作者 : 付晨浩, 方涵, 耿修忠, 魏博, 李永华, 孙昊, 李学龙
单位 : 北京邮电大学, 人工智能研究院(TeleAI), 中国电信
https://arxiv.org/pdf/2601.09147
摘要
零样本异常检测(ZSAD)利用视觉-语言模型(VLMs)实现无监督的工业检测。然而,现有的ZSAD范式受限于单一的视觉主干网络,难以在全局语义泛化能力和细粒度结构判别能力之间取得平衡。为弥合这一差距,我们提出了协同语义-视觉提示 (SSVP),它能高效地融合多样化的视觉编码,以提升模型的细粒度感知能力。具体而言,SSVP引入了分层语义-视觉协同 (HSVS)机制,将DINOv3的多尺度结构先验深度集成到CLIP的语义空间中。随后,视觉条件提示生成器 (VCPG)采用跨模态注意力来引导动态提示的生成,使语言查询能够精确锚定到特定的异常模式。此外,为解决全局评分与局部证据之间的不一致性,视觉-文本异常映射器(VTAM)建立了一种双门控校准范式。在七个工业基准上的大量评估验证了我们方法的鲁棒性;SSVP在MVTec-AD上取得了93.0%的图像级AUROC和92.2%的像素级AUROC,显著优于现有的零样本方法。
通讯作者: 孙昊 (sun.010@163.com), 李学龙 (xuelong_li@ieee.org)
1 引言
工业异常检测(IAD)对于智能制造和工业质量检验至关重要,可确保生产可靠性 (Liu et al., 2024; Hu et al., 2025; Rahmaniar and Suzuki, 2025; Yang et al., 2024; Chen and Imani, 2025)。然而,传统的监督模型因固有的数据稀缺性和频繁的类别变化而面临挑战 (Zhou et al., 2025; Zhang et al., 2025)。零样本异常检测(ZSAD)通过消除对目标域标签的需求来克服这一问题 (Luo et al., 2024),旨在通过广义知识迁移来识别未见过的缺陷。近期,基于CLIP的VLMs (Chen et al., 2025; Gao et al., 2026) 通过构建统一的语义空间,实现了语言引导的视觉检测。早期的方法使用静态模板 (Jeong et al., 2023; Chen et al., 2023),而当前的研究则优先考虑动态提示 (Zhou et al., 2022, 2023; Cao et al., 2024)。通过适应特定输入,这种方法比固定描述能更有效地处理复杂缺陷。
尽管取得了这些进展,现有的动态提示方法在复杂场景中仍面临三个系统性局限。首先,VLM的全局对齐牺牲了细粒度的判别能力,无法捕捉对精确工业检测至关重要的微小失真。其次,当前的概率性提示 (Qu et al., 2025) 缺乏深度的跨模态交互。这些方法依赖浅层的线性叠加来集成视觉先验,未能有效地使文本嵌入自适应地锚定到特定的异常模式。第三,全局评分与局部证据不一致。过度依赖全局余弦相似度常常导致微弱的异常信号被主导的背景噪声所掩盖,从而在高精度任务中造成漏检。
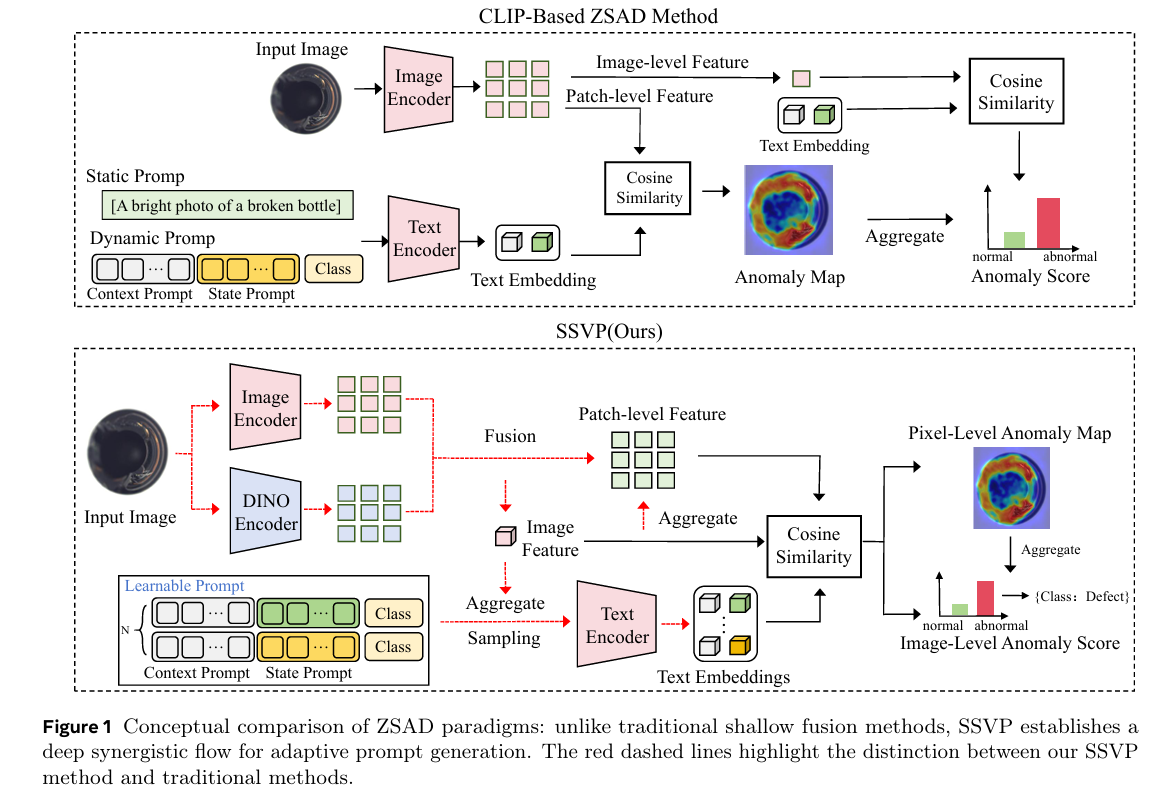
为直观地说明这些局限性,我们在图1中展示了现有范式与我们所提出框架的概念性对比。为应对这些挑战,我们提出了协同语义-视觉提示(SSVP)框架。与以往孤立处理模态的方法不同,SSVP集成了一个深度协同流,以协调CLIP的广义语义推理与DINO的细粒度结构定位。
具体来说,我们通过三个技术上截然不同的模块来实例化此方法。首先,为弥合特征粒度差距,我们设计了分层语义-视觉协同 (HSVS)机制。详细来说,HSVS采用一个自适应令牌特征融合 (ATF)块,该块利用双路径跨模态注意力来对齐不同的特征,并通过可学习的投影矩阵显式地将DINOv3的多尺度结构先验注入到CLIP的语义流形中。其次,为缓解确定性提示的局限性,我们提出了视觉条件提示生成器 (VCPG)。该模块利用变分自编码器(VAE)对视觉异常的潜在分布进行建模,并采用文本-潜在交叉注意力机制。这种设计允许文本嵌入通过重参数化技巧动态地"检索"并集成生成性的视觉偏差,从而确保对未见缺陷模式的鲁棒锚定。第三,为克服全局-局部脱节问题,我们构建了视觉-文本异常映射器 (VTAM)。该模块实现了一种由双门控机制驱动的异常混合专家(AnomalyMoE)范式,涵盖全局尺度选择和局部空间滤波。通过自适应地路由多尺度特征并用显著的局部证据校准全局评分,VTAM确保了精确的异常定位。
总体而言,本研究的核心贡献总结如下:
- 分层语义-视觉协同:HSVS通过深度融合多尺度结构先验来提升细粒度感知。
- 视觉条件提示:VCPG使用生成性视觉先验来调制文本嵌入,增强提示的多样性和语义一致性。
- 局部增强的判别:VTAM通过异常混合专家策略校准全局评分,以解决对微小缺陷的不敏感问题。
2 相关工作
2.1 零样本异常检测
视觉-语言模型(VLMs)的集成已为零样本异常检测(ZSAD)(Xu et al., 2025; Zhu et al., 2025) 建立了一种灵活的范式。通过将视觉数据与语言概念对齐,这些模型能够通过描述而非示例来识别异常。这种方法与传统的监督策略有根本区别。传统方法严重依赖特定检测场景的大量训练样本。相比之下,ZSAD优先考虑跨域泛化。它有效地利用从大规模源数据集中学到的通用知识。因此,该系统可以在无需对其额外训练的情况下,在未见过的目标域中检测异常。开创性的工作已通过各种策略利用CLIP (Liu et al., 2024; Radford et al., 2021) 来适应此任务。例如,一些方法采用多尺度滑动窗口来改进定位 (Jeong et al., 2023),而另一些则使用线性嵌入适配器 (Chen et al., 2023) 或原型记忆库来估计稀有性 (He et al., 2025)。虽然这些方法对物体级分类有效,但它们主要依赖于粗粒度的特征匹配,由于缺乏密集的视觉-语义交互,通常限制了其捕获细粒度纹理和结构缺陷的能力。
2.2 提示学习方法
提示工程对于将VLMs适配到异常检测至关重要,其发展已从静态模板演变为概率生成 (Jin et al., 2025; Cao et al., 2025)。早期方法 (Jeong et al., 2023; Chen et al., 2023) 依赖于手动设计的静态提示,难以覆盖多样的缺陷类型。为了提高适应性,引入了动态提示方法 (Zhou et al., 2022, 2023; Cao et al., 2024),通过优化可学习的上下文向量来实现特定实例的语义调整。然而,这些方法仍然是确定性的,会收敛到点估计,可能无法完全涵盖未见异常的长尾分布。因此,近期研究已转向概率建模 (Derakhshani et al., 2023)。值得注意的是,Bayes-PFL (Qu et al., 2025) 利用变分自编码器(Kingma and Welling, 2013)通过潜在采样生成多样化的提示分布。尽管取得了这一进展,但当前的生成方法通常仅以简单的CLIP文本嵌入为条件进行生成,从而错过了精确定位缺陷所需的细粒度局部线索。
2.3 视觉特征表示
异常检测的有效性取决于视觉表示的粒度。CLIP (Radford et al., 2021; Lv et al., 2025) 利用大规模的图像-文本对在视觉特征和语言概念之间建立强大的对齐。这赋予了它强大的全局语义理解能力。然而,它缺乏工业检测所需的像素级判别能力。相比之下,DINO (Oquab et al., 2023; Siméoni et al., 2025) 利用大规模自监督训练来捕捉密集的结构和纹理细节。因此,DINO提供了细粒度的感知能力,有效地补充了CLIP的语义能力。在单模态AD领域,采用记忆库 (Roth et al., 2022; Damm et al., 2025; Batzner et al., 2024; Ammar et al., 2025) 或标准化流 (Liu et al., 2023; Yu et al., 2021) 等技术的方法已被证明非常有效。然而,一个主要的局限性是它们缺乏零样本推理能力。ZSAD的一个主要目标是增强泛化能力。为此,结合多个模型并利用它们的互补优势是有益的。然而,有效地集成这些模型仍然是一个重大挑战。虽然最近的工作如FiLo (Gu et al., 2024) 和MuSc (Li et al., 2024) 探索了多尺度对齐,但简单的融合策略常常因不同的流形拓扑而遭受特征冲突。这凸显了需要一种深度协同机制,如SSVP中提出的那样,以有效地将判别性结构先验注入语义空间。
2.4 特征协同增强机制
集成多模态和多尺度特征的协同方法已在多种计算机视觉领域得到重视,从医学成像 (Dai et al., 2026)、工业故障诊断 (Ye et al., 2024) 到多模态情感分析 (Wang et al., 2025)、自动驾驶 (Rajpoot and Agrawal, 2025) 以及通用视觉识别 (Li et al., 2025; Liu et al., 2022)。这些成就凸显了协作智能的潜力。值得注意的是,AI Flow (An et al., 2025) 引入了基于交互的涌现概念。它认为,多样化智能体的动态协调可以超越单个组件的局限。受AI Flow启发,SSVP通过在语义推理和视觉感知之间建立强大的协同作用来采纳这一概念。传统方法通常依赖于特征的静态拼接。然而,这种方法限制了不同模态之间的有效交互。为解决此问题,我们的方法引入了一个动态融合过程。具体来说,细粒度的视觉细节主动将空间信息注入全局语义表示。该过程利用局部纹理细节迭代地校准高层理解。因此,我们的方法在检测微小缺陷方面优于标准策略。
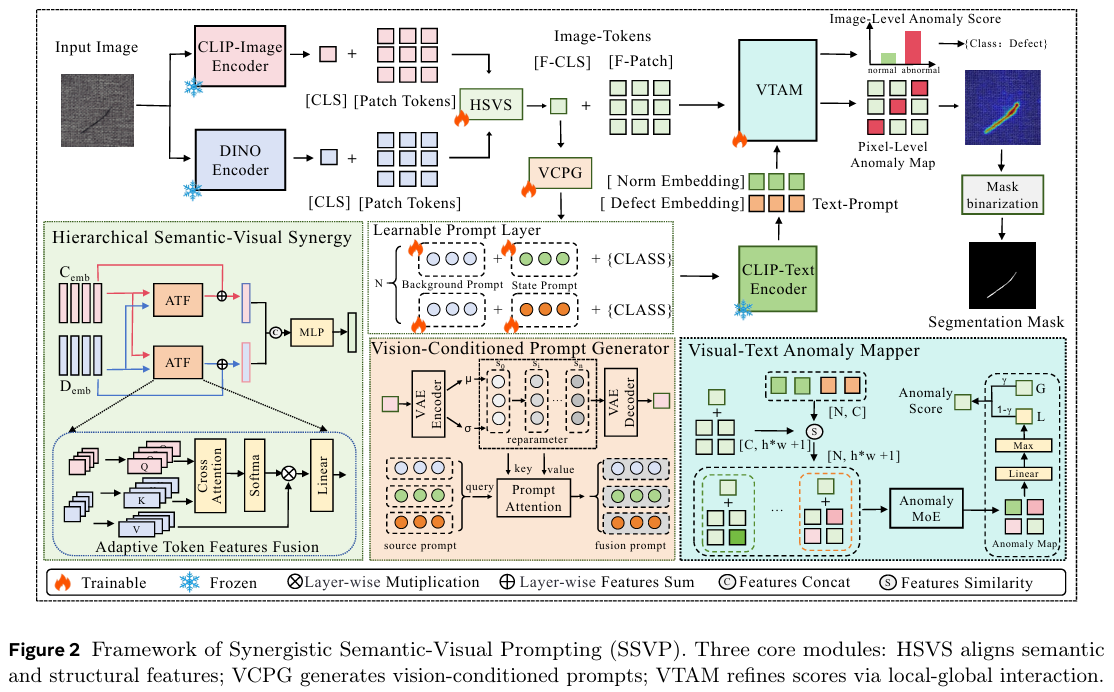
3 方法
在本节中,我们将详细阐述所提出的SSVP框架。如图2所示,SSVP旨在通过深度跨模态协同来解决零样本异常检测中的关键挑战:特征粒度瓶颈、语义漂移和粗粒度判别。通过协同融合高层语义上下文和多尺度结构细节,该框架建立了一种强大的视觉-语义对齐机制,能够在没有目标域监督的情况下识别未见缺陷。该框架由三个逻辑上耦合的模块组成。(1) 分层语义-视觉协同 (HSVS)通过将DINO的细粒度结构特征对齐并注入CLIP语义流形来构建鲁棒的视觉表示。(2) 视觉条件提示生成器 (VCPG)将增强的视觉特征作为强先验注入潜在空间,并利用跨模态注意力引导文本嵌入精确锚定在缺陷区域。(3) 视觉-文本异常映射器(VTAM)建立了一种局部-全局交互范式,通过局部细节动态修正全局评分,以增强检测灵敏度。详细的前向推理流程见算法1。

3.1 分层语义-视觉协同 (HSVS)
为弥合CLIP的全局语义与DINOv3的细粒度结构之间的差距,我们提出了HSVS机制。HSVS的核心组件是自适应令牌特征融合 (ATF)模块。ATF基于双路径跨模态注意力构建了一个精细化的特征交互流。
首先,给定一张输入图像 III,我们使用CLIP和DINOv3编码器提取特征,并将它们解耦为全局类别令牌和局部块特征序列:
{Fgc,Flc}=Eclip(I),{Fgd,Fld}=Edino(I), \{F_{g}^{c},F_{l}^{c}\}=\mathcal{E}{clip}(I),\quad\{F{g}^{d},F_{l}^{d}\}=\mathcal{E}_{dino}(I), {Fgc,Flc}=Eclip(I),{Fgd,Fld}=Edino(I),
其中 Flc∈RN×DcF_{l}^{c}\in\mathbb{R}^{N\times D_{c}}Flc∈RN×Dc 和 Fld∈RN×DdF_{l}^{d}\in\mathbb{R}^{N\times D_{d}}Fld∈RN×Dd 分别表示CLIP和DINO的局部特征。ATF独立处理全局和局部对。以局部分支为例,为了在共享的潜在子空间内对齐这些不同的特征,我们首先使用可学习的投影矩阵将特征转换为查询(Query)、键(Key)和值(Value)嵌入。然后,我们构建两条并行的交互路径:
Qc=FlcWQc,Kd=FldWKd,Vd=FldWVd,Qd=FldWQd,Kc=FlcWKc,Vc=FlcWVc, \begin{align*} Q_{c}&=F_{l}^{c}W_{Q}^{c},\quad K_{d}=F_{l}^{d}W_{K}^{d},\quad V_{d}=F_{l}^{d}W_{V}^{d},\\ Q_{d}&=F_{l}^{d}W_{Q}^{d},\quad K_{c}=F_{l}^{c}W_{K}^{c},\quad V_{c}=F_{l}^{c}W_{V}^{c}, \end{align*} QcQd=FlcWQc,Kd=FldWKd,Vd=FldWVd,=FldWQd,Kc=FlcWKc,Vc=FlcWVc,
其中 W(⋅)c∈RDc×dheadW_{(\cdot)}^{c}\in\mathbb{R}^{D_{c}\times d_{head}}W(⋅)c∈RDc×dhead 和 W(⋅)d∈RDd×dheadW_{(\cdot)}^{d}\in\mathbb{R}^{D_{d}\times d_{head}}W(⋅)d∈RDd×dhead 表示各自特征路径的投影权重。
随后,我们计算双向注意力图以集成互补信息。第一条路径用CLIP语义查询DINO特征,而第二条路径执行反向操作。归一化的跨模态注意力权重计算如下:
Attnc→d=Softmax(Qc(Kd)⊤dhead)Vd,Attnd→c=Softmax(Qd(Kc)⊤dhead)Vc, \begin{aligned} &\mathbf{Attn}{c\rightarrow d}=Softmax\left(\frac{Q{c}(K_{d})^{\top}}{\sqrt{d_{head}}}\right)V_{d},\\ &\mathbf{Attn}{d\rightarrow c}=Softmax\left(\frac{Q{d}(K_{c})^{\top}}{\sqrt{d_{head}}}\right)V_{c}, \end{aligned} Attnc→d=Softmax(dhead Qc(Kd)⊤)Vd,Attnd→c=Softmax(dhead Qd(Kc)⊤)Vc,
其中 Attnc→d\mathbf{Attn}{c\rightarrow d}Attnc→d 显式地将细粒度几何先验注入语义流形,而 Attnd→c\mathbf{Attn}{d\rightarrow c}Attnd→c 提供互惠的结构强化。在获得双路径上下文特征后,我们应用层归一化(LN)并将它们沿通道维度拼接,形成联合描述符 ZjointZ_{joint}Zjoint:
Zjoint=LN(Attnc→d)∥LN(Attnd→c), Z_{joint}=\\mathrm{LN}(\\mathbf{Attn}_{c\\rightarrow d}) \\parallel \\mathrm{LN}(\\mathbf{Attn}_{d\\rightarrow c}), Zjoint=LN(Attnc→d)∥LN(Attnd→c),
其中 ∥\parallel∥ 表示拼接操作。为了实现深度特征融合并引入非线性,ZjointZ_{joint}Zjoint 被送入一个由GELU激活的两层多层感知机(MLP)。最后,为了保持原始语义空间的分布稳定性,我们采用残差连接将融合后的特征加回原始表示,得到最终的局部协同特征 VsynlocalV_{syn}^{local}Vsynlocal:
Vsynlocal=Flc+Fmlp(Zjoint). V_{syn}^{local}=F_{l}^{c}+\mathcal{F}{mlp}(Z{joint}). Vsynlocal=Flc+Fmlp(Zjoint).
类似地,全局协同特征 VsynglobalV_{syn}^{global}Vsynglobal 通过相同的ATF逻辑计算。因此,最终的输出集 {Vsynglobal,Vsynlocal}\{V_{syn}^{global}, V_{syn}^{local}\}{Vsynglobal,Vsynlocal} 结合了零样本语义理解和像素级结构感知的双重优势。
3.2 视觉条件提示生成器 (VCPG)
SSVP的核心创新在于VCPG模块。传统的动态提示通常局限于静态表示,无法捕捉未见异常的长尾分布。VCPG通过引入一种"视觉-潜在"交互机制来解决此问题,利用变分推断将细粒度视觉提示转化为附加的语义偏差。
3.2.1 结构化可学习提示嵌入
为了区分不变的环境上下文和特定的异常状态,我们提出了一种解耦提示构建策略 。我们通过将其分解为共享和状态特定组件来简化提示参数化。具体来说,通用提示模板 ttt 定义为:
t=Vbg,Vstate,CLASS. t=V{bg}, V{state}, CLASS. t=Vbg,Vstate,CLASS.
在此公式中:
- Vbg={v1,...,vL}V{bg}=\{v{1},\ldots,v_{L}\}Vbg={v1,...,vL} 表示参数共享的背景向量序列。无论样本类别(正常或异常)如何,该组件都旨在学习域不变的环境语义(例如,纹理风格、光照条件)。
- VstateV{state}Vstate 表示状态特定的向量序列。我们为正常提示库 Pn{\mathcal{P}}{n}Pn 学习一组 VnormalV{normal}Vnormal,并为异常提示库 Pa{\mathcal{P}}{a}Pa 学习一组单独的 VabnormalV{abnormal}Vabnormal。这种设计迫使模型关注状态差异而非背景变化。
这些序列由文本编码器 T\mathcal{T}T 处理,生成初始文本嵌入 TinitT{init}Tinit。
3.2.2 变分视觉建模与注意力交互
受Bayes-PFL (Qu et al., 2025) 的启发,我们引入了一种视觉潜在注入机制。HSVS特征通过VAE编码为潜在表示,这些表示通过交叉注意力与可学习提示进行交互。这使得文本语义能够动态适应视觉异常模式。
为了捕捉异常外观的不确定性,我们采用VAE来学习潜在流形。我们利用从HSVS派生的全局协同特征 VsynglobalV_{syn}^{global}Vsynglobal 作为输入观测。由两个并行MLP Fμ{\mathcal{F}}{\mu}Fμ 和 Fσ{\mathcal{F}}{\sigma}Fσ 组成的概率编码器 EϕE_{\phi}Eϕ 将视觉特征映射到潜在分布的参数:
μ=Fμ(Vsynglobal),logσ2=Fσ(Vsynglobal), \mu=\mathcal{F}{\mu}(V{syn}^{global}),\quad \log\sigma^{2}=\mathcal{F}{\sigma}(V{syn}^{global}), μ=Fμ(Vsynglobal),logσ2=Fσ(Vsynglobal),
其中 μ\muμ 和 σ2\sigma^{2}σ2 分别表示潜在高斯分布的均值和方差。为了确保反向传播期间的可微性,我们应用重参数化技巧 。我们采样一个标准高斯噪声 ϵ∼N(0,I)\epsilon\sim\mathcal{N}(0,\mathbf{I})ϵ∼N(0,I) 并通过仿射变换生成潜在变量 zzz:
z=μ+ϵ⊙exp(logσ22). z=\mu+\epsilon\odot\exp\left(\frac{\log\sigma^{2}}{2}\right). z=μ+ϵ⊙exp(2logσ2).
这里,zzz 表示视觉潜在偏差 ,它编码了输入图像的全局异常分布。
为了将潜在空间正则化为标准正态分布,我们通过最大化证据下界(ELBO)来优化VAE。该方法与异常检测中既定的基于重建的范式 (Deng and Li, 2022) 一致。VAE损失 LVAE\mathcal{L}{VAE}LVAE 表述为:
LVAE=∥Vsynglobal−Dθ(z)∥22+β⋅DKL(qϕ(z∣Vsynglobal)∥N(0,I)), \mathcal{L}{VAE}=\|V_{syn}^{global}-D_{\theta}(z)\|{2}^{2}+\beta\cdot D{KL}(q_{\phi}(z|V_{syn}^{global})\|\mathcal{N}(0,\mathbf{I})), LVAE=∥Vsynglobal−Dθ(z)∥22+β⋅DKL(qϕ(z∣Vsynglobal)∥N(0,I)),
其中 DθD_{\theta}Dθ 表示解码器,β\betaβ 作为一个平衡系数。
在推理过程中,我们采用文本-潜在交叉注意力 模块,使用采样的 zzz 来调制文本语义。具体来说,该机制将初始文本嵌入 TinitT_{init}Tinit 视为查询(Query),并将潜在偏差 zzz 映射到键(Key)和值(Value)嵌入,以生成视觉增强的残差 δinj\delta_{inj}δinj:
Qtext=TinitWQ,Kz=zWK,Vz=zWV,δinj=Softmax(Qtext(Kz)⊤dk)Vz. \begin{align*} Q_{text}&=T_{init}W_Q,\quad K_z=zW_K,\quad V_z=zW_V,\\ \delta_{inj}&=Softmax\left(\frac{Q_{text}(K_z)^\top}{\sqrt{d_k}}\right)V_z. \end{align*} Qtextδinj=TinitWQ,Kz=zWK,Vz=zWV,=Softmax(dk Qtext(Kz)⊤)Vz.
3.2.3 基于边界的门控注入
最后,我们将生成的视觉偏差注入文本嵌入。为了防止过多的视觉信息扭曲原始类别分布,我们引入了一个自适应门控机制 以及基于边界的语义正则化 。我们通过一个可学习的门控标量 α\alphaα(初始化为0)将计算出的视觉偏差 δinj\delta_{inj}δinj 注入初始文本嵌入:
Tfinal=LayerNorm(Tinit+α⋅δinj). T_{final}=\mathrm{LayerNorm}(T_{init}+\alpha\cdot\delta_{inj}). Tfinal=LayerNorm(Tinit+α⋅δinj).
门控标量 α\alphaα 根据输入图像的不确定性自适应地调节注入的视觉偏差强度。
为了平衡语义一致性与视觉特异性,我们避免将 TfinalT_{final}Tfinal 严格约束到初始锚点。我们施加一个宽松的约束,将正则化损失 Lreg\mathcal{L}{reg}Lreg 表述为:
Lreg=max(0,ξ−Tfinal⋅sg(Tinit)⊤∥Tfinal∥∥sg(Tinit)∥), \mathcal{L}{reg}=\max\left(0,\xi-\frac{T_{final}\cdot\mathrm{sg}(T_{init})^{\top}}{\|T_{final}\|\|\mathrm{sg}(T_{init})\|}\right), Lreg=max(0,ξ−∥Tfinal∥∥sg(Tinit)∥Tfinal⋅sg(Tinit)⊤),
其中 ξ\xiξ 表示预定义的相似度阈值,sg(⋅)\operatorname{sg}(\cdot)sg(⋅) 表示停止梯度(stop-gradient)算子。该公式意味着只有当余弦相似度低于 ξ\xiξ 时才会产生惩罚。实际上,该机制定义了一个语义邻域:只要 TfinalT_{final}Tfinal 保持在该区域内,模型就被允许利用视觉偏差来优化异常检测性能,从而防止表示坍缩为静态嵌入。
**3.3 视觉-文本异常映射器 **(VTAM)
现有的ZSAD方法受限于全局和局部表示的不一致。全局语义常常忽略细粒度的异常信号,而静态聚合无法适应在不同尺度上表现的缺陷。为解决此问题,我们引入了一个异常混合专家(AnomalyMoE)模块,该模块通过双门控机制动态路由多尺度特征,确保在全局校准之前进行精确定位。
3.3.1 像素级异常概率图构建
为启动定位过程,我们首先使用从HSVS模块派生的协同特征和优化后的异常提示来计算逐层的异常概率图。给定第 lll 层的协同局部特征图 Vsynlocal,(l)∈RHl×Wl×DV_{syn}^{local,(l)}\in\mathbb{R}^{H_{l}\times W_{l}\times D}Vsynlocal,(l)∈RHl×Wl×D 和视觉条件提示 TfinalT_{final}Tfinal,我们计算密集余弦相似度以生成原始异常图 M(l)\mathcal{M}^{(l)}M(l):
Mh,w(l)=Vsynlocal,(l)(h,w)⋅(Tfinal)⊤∥Vsynlocal,(l)(h,w)∥∥Tfinal∥. \mathcal{M}{h,w}^{(l)}=\frac{V{syn}^{local,(l)}(h,w)\cdot(T_{final})^{\top}}{\|V_{syn}^{local,(l)}(h,w)\|\|T_{final}\|}. Mh,w(l)=∥Vsynlocal,(l)(h,w)∥∥Tfinal∥Vsynlocal,(l)(h,w)⋅(Tfinal)⊤.
为确保数值稳定性并在不同层之间归一化尺度,我们通过在正常和异常通道上应用Softmax操作,将这些原始相似度分数转换为像素级异常概率:
Panom(l)(h,w)=exp(Manom(l)h,w/τ)exp(Mnorm(l)h,w/τ)+exp(Manom(l)h,w/τ). \mathcal{P}{anom}^{(l)}(h,w)=\frac{\operatorname{exp}(\mathcal{M}{anom}^{(l)}h,w/\tau)}{\operatorname{exp}(\mathcal{M}{norm}^{(l)}h,w/\tau)+\operatorname{exp}(\mathcal{M}{anom}^{(l)}h,w/\tau)}. Panom(l)(h,w)=exp(Mnorm(l)h,w/τ)+exp(Manom(l)h,w/τ)exp(Manom(l)h,w/τ).
这里,Panom(l)∈0,1H×W\mathcal{P}_{anom}^{(l)}\in0,1^{H\times W}Panom(l)∈0,1H×W 表示第 lll 个专家的初始置信度。τ\tauτ 是一个温度参数,用于控制概率分布的尖锐度,通过缩放余弦相似度来增强判别能力。
**3.3.2 异常混合专家 **(AnomalyMoE)
我们提出了一种密集双门控机制 ,以有效地聚合多尺度专家。与稀疏的top-k选择不同,我们的方法利用可微的软门控来自适应地组合所有特征尺度,同时解决层间尺度选择和层间噪声过滤问题。详细的推理过程总结在算法2中。
我们认为全局语义上下文携带着输入图像最有信息量的特征尺度。为对此依赖性进行建模,我们采用全局协同特征 VsynglobalV_{syn}^{global}Vsynglobal 来生成尺度特定的权重 wscale∈RLw_{scale}\in\mathbb{R}^{L}wscale∈RL:
wscale=Softmax(Fgateglobal(Vsynglobal)), w_{scale}=\mathrm{Softmax}\left(\mathcal{F}{gate}^{global}(V{syn}^{global})\right), wscale=Softmax(Fgateglobal(Vsynglobal)),
其中 Fgateglobal\mathcal{F}_{gate}^{global}Fgateglobal 是一个多层感知机(MLP)。这个全局门控分支允许模型自适应地突出特定层,例如在处理以纹理为中心的图像时聚焦于浅层。
作为尺度选择的补充,我们认识到即使在最优层内,背景区域也可能引入无关噪声。为了进一步净化特征,我们采用一个局部门控网络 Fgatelocal\mathcal{F}{gate}^{local}Fgatelocal(实现为 1×11\times11×1 卷积)来生成一个空间注意力掩码 Mspatial(l)∈0,1H×WM{spatial}^{(l)}\in0,1^{H\times W}Mspatial(l)∈0,1H×W:
Mspatial(l)=σ(Fgatelocal(Vsynlocal,(l))), M_{spatial}^{(l)}=\sigma\left(\mathcal{F}{gate}^{local}(V{syn}^{local,(l)})\right), Mspatial(l)=σ(Fgatelocal(Vsynlocal,(l))),
其中 σ\sigmaσ 表示sigmoid函数。这个局部门控分支充当一个像素级过滤器,以抑制非异常区域。
最后,通过聚合由全局尺度重要性和局部空间显著性加权的专家,得到融合的像素级异常图 Pmap\mathcal{P}{map}Pmap:
Pmap=∑l=1Lwscalel⋅(Mspatial(l)⊙Panom(l)), \mathcal{P}{map}=\sum_{l=1}^{L}w_{scale}l\cdot\left(M_{spatial}^{(l)}\odot\mathcal{P}_{anom}^{(l)}\right), Pmap=l=1∑Lwscalel⋅(Mspatial(l)⊙Panom(l)),
其中 ⊙\odot⊙ 表示逐元素乘法。通过这种双门控聚合,模型有效地过滤掉无关尺度和背景噪声,产生高质量的异常图。

3.3.3 评分增强策略
我们利用生成的异常图通过空间最大池化(Spatial Max-Pooling)提取最显著的局部证据来增强全局分类分数:
Slocal=maxh,wPmap(h,w). S_{local}=\operatorname*{max}{h,w}\mathcal{P}{map}(h,w). Slocal=h,wmaxPmap(h,w).
局部证据充当一个动态增益项。我们将其注入全局语义分数以优化预测。结果是最终的异常分数 SfinalS_{final}Sfinal:
Sfinal=(1−γ)⋅⟨Vsynglobal,Tfinal⟩+γ⋅Slocal, S_{final}=(1-\gamma)\cdot\langle V_{syn}^{global},T_{final}\rangle+\gamma\cdot S_{local}, Sfinal=(1−γ)⋅⟨Vsynglobal,Tfinal⟩+γ⋅Slocal,
其中 γ\gammaγ 平衡了全局语义和局部细节的贡献。
3.4 目标函数
SSVP框架使用一个联合目标进行端到端训练,该目标同时监督像素级分割和图像级分类。对于像素级监督,我们在VTAM模块的异常概率图 Panom(l~)\mathcal{P}_{anom}^{(\tilde{l})}Panom(l~) 上采用焦点损失(focal loss),以解决正常像素和异常像素之间严重的不平衡问题。
给定真实掩码 Y∈{0,1}H×WY\in\{0,1\}^{H\times W}Y∈{0,1}H×W,分割损失定义为:
LSeg=−1HW∑h,w(Yh,w(1−ph,w)λlog(ph,w)+(1−Yh,w)ph,wλlog(1−ph,w)), \begin{aligned} \mathcal{L}{Seg}=-\frac{1}{HW}\sum{h,w}\bigg(&Y_{h,w}(1-p_{h,w})^{\lambda}\log(p_{h,w})\\ &+(1-Y_{h,w})p_{h,w}^{\lambda}\log(1-p_{h,w})\bigg), \end{aligned} LSeg=−HW1h,w∑(Yh,w(1−ph,w)λlog(ph,w)+(1−Yh,w)ph,wλlog(1−ph,w)),
其中 ph,w=Panom(l)(h,w)p_{h,w} = \mathcal{P}{anom}^{(l)}(h, w)ph,w=Panom(l)(h,w) 表示预测概率,λ\lambdaλ 是聚焦参数。除了分割任务外,图像级监督对于优化 VTAM 融合机制并强制全局表示具备异常感知能力至关重要。我们使用图像级二值标签 yimg∈{0,1}y{img} \in \{0, 1\}yimg∈{0,1},通过二元交叉熵(BCE)损失来监督最终融合得分 SfinalS_{final}Sfinal:
LClass=BCE(σ(Sfinal),yimg), \mathcal{L}{Class} = \text{BCE}(\sigma(S{final}), y_{img}), LClass=BCE(σ(Sfinal),yimg),
其中 σ(⋅)\sigma(\cdot)σ(⋅) 是用于归一化得分的 Sigmoid 函数。通过反向传播 LClass\mathcal{L}{Class}LClass,模型学习动态调整局部与全局特征的贡献,以实现鲁棒的决策。因此,总训练目标 Ltotal\mathcal{L}{total}Ltotal 聚合了分割损失、分类损失以及来自 VCPG 模块的正则化项:
Ltotal=LSeg+LClass+λ1LVAE+λ2Lreg, \mathcal{L}{total} = \mathcal{L}{Seg} + \mathcal{L}{Class} + \lambda_1 \mathcal{L}{VAE} + \lambda_2 \mathcal{L}_{reg}, Ltotal=LSeg+LClass+λ1LVAE+λ2Lreg,
其中 LVAE\mathcal{L}{VAE}LVAE 和 Lreg\mathcal{L}{reg}Lreg 分别强制潜在分布约束和语义一致性约束,由超参数 λ1\lambda_1λ1 和 λ2\lambda_2λ2 进行平衡。完整的优化过程(包括这些损失的计算和梯度更新步骤)总结在算法 3 中。

4 实验
在本节中,我们开展大量实验以评估所提出的 SSVP 框架的有效性。首先介绍数据集和评估指标;随后,描述实现细节与训练协议;接着,将 SSVP 与当前最先进的(SOTA)零样本异常检测方法进行对比;最后,通过深入的消融研究和定性分析,验证各组件的贡献。
4.1 数据集与评估指标
为全面评估 SSVP 在多样工业场景下的鲁棒性与泛化能力,我们采用了七个具有挑战性的基准数据集,涵盖以物体为中心、以纹理为中心以及真实世界表面缺陷三类场景:
-
MVTec-AD(Bergmann et al., 2019):一个标准工业基准数据集,包含来自 15 个类别(5 种纹理、10 类物体)的 5,354 张高分辨率图像。其缺陷类型多样,从细微划痕到结构性形变均有覆盖。
-
VisA(Zou et al., 2022):一个大规模数据集,包含跨越 12 个类别的 9,621 张图像。其中包含结构复杂、多实例共存、空间布局松散的物体,对零样本定位任务构成显著挑战。
-
BTAD(Mishra et al., 2021):BeanTech 异常检测数据集,包含 2,540 张真实工业产品的图像,聚焦于细微表面缺陷。
-
KSDD2(Božič et al., 2021):Kolektor 表面缺陷数据集 2,包含 3,355 张电气换向器图像,专为检测细微表面裂纹而设计。
-
RSDD(Yu et al., 2018):铁路表面缺陷数据集,包含 Type-I 和 Type-II 两类钢轨表面图像,模型需在复杂背景噪声下进行挑战。
-
DAGM(Deutsche Arbeitsgemeinschaft für Mustererkennung, 2007):合成数据集(DAGM 2007),包含 10 类不同纹理并生成异常样本,用于评估模型在纹理缺陷上的鲁棒性。
-
DTD-Synthetic(Aota et al., 2023):基于 Describable Textures Dataset 构建,我们在合成异常上进行评估,以测试模型处理多样化纹理模式的能力。
我们采用严格的跨域零样本迁移协议。具体而言,我们将 MVTec-AD 的训练集作为 VisA 评估的辅助源域,并将 VisA 的训练集作为其他所有数据集(如 MVTec-AD、BTAD 等)的源域,确保目标数据无泄露。
对比基线。 我们在零样本异常检测(ZSAD)领域将 SSVP 与最先进的方法进行基准对比,以验证其优越性。对比模型包括:(1) 零样本基线:WinCLIP(Jeong et al., 2023)、APRIL-GAN(Chen et al., 2023);(2) 动态提示方法:AnomalyCLIP(Zhou et al., 2023)、AdaCLIP(Cao et al., 2024)和 Bayes-PFL(Qu et al., 2025)。
零样本训练协议。 我们采用严格的跨域零样本迁移协议,以确保目标域无数据泄露。
- VisA 评估: 我们利用 MVTec-AD 的 15 个类别的训练集作为辅助源域,以优化可学习参数(提示库、VAE、HSVS 权重)。
- 其他数据集: 对于 MVTec-AD、BTAD、KSDD2、RSDD、DAGM 和 DTD-Synthetic 的评估,我们利用 VisA 的 12 个类别的训练集作为辅助源域。
在此设置下,模型严格遵循零样本假设,因为在训练阶段从未接触过目标类别的任何正常或异常样本(图像或文本描述)。
评估指标。 我们采用标准指标在图像级和像素级评估性能:
- 图像级指标: 我们报告 AUROCAUROCAUROC、F1-MaxF1\text{-}MaxF1-Max(最优阈值下的最大 F1 分数)和 APAPAP(平均精度),以全面评估异常分类性能,确保模型在各种决策阈值下区分正常与异常样本的能力得到鲁棒评估。
- 像素级指标: 为评估细粒度缺陷定位质量,我们报告 AUROCAUROCAUROC、PROPROPRO(区域重叠率)和 APAPAP。值得注意的是,PROPROPRO 随连通区域的重叠比例缩放,与像素级 AUROCAUROCAUROC 相比,它对缺陷区域的精确覆盖更敏感,从而对不同大小的异常给予同等重要性,避免大面积背景区域带来的偏差。
4.2 实现细节
架构与特征对齐。 我们使用 CLIP(ViT-L/14)和 DINOv3(ViT-L/16)作为冻结的骨干编码器。为实现跨模态的像素级对齐,我们采用分辨率自适应策略来抵消补丁大小的差异。具体而言,鉴于 CLIP 使用 141414 的补丁大小,我们将 CLIP 分支的输入图像调整为 518×518518 \times 518518×518。相反,由于 DINOv3 使用 161616 的补丁大小,我们将 DINO 分支的输入分辨率设置为 592×592592 \times 592592×592。此配置确保两个编码器的特征图具有相同的空间网格尺寸 H′×W′=37×37H' \times W' = 37 \times 37H′×W′=37×37,从而促进直接交互而无需插值伪影。
为捕获分层语义和结构信息,我们提取多尺度特征进行融合。我们从 CLIP 中选择索引 {6,12,18,24}\{6, 12, 18, 24\}{6,12,18,24},从 DINOv3 中选择索引 {3,6,9,11}\{3, 6, 9, 11\}{3,6,9,11} 作为 HSVS 模块的输入。语义流形的维度被投影到 Dc=768D_c = 768Dc=768。对于 VCPG 模块,我们使用 666 个可学习提示,包括 333 个正常提示和 333 个异常提示。
为确保公平性,所有模型采用相同的训练配置参数,其中轮数(epoch)设置为 151515,批大小(batch size)设置为 888。所有实验均在单块 NVIDIA RTX 4090 GPU(24GB)上使用 PyTorch 进行。初始学习率对于提示嵌入设置为 5×10−45 \times 10^{-4}5×10−4,对于 VAE 和投影层设置为 1×10−41 \times 10^{-4}1×10−4,并遵循余弦衰减调度器。关于损失超参数,我们将 KL 散度项的 β\betaβ 设置为 0.10.10.1,VAE 重建的 λ1\lambda_1λ1 设置为 1.01.01.0,语义正则化的 λ2\lambda_2λ2 设置为 0.50.50.5。公式 12 中的阈值 ξ\xiξ 设置为 0.850.850.85,VTAM 平衡因子 γ\gammaγ 设置为 0.50.50.5。
4.3 对比实验
我们将 SSVP 与领先的零样本异常检测(ZSAD)方法进行比较,包括:(1) 静态提示方法:WinCLIP(Jeong et al., 2023)、APRIL-GAN(Chen et al., 2023);(2) 动态提示方法:AnomalyCLIP(Zhou et al., 2023)、AdaCLIP(Cao et al., 2024)、Bayes-PFL(Qu et al., 2025)。
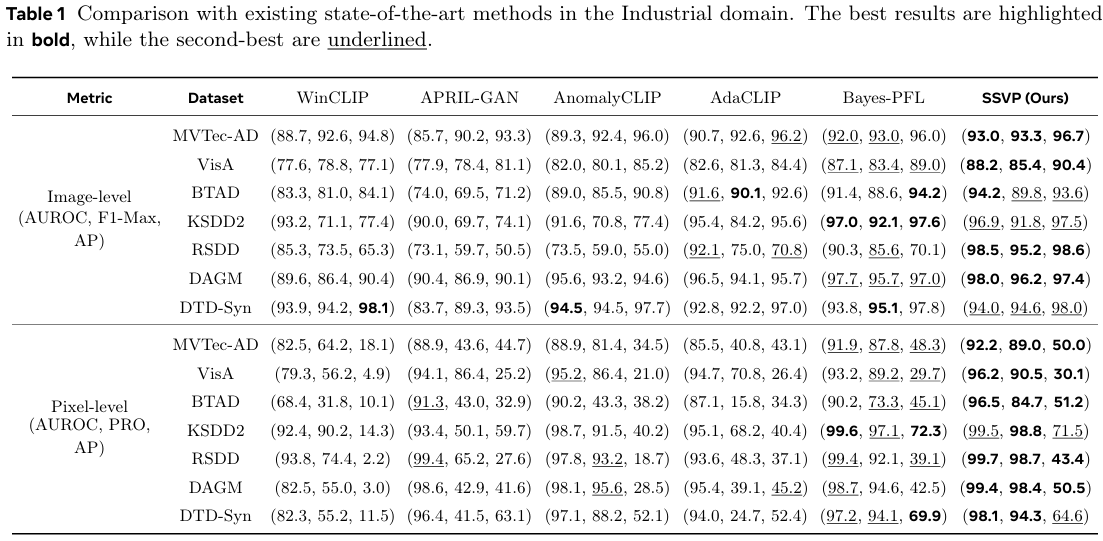
定量结果。 如表 1 所示,SSVP 在七个基准数据集上均取得了新的最先进(SOTA)性能。值得注意的是,它在 MVTec-AD 上超越了 Bayes-PFL,图像级 AUROCAUROCAUROC 达到 93.0%93.0\%93.0%,像素级 AUROCAUROCAUROC 达到 92.2%92.2\%92.2%。SSVP 通过在复杂场景(VisA、RSDD、DAGM)中占据主导地位,并在五个数据集上取得最佳像素级指标,展现了其鲁棒性。至关重要的是,PROPROPRO 指标上的持续优势验证了我们的 HSVS 模块能够有效捕获其他 CLIP 方法常常遗漏的细粒度结构异常。
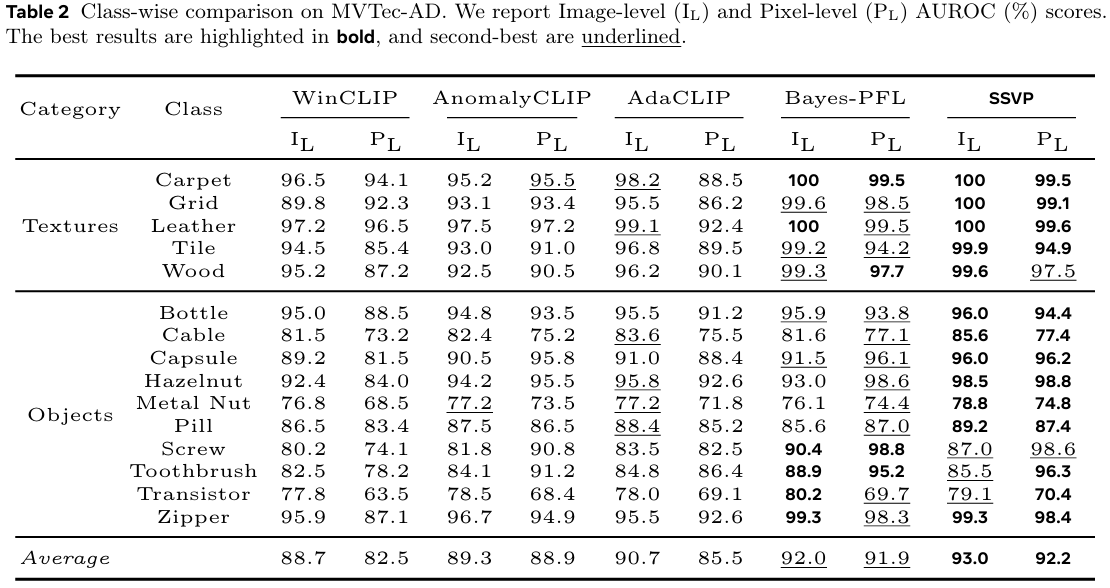
类别级性能。 表 2 详细展示了 MVTec-AD 上的结果,表明 SSVP 在各类别上表现一致。对于 Carpet(地毯)、Grid(网格)和 Leather(皮革),它实现了 100%100\%100% 的图像级 AUROCAUROCAUROC,表明 DINOv3 的高频细节得到了良好保留并与文本语义对齐。对于复杂结构物体,SSVP 在 Cable(电缆)和 Metal Nut(金属螺母)上也有显著提升,在像素级 AUROCAUROCAUROC 上分别比最强基线高出 2.0%2.0\%2.0% 和 1.6%1.6\%1.6%。这证明 VCPG 能有效引导注意力到异常敏感区域,抑制背景噪声。
4.4 可视化分析
本节通过 SOTA 对比、消融实验和多样化基准,可视化所展示的融合机制的有效性与泛化能力。
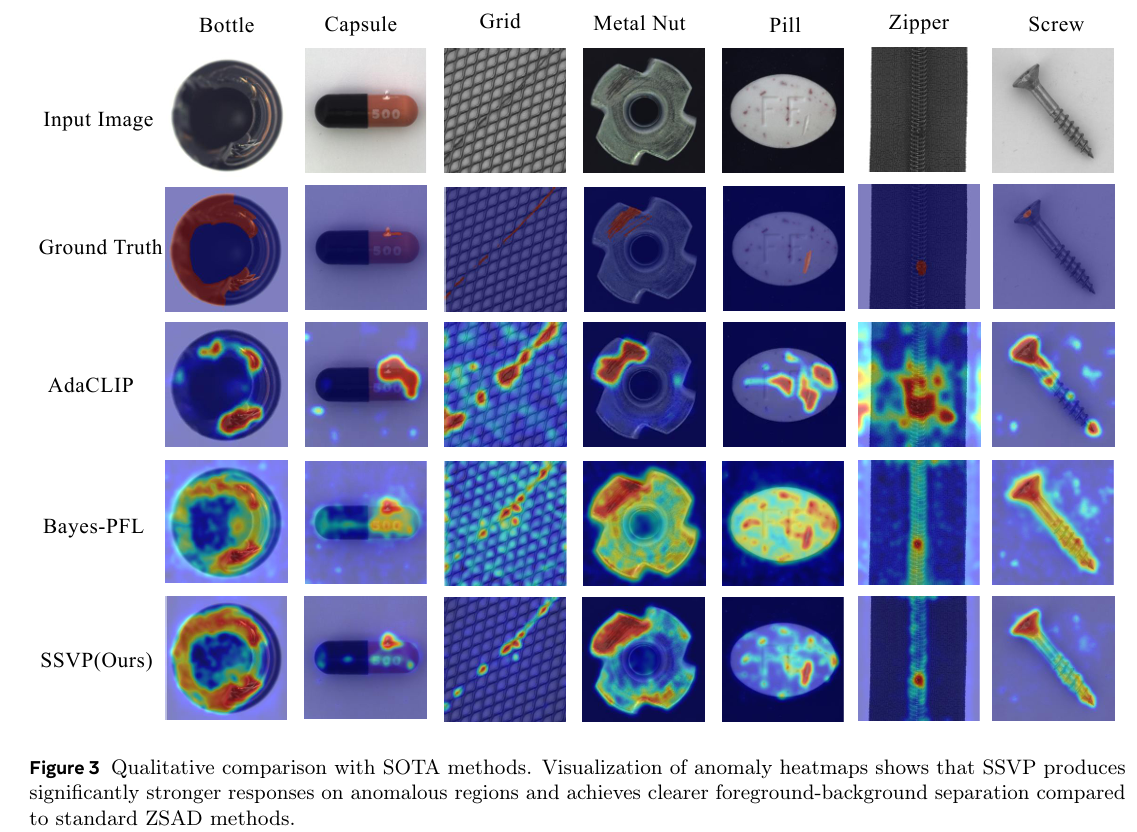
定性异常定位。 图 3 展示了典型工业样本上的分割结果。与 AdaCLIP 和 Bayes-PFL 相比,SSVP 生成具有清晰边界的精确异常图。这种精度主要归功于 HSVS 模块,它成功保留了高频结构细节。
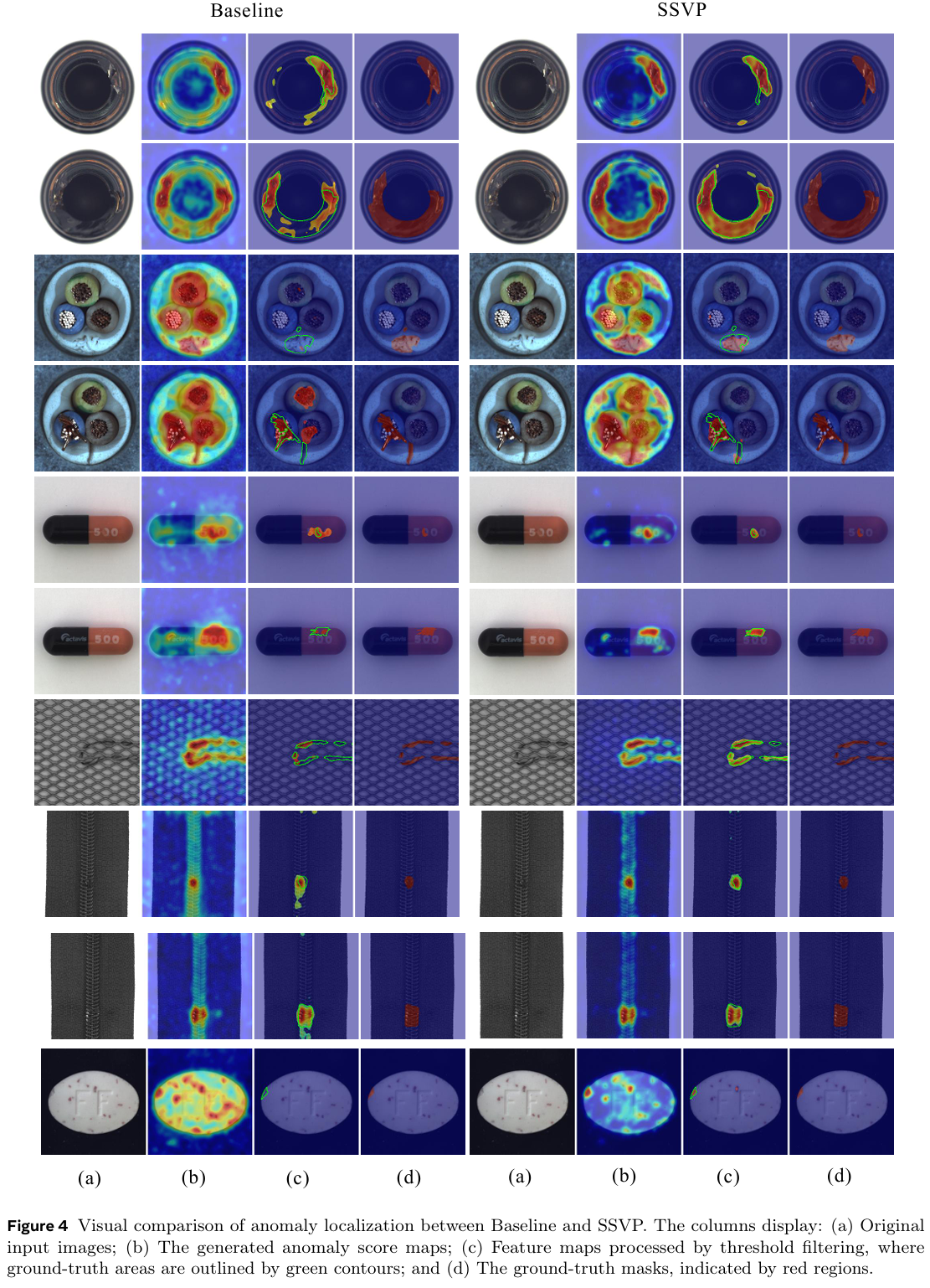
所提模块的有效性。 为了进一步验证我们特定设计带来的增益,我们在图 4 中将完整模型与基线模型进行了直接对比。观察发现,在集成我们提出的组件(HSVS 和 VCPG)后,分割结果显著更加精确。具体而言,我们的方法有效抑制了基线模型在复杂背景区域中常出现的误报噪声。SSVP 展现出对小尺度目标更卓越的敏感性,能够定位基线无法捕捉的微小缺陷。生成的异常图显示出前景缺陷与正常背景之间更清晰的分离,验证了我们语义 - 视觉对齐策略的有效性。

我们还在四个额外的挑战性基准数据集(BTAD、DAGM、DTD-Synthetic 和 KSDD2)上进一步评估了 SSVP 的鲁棒性,如图 5 所示。结果验证了我们框架强大的泛化能力。具体而言,SSVP 能很好地适应以纹理为中心的场景,在复杂图案中准确识别异常。对于具有微小缺陷的以物体为中心的数据集,该模型保持了对小目标的高敏感度。这种在不同域间的一致性表现证实,SSVP 有效地学习了可迁移的视觉 - 语义特征。
4.5 消融研究
我们在 MVTec-AD 数据集上进行组件级消融研究,以系统地验证每个模块的贡献。
我们在表 3 中评估各组件。模型 B 的简单拼接由于未对齐,导致图像级 AUROCAUROCAUROC 下降至 90.8%90.8\%90.8%。模型 C 中的 HSVS 模块实现了特征对齐,将像素级 AUROCAUROCAUROC 提升至 92.1%92.1\%92.1%。在模型 D 中加入 VCPG 后,像素级 AUROCAUROCAUROC 达到 92.7%92.7\%92.7%,增强了细粒度敏感性。完整 SSVP(模型 E)结合 VTAM 对得分进行校准,实现 93.0%93.0\%93.0% 的图像级 AUROCAUROCAUROC 和鲁棒性能。
为定量评估语义 - 视觉对齐质量,我们引入文本 - 图像响应(TIR)和语义一致性距离(SCD)。TIR-FG 衡量缺陷区域上的激活强度:
TIRFG=1∣Ωfg∣∑u∈ΩfgCosSim(vu,tabn), \text{TIR}{\text{FG}} = \frac{1}{|\Omega{fg}|} \sum_{u \in \Omega_{fg}} \text{CosSim}(\mathbf{v}u, \mathbf{t}{abn}), TIRFG=∣Ωfg∣1u∈Ωfg∑CosSim(vu,tabn),
其中 Ωfg\Omega_{fg}Ωfg 表示真实异常掩码。SCD 评估所学提示相对于静态原型的保真度:
SCD=∥tfinal−tstatic∥2. \text{SCD} = \|\mathbf{t}{final} - \mathbf{t}{static}\|_2. SCD=∥tfinal−tstatic∥2.
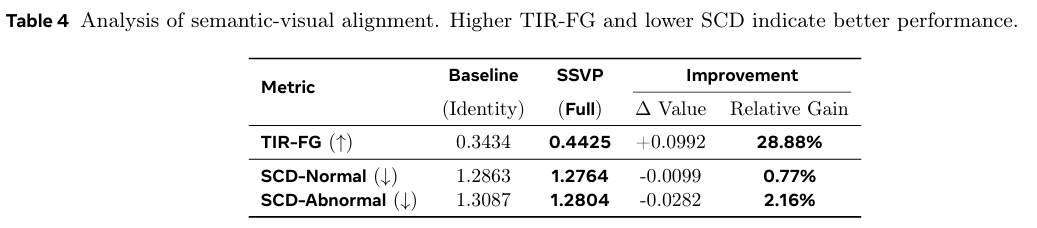
如表 4 所示,与基线相比,SSVP 将 TIR-FG 相对提升了 28.88%28.88\%28.88%,验证了我们的动态提示能有效锚定判别性视觉缺陷。对于正常和异常提示,SCD 指标均有所下降,表明我们基于边界的正则化有效防止了语义漂移并保持了类别保真度。
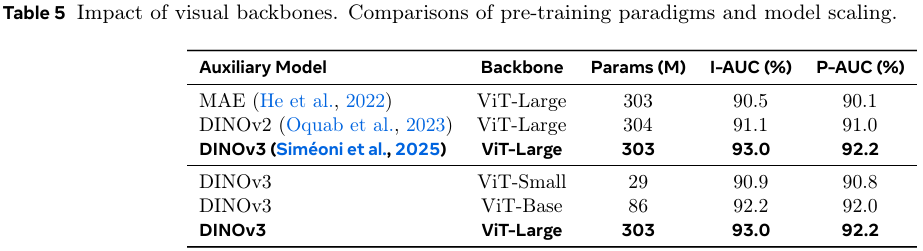
表 5 评估了视觉骨干网络。DINOv3(自监督)优于基于重建的 MAE(93.0%93.0\%93.0% vs. 90.5%90.5\%90.5% 图像级 AUROC)。将 DINOv3 从 ViT-Small 扩展到 ViT-Large 带来了持续的性能提升,证实了更大的模型为异常检测提供了更丰富的结构细节。

图 6 展示了 BTAD 数据集上的 t-SNE 嵌入。与基线分布中离散的聚类相比,SSVP 形成了一个连贯的流形,证实了我们的视觉条件机制保持了语义一致性。提示组的独特排列进一步确保了在捕获多样化异常时的多样性,同时与类别语义保持对齐。
为严格确定 SSVP 的最优超参数,我们采用逐步优化策略。我们通过坐标搜索固定 P∗={γ=0.5,ξ=0.85}\mathcal{P}^* = \{\gamma = 0.5, \xi = 0.85\}P∗={γ=0.5,ξ=0.85},并每次仅调整一个参数:γ\gammaγ(公式 (19))用于平衡全局语义与局部异常证据;ξ\xiξ(公式 (12))则设定 TfinalT_{final}Tfinal 与 TinitT_{init}Tinit 之间的余弦相似度下限,以控制语义漂移。
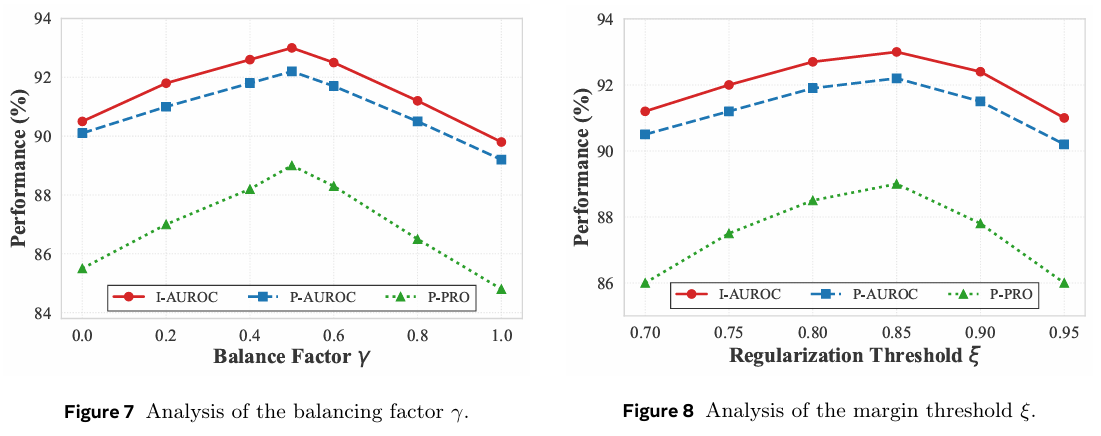
图 7 和图 8 展示了平衡因子 γ\gammaγ 与边界阈值 ξ\xiξ 的敏感性。性能在 γ=0.5\gamma = 0.5γ=0.5 时达到峰值,该值能最优地平衡缺陷检测与噪声抑制;ξ=0.85\xi = 0.85ξ=0.85 能有效正则化语义,在防止漂移的同时保持足够的多样性以捕获多样化的异常。
5 结论
本文提出了 SSVP,一种新颖的框架,通过建立 CLIP 的语义泛化能力与 DINOv3 的结构判别能力之间的深度协同,弥合了零样本工业异常检测中的粒度鸿沟。通过结合分层语义 - 视觉协同(HSVS)、视觉条件提示生成器(VCPG)以及局部校准评分(VTAM),我们的方法将静态语义匹配转化为自适应、视觉锚定的检测过程。在七个多样化基准上的大量实验表明,SSVP 确立了新的最先进水平,无需目标域监督即可有效处理以纹理为中心和以物体为中心的缺陷。尽管取得了这些进展,主要局限在于双骨干架构与迭代生成过程带来的计算开销,这限制了其在实时边缘部署中的推理速度。未来工作将聚焦于两个方向:(1) 研究知识蒸馏技术,将协同知识压缩为轻量级统一网络;(2) 探索测试时适应策略,以在未标注的目标数据流上进一步优化视觉 - 语义对齐。