你推出了一款新应用,用户每天都在注册。但这里有一个价值百万的问题:他们会回来吗?
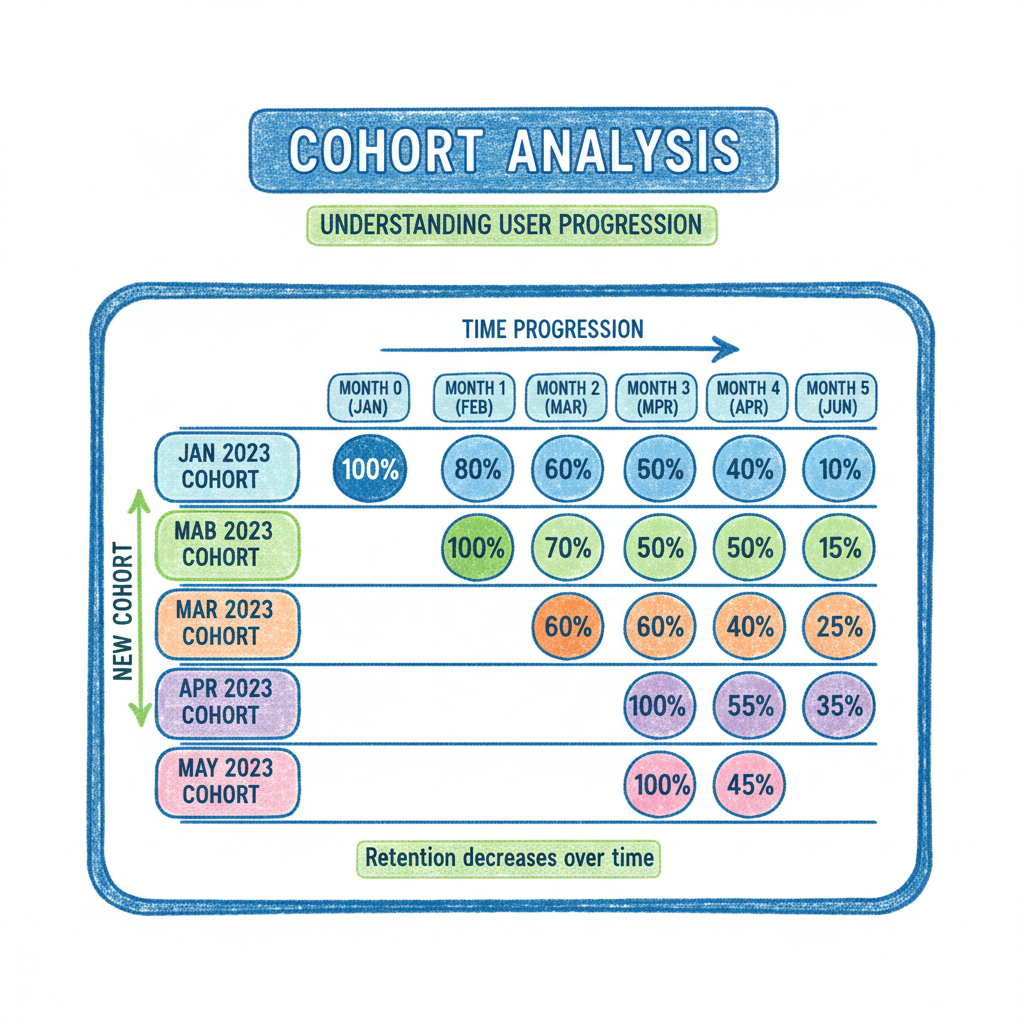
队列分析概览:展示不同队列(JAN 2023, MAB 2023, MAR 2023, APR 2023, MAY 2023)在不同月份的留存率变化
单一指标如"总活跃用户数"无法告诉你完整的故事。你需要知道:1月注册的用户在3月还活跃吗?他们比2月注册的用户更活跃吗?
这就是队列分析(Cohort Analysis)的用武之地------产品分析中最强大的技术之一。最棒的是?你可以完全用 SQL 来实现它。
什么是队列分析?
队列(Cohort)是一组在特定时间段内共享共同特征的用户。例如:
- 所有在 2024年1月 注册的用户
- 所有在 黑色星期五 首次购买的用户
队列分析 跟踪这些群体随时间的行为变化。最常见的用例是留存分析(Retention Analysis):衡量用户在首次互动后回归的百分比。
为什么队列分析很重要?
想象你正在运营一个 SaaS 产品。你注意到:
- 1月队列:60% 的用户在3个月后仍然活跃
- 2月队列:只有30% 的用户在3个月后仍然活跃
这告诉你1月和2月之间发生了一些变化。也许你发布了一个有 bug 的功能,或者你的入门流程出了问题。没有队列分析,你永远不会发现这一点。
队列分析的价值:
队列分析帮助你回答关键的业务问题,包括产品留存率评估、功能变更影响分析、用户生命周期价值预测以及流失预警和干预。通过对比不同时期的队列表现,你可以量化产品改进的效果,识别用户流失的关键节点,并制定更精准的用户运营策略。
数据模型
让我们使用一个简单的电商示例。我们有一个 user_activity 表,跟踪用户访问网站的时间:
示例数据:user_activity 表
| user_id | activity_date |
|---|---|
| 1 | 2024-01-05 |
| 1 | 2024-01-12 |
| 1 | 2024-02-03 |
| 2 | 2024-01-10 |
| 2 | 2024-01-15 |
| 3 | 2024-01-20 |
| 3 | 2024-02-10 |
| 3 | 2024-03-05 |
| 4 | 2024-02-05 |
| 4 | 2024-02-15 |
我们想回答:1月加入的用户中有多少百分比在2月回来了?
步骤 1:识别队列
首先,我们需要确定每个用户的队列------他们首次活跃的月份。
sql
SELECT
user_id,
DATE_TRUNC('month', MIN(activity_date)) AS cohort_month
FROM user_activity
GROUP BY user_id;查询结果:
| user_id | cohort_month |
|---|---|
| 1 | 2024-01-01 |
| 2 | 2024-01-01 |
| 3 | 2024-01-01 |
| 4 | 2024-02-01 |
结果解读 :用户 1、2、3 属于 2024年1月队列 ,用户 4 属于 2024年2月队列。
跨数据库语法:
| 数据库 | 月份截断语法 |
|---|---|
| PostgreSQL | DATE_TRUNC('month', activity_date) |
| MySQL | DATE_FORMAT(activity_date, '%Y-%m-01') |
| SQL Server | DATEFROMPARTS(YEAR(activity_date), MONTH(activity_date), 1) |
| SQLite | DATE(activity_date, 'start of month') |
步骤 2:计算活动周期
接下来,对于每次活动,我们计算自用户队列月份以来已经过去了多少个月。这被称为周期数(Period Number)。
sql
WITH cohorts AS (
SELECT
user_id,
DATE_TRUNC('month', MIN(activity_date)) AS cohort_month
FROM user_activity
GROUP BY user_id
)
SELECT
ua.user_id,
c.cohort_month,
DATE_TRUNC('month', ua.activity_date) AS activity_month,
(EXTRACT(YEAR FROM ua.activity_date) - EXTRACT(YEAR FROM c.cohort_month)) * 12
+ (EXTRACT(MONTH FROM ua.activity_date) - EXTRACT(MONTH FROM c.cohort_month)) AS period_number
FROM user_activity ua
JOIN cohorts c ON ua.user_id = c.user_id;查询结果:
| user_id | cohort_month | activity_month | period_number |
|---|---|---|---|
| 1 | 2024-01-01 | 2024-01-01 | 0 |
| 1 | 2024-01-01 | 2024-01-01 | 0 |
| 1 | 2024-01-01 | 2024-02-01 | 1 |
| 2 | 2024-01-01 | 2024-01-01 | 0 |
| 2 | 2024-01-01 | 2024-01-01 | 0 |
| 3 | 2024-01-01 | 2024-01-01 | 0 |
| 3 | 2024-01-01 | 2024-02-01 | 1 |
| 3 | 2024-01-01 | 2024-03-01 | 2 |
| 4 | 2024-02-01 | 2024-02-01 | 0 |
| 4 | 2024-02-01 | 2024-02-01 | 0 |
周期数说明:
- Period 0 = 队列月份(用户首次活跃的月份)
- Period 1 = 1个月后
- Period 2 = 2个月后
- 以此类推
工作原理:
- CTE cohorts:为每个用户计算队列月份(首次活跃月份)
- JOIN:将每次活动与用户的队列月份关联
- period_number 计算:使用年份和月份的差值计算周期数
步骤 3:构建留存矩阵
现在我们统计每个队列在每个周期有多少用户活跃。
sql
-- 完整的队列分析查询
WITH cohorts AS (
SELECT
user_id,
DATE(MIN(activity_date), 'start of month') AS cohort_month
FROM user_activity
GROUP BY user_id
),
user_periods AS (
SELECT
ua.user_id,
c.cohort_month,
DATE(ua.activity_date, 'start of month') AS activity_month,
(CAST(strftime('%Y', ua.activity_date) AS INTEGER) - CAST(strftime('%Y', c.cohort_month) AS INTEGER)) * 12
+ (CAST(strftime('%m', ua.activity_date) AS INTEGER) - CAST(strftime('%m', c.cohort_month) AS INTEGER)) AS period_number
FROM user_activity ua
JOIN cohorts c ON ua.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;查询结果:
| cohort_month | period_number | active_users |
|---|---|---|
| 2024-01-01 | 0 | 3 |
| 2024-01-01 | 1 | 2 |
| 2024-01-01 | 2 | 1 |
| 2024-02-01 | 0 | 1 |
结果解读:
- 2024-01-01, Period 0: 3个用户(所有1月注册的用户在1月都活跃)
- 2024-01-01, Period 1: 2个用户(3个1月注册用户中有2个在2月回来了)
- 2024-01-01, Period 2: 1个用户(3个1月注册用户中有1个在3月回来了)
- 2024-02-01, Period 0: 1个用户(2月注册的用户在2月活跃)
留存率计算公式:
留存率 = (Period N 的活跃用户数) / (Period 0 的活跃用户数) × 100%对于1月队列:
- Month 1 留存率: 2/3 = 67%
- Month 2 留存率: 1/3 = 33%
查询解析:
- cohorts CTE:识别每个用户的队列月份
- user_periods CTE:计算每次活动的周期数
- 最终查询:按队列月份和周期数分组,统计活跃用户数
可视化队列数据

留存热力图:使用颜色(绿色=高留存,红色=低留存)展示不同队列的留存率
在实践中,你会将这些数据导出到 Excel、Google Sheets 或 BI 平台来创建留存热力图:
| 队列 | Month 0 | Month 1 | Month 2 |
|---|---|---|---|
| 2024年1月 | 100% | 67% | 33% |
| 2024年2月 | 100% | 100% | 100% |
颜色编码:
- 绿色 = 高留存(80%+)
- 黄色 = 中等留存(50-80%)
- 红色 = 低留存(<50%)
热力图的价值:
热力图让你一眼就能看出哪些队列表现良好,哪些队列需要关注。例如,如果你看到某个队列的留存率突然下降,你可以立即调查那个时期发生了什么(产品变更、营销活动、外部事件等)。
高级:计算队列指标
一旦你有了队列结构,你可以计算其他指标:
每个队列的平均收入
sql
SELECT
c.cohort_month,
AVG(o.order_total) AS avg_revenue
FROM orders o
JOIN cohorts c ON o.user_id = c.user_id
GROUP BY c.cohort_month;示例数据:orders 表
| user_id | order_total | order_date |
|---|---|---|
| 1 | 100.00 | 2024-01-10 |
| 1 | 50.00 | 2024-02-05 |
| 2 | 200.00 | 2024-01-15 |
| 3 | 75.00 | 2024-01-25 |
| 4 | 150.00 | 2024-02-10 |
查询结果:
| cohort_month | avg_revenue |
|---|---|
| 2024-01-01 | 106.25 |
| 2024-02-01 | 150.00 |
业务洞察:2月队列的平均收入更高,可能是因为营销活动吸引了更高价值的用户。
流失率
sql
-- 在 Period 0 活跃但在 Period 1 不活跃的用户
SELECT
cohort_month,
COUNT(DISTINCT CASE WHEN period_number = 0 THEN user_id END) AS period_0_users,
COUNT(DISTINCT CASE WHEN period_number = 1 THEN user_id END) AS period_1_users,
1.0 - (COUNT(DISTINCT CASE WHEN period_number = 1 THEN user_id END) * 1.0 /
COUNT(DISTINCT CASE WHEN period_number = 0 THEN user_id END)) AS churn_rate
FROM user_periods
GROUP BY cohort_month;查询结果:
| cohort_month | period_0_users | period_1_users | churn_rate |
|---|---|---|---|
| 2024-01-01 | 3 | 2 | 0.33 |
| 2024-02-01 | 1 | 1 | 0.00 |
流失率解读:
- 1月队列:33% 的用户在第一个月后流失
- 2月队列:0% 的用户流失(所有用户都回来了)
流失率 vs 留存率:
- 流失率 = 1 - 留存率
- 流失率关注离开的用户,留存率关注留下的用户
用户生命周期价值(LTV)
sql
SELECT
c.cohort_month,
SUM(o.order_total) / COUNT(DISTINCT c.user_id) AS ltv
FROM cohorts c
LEFT JOIN orders o ON c.user_id = o.user_id
GROUP BY c.cohort_month;查询结果:
| cohort_month | ltv |
|---|---|
| 2024-01-01 | 141.67 |
| 2024-02-01 | 150.00 |
LTV 解读:每个1月队列用户平均贡献 141.67 的收入,而2月队列用户平均贡献 150.00。
最佳实践
1. 选择正确的队列窗口
月度队列很常见,但你也可以使用周度或日度队列,具体取决于产品的节奏。
队列窗口选择指南:
| 产品类型 | 推荐队列窗口 | 原因 |
|---|---|---|
| 快速迭代的移动应用 | 日度或周度 | 用户行为变化快,需要快速反馈 |
| SaaS 产品 | 月度 | 用户订阅周期通常是月度 |
| 电商平台 | 月度或季度 | 购买周期较长 |
| 社交媒体 | 周度 | 用户互动频繁 |
2. 明确定义"活跃"
用户"活跃"的定义是什么?登录?购买?与内容互动?保持一致。
活跃定义示例:
| 产品类型 | 活跃定义 |
|---|---|
| SaaS 产品 | 登录并使用核心功能 |
| 电商平台 | 浏览商品或购买 |
| 社交媒体 | 发布内容或互动(点赞、评论) |
| 内容平台 | 观看视频或阅读文章 |
错误示例:
sql
-- ❌ 不一致的活跃定义
SELECT * FROM user_activity WHERE login_count > 0 -- 有时用登录
SELECT * FROM user_activity WHERE purchase_count > 0 -- 有时用购买正确示例:
sql
-- ✅ 一致的活跃定义
SELECT * FROM user_activity WHERE engaged = TRUE -- 统一的活跃标志3. 使用 CTE 提高可读性
队列查询可能很复杂。用 CTE(Common Table Expressions)分步骤处理。
不推荐(一个巨大的嵌套查询):
sql
-- ❌ 难以阅读和维护
SELECT cohort_month, period_number, COUNT(DISTINCT user_id)
FROM (
SELECT ua.user_id, c.cohort_month, ...
FROM user_activity ua
JOIN (SELECT user_id, MIN(activity_date) AS cohort_month FROM user_activity GROUP BY user_id) c
ON ua.user_id = c.user_id
) sub
GROUP BY cohort_month, period_number;推荐(使用 CTE):
sql
-- ✅ 清晰、易读、易维护
WITH cohorts AS (...),
user_periods AS (...)
SELECT cohort_month, period_number, COUNT(DISTINCT user_id)
FROM user_periods
GROUP BY cohort_month, period_number;4. 使用视图自动化
创建视图以便分析师轻松查询队列逻辑。
sql
CREATE VIEW cohort_retention AS
WITH cohorts AS (
SELECT user_id, DATE_TRUNC('month', MIN(activity_date)) AS cohort_month
FROM user_activity
GROUP BY user_id
),
user_periods AS (
SELECT
ua.user_id,
c.cohort_month,
DATE_TRUNC('month', ua.activity_date) AS activity_month,
(EXTRACT(YEAR FROM ua.activity_date) - EXTRACT(YEAR FROM c.cohort_month)) * 12
+ (EXTRACT(MONTH FROM ua.activity_date) - EXTRACT(MONTH FROM c.cohort_month)) AS period_number
FROM user_activity ua
JOIN cohorts c ON ua.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users
FROM user_periods
GROUP BY cohort_month, period_number;使用视图:
sql
-- 分析师可以轻松查询
SELECT * FROM cohort_retention WHERE cohort_month = '2024-01-01';5. 处理数据质量问题
确保数据质量,避免重复记录和异常值。
sql
-- 去重
WITH clean_activity AS (
SELECT DISTINCT user_id, DATE(activity_date) AS activity_date
FROM user_activity
WHERE activity_date IS NOT NULL -- 过滤 NULL 值
AND user_id IS NOT NULL
)
SELECT * FROM clean_activity;实际应用场景
1. SaaS 产品留存分析
场景:你运营一个项目管理工具,想知道不同月份注册的用户的留存情况。
查询:
sql
WITH cohorts AS (
SELECT user_id, DATE_TRUNC('month', MIN(signup_date)) AS cohort_month
FROM users
GROUP BY user_id
),
user_periods AS (
SELECT
l.user_id,
c.cohort_month,
DATE_TRUNC('month', l.login_date) AS activity_month,
(EXTRACT(YEAR FROM l.login_date) - EXTRACT(YEAR FROM c.cohort_month)) * 12
+ (EXTRACT(MONTH FROM l.login_date) - EXTRACT(MONTH FROM c.cohort_month)) AS period_number
FROM logins l
JOIN cohorts c ON l.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;业务洞察:如果你发现某个月的队列留存率特别低,可以调查那个月发生了什么(产品变更、营销活动、竞争对手动作等)。
2. 电商平台购买队列
场景:你想知道首次购买用户的复购率。
查询:
sql
WITH cohorts AS (
SELECT user_id, DATE_TRUNC('month', MIN(order_date)) AS cohort_month
FROM orders
GROUP BY user_id
),
user_periods AS (
SELECT
o.user_id,
c.cohort_month,
DATE_TRUNC('month', o.order_date) AS activity_month,
(EXTRACT(YEAR FROM o.order_date) - EXTRACT(YEAR FROM c.cohort_month)) * 12
+ (EXTRACT(MONTH FROM o.order_date) - EXTRACT(MONTH FROM c.cohort_month)) AS period_number
FROM orders o
JOIN cohorts c ON o.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS repeat_buyers
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;业务洞察:复购率是电商的关键指标。如果某个队列的复购率低,可能需要改进产品质量或客户服务。
3. 内容平台用户参与度
场景:你运营一个视频平台,想知道不同队列的用户观看频率。
查询:
sql
WITH cohorts AS (
SELECT user_id, DATE_TRUNC('month', MIN(watch_date)) AS cohort_month
FROM video_watches
GROUP BY user_id
),
user_periods AS (
SELECT
vw.user_id,
c.cohort_month,
DATE_TRUNC('month', vw.watch_date) AS activity_month,
(EXTRACT(YEAR FROM vw.watch_date) - EXTRACT(YEAR FROM c.cohort_month)) * 12
+ (EXTRACT(MONTH FROM vw.watch_date) - EXTRACT(MONTH FROM c.cohort_month)) AS period_number,
vw.watch_duration_minutes
FROM video_watches vw
JOIN cohorts c ON vw.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users,
AVG(watch_duration_minutes) AS avg_watch_time
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;业务洞察:观看时长是参与度的重要指标。如果某个队列的观看时长下降,可能需要改进内容推荐算法。
4. 移动应用会话队列
场景:你想知道不同队列的用户会话频率。
查询:
sql
WITH cohorts AS (
SELECT user_id, DATE_TRUNC('month', MIN(session_start)) AS cohort_month
FROM app_sessions
GROUP BY user_id
),
user_periods AS (
SELECT
s.user_id,
c.cohort_month,
DATE_TRUNC('month', s.session_start) AS activity_month,
(EXTRACT(YEAR FROM s.session_start) - EXTRACT(YEAR FROM c.cohort_month)) * 12
+ (EXTRACT(MONTH FROM s.session_start) - EXTRACT(MONTH FROM c.cohort_month)) AS period_number
FROM app_sessions s
JOIN cohorts c ON s.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users,
COUNT(*) AS total_sessions,
COUNT(*) * 1.0 / COUNT(DISTINCT user_id) AS sessions_per_user
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;业务洞察:会话频率反映用户粘性。如果某个队列的会话频率低,可能需要改进推送通知或应用内提示。
跨数据库实现
不同数据库的队列分析实现略有不同,主要是日期函数的差异。
PostgreSQL
sql
WITH cohorts AS (
SELECT
user_id,
DATE_TRUNC('month', MIN(activity_date)) AS cohort_month
FROM user_activity
GROUP BY user_id
),
user_periods AS (
SELECT
ua.user_id,
c.cohort_month,
DATE_TRUNC('month', ua.activity_date) AS activity_month,
(EXTRACT(YEAR FROM ua.activity_date) - EXTRACT(YEAR FROM c.cohort_month)) * 12
+ (EXTRACT(MONTH FROM ua.activity_date) - EXTRACT(MONTH FROM c.cohort_month)) AS period_number
FROM user_activity ua
JOIN cohorts c ON ua.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;MySQL
sql
WITH cohorts AS (
SELECT
user_id,
DATE_FORMAT(MIN(activity_date), '%Y-%m-01') AS cohort_month
FROM user_activity
GROUP BY user_id
),
user_periods AS (
SELECT
ua.user_id,
c.cohort_month,
DATE_FORMAT(ua.activity_date, '%Y-%m-01') AS activity_month,
TIMESTAMPDIFF(MONTH, c.cohort_month, ua.activity_date) AS period_number
FROM user_activity ua
JOIN cohorts c ON ua.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;SQL Server
sql
WITH cohorts AS (
SELECT
user_id,
DATEFROMPARTS(YEAR(MIN(activity_date)), MONTH(MIN(activity_date)), 1) AS cohort_month
FROM user_activity
GROUP BY user_id
),
user_periods AS (
SELECT
ua.user_id,
c.cohort_month,
DATEFROMPARTS(YEAR(ua.activity_date), MONTH(ua.activity_date), 1) AS activity_month,
DATEDIFF(MONTH, c.cohort_month, ua.activity_date) AS period_number
FROM user_activity ua
JOIN cohorts c ON ua.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;SQLite
sql
WITH cohorts AS (
SELECT
user_id,
DATE(MIN(activity_date), 'start of month') AS cohort_month
FROM user_activity
GROUP BY user_id
),
user_periods AS (
SELECT
ua.user_id,
c.cohort_month,
DATE(ua.activity_date, 'start of month') AS activity_month,
(CAST(strftime('%Y', ua.activity_date) AS INTEGER) - CAST(strftime('%Y', c.cohort_month) AS INTEGER)) * 12
+ (CAST(strftime('%m', ua.activity_date) AS INTEGER) - CAST(strftime('%m', c.cohort_month) AS INTEGER)) AS period_number
FROM user_activity ua
JOIN cohorts c ON ua.user_id = c.user_id
)
SELECT
cohort_month,
period_number,
COUNT(DISTINCT user_id) AS active_users
FROM user_periods
GROUP BY cohort_month, period_number
ORDER BY cohort_month, period_number;性能优化
队列分析查询可能很慢,特别是对于大型数据集。以下是一些优化建议:
1. 添加索引
sql
-- 为 user_id 和 activity_date 添加索引
CREATE INDEX idx_user_activity_user_date ON user_activity(user_id, activity_date);2. 使用物化视图
sql
-- 创建物化视图(PostgreSQL)
CREATE MATERIALIZED VIEW cohort_retention_mv AS
WITH cohorts AS (...),
user_periods AS (...)
SELECT * FROM user_periods;
-- 定期刷新
REFRESH MATERIALIZED VIEW cohort_retention_mv;3. 分区表
sql
-- 按月份分区(PostgreSQL)
CREATE TABLE user_activity (
user_id INT,
activity_date DATE,
...
) PARTITION BY RANGE (activity_date);
CREATE TABLE user_activity_2024_01 PARTITION OF user_activity
FOR VALUES FROM ('2024-01-01') TO ('2024-02-01');4. 限制时间范围
sql
-- 只分析最近 12 个月的数据
WITH cohorts AS (
SELECT user_id, DATE_TRUNC('month', MIN(activity_date)) AS cohort_month
FROM user_activity
WHERE activity_date >= CURRENT_DATE - INTERVAL '12 months'
GROUP BY user_id
)
...结论
队列分析对于理解用户随时间的行为至关重要。通过根据用户加入时间对用户进行分组并跟踪他们的活动,你可以:
- 衡量留存率并识别流失点
- 比较队列以查看产品变更的影响
- 预测流失并在用户离开之前采取行动
而且使用 SQL,你可以完全控制分析------无需等待第三方工具添加你需要的功能。
关键要点:
- 队列分析的核心是将用户按首次互动时间分组,跟踪他们的后续行为
- 三步法:识别队列 → 计算周期数 → 构建留存矩阵
- 留存率是最重要的指标,但你也可以计算收入、流失率、LTV 等
- 最佳实践:选择合适的队列窗口、明确定义"活跃"、使用 CTE、创建视图
- 跨数据库:主要差异在于日期函数,核心逻辑相同
- 性能优化:索引、物化视图、分区表、限制时间范围
现在去构建一些队列吧!📊
相关文章推荐
- SQL for Data Analysis: The Ultimate Guide
- Calculating Percentiles and Median in SQL
- Ranking Data with SQL: RANK, DENSE_RANK, and ROW_NUMBER Explained
版权声明 :本文转载自 SQL Boy,原文链接:https://www.hisqlboy.com/blog/cohort-analysis-with-sql