- 第一步:翻页抓包,这里没有无限debugger的干扰,经过在headers里面分过后发现这是post请求,请求参数有3个,均是动态,其中的token是我需要逆向的参数。
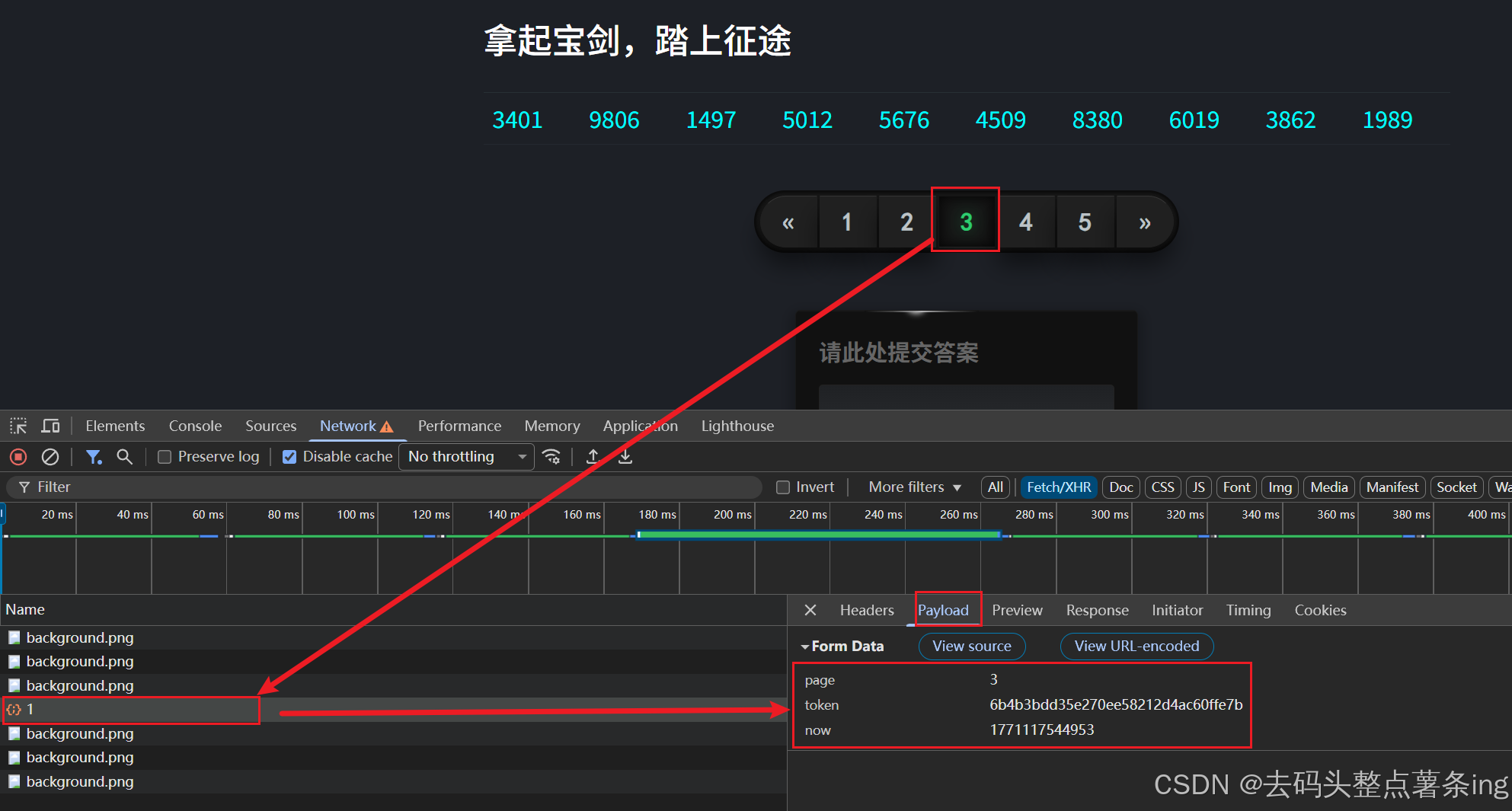
- 第二步:查找加密参数位置的方式有很多,我这里就直接看堆栈下断点进去跟了。
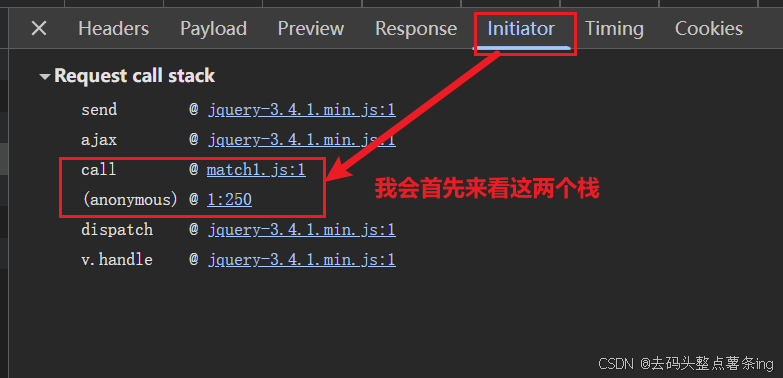
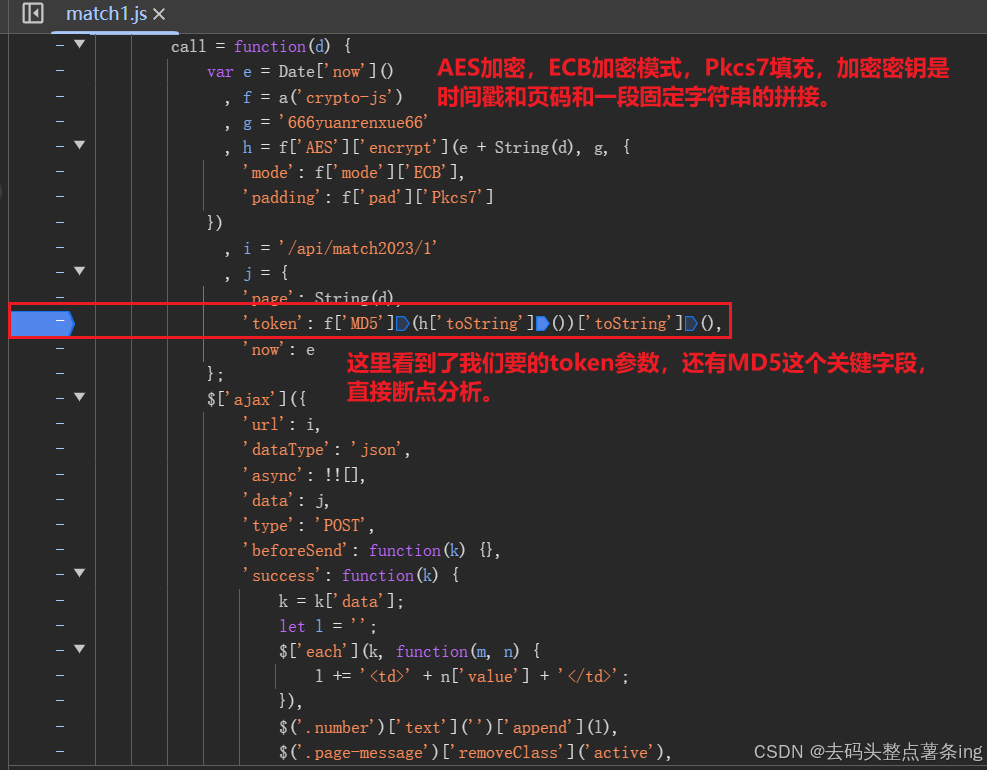
- 第三步:断点分析,跟出加密值token,从第二步进来后能看到的信息就很多了。
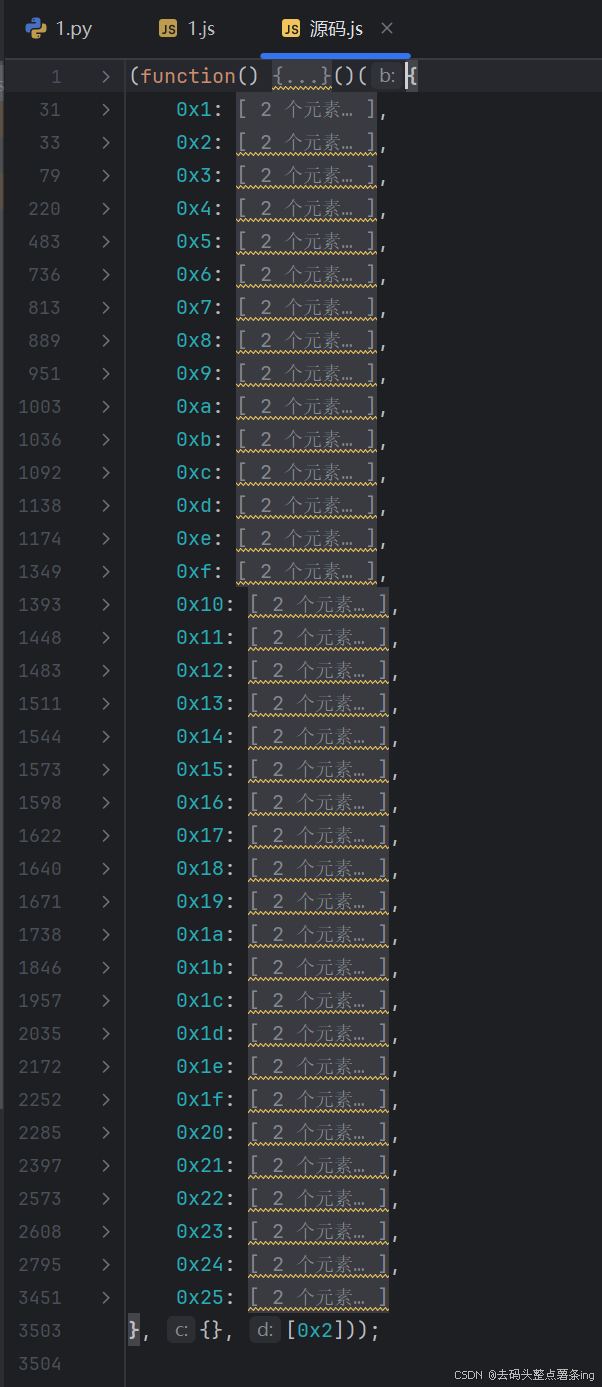
- 第四步:我在观察代码的时候无意间看见了这个js源码有点像webpack打包模式,于是我粘贴到pycharm上折叠看了一下,就是一个很明显的webpack打包,我就直接采用补环境来做这个题了。
- 第五步:在补环境之前我会先把需要的哪个加密参数全局化,然后打印输出,看看代码有什么报错的地方。
第一个报错在517行,我们直接到源码里面去观察。

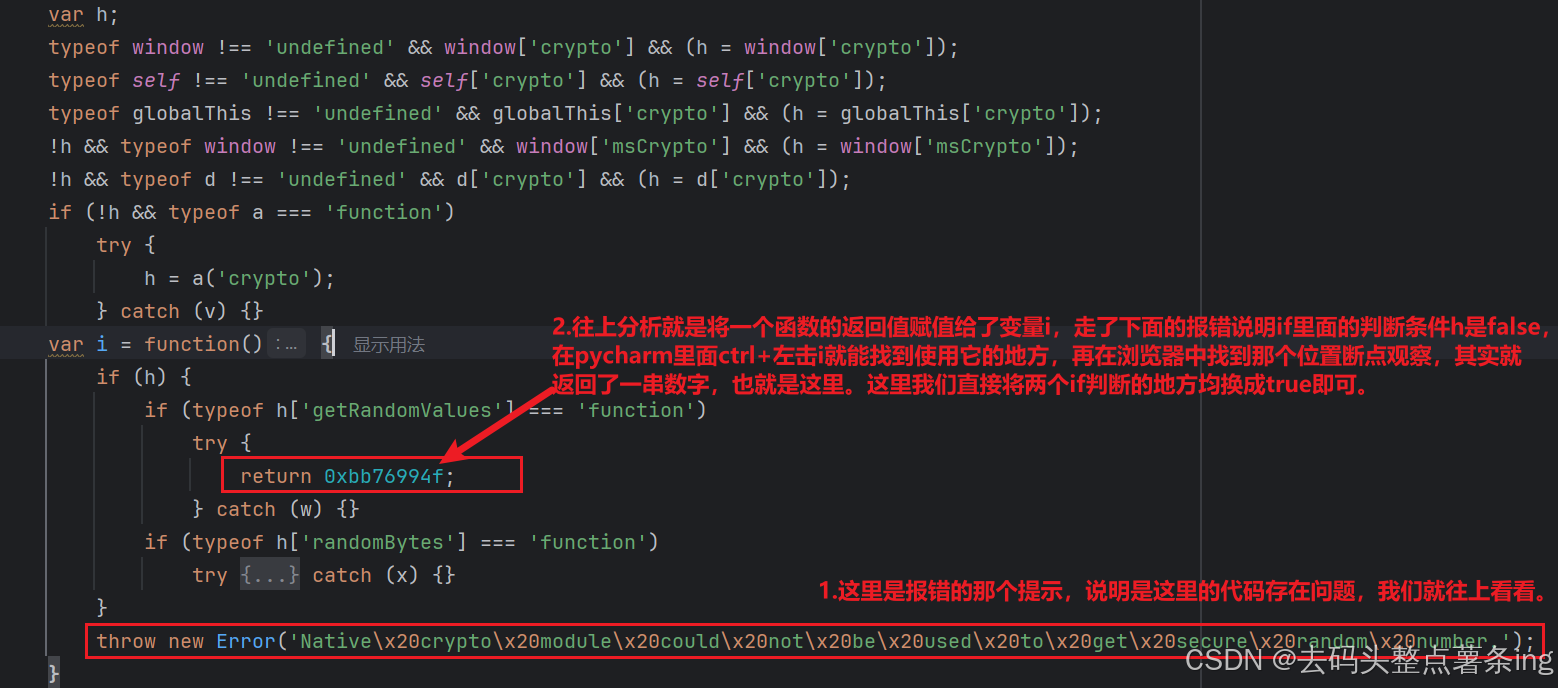
第二个报错也很好处理,因为我们不需要发送请求,所以我们直接将ajsx那段注释掉即可。
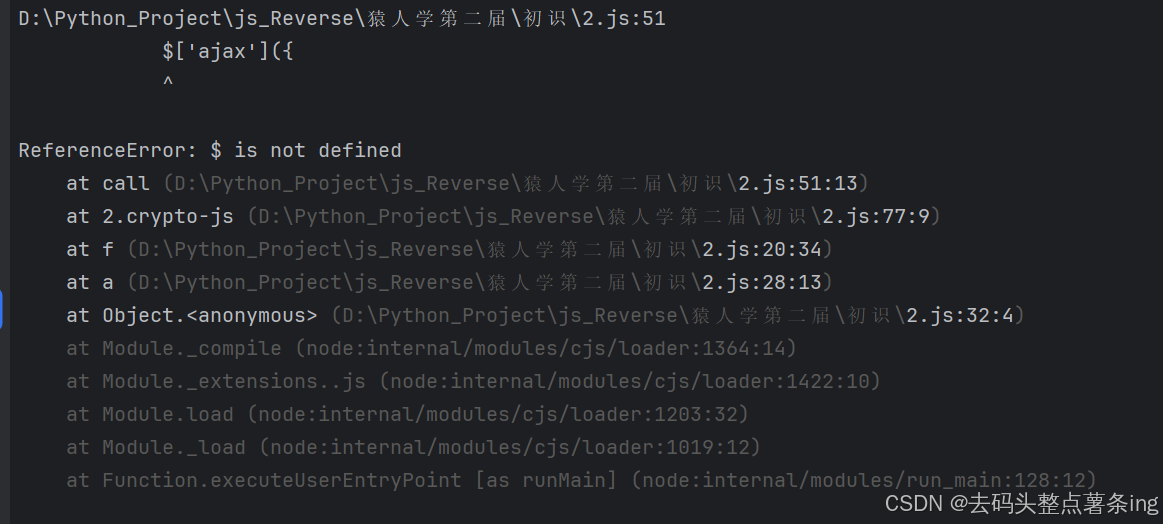
- 第六步:经过上面的初略修改,现在已经能出值了,但是我们不知道这个值对不对,所以我们去浏览器中拿一组正确的值过来固定上,和我们本地的值对比看看是否还有不足,这里自己去对比,我对比后token值是不对的,这个时候也没有报错了,我们就只有挂上吐环境代理看看是否缺少环境。
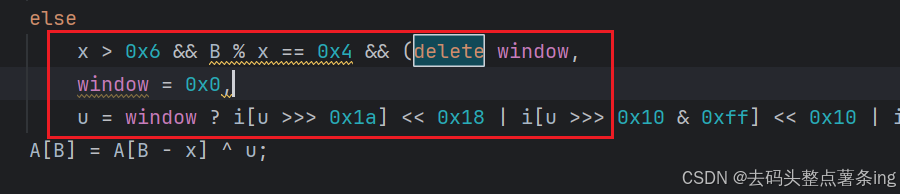
- 第七步:这里小补了一下环境,但是还是token值就是不对,这里就感觉在代码里面对环境做了手脚,我们全局搜索一下delete,很明显对window做了手脚,这也是刚开始我的疑惑点,我明明定义了window=global但是打印window对象的时候却是0,就是在这里应验了,但是这里的这样操作是不会在浏览器中成功删除window的,但是我们本地却能,所以我们这里直接将window改成1即可。
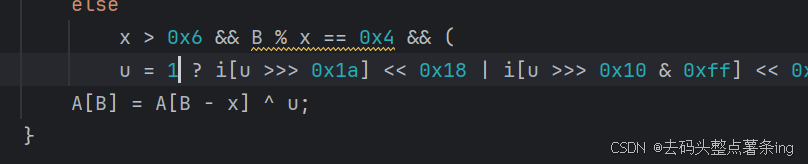
8.结尾: 在这里也就已经拿到对的token值了,接下来我把py代码放下面,js代码太多就不放了。
python
import requests
import execjs
class Spider(object):
def __init__(self):
self.headers = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-language": "zh-CN,zh;q=0.9",
"cache-control": "no-cache",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"origin": "https://match2023.yuanrenxue.cn",
"pragma": "no-cache",
"priority": "u=1, i",
"referer": "https://match2023.yuanrenxue.cn/topic/1",
"sec-ch-ua": "\"Not:A-Brand\";v=\"99\", \"Google Chrome\";v=\"145\", \"Chromium\";v=\"145\"",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "\"Windows\"",
"sec-fetch-dest": "empty",
"sec-fetch-mode": "cors",
"sec-fetch-site": "same-origin",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"x-requested-with": "XMLHttpRequest"
}
self.cookies = {
"Hm_lvt_2a795944b81b391f12d70da5971ba616": "1768524139,1770961193",
"HMACCOUNT": "E5BFF01C20A19C55",
"qpfccr": "true",
"no-alert3": "true",
"tk": "7760994193272813306",
"sessionid": "放你们自己的sessionid",
"Hm_lpvt_2a795944b81b391f12d70da5971ba616": "1770961235"
}
self.url = "https://match2023.yuanrenxue.cn/api/match2023/1"
with open('./1.js', 'r', encoding = 'utf-8') as f:
self.ctx = f.read()
def parse_url(self):
sum = 0
for page in range(1, 6):
replaced_js = self.ctx.replace('window_page;', f'window.page = {page};')
# print(replaced_js)
self.sign = execjs.compile(replaced_js).call('get_sign')
# print(self.sign)
data = {
"page": str(page),
"token": self.sign['token'],
"now": self.sign['now'],
}
response = requests.post(self.url, headers=self.headers, cookies=self.cookies, data=data).json()
print(response)
for item in response['data']:
sum += item['value']
print(sum)
if __name__ == '__main__':
s = Spider()
s.parse_url()