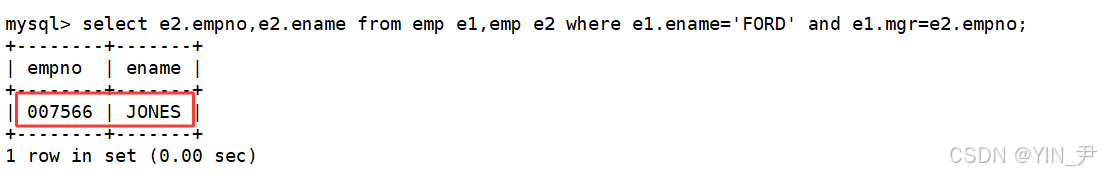文章目录
- [1. 基本查询回顾](#1. 基本查询回顾)
-
- [1.1 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J](#1.1 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J)
- [1.2 按照部门号升序而雇员的工资降序排序](#1.2 按照部门号升序而雇员的工资降序排序)
- [1.3 使用年薪进行降序排序](#1.3 使用年薪进行降序排序)
- [1.4 显示工资最高的员工的名字和工作岗位](#1.4 显示工资最高的员工的名字和工作岗位)
- [1.5 显示工资高于平均工资的员工信息](#1.5 显示工资高于平均工资的员工信息)
- [1.6 显示每个部门的平均工资和最高工资](#1.6 显示每个部门的平均工资和最高工资)
- [1.7 显示平均工资低于2000的部门号和它的平均工资](#1.7 显示平均工资低于2000的部门号和它的平均工资)
- [1.8 显示每种岗位的雇员总数,平均工资](#1.8 显示每种岗位的雇员总数,平均工资)
- [2. 多表查询](#2. 多表查询)
-
- [2.1 显示雇员姓名、雇员工资以及所在部门的名字](#2.1 显示雇员姓名、雇员工资以及所在部门的名字)
- 笛卡尔积
- [2.2 显示部门号为10的部门名,员工名和工资](#2.2 显示部门号为10的部门名,员工名和工资)
- [2.3 显示各个员工的姓名,工资,及工资级别](#2.3 显示各个员工的姓名,工资,及工资级别)
- [3. 自连接](#3. 自连接)
前面我们讲解的mysql表的查询都是对一张表进行查询,在实际开发中这远远不够。
先来复习一下我们之前学过的基本查询,做几道题
1. 基本查询回顾
1.1 查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
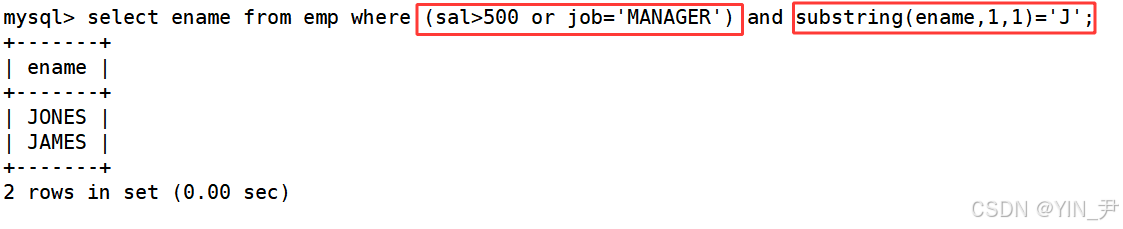
查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
select ename from emp where (sal>500 or job='MANAGER') and ename like 'J%';
当然满足他们的姓名首字母为大写的J也可以使用我们上一篇文章学的字符串函数,截取第一个字符,判断其是否为J
select ename from emp where (sal>500 or job='MANAGER') and substring(ename,1,1)='J';

1.2 按照部门号升序而雇员的工资降序排序
sql
select * from emp order by deptno asc,sal desc;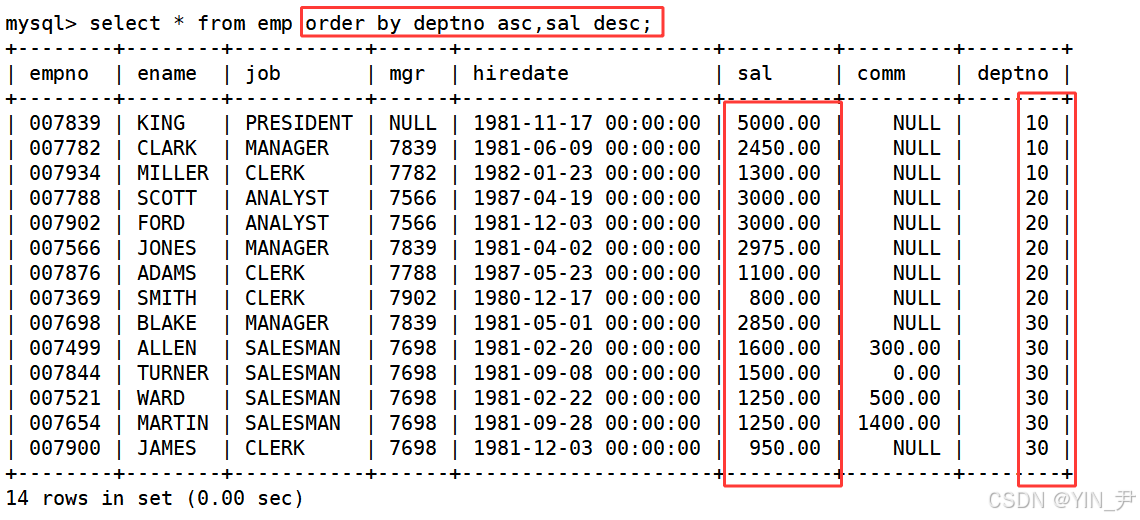
1.3 使用年薪进行降序排序
按年薪降序排序,那这很简单,但是我们发现表中是没用年薪的,只有sal(月薪)
所以我们要先计算出年薪,然后按年薪降序排序:
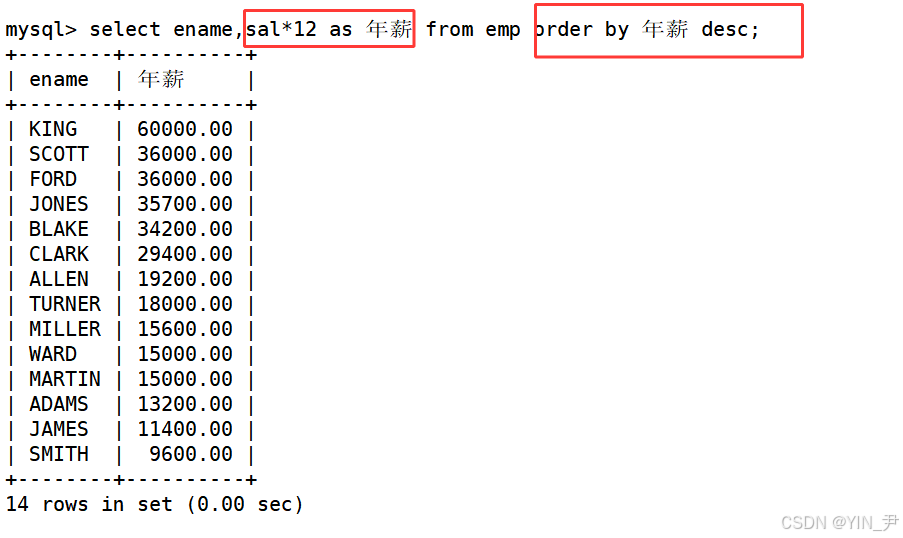
select ename,sal*12 as 年薪 from emp order by 年薪 desc;
没问题,但是少算了一个
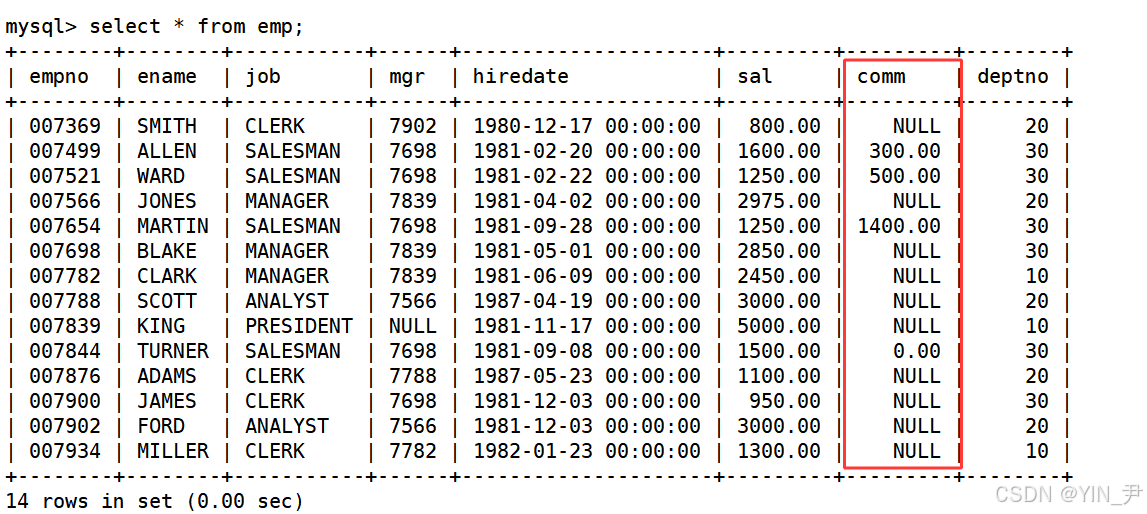
翻看前面文章我们这张表的结构,发现sal是月薪,但是还有一个奖金comm,所以最终需要加上
但是我们发现奖金不是每个人都有的,有的是null(根本没有奖金这回事,而不是奖金为0),那怎么加呢?
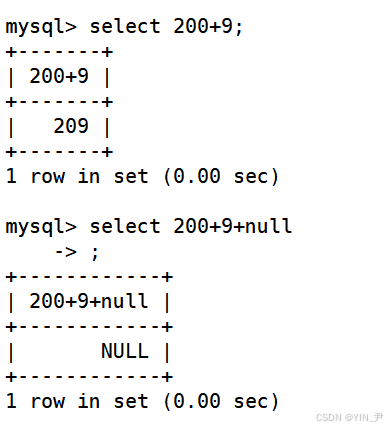
null是不参与运算的,如果加了null,那结果就也是null了
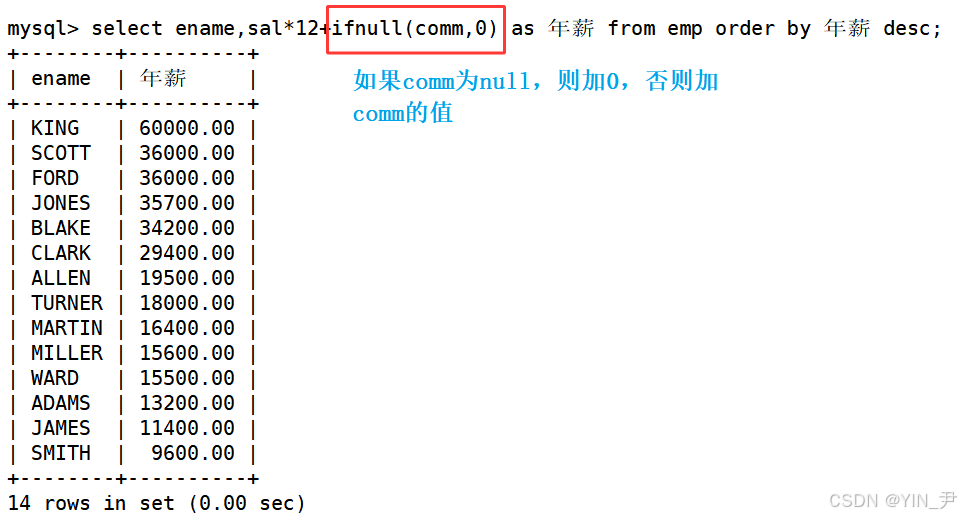
🆗,上一篇文章学的 ifnull(val1, val2)函数就可以派上用场了
ifnull(val1, val2)
如果val1为null,则返回val2,否则返回val1的值
select ename,sal*12+ifnull(comm,0) as 年薪 from emp order by 年薪 desc;
1.4 显示工资最高的员工的名字和工作岗位
怎么做?
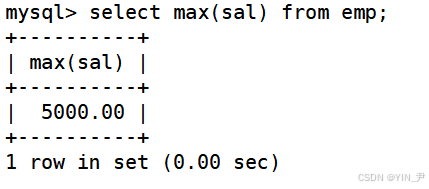
select ename,job from emp where sal=max(sal);
这样可以吗?
报错了,为什么?
那就要思考一下聚合函数的执行顺序是排在哪里的?
聚合函数是在 GROUP BY 确定分组后,对每个分组内的行进行汇总计算。
即聚合函数在 GROUP BY 分组之后执行,因此不能在 WHERE 中使用(你可以当作语法规定记住),但可以在 HAVING、SELECT、ORDER BY 中使用。
那大家可能很自然的会有这样一个疑惑?
这里没有 GROUP BY,为什么可以直接用 MAX(sal)?
我们之前提到过,一张表没有被分组,本身就可以看作是单独一组 。
即使没有显式的 GROUP BY,整个表也被隐式地当作一个"大组"来处理。
"隐式分组"(全表作为一个组)也应该是在 WHERE 子句之后才进行的。 这正是为什么 WHERE 中不能直接使用聚合函数,而 SELECT 中可以使用的根本原因。
所以记住where子句中不能使用聚合函数


那怎么办呢?
那就可以这样做
select ename,job from emp where sal=(select max(sal) from emp);
之前文章也提了一下,这叫做子查询或嵌套查询
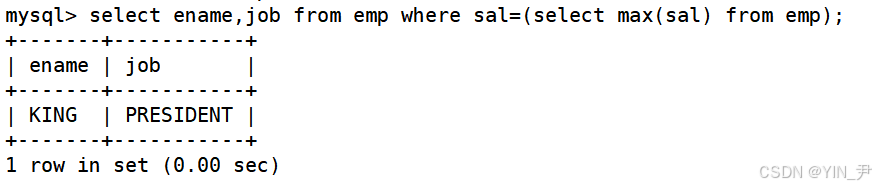
1.5 显示工资高于平均工资的员工信息
依然使用子查询就可以
sql
select * from emp where sal>(select avg(sal) from emp);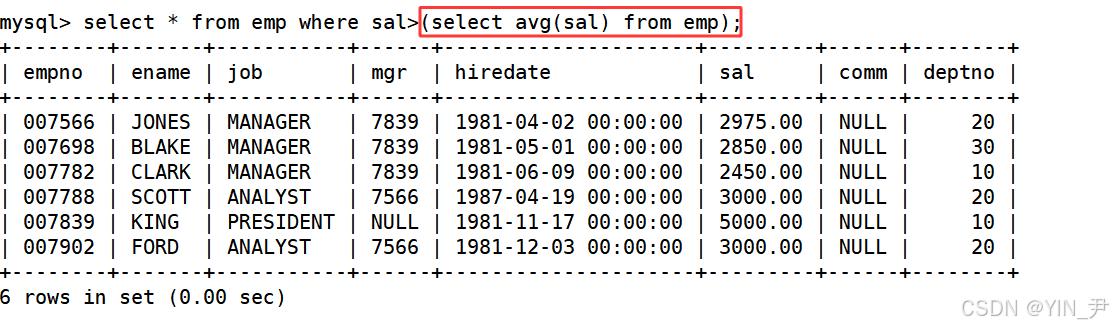
1.6 显示每个部门的平均工资和最高工资
按部门分组,再聚合统计即可
sql
select deptno,avg(sal),max(sal) from emp group by deptno;
1.7 显示平均工资低于2000的部门号和它的平均工资
sql
select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资<2000;
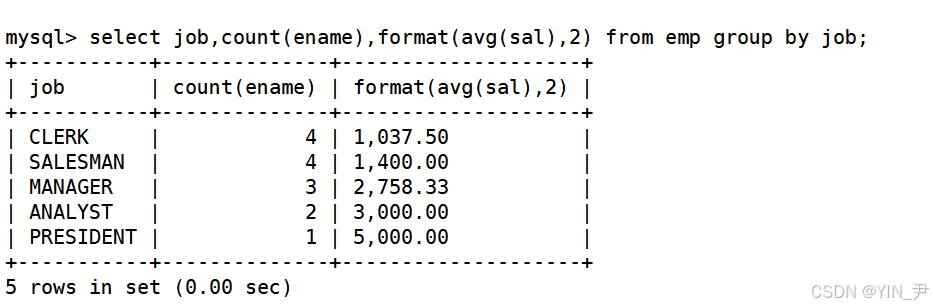
1.8 显示每种岗位的雇员总数,平均工资
sql
select job,count(ename),avg(sal) from emp group by job;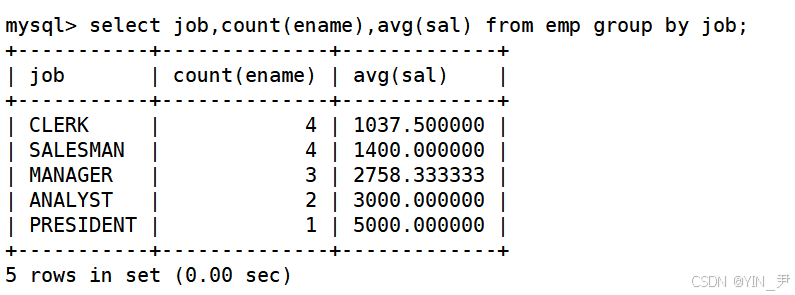
2. 多表查询
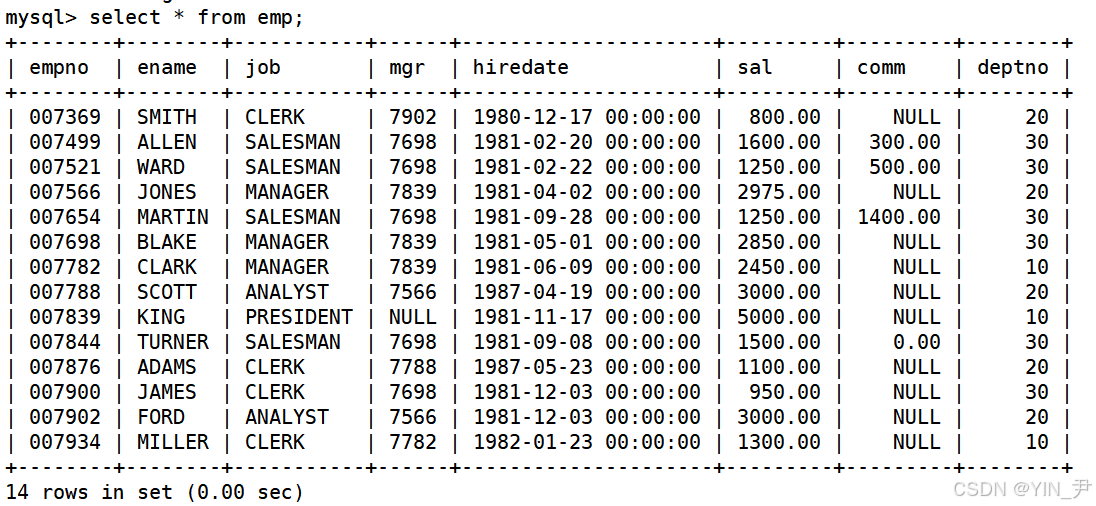
实际开发中往往数据来自不同的表,所以需要多表查询。这里我们依然使用之前文章中用到的来自oracle 9i的经典测试表,有三张表EMP,DEPT,SALGRADE来演示如何进行多表查询。
sql
DROP database IF EXISTS `scott`;
CREATE database IF NOT EXISTS `scott` DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
USE `scott`;
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`deptno` int(2) unsigned zerofill NOT NULL COMMENT '部门编号',
`dname` varchar(14) DEFAULT NULL COMMENT '部门名称',
`loc` varchar(13) DEFAULT NULL COMMENT '部门所在地点'
);
DROP TABLE IF EXISTS `emp`;
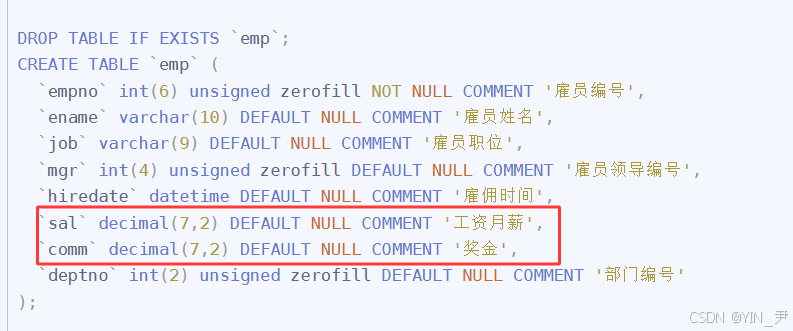
CREATE TABLE `emp` (
`empno` int(6) unsigned zerofill NOT NULL COMMENT '雇员编号',
`ename` varchar(10) DEFAULT NULL COMMENT '雇员姓名',
`job` varchar(9) DEFAULT NULL COMMENT '雇员职位',
`mgr` int(4) unsigned zerofill DEFAULT NULL COMMENT '雇员领导编号',
`hiredate` datetime DEFAULT NULL COMMENT '雇佣时间',
`sal` decimal(7,2) DEFAULT NULL COMMENT '工资月薪',
`comm` decimal(7,2) DEFAULT NULL COMMENT '奖金',
`deptno` int(2) unsigned zerofill DEFAULT NULL COMMENT '部门编号'
);
DROP TABLE IF EXISTS `salgrade`;
CREATE TABLE `salgrade` (
`grade` int(11) DEFAULT NULL COMMENT '等级',
`losal` int(11) DEFAULT NULL COMMENT '此等级最低工资',
`hisal` int(11) DEFAULT NULL COMMENT '此等级最高工资'
);下面我们依然通过案例来讲解
2.1 显示雇员姓名、雇员工资以及所在部门的名字
回看上面的表结构我们发现:
雇员姓名和工资是在emp表中的,但是emp表中只有部门编号,现在要想拿到部门名称,就需要拿着部门编号去dept表里找。

笛卡尔积
因为上面的数据分别来自EMP和DEPT表,因此要进行多表联合查询
首先来将两张表的数据整合到一块,怎么做呢?
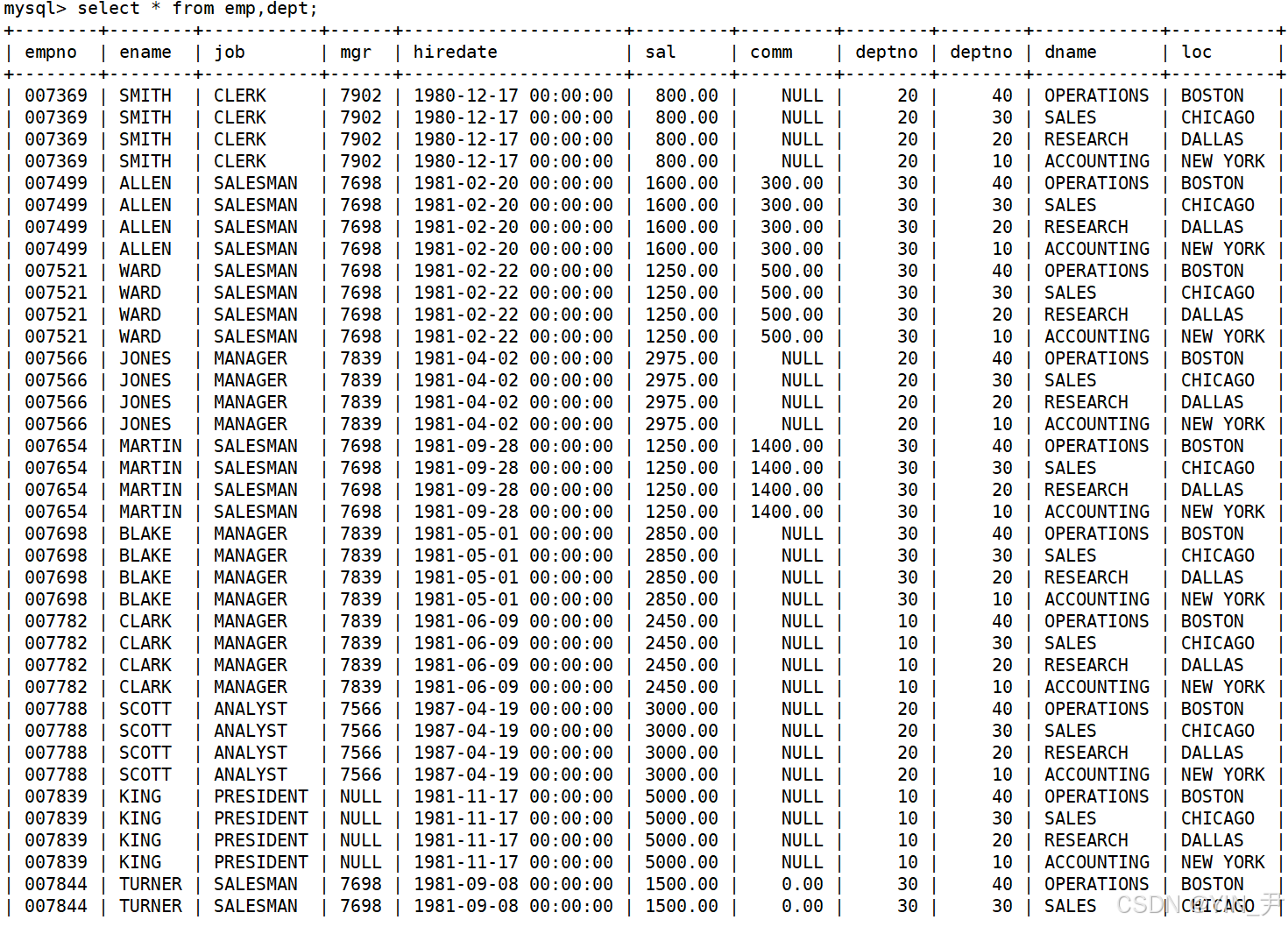
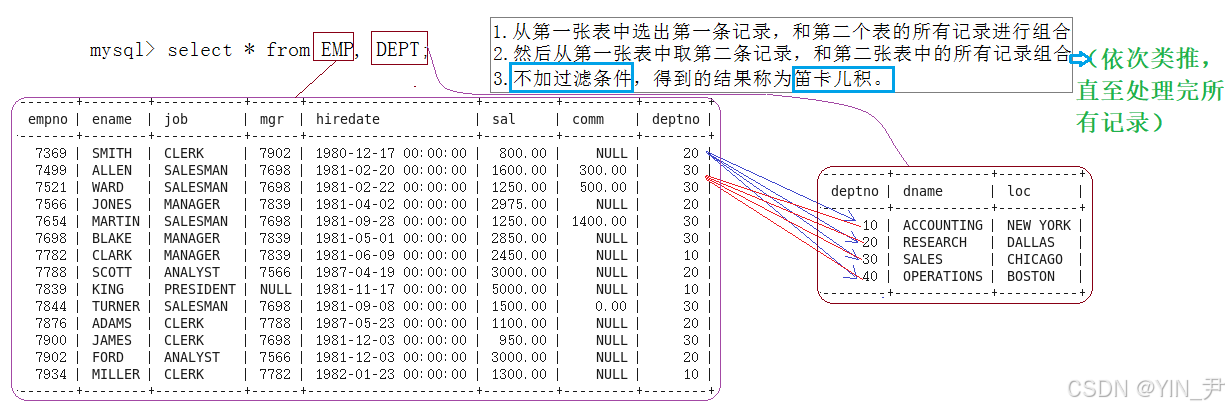
select * from emp,dept;
同时查询这两张表,用逗号隔开,那结果会是什么样呢?
我们看到得到了一个非常大的表(下面还有没截完),但是这是个啥啊?
如果大家之前学过数据库系统概论的话,肯定学过一个概念叫做笛卡尔积
其实得到的这张表就是emp和dept的笛卡尔积(当然也可以是更多张的表)。(等价写法:SELECT * FROM emp CROSS JOIN dept;)
那什么是笛卡尔积呢?
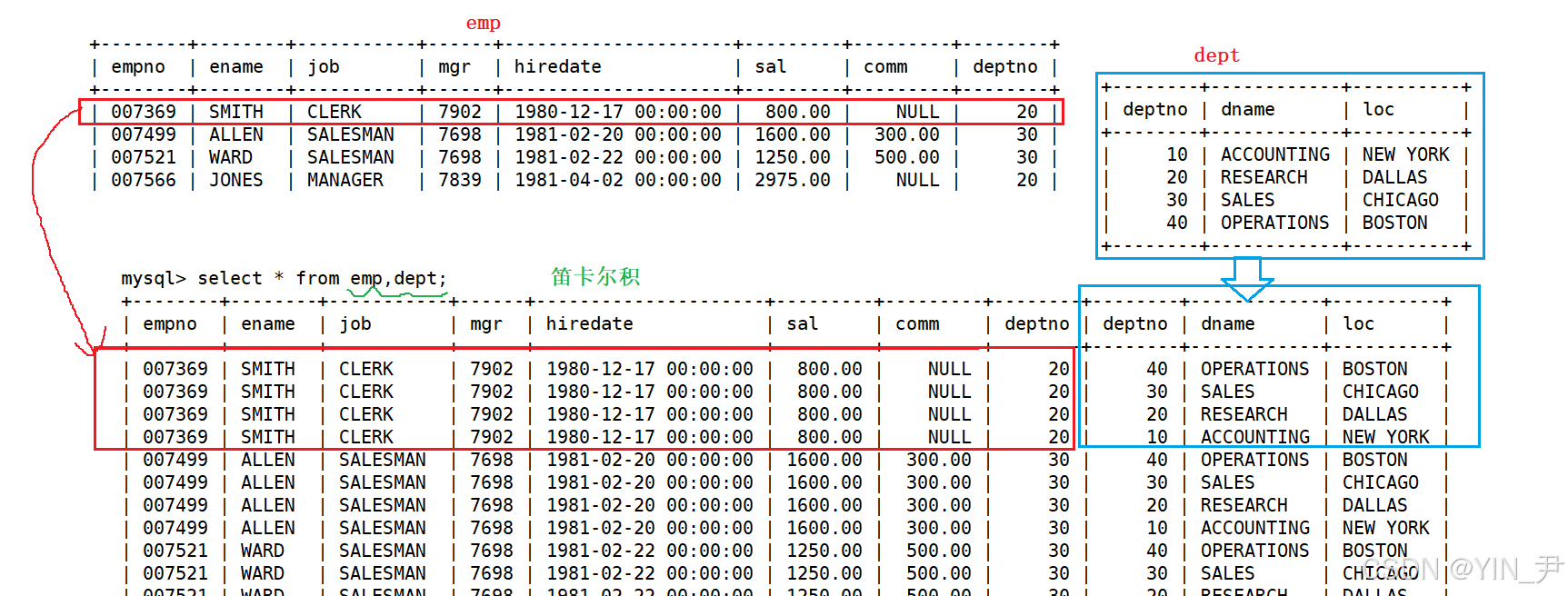
以这两张表为例,emp和dept的笛卡尔积其实就是
emp 的每一行与 dept 的每一行的所有组合
即先拿emp的第一行与dept 的每一行依次拼接,然后再拿emp的第二行与dept 的每一行依次拼接...
得到的笛卡尔积中表的列数就是两表列数相加,行数就是两边行数相乘。
那此时:
我们得到的这张表中不就同时拥有雇员名、雇员工资以及所在部门的名字嘛!
然后我们来对这张表进行查询不就是我们之前学的内容了嘛。
但是,我们会发现,笛卡尔积中不是所有的记录都是有意义的
比如,SMITH这个人
emp表中,我们看到他的部门编号是20
但是在笛卡尔积中
它又在其它三个部门也出现了,这显然是不合理的。
所以实际应用中一定要加连接条件进行过滤,否则会产生大量无意义数据。
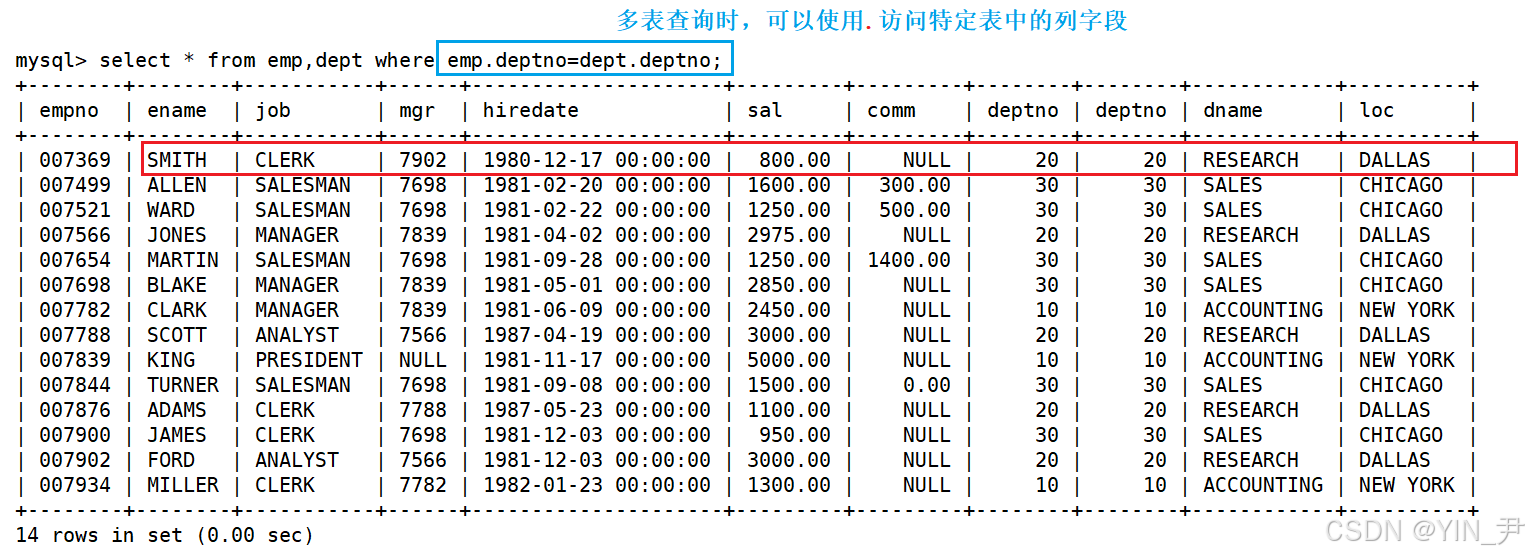
在我们当前的场景中,只有这个员工的emp和dept表中部门编号是一样的,那么这条记录才是有意义的
select * from emp,dept where emp.deptno=dept.deptno;
这样,我们就只保留了有意义的数据。

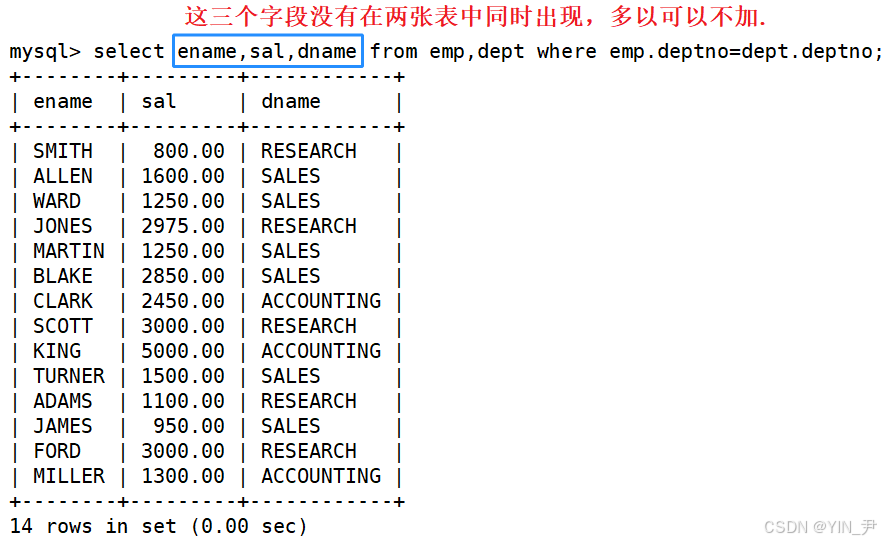
然后我们来看题目要求要的是什么:
雇员名、雇员工资以及所在部门的名字
所以
这样就可以了
2.2 显示部门号为10的部门名,员工名和工资
通过上面的学习,这就太简单了
sql
select ename,sal,dname from emp,dept where emp.deptno=dept.deptno and dept.deptno=10;

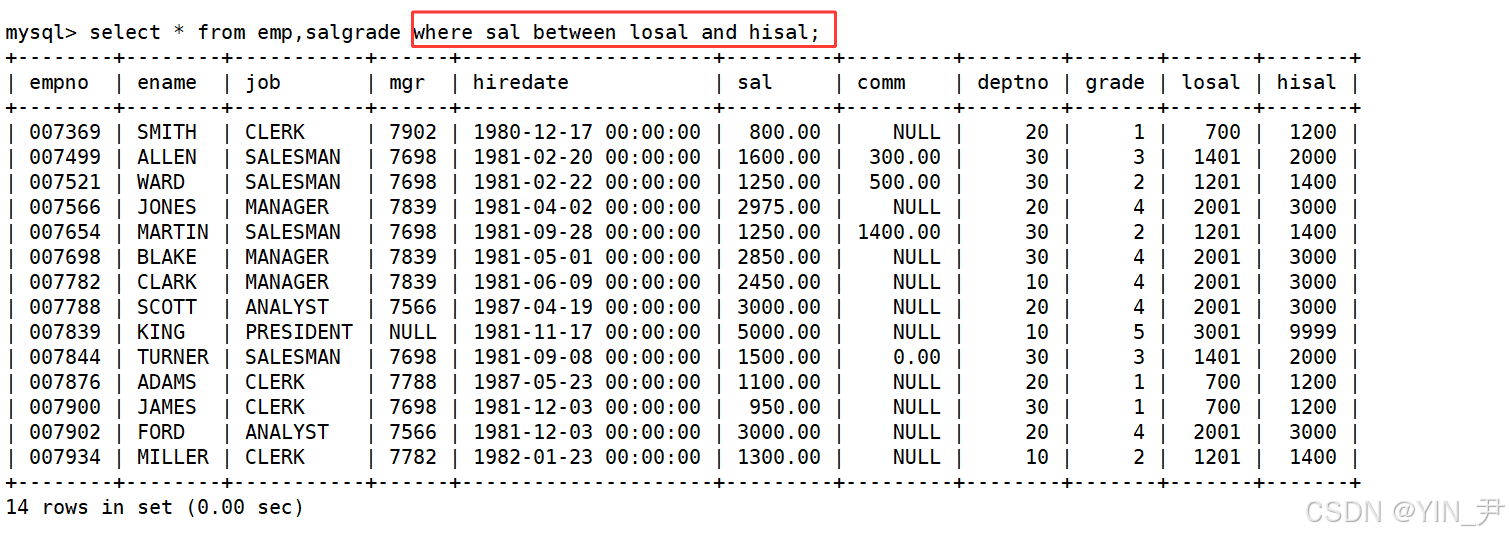
2.3 显示各个员工的姓名,工资,及工资级别
工资级别在哪张表里呢?
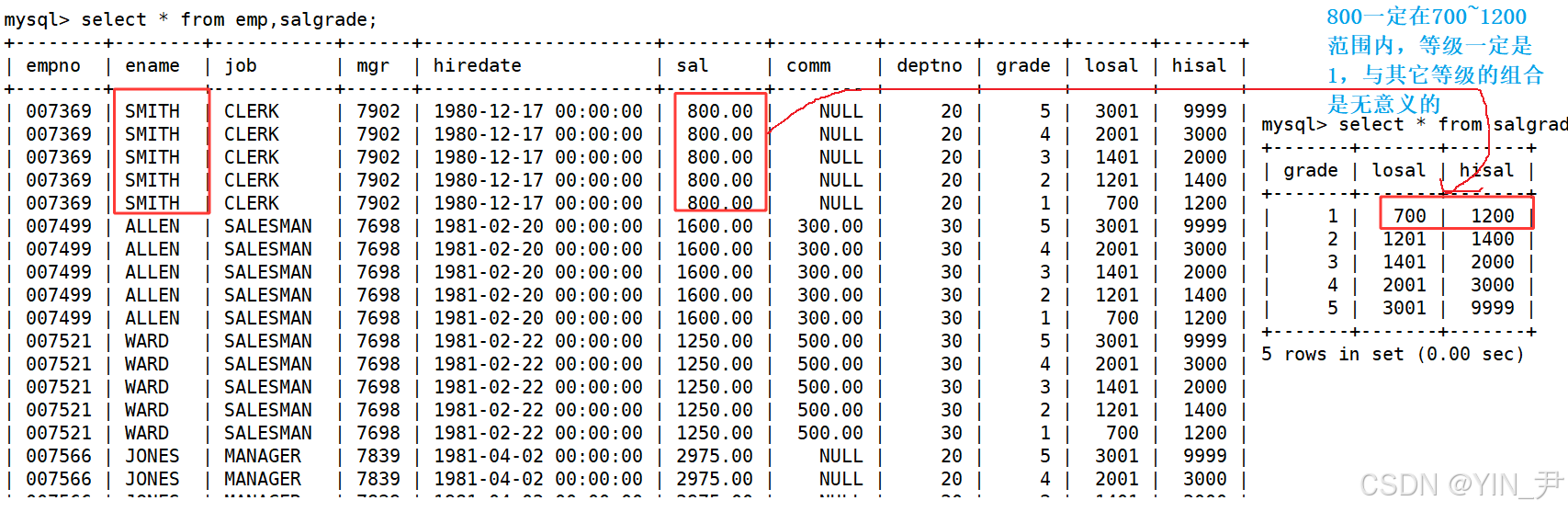
在salgrade里面呢,所以这次就应该查询emp和salgrade这两张表,从他们的笛卡尔积中查找。
那筛选条件应该是什么呢?
先来看一下他们的笛卡尔积
所以,过滤条件就应该是
这样就过滤掉了无意义的记录,然后,再选择我们想要的字段就行了


3. 自连接
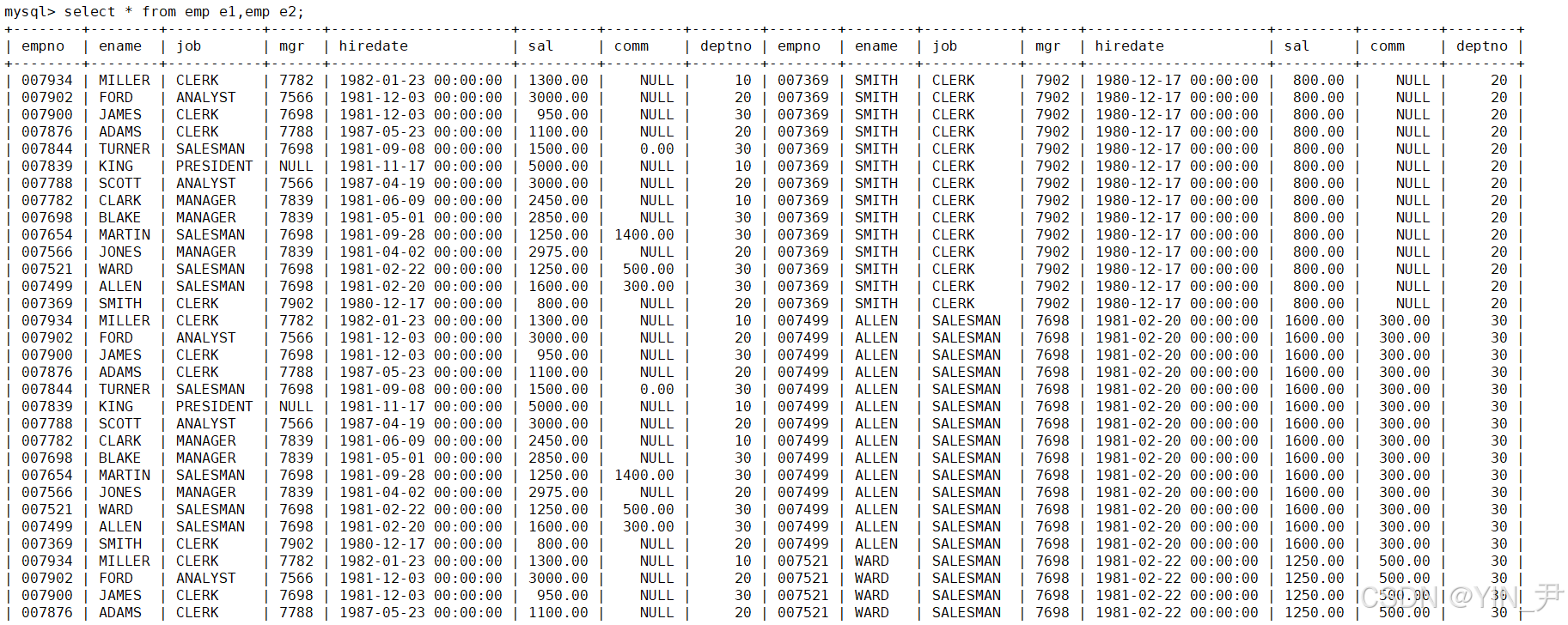
上面呢我们是两张不同的表进行了笛卡尔积,哪同一张表可以和自己进行笛卡尔积嘛
那怎么写呢?写两次表名,逗号隔开嘛
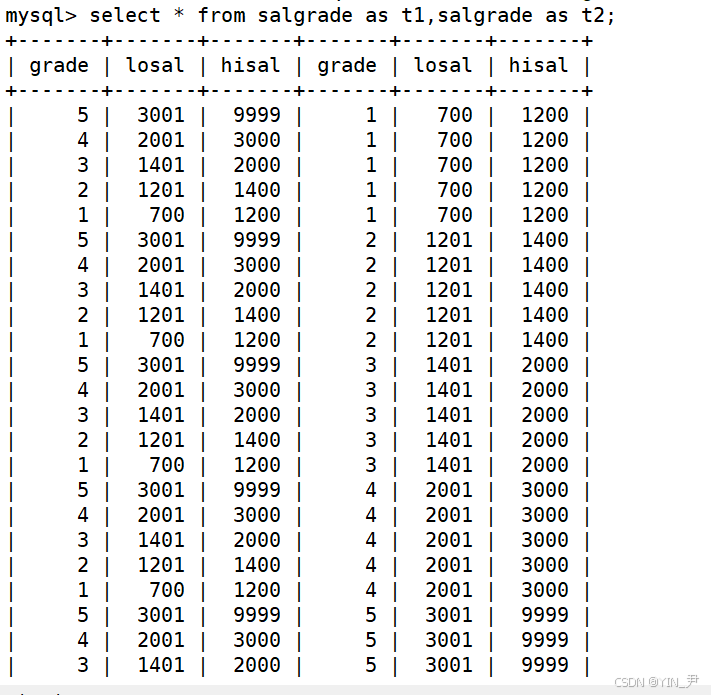
我们来试一下,以salgrade为例
select * from salgrade,salgrade;
直接这样写是不行的,当同一个表被多次引用时,如果不指定不同的别名,数据库就无法区分哪个是哪个,因此会报"表/别名不唯一"的错误。
我们可以起个别名,让别名不一样
select * from salgrade as t1,salgrade as t2;
这样就可以了,这就得到了salgrade表自己和自己的笛卡尔积(也叫自连接,指一张表与自身进行连接操作)。

那什么场景下需要进行自连接呢?来看下面的案例:
案例:显示员工FORD的上级领导的编号和姓名
我们来分析一下:
在emp表中,mgr为员工领导的编号(即员工领导的雇员编号 )
然后我们要知道,领导也是该公司的员工,所以他的信息 也在emp表中

解法一:子查询
那这里我们该怎么做呢?
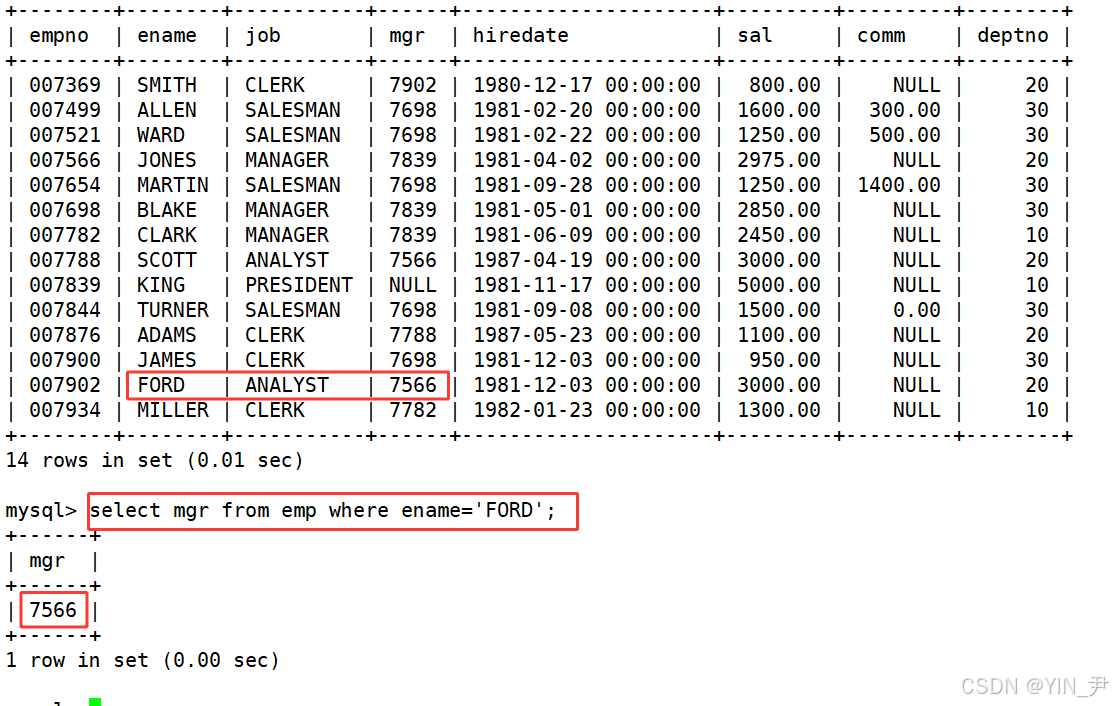
第一步,先找到FORD这个人的领导的领导编号(在emp表中)
第二步,根据这个领导编号信息找到他领导的编号和姓名(也在emp表中)
我们来一块做一下
第一步:select mgr from emp where ename='FORD';
就找到了他的领导编号,也就是他领导的雇员编号。
然后根据领导编号就可以找到他领导的信息了
select empno,ename from emp where empno=(select mgr from emp where ename='FORD');
所以这里使用子查询也可以完成。

但是我们这里不是讲自连接嘛,是的,也可以用自连接完成。
解法二:自连接
怎么做呢?
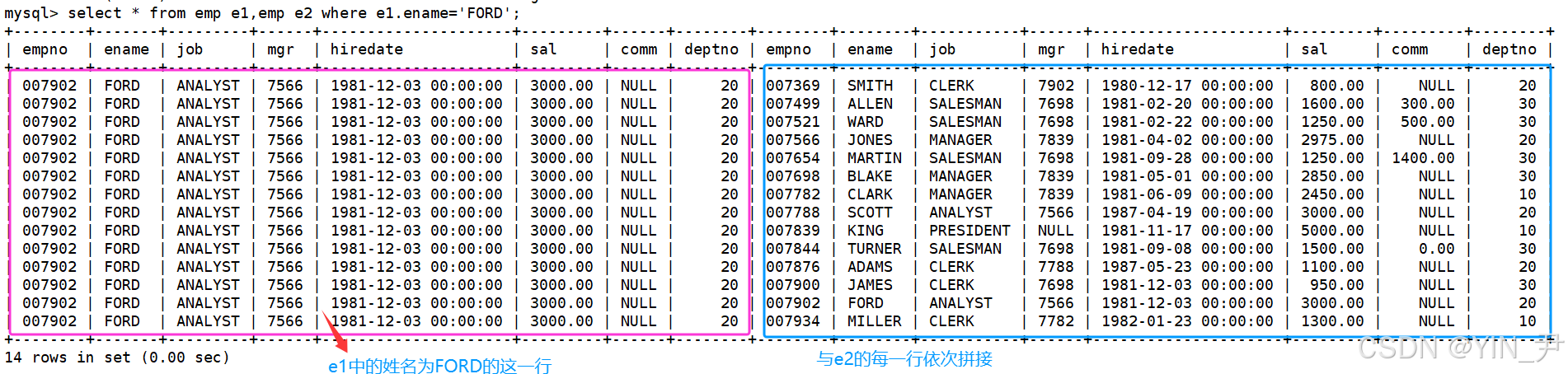
可以先看一下对emp进行自连接(自笛卡尔积)的结果
由于这张表本身就比较大,所以笛卡尔积的结果非常大。
这里把第一个emp起别名为e1,第二个emp起别名为e2。
现在要从这个笛卡尔积中找FORD 的领导编号和姓名,应该怎么做呢?
可以先查找e1中姓名为FORD的记录,那就得到的就是e1中FORD这一列与e2的每一行拼接的结果。
所以第一层过滤
然后此时,e1的这一行中的mgr就是FORD的领导编号,他的领导肯定不是自己,那么这个编号对应的人就要在e2中查找。
所以只需加上e1.mgr等于e2.empno这个条件
select * from emp e1,emp e2 where e1.ename='FORD' and e1.mgr=e2.empno;
此时,e1中留下的是FORD这个员工的信息,e2中留下的就是他的领导的信息 。
我们要的是什么,他领导的员工编号和姓名,那从e2中直接获取就行了
select e2.empno,e2.ename from emp e1,emp e2 where e1.ename='FORD' and e1.mgr=e2.empno;
和上面子查询方法的结果是一样的。
讲的应该是比较详细的,相信大家可以理解。