基于BP神经网络的数据分类预测 matlab 代码 这段程序是一个简单的神经网络模型,用于分类任务。下面我将对程序进行详细分析和解释。 首先,程序开始时清空环境变量、关闭报警信息、关闭图窗、清空变量和命令行。这些操作是为了确保程序运行时的环境干净。 接下来,程序读取名为"数据集.xlsx"的Excel文件中的数据,并将数据存储在变量"res"中。 然后,程序通过统计"res"中的类别数和样本数,计算出训练集和测试集的划分比例。默认情况下,训练集占数据集的70%。 接着,程序根据类别将数据集划分为训练集和测试集。对于每个类别,根据划分比例,将相应数量的样本分配给训练集和测试集。 然后,程序对训练集和测试集进行数据转置,以便后续处理。 接下来,程序对训练集和测试集进行数据归一化处理。使用mapminmax函数将输入数据映射到0到1的范围内,以便更好地进行神经网络训练。 然后,程序定义了一些超参数,包括最大训练次数、学习率和隐藏层节点数。 接下来,程序开始进行模型训练。调用net_train函数,传入训练集数据、训练集标签、隐藏层节点数、学习率和最大训练次数。net_train函数会返回训练好的神经网络模型和损失函数值。 然后,程序使用训练好的模型对训练集和测试集进行预测。调用net_sim函数,传入训练集和测试集数据以及训练好的模型。net_sim函数会返回预测结果。 接下来,程序对预测结果进行反归一化处理,将预测结果转换为类别标签。 然后,程序计算训练集和测试集的准确率。 接着,程序绘制了训练集和测试集的预测结果对比图。图中包含真实值和预测值,以及准确率的显示。 然后,程序根据标志位判断是否绘制混淆矩阵。如果标志位为1,则绘制训练集和测试集的混淆矩阵。 接下来,程序绘制了损失函数的曲线图,用于显示训练过程中损失函数的变化情况。 最后,程序结束。 总结起来,这段程序主要是一个简单的神经网络模型,用于分类任务。它读取数据集,划分训练集和测试集,对数据进行归一化处理,定义超参数,进行模型训练和预测,计算准确率,绘制预测结果对比图和损失函数曲线图。它涉及到的知识点包括神经网络、数据处理、数据归一化和性能评价等。
在数据科学和机器学习领域,BP神经网络是一种常用的分类预测工具。今天咱们就来详细看看一段基于BP神经网络进行数据分类预测的Matlab代码,顺便深入分析分析它。
代码环境准备
matlab
clear all; % 清空环境变量
warning off; % 关闭报警信息
close all; % 关闭图窗
clc; % 清空命令行这段代码就是在给程序运行创造一个"干净"的环境。想象一下,要是环境里乱七八糟的,之前的变量、图窗啥的还在,说不定就会干扰新程序的运行。所以清空环境变量、关闭报警信息、图窗和清空命令行,能让程序轻装上阵。
数据读取
matlab
res = xlsread('数据集.xlsx');这里使用xlsread函数读取名为"数据集.xlsx"的Excel文件,把里面的数据存到变量res中。就好像我们把一本书里的内容都拿到手上,准备开始研究一样。
数据集划分
matlab
classes = unique(res(:, end)); % 统计类别数
num_classes = length(classes); % 类别数量
num_samples = size(res, 1); % 样本数量
train_ratio = 0.7; % 训练集比例
train_size = floor(train_ratio * num_samples); % 训练集大小
test_size = num_samples - train_size; % 测试集大小
train_data = [];
test_data = [];
for i = 1:num_classes
class_data = res(res(:, end) == classes(i), :);
class_train_size = floor(train_ratio * size(class_data, 1));
train_data = [train_data; class_data(1:class_train_size, :)];
test_data = [test_data; class_data(class_train_size + 1:end, :)];
end先统计数据集中的类别数和样本数,然后默认把70%的数据作为训练集,剩下的作为测试集。这里按类别划分数据集很重要,这样能保证每个类别在训练集和测试集中都有合适的比例,避免出现某个类别在训练集或测试集中缺失的情况。
数据转置和归一化
matlab
train_data = train_data';
test_data = test_data';
[train_input, ps] = mapminmax(train_data(1:end - 1, :));
test_input = mapminmax('apply', test_data(1:end - 1, :), ps);
train_target = train_data(end, :);
test_target = test_data(end, :);把训练集和测试集的数据转置一下,方便后续处理。然后使用mapminmax函数对输入数据进行归一化,把数据映射到0到1的范围内。归一化能让数据的特征处于同一量级,这样神经网络在训练时能更快收敛,效果也更好。
超参数定义
matlab
max_epoch = 100; % 最大训练次数
learning_rate = 0.1; % 学习率
hidden_nodes = 10; % 隐藏层节点数这里定义了几个重要的超参数。最大训练次数就像是规定了学习的总时长,学习率决定了每次学习前进的"步子"大小,隐藏层节点数则影响着神经网络的复杂度和学习能力。
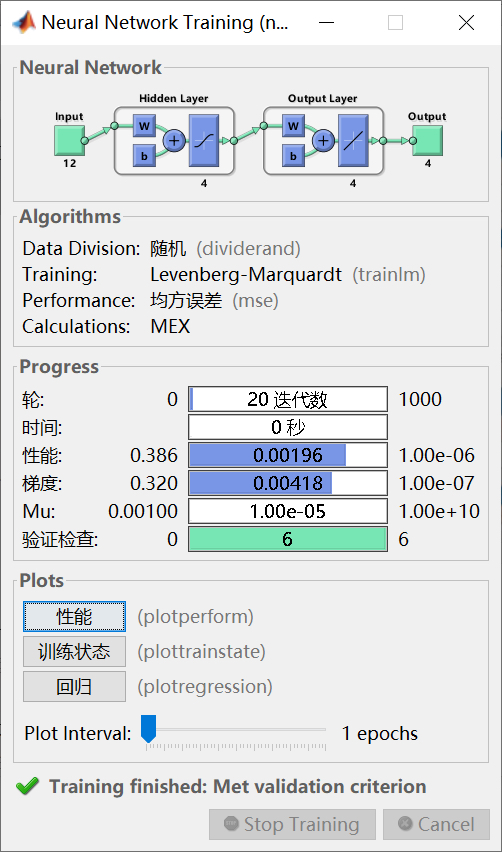
模型训练
matlab
[net, loss] = net_train(train_input, train_target, hidden_nodes, learning_rate, max_epoch);调用net_train函数进行模型训练,这个函数会返回训练好的神经网络模型和损失函数值。训练的过程就像是让神经网络不断学习数据中的模式和规律。
模型预测
matlab
train_pred = net_sim(train_input, net);
test_pred = net_sim(test_input, net);使用训练好的模型对训练集和测试集进行预测,调用net_sim函数,它会根据输入数据和模型给出预测结果。
反归一化和准确率计算
matlab
train_pred = round(train_pred);
test_pred = round(test_pred);
train_accuracy = sum(train_pred == train_target) / length(train_target);
test_accuracy = sum(test_pred == test_target) / length(test_target);对预测结果进行反归一化,把预测结果转换为类别标签。然后计算训练集和测试集的准确率,看看模型在训练数据和测试数据上的表现怎么样。
结果可视化
matlab
figure;
subplot(2, 1, 1);
plot(train_target, 'b', 'LineWidth', 1.5);
hold on;
plot(train_pred, 'r--', 'LineWidth', 1.5);
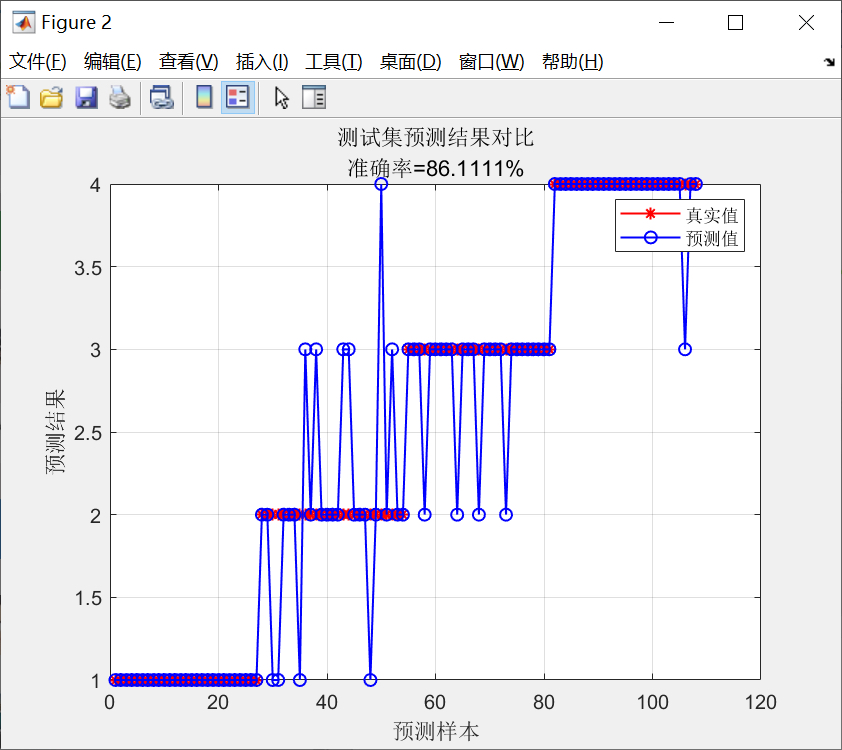
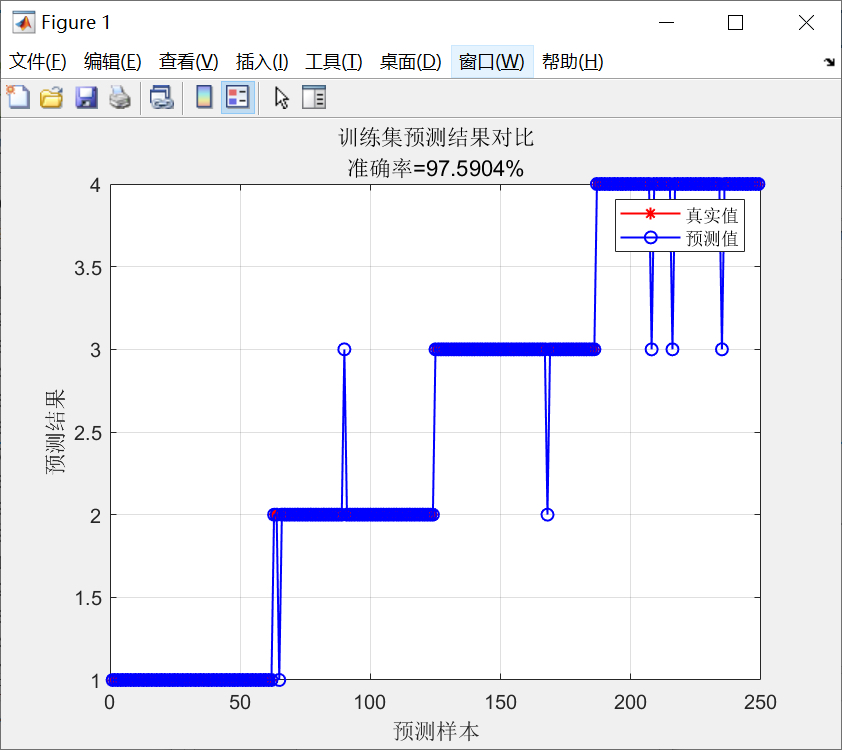
title(['训练集预测结果对比,准确率: ', num2str(train_accuracy * 100), '%']);
legend('真实值', '预测值');
subplot(2, 1, 2);
plot(test_target, 'b', 'LineWidth', 1.5);
hold on;
plot(test_pred, 'r--', 'LineWidth', 1.5);
title(['测试集预测结果对比,准确率: ', num2str(test_accuracy * 100), '%']);
legend('真实值', '预测值');
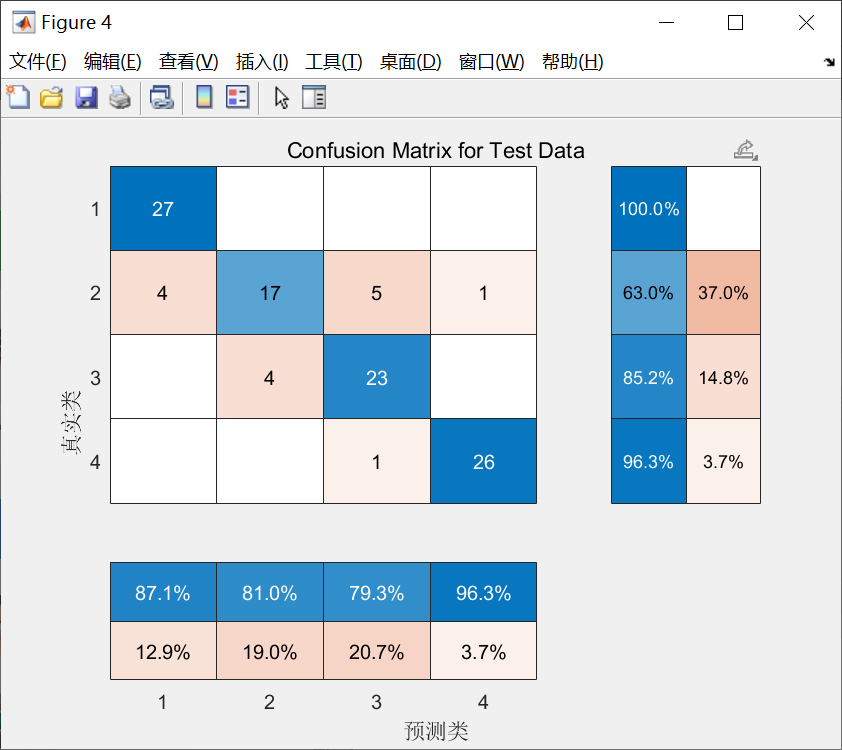
if flag == 1
figure;
subplot(2, 1, 1);
confusionchart(train_target', train_pred');
title('训练集混淆矩阵');
subplot(2, 1, 2);
confusionchart(test_target', test_pred');
title('测试集混淆矩阵');
end
figure;
plot(loss);
title('损失函数曲线');绘制训练集和测试集的预测结果对比图,能直观地看到真实值和预测值的差异。如果标志位flag为1,还会绘制混淆矩阵,混淆矩阵可以帮助我们分析模型在各个类别上的分类情况。最后绘制损失函数的曲线图,从图中可以看到训练过程中损失函数的变化,了解模型的训练效果。
基于BP神经网络的数据分类预测 matlab 代码 这段程序是一个简单的神经网络模型,用于分类任务。下面我将对程序进行详细分析和解释。 首先,程序开始时清空环境变量、关闭报警信息、关闭图窗、清空变量和命令行。这些操作是为了确保程序运行时的环境干净。 接下来,程序读取名为"数据集.xlsx"的Excel文件中的数据,并将数据存储在变量"res"中。 然后,程序通过统计"res"中的类别数和样本数,计算出训练集和测试集的划分比例。默认情况下,训练集占数据集的70%。 接着,程序根据类别将数据集划分为训练集和测试集。对于每个类别,根据划分比例,将相应数量的样本分配给训练集和测试集。 然后,程序对训练集和测试集进行数据转置,以便后续处理。 接下来,程序对训练集和测试集进行数据归一化处理。使用mapminmax函数将输入数据映射到0到1的范围内,以便更好地进行神经网络训练。 然后,程序定义了一些超参数,包括最大训练次数、学习率和隐藏层节点数。 接下来,程序开始进行模型训练。调用net_train函数,传入训练集数据、训练集标签、隐藏层节点数、学习率和最大训练次数。net_train函数会返回训练好的神经网络模型和损失函数值。 然后,程序使用训练好的模型对训练集和测试集进行预测。调用net_sim函数,传入训练集和测试集数据以及训练好的模型。net_sim函数会返回预测结果。 接下来,程序对预测结果进行反归一化处理,将预测结果转换为类别标签。 然后,程序计算训练集和测试集的准确率。 接着,程序绘制了训练集和测试集的预测结果对比图。图中包含真实值和预测值,以及准确率的显示。 然后,程序根据标志位判断是否绘制混淆矩阵。如果标志位为1,则绘制训练集和测试集的混淆矩阵。 接下来,程序绘制了损失函数的曲线图,用于显示训练过程中损失函数的变化情况。 最后,程序结束。 总结起来,这段程序主要是一个简单的神经网络模型,用于分类任务。它读取数据集,划分训练集和测试集,对数据进行归一化处理,定义超参数,进行模型训练和预测,计算准确率,绘制预测结果对比图和损失函数曲线图。它涉及到的知识点包括神经网络、数据处理、数据归一化和性能评价等。
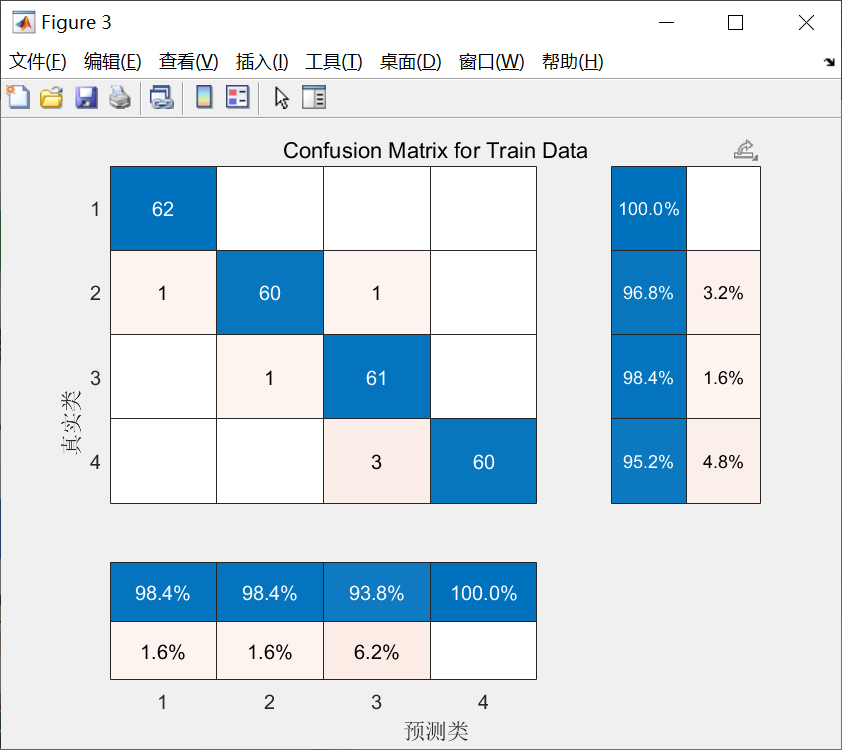
总的来说,这段代码实现了一个简单的BP神经网络分类预测模型。它涵盖了数据读取、划分、归一化、模型训练、预测、准确率计算和结果可视化等多个步骤,涉及到神经网络、数据处理、数据归一化和性能评价等多个知识点。通过这段代码,我们可以初步了解如何使用BP神经网络进行数据分类预测。