpdateLeaderHighWatermark(state, currentTimeMs);
}
records = info.records;
} else {
records = MemoryRecords.EMPTY;
}
return buildFetchResponse(...);
}ReplicatedLog.validateOffsetAndEpoch:校验Follower的fetch epoch和offset,可能返回
- Follower数据较老,返回需要FetchSnapshot;
- Follower数据超出Leader,返回需要截断;
- 正常,继续处理;
java
// offset=客户端的LEO下一个写入位置,epoch=客户端最后一条数据的epoch
default ValidOffsetAndEpoch validateOffsetAndEpoch(long offset, int epoch) {
if (startOffset() == 0 && offset == 0) {
return ValidOffsetAndEpoch.valid(new OffsetAndEpoch(0, 0));
}
// 快照存在
Optional<OffsetAndEpoch> earliestSnapshotId = earliestSnapshotId();
if (earliestSnapshotId.isPresent() &&
((offset < startOffset()) ||
(offset == startOffset() && epoch != earliestSnapshotId.get().epoch()) ||
(epoch < earliestSnapshotId.get().epoch()))
) {
OffsetAndEpoch latestSnapshotId = latestSnapshotId();
// case1 follower的(epoch,offset)不在raft日志里,需要snapshot
return ValidOffsetAndEpoch.snapshot(latestSnapshotId);
} else {
// 小于等于
OffsetAndEpoch endOffsetAndEpoch = endOffsetForEpoch(epoch);
if (endOffsetAndEpoch.epoch() != epoch || endOffsetAndEpoch.offset() < offset) {
// case2 follower的(epoch,offset)超出leader,需要截断
return ValidOffsetAndEpoch.diverging(endOffsetAndEpoch);
} else {
// case3 正常fetch
return ValidOffsetAndEpoch.valid(new OffsetAndEpoch(offset, epoch));
}
}
}LeaderState.updateReplicaState→ReplicaState.updateFollowerState:处理Follower副本的拉取进度。和老版本一致,用lastCaughtUpTimestamp上次追上Leader副本的时间戳来判断Follower的副本进度。
java
void updateFollowerState(
long currentTimeMs,
LogOffsetMetadata fetchOffsetMetadata,
Optional<LogOffsetMetadata> leaderEndOffsetOpt) {
leaderEndOffsetOpt.ifPresent(leaderEndOffset -> {
if (fetchOffsetMetadata.offset() >= leaderEndOffset.offset()) {
// fetch请求offset 达到 leader的LEO
// lastCaughtUpTimestamp上次追上leader的时间=当前时间
lastCaughtUpTimestamp = Math.max(lastCaughtUpTimestamp, currentTimeMs);
} else if (lastFetchLeaderLogEndOffset > 0
&& fetchOffsetMetadata.offset() >= lastFetchLeaderLogEndOffset) {
// fetch请求offset 超出 上次fetch请求时Leader的LEO
// lastCaughtUpTimestamp上次追上leader的时间=上次fetch请求时间
lastCaughtUpTimestamp = Math.max(lastCaughtUpTimestamp, lastFetchTimestamp);
}
lastFetchLeaderLogEndOffset = leaderEndOffset.offset();
});
lastFetchTimestamp = Math.max(lastFetchTimestamp, currentTimeMs);
endOffset = Optional.of(fetchOffsetMetadata);
hasAcknowledgedLeader = true;
}LeaderState.updateCheckQuorumForFollowingVoter:收到正常Fetch,更新发送fetch请求的voters数量。(见5-2,如果Leader未在每3s内收到过半fetch,会自动下线)
java
public void updateCheckQuorumForFollowingVoter(ReplicaKey replicaKey, long currentTimeMs) {
updateFetchedVoters(replicaKey);
if (voterStates.containsKey(localVoterNode.voterKey().id())) {
majority = majority - 1;
}
if (fetchedVoters.size() >= majority) {
fetchedVoters.clear();
checkQuorumTimer.update(currentTimeMs);
checkQuorumTimer.reset(checkQuorumTimeoutMs);
}
}HW变更见Leader部分。
KafkaRaftClient.handleFetchRequest:Leader,满足6个条件之一,直接返回,否则挂起fetch请求,等待高水位增加后响应。
- 有异常;
- 有数据可以返回(注意元数据同步不能攒批拉取);
- 请求挂起时间为0(写死500ms,所以不会挂起);
- Follower数据需要被截断;
- Follower需要发送FetchSnapshot;
- 高水位变化;
java
private CompletableFuture<FetchResponseData> handleFetchRequest(
RaftRequest.Inbound requestMetadata,
long currentTimeMs) {
// 1. 尝试处理fetch
FetchResponseData response = tryCompleteFetchRequest(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
replicaKey,
fetchPartition,
currentTimeMs
);
FetchResponseData.PartitionData partitionResponse =
response.responses().get(0).partitions().get(0);
// 2. 满足条件,直接响应
if (partitionResponse.errorCode() != Errors.NONE.code()
|| FetchResponse.recordsSize(partitionResponse) > 0
|| request.maxWaitMs() == 0
|| isPartitionDiverged(partitionResponse)
|| isPartitionSnapshotted(partitionResponse)
|| isHighWatermarkUpdated(partitionResponse, fetchPartition)) {
return completedFuture(response);
}
// 3. 否则等待HW超过请求offset再次触发tryCompleteFetchRequest
CompletableFuture<Long> future = fetchPurgatory.await(
fetchPartition.fetchOffset(),
request.maxWaitMs()
);
return future.handle((completionTimeMs, exception) -> {
return tryCompleteFetchRequest(...);
});
}5-3-3、Follower处理Fetch响应
KafkaRaftClient.handleFetchResponse:根据Leader的三类响应,Follower执行不同逻辑。
java
private boolean handleFetchResponse(RaftResponse.Inbound responseMetadata,
long currentTimeMs) {
FetchResponseData response = (FetchResponseData) responseMetadata.data();
// 1. 通用处理,发现高epoch转移Unattached
Optional<Boolean> handled = maybeHandleCommonResponse(...);
if (handled.isPresent()) {
return handled.get();
}
FollowerState state = quorum.followerStateOrThrow();
if (error == Errors.NONE) {
FetchResponseData.EpochEndOffset divergingEpoch = partitionResponse.divergingEpoch();
if (divergingEpoch.epoch() >= 0) {
// case1 follower截断
final OffsetAndEpoch divergingOffsetAndEpoch = new OffsetAndEpoch(
divergingEpoch.endOffset(), divergingEpoch.epoch());
long truncationOffset = log.truncateToEndOffset(divergingOffsetAndEpoch);
partitionState.truncateNewEntries(truncationOffset);
} else if (partitionResponse.snapshotId().epoch() >= 0 ||
partitionResponse.snapshotId().endOffset() >= 0) {
// case2 follower需要snapshot
final OffsetAndEpoch snapshotId = new OffsetAndEpoch(
partitionResponse.snapshotId().endOffset(),
partitionResponse.snapshotId().epoch()
);
// 设置FetchingSnapshot状态,下次poll发送FetchSnapshot而不是Fetch
state.setFetchingSnapshot(log.createNewSnapshotUnchecked(snapshotId));
} else {
// case3 raft日志同步follower
appendAsFollower(FetchResponse.recordsOrFail(partitionResponse));
// 更新hw=leader.hw
OptionalLong highWatermark = partitionResponse.highWatermark() < 0 ?
OptionalLong.empty() : OptionalLong.of(partitionResponse.highWatermark());
updateFollowerHighWatermark(state, highWatermark);
}
// 更新fetch成功时间,即fetch没超时
state.resetFetchTimeoutForSuccessfulFetch(currentTimeMs);
return true;
} else {
return handleUnexpectedError(error, responseMetadata);
}
}KafkaRaftClient.poll:在raft主循环中,handleInboundMessage处理FetchResponse写log和从leader同步hw完成,进而触发Listener,如MetadataLoader回放raft日志中的元数据,应用到内存。
java
public void poll() {
// 1. 根据状态做不同处理,如leader写log,follower发送fetch请求
long pollStateTimeoutMs = pollCurrentState(startPollTimeMs);
// 2. 处理收到的请求和响应
RaftMessage message = messageQueue.poll(pollTimeoutMs);
if (message != null) {
handleInboundMessage(message, endWaitTimeMs);
}
// 3. 如果元数据raft日志的hw升高,触发Listener
pollListeners();
}5-3-4、关于Snapshot同步
Follower通过Fetch请求发现需要走Snapshot同步,分片请求Leader获取Snapshot并落盘。
KafkaRaftClient.handleFetchSnapshotRequest:Leader处理FetchSnapshotRequest。
java
private FetchSnapshotResponseData handleFetchSnapshotRequest(
RaftRequest.Inbound requestMetadata,
long currentTimeMs) {
FetchSnapshotRequestData data = (FetchSnapshotRequestData) requestMetadata.data();
Optional<FetchSnapshotRequestData.PartitionSnapshot> partitionSnapshotOpt
= FetchSnapshotRequest.forTopicPartition(data, log.topicPartition());
FetchSnapshotRequestData.PartitionSnapshot partitionSnapshot
= partitionSnapshotOpt.get();
// 请求中包含目标snapshot
OffsetAndEpoch snapshotId = new OffsetAndEpoch(
partitionSnapshot.snapshotId().endOffset(),
partitionSnapshot.snapshotId().epoch()
);
Optional<RawSnapshotReader> snapshotOpt = log.readSnapshot(snapshotId);
RawSnapshotReader snapshot = snapshotOpt.get();
// 按照[position,position+maxBytes]截取传输
UnalignedRecords records = snapshot.slice(partitionSnapshot.position(), Math.min(data.maxBytes(), maxSnapshotSize));
return RaftUtil.singletonFetchSnapshotResponse(...);
}KafkaRaftClient.handleFetchSnapshotResponse:Follower处理FetchSnapshotResponse。
java
private boolean handleFetchSnapshotResponse(
RaftResponse.Inbound responseMetadata, long currentTimeMs) {
// ...
// 可能snapshot需要多轮传输,这里会存储当前fetchSnapshot状态
RawSnapshotWriter snapshot = state.fetchingSnapshot().orElseThrow(
() -> new IllegalStateException();
// 写snapshot
UnalignedMemoryRecords records
= new UnalignedMemoryRecords(((MemoryRecords) partitionSnapshot.unalignedRecords()).buffer());
snapshot.append(records);
// snapshot大小 = 期望大小
if (snapshot.sizeInBytes() == partitionSnapshot.size()) {
// snapshot完整传输
snapshot.freeze();
state.setFetchingSnapshot(Optional.empty());
// log按照snapshot截断,只保留snapshot之后的内容
if (log.truncateToLatestSnapshot()) {
updateFollowerHighWatermark(state, OptionalLong.of(log.highWatermark().offset()));
} else {
throw new IllegalStateException();
}
}
return true;
}5-4、Unattached
KafkaRaftClient.pollUnattached:
- Controller角色:选举超时时间内(随机在1s-2s之间),可以发送Fetch给任意bootstrap节点用于发现Leader;超时后进入Prospective,开始Pre-Vote准备竞选;
- Broker角色:没有超时时间限制,持续发送Fetch给任意bootstrap节点;
java
private long pollUnattached(long currentTimeMs) {
UnattachedState state = quorum.unattachedStateOrThrow();
if (quorum.isVoter()) {
// Controller
return pollUnattachedAsVoter(state, currentTimeMs);
} else {
// Broker
return pollUnattachedCommon(state, currentTimeMs);
}
}
private long pollUnattachedAsVoter(UnattachedState state, long currentTimeMs) {
GracefulShutdown shutdown = this.shutdown.get();
if (shutdown != null) {
return shutdown.remainingTimeMs();
} else if (state.hasElectionTimeoutExpired(currentTimeMs)) {
// Controller角色,处于Unattached超过选举超时时间,进入Prospective
transitionToProspective(currentTimeMs);
return 0L;
} else {
// 发送fetch给bootstrap节点,用于发现Leader
return pollUnattachedCommon(state, currentTimeMs);
}
}
// 选举超时时间
private int randomElectionTimeoutMs() {
// electionTimeoutMs = controller.quorum.election.timeout.ms = 1000ms
return electionTimeoutMs + random.nextInt(electionTimeoutMs);
}5-5、Prospective/Candidate
5-5-1、客户端发送VoteRequest
KafkaRaftClient.pollProspective:Prospective状态
- 选举超时(随机在1s-2s之间),如果Leader已知转移为Follower(可能是Follower与Leader失联,短暂进入Prospective);如果Leader未知转移为Unattached,重新发现Leader;
- 正常情况,如果拒绝票不过半,持续发送VoteRequest ,preVote=true;
java
private long pollProspective(long currentTimeMs) {
ProspectiveState state = quorum.prospectiveStateOrThrow();
GracefulShutdown shutdown = this.shutdown.get();
if (shutdown != null) {
long minRequestBackoffMs = maybeSendVoteRequests(state, currentTimeMs);
return Math.min(shutdown.remainingTimeMs(), minRequestBackoffMs);
} else if (state.hasElectionTimeoutExpired(currentTimeMs)) {
// 选举超时([1s,2s])
// electionTimeoutMs = controller.quorum.election.timeout.ms = 1000ms
prospectiveTransitionAfterElectionLoss(state, currentTimeMs);
return 0L;
} else {
// 拒绝票不过半,持续发送VoteRequest
long minVoteRequestBackoffMs = maybeSendVoteRequests(state, currentTimeMs);
return Math.min(minVoteRequestBackoffMs, state.remainingElectionTimeMs(currentTimeMs));
}
}
private void prospectiveTransitionAfterElectionLoss(ProspectiveState prospective, long currentTimeMs) {
if (prospective.election().hasLeader() && !prospective.leaderEndpoints().isEmpty()) {
// 如果leader已知,prospective->follower
transitionToFollower(quorum().epoch(), prospective.election().leaderId(),
prospective.leaderEndpoints(), currentTimeMs);
} else {
// leader未知,prospective->unattached
transitionToUnattached(quorum().epoch(), prospective.election().optionalLeaderId());
}
}
private long maybeSendVoteRequests(NomineeState state, long currentTimeMs) {
if (!state.epochElection().isVoteRejected()) {
// 拒绝票不过半,仍有机会选举成功,继续发送VoteRequest
VoterSet voters = partitionState.lastVoterSet();
// preVote=true
boolean preVote = quorum.isProspective();
return maybeSendRequest(
currentTimeMs,
// 对未收到响应的voter
state.epochElection().unrecordedVoters(),
voterId -> voters
.voterNode(voterId, channel.listenerName())
.orElseThrow(...),
voterId -> buildVoteRequest(voterId, preVote)
);
}
return Long.MAX_VALUE;
}KafkaRaftClient.pollCandidate:Candidate状态
- 选举超时,回退到Prospective状态;
- 否则,同Prospective状态,持续发送VoteRequest,preVote=false;
java
private long pollCandidate(long currentTimeMs) {
CandidateState state = quorum.candidateStateOrThrow();
GracefulShutdown shutdown = this.shutdown.get();
if (shutdown != null) {
long minRequestBackoffMs = maybeSendVoteRequests(state, currentTimeMs);
return Math.min(shutdown.remainingTimeMs(), minRequestBackoffMs);
} else if (state.hasElectionTimeoutExpired(currentTimeMs)) {
transitionToProspective(currentTimeMs);
return 0L;
} else {
long minVoteRequestBackoffMs = maybeSendVoteRequests(state, currentTimeMs);
return Math.min(minVoteRequestBackoffMs, state.remainingElectionTimeMs(currentTimeMs));
}
}5-5-2、服务端响应VoteResponse
KafkaRaftClient.handleVoteRequest:服务端处理VoteRequest
- 校验epoch,如果客户端epoch小于当前epoch,返回正确leader和epoch;
- 如果客户端epoch大于当前epoch ,服务端自行转换为Unattached,继续处理请求;
- canGrantVote,根据当前节点的状态,决定是否投票给客户端;
- 非pre-vote,且投票给客户端,将投票记录到当前状态;
java
private VoteResponseData handleVoteRequest(RaftRequest.Inbound requestMetadata) {
VoteRequestData request = (VoteRequestData) requestMetadata.data();
VoteRequestData.PartitionData partitionRequest =
request.topics().get(0).partitions().get(0);
// 对端id和所处leader任期
int replicaId = partitionRequest.replicaId();
int replicaEpoch = partitionRequest.replicaEpoch();
// pre-vote标志
boolean preVote = partitionRequest.preVote();
// 对端最后一条元数据的epoch和offset
int lastEpoch = partitionRequest.lastOffsetEpoch();
long lastEpochEndOffset = partitionRequest.lastOffset();
// 1. 通用处理,请求中epoch < 当前epoch,返回正确leader和epoch
Optional<Errors> errorOpt = validateVoterOnlyRequest(replicaId, replicaEpoch);
if (errorOpt.isPresent()) {
return buildVoteResponse(...);
}
// 2. 如果对端epoch > 当前节点epoch,当前节点转换为Unattached
// 正常Prospective状态Pre-Vote不会改变epoch,只有Candidate状态+1
if (replicaEpoch > quorum.epoch()) {
transitionToUnattached(replicaEpoch, OptionalInt.empty());
}
OffsetAndEpoch lastEpochEndOffsetAndEpoch = new OffsetAndEpoch(lastEpochEndOffset, lastEpoch);
ReplicaKey replicaKey = ReplicaKey.of(
replicaId,
partitionRequest.replicaDirectoryId()
);
// 3. 判断是否能投票给对端
boolean voteGranted = quorum.canGrantVote(
replicaKey,
lastEpochEndOffsetAndEpoch.compareTo(endOffset()) >= 0,
preVote
);
// 4. 如果非preVote,且投票给对端,将投票数据记录到状态
if (!preVote && voteGranted) {
if (quorum.isUnattachedNotVoted()) {
quorum.unattachedAddVotedState(replicaEpoch, replicaKey);
} else if (quorum.isProspectiveNotVoted()) {
quorum.prospectiveAddVotedState(replicaEpoch, replicaKey);
}
}
return buildVoteResponse(
requestMetadata.listenerName(),
requestMetadata.apiVersion(),
Errors.NONE,
voteGranted
);
}EpochState.canGrantVote:服务端是否投票给客户端
- 上面因为客户端epoch比自己大,一定会转换为Unattached;
- 如果客户端epoch与自己相等,根据不同状态处理方式不同
replicaKey-参选节点,isLogUpToDate-参选者日志是否比自己新。
java
// Leader 一定不会同意epoch与自己相等的投票
public boolean canGrantVote(ReplicaKey replicaKey, boolean isLogUpToDate, boolean isPreVote) {
return false;
}
// Follower
// 满足:pre-vote,没有从leader成功fetch过,对端数据>=自己,同意
public boolean canGrantVote(ReplicaKey replicaKey, boolean isLogUpToDate, boolean isPreVote) {
if (isPreVote && !hasFetchedFromLeader && isLogUpToDate) {
return true;
}
return false;
}
// Candidate和Resigned
// 满足:pre-vote,对端数据>=自己,同意
public boolean canGrantVote(ReplicaKey replicaKey, boolean isLogUpToDate, boolean isPreVote) {
if (isPreVote && isLogUpToDate) {
return true;
}
return false;
}
// Unattached和Prospective
public static boolean unattachedOrProspectiveCanGrantVote(...) {
if (isPreVote) {
// pre-vote,和Candidate和Resigned一致,数据>=自己,同意
return isLogUpToDate;
} else if (votedKey.isPresent()) {
ReplicaKey votedReplicaKey = votedKey.get();
if (votedReplicaKey.id() == replicaKey.id()) {
// 已经投票给本次请求的客户端,再次返回true
return votedReplicaKey.directoryId().isEmpty() || votedReplicaKey.directoryId().equals(replicaKey.directoryId());
}
// 已经投票给别人,否决
return false;
} else if (leaderId.isPresent()) {
// 如果Leader存在,否决
return false;
}
// 未投票&Leader不存在,数据>=自己,同意
return isLogUpToDate;
}5-5-3、客户端处理VoteResponse
KafkaRaftClient.handleVoteResponse:客户端
- 服务端返回更高epoch或高epoch的leader,进入Unattached或Follower;
- 客户端此时为非Candidate或Prospective,忽略投票响应;
- 如果对端同意,判断过半同意,向后推进状态,Prospective→Candidate,Candidate→Leader;
- 如果对端否决,判断过半否决,Candidate不处理,等待选举超时;Prospective根据leader是否未知,进入unattached或follower;
java
private boolean handleVoteResponse(
RaftResponse.Inbound responseMetadata,
long currentTimeMs) {
int remoteNodeId = responseMetadata.source().id();
// ...
// 通用处理,发现响应更高epoch或更高epoch的leader,进入Unattached或Follower
Optional<Boolean> handled = maybeHandleCommonResponse(...);
if (handled.isPresent()) {
return handled.get();
} else if (error == Errors.NONE) {
if (quorum.isLeader()) {
// 客户端此时已经成为Leader,忽略收到的Vote响应
} else if (quorum.isNomineeState()) {
// 客户端此时Candidate或Prospective,处理投票结果
NomineeState state = quorum.nomineeStateOrThrow();
if (partitionResponse.voteGranted()) {
// 如果对端同意,如果选票过半,进入下一个状态
state.recordGrantedVote(remoteNodeId);
maybeTransitionForward(state, currentTimeMs);
} else {
// 如果对端否决
state.recordRejectedVote(remoteNodeId);
maybeHandleElectionLoss(state, currentTimeMs);
}
} else {
// 客户端此时非Leader、Candidate、Prospective,忽略
}
return true;
} else {
return handleUnexpectedError(error, responseMetadata);
}
}
private void maybeHandleElectionLoss(NomineeState state, long currentTimeMs) {
if (state instanceof CandidateState candidate) {
// Candidate选举失败,等待超时后进入Prospective
if (candidate.epochElection().isVoteRejected()) {
logger.info(...);
}
} else if (state instanceof ProspectiveState prospective) {
// Prospective选举失败,根据leader是否未知,进入unattached或follower
if (prospective.epochElection().isVoteRejected()) {
logger.info(...);
prospectiveTransitionAfterElectionLoss(prospective, currentTimeMs);
}
}
}QuorumState.transitionToCandidate:如果Prospective通过Pre-Vote,进入Candidate才会增加epoch。
java
public void transitionToCandidate() {
checkValidTransitionToCandidate();
int newEpoch = epoch() + 1;
int electionTimeoutMs = randomElectionTimeoutMs();
durableTransitionTo(new CandidateState(
time,
localIdOrThrow(),
localDirectoryId,
newEpoch,
partitionState.lastVoterSet(),
state.highWatermark(),
electionTimeoutMs,
logContext
));
}总结
Raft日志
Raft日志=cluster_metadata的0分区的消息记录。
Raft快照={offset}-{epoch}.checkpoint,包含一份到(offset,epoch)的元数据。
集群初始化
集群中有两种角色:
- Controller:负责集群管理,如元数据管理、Topic管理;
- Broker:接收客户端请求,收发消息;
两者的主要区别是:
- Controller:在Voter集合中,可以参与Raft选举投票。如果选举通过成为Leader,称为Active Controller;否则成为Follower,称为Standby Controller,当发现Leader线下可以重新参与选举;
- Broker:不在Voter集合中,只能作为Observer(特殊Follower)复制日志;
Raft日志中最后一条KRAFT_VOTERS类型日志,即当前Voter集合。
集群建立:
- 首个Controller,admin通过standalone参数格式化数据目录,写入KRAFT_VOTERS。当启动重放日志,发现自己是唯一Voter,自动成为Leader;
- 其他节点向controller.quorum.bootstrap.servers随机节点发送Fetch请求,发现Leader,自动成为Follower,开始复制数据;
- admin通过kafka-metadata-quorum.sh将追上Leader的Controller角色Follower节点,加入Voter集合,使之成为Standby Controller;
后续Leader发现方式:
- 节点发送Fetch请求,响应收到更高epoch的Leader;
- Leader节点每1s,向其他Voter发送BeginQuorumEpochRequest,告知自己的id、epoch、endpoint;
failover和选主
ZK模式:通过竞争**/controller**临时ZNode实现Controller的failover和选主。
KRaft模式:
- Controller角色Follower,发现Fetch响应超时(controller.quorum.fetch.timeout.ms=2000ms),进入Prospective状态,准备参与选举;Leader发现过半Voter长时间未发送Fetch(3s),自行进入Resigned下线;
- Prospective状态,不更新epoch,发送VoteRequest(preVote=true)给所有Voter;
- Voter,如果对端epoch和日志都比自己新(简单概括),则同意,否则否决;
- 如果过半Voter同意,Prospective进入Candidate状态;否则,Leader已存在则进入Follower,Leader不存在进入Unattached,重新发现Leader或选举超时再次进入Prospective;
- Candidate状态,epoch+1,发送VoteRequest(preVote=false)给所有Voter;
- Voter再次判断;
- 如果过半Voter同意,进入Leader状态;否则等待选举超时后,重新进入Prospective状态;
每次状态变更都会持久化到cluster_metadata的0分区的quorum-state文件里,包括当前leaderId、任期等。
日志复制
ZK模式:Broker启动后注册到/brokers,Controller可以发现所有集群成员。当元数据变化(如Topic新建),Controller通过UpdateMetadataRequest发送给所有存活Broker。
KRaft模式:Broker(或Standby Controller)通过复制Raft日志,重放到内存,完成元数据更新。
传统Raft写:
- Leader写日志,提升writeIndex,发送AppendEntries RPC给所有Follower;
- Follower写日志,提升writeIndex;
- 过半Follower响应Leader成功,Leader提升commitIndex;
- Leader将日志应用到内存,响应客户端成功;
- Leader通过AppendEntries RPC推进follower的commitIndex,follower将日志应用到内存;
KRaft写在KafkaRaftClient单线程处理:
-
收到写请求,写内存累积器accumulator;
-
Leader,消费accumulator,写日志,推进LEO;
-
Follower,发送FetchRequest,包含epoch=当前leader任期、lastFetchedEpoch=最后一条数据的epoch、fetchOffset=消费进度(Follower的LEO);
-
Leader,校验fetchOffset和lastFetchedEpoch,三种case:
- fetchOffset比最小的snapshot还小,返回Follower需要发送FetchSnapshot;
- fetchOffset比自己LEO大,返回Follower需要截断;
- fetchOffset合法,返回数据或挂起请求等待新数据;
-
Follower,收到数据写日志;
-
Follower,发送FetchRequest,持续同步;
-
Leader,发现过半Controller角色的fetchOffset超过当前高水位HW,更新HW=该offset;
-
Leader,当HW超出客户端Raft写入对应offset,响应成功;
-
当HW变化,所有Raft成员通过MetadataLoader作为Listener读取新增Raft日志,构造增量和全量元数据Image,通过MetadataPublisher将元数据更新到内存;
后续章节:
- 创建Topic在KRaft下如何实现;
- Share Group的实现;