前言
随着大语言模型(LLM)技术的飞速迭代,应用开发范式正经历从"单一脚本调用"向"复杂系统工程"的转变。在构建企业级 LLM 应用时,开发者面临的核心挑战在于如何平衡系统的稳定性与灵活性:既要适配快速更迭的模型接口(如 DeepSeek V3.2),又要满足多样化的业务场景(如代码审计、日志分析、运维自动化)。
本文将深入剖析如何利用 Rust 语言强大的类型系统与所有权机制,结合 DeepSeek V3.2 强大的推理能力,构建一个高内聚、低耦合的插件化 LLM 应用框架。该架构通过定义清晰的 Trait 边界,实现了核心逻辑与业务实现的物理隔离,确保了系统的可扩展性与类型安全。
一、 架构设计理念与分层模型
传统的大模型应用往往将 API 调用、提示词工程(Prompt Engineering)与业务逻辑硬编码在单一代码库中。这种紧耦合结构导致模型切换成本极高,且难以复用功能模块。为此,本框架采用了经典的分层插件化架构。
text
┌─────────────────────────────────────┐
│ 应用层 (Application Layer) │
│ - 插件管理器 (PluginManager) │
│ - 业务编排 (Orchestration) │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 插件层 (Plugin Layer) │
│ - LLM 插件接口 (LLMPlugin Trait) │
│ - 功能插件接口 (FeaturePlugin) │
└─────────────────────────────────────┘
↓
┌─────────────────────────────────────┐
│ 核心层 (Core Layer) │
│ - 配置管理 (Config) │
│ - 日志系统 (Tracing) │
│ - 错误处理 (Anyhow/Thiserror) │
└─────────────────────────────────────┘应用层 负责加载插件并调度执行流;插件层 定义了标准化的接口协议,任何实现了该协议的模块均可被动态加载;核心层则提供基础设施支持。这种设计确保了当引入 DeepSeek V3.2 等新模型时,仅需新增一个 LLM 插件,而无需修改核心业务代码。
二、 开发环境构建与工具链配置
Rust 的开发环境以其现代化和工具链的完善著称。构建本框架的首要步骤是配置基础编译环境。
在 Linux 环境下,系统级构建工具是必不可少的先决条件。通过包管理器安装 curl 和 build-essential,后者包含了 GCC、Make 以及 glibc 头文件,这是编译 Rust 项目中涉及 C 语言绑定的 crate(如某些加密库或系统接口库)所必需的基础设施。
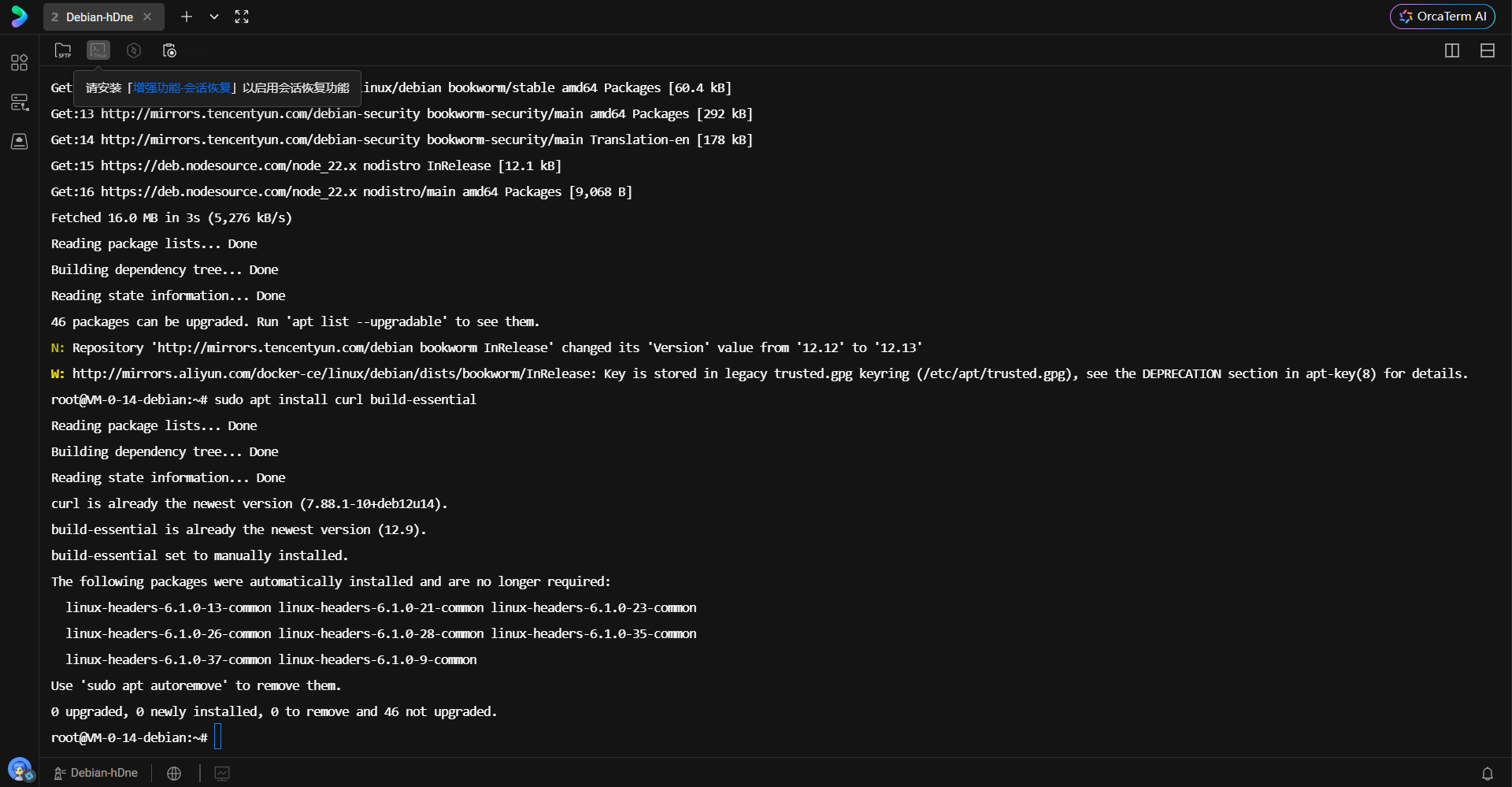
执行以下命令完成基础工具安装:
bash
sudo apt update
sudo apt install curl build-essential下图展示了在终端中执行上述命令的过程,系统正在读取软件包列表并准备安装必要的编译工具链。
接下来安装 Rust 语言的核心工具链。官方提供的 rustup 脚本是管理 Rust 版本及组件的最佳实践。该脚本不仅安装编译器 rustc 和包管理器 cargo,还会配置环境变量。
bash
curl --proto '=https' --tlsv1.2 -sSf https://sh.rustup.rs | sh安装过程中,脚本会自动检测系统架构并下载对应的预编译二进制文件。
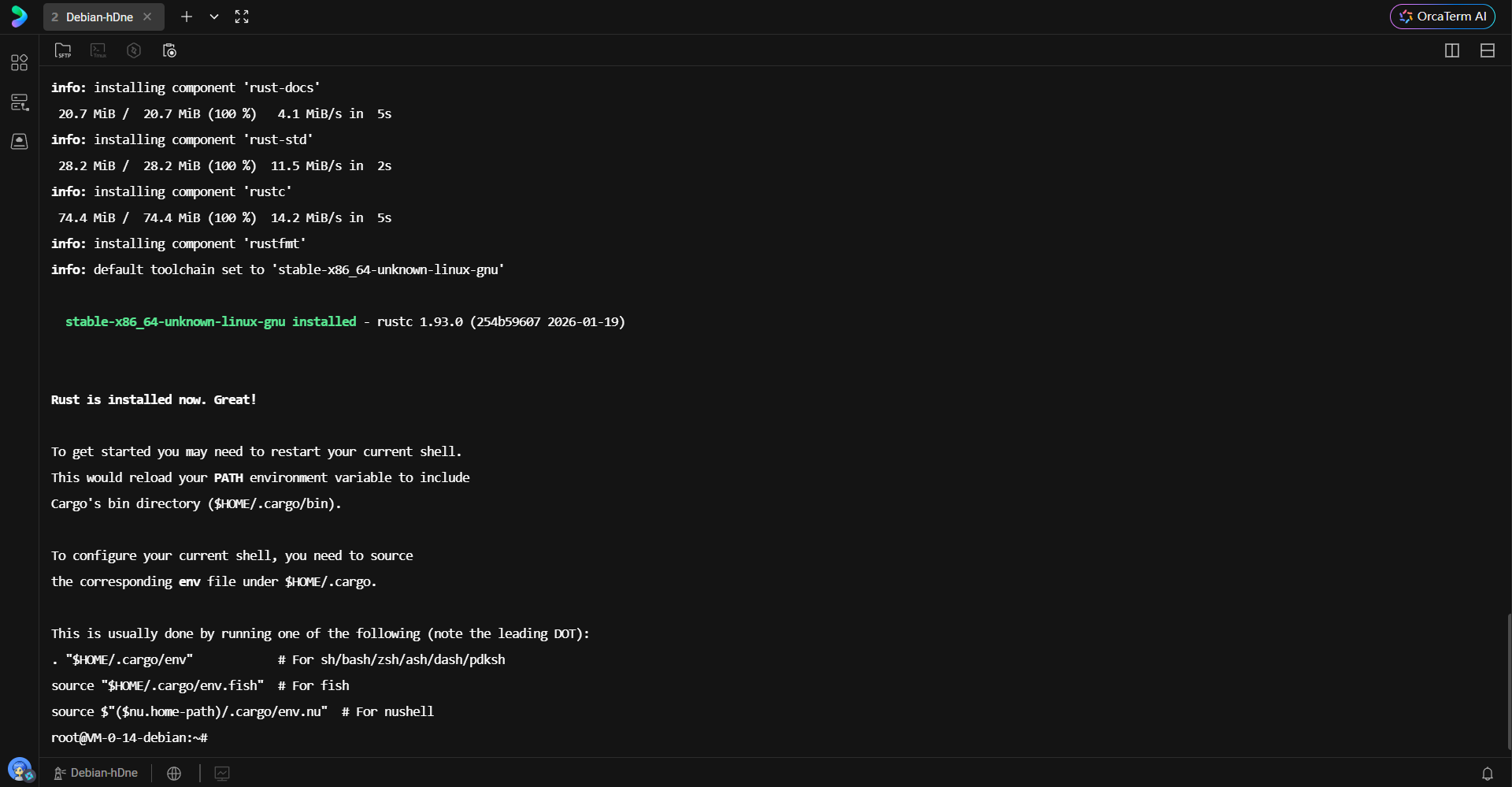
安装脚本执行完毕后,环境变量的变更通常只在新的 Shell 会话中生效。为了立即在当前终端使用 Rust 工具链,需要手动加载环境配置脚本:
bash
. "$HOME/.cargo/env"验证安装是否成功的标准做法是检查编译器与包管理器的版本号。这确保了后续开发基于稳定的 Rust 版本。
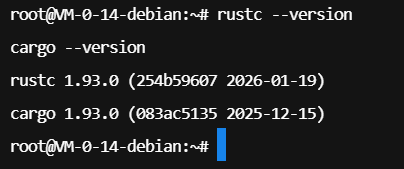
为了提升开发体验,将环境加载命令写入 .bashrc 文件,确保每次启动终端时自动初始化 Rust 环境,避免重复手动配置。

三、 DeepSeek V3.2 模型接入准备
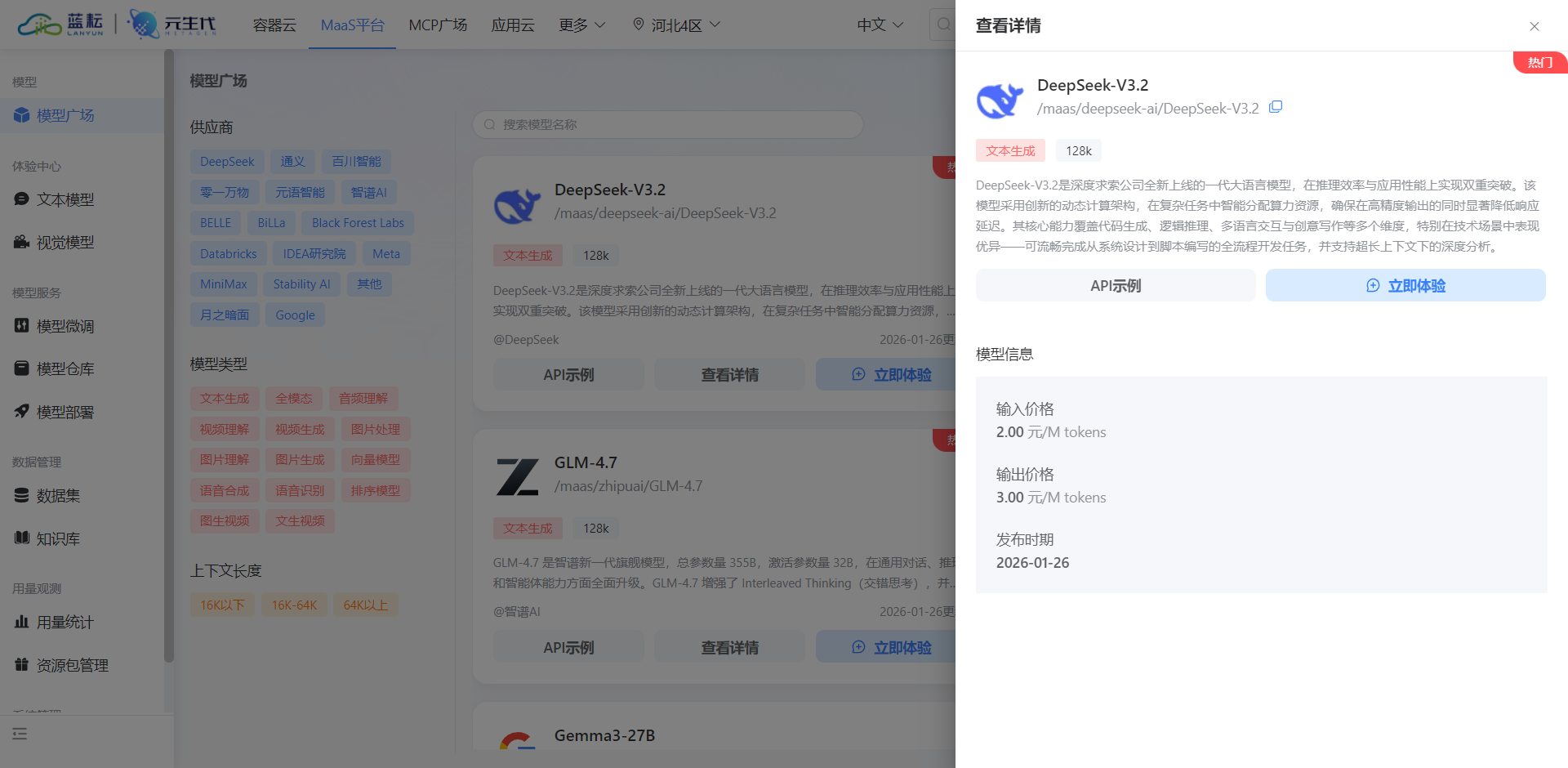
本框架的核心智能引擎选用 DeepSeek V3.2 模型。接入该模型需要通过蓝耘(Lanyun)MaaS 平台获取访问凭证。在平台控制台中创建 API Key 是建立安全连接的第一步,该 Key 将作为后续 HTTP 请求的鉴权令牌。
bash
https://console.lanyun.net/#/register?promoterCode=0131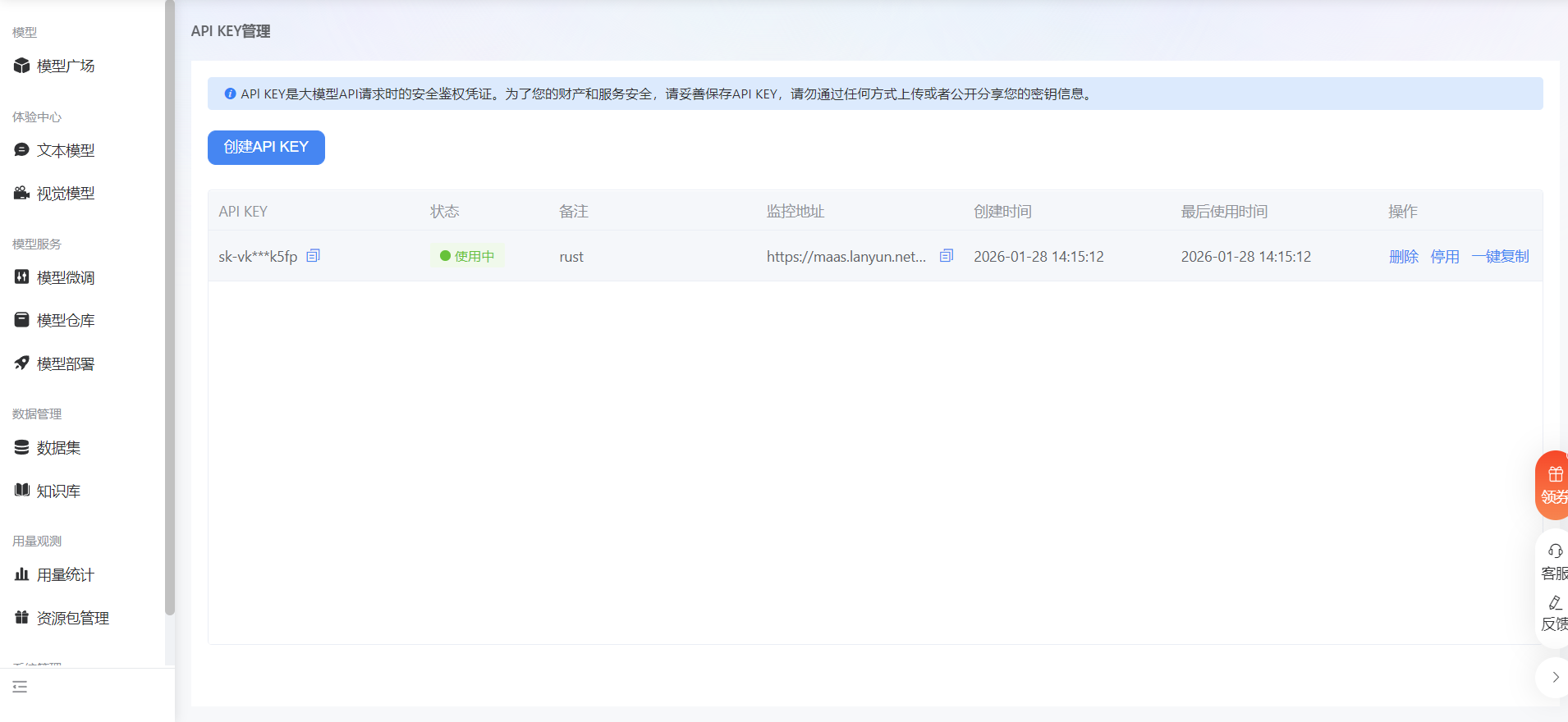
在模型广场中,选择 /maas/deepseek-ai/DeepSeek-V3.2。DeepSeek V3.2 在代码生成与逻辑推理任务上表现优异,非常契合本框架涉及的代码审计与运维指令生成场景。
四、 Rust 工作空间(Workspace)工程结构搭建
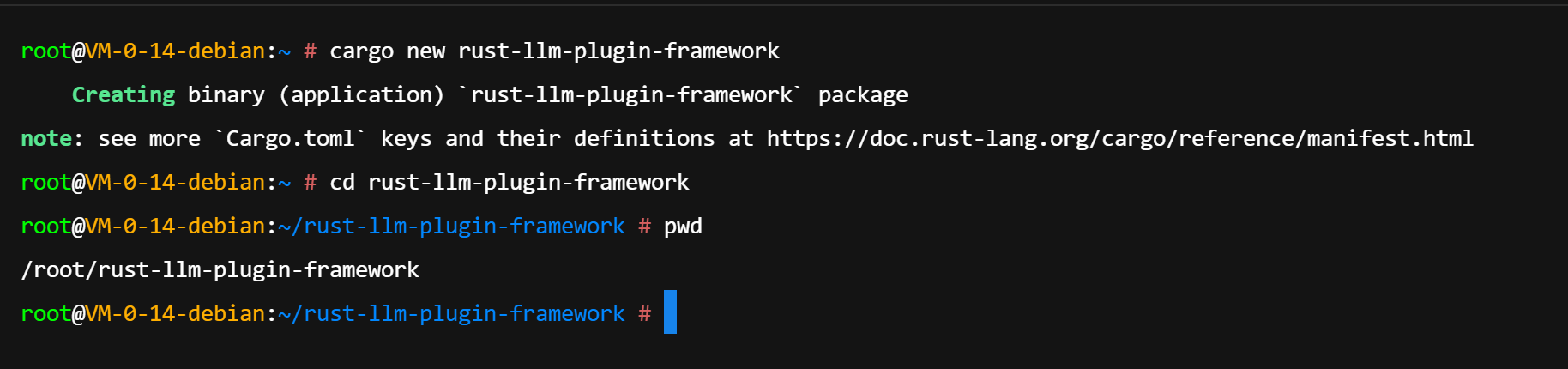
为了有效管理核心库、插件接口定义以及具体插件实现,本项目采用 Cargo Workspace 机制。Workspace 允许在同一个代码仓库中管理多个 Package,它们共享 Cargo.lock 文件与构建目录(target),极大地优化了编译速度与依赖管理。
使用 cargo new 命令初始化项目,随后进入项目目录:
4.1 配置文件设计
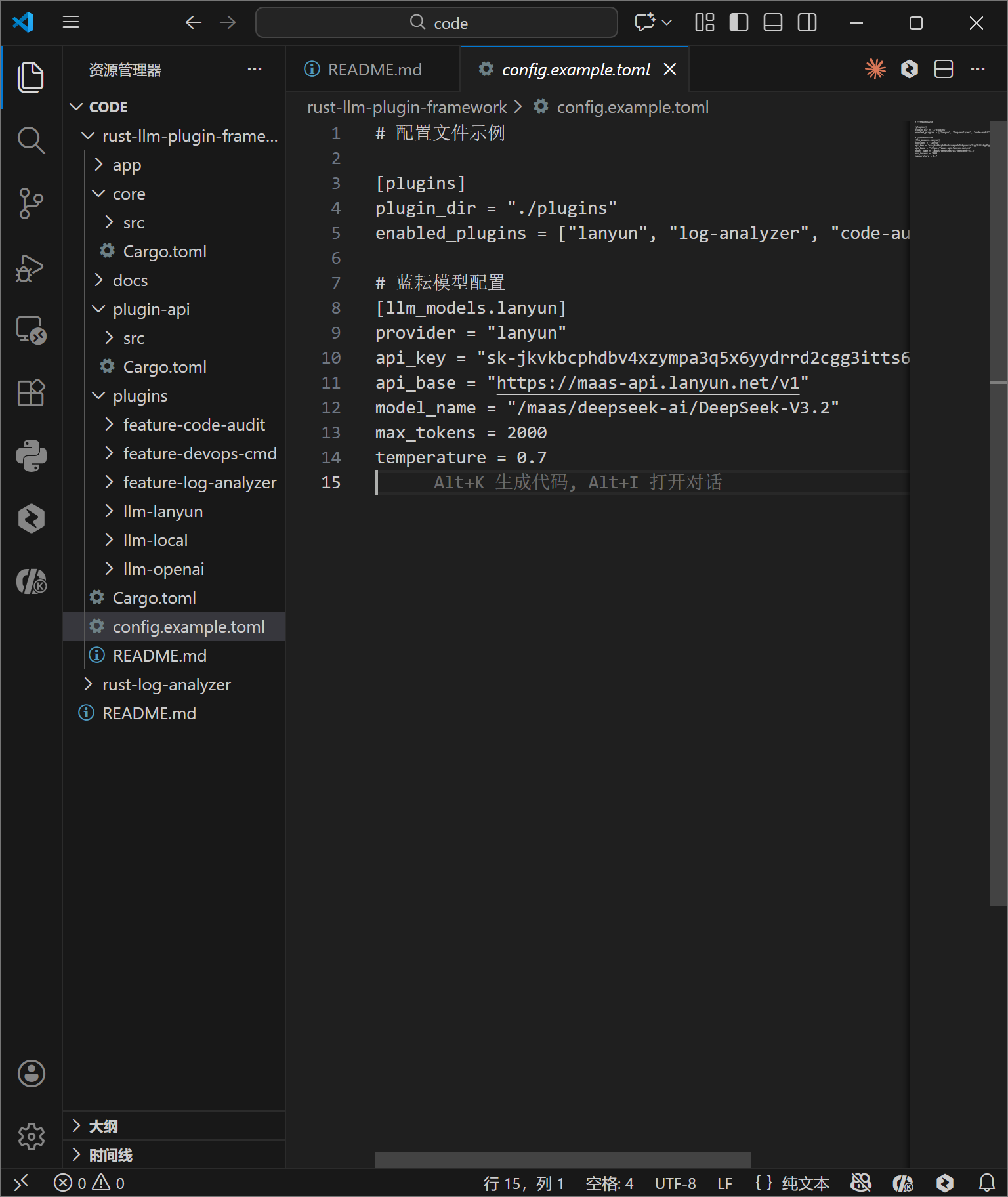
配置系统是应用灵活性的基石。config.example.toml 文件定义了插件加载路径、启用的插件列表以及 LLM 模型的具体参数。通过将 API Key、模型名称(model_name)与代码解耦,运维人员可以在不重新编译的情况下调整推理参数(如 temperature 或 max_tokens)。
toml
# 配置文件示例
[plugins]
plugin_dir = "./plugins"
enabled_plugins = ["lanyun", "log-analyzer", "code-audit", "devops-cmd"]
# 蓝耘模型配置
[llm_models.lanyun]
provider = "lanyun"
api_key = "sk-jxxxxxxxxxxxxxxxxxx"
api_base = "https://maas-api.lanyun.net/v1"
model_name = "/maas/deepseek-ai/DeepSeek-V3.2"
max_tokens = 2000
temperature = 0.7下图展示了配置文件的实际内容,清晰的 TOML 结构使得配置项一目了然。
4.2 依赖管理与 Workspace 定义
根目录下的 Cargo.toml 是整个 Workspace 的总控文件。这里定义了 members 列表,包含核心库 core、接口定义库 plugin-api、应用入口 app 以及各个具体的插件 crate。同时,通过 [workspace.dependencies] 统一声明了第三方库的版本,如异步运行时 tokio、序列化库 serde、日志库 tracing 以及错误处理库 anyhow。
这种集中式版本管理避免了不同子项目依赖同一库的不同版本导致的编译冗余或兼容性冲突。
五、 核心层与接口定义实现
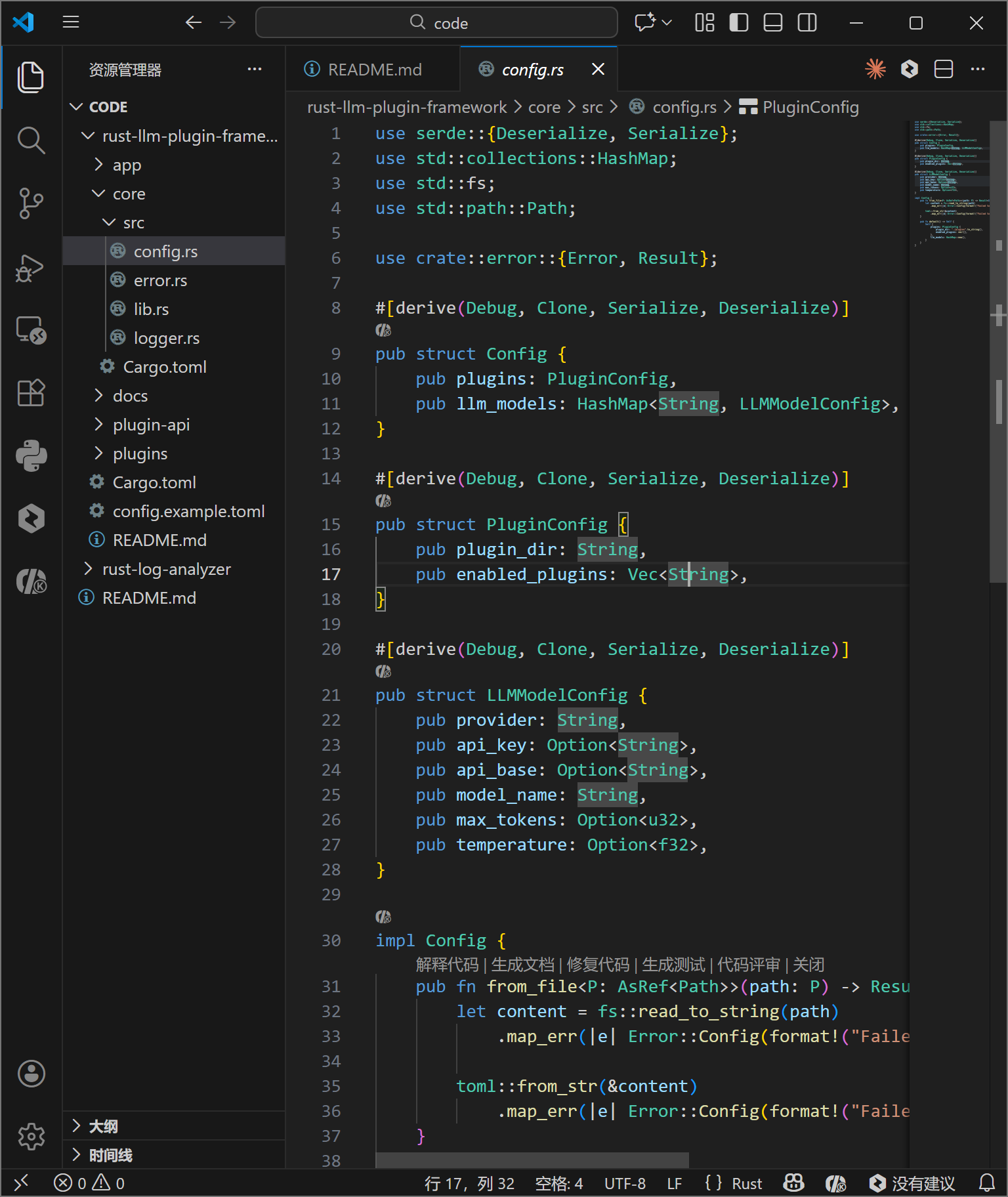
5.1 配置解析与错误模型
core 模块负责处理配置文件的反序列化。利用 serde 库的强大功能,可以将 TOML 文本直接映射为 Rust 结构体 Config。LLMModelConfig 结构体中使用了 Option 类型来处理可选参数,体现了 Rust 对空值安全处理的哲学。
错误处理方面,使用 thiserror 宏定义了枚举 Error,将 I/O 错误、序列化错误、网络错误等统一封装。这使得上层调用者可以统一处理异常,同时保留了底层的错误上下文。
5.2 插件 Trait 接口设计
虽然文中未直接展示 plugin-api 的源码,但从 PluginManager 的实现可以推断出接口的设计。LLMPlugin 和 FeaturePlugin 是核心 Trait。
- LLMPlugin : 负责抽象大模型的调用。输入为 Prompt,输出为生成的文本。需支持异步调用 (
async-trait)。 - FeaturePlugin : 定义业务功能。包含
metadata()用于返回插件元数据,以及execute()方法用于执行具体逻辑。
这种接口设计遵循了依赖倒置原则(DIP),高层模块不依赖低层模块,二者都依赖于抽象。
六、 业务插件实现:代码审计功能
以 feature-code-audit 插件为例,展示了如何实现一个具体的业务插件。该插件的核心逻辑在于利用正则表达式(Regex)扫描源代码中的安全漏洞。
在 lib.rs 中,CodeAuditPlugin 结构体持有编译好的正则表达式对象。在 default() 方法中初始化这些正则模式(如 SQL 注入关键字、XSS 攻击特征、硬编码密钥格式),避免了每次执行时重复编译正则的开销。
execute 方法接收代码文本,逐行扫描并匹配安全规则。一旦发现风险,系统会生成包含行号、风险等级和代码片段的结构化报告。通过 serde_json,审计结果被封装为标准化的 JSON 格式,便于后续处理或展示。
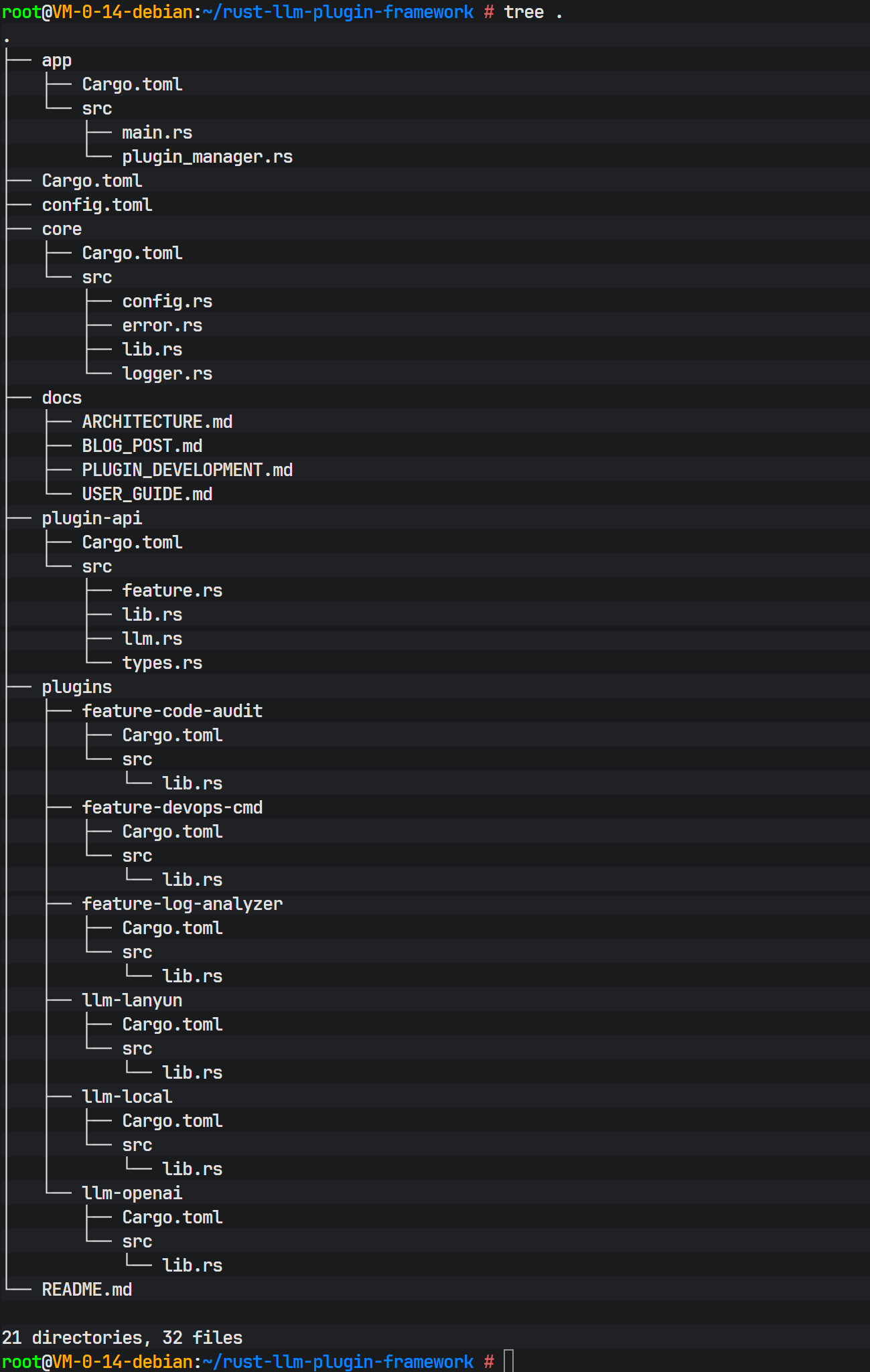
七、 应用层编排与插件管理
应用层是系统的指挥中枢。plugin_manager.rs 中的 PluginManager 结构体使用 HashMap<String, Arc<Box<dyn FeaturePlugin>>> 来存储已注册的插件。
- HashMap: 提供 O(1) 的查找效率,根据插件名称快速定位。
- Box: 因为 Trait 对象在编译期大小未知,必须通过堆分配(Box)来存储。
- Arc: 原子引用计数指针,使得插件实例可以在多线程或异步任务中安全共享。
- dyn FeaturePlugin: 动态分发(Dynamic Dispatch),允许在运行时处理实现了相同接口的不同类型插件。
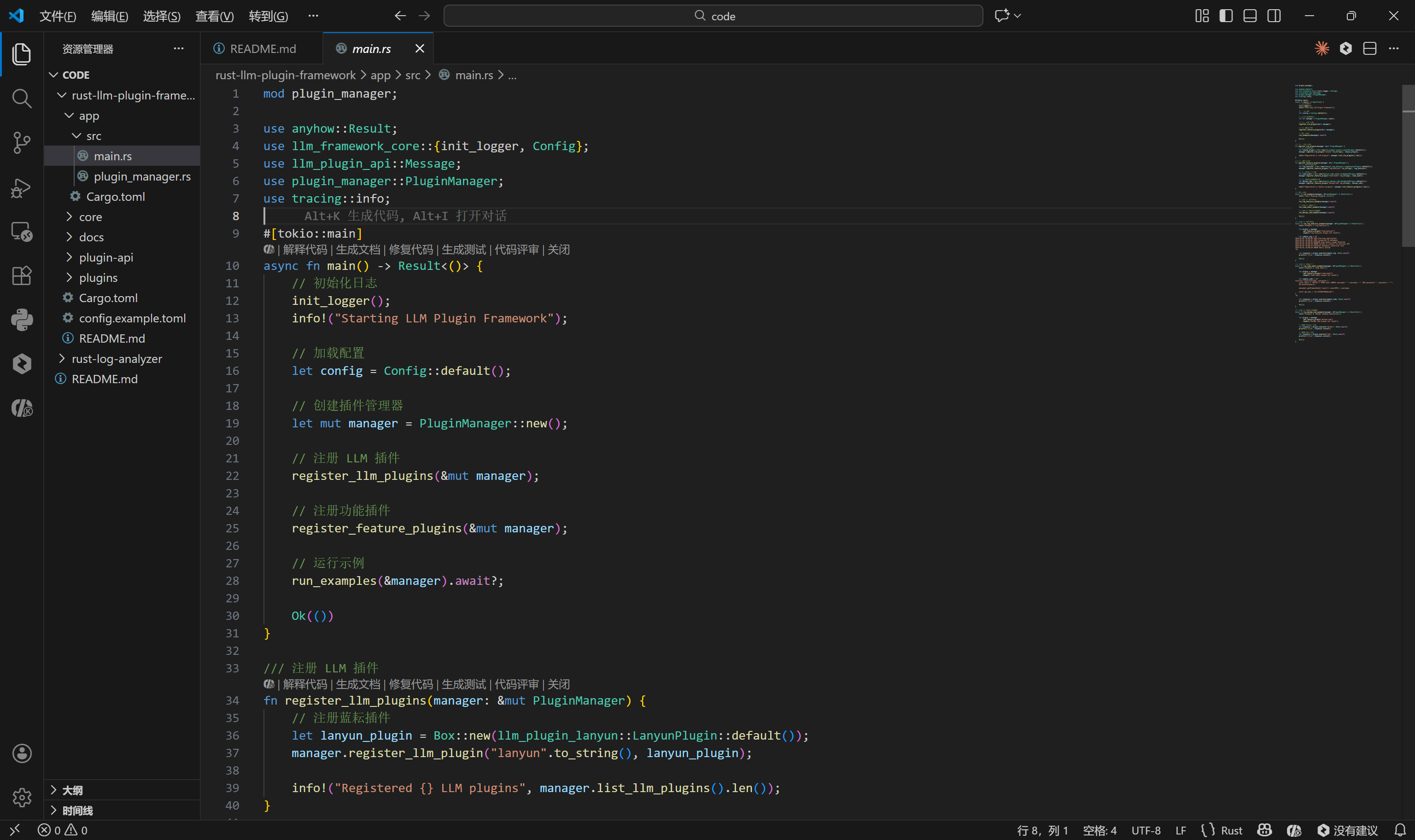
main.rs 展示了完整的启动流程:初始化日志系统 -> 加载配置 -> 实例化插件管理器 -> 注册插件 -> 运行示例。这种显式的注册机制使得系统的启动过程清晰可控。
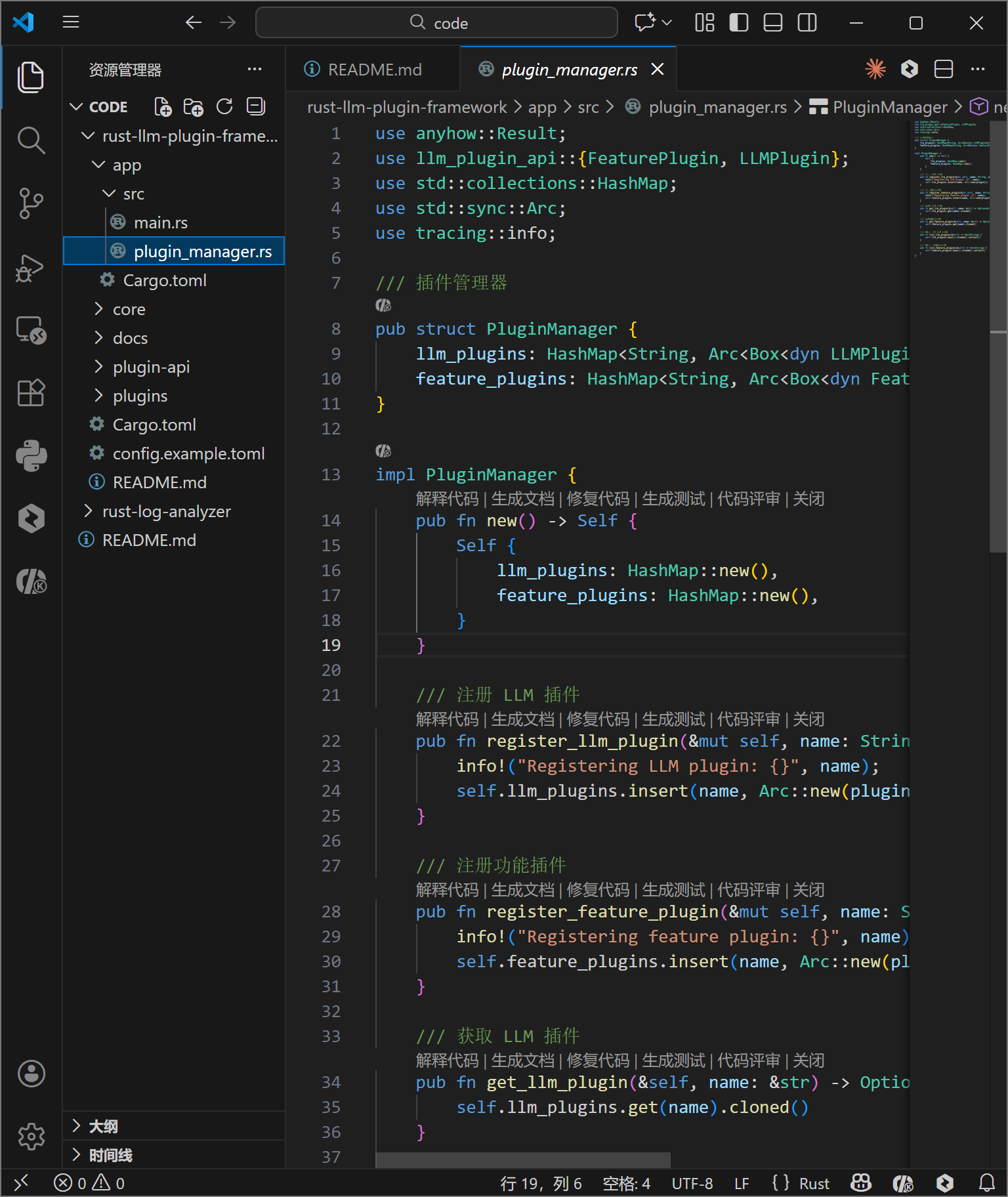
app 的入口文件通过 tokio::main 宏将主函数转换为异步运行时入口,这是驱动整个异步 IO 系统的关键。
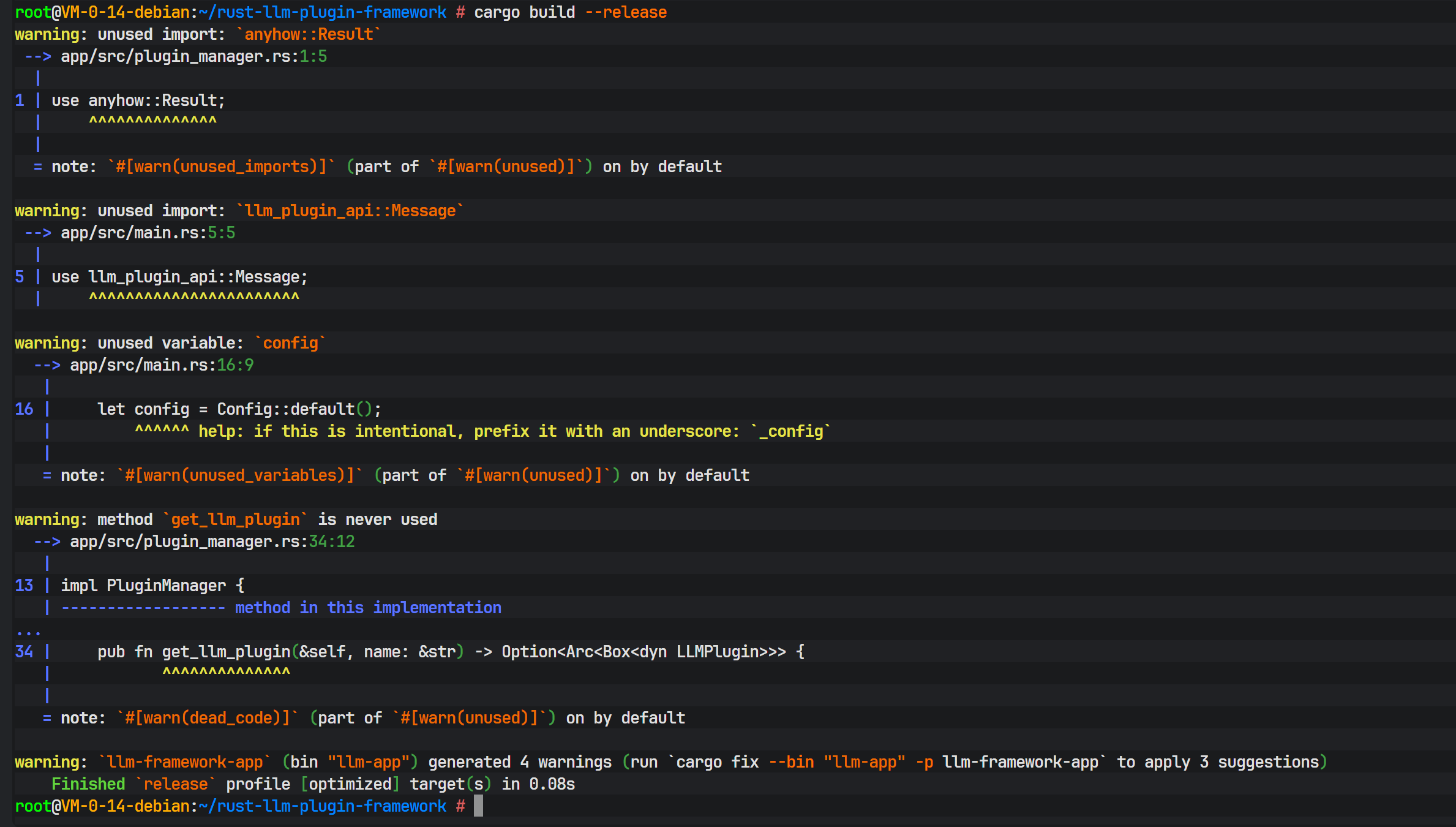
八、 编译调试与问题修复
在首次执行 cargo build --release 进行优化编译时,可能会遇到依赖缺失的问题。编译器报错指出在 llm.rs 文件中使用了 futures::Stream,但 Cargo.toml 中未声明该依赖。
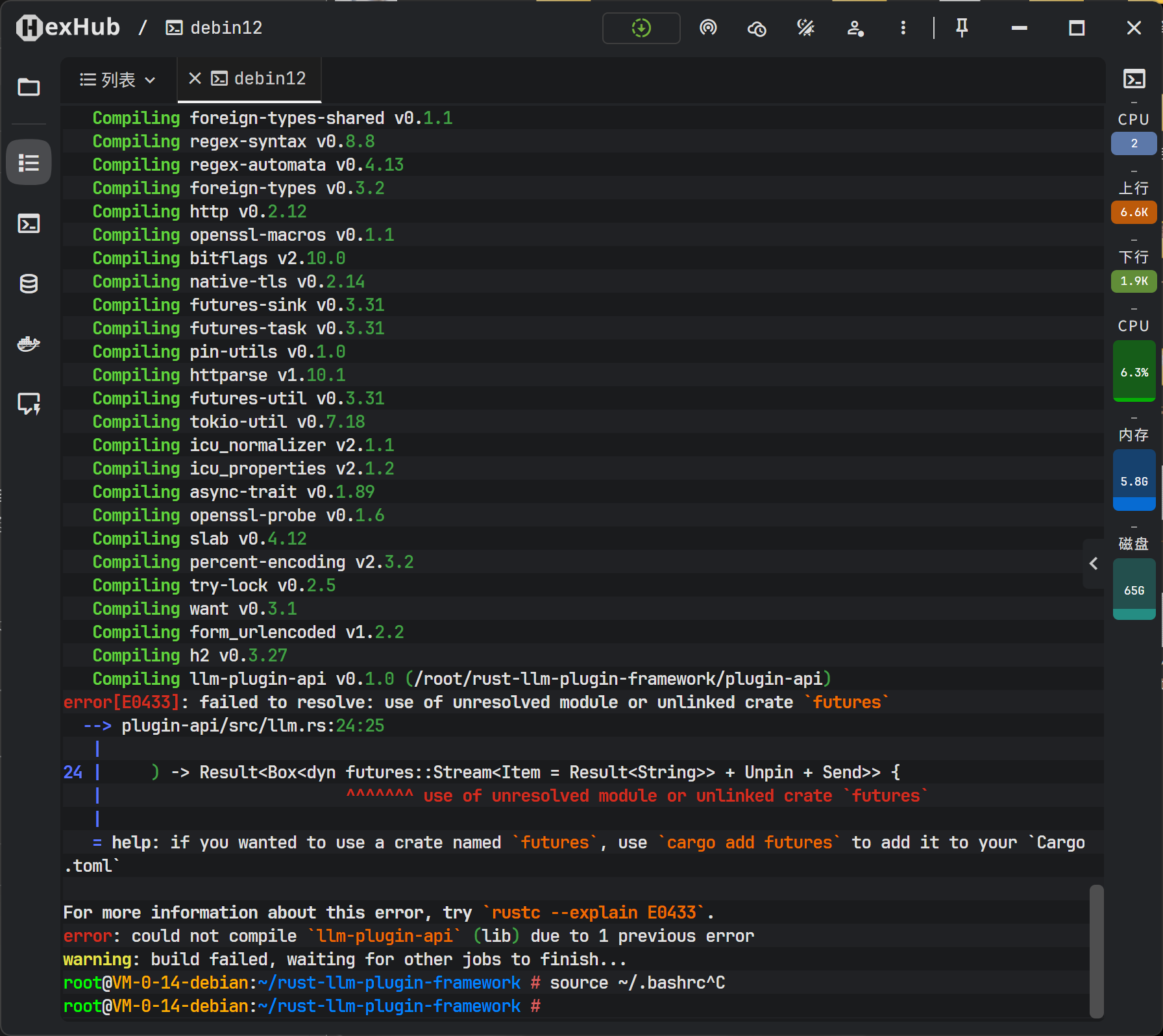
这是 Rust 编译器严格依赖检查的体现。解决方法是在 plugin-api 的 Cargo.toml 中明确添加 futures crate。futures 提供了异步流处理的基础抽象,对于处理 LLM 的流式响应至关重要。
修正依赖后,再次编译通过。Rust 的编译器虽然严格,但其报错信息通常非常精准,能有效引导开发者解决问题。
九、 运行演示与效果验证
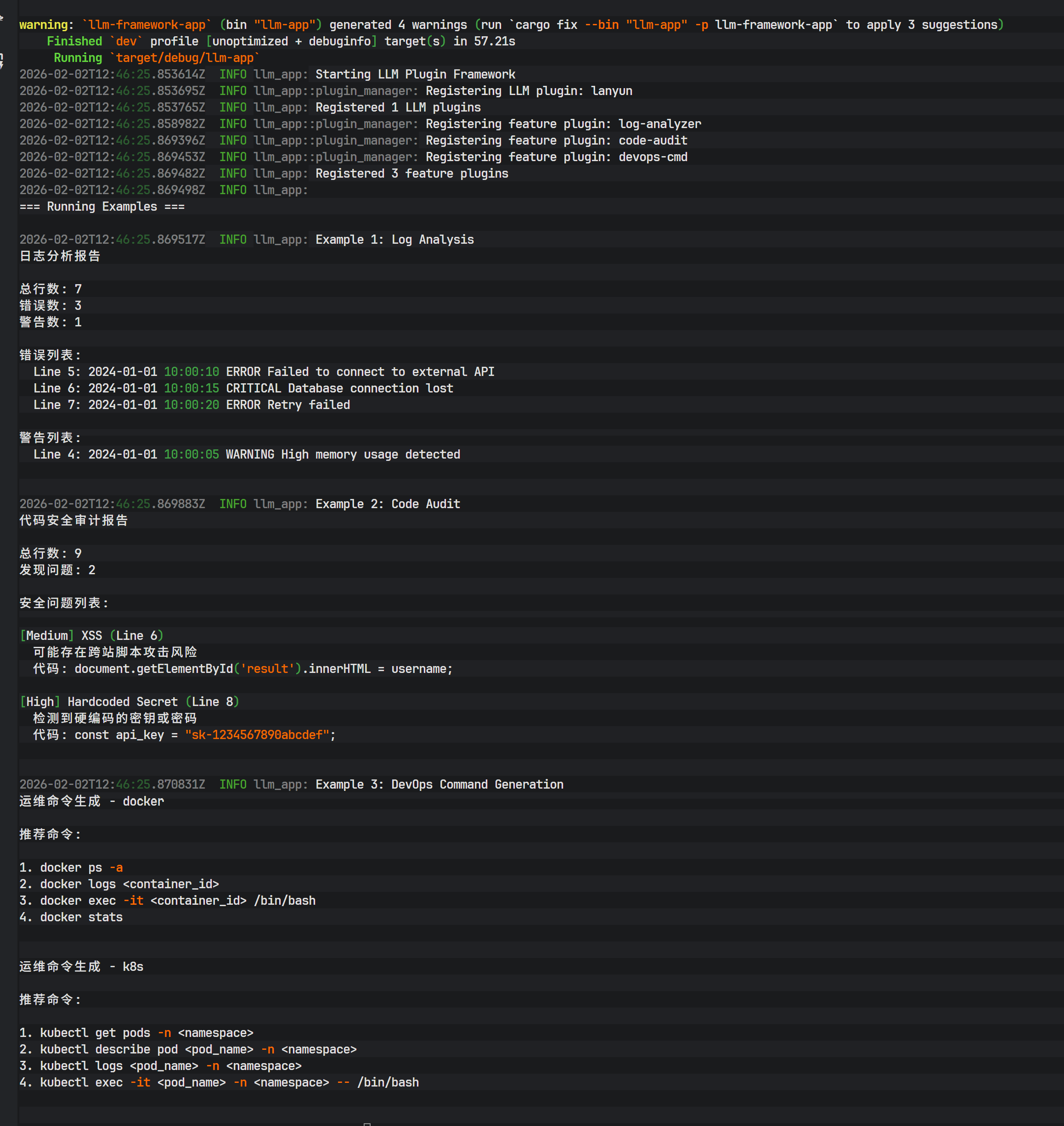
执行 cargo run --bin llm-app 启动应用。控制台输出展示了各个插件的执行结果。
- Log Analysis: 成功识别日志中的 CRITICAL 错误。
- Code Audit: 扫描示例代码,准确指出了 SQL 注入风险和硬编码 API Key。
- DevOps Command: 生成了 Docker 和 K8s 的操作指令。
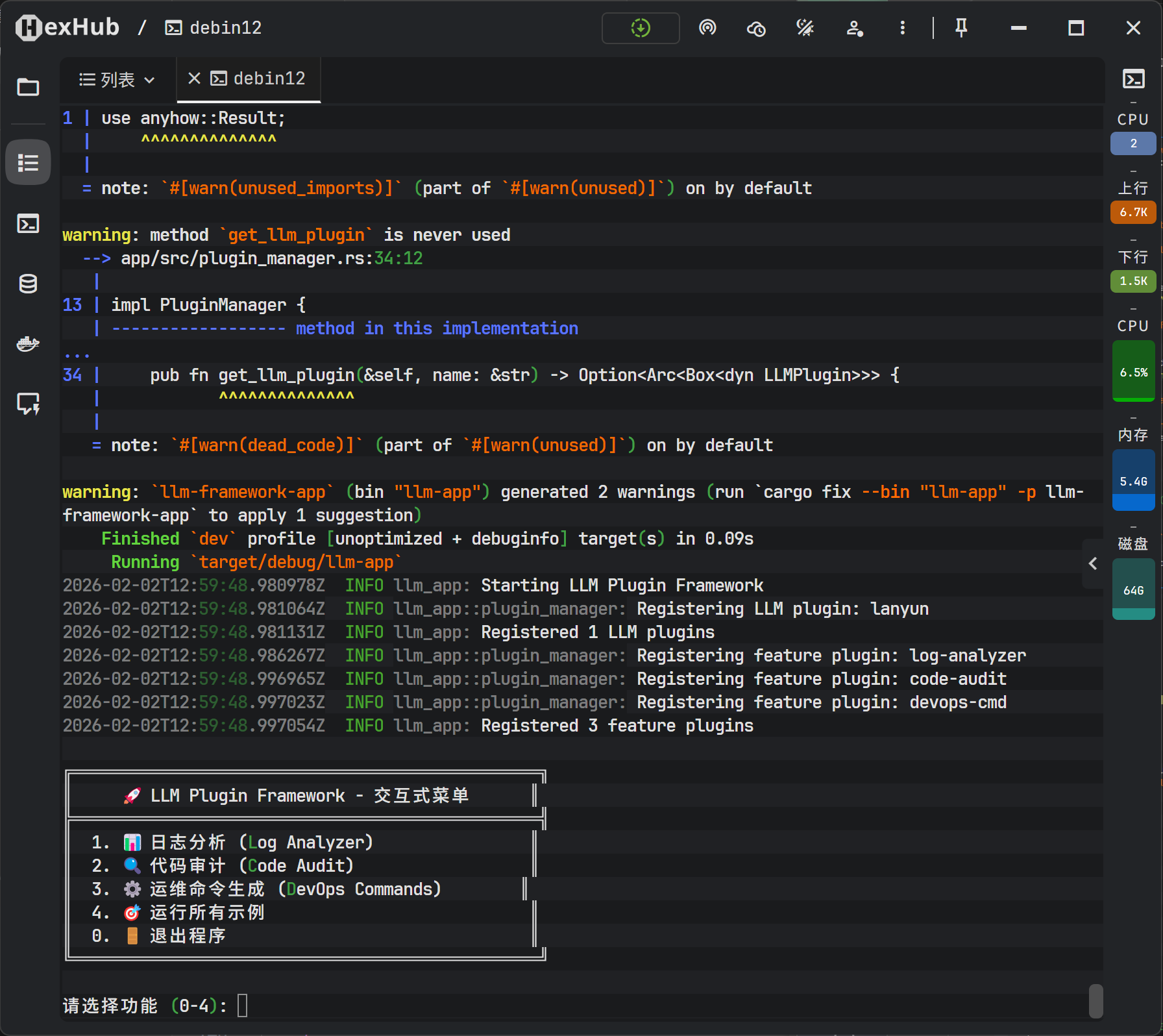
为了增强用户体验,进一步开发了交互式终端菜单(TUI)。用户可以通过方向键选择功能模块,实时输入待分析的内容。这种交互方式使得演示更加直观,也证明了框架可以轻松对接不同的前端接口(CLI、Web、GUI)。
十、 总结
本文构建的 Rust LLM 插件化框架,成功演示了如何利用 Rust 的高级特性(Trait、Async/Await、Ownership)结合 DeepSeek V3.2 模型,打造一个高性能、安全且易于扩展的应用系统。通过将业务逻辑封装为独立插件,系统具备了极强的适应性,能够灵活应对不断变化的 AI 应用场景。该架构不仅解决了单一模型适配多场景的难题,也为构建大规模、生产级的 AI Agent 平台提供了坚实的工程参考。