文章目录
-
- 00|先上"全局图":把清洗从玄学变成流水线
- [01|去重:MinHash / SimHash 的工程思路(先消灭"重复毒药")](#01|去重:MinHash / SimHash 的工程思路(先消灭“重复毒药”))
-
- [1.1 两层去重策略(最稳)](#1.1 两层去重策略(最稳))
-
- [✅ MinHash(集合相似度,适合 shingle / n-gram)](#✅ MinHash(集合相似度,适合 shingle / n-gram))
- [✅ SimHash(指纹法,适合 web 文本/文档快速粗筛)](#✅ SimHash(指纹法,适合 web 文本/文档快速粗筛))
- 02|分段与结构化:把"长文本"变成"可学习样本"
-
- [2.1 切分最小粒度(工程必做)](#2.1 切分最小粒度(工程必做))
- [2.2 最小够用字段(建议你直接固定)](#2.2 最小够用字段(建议你直接固定))
- 03|规范化:统一口径,降低噪声(模型才不会学"脏习惯")
- 04|异常样本剔除:别把"垃圾"当数据量
- 05|脏词与格式纠错:把"合规风险"和"结构崩坏"扼杀在训练前
-
- [5.1 脏词 / 敏感信息(最小实践就够交付)](#5.1 脏词 / 敏感信息(最小实践就够交付))
- [5.2 格式纠错(结构化输出任务的生死线)](#5.2 格式纠错(结构化输出任务的生死线))
- [✅ 交付物 1:清洗管线脚本骨架(可直接落 repo)](#✅ 交付物 1:清洗管线脚本骨架(可直接落 repo))
- [✅ 交付物 2:数据 schema(训练/评测通用 JSONL)](#✅ 交付物 2:数据 schema(训练/评测通用 JSONL))
-
- [🧾 清洗验收门禁(建议贴 CI,不通过不准进训练)](#🧾 清洗验收门禁(建议贴 CI,不通过不准进训练))
- 📚参考资料(工程去重与近重复检测)
你做私训模型,最常见的幻觉是:"数据只要多就行。"
结果训出来:输出更像"复读机"、口径互相打架、离线评测虚高、上线直接翻车。
这篇只解决一个工程问题:把原始文本变成"可训练资产"。并且给你两份可交付的东西:
- ✅ 清洗管线脚本骨架(可扩展 / 可审计 / 可版本化)
- ✅ 数据 schema(训练 / 评测通用)
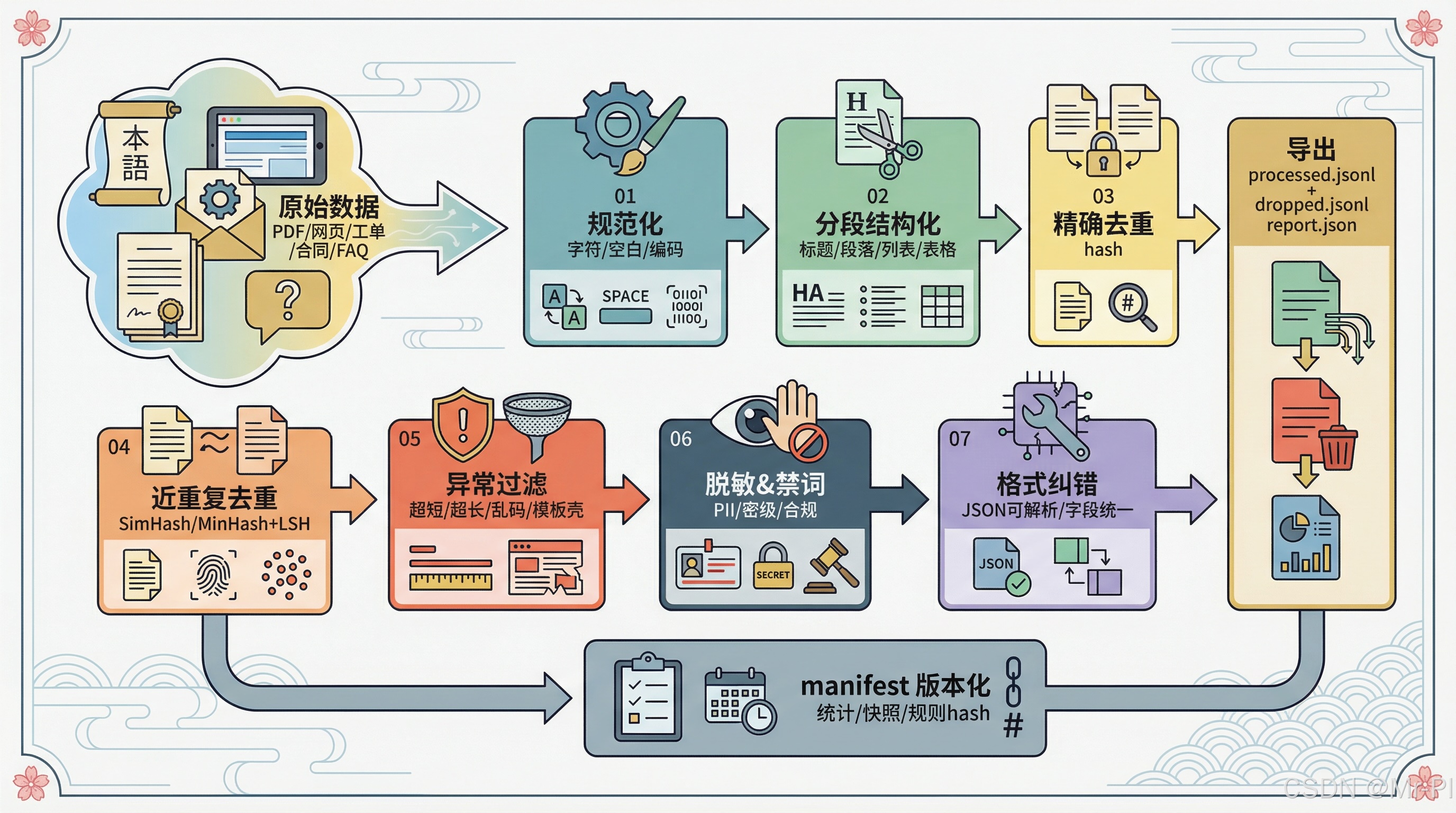
00|先上"全局图":把清洗从玄学变成流水线
你不缺"更多规则",你缺的是:每一步都能解释、能复跑、能产出报告。
原始数据
PDF/网页/工单/合同/FAQ
01 规范化
字符/空白/编码
02 分段结构化
标题/段落/列表/表格
03 精确去重
hash
04 近重复去重
SimHash/MinHash+LSH
05 异常过滤
超短/超长/乱码/模板壳
06 脱敏&禁词
PII/密级/合规
07 格式纠错
JSON可解析/字段统一
导出
processed.jsonl + dropped.jsonl + report.json
manifest 版本化
统计/快照/规则hash
01|去重:MinHash / SimHash 的工程思路(先消灭"重复毒药")
为什么要去重?
大规模语料天然带大量重复/近重复;不去重会导致:
- 训练浪费算力(同一句话喂一万遍)
- 输出更"复读机",甚至更容易"背答案"
- train/eval 污染:评测看起来很强,其实是泄漏
Hugging Face 在大规模去重实践里把动机说得很直:重复会带来训练数据"逐字输出"、隐私风险、以及评测污染;同时去重还能提升训练效率与可协作性。(Hugging Face)
FineWeb 的数据构建也专门讨论了不同去重策略/粒度对效果的影响,说明"去重不是可选项,而是配方的一部分"。
1.1 两层去重策略(最稳)
第一层:精确去重(Exact Dedup)
- 做法:对规范化后的文本 做
sha1/md5 - 目标:秒杀完全一样的样本(ROI 最高)
第二层:近重复去重(Near Dedup)
这里两把刀,各有分工:
✅ MinHash(集合相似度,适合 shingle / n-gram)
- 逻辑:切 shingles(词/字符 n-gram)→ MinHash 近似 Jaccard → LSH 召回候选 →(可选)再算真相似度做精裁
- 工程优势:可扩到百万/千万级,并且"可解释"(能看到重复簇)
这套流程在 Datasketch + LSH 的实践里讲得很清楚:shingling → minhash → LSH 召回候选对,再做校验。(Yury Kashnitsky)
✅ SimHash(指纹法,适合 web 文本/文档快速粗筛)
- 逻辑:把文档映射成 64-bit 指纹,相似文档的指纹在少量 bit上不同(海明距离小)
- 工程优势:指纹极小、比较极快,适合先粗筛
Google/Charikar 系列工作对 simhash 的描述很标准:它把高维特征压成小指纹,并利用"近重复只差少量 bit"的性质做高效检索。
⚡robin 实战建议(够用且稳)
- 语料 < 100 万:MinHash + LSH 直接上
- 语料更大、要更快:SimHash 粗筛 + MinHash 精筛(混合更稳)
02|分段与结构化:把"长文本"变成"可学习样本"
私有数据常见来源:PDF 解析、网页正文、会议纪要、合同条款、FAQ......最大问题是:
- 一条样本太长(训练效率差、激活炸)
- 结构太乱(标题/列表/表格混在一起)
- 信息密度不均(前面是目录,后面才是干货)
你要做的是:切成"片段 + 元信息" ,保证每段语义完整 + 可定位来源。
2.1 切分最小粒度(工程必做)
至少要分清:
title:标题/小节paragraph:自然段bullets:列表项(要保序)table:表格(转 Markdown 或抽成结构化字段)
切分目标不是"越碎越好",而是:一段能被模型学、也能被你追责。
2.2 最小够用字段(建议你直接固定)
title:标题/小节名content:清洗后的正文片段source:来源(doc_id/url/file/ticket_id)loc:定位(页码/段号/行号/时间戳/字符 span)tags:领域标签(可选)
03|规范化:统一口径,降低噪声(模型才不会学"脏习惯")
规范化做三件事,你就能超过 80% 的"只会堆数据"的团队:
- 字符规范:全角半角、空白折叠、不可见字符、异常换行
- 单位/格式统一:日期、金额、编号、版本号(企业文档高频雷区)
- 可控保留:标点/大小写/emoji 要不要保留------按任务目标定
⚡黄金句:
规范化不是"洗白一切",而是"让模型学你想让它学的部分"。
04|异常样本剔除:别把"垃圾"当数据量
异常样本不剔除,LoRA/QLoRA 很容易学出坏习惯(而且你还以为是"模型不行")。
常见异常:
- 超短:1--2 个词(信息密度过低)
- 超长:正文堆叠但无结构(训练慢、还污染上下文)
- 乱码/编码错误 :
�、不可见字符爆炸 - 高重复字符 :
哈哈哈哈哈/=====/0000000 - 模板壳:明显同模板替换变量(会把模型训成"模板机")
建议"规则 + 统计"组合拳:
- 规则:长度阈值、字符集比例、重复率阈值
- 统计:语言检测、重复簇密度、(可选)困惑度异常
05|脏词与格式纠错:把"合规风险"和"结构崩坏"扼杀在训练前
5.1 脏词 / 敏感信息(最小实践就够交付)
- PII:手机号/邮箱/证件号/精确地址 → 脱敏或替换占位符
- 内部密级:按授权与审计策略处理(最小权限)
- 业务禁词:你线上不能出现的表达(合规门禁)
关键点:脱敏不是"删掉就完事",要可审计(谁脱的、用的什么规则版本、命中哪些字段)。
5.2 格式纠错(结构化输出任务的生死线)
你要训练 JSON / 表格 / 固定模板输出:
清洗阶段必须保证:
- JSON 可解析
- 字段名统一(mapping 固定)
- 引号/逗号/换行稳定
否则模型会学到"半截 JSON",上线必炸。
✅ 交付物 1:清洗管线脚本骨架(可直接落 repo)
下面这个骨架的目标是:可扩展、可审计、可版本化(后面接 W&B、manifest、回归集冻结都很顺)。
目录建议
text
data-pipeline/
├── pipeline/
│ ├── 00_ingest.py
│ ├── 01_normalize.py
│ ├── 02_segment.py
│ ├── 03_dedup_exact.py
│ ├── 04_dedup_near_minhash.py
│ ├── 05_dedup_near_simhash.py
│ ├── 06_filter_anomalies.py
│ ├── 07_sanitize.py
│ ├── 08_format_fix.py
│ └── 99_export.py
├── configs/
│ └── pipeline.yaml
├── outputs/
│ ├── processed.jsonl
│ ├── dropped.jsonl
│ └── report.json
└── manifests/
└── data_manifest_v0.1.json核心接口(伪代码,按这个写就不会散)
python
# pipeline/core.py
from dataclasses import dataclass
from typing import Iterable, Dict, Any, List
@dataclass
class Record:
doc_id: str
source: str
loc: Dict[str, Any]
title: str
content: str
meta: Dict[str, Any]
def normalize(text: str) -> str:
# 全角半角、空白折叠、不可见字符清理、统一换行
...
def segment(rec: Record) -> List[Record]:
# 标题/段落/列表切分,并继承 doc_id/source/loc
...
def dedup_exact(records: Iterable[Record]) -> Iterable[Record]:
# hash(normalize(content)) 精确去重
...
def dedup_minhash(records: Iterable[Record]) -> Iterable[Record]:
# MinHash + LSH 近重复聚类/保留代表样本
...
def dedup_simhash(records: Iterable[Record]) -> Iterable[Record]:
# SimHash 指纹 + 海明距离阈值
...
def filter_anomalies(records: Iterable[Record]) -> Iterable[Record]:
# 长度/字符比例/重复字符/乱码/模板壳
...
def sanitize(records: Iterable[Record]) -> Iterable[Record]:
# PII 脱敏、禁词标注、敏感字段处理(可审计)
...
def format_fix(records: Iterable[Record]) -> Iterable[Record]:
# JSON 输出类任务:修复引号/逗号/字段名映射;标记不可修复样本
...去重实现落地时:MinHash+LSH 的工程路线(shingles → minhash → LSH → 候选对校验)可以直接参考 Datasketch 的实践讲解。(Yury Kashnitsky)
SimHash 的"指纹 + 海明距离检索"原理可参考经典 simhash/近重复检测论文。
✅ 交付物 2:数据 schema(训练/评测通用 JSONL)
清洗完的 processed.jsonl 建议统一成这套 schema(最小够用,后续可扩展到 SFT):
json
{
"id": "doc123#p07#seg03",
"doc_id": "doc123",
"source": "wiki_internal|ticket|pdf|url",
"loc": { "page": 7, "para": 3, "span": [120, 560] },
"title": "xx系统部署步骤",
"content": "(清洗规范化后的正文)",
"meta": {
"lang": "zh",
"created_at": "2026-02-10",
"license": "internal_authorized",
"pii_redacted": true,
"dedup": { "exact": false, "near": true, "method": "minhash", "cluster_id": "c_102" },
"quality": { "len": 420, "badword_hits": 0, "anomaly_flags": [] }
}
}如果你要直接用于指令微调(SFT),导出阶段再映射成:
instruction / input / output(或 chat 格式messages)
🧾 清洗验收门禁(建议贴 CI,不通过不准进训练)
- Exact dup 比例 < 5%(按数据源可调)
- Near dup 聚类后保留率合理(避免只剩模板壳)
- 语言/字符集异常样本占比 < 1%
- PII 脱敏覆盖率 100%(抽检)
- 结构化样本(JSON)可解析率 ≥ 99%
-
dropped.jsonl每条都有drop_reason(可审计) -
report.json输出:重复率、Top 重复簇、异常分布、修复成功率(让质量"可量化")
📚参考资料(工程去重与近重复检测)
- Hugging Face:大规模近重复去重动机与 MinHash/LSH 实战(BigCode)。(Hugging Face)
- FineWeb:在数据构建中系统讨论去重策略与粒度影响。
- SimHash/近重复检测:指纹法与海明距离检索的经典路线。
- Datasketch + LSH:MinHash-LSH 近重复检测的可落地流程。(Yury Kashnitsky)