循环神经网络(RNN):AI怎么"听懂"语音?
从"翻译一句话"看RNN的价值
想象你正在翻译一句话:"I love eating apples"。如果逐词翻译:
- "I"→"我","love"→"爱","eating"→"吃","apples"→"苹果"
结果会是"我爱吃苹果"------完美通顺。
但如果遇到歧义句:"I saw the man with a telescope",逐词翻译就会出问题:
- 是"我用望远镜看到了那个男人",还是"我看到了那个带着望远镜的男人"?
人类能通过上下文理解消除歧义,但普通神经网络做不到------它把每个词当成独立输入,忽略了词与词之间的顺序和依赖关系。
RNN(Recurrent Neural Network,循环神经网络) 的诞生就是为了解决这个问题:它像记笔记一样,能记住前面出现的词,用上下文推断后面的含义。
为什么普通神经网络"记不住"上下文?
普通神经网络(如CNN)处理数据时像"一次性快照":
- 输入一张图片或一个词 → 输出结果 → 清空所有中间状态
- 就像考试时做完一道题就忘记解题思路,无法把前面的知识用到后面的题目中。
而语言、语音、视频这些序列数据,上下文至关重要:
- 语音识别:听到"h"后,"e"的概率远高于"x"(因为"he"是常见组合)
- 机器翻译:"苹果"在中文里是水果,但在"苹果公司"中是品牌
- 股价预测:今天的价格和昨天、上周的价格密切相关
RNN的解决方案是:在网络中加入"循环",让信息在处理过程中传递------就像说话时,每说一个字都会参考前面说过的内容。
RNN的"记忆循环":像传送带一样传递信息
基本结构:带"回路"的神经网络
想象一个普通神经元有两个输入:
- 当前输入:比如一句话中的"吃"这个词
- 记忆输入:从"爱"这个词传递过来的信息
处理完"吃"后,神经元会把"我爱吃"的组合信息通过循环回路传递给下一个神经元,帮助处理"苹果"这个词。
这个"回路"就是RNN的核心:它让网络能把过去的信息带到现在,就像你边听故事边在脑海里整理剧情。
用"传话游戏"理解RNN工作流程
幼儿园的传话游戏:
- 老师悄悄告诉小明:"今天下午吃草莓蛋糕"
- 小明记住这句话,传给小红时说:"今天下午吃..."
- 小红结合自己听到的和小明的记忆,完整复述:"今天下午吃草莓蛋糕"
RNN处理一句话的过程完全一样:
- 时间步1:输入"我",网络记住"我"的信息
- 时间步2:输入"爱",结合"我"的记忆 → "我爱"
- 时间步3:输入"吃",结合"我爱"的记忆 → "我爱吃"
- 时间步4:输入"苹果",结合"我爱吃"的记忆 → 最终理解"我爱吃苹果"
每一步的输出都依赖于当前输入 和历史记忆,这就是"循环"的意义。
RNN的"失忆症":为什么需要LSTM?
短期记忆的困境
标准RNN有个严重问题:记不住太久远的信息。
- 处理一句话时,它能记住前3-5个词,但如果句子很长(比如50个词),前面的信息会逐渐"遗忘"。
- 就像你听讲座时,能记住前5分钟的内容,但听完1小时后,开头讲了什么可能已经模糊。
这是因为反向传播时会出现"梯度消失":调整早期参数时,梯度(误差信号)经过多步传递后几乎衰减为0,导致网络学不到长期依赖关系。
LSTM:带"笔记本"的RNN
LSTM(Long Short-Term Memory,长短期记忆网络)是RNN的"升级版",它像带分页笔记本的学生:
- 普通RNN:只有一个"临时草稿本",记满了就擦掉重写
- LSTM:有专门的"长期笔记本"(细胞状态)和"临时草稿区"(隐藏状态),重要信息记在笔记本里,临时信息写在草稿上
LSTM通过三个"门"控制信息流动:
- 遗忘门:决定哪些长期记忆可以丢掉(比如听完一段故事后,忘记不重要的细节)
- 输入门:决定哪些新信息需要存入长期记忆(比如记住故事的关键转折点)
- 输出门:决定哪些记忆需要输出到下一个时间步(比如用关键转折点预测后续剧情)
有了这三个门,LSTM能轻松记住几百个词的上下文,彻底解决RNN的"健忘症"。
生活中的RNN:不止"听懂语音"
案例1:语音转文字(Speech to Text)
你的手机能把语音转成文字,背后是LSTM在工作:
- 语音信号是连续的声波,LSTM按时间片处理:
- 第10ms听到"sh"音 → 记忆"sh"
- 第20ms听到"uo"音 → 结合"sh"记忆 → "sh-uo=说"
- 第30ms听到"hua"音 → 结合"说"记忆 → "说话"
- 即使你说话有口音、语速快,LSTM也能通过上下文纠正错误(比如把"灰机"纠正为"飞机")。
案例2:机器翻译(Machine Translation)
Google翻译能把中文翻译成英文,靠的是"编码器-解码器"RNN:
- 编码器:用LSTM把"我爱中国"编码成向量(记住语义)
- 解码器:根据这个向量,逐词生成"I love China"
- 关键:解码器会参考已生成的词(比如生成"I"后,更可能生成"love"而不是"eat")。
案例3:自动写代码(GitHub Copilot)
当你输入"for i in range(10):",Copilot能自动补全循环体,因为:
- RNN学习了 millions 行代码的上下文模式
- 它知道"for循环"通常跟着"print(i)"或"list.append(i)"
- 就像老程序员看到"for"就知道下一步该写什么。
RNN vs CNN:各有所长的"兄弟"
| 网络类型 | 擅长处理 | 核心优势 | 典型应用 |
|---|---|---|---|
| RNN | 序列数据(文字、语音、视频) | 能记住上下文,处理时间依赖 | 翻译、语音识别、股价预测 |
| CNN | 空间数据(图片、图像) | 擅长提取局部空间特征 | 人脸识别、医学影像、自动驾驶 |
结合使用:比如视频理解的模型会先用CNN提取每一帧的图像特征,再用RNN分析帧与帧之间的时间关系,实现动作识别。
为什么Transformer会取代RNN?
尽管RNN在NLP领域长期占据主导地位,但近年来被Transformer(如BERT、GPT)取代,原因是RNN有两个致命缺点:
- 无法并行计算:必须按顺序处理,速度慢;
- 长文本处理能力仍有限,而Transformer通过自注意力机制能同时处理所有词之间的关系。
不过,RNN在实时性要求高的场景(如语音识别)中仍被广泛使用。
小问题:为什么说LSTM的"遗忘门"是最关键的创新?
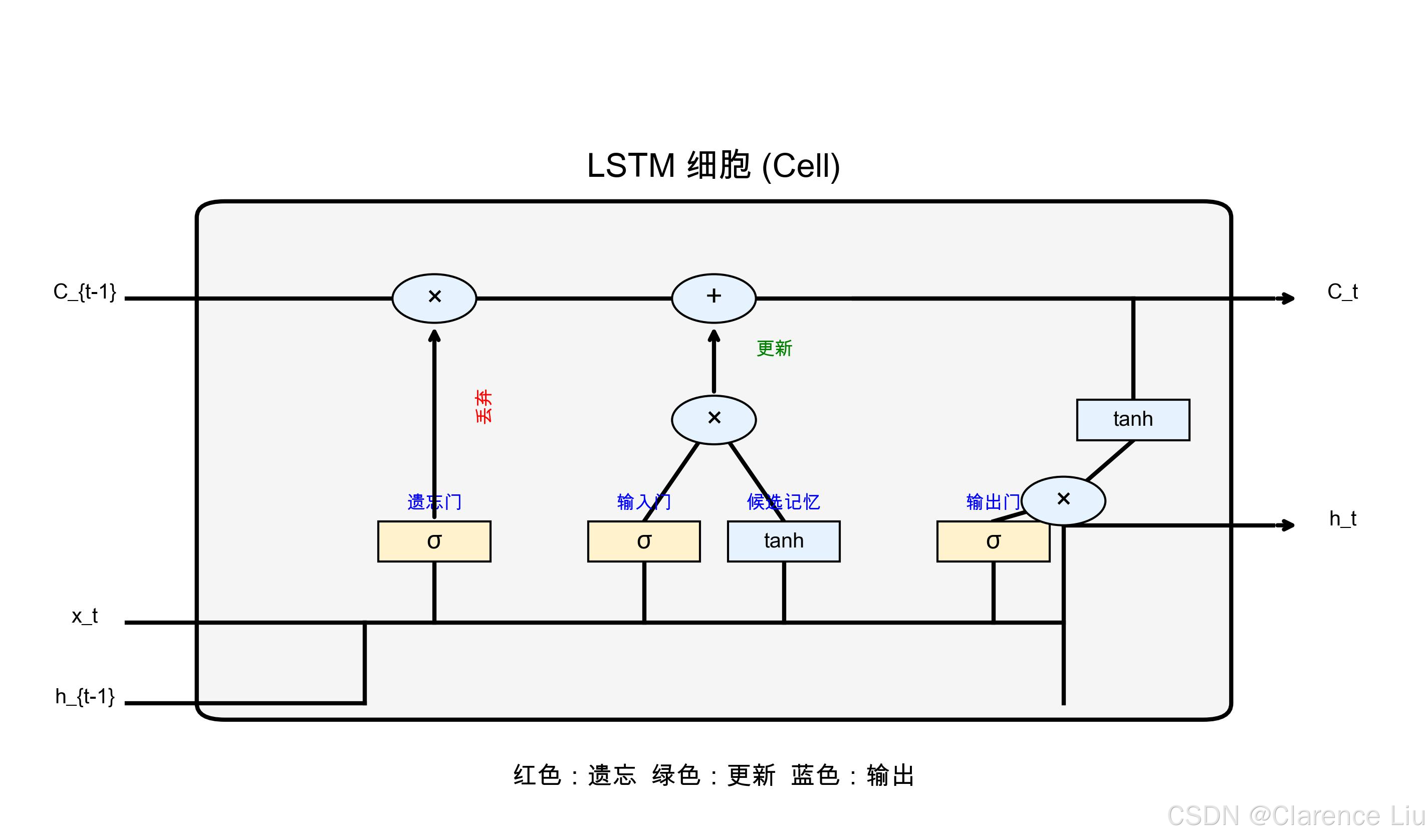
(提示:传统RNN无法主动忘记无关信息,导致"信息过载"。遗忘门能有选择地保留关键信息,就像整理衣柜时丢掉不需要的旧衣服,腾出空间装新衣服。)
下一篇预告:《Transformer模型:让AI真正理解上下文》------用"注意力机制"解释为什么GPT能写出连贯的文章。