一、背景结论
本论文《Development and real-time implementation of a rule-based auto-focus algorithm》开发的基于规则的方法与常用的全局搜索和二进制搜索算法进行了比较。研究表明,引入的基于规则的搜索算法实现了更少的聚焦迭代次数或更快的聚焦速度,以及更少的步数或更低的功耗。
自动聚焦同样是分为两个部分,清晰度评价、峰值搜索。
1. 清晰度评价函数
论文采用 平方梯度(Squared-Gradient) 函数作为清晰度度量:
F=i=1∑Mj=1∑N(y(i,j+1)−y(i,j))2
2. 基于规则的峰值搜索算法(核心)
启发式规则动态调整步进电机步长,实现快速峰值搜索:
| 算法 | 平均迭代次数 | 平均步数 | 特点 |
|---|---|---|---|
| 全局搜索(Global Search) | 基准 | 基准 | 遍历所有位置,最慢但最可靠 |
| 二分搜索(Binary Search) | 中等 | 中等 | 假设单峰性,可能错过峰值 |
| 基于规则搜索(Rule-based) | 显著降低 | 显著降低 | 最快,功耗最低 |
关键结论:
- 基于规则算法在对焦速度 和功耗消耗两方面均优于传统方法
- 成功在DM310处理器上实现实时处理(满足1秒时限要求)
- 算法能可靠找到全局峰值,避免局部最大值陷阱
二、基于规则的峰值搜索方案前置分析
本文提出了一种基于规则的峰值搜索算法,并将其与两种标准峰值搜索算法进行了比较
基于全局和二分法峰值搜索
2.1 影响自动聚焦效果的因素
1)在任何搜索流程中,步进电机都是关键考量因素。论文中列举的镜头电机存在机械间隙问题。即镜头电机的往返运动会带来一定的误差,运动精度没那么精准。 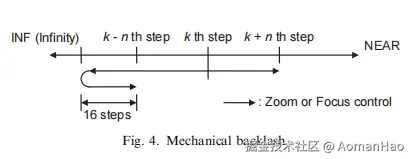
2)每次聚焦迭代的完成至少需要延迟空指令。当峰值搜索算法使用的聚焦迭代次数较少时,可实现更快的聚焦速度。减少延迟空指令次数
3)作为聚焦迭代的一部分,访问SDRAM内存是该迭代中最耗时的部分。处理部分图像数据减少计算量。
4)清晰度评价值表上,选择squared-gradient(平方梯度)
F=i=1∑Mj=1∑N(y(i,j+1)−y(i,j))2
2.2 减少图像数据计算
清晰度评价函数使用色彩滤波器图像的亮度部分来计算的。然而,使用RGB三原色中的所有数据来计算亮度,处理速度不够快。在大多数情况下,使用绿色分量即可提供足够的对比度信息用于对焦。
2.3 聚焦区域选择
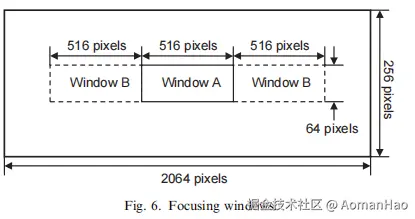
通常采用图像中心区域而非全幅图像。图6展示了本方案中覆盖图像中心区域的缩小图像尺寸。初始阶段使用图像数据的A窗口区域,若未检测到峰值,则会考虑B窗口区域的补充数据。
注:论文中相机sensor尺寸为2064×258。
三、基于规则的峰值搜索方案分析
3.1 Rule-based search
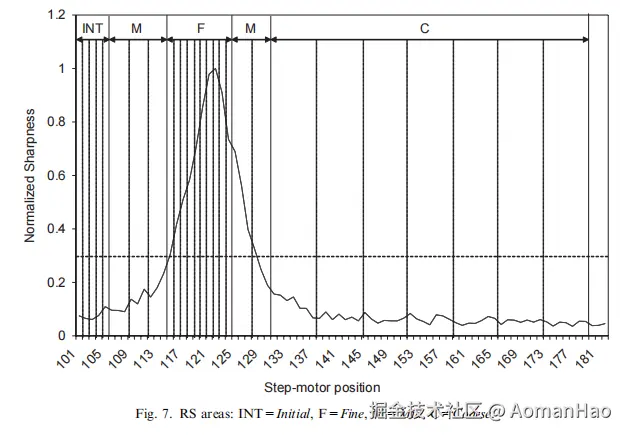
论文将聚焦范围划分为四种搜索区域:Initial(初始区)Fine(精细区), Mid(中区), Coarse(粗区)。
1)精细搜索区域对应包含全局峰值可能性较高的区域,该区域会逐个检查每个聚焦步进(即与镜头头步进电机相关的步骤)。
2)中区对应包含全局峰值可能性较低的区域,该区域每三到四个步进进行检查。
3)粗区对应包含全局峰值可能性极低的区域,该区域每七到十个步进进行检查。
所有方法均需先通过初始设置区域将步进电机移至起始位置,随后启动搜索程序,搜索示意图如下
3.2搜索过程伪代码
FCurrent:当前图像数据的锐度值
FPrevious:前一图像数据的锐度值
FMax:最大锐度值
CIteration:迭代计数器
AControl:控制区域(初始、精细、中等和粗略)
CDown:下坡计数器

相较于标准搜索方法,规则能更有效地捕捉特定镜头模块的特性
3.3 假峰
由于场景亮度波动等各类噪声的存在,清晰度评价函数在实际应用中会产生大量局部假峰值。这些假峰值可能导致搜索算法误入错误焦点区域。
论文通过a five-tap moving window卷积操作进行规避,文中没有说明具体操作。
常见的five-tap moving window是十字形 / 菱形(避免方形窗口的边缘伪影),包含中心像素 + 上下左右 4 个相邻像素(共 5 个),公式为:
I′(x,y)=w0⋅I(x,y)+w1⋅I(x−1,y)+I(x+1,y)+I(x,y−1)+I(x,y+1)
其中 w0+4w1=1(保证亮度守恒)
3.4 论文结果

标准全局搜索(GS)算法能确保找到全局峰值,且不会误判局部峰值。该算法始终生成相同数量的聚焦迭代次数。
而二分法(BS)算法会根据峰值位置生成不同次数的聚焦迭代,通常比全局搜索算法更快。但由于需要反复移动来获取锐度函数的峰值位置,其所需的回弹量会导致步骤过多或功耗增加。此外,该算法存在较高的误判风险,可能检测到局部峰值而非全局峰值。
如表1所示,与标准全局搜索和二分搜索算法相比,基于规则的算法(RS)在聚焦迭代次数和步骤数方面均表现最优。