卷积神经网络(CNN):AI怎么"看懂"图片?
从"拼图游戏"理解CNN的工作方式
想象你在玩一幅1000片的猫咪拼图。如果直接把所有碎片倒在桌上,你肯定一脸懵。但聪明的做法是:
- 先挑出边缘碎片(直线、曲线);
- 再找出有眼睛、鼻子图案的碎片;
- 最后把这些局部图案拼在一起,组成完整的猫脸。
这就是CNN(Convolutional Neural Network,卷积神经网络)"看图片"的方法------不是一次性看全图,而是分层提取局部特征,再组合成整体理解。和传统神经网络相比,CNN就像给AI戴上了"老花镜",能聚焦关键细节,忽略无关噪点。
为什么普通神经网络看不懂图片?
假设你有一张200×200像素的猫咪图片,展开后就是40000个像素值(特征)。如果用普通神经网络:
- 第一层就需要40000个权重参数,计算量巨大;
- 而且它会把像素当成独立个体,忽略"相邻像素构成边缘"这种空间关系------就像把拼图碎片打乱后随机堆放,永远拼不出猫。
CNN的解决方案是:利用图像的"局部相关性"------猫的眼睛旁边通常是鼻子,而不是爪子。通过"局部感知"和"权值共享",CNN能高效提取有用特征。
CNN的"三层拼图法"
第一层:卷积层(Convolutional Layer)------找边缘和纹理
核心功能:像用放大镜观察图片,每次只看一小块区域(称为"卷积核"或"过滤器"),找出局部特征。
用"印章盖章"理解卷积操作:
- 想象你有一个3×3的"边缘检测印章"(卷积核),在图片上从左到右、从上到下盖章。
- 每次盖章会计算印章覆盖区域的像素加权和,得到一个新的"特征值"。
- 盖章结束后,原图就变成了"特征图"------比如专门记录边缘的特征图、记录颜色的特征图。
举个例子:
- 当印章盖在猫的胡须区域,会输出高值("这里有边缘!");
- 盖在纯色背景上,输出低值("这里没特征")。
- 一张图经过多个不同印章(不同卷积核)处理,会得到多张特征图,分别记录边缘、颜色、纹理等信息。
第二层:池化层(Pooling Layer)------"模糊图片"保留关键信息
核心功能:把特征图缩小,减少计算量,同时保留最重要的特征。
用"马赛克拼图"理解池化:
- 最大池化(Max Pooling):从2×2的区域中取最大值(比如"这个区域最亮的点是眼睛的一部分")。
- 平均池化(Average Pooling):取区域平均值(适合保留整体亮度)。
效果 :
原图200×200 → 卷积后100×100 → 池化后50×50,像素减少75%,但关键特征(眼睛、胡须边缘)依然清晰。就像把高清图缩成缩略图,人眼仍能认出是猫。
第三层:全连接层(Fully Connected Layer)------拼图总装
核心功能:把前面提取的所有局部特征(眼睛、耳朵、胡须)组合起来,判断"这是什么"。
用"侦探破案"理解全连接:
- 卷积层发现"有圆形眼睛特征"(证据A)、"有三角形耳朵特征"(证据B)、"有胡须纹理"(证据C);
- 全连接层像侦探,综合所有证据:A+B+C → "90%概率是猫"。
输出:经过Softmax回归,得到最终分类结果(猫、狗、鸡等概率)。
CNN的"独门暗器":权值共享(Weight Sharing)
这是CNN比普通神经网络高效的关键:
- 同一个卷积核(比如边缘检测印章)在图片不同位置使用相同的权重参数,而不是每个位置单独训练参数。
- 比如3×3的卷积核只有9个参数,无论原图多大,参数数量不变。
- 好处:训练速度快,不易过拟合(因为参数少,不会死记硬背训练数据)。
生活中的CNN:不止"看图片"
案例1:手机人脸识别解锁
- 前置摄像头拍一张你的脸 → CNN提取"眼角距离""鼻梁高度"等特征 → 和手机里存的特征比对 → 匹配成功就解锁。
- 即使你化了妆、戴了眼镜,CNN也能通过关键特征认出你------因为它看的是"五官布局",不是细节。
案例2:医学影像诊断
- 医生看CT片可能漏过早期肿瘤,但CNN能发现"毫米级异常":
- 卷积层找出肺部的"结节边缘"特征;
- 池化层保留结节的大小和位置;
- 全连接层判断"这是良性结节还是恶性肿瘤"。
- 准确率甚至超过资深 radiologist(放射科医生)。
案例3:自动驾驶的"眼睛"
- 车载摄像头实时拍摄路况 → CNN同时检测:
- 交通信号灯(红色/绿色特征);
- 行人(人体轮廓特征);
- 车道线(直线/曲线特征);
- 瞬间做出决策:"红灯,停车"或"前方有行人,减速"。
CNN的"进化史":从LeNet到ResNet
- LeNet-5(1998):最早的CNN,用于手写数字识别(ATM机读银行卡号),只有5层。
- AlexNet(2012):让CNN火起来的模型,8层网络,在ImageNet比赛中准确率远超传统方法。
- ResNet(2015):152层!通过"残差连接"解决深层网络"梯度消失"问题,能训练更深的网络。
层数越多,能识别的特征越复杂------从简单边缘到整个物体,再到场景(比如"沙滩上的猫")。
小问题:为什么CNN对图片旋转、缩放不敏感?
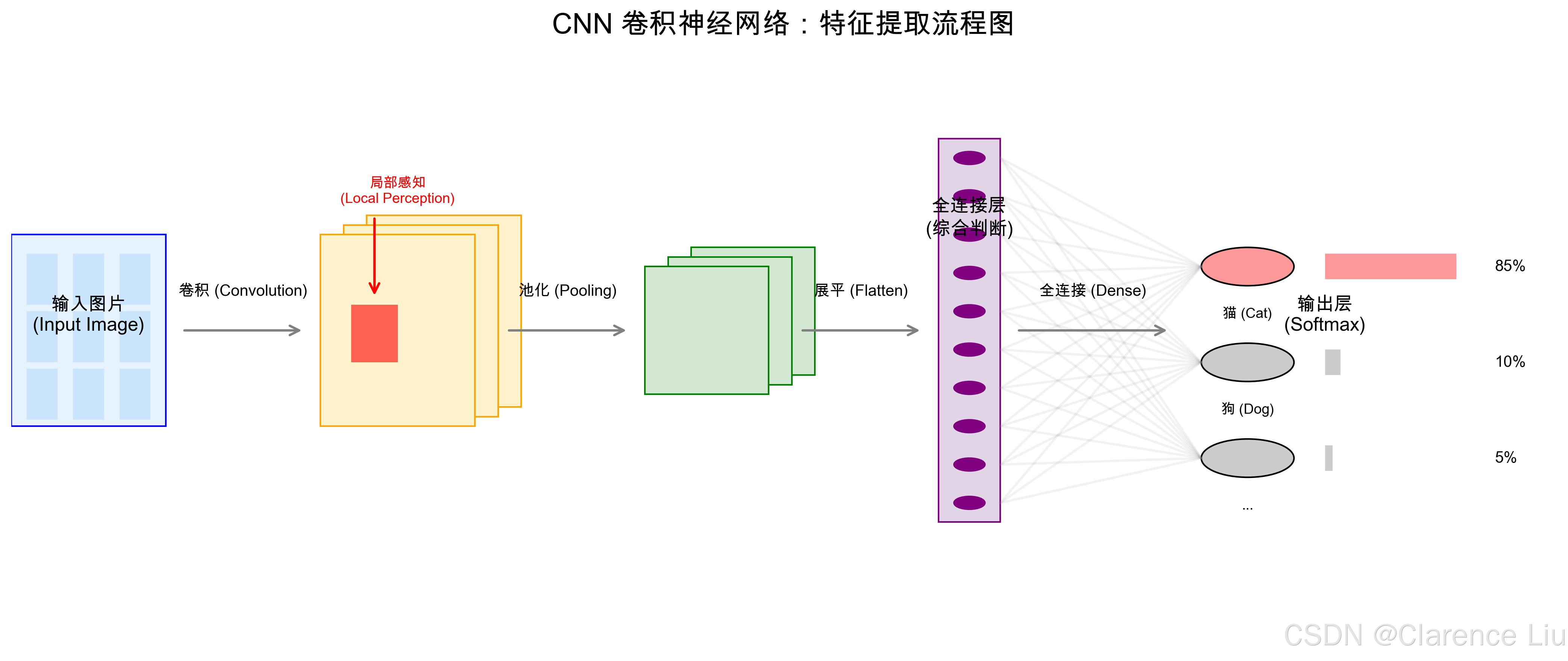
(提示:因为卷积核是"局部感知"的,无论猫是正放、倒放还是缩小,眼睛、耳朵的局部特征依然存在;池化层进一步强化了这种"位置无关性"。这就是CNN的"平移不变性"。)
下一篇预告:《循环神经网络(RNN):AI怎么"听懂"语音?》------用"记笔记"的例子,讲透RNN如何处理文字、语音等序列数据。