显卡扫盲
参考视频
讲的挺好的,强推
说来惭愧用这么多年显卡竟然对它不算很了解只是一味的用,之前英伟达一面的时候问了一些相关问题可谓是几乎答不上来,虽然现在在一面二面中间赶紧补补
种类
集成显卡
核心显卡: AMD APU Intel-Core
独立显卡: 有自己的显存和缓存
构成
其它
散热模块,电路板,接口,供电,显存,gpu
电路板/散热
厂商: Nvidia/ 华硕asus
gpu
显卡中间的一块芯片,负责运算任务
厂商: Intel, AMD, Nvidia
(居然Intel 也做gpu 吗, 我一直以为它是做cpu 的)
结构:
- SM流式多处理器 -- 负责图形运算
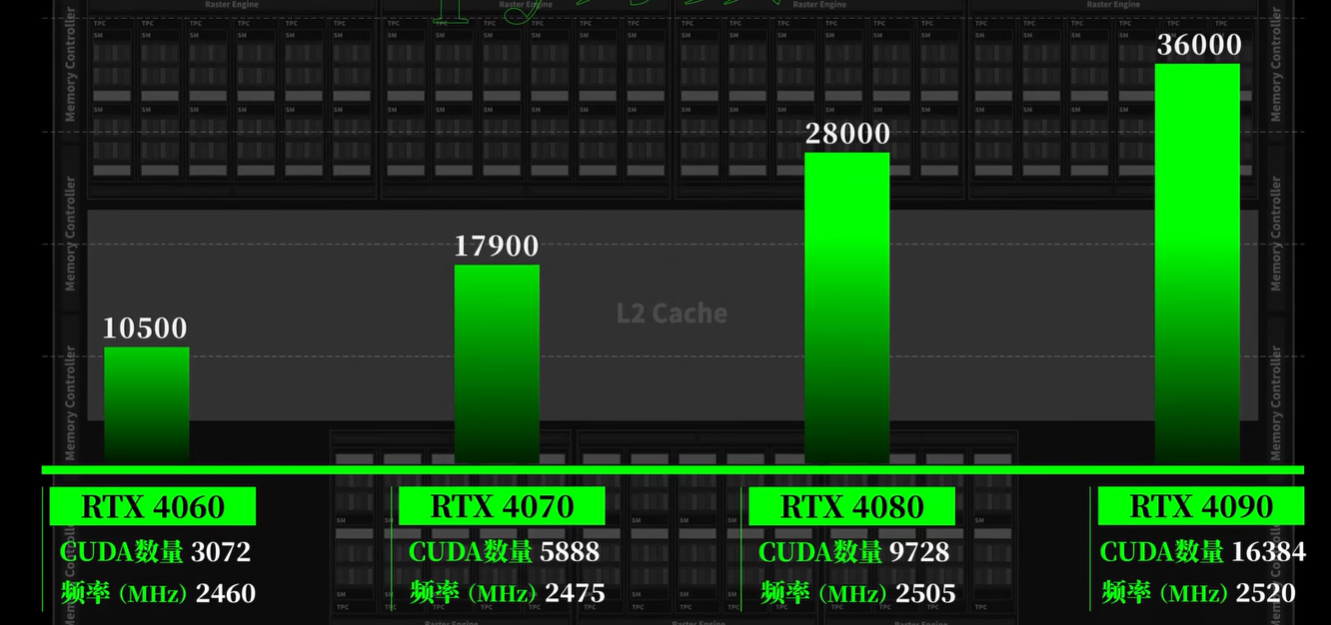
CUDA core
用于通用计算(渲染、卷积、逻辑运算)
每组SM 单元里面有些流处理器,而流处理器就是我们熟悉的CUDA(compute Unified Device Architecture)
流处理器越多性能越强
cpu 能处理复杂任务, 但是 gpu 数量优势大,算的更快,适合需要大量简单计算的场景
算力和架构(GPU 设计方案)有关, 架构越先进,相同效率下图形渲染效率就越高
tensor core
用于高速矩阵乘法(GEMM)
3rd RT core 光追核心
专门用来加速光照和反射计算
rt-tflops
4th Tensor Core 张量核心
生成图像的速率更快
-
L2 缓存
-
NVENC 视频编码器
拍到的画面以新的编码方式压缩成期望的格式和大小(e.g 剪辑视频导出)
- NVDEC 视频解码器
0101 → 画面
显存
cpu对应内存,gpu对应显存
居然是一片一片的OvO
每一片都有 容量 和位宽
总带宽:频率(周期/s) x 位宽(一次可以传输的数据量)x 显存类型(倍增系数)

其它
控制器
显存控制器
gpu 和显存得以顺利交互数据
GDDR 系列
PCIe 控制器
让显卡通过主板和其他元器件交互数据
接口
视频接口让gpu 把运算好的图像给显示器显示
PCLe接口 让显卡通过主板和其他元器件交互数据
型号
GeForce(消费级卡)
RTX 20/30/40/50 系列
RTX | 30 | 70 | 加强版(Ti)或专业向(Titan)
架构 世代 等级 版本
用途:玩游戏/本地推理/小模型训练/AI 个人开发
便宜/显存小(8--24GB)/功耗可控/没有 NVLink(多卡矩阵差,用于多卡通讯)
Data Center(专业级服务器卡)
A100(Ampere)/ H100(Hopper)
用途:大模型训练(GPT/LLAMA 级)/ 推理集群 / 企业服务器
极高显存(40--80--120GB)/ NVLink/NVSwitch(多卡融合)/ECC 内存/专业驱动/价格贵(H100 一张 20 万+)
架构
GPU 设计方案
| 型号 | 架构 | 显存 | 精度支持 | NVLink | 用途 | 性能级别 |
|---|---|---|---|---|---|---|
| RTX 30 系 | Ampere | 8--24GB GDDR6 | FP16(弱),无 BF16 | ❌ | 游戏、小模型 | 低 |
| RTX 40 系 | Ada | 12--24GB GDDR6X | FP16、BF16 | ❌ | 推理、小模型 | 中 |
| RTX 50 系 | Blackwell | 16--32GB | FP16、BF16、(部分 FP8) | ❌ | 推理、中模型 | 中偏高 |
| A100 | Ampere | 40/80GB HBM2e | FP16、BF16 | ✔ | 大模型训练 | 高 |
| H100 | Hopper | 80GB HBM3 | FP8、BF16、FP16 | ✔ | 超大模型训练 | 极高(AI 最强) |
我用过的4090 显存24g, 3070ti 显存8g
迭代
GPU 每一代的升级来自:
新架构 + 更多 CUDA cores + 更强 Tensor Cores + 更快显存 + 更先进工艺 + 更好软件栈。
指标/数值
GPU Benchmark
显卡跑分(GPU Benchmark)= 用标准化的测试软件,测显卡在一系列固定任务里的性能,最后给一个分数用来对比显卡强弱。
通常包括:
-
图形渲染性能(游戏/实时图形)
-
AI计算性能(矩阵乘法、推理、训练)
-
通用计算性能(CUDA kernel、FP32/FP16/INT8 吞吐量)
-
显存带宽、延迟测试
-
光线追踪性能
最后得出来一个综合分。
精度
精度 = 用多少位(bit) 来表示一个数字(浮点数 / 整数)
| 精度 | 位宽 | 类型 | 解释 |
|---|---|---|---|
| FP32 | 32 bit | 浮点 | 高精度,慢 |
| BF16 | 16 bit | 浮点 | 更大范围但精度比 FP32 少 |
| FP16 | 16 bit | 浮点 | 精度较低 |
| FP8 | 8 bit | 浮点 | 超低精度,最新模型使用 |
| INT8 | 8 bit | 整数 | 超低精度,多用于推理 |
只有FP32 不支持Tensor Core, 只支持CUDA core
TFLOP
TFLOPs = Tera Floating-Point Operations per Second
= 每秒能执行多少万亿次浮点运算。
-
1 FLOP = 1 次浮点运算(乘法或加法)
-
1 TFLOP = 1e12 FLOPs
这是衡量 GPU 算力(compute capacity) 的标准。
如果 TFLOPs 接近峰值(>70%):算力吃满,不是 bottleneck
如果 TFLOPs 很低(<40%)→ memory-bound / shape 不佳 → 这个 matmul 没满载,可能需要优化 batch、shape、kernel fusion、flash attention 等。
性能瓶颈判断
LLM 的瓶颈只有两个:算力瓶颈(compute-bound)和显存带宽瓶颈(memory-bound)。
所有优化方法(FlashAttention、Quant、PagedAttention、连续batch)都是围绕这两件事做文章。
Compute-bound 情况(算力瓶颈)
-
你 GPU 算力不够 → kernel 执行慢
-
表现:训练速度变慢 (batch/sec下降),不会报错
-
因为 GPU 只是"忙不过来",依然可以完成计算,只是耗时更长
-
举例:一个大 matmul 或 attention 乘法,如果 GPU core 不够,tensor core 就满负荷工作,但结果依然正确
-
结论:compute-bound → 慢,但能跑通
Memory-bound 情况(显存瓶颈 / 内存瓶颈)
-
显存不够,或者内存访问方式不连续 → kernel 无法分配/写入 tensor
-
表现:直接报错,通常是:
-
CUDA out of memory -
RuntimeError: trying to access memory that doesn't exist -
或者某些 fused kernel 报 memory access violation
-
-
原因:
-
训练时需要为每个 layer 分配激活(activation)和梯度
-
batch 太大、seq 太长 → 激活矩阵无法放入显存
-
Memory-bound 不只是速度问题,而是物理资源限制
-
这就是为什么大 batch / 长序列训练经常 OOM
-
-
结论:memory-bound → 有可能直接报错,算力够慢不报错
| 类型 | 现象 | Profiler 特征 | 优化手段 |
|---|---|---|---|
| Compute-bound | GPU 算力不够 | matmul / attention kernel 占比高,GPU 满载 | FlashAttention, Quantization, Bigger GPU |
| Memory-bound | 内存带宽限制性能 | transpose / as_strided / copy 占比高,GPU FLOPs 不满 | Fuse kernel, Contiguous memory, FlashAttention |
| 调度瓶颈 | kernel 太碎 / 调度开销大 | GPU Util低,kernel 很碎,每个很短 | Kernel fusion, CUDA Graph, 减少小 kernel |
| CPU bottleneck | CPU 下发慢 / Python overhead | CPU Self Time >> GPU Self Time | CUDA Graph, JIT, batch 调度 |
⚠️ 注意:调度瓶颈和 CPU 瓶颈有交集,但不完全一样:
-
调度瓶颈更强调kernel launch overhead,可能 GPU 等 CPU 发指令
-
CPU 瓶颈更宽泛,包括 Python 层循环、mask 生成、KV cache 处理
算子类型
Profiler 输出中最关键的只有 两类算子:
(1) 大算子 → matmul / attention / GEMM(真正吃算力的)
matmul
矩阵乘法,用来把一组向量线性变换到另一组向量。
所有的 全连接层、attention 的 Q/K/V 投影、MLP 里的 weight、卷积的本质 都能转成 matmul。
| 模块 | 是否 matmul | 说明 |
|---|---|---|
| Q/K/V projection | ✔ | X @ Wq |
| attention score | ✔ | Q @ Kᵀ |
| attention output | ✔ | attention @ V |
| FFN 前后两个线性层 | ✔ | h @ W1, W2 |
| softmax | ✘ | 针对每个 token 的归一化 |
| layernorm | ✘ | 轻量运算 |
| gelu | ✘ | elementwise 计算 |
GEMM = 专门为矩阵乘法而优化的底层实现接口
(2) 小算子 → transpose / reshape / view / empty
(调度 / 内存访问 / 非核算操作)
如何找瓶颈(从 Profiler 出发)
Profiler → 确认 compute-bound vs memory-bound → 找占时最多的 kernel。
step1 看CUDA Total Time 最大的算子
Transformer 最长的通常是
aten::matmul (QK;KV;线性层)
aten::scaled_dot_product_attention
aten::bmm
aten::mm
如果你看到:
-
matmul 占比 > 70%
→ 说明整个模型 compute-bound(算力瓶颈)
-
transpose/reshape/as_strided 占比很高
→ 说明有 memory-bound(内存瓶颈)
-
empty/alloc/free 很频繁
→ 说明 内存申请碎片化,可能造成 fragmentation
step2 compute or memory bound?
判断模型是否被 GEMM 限制:
✔ 方法 1:看 profiler 排名
如果你看到:
aten::matmul 78% CUDA time
→ 说明 绝大部分 GPU 时间都在乘法, 你的瓶颈在 **算力,**做不了太多优化,除非你:
-
增加 batching
-
fuse kernel(TensorRT-LLM)
-
quant 化(减少算力)
-
FlashAttention(减少 FLOPs)
✔ 方法 2:看 FLOPs / sec 是否逼近 GPU 理论上限
例如:
4090 理论算力:
-
FP16 ~ 165 TFLOPs
-
BF16 ~ 82 TFLOPs
-
INT8 ~ 660 TOPS(tensor core)
如果你测出来:
模型实际只有 30--40 TFLOPs → matmul 不满载 → 多半是 memory-bound
模型快接近 80+ TFLOPs → matmul 满负荷 → compute-bound
但是这需要 benchmark 工具
step3 识别memory bound
特征 1:大量 as_strided、transpose、view、index_select
e.g
transpose 18%
as_strided 10%
view 5%
empty 4%
不做密集计算
但大量读写显存(non-contiguous access)
导致 GPU 计算单元(tensor cores)闲着
特征 2:CUDA Self Time 很小,但 Total Time 很大
e.g
aten::transpose
self_cuda_time: 20us
total_cuda_time: 2.4ms
transpose 本身时间很短,但它导致后续 kernel(如 matmul)变得更慢 → 因为 stride 不连续!
特征 3:Profiler 显示 GPU 利用率低,kernel 很碎
例如:
-
每个 kernel 200us
-
一秒跑几百次 kernel
→ 调度变成瓶颈,GPU 没被吃满。
TensorRT-LLM / vLLM 的关键优化就是减少 kernel 次数(kernel fusion)。
特征 4:CPU Self Time 比 GPU Self Time 高很多
表示 GPU 等 CPU 下发指令,算力完全没吃满
2) Self vs Total 是面试最常考的点
LLM 推理优化会问:你怎么看 self time 和 total time 的区别?
哪些算子本身慢,哪些算子是 wrapper?
性能优化
FlashAttention
FlashAttention 把 attention 的几个步骤做了 kernel fusion,并且通过 tile 算法把中间结果保留在 SRAM(shared memory)中,减少了大量显存读写。
所以本质是:降低 memory I/O → 减少 kernel 调度 → 提高有效带宽利用。
Fusing
多个算子拆开执行会产生大量 kernel launch 和显存往返(load/store)。
Fusing 把它们合成一个 kernel:
-
更少的 kernel 调度时间
-
中间结果不用写回显存
-
更高算子并行度
所以吞吐量明显提升。
Fusing = 减显存 I/O + 减 kernel 调度 →高吞吐,性能提升
LLM Benchmarks
关键指标
| 指标 | 含义 | 为什么重要 | 怎么测 |
|---|---|---|---|
| 吞吐量(Tokens/sec) | 每秒生成 token 数 | 衡量算力利用率 | vLLM logs / 自测脚本 |
| 延迟(Latency) | 单次响应耗时 | 用户体验关键 | time + profiling |
| Batch Size Scaling | batch 增加 → 吞吐提升 | 优化并发场景 | sweep scripts |
| 并发性能(QPS) | 多请求同时处理性能 | Serve系统指标 | vLLM 并发测试 |
| step 数量 | 训练的时候梯度下降的速度 |
Attention 机制
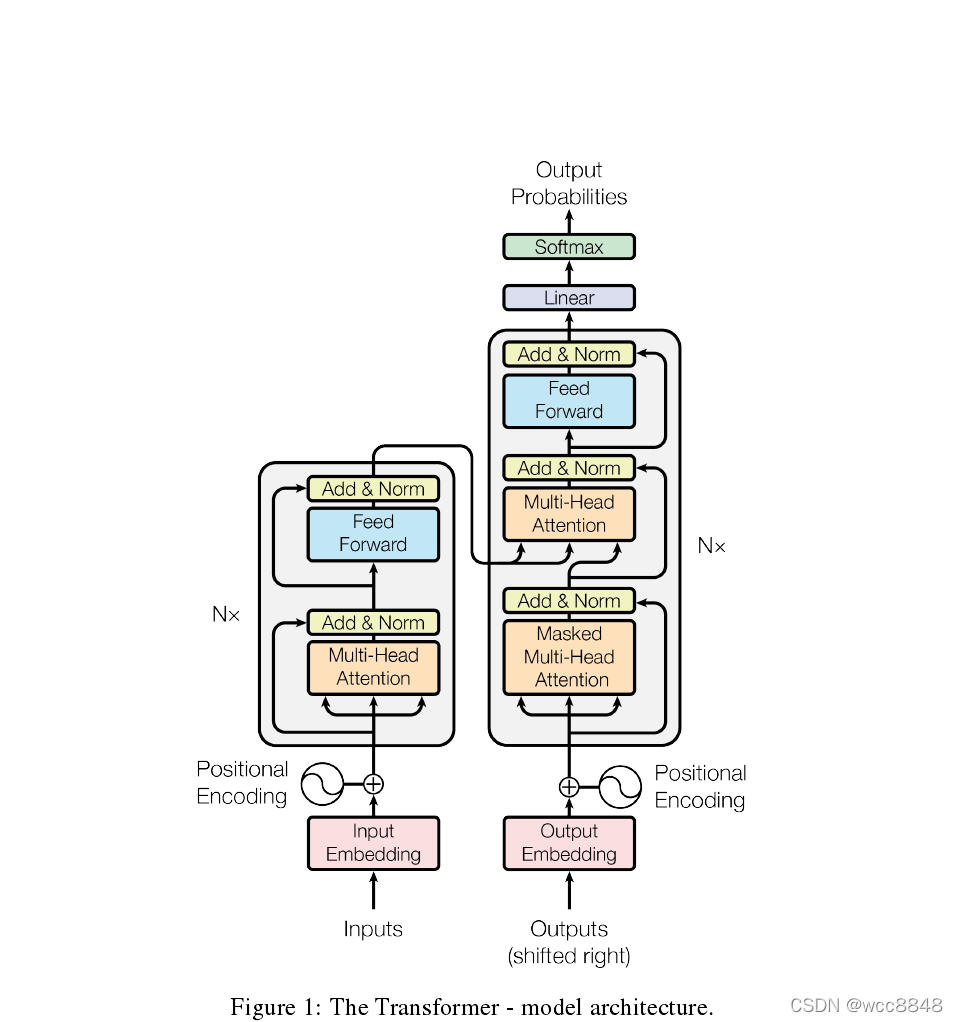
当前 token(Q)要从历史 token(K,V)里取多少信息?
-
Q:query,当前 token 的需求(我要什么)
-
K:key,每个历史 token 的标签(我是什么)
-
V:value,每个 token 的内容(信息本体)
why multi-head?
因为单一 attention 只能学一种"关注方式",多个 head 可以关注不同维度。
一个 head 看语法
一个 head 看语义
一个 head 看位置
叠起来模型表达能力更强
KV cache
推理生成时,每次生成一个 token,不可能把所有历史重新算一遍,所以需要把历史 token 的 Key 和 Value 保存下来,下次生成复用。
推理框架
| 框架 | 一句话总结 | 适用场景 |
|---|---|---|
| HuggingFace Transformers | 标准实现,易用但不快 | 基线测试 |
| vLLM | Continuous batching + PagedAttention → 高吞吐 | 多用户推理服务 |
| TensorRT-LLM | CUDA 图优化 + kernel 优化 → 最高性能 | NVIDIA GPU 生产部署 |
| llama.cpp | CPU/Mobile/Edge 推理 | 低资源设备 |
优先用 vLLM 做 serve 场景吞吐测试,再用 TensorRT-LLM 做极限性能测试。
vLLM
拿这个我用过的来说怎么加速的呢
-
PagedAttention:分页管理 KV Cache,避免内存碎片,使 batch 可以做得超大,这是最主要的加速点。
-
KV Cache 高效复用:每次生成只算增量 Attention,不重算历史。
-
高效调度器:动态把用户请求合并成大 batch,提高 GPU 利用率。
-
大量 fused CUDA kernels:减少 memory-bound 开销,更多算力用在 matmul 上。
多 GPU 并行
Tensor Parallel
把每层的矩阵拆开,分到多个 GPU 上一起算。
用于 大矩阵的分布式 matmul。
Pipeline Parallel
把模型的不同层放不同 GPU,每个 GPU 算一段。
适合 超长模型(如百层)。
Linux 基础命令
查看 CPU/GPU 利用率
top: 包括 CPU、内存使用情况、进程信息,常用于查看哪个进程占用 CPU 或内存高。
nvidia-smi:NVIDIA 显卡专用工具,显示 GPU 使用率、显存占用、运行的 GPU 进程等。
系统资源状态
ps:列出当前系统的进程信息。可结合参数 ps aux 或 ps -ef 显示详细进程状态。
lsof(List Open Files):查看当前系统打开的文件,包括网络连接、文件描述符等。常用于排查"文件被占用无法删除"问题。
df, du(Disk Free / Usage): 查看磁盘空间使用情况,显示各挂载点的总量、已用和剩余空间 /显示指定目录或文件占用的磁盘空间大小
free:查看内存使用情况,包括 RAM 和 swap。
文件/目录操作、权限修改、编译程序
chmod(Change Mode): 修改文件或目录权限(如可读、可写、可执行)
Python / Shell 脚本实操(2-3h)
-
写一个脚本:
-
批量运行一个小模型的推理(可以用 Hugging Face 的小模型,如 DistilBERT)
-
收集 GPU 利用率 / CPU 利用率 / 内存
-
输出 CSV 文件
-
熟悉 grep, awk, sed 处理日志文件