目录
文章目录
- 目录
- [Prompt Engineering(提示词工程)](#Prompt Engineering(提示词工程))
- [LLM 输出配置](#LLM 输出配置)
- 提示词的类型
- 样本学习提示词的类型
-
- [零样本学习(Zero-shot Learning)提示词](#零样本学习(Zero-shot Learning)提示词)
- [单样本或少样本学习(Few-shot Learning)提示词](#单样本或少样本学习(Few-shot Learning)提示词)
- 负载推理提示词的类型
- 最佳实践
-
- 提供少量示例
- 使用简洁的大白话
- 使用指令而不是约束
- 通过约束来明确输出格式
- 使用提示词模版和变量嵌入
- [在程序化场景中使用 JSON 格式输出](#在程序化场景中使用 JSON 格式输出)
- 自动提示词工程(APE)
Prompt Engineering(提示词工程)
现在大多数 LLM 都是一个基于 Transformer Decoder-Only 架构的自回归 Token 预测引擎,它通过输入 Prompt(提示词)来触发开始进行预测。而 Prompt Engineering(提示词工程)则是设计和优化出高质量 Prompt 的一个过程,用来引导 LLM 预测出符合预期的结果。
感性的认识上,Prompt Engineering 能够让 LLM 更清晰理解用户的意图,并且返回更符合预期的结果。因此,Prompt Engineering 常被人称之为 "魔法咒语",它是一种将人类意图转化为 LLM 执行指令的翻译艺术。
如下图所示,Prompt Engineering 是一个体系化的工程技术,包括以下核心技术。

LLM 输出配置
大多数 LLM API(例如 OpenAI API)都会提供各种控制 LLM 输出的配置选项,包括:输出长度控制、输出采样控制等。
OpenAI API 示例:
bash
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello"}],
max_tokens=1000, # 最大输出长度
temperature=0.7, # 采样温度
top_p=1.0, # 核采样
frequency_penalty=0, # 频率惩罚
presence_penalty=0, # 存在惩罚
stop=["\n", "###"] # 停止序列
)输出长度控制
输出长度控制,即:LLM 在达到长度限制之后就会停止预测更多的 token。
这对 Agent 而言很重要,因为生成更多的 token 意味着更多的算力消耗、成本和生成时间,而且 LLM 生成有时候会特别的啰嗦,完全是无效的浪费。
长度控制参数:
- Max Length / Max Tokens:限制生成的最大 token 数量。
- Stop Sequences:遇到指定字符串时停止生成,如 "\n"、"###" 等。
输出采样控制
Decoder 的输出是一个基于词汇表的概率分布(Output Probabilities),表示词汇表中每个单词作为下一个输出单词的概率,并依据某种策略输出一个最可能的单词。
而这些可配置的策略就包括以下参数,它们控制如何对 Output Probabilities 进行采样,以确定下一个生成的 token 将是什么。
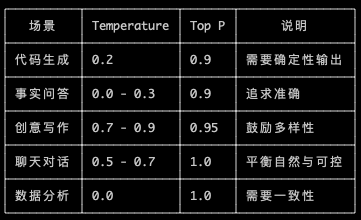
- Temperature :控制 token 选择中的随机程度,即:希望输出偏向随机性还是偏向创造性,范围在 0~10 不等。temperature 低值表示确定性高;而高值表示创造性高,可能导致更多样化或意外的结果。当 temperature==0 时,表示始终选择 Output Probabilities 最高的 token 输出。
- Nucleus sampling(核采样) :目的与 temperature 一样,可以控制 token 选择中的随机性和多样性。区别在于 Sampling 用于将下一个 token 限制在具有最高预测概率的 tokens 当中。
- Top-K:采样 Output Probabilities 中最高的 K 个 tokens,范围在 1~50 不等。数值越高就越有创造性和多样性;而越低则相反。
- Top-P:采样累计概率不超过 top_p 数值的 tokens,范围在 0~1 不等 。低值表示精确,高值表示多样。
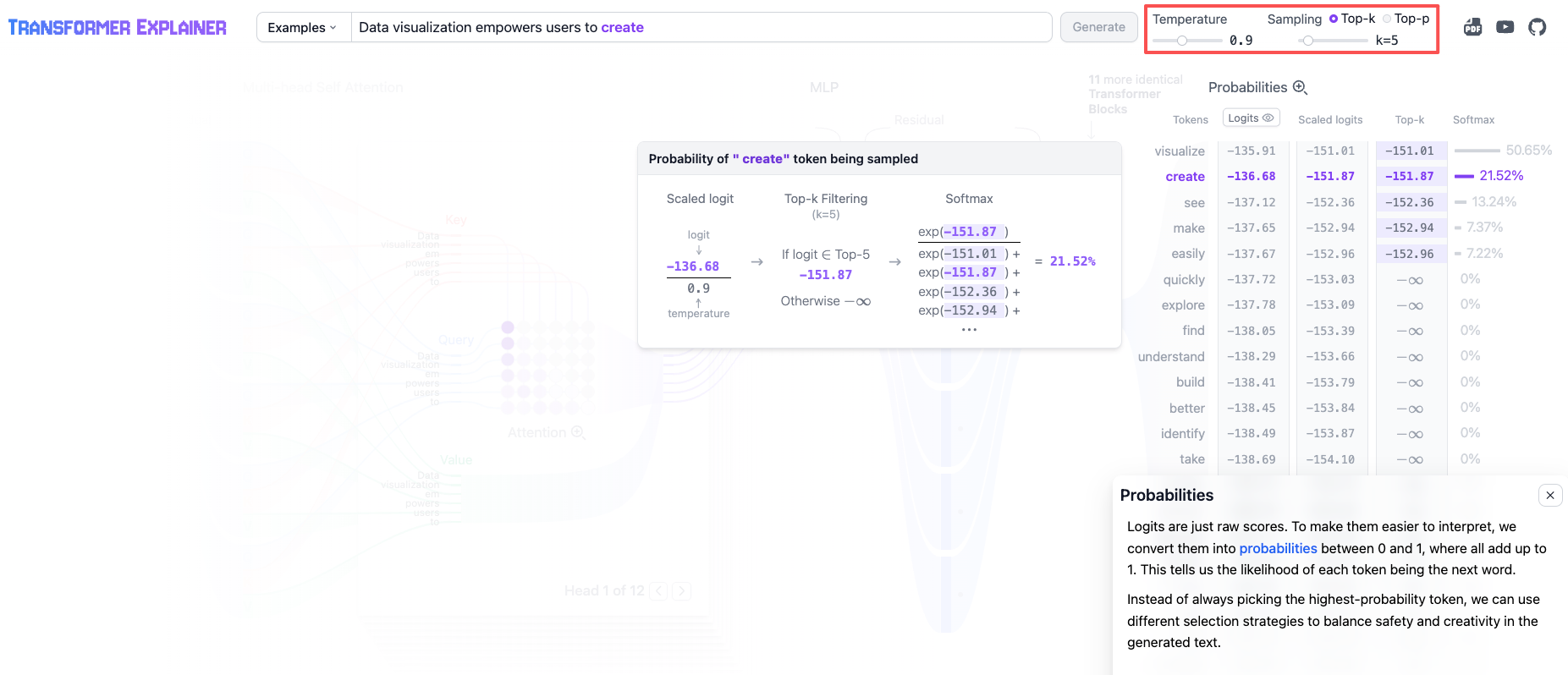
应用场景参考
提示词的类型
根据目的和作用的不同,可以将 Prompt 分为以下几种类型,LLM API 可以认识这些 Prompt 的类型,并且执行相应的操作。
- System Prompt:用于设置 LLM 的基本能力和总体目标,例如:翻译语言、代码编程等。这有助于 LLM 生成趋近于总体目标的内容。
- Role Prompt:用于设置 LLM 的角色身份,例如:编程专家、医生专家等。这有助于 LLM 在特定的领域内,应用和生成与其角色领域相关的知识。
- User Prompt:就是用户输入的原始 Prompt。
- Context Prompt:用于携带 User 和 LLM 当前对话的上下文历史、特定细节或相关信息,让 LLM 了解对话的背景,避免 "失忆" 问题。
样本学习提示词的类型
零样本学习(Zero-shot Learning)提示词
零样本学习(Zero-shot Learning)提示词是最简单的 Prompt,日常的 ChatBot 应用场景中,默认采用的就是 Zero-shot Learning Prompt。我们只需要输入问题的描述和一些文本,供 LLM 开始处理,而不需要为一个问题附加特定的示例。
GPT-2 追求的就是 Zero-shot Learning(零样本学习),即:默认情况下不需要向 LLM 提供任何示例,仅靠指令和 LLM 预训练知识进行推理,就足以支撑通用任务处理能力。但实际上,GPT-2 已经证明了这种方式的局限性。
单样本或少样本学习(Few-shot Learning)提示词
当零样本的输出不及预期时,我们应该考虑在 Prompt 中附加 1 个或几个示例,即:单样本或少样本学习(Few-shot Learning)提示词,就是在 Prompt 中提供少量(e.g. 1~5 个)示例。
这些示例帮助 LLM 理解你的要求,并进行模仿,继而输出与示例相似的结果。当你想要引导 LLM 输出特定的数据结构或模式时,示例尤其有用。如果效果还是不及预期,那么可以考虑添加更多的示例看看。
负载推理提示词的类型
思维链提示词
一般来说,LLM 对复杂问题的理解有难度,比如需要多步推理才能解决的问题。此时,可以使用思维链(Chain of Thought,CoT)来进行分步引导推理和回答。CoT 提示词是一种通过生成中间推理步骤来提高 LLM 推理能力的技术。在复杂推理场景中,CoT + Few-shot 有助于 LLM 生成更准确的答案。
CoT 更详细的内容请浏览论文:https://arxiv.org/pdf/2201.11903
一个触发 LLM 分步推理的最简单的 CoT Prompt 就是 "Let's think step by step",如下图所示。但此时的推理步骤受到采样控制参数的影响,可能表现出非一致性。
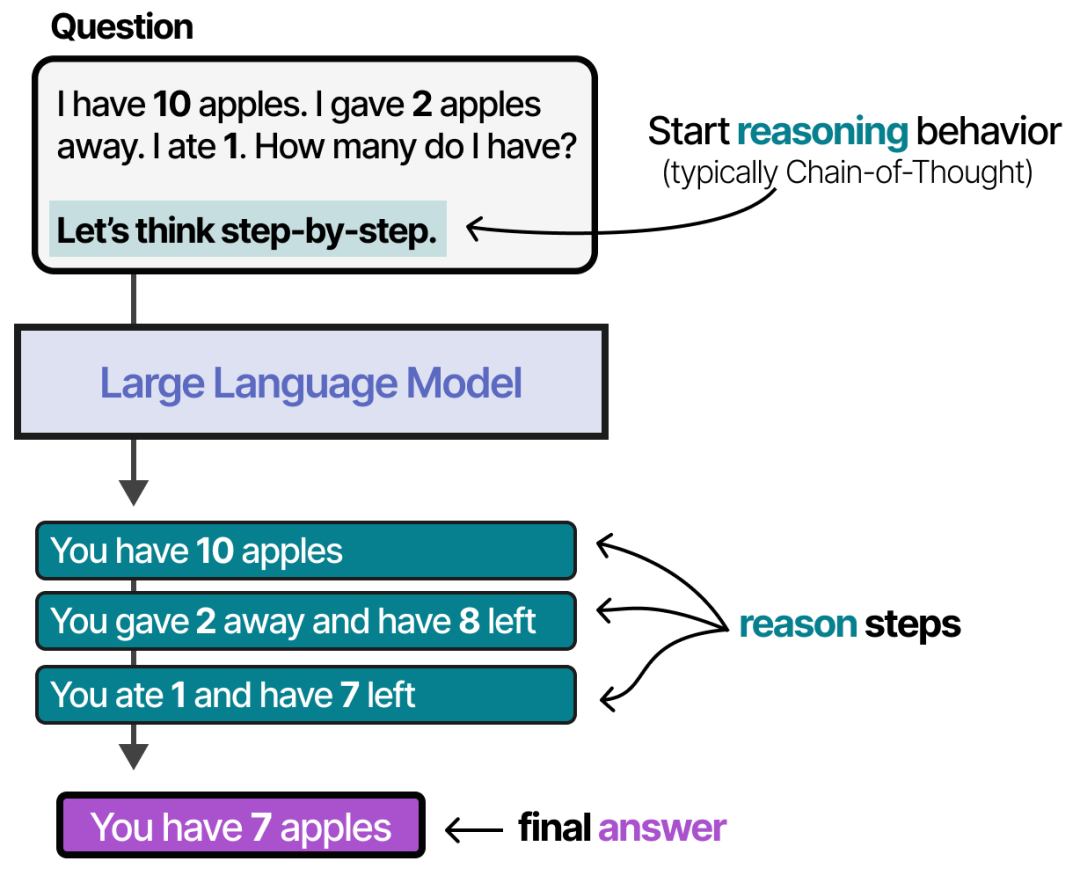
一个引导 LLM 分步推理的 CoT Prompt 如下,此时由于步骤的约束可以保持更好的一致性。
- 原子化拆解:将复杂问题分解为不可再分的子步骤。例如 "请逐步推理:首先...其次...因此..."。
- 显式占位符:用占位符(例如:___)引导 LLM 思考作答。
bash
预测未来 6 个月 AWS EC2 的 CPU/内存用量需求。
基于历史数据制定扩容方案,执行以下步骤:
3. **数据提取**:
- 来源:CloudWatch指标 → 关键指标名:`CPUUtilization`, `MemoryUsage`
- 时间范围:过去3个月,粒度:按周均值
4. **趋势计算**:
- CPU月均增长率:(本月均值 - 3月前均值)/ 3 = ___%
- 内存使用线性回归:`y = [斜率]x + [截距]` (x为月份)
5. **峰值预留**:
- 历史峰值CPU:___%(发生时间:___)→ 安全余量设置:___%
- 突发流量容忍:是否启用Auto Scaling? □是 □否
6. **实例选型**:
- 当前配置:m5.xlarge(4vCPU/16GB)
- 6个月后需求预测:CPU = __ vCPU, 内存 = __ GB → 建议型号:_____
7. **成本优化**:
- 预留实例覆盖率计算:___% → 建议新增预留实例数:___
- Spot实例适用场景:_____(如批处理任务) 一个带有单样本学习的 CoT Prompt 如下:
bash
# Prompt
Q: When my brother was 2 years old, I was double his age. Now I am 40 years old. How old is my brother? Let's think step by step.
A: When my brother was 2 years, I was 2 * 2 = 4 years old.That's an age difference of 2 years and I am older. Now I am 40 years old, so my brother is 40 - 2 = 38 years old. The answer is 38.
Q: When I was 3 years old, my partner was 3 times my age. Now,I am 20 years old. How old is my partner? Let's think step by step.
A:
# Output
When I was 3 years old, my partner was 3 * 3 = 9 years old. That's an age difference of 6 years and my partner is older. Now I am 20 years old, so my partner is 20 + 6 = 26 years old. The answer is 26.可见,使用 CoT Prompt 的优点如下:
- 适用于复杂推理场景。
- 可解释性:因为可以从 LLM 的 Step-by-Step 响应中查看推理步骤和每一步的执行结果。如果出现了非预期的输出,我们也能识别它。
- 可迁移性: CoT Prompt 对不同推理能力不同的 LLM 都适用。
另外,在一致性要求高的场景中,CoT Prompt 的 API 调用应该将 Temperature 设置为 0。
思维树提示词
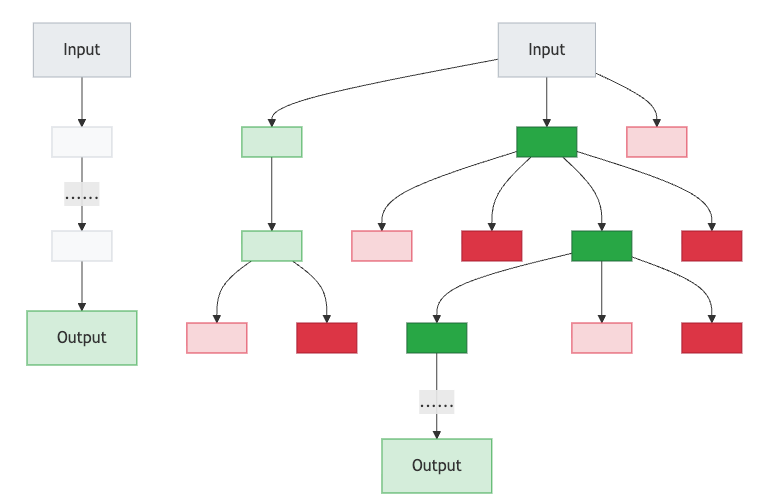
思维树(Tree of Thoughts,ToT)是 CoT 的变体。CoT 可以约束 LLM 的推理步骤,具有很好的输出一致性,但却缺少了多样性,ToT 则解决了这一点。
如下图所示,左边是 CoT,右边是 ToT。显然 ToT 会在每个 Step 中探索多个不同的推理路径(分支),而不仅仅是遵循单一的线性 CoT。这一特性使得 ToT 特别适合需要多样性探索的复杂任务。
最佳实践
提供少量示例
尽可能的采用单样本或少样本学习提示词,GPT-3 已经证明了其有效性。它就像一个强大的教学工具,展示了用户预期的输出或类似的响应,使 LLM 能够从中学习并相应地调整其生成的内容。这就像为 LLM 提供一个参考点或目标,以提高其响应的准确性、风格和语气,从而更好地满足你的期望。
使用简洁的大白话
尽量不要使用复杂的术语和语句,也不要提供不必要的信息,它可能也会使 LLM 感到困惑。
bash
# Good
我现在正在纽约旅行,想听听更多关于好地方的信息。我带着两个 3 岁的孩子。我们假期应该去哪里?
# Bad
充当游客的旅行指南。描述一下在纽约曼哈顿与 3 岁儿童一起游览的好地方。优先采用描述动作的动词。例如:充当、分析、分类、归类、对比、比较、创建、描述、定义、评估、提取、查找、生成、识别、列出、测量、组织、解析、选择、预测、提供、排序、推荐、返回、检索、重写、选择、显示、排序、总结、翻译、写作。
使用指令而不是约束
- 指令:提供有关响应的所需格式、样式或内容的明确说明。它指导模型应该做什么或产生什么。
- 约束:是对响应的一组限制或边界。它限制了模型不应该做什么或避免什么。
越来越多的研究表明,在 Prompt 中使用积极的指令可能比约束更有效。这种方法与人类喜欢积极的指令而不是约束相一致。指令直接传达期望的结果,而约束可能会让模型猜测允许做什么。
bash
# Good
生成一篇关于前 5 名视频游戏机的 1 段博客文章。只讨论游戏机、制造公司、年份和总销量。
# Bad
生成一篇关于前 5 名视频游戏机的 1 段博客文章。不要列出视频游戏名称。通过约束来明确输出格式
在某些情况下,约束仍然有效,例如:幻觉抑制、防止生成有害或有偏见的内容,或者严格要求输出格式或样式时。
- 角色扮演:让 LLM 扮演特定角色,如:你是一位资深营养师,为健身人设计食谱。
- 输出样本学习:在 Prompt 中提供输入和输出的样本,如:根据以下合同条款回答问题:示例。
- 格式化输出:强制要求以 Markdown、JSON、YAML 等格式输出。
- 幻觉抑制:强制要求基于已知信息回答、不会就说不会,并标注不确定内容。
格式化输出示例:
bash
请从以下会议记录中提取所有待办事项,要求:
1. 每条任务以 "负责人:任务内容(截止时间)" 格式输出
2. 仅输出事项,不添加解释。
3. 若无明确时间则标注 "待确认"。
会议记录:[粘贴记录文本]使用提示词模版和变量嵌入
为了 Prompt 的可复用性,许多 Agent 框架都会提供 PromptTemplate 模版功能,支持形参变量的嵌入和实参的传递。
bash
# Prompt
VARIABLES
{city} = "Amsterdam"
PROMPT
You are a travel guide. Tell me a fact about the city:
# Output
Amsterdam is a beautiful city full of canals, bridges, and narrow streets. It's a great place to visit for its rich history, culture, and nightlife.在程序化场景中使用 JSON 格式输出
在 Agent 此类的程序化场景中,尽量使用统一的 JSON 格式输出。具有以下好处:
- 始终以相同的 JSON 格式返回。
- 方便程序使用 JSON Schema 进行数据解析和处理。
- 减少幻觉的可能性。
但需要注意的是,JSON 的冗长性很容易消耗掉整个输出窗口。由于 token 长度限制会让 JSON 数据结构被截断,进而造成程序化解析失败。对此可以使用 PyPI json-repair 库进行 JSON 格式修复。
自动提示词工程(APE)
自动提示词工程(APE)是一种通过 LLM 来自动化生成 Prompt,再有人类来进行评估的工程实践方法。
实际上,现在不仅仅是 Prompt,连 SFT 微调大模型的 Dataset 都可以采用自动化的方式进行生产。一个例子:
bash
# Prompt
We have a band merchandise t-shirt webshop, and to train a chatbot we need various ways to order: "One Metallica t-shirt size S". Generate 10 variants, with the same semantics but keep the same meaning.
# Output
1. I'd like to purchase a Metallica t-shirt in size small.
2. Can I order a small-sized Metallica t-shirt?
3. I'd like to buy one Metallica t-shirt in small.
4. One Metallica shirt, size small, please.
5. I want one Metallica t-shirt in size small.
6. I'd like to place an order for one Metallica t-shirt in small.
7. Small Metallica t-shirt, one please.
8. I'm looking for one Metallica t-shirt in small.
9. Can you get me one Metallica t-shirt in small?
10. One Metallica small t-shirt, please.