文章目录
一、前言
我这里以docker desktop为例,所以部分路径是windows的
二、安装方式
1.拉取镜像
python
docker pull qdrant/qdrant2. 创建数据目录
python
mkdir D:\ProgramData\docker_data\qdrant_data3. 启动容器
win下
python
docker run -d --name my-qdrant -p 6333:6333 -p 6334:6334 -v D:\ProgramData\docker_data\qdrant_data:/qdrant/storage --restart always qdrant/qdrantlinux下改成类似这样
python
docker run -d \
--name my-qdrant \
-p 6333:6333 \
-p 6334:6334 \
-v ~/qdrant_data:/qdrant/storage \
--restart always \
qdrant/qdrant三、测试
-
查看容器状态
pythondocker ps
-
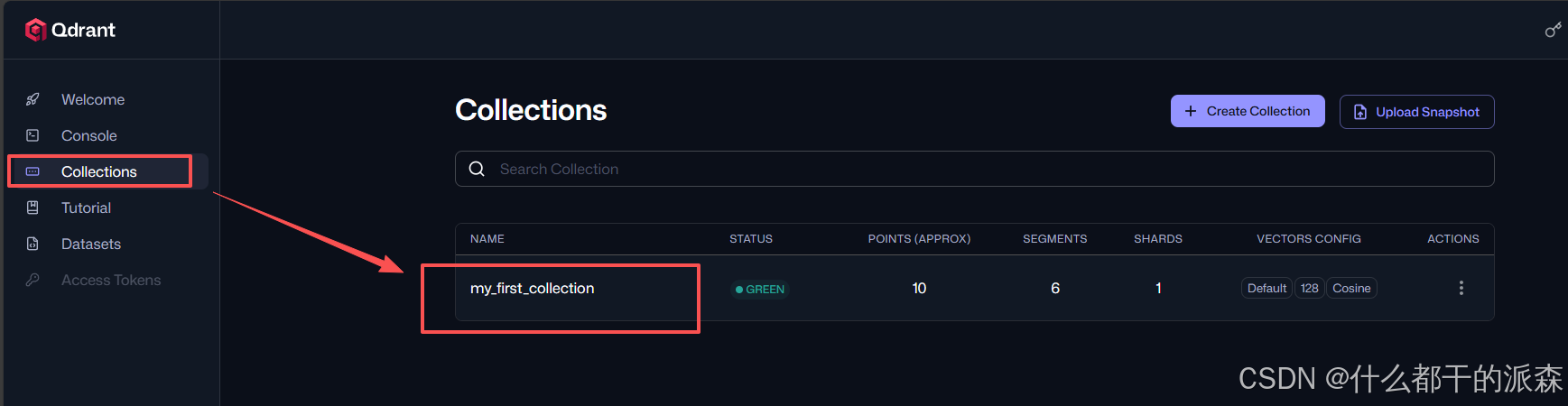
访问web管理页
http://localhost:6333/dashboard
-
向量库测试
测试代码
pythonfrom qdrant_client import QdrantClient from qdrant_client.models import Distance, VectorParams, PointStruct import numpy as np # ---------------------- 1. 连接 Qdrant ---------------------- client = QdrantClient(host="localhost", port=6333) print("Qdrant 状态:", client.get_collections()) # ---------------------- 2. 创建集合 ---------------------- collection_name = "my_first_collection" if not client.collection_exists(collection_name): client.create_collection( collection_name=collection_name, vectors_config=VectorParams(size=128, distance=Distance.COSINE) ) print(f"集合 {collection_name} 创建成功") else: print(f"集合 {collection_name} 已存在") # ---------------------- 3. 插入数据 ---------------------- vectors = np.random.rand(10, 128).tolist() points = [ PointStruct( id=i, vector=vectors[i], payload={"text": f"这是第 {i} 条数据", "category": "test"} ) for i in range(10) ] client.upsert(collection_name=collection_name, points=points) print("数据插入成功") # ---------------------- 4. 向量搜索(新版正确写法) ---------------------- query_vector = np.random.rand(128).tolist() search_results = client.query_points( collection_name=collection_name, query=query_vector, # 注意:新版用 query,不是 query_vector limit=3 ) # 打印结果 print("\n搜索结果:") for result in search_results.points: print(f"ID: {result.id}, 相似度: {result.score:.4f}, 元数据: {result.payload}")命令行输出
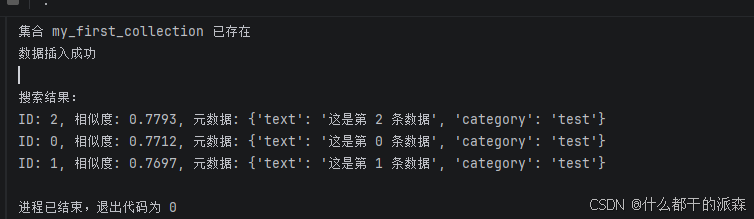
dashboard回显