前言
上一节我们简要介绍了Prometheus和Grafana的安装流程,本节我们将重点探讨系统监控的重要性以及Prometheus的原理和实际配置。
为什么要使用Prometheus监控系统?
微服务架构的普及使系统组件间的交互日益复杂。建立完善的监控系统,对及时发现故障、定位性能瓶颈以及提升系统可观测性至关重要,已成为现代微服务体系的标配。
本文以主流开源监控系统Prometheus为核心,结合Grafana的可视化功能,系统性地介绍从原理到实践的微服务监控方案构建方法。
一、监控的基本概念
监控系统是用于采集、处理、存储和展示系统运行状态信息的专业工具,主要实现以下核心功能:
- 实时监测系统健康状态
- 快速诊断和定位故障
- 通过历史数据分析优化性能
- 实现智能预警机制,防患于未然
在微服务架构环境下,由于服务数量庞大且状态变化频繁,传统监控方案已难以应对复杂的运维需求。因此,构建高效、灵活且具备良好扩展性的监控系统变得至关重要。
二、监控系统的工作原理
完整的监控系统主要由以下核心环节构成:
-
数据采集
从各类系统、服务和网络设备中获取监控指标数据
-
数据存储
采用时序数据库存储采集的监控数据
-
数据处理
对原始监控数据进行聚合计算和格式转换
-
数据展示
通过可视化图表和仪表盘呈现监控信息
-
告警管理
配置告警规则并支持多渠道告警通知(邮件/短信/电话/企业微信机器人/飞书等)
三、 Prometheus 基本介绍
Prometheus 是一个开源监控系统解决方案,集成了监控告警和时间序列数据库功能。该系统最初由 SoundCloud 开发,现已成为 CNCF(云原生计算基金会)的核心项目之一。
其主要特点包括:
- 采用 HTTP 协议周期性拉取(pull)监控目标的指标数据
- 原生支持 Docker、Kubernetes 等云原生环境
- 提供灵活的可视化集成能力(如 Grafana),并配备强大的查询语言 PromQL
📌 Prometheus 的 pull 模式相比传统的 push 模式更安全、更可控,也便于管理大规模服务的监控目标。
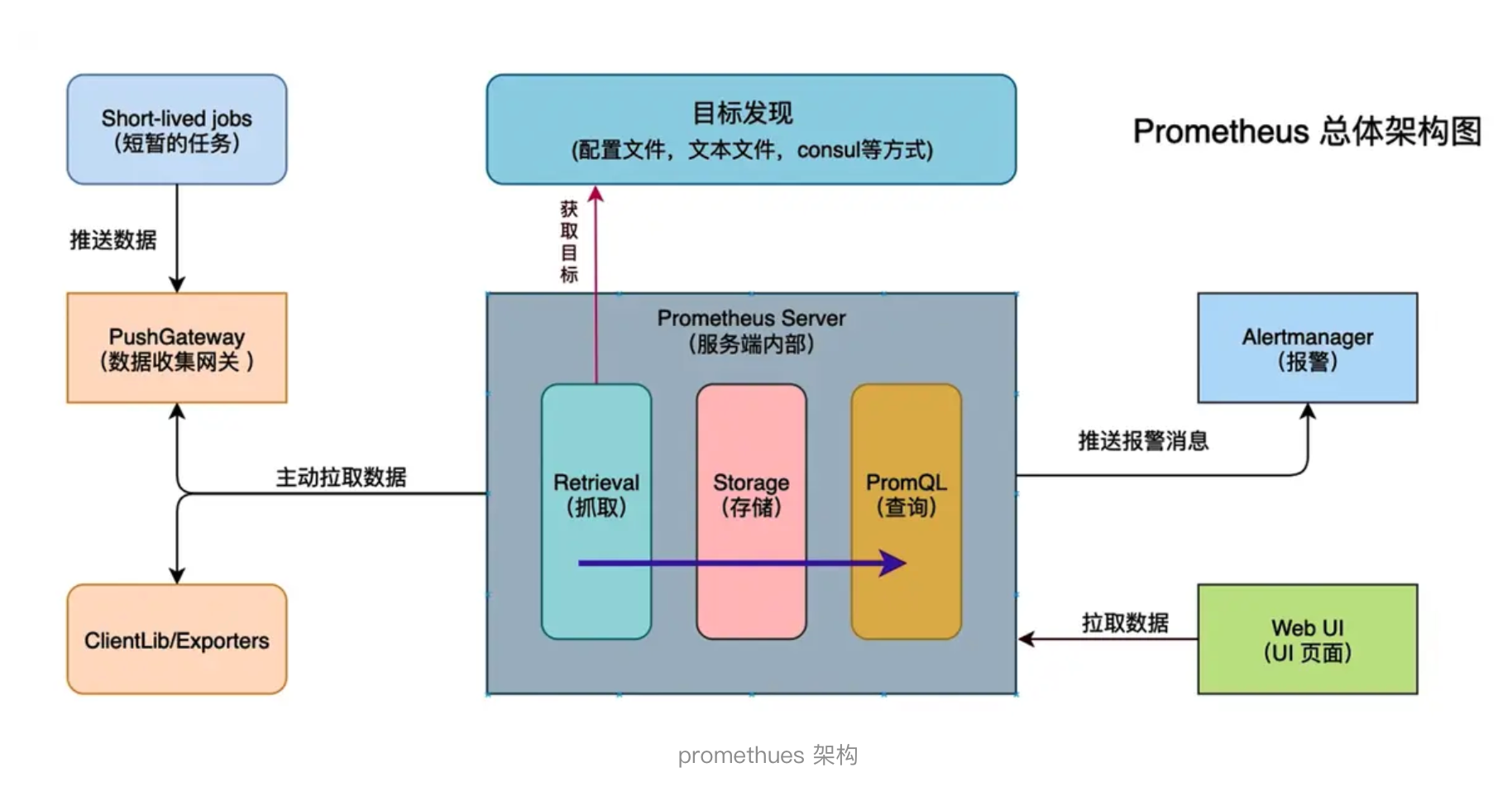
四、Prometheus 的组件
构建 Prometheus 监控体系,需要了解它的核心组件:
| 组件名称 | 功能说明 |
|---|---|
| Prometheus Server | 负责从配置的目标中定期拉取监控数据,存储为时间序列数据库,并根据报警规则生成告警。 |
| Client Library | 应用侧接入的客户端库,用于生成并暴露自定义 metrics。 |
| Push Gateway | 用于短生命周期的任务(如 CI Job)的 metrics 上报。 |
| Exporters | 用于将第三方系统(如 Node、MySQL、Redis)暴露为 Prometheus 可识别的格式。 |
| Alertmanager | 负责处理 Prometheus 发出的警报,包括去重、分组、路由和通知等操作。 |
五、Prometheus 的工作流程
Prometheus 的核心运行流程如下:
-
数据采集
Prometheus Server 按照预设周期从配置的 jobs/exporters 以及 Pushgateway 主动拉取监控数据
-
数据存储
采集的指标数据会被存储为带时间戳的时间序列数据
-
告警检测
当监控指标触发预设的告警规则时,系统会自动生成告警事件并推送至 Alertmanager
-
告警处理
Alertmanager 根据配置的策略对告警进行去重、分组等处理,最终通过指定渠道发送告警通知
-
可视化展示
用户可通过 Prometheus 原生 Web UI 或集成 Grafana 进行指标数据的可视化分析和查询
六、Prometheus 相关核心概念
1. 数据模型
-
所有数据都以**时间序列(Time Series)**形式存储。
-
每条时间序列由 metric 名称 + 一组标签(labels) 唯一标识。
-
标签采用键值对形式,可灵活描述来源、服务、节点等维度。
http_requests_total{method="GET", handler="/api/getUserById"} 1000
上述表示 /api/getUserById 接口的 GET 请求次数为 1000。
2. 指标(Metrics)类型
Prometheus 支持四种主要的 metric 类型:
| 类型 | 描述 | 示例 |
|---|---|---|
| Counter | 单调递增,只能加不能减(除非重启),如请求数、错误数 | http_requests_total |
| Gauge | 可增可减,表示当前状态值,如温度、内存使用量 | cpu_usage |
| Histogram | 统计数据分布,可用于生成柱状图 | request_duration_seconds_bucket |
| Summary | 提供观测值的总数、总和与分位数 | request_duration_seconds_sum |
3. Instance 和 Jobs
- Instance:一个监控目标(通常是一个进程实例)。
- Job:一组逻辑上相同的 instance,用于批量管理和配置。
例如监控一组ES机器配置如下:
scrape_configs:
- job_name: "node"
static_configs:
- targets: ["192.168.1.10:9100", "192.168.1.11:9100", "192.168.1.12:9100"]上面配置中,job_name 是 node,它包含三个 instance。
七、Grafana:完美的可视化搭档
尽管 Prometheus 提供了基础 Web UI,但在生产环境中,Grafana 是更优的可视化解决方案。
Grafana 的核心优势包括:
- 提供丰富的预设仪表盘模板,可快速适配各类监控需求
- 具备强大的图表编辑功能,完美支持 PromQL 查询
- 兼容多种数据源(包括 Prometheus、InfluxDB、Elasticsearch 等)
- 拥有完善的权限管理机制,满足企业级部署要求
🎯 实践经验:在团队中可以根据业务类型定制多个 Grafana Dashboard,例如 API 性能监控、数据库指标面板、Kubernetes 节点资源情况等,提高运维效率。
八、Prometheus + Grafana 安装和配置
目标:监控一个spring boot 应用prometheusapp的接口性能,prometheus.yml 的配置如
bashglobal: scrape_interval: 15s scrape_configs: - job_name: "prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: - targets: ["127.0.0.1:9090"] - job_name: 'prometheusapp' metrics_path: '/actuator/prometheus' static_configs: - targets: ['host.docker.internal:8080']
本地Docker 安装prometheus
bash
yangyanping@yangyaningdeAir bin % docker pull prom/prometheus
yangyanping@yangyaningdeAir bin % docker run -d --restart always --name prometheus -p 9090:9090 -v /data/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus
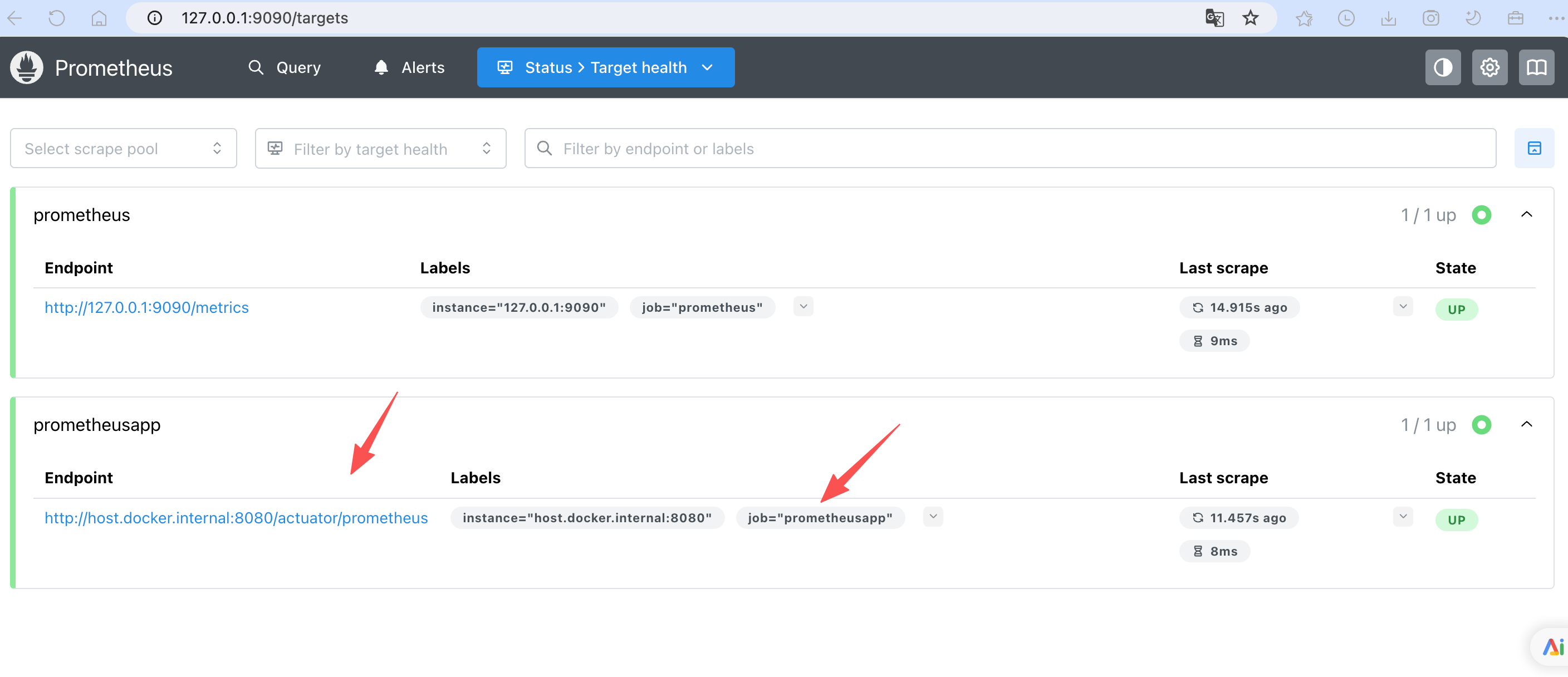
63af249b69223c410e989c254246876906d6855e9d3400fc250895d059e9abca访问地址: http://127.0.0.1:9090/, 选择 status 栏目下的 Target health ,查看应用的监控状态信息。
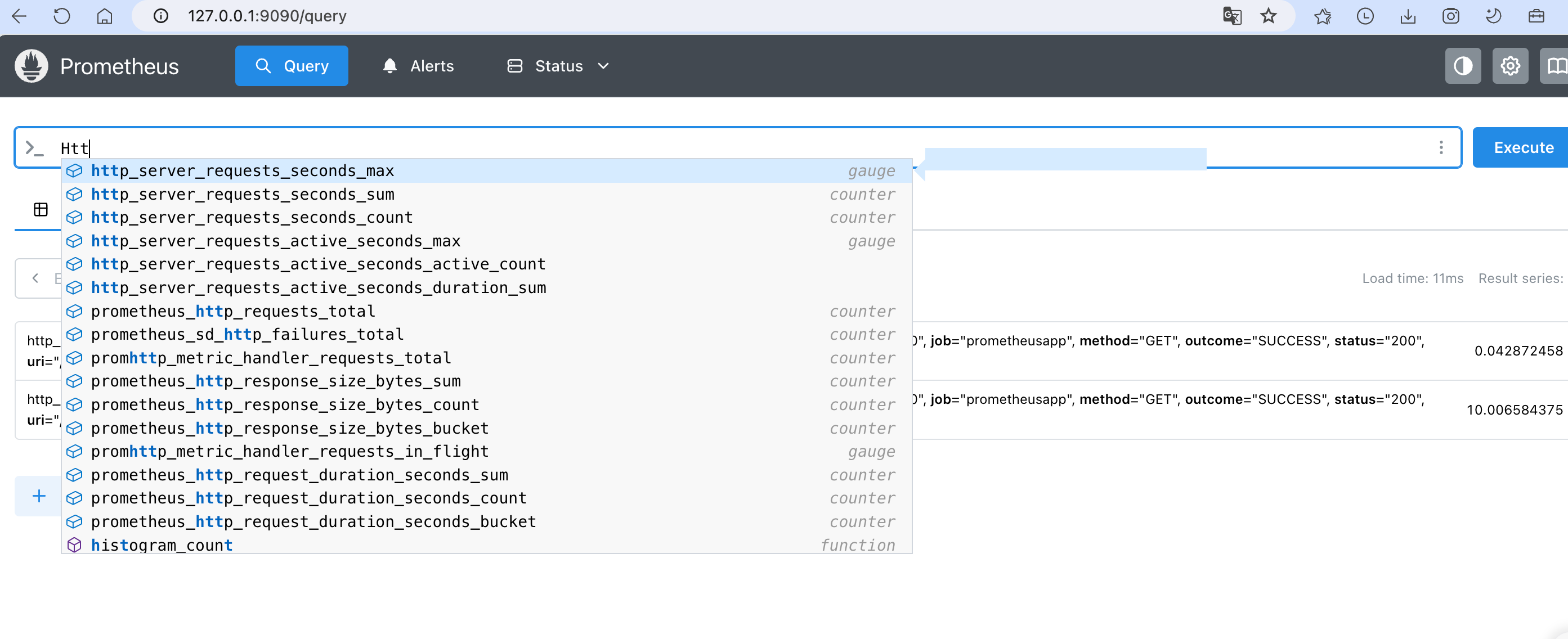
访问一下服务接口 http://127.0.0.1:8080/hello,然后查询接口的Http监控信息
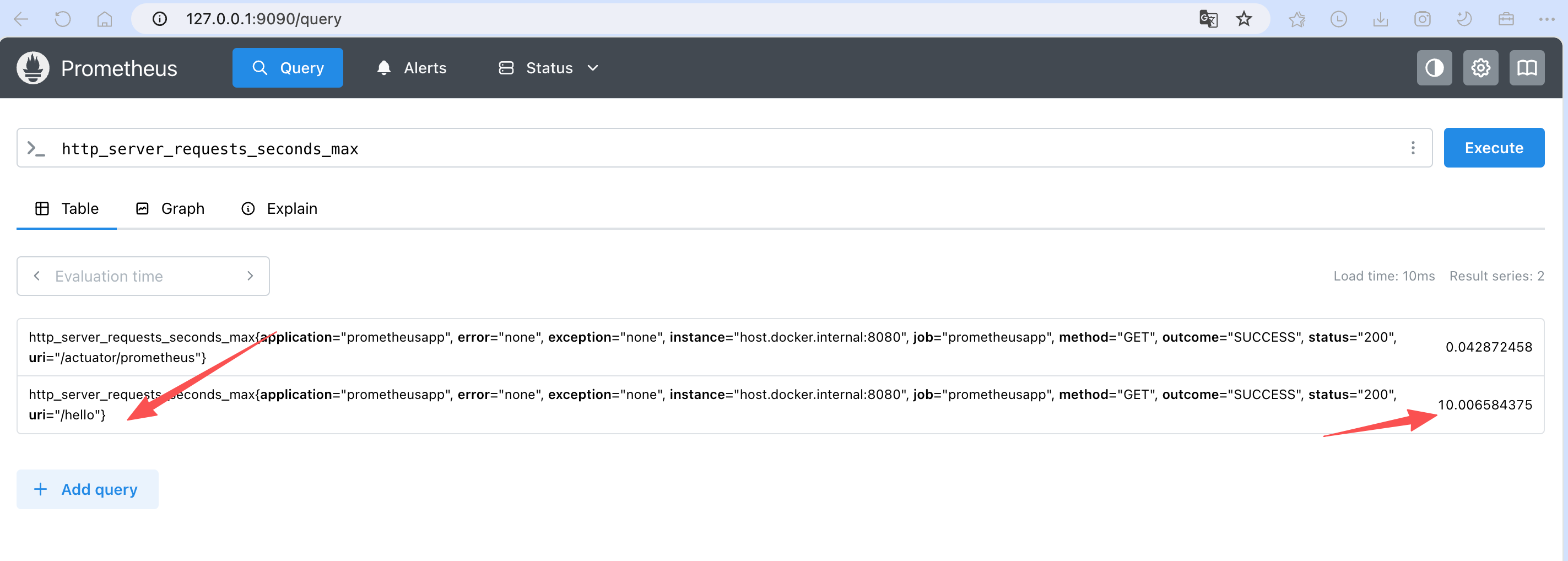
安装Grafana
bash
yangyanping@yangyaningdeAir bin % docker pull grafana/grafana
yangyanping@yangyaningdeAir bin % docker run -d --name=grafana -p 3000:3000 grafana/grafana
0d93609ed1f8140b2f078c78c2633936d7674a617ad27137da4c03751bcd52a4访问地址:http://127.0.0.1:3000/, 然后添加数据源