目录
[ReAct-Loop 核心实现要点](#ReAct-Loop 核心实现要点)
ReActAgent
ReAct 是一种智能体设计模式,它在迭代循环中结合了推理(思考与规划)和行动(工具执行)两个环节。智能体会在这两个阶段之间交替执行,直到完成任务或达到最大迭代次数限制。
关键特性:
-
响应式流处理:基于 Project Reactor 实现非阻塞执行
-
钩子系统:可扩展的钩子机制,用于监控和拦截智能体的执行过程
-
人机协同支持:通过 PostReasoningEvent/PostActingEvent 事件中的 stopAgent() 方法实现人在回路(HITL)
-
结构化输出:StructuredOutputCapableAgent 提供类型安全的输出生成能力
我们本篇内容将围绕上述关键特性展开梳理。
java
import io.agentscope.core.ReActAgent;
import io.agentscope.core.model.DashScopeChatModel;
import io.agentscope.core.message.Msg;
// 创建智能体并内联配置模型
ReActAgent agent = ReActAgent.builder()
.name("Assistant")
.sysPrompt("你是一个有帮助的 AI 助手。")
.model(DashScopeChatModel.builder()
.apiKey(System.getenv("DASHSCOPE_API_KEY"))
.modelName("qwen3-max")
.build())
.build();
Msg response = agent.call(Msg.builder()
.textContent("你好!")
.build()).block();
System.out.println(response.getTextContent());分析源码时,由外到内。我们先看一切的开始call方法是如何打通与模型的交互?
AgentBase-call------一切的入口
在AgentBase中call方法
java
/**
* 智能体核心调用方法,处理输入消息列表并生成响应
* 特性:
* 1. 线程安全:通过 CAS 操作保证同一时间只有一个调用执行
* 2. 链路追踪:集成遥测系统捕获调用链路数据
* 3. 钩子机制:执行前后置钩子函数,支持扩展
* 4. 异常处理:统一的异常恢复策略,保证执行状态一致性
* 5. 响应式:基于 Project Reactor 实现非阻塞异步处理
* @param msgs 输入消息列表(用户/系统消息)
* @return 包装响应消息的 Mono 异步对象
*/
@Override
public final Mono<Msg> call(List<Msg> msgs) {
// 1. 线程安全检查:通过 CAS 原子操作尝试将运行状态从 false 置为 true
// checkRunning 为开关,若开启则防止并发调用,避免资源冲突
if (!running.compareAndSet(false, true) && checkRunning) {
// 并发调用时返回 IllegalStateException 异常
return Mono.error(
new IllegalStateException(
"Agent is still running, please wait for it to finish"));
}
// 2. 重置中断标志位:清除之前可能的中断状态,保证本次调用干净执行
// 方法体:interruptFlag.set(false); userInterruptMessage.set(null);
resetInterruptFlag();
// 3. 核心执行流程:集成链路追踪 + 钩子回调 + 异常处理 + 最终状态重置
return TracerRegistry.get()
// 开启智能体调用的链路追踪,捕获调用元数据
.callAgent(
this, // 当前智能体实例
msgs, // 输入消息列表
// 核心执行逻辑(Supplier 函数式接口)
() ->
// 3.1 执行调用前钩子:通知监听器调用开始(如日志、埋点)
notifyPreCall(msgs)
// 3.2 执行真正的业务逻辑(核心消息处理)
.flatMap(this::doCall)
// 3.3 执行调用后钩子:通知监听器调用完成(如结果处理、资源清理)
.flatMap(this::notifyPostCall)
// 3.4 异常恢复:捕获上游所有异常,使用自定义处理器处理
.onErrorResume(
createErrorHandler(msgs.toArray(new Msg[0]))))
// 4. 最终操作:无论调用成功/失败/取消,都重置运行状态为 false,释放执行权限
.doFinally(signalType -> running.set(false));
}这个TracerRegistry.get()将返回个 Trace对象,call内部是直接执行 函数式内容。
java
default Mono<Msg> callAgent(
AgentBase instance, List<Msg> inputMessages, Supplier<Mono<Msg>> agentCall) {
return agentCall.get();
}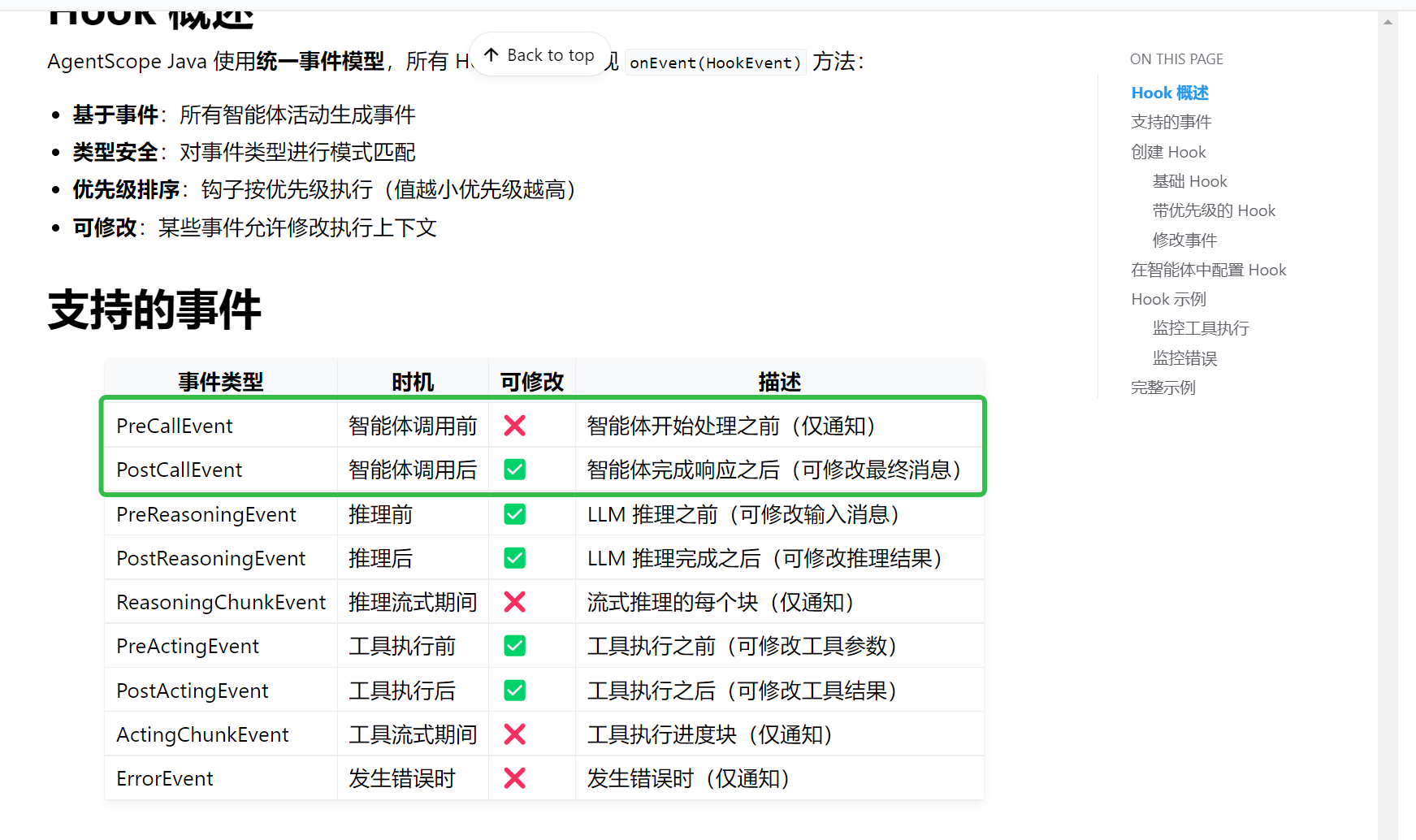
在官网中能够看到智能体调用前后的处理是基于Event
我们直观的能看出来,这俩方法的内部肯定是获取相关类型的事件对象,并执行。
java
/**
* 通知所有钩子函数:智能体即将开始执行(preCall 前置钩子)。
*
* <p>钩子函数可通过 {@link PreCallEvent#setInputMessages(List)} 方法修改输入消息。
* 所有钩子按排序后的顺序串行执行,每个钩子接收的事件对象会包含前一个钩子修改后的结果。
*
* @param msgs 原始输入消息列表(未经过钩子处理)
* @return 包装处理后消息列表的 Mono 对象(消息可能被钩子修改)
*/
private Mono<List<Msg>> notifyPreCall(List<Msg> msgs) {
// 1. 创建前置调用事件对象:封装当前智能体实例和原始输入消息
PreCallEvent event = new PreCallEvent(this, msgs);
// 2. 初始化响应式流:将事件对象包装为 Mono,作为钩子执行的起点
Mono<PreCallEvent> result = Mono.just(event);
// 3. 遍历排序后的钩子列表(按优先级/注册顺序),串行执行每个钩子的 onEvent 方法
// 注:flatMap 保证前一个钩子执行完成后,再执行下一个,实现串行处理
for (Hook hook : getSortedHooks()) {
result = result.flatMap(hook::onEvent);
}
// 4. 提取最终处理后的消息列表:将事件对象转换为消息列表返回
// map 操作仅做数据转换,不改变响应式流的执行逻辑
return result.map(PreCallEvent::getInputMessages);
}
java
/**
* 通知所有钩子函数智能体调用已完成(postCall 后置钩子)。
* <p>核心逻辑:
* 1. 校验最终响应消息的合法性,避免空消息流转
* 2. 创建后置调用事件并触发所有钩子的串行执行
* 3. 钩子执行完成后,将最终消息广播给所有订阅者
* 4. 保证响应式流的完整性,返回处理后的最终消息
*
* @param finalMsg 智能体处理完成后的最终响应消息(非空)
* @return 包装了「可能被钩子修改后的最终消息」的 Mono 异步对象
* @throws IllegalStateException 当传入的 finalMsg 为 null 时抛出该异常,阻断后续流程
*/
private Mono<Msg> notifyPostCall(Msg finalMsg) {
// 1. 前置校验:防止空消息进入后续流程,保证消息流转的合法性
if (finalMsg == null) {
return Mono.error(new IllegalStateException("Agent returned null message"));
}
// 2. 创建后置调用事件对象:封装当前智能体实例和最终响应消息
PostCallEvent event = new PostCallEvent(this, finalMsg);
// 3. 初始化响应式流:将事件对象包装为 Mono,作为钩子执行的起点
Mono<PostCallEvent> result = Mono.just(event);
// 4. 串行执行所有钩子:按优先级/注册顺序遍历钩子列表,保证钩子执行的有序性
// flatMap 确保前一个钩子执行完成后,再执行下一个钩子,避免并发修改事件
for (Hook hook : getSortedHooks()) {
result = result.flatMap(hook::onEvent);
}
// 5. 核心处理链:【链式修改哦】
// - map:从执行完所有钩子的事件中提取最终消息(可能被钩子修改)
// - flatMap:先将消息广播给所有订阅者,广播完成后返回原消息
// - thenReturn:保证广播操作完成后,最终返回处理后的消息对象
return result.map(PostCallEvent::getFinalMessage)
.flatMap(msg -> broadcastToSubscribers(msg).thenReturn(msg));
}震惊!他竟然在这里进行区分了!
hook的onEvent是需要传参的,但这里因为result的类型是PreCallEvent,在每个Hook中所做的事情是根据当前的Event类型进行处理,利用instanceof。比如下例:
java
import io.agentscope.core.hook.Hook;
import io.agentscope.core.hook.HookEvent;
import io.agentscope.core.hook.PreCallEvent;
import io.agentscope.core.hook.PostCallEvent;
import reactor.core.publisher.Mono;
public class LoggingHook implements Hook {
@Override
public <T extends HookEvent> Mono<T> onEvent(T event) {
if (event instanceof PreCallEvent) {
System.out.println("智能体启动: " + event.getAgent().getName());
return Mono.just(event);
}
if (event instanceof PostCallEvent) {
System.out.println("智能体完成: " + event.getAgent().getName());
return Mono.just(event);
}
return Mono.just(event);
}
}我们能看出来他是如何操作的了。简要总结下当前分析的内容:
-
异步编程最佳实践:基于 Reactor 的 Mono 实现异步流处理,通过
flatMap/doFinally/onErrorResume保证流程的健壮性 -
可扩展架构设计:通过「钩子+事件」模式实现核心逻辑与扩展逻辑的解耦,符合开闭原则
-
线程安全实现:利用 CAS 原子操作替代锁机制,降低并发调用的性能开销
-
异常处理设计:统一的异常恢复策略(
onErrorResume)保证异常场景下的状态一致性,避免智能体卡死
-
ReActAgent 基础调用流程:从
agent.call()入口到最终返回响应的完整链路 -
AgentBase 中
call()方法的核心实现:-
- 线程安全保障:通过 CAS 操作(
running.compareAndSet)防止并发调用
- 线程安全保障:通过 CAS 操作(
-
- 状态重置:执行前清除中断标志位(
resetInterruptFlag())
- 状态重置:执行前清除中断标志位(
-
- 核心执行链路:链路追踪(TracerRegistry)→ 前置钩子(notifyPreCall)→ 业务逻辑(doCall)→ 后置钩子(notifyPostCall)→ 异常兜底(onErrorResume)
-
- 最终清理:通过
doFinally重置运行状态,释放执行权限
- 最终清理:通过
-
-
钩子系统(Hook)的核心机制:
-
- 事件驱动:基于
PreCallEvent/PostCallEvent等事件对象传递上下文
- 事件驱动:基于
-
- 串行执行:钩子按优先级排序,通过
flatMap保证顺序执行
- 串行执行:钩子按优先级排序,通过
-
- 动态适配:Hook 接口通过
instanceof判断事件类型,实现不同事件的差异化处理
- 动态适配:Hook 接口通过
-
基于上述内容,我们大致先了解钩子系统的机理,在代码中我们关注到Trace!
在AI原生应用开发中,可观测是治理、评估、调试智能体的最大要素。接下来我们优先看看Trace
Trace------可观测
java
package io.agentscope.core.tracing;
import org.reactivestreams.Subscription;
import reactor.core.CoreSubscriber;
import reactor.core.publisher.Hooks;
import reactor.core.publisher.Operators;
import reactor.util.context.Context;
/**
* 全局 {@link Tracer} 实例的注册表。
* <p>
* <b>Reactor 全局钩子:</b> 此类提供了启用或禁用全局 Reactor
* 钩子的方法(通过 {@link #enableTracingHook()} 和 {@link #disableTracingHook()}),
* 用于在 Reactor 操作符之间传播追踪上下文。启用此钩子会影响 JVM 中的
* <i>所有</i> Reactor 操作,即使对于与追踪无关的代码也可能产生性能影响。
* 请谨慎使用,仅在需要为所有 Reactor 管道传播追踪上下文时才启用此钩子。
*/
public class TracerRegistry {
private static final String HOOK_KEY = "agentscope-trace-context";
private static volatile boolean hookEnabled = false;
/**
* 启用用于追踪上下文传播的全局 Reactor 钩子。
* <p>
* <b>机制:</b> 此方法使用 {@link Hooks#onEachOperator(String, Function)}
* 注册一个全局钩子,该钩子会拦截 {@code Flux} 和 {@code Mono}
* 链中涉及的 <i>每个</i> Reactor 操作符创建。它包装了 {@code Subscriber},
* 确保下游信号({@code onNext}、{@code onError}、{@code onComplete})
* 在组装时捕获的追踪上下文中或从上游获取的追踪上下文中处理。
* <p>
* <b>激活:</b> 调用此方法后,钩子立即激活。
* 它会影响 JVM 中随后组装的所有 Reactor 流。
* <p>
* <b>性能:</b> 启用此钩子会为应用程序中的每个 Reactor 操作符引入开销,
* 即使是与 AgentScope 追踪无关的操作符。它涉及对象分配(包装订阅者)
* 和上下文捕获/恢复。
* 仅当需要跨异步边界自动传播上下文时才应启用它。
* <p>
* 此方法可以安全地多次调用;钩子只会注册一次。
*/
public static synchronized void enableTracingHook() {
if (!hookEnabled) {
Hooks.onEachOperator(
HOOK_KEY,
Operators.lift(
(scannable, subscriber) ->
new CoreSubscriber<Object>() {
@Override
public void onSubscribe(Subscription s) {
subscriber.onSubscribe(s);
}
@Override
public void onNext(Object o) {
TracerRegistry.get()
.runWithContext(
subscriber.currentContext(),
() -> {
subscriber.onNext(o);
return null;
});
}
@Override
public void onError(Throwable t) {
TracerRegistry.get()
.runWithContext(
subscriber.currentContext(),
() -> {
subscriber.onError(t);
return null;
});
}
@Override
public void onComplete() {
TracerRegistry.get()
.runWithContext(
subscriber.currentContext(),
() -> {
subscriber.onComplete();
return null;
});
}
@Override
public Context currentContext() {
return subscriber.currentContext();
}
}));
hookEnabled = true;
}
}
/**
* 禁用用于追踪上下文传播的全局 Reactor 钩子。
* 此方法会移除 JVM 中所有 Reactor 操作符的钩子。
*/
public static synchronized void disableTracingHook() {
if (hookEnabled) {
Hooks.resetOnEachOperator(HOOK_KEY);
hookEnabled = false;
}
}
private static volatile Tracer tracer = new NoopTracer();
public static void register(Tracer tracer) {
TracerRegistry.tracer = tracer;
if (tracer instanceof NoopTracer) {
disableTracingHook();
} else {
enableTracingHook();
}
}
public static Tracer get() {
return tracer;
}
}
java
package io.agentscope.core.tracing;
import io.agentscope.core.agent.AgentBase;
import io.agentscope.core.formatter.AbstractBaseFormatter;
import io.agentscope.core.message.Msg;
import io.agentscope.core.message.ToolResultBlock;
import io.agentscope.core.model.ChatModelBase;
import io.agentscope.core.model.ChatResponse;
import io.agentscope.core.model.GenerateOptions;
import io.agentscope.core.model.ToolSchema;
import io.agentscope.core.tool.ToolCallParam;
import io.agentscope.core.tool.Toolkit;
import java.util.List;
import java.util.function.Supplier;
import reactor.core.publisher.Flux;
import reactor.core.publisher.Mono;
import reactor.util.context.ContextView;
public interface Tracer {
default Mono<Msg> callAgent(
AgentBase instance, List<Msg> inputMessages, Supplier<Mono<Msg>> agentCall) {
return agentCall.get();
}
default Flux<ChatResponse> callModel(
ChatModelBase instance,
List<Msg> inputMessages,
List<ToolSchema> toolSchemas,
GenerateOptions options,
Supplier<Flux<ChatResponse>> modelCall) {
return modelCall.get();
}
default Mono<ToolResultBlock> callTool(
Toolkit toolkit,
ToolCallParam toolCallParam,
Supplier<Mono<ToolResultBlock>> toolKitCall) {
return toolKitCall.get();
}
default <TReq, TResp, TParams> List<TReq> callFormat(
AbstractBaseFormatter<TReq, TResp, TParams> formatter,
List<Msg> msgs,
Supplier<List<TReq>> formatCall) {
return formatCall.get();
}
default <TResp> TResp runWithContext(ContextView reactorCtx, Supplier<TResp> inner) {
return inner.get();
}
}Tracer 是 AgentScope 框架中可观测性体系的核心接口,为智能体执行全链路(智能体调用、模型调用、工具调用、格式转换)提供统一的追踪能力,同时基于 Reactor 响应式框架实现追踪上下文的跨异步边界传播,是实现「可观测性」(监控、日志、链路追踪、性能分析)的基础组件。
核心功能拆解
- 全链路调用埋点:覆盖智能体执行核心环节。Tracer 接口定义了智能体生命周期中 4 个核心环节的追踪入口,默认直接执行业务逻辑,支持子类扩展实现自定义追踪逻辑:
|----------------|-----------------------------|-----------------------------------|
| 方法名 | 追踪场景 | 核心作用 |
| callAgent | 智能体调用(AgentBase.call) | 追踪智能体整体调用过程(输入消息、执行耗时、返回结果、异常信息) |
| callModel | 大模型调用(ChatModelBase) | 追踪模型交互细节(请求参数、响应内容、token 消耗、调用耗时) |
| callTool | 工具调用(Toolkit) | 追踪工具执行过程(工具名称、入参、执行结果、异常信息) |
| callFormat | 格式转换(AbstractBaseFormatter) | 追踪消息格式转换过程(原始消息、转换后数据、格式校验结果) |
| runWithContext | 上下文传播 | 保证追踪上下文在 Reactor 异步流中正确传递,避免上下文丢失 |
-
追踪上下文传播:跨异步边界的上下文保障。通过 TracerRegistry 实现全局 Reactor 钩子管理,解决异步场景下追踪上下文丢失问题:
-
启用钩子(enableTracingHook):
-
注册全局 Reactor 钩子,拦截所有 Flux/Mono 操作符的创建;
-
包装 CoreSubscriber,在 onNext/onError/onComplete 等信号处理时,通过
runWithContext恢复追踪上下文; -
确保异步执行的每个环节都能获取到完整的追踪上下文(如 traceId、spanId)。
-
-
禁用钩子(disableTracingHook):
- 移除全局钩子,恢复 Reactor 原生执行逻辑,降低非追踪场景下的性能开销。
-
-
灵活的追踪实现扩展
-
默认实现(NoopTracer):空实现,所有方法直接执行业务逻辑,无任何追踪开销,作为框架默认配置;
-
扩展能力:用户可通过实现 Tracer 接口,对接 SkyWalking、Zipkin、Jaeger 等主流链路追踪系统,或自定义日志/监控埋点;
-
动态切换:通过 TracerRegistry.register() 方法动态注册 Tracer 实现类,注册非 NoopTracer 时自动启用上下文传播钩子,注册 NoopTracer 时自动禁用钩子,兼顾灵活性与性能。
-
-
无侵入设计:通过「接口默认方法 + 钩子拦截」实现追踪能力,无需修改智能体/模型/工具的核心业务代码;
-
性能可控:追踪上下文传播钩子可动态启停,非追踪场景下禁用钩子,避免不必要的性能开销;
-
全链路覆盖:从智能体调用到模型/工具执行,再到格式转换,实现端到端的追踪覆盖;
-
响应式适配:深度结合 Reactor 响应式框架,解决异步流中上下文传播的核心痛点。
典型使用场景
-
链路追踪:扩展 Tracer 实现类,在 callAgent/callModel/callTool 中创建 span,记录各环节耗时、入参、出参,实现智能体执行链路可视化;
-
日志增强:在追踪方法中添加日志埋点,为日志补充 traceId/spanId,实现日志与链路的关联分析;
-
性能监控:统计各环节执行耗时,上报至监控系统(如 Prometheus),实现智能体执行性能的实时监控;
-
异常定位:在 onError 处理中记录异常信息与追踪上下文,快速定位智能体/模型/工具调用的异常根因。
默认实现-源码中提供的。
java
public class NoopTracer implements Tracer {}doCall------ReAct-Loop如何实现?
java
/** from AgentBase.java
* 处理多输入消息的内部实现逻辑。
* 子类必须在此实现自身的特定业务逻辑。
*
* @param msgs 输入消息列表
* @return 响应消息(异步对象)
*/
protected abstract Mono<Msg> doCall(List<Msg> msgs);
java
@Override
protected Mono<Msg> doCall(List<Msg> msgs) {
Set<String> pendingIds = getPendingToolUseIds();
// No pending tools -> normal processing
if (pendingIds.isEmpty()) {
addToMemory(msgs);
// 执行循环,进行推理。
return executeIteration(0);
}
// Has pending tools -> validate and add tool results
// 当存在待处理的工具调用时验证输入消息,然后添加到内存中。
validateAndAddToolResults(msgs, pendingIds);
return hasPendingToolUse() ? acting(0) : executeIteration(0);
}如何行动?
java
/**
* 执行行动阶段。
*
* <p>此方法仅执行待处理的工具(内存中没有结果的工具),
* 为成功的工具结果通知钩子,并决定是继续迭代
* 还是返回(HITL停止、工具挂起或结构化输出)。
*
* <p>对于抛出{@link io.agentscope.core.tool.ToolSuspendException}的工具:
* <ul>
* <li>异常被Toolkit捕获并转换为待处理的ToolResultBlock</li>
* <li>成功的结果存储在内存中,待处理的结果不存储</li>
* <li>返回带有{@link GenerateReason#TOOL_SUSPENDED}的Msg,包含被挂起的ToolUseBlocks</li>
* </ul>
*
* @param iter 当前迭代次数
* @return 包含最终结果消息的Mono
*/
private Mono<Msg> acting(int iter) {
// 1. 提取待处理的工具调用:仅筛选内存中无执行结果的ToolUseBlock
// 从最近的助手消息中仅提取待处理的工具调用(内存中没有结果的调用)。
List<ToolUseBlock> pendingToolCalls = extractPendingToolCalls();
// 2. 边界判断:无待处理工具时,直接进入下一轮迭代(推理+行动循环)
if (pendingToolCalls.isEmpty()) {
// 没有待执行的工具,继续执行下一次迭代
return executeIteration(iter + 1);
}
// 3. 配置流式工具响应的分片回调:用于实时通知工具执行的流式输出(如大模型流式返回)
// 注:subscribe() 触发回调执行,保证分片消息能实时处理
toolkit.setChunkCallback((toolUse, chunk) -> notifyActingChunk(toolUse, chunk).subscribe());
// 4. 核心执行链路:前置钩子 → 执行工具 → 结果处理 → 决策下一步行为
// 仅执行内存中无结果的待处理工具
return notifyPreActingHooks(pendingToolCalls) // 4.1 触发行动阶段前置钩子(如日志、参数校验)
.flatMap(this::executeToolCalls) // 4.2 执行筛选后的待处理工具调用
.flatMap(
results -> {
// 5. 结果分类:拆分成功执行的工具结果 和 挂起的工具结果
// 成功结果:工具正常执行完成,无挂起
// 挂起结果:工具抛出ToolSuspendException,执行中断
List<Map.Entry<ToolUseBlock, ToolResultBlock>> successPairs =
results.stream()
.filter(e -> !e.getValue().isSuspended())
.toList();
List<Map.Entry<ToolUseBlock, ToolResultBlock>> pendingPairs =
results.stream()
.filter(e -> e.getValue().isSuspended())
.toList();
// 6. 分支1:无成功结果的情况
if (successPairs.isEmpty()) {
// 6.1 有挂起结果 → 构建包含挂起信息的响应消息
if (!pendingPairs.isEmpty()) {
return Mono.just(buildSuspendedMsg(pendingPairs));
}
// 6.2 无挂起结果 → 继续下一轮迭代
return executeIteration(iter + 1);
}
// 7. 分支2:有成功结果的情况 → 处理成功结果并决策下一步
// 7.1 流式处理所有成功结果:触发后置钩子 + 将结果存入内存
// 7.2 last() 确保所有结果处理完成后,取最后一个事件做最终决策
return Flux.fromIterable(successPairs)
.concatMap(this::notifyPostActingHook) // 触发每个成功结果的后置钩子
.last()
.flatMap(
event -> {
// 8. 决策逻辑1:HITL人工干预停止(或结构化输出完成触发)
// 通过事件中的stopRequested标志判断是否需要终止智能体
if (event.isStopRequested()) {
return Mono.just(
event.getToolResultMsg()
.withGenerateReason(
GenerateReason
.ACTING_STOP_REQUESTED));
}
// 9. 决策逻辑2:存在挂起结果 → 构建挂起响应消息返回
if (!pendingPairs.isEmpty()) {
return Mono.just(
buildSuspendedMsg(pendingPairs));
}
// 10. 决策逻辑3:无停止请求且无挂起结果 → 继续下一轮迭代
return executeIteration(iter + 1);
});
});
}我们看到了亲切的老朋友,Hook机制,不过我们可以心领神会。优先看别的内容了。
怎么实现人机交互的?
当事件中工具调用的结果存在终止智能体的标识时,会直接打断循环。并将原因携带到其元数据中。
怎么恢复?
这里框架中没有给出相关存储,需要开发者自行处理。按照道理看,应是采用智能体结束的事件方案。
如何循环?
java
private Mono<Msg> executeIteration(int iter) {
return reasoning(iter, false);
}
/**
* 执行推理阶段。
*
* <p>此方法从模型流式获取输出,累积块,通知钩子,并
* 决定是继续执行行动阶段还是提前返回(HITL停止、跳转到推理或完成)。
*
* @param iter 当前迭代次数
* @param ignoreMaxIters 如果为true,跳过maxIters检查(用于gotoReasoning)
* @return 包含最终结果消息的Mono
*/
private Mono<Msg> reasoning(int iter, boolean ignoreMaxIters) {
// 1. 最大迭代次数校验:除非忽略校验,否则达到上限时直接进入总结阶段
// 防止智能体无限迭代,保证执行边界
if (!ignoreMaxIters && iter >= maxIters) {
return summarizing();
}
// 2. 初始化推理上下文:存储流式输出的累积结果、模型响应块等状态信息
ReasoningContext context = new ReasoningContext(getName());
// 3. 核心推理链路:中断检查 → 前置钩子 → 模型流式调用 → 结果处理 → 分支决策
return checkInterruptedAsync() // 3.1 异步检查是否存在外部中断请求(HITL干预)
.then(notifyPreReasoningEvent(prepareMessages())) // 3.2 触发推理前置钩子,预处理输入消息
.flatMapMany(
event -> {
// 3.3 构建模型生成配置:优先使用事件中自定义的配置,否则使用默认配置
GenerateOptions options =
event.getEffectiveGenerateOptions() != null
? event.getEffectiveGenerateOptions()
: buildGenerateOptions();
// 3.4 模型流式调用:获取分片响应,且每个分片前检查中断状态
// concatMap + checkInterruptedAsync:保证分片处理前先校验中断,避免无效执行
return model.stream(
event.getInputMessages(), // 预处理后的输入消息
toolkit.getToolSchemas(), // 工具Schema(供模型选择调用工具)
options) // 生成配置
.concatMap(chunk -> checkInterruptedAsync().thenReturn(chunk));
})
// 3.5 流式分片处理:累积分片到上下文,并通知推理分片钩子(如实时输出日志/前端展示)
.doOnNext(
chunk -> {
// 处理单个模型响应分片,更新推理上下文(累积内容、解析工具调用等)
List<Msg> chunkMsgs = context.processChunk(chunk);
// 为每个分片消息触发钩子(如流式返回给用户、记录实时日志)
for (Msg msg : chunkMsgs) {
notifyReasoningChunk(msg, context).subscribe();
}
})
// 3.6 流式结束后构建最终消息:defer保证延迟执行(等待所有分片处理完成)
.then(Mono.defer(() -> Mono.justOrEmpty(context.buildFinalMessage())))
// 3.7 中断异常处理:捕获InterruptedException,保存已累积的消息到内存后再抛出异常
.onErrorResume(
InterruptedException.class,
error -> {
// 中断前保存已累积的消息,避免状态丢失
Msg msg = context.buildFinalMessage();
if (msg != null) {
memory.addMessage(msg);
}
return Mono.error(error);
})
// 3.8 触发推理后置钩子:处理最终推理结果(如HITL干预、结构化输出校验)
.flatMap(this::notifyPostReasoning)
.flatMap(
event -> {
// 3.9 保存推理结果到内存:供后续迭代/行动阶段使用
Msg msg = event.getReasoningMessage();
if (msg != null) {
memory.addMessage(msg);
}
// ========== 分支1:HITL人工停止(优先级最高) ==========
if (event.isStopRequested()) {
// 标记消息为「推理阶段人工终止」,直接返回结果,终止所有迭代
return Mono.just(
msg.withGenerateReason(
GenerateReason.REASONING_STOP_REQUESTED));
}
// ========== 分支2:跳转到下一轮推理(如结构化输出未完成) ==========
if (event.isGotoReasoningRequested()) {
// 验证逻辑已在PostReasoningEvent.gotoReasoning()中完成
List<Msg> gotoMsgs = event.getGotoReasoningMsgs();
if (gotoMsgs != null) {
// 添加跳转消息到内存,供下一轮推理使用
gotoMsgs.forEach(memory::addMessage);
}
// 继续下一轮推理,且忽略最大迭代次数检查(避免被上限终止)
return reasoning(iter + 1, true);
}
// ========== 分支3:满足结束条件(任务完成) ==========
if (isFinished(msg)) {
// 推理结果满足结束条件,直接返回最终消息
return Mono.just(msg);
}
// ========== 分支4:无终止/结束条件,进入行动阶段 ==========
// 先检查中断状态,再调用acting()执行工具调用
return checkInterruptedAsync().then(acting(iter));
})
// 3.10 空结果兜底:若推理阶段未生成任何消息,返回空Msg的Mono
.switchIfEmpty(
Mono.defer(
() -> {
// 无消息生成时的兜底处理
return Mono.justOrEmpty((Msg) null);
}));
}
java
/**
* 检查智能体执行是否已被中断(响应式版本)。
* 如果未中断,返回正常完成的 Mono;如果已中断,返回携带
* InterruptedException 异常的 Mono。
*
* <p>子类应在其 Mono 调用链的关键检查点调用此方法。
* 对于简单智能体(如 UserAgent),可能无需设置检查点;
* 对于复杂智能体(如 ReActAgent),应在以下节点调用:
* <ul>
* <li>每次迭代的开始阶段</li>
* <li>推理阶段执行前/后</li>
* <li>每个工具执行前/后</li>
* <li>流式处理过程中(每个分片)</li>
* </ul>
*
* <p>使用示例:
* <pre>{@code
* return checkInterruptedAsync()
* .then(reasoning())
* .flatMap(result -> checkInterruptedAsync().thenReturn(result))
* .flatMap(result -> executeTools(result));
* }</pre>
*
* @return 未中断时正常完成的 Mono;中断时抛出异常的 Mono
*/
protected Mono<Void> checkInterruptedAsync() {
return Mono.defer(
() ->
interruptFlag.get()
? Mono.error(
new InterruptedException("智能体执行已被中断"))
: Mono.empty());
}
java
/**
* 处理模型响应分片,并返回可立即发送的消息列表。
*
* <p>处理策略:
* <ul>
* <li>TextBlock/ThinkingBlock:立即输出,用于实时展示(如前端流式返回文本/思考过程)
* <li>ToolUseBlock:累积的同时立即输出,支持工具调用的实时流式展示
* </ul>
*
* @hidden
* @param chunk 模型返回的响应分片(流式输出的单个片段)
* @return 可立即发送的消息列表(供前端/钩子实时消费)
*/
public List<Msg> processChunk(ChatResponse chunk) {
// 1. 记录当前响应分片的消息ID,保证全链路消息ID一致性
this.messageId = chunk.getId();
// 2. 累积模型调用的用量信息(Token数、耗时等)
ChatUsage usage = chunk.getUsage();
if (usage != null) {
inputTokens = usage.getInputTokens(); // 累计输入Token数
outputTokens = usage.getOutputTokens(); // 累计输出Token数
time = usage.getTime(); // 累计模型调用耗时
}
// 3. 初始化流式消息列表:存储当前分片可立即发送的消息
List<Msg> streamingMsgs = new ArrayList<>();
// 4. 遍历分片内的所有内容块,按类型差异化处理
for (ContentBlock block : chunk.getContent()) {
// 4.1 处理文本块(TextBlock):实时输出,支持流式文本展示
if (block instanceof TextBlock tb) {
// 将文本块累积到上下文(用于后续构建完整消息)
textAcc.add(tb);
// 构建分片消息并加入实时发送列表
Msg msg = buildChunkMsg(tb);
streamingMsgs.add(msg);
// 记录所有已流式输出的分片,用于后续拼接完整消息
allStreamedChunks.add(msg);
// 4.2 处理思考块(ThinkingBlock):实时输出,展示智能体思考过程
} else if (block instanceof ThinkingBlock tb) {
// 将思考块累积到上下文
thinkingAcc.add(tb);
// 构建分片消息并加入实时发送列表
Msg msg = buildChunkMsg(tb);
streamingMsgs.add(msg);
allStreamedChunks.add(msg);
// 4.3 处理工具调用块(ToolUseBlock):累积+实时输出,支持并行工具调用的流式展示
} else if (block instanceof ToolUseBlock tub) {
// 将工具调用块累积到上下文(用于后续执行工具/拼接完整调用)
toolCallsAcc.add(tub);
// 为工具调用块补充唯一ID:解决分片场景下(如__fragment__占位符)的拼接问题
// 保证用户端能根据ID正确拼接多个工具调用分片
ToolUseBlock outputBlock = enrichToolUseBlockWithId(tub);
// 构建工具调用分片消息,支持多工具并行调用的实时展示
Msg msg = buildChunkMsg(outputBlock);
streamingMsgs.add(msg);
allStreamedChunks.add(msg);
}
}
// 5. 返回当前分片可立即发送的消息列表(供钩子/前端实时消费)
return streamingMsgs;
}
java
/**
* 通知所有钩子函数推理阶段的分片消息(流式场景)。
* 核心逻辑:根据分片消息类型构建「累积内容块」,封装为推理分片事件并触发钩子,
* 支持文本、思考过程、工具调用的流式实时通知。
*
* @param chunkMsg 推理阶段的单个分片消息(如模型返回的文本分片/工具调用分片)
* @param context 推理上下文(存储已累积的文本、思考过程、工具调用等状态)
* @return 异步完成的 Mono<Void>,表示钩子通知完成
*/
private Mono<Void> notifyReasoningChunk(Msg chunkMsg, ReasoningContext context) {
// 1. 提取分片消息中的首个内容块(流式场景下单个分片通常仅含一个内容块)
ContentBlock content = chunkMsg.getFirstContentBlock();
// 2. 初始化累积内容块:用于存储「当前分片+历史分片」的合并结果
ContentBlock accumulatedContent = null;
// 3. 按内容块类型构建对应的累积内容块
// 3.1 文本块(TextBlock):合并上下文所有已累积的文本
if (content instanceof TextBlock) {
accumulatedContent = TextBlock.builder()
.text(context.getAccumulatedText()) // 获取上下文累积的完整文本
.build();
// 3.2 思考块(ThinkingBlock):合并上下文所有已累积的思考过程
} else if (content instanceof ThinkingBlock) {
accumulatedContent = ThinkingBlock.builder()
.thinking(context.getAccumulatedThinking()) // 获取上下文累积的完整思考内容
.build();
// 3.3 工具调用块(ToolUseBlock):支持流式工具调用的累积与通知
} else if (content instanceof ToolUseBlock tub) {
// 根据工具调用ID,从上下文获取该工具调用的所有累积分片
ToolUseBlock accumulated = context.getAccumulatedToolCall(tub.getId());
if (accumulated != null) {
// 有累积数据:使用合并后的完整工具调用块
accumulatedContent = accumulated;
} else {
// 无累积数据:直接使用当前分片(首次收到该工具调用的分片)
accumulatedContent = tub;
}
}
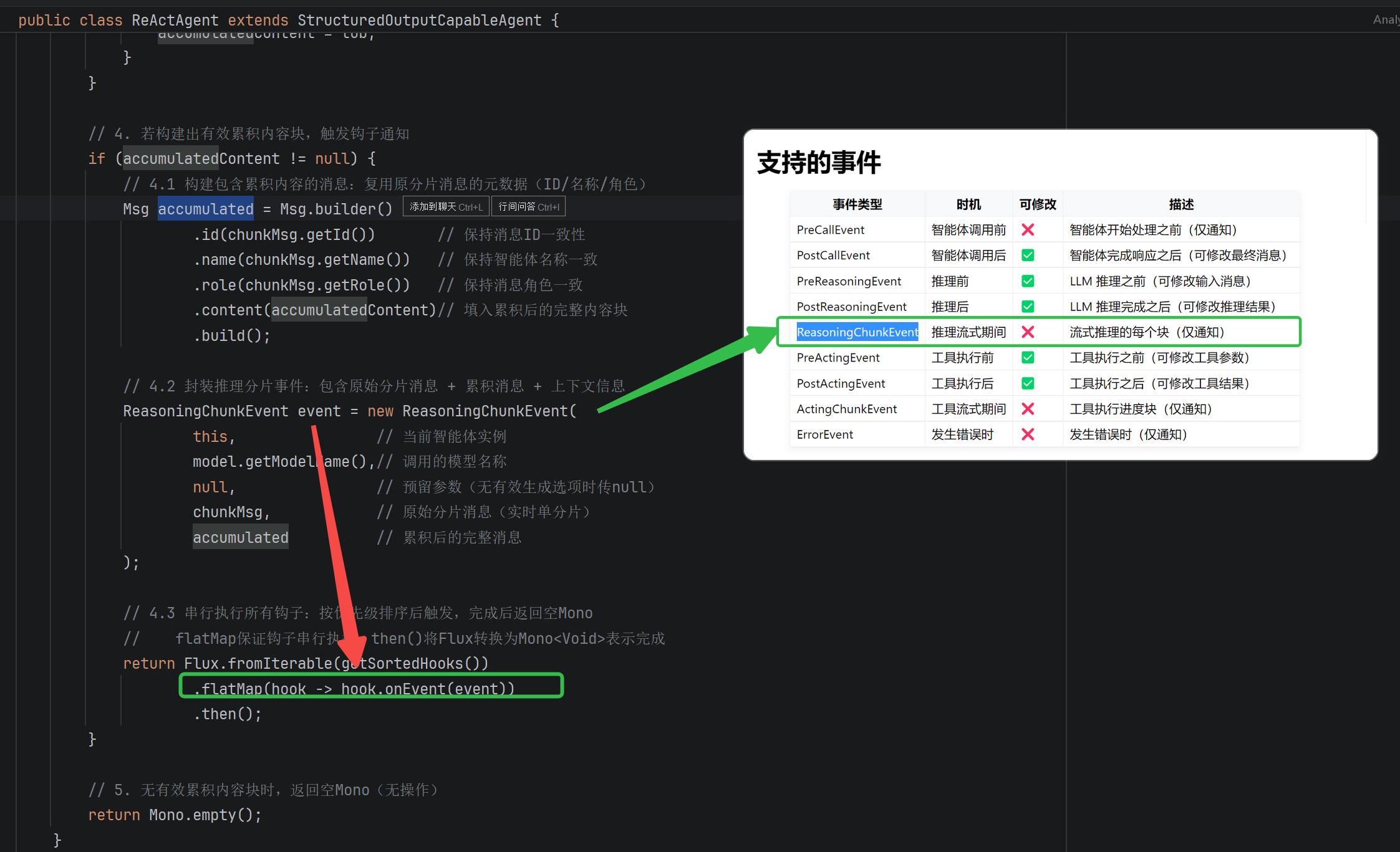
// 4. 若构建出有效累积内容块,触发钩子通知
if (accumulatedContent != null) {
// 4.1 构建包含累积内容的消息:复用原分片消息的元数据(ID/名称/角色)
Msg accumulated = Msg.builder()
.id(chunkMsg.getId()) // 保持消息ID一致性
.name(chunkMsg.getName()) // 保持智能体名称一致
.role(chunkMsg.getRole()) // 保持消息角色一致
.content(accumulatedContent)// 填入累积后的完整内容块
.build();
// 4.2 封装推理分片事件:包含原始分片消息 + 累积消息 + 上下文信息
ReasoningChunkEvent event = new ReasoningChunkEvent(
this, // 当前智能体实例
model.getModelName(),// 调用的模型名称
null, // 预留参数(无有效生成选项时传null)
chunkMsg, // 原始分片消息(实时单分片)
accumulated // 累积后的完整消息
);
// 4.3 串行执行所有钩子:按优先级排序后触发,完成后返回空Mono
// flatMap保证钩子串行执行,then()将Flux转换为Mono<Void>表示完成
return Flux.fromIterable(getSortedHooks())
.flatMap(hook -> hook.onEvent(event))
.then();
}
// 5. 无有效累积内容块时,返回空Mono(无操作)
return Mono.empty();
}
ReAct-Loop 核心实现要点
-
核心流程 :以
doCall为入口,遵循「推理(Reasoning)→ 行动(Acting)→ 循环」范式,无待处理工具时直接推理,有工具结果时先验证再行动。 -
推理阶段:流式调用模型,实时累积分片(文本/思考/工具调用),通过中断检查、最大迭代次数限制避免无限循环,满足终止条件(人工停止/任务完成)则退出,否则进入行动阶段。
-
行动阶段:执行待处理工具调用,分类处理成功/挂起结果,成功结果存入内存后继续迭代,仅挂起结果则返回挂起消息,无结果直接回到推理。
-
流式能力:基于 ReasoningContext 累积流式分片,通过 notifyReasoningChunk 实时通知钩子,工具调用补充唯一ID解决分片拼接问题。
-
人机交互与中断:关键节点异步检查中断状态,人工干预(stopRequested)可终止循环并携带原因;挂起恢复需开发者自行实现状态持久化。
-
设计特性:基于 Mono/Flux 实现异步非阻塞,钩子机制覆盖全流程,内存/上下文保证状态一致性,多重边界防护(迭代上限、异常兜底)保障稳定性。
总结:
我们这一次先围绕ReActAgent的基础使用,初步拆解了其核心源码实现,从入口调用到内部循环,从扩展机制到可观测性保障,完整梳理了ReAct智能体"推理-行动"迭代范式的落地逻辑,也清晰掌握了AgentScope框架对该范式的工程化封装思路,现将本次分析的核心要点与整体认知总结如下:
本次分析以ReActAgent的核心特性为线索,从"使用示例→源码拆解→机制提炼"逐步深入,先通过简单的代码示例快速掌握ReActAgent的基础调用方式,明确其与大模型的交互入口的是call方法;随后以call方法为起点,由外到内拆解了AgentBase中call方法的核心实现,厘清了线程安全保障、状态重置、核心执行链路及最终清理的完整流程,其中"链路追踪→前置钩子→业务逻辑→后置钩子→异常兜底"的链路设计,是保证智能体稳定执行的核心支撑。
在核心机制的拆解中,我们重点分析了三大核心模块的实现逻辑与价值。其一为钩子系统,作为ReActAgent可扩展能力的核心,它基于事件驱动模式,通过PreCallEvent、PostCallEvent、ReasoningChunkEvent等多种事件类型,结合Hook接口的instanceof动态适配,实现了对智能体全流程的监控、拦截与扩展,且无需侵入核心业务代码,完美契合开闭原则;同时,钩子系统也贯穿于推理、行动全阶段,为个性化扩展(如日志埋点、参数校验)提供了灵活的入口。
其二为可观测性体系,以Tracer接口与TracerRegistry注册中心为核心,实现了智能体执行全链路的追踪能力。Tracer接口覆盖了智能体调用、模型调用、工具调用、格式转换四大核心环节,默认提供NoopTracer空实现以降低无追踪场景的性能开销,同时支持用户自定义实现,可灵活对接主流链路追踪系统;TracerRegistry则通过全局Reactor钩子的动态启停,解决了异步流中追踪上下文丢失的痛点,实现了追踪上下文的跨异步边界传播,为智能体的调试、监控、性能分析提供了坚实基础。
其三为ReAct-Loop核心循环的实现,这是ReAct范式落地的关键。以doCall方法为入口,智能体根据是否存在待处理工具调用,灵活切换至推理(Reasoning)或行动(Acting)阶段,形成闭环迭代。推理阶段负责流式调用模型、累积分片响应、检查中断与迭代上限,根据终止条件(人工干预、任务完成等)决定是否进入行动阶段;行动阶段负责执行待处理工具调用、分类处理成功与挂起结果,更新内存状态后继续迭代,直至完成任务或触发终止条件。整个循环过程中,异步非阻塞(基于Reactor的Mono/Flux)、状态一致性(内存与上下文管理)、多重边界防护(迭代上限、异常兜底、中断检查),共同保障了智能体的稳定性与健壮性。
此外,本次分析也明确了ReActAgent的几大设计亮点:一是响应式流处理的深度应用,基于Project Reactor实现全链路非阻塞执行,适配高并发场景的需求;二是人机协同(HITL)的简洁实现,通过事件中的stopRequested标志与stopAgent()方法,支持人工干预智能体执行流程,兼顾自动化与可控性;三是结构化与可扩展性的平衡,既通过StructuredOutputCapableAgent提供类型安全的输出生成能力,又通过钩子系统、Tracer接口等设计,为用户自定义扩展提供了灵活的入口;四是性能与安全性的优化,通过CAS原子操作实现线程安全、动态启停Reactor钩子控制性能开销、统一异常处理保障状态一致性,兼顾了执行效率与系统稳定性。
需要注意的是,框架在部分细节上仍需开发者自行补充实现,例如工具调用挂起后的状态恢复机制,框架未提供默认的持久化方案,需开发者结合业务场景,基于事件机制或外部存储实现状态的保存与恢复。同时,ReAct-Loop的迭代逻辑、钩子的执行顺序、Tracer的自定义实现等,也可结合具体业务需求进行优化调整,进一步适配不同场景下的智能体开发需求。
综上,ReActAgent作为AgentScope框架中基于ReAct范式实现的核心智能体,其设计思路既贴合ReAct"推理-行动"的核心逻辑,又通过工程化封装解决了实际开发中的异步处理、可观测性、可扩展性、稳定性等关键问题,为AI原生应用中智能体的开发提供了高效、灵活的解决方案。本次分析仅覆盖了ReActAgent的核心特性与基础源码实现,后续可进一步深入拆解doCall方法中未详细分析的工具调用校验、推理上下文的细节处理、钩子系统的自定义实践、Tracer与主流链路追踪系统的集成等内容,结合具体业务场景,挖掘ReActAgent的更多优化空间与应用价值,助力开发者更高效地基于ReActAgent构建高性能、高可用的智能体应用。