
⚡⚡⚡ 新年新文⚡⚡⚡
文章目录
-
- [1,Wan.video 万相线上平台讲解与实操](#1,Wan.video 万相线上平台讲解与实操)
- 2,图生视频、视频首尾帧及视频特效功能讲解与演示
- 3,图像参考、视频转绘及局部编辑功能讲解及演示
1,Wan.video 万相线上平台讲解与实操
万相网址:https://tongyi.aliyun.com/wan/explore
万相集成了多模态生成能力,为用户提供从基础创作到高阶设计的完整工具链。在基础功能层面,它支持文生图、文生视频、图生视频,首尾帧生视频及视频特效,进阶功能则包含图像参考,视频重绘及局部编辑,这些功能既满足日常创作需求,又能为更复杂的专业场景提供创新解决方案,激发创意灵感。
1.1,核心功能模块
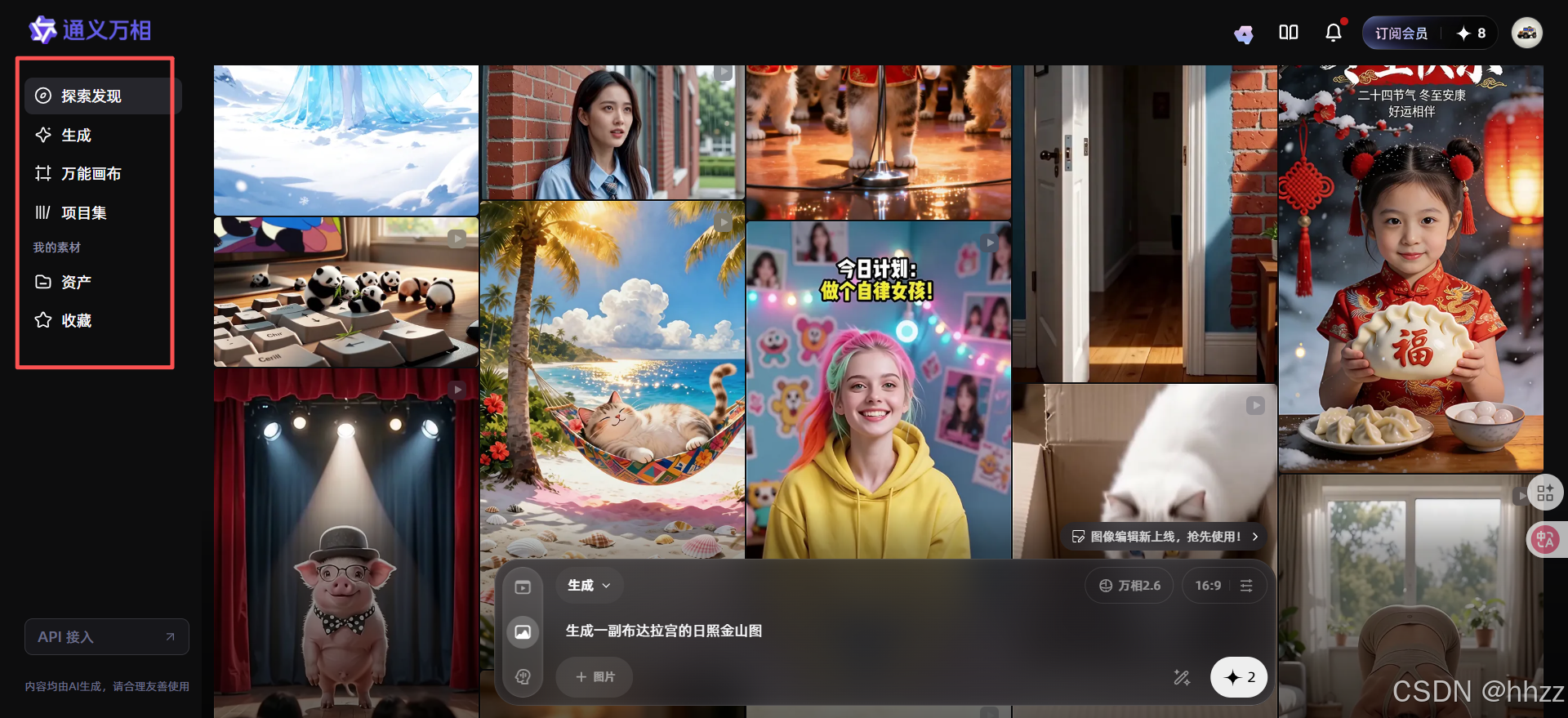
万相的产品功能分成了三大模块。
- 模块1 - 探索发现(Explore):
在这里我们可以看到万相最新的动态以及创作者们生成的各式各样的优秀案例,这可以为我们带来许多的创作灵感。 - 模块2 - 创作模块(Create):
创作模块(Create)包含了生成及项目集两部分。
在生成(Generate)部分中,用户可以看到自己当前的生成记录,通过鼠标滚轮下滑还可以看到过往的素材列表。
在项目集(Project)中,用户可以以项目为单位进行素材生产,并传送到时间轴上进行串联编辑,为进阶创作者提供更沉浸的工作空间。 - 模块3 - 我的素材(Library):
我的素材(Library)模块包含了资产及收藏两部分。
在资产(Assets)中我们可以批量管理生成记录。
在收藏(Favorites)部分我们可以管理点赞作品。
1.2,WanBox操作
在屏幕下端的这个模块,它有一个非常神奇的名称WanBox。它就像一个魔法盒子,集成了万相目前所有的生成功能。
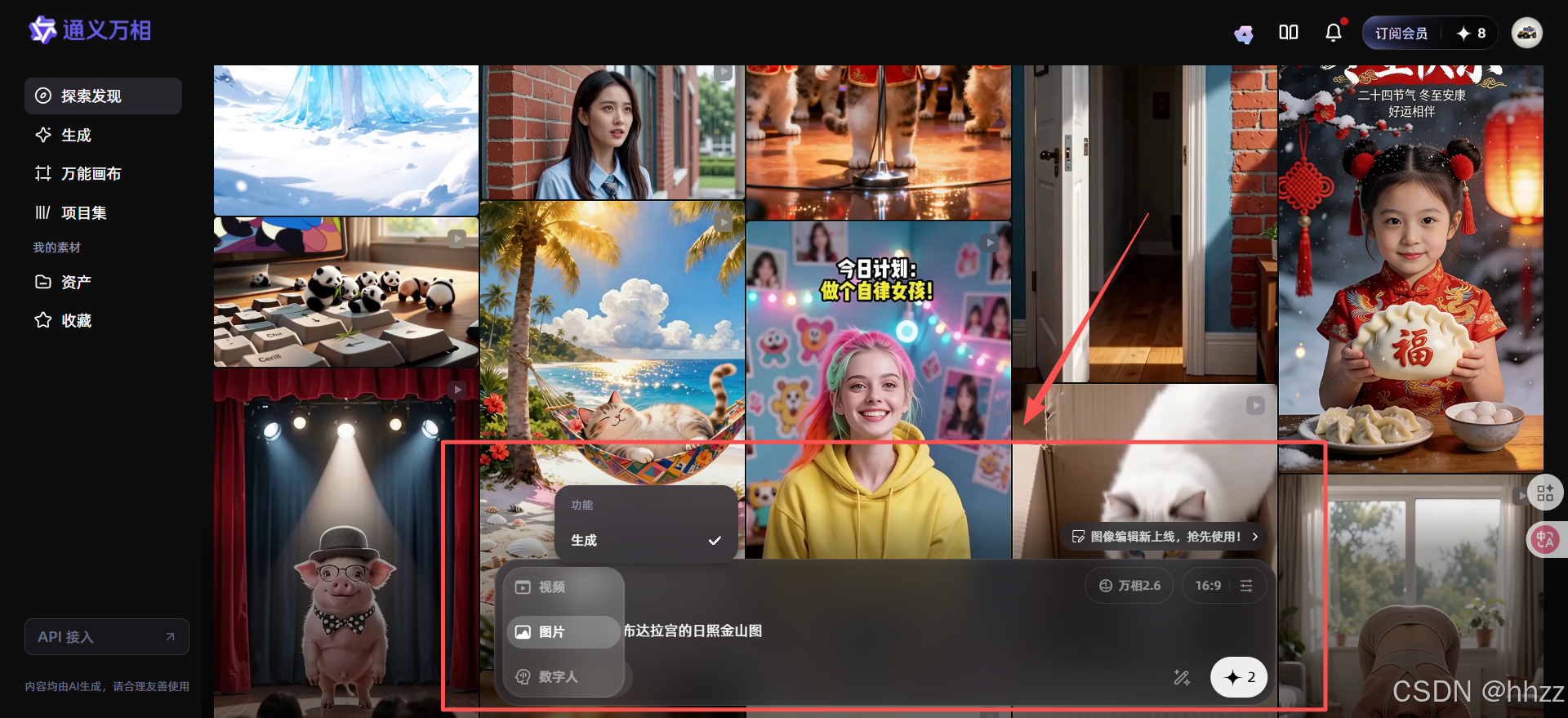
- 图像
- 视频
- 数字人
2,图生视频、视频首尾帧及视频特效功能讲解与演示
高效创作高质量视频。通过图生视频功能,仅需首帧图像与提示词即可生成动态画面,摆脱传统逐帧制作的限制;视频首尾帧衔接技术实现流畅转场,支撑影视级镜头语言;内置多种视频特效模板,一键应用专业级视觉效果,大幅降低后期门槛。课程结合实操演示,展示AI在影视广告、创意短片等场景中的应用,助你以更低的成本实现艺术化视频创作,推动AI技术在视觉工业中的深度落地。
2.1,图生视频
我们展开WanBox,选择视频(Video),再选择图生视频(Image to Video),图生视频的基础原理顾名思义就是结合首帧图加提示词的方式去生成视频,我们选择Wan2.2的模型,其余参数我们保持默认,接着上传一张我们提前准备好的首帧图,这幅画面描述了一位金发碧眼的欧美男人看着一颗即将掉落的苹果,随后输入我们的提示词,这里我希望我上传的参考图里的苹果掉落。
● 原理:结合首帧图像与提示词生成动态视频
● 操作步骤:
○ 在WanBox中选择视频(Video)→图生视频(Image to Video)
○ 加载模型(如Wan2.2)并保持默认参数
○ 上传首帧图像(示例:金发男人注视掉落苹果)
○ 输入提示词(如苹果掉落)并生成
万相在视频生成领域的三大核心能力:图生视频、首尾帧生视频与视频特效。图生视频结合首帧图像与提示词,精准控制物理规律(如重力模拟)与艺术风格;首尾帧生视频通过输入起止帧自动生成中间过渡,有效应对复杂转场与大角度运镜;预设的视频特效模板支持一键复用,显著提升后期效率。
2.2,首尾帧生视频
我们切换到首尾帧生视频(First and Last Frame),用户可以通过上传首帧和尾帧图像,AI将自动生成中间过渡画面。该技术可处理连续动作、大角度转场等复杂场景,已广泛应用于AI影视创作。当前Wan2.2暂未开放此功能,系统会自动调用Wan2.1 plus模型,后续将升级支持。那么在这里我们上传一张探险者正面作为首帧,她转身望向星球的图片作为尾帧,示例提示词可简单输入"镜头环绕",我们一起看看效果。
● 原理:通过首帧与尾帧图像自动生成中间过渡内容
● 应用场景:
○ 连续动作衔接(如转身、运镜)
○ 大幅度转场(如场景切换)
● 操作限制:
○ 当前仅支Wan2.1 plus模型(Wan2.2后续更新)
● 操作步骤:
○ 选择视频(Video)→首尾帧生视频(First and Last Frame)
○ 上传首帧(探险者面对镜头)与尾帧(转身望向星球)
○ 输入提示词(如镜头环绕)并生成
3,图像参考、视频转绘及局部编辑功能讲解及演示
万相视频创作的三大核心能力:图像参考、视频重绘与局部编辑。图像参考支持跨风格元素融合,突破原始素材限制;视频重绘实现动态内容与艺术风格的精准匹配,拓展视觉表达维度;局部编辑则在保留视频整体结构的前提下,完成细节级精准优化。
3.1,图像参考功能解析
它的基本使用方法就是用户可以上传一到两张参考图,通过识别参考图中的主体或背景,结合提示词生成融合主体与背景的视频。
3.2,视频重绘功能详解
它的基本使用方法是参考用户上传视频的整体构图或者视频内人物姿态,并结合上传图片的画面风格或者主体特征,进行视频重绘,这里的构图(Depth)是AI参考视频的景深信息生成的灰度图像,姿态(Pose)是AI参考视频中人物关节和四肢的动态生成的动态骨骼。
● 构图模式:
-
基于视频灰度图像(景深信息)保留原始构图
-
迁移参考图的风格特征(如人物服饰、色调)
● 姿态模式:
-
提取视频动态骨骼(关节与四肢运动)
-
保留动作姿态,替换主体特征(如服装、形象)
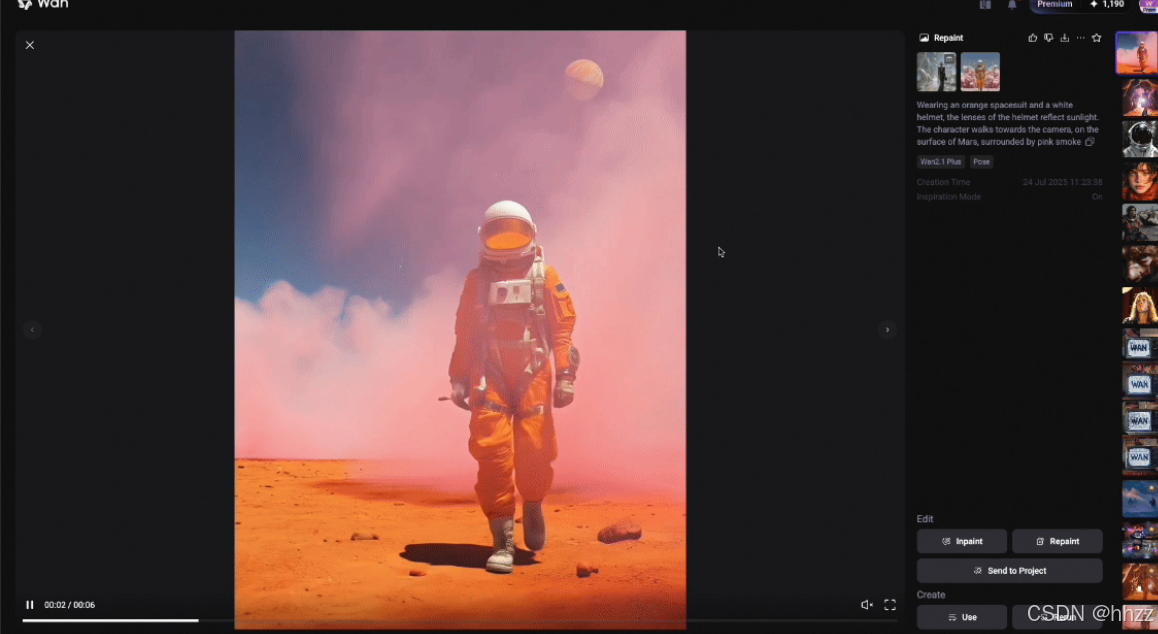
3.3,局部编辑功能操作指南
局部编辑(Inpaint),相较于视频重绘(Repaint)的对整体画面的修改,局部编辑更聚焦原有视频画面中某一处的重新绘制,比如说有一段你认为不错的视频,但是其中某个角落的物品或人物动态有一点瑕疵,那么你就可以使用这个功能来完成局部画面的再绘制,这里的姿态(Pose)我们可以理解为,在一段视频中,如果有某个人物形象不符合预期,但是他的动作又是符合标准,那么我们就可以固定住他的动作,只更换他的形象。
● 核心价值:针对视频中特定区域进行精准重绘,保留其他画面完整性
● 典型应用:
○ 修正瑕疵(如背景杂乱、人物形象不符)
○ 动态替换(如骑骆驼→骑马)
3.4,操作建议
- 图像参考:
○ 主体图需保证背景简洁(提升识别精度)
○ 提示词需明确主体动作与环境关系 - 视频重绘:
○ 构图模式适合风格统一需求,姿态模式适合动作复用
○ 参考图需包含目标特征(如服装、配色) - 局部编辑:
○ 手动涂抹可纠正自动识别误差
○ 提示词需具体描述替换目标(如"马匹"而非模糊描述)
通过万相的图像参考、视频重绘与局部编辑功能,实现从整体构图到细节调整的全流程视频创作。图像参考功能分离主体与背景,支持跨场景精准融合;视频重绘提供构图与姿态两种模式,在保留画面结构的同时满足风格迁移需求;局部编辑则支持像素级修改,提升细节控制精度。
感谢阅读,下期更精彩 👋👋👋
