前言:数据库索引的进化之路
在数字化浪潮席卷全球的今天,数据已成为企业最核心的资产之一。面对海量数据的存储与检索挑战,数据库索引技术如同"数据世界的导航仪",直接影响着系统性能的生死线。从传统关系型数据库的B+树索引,到分布式系统的LSM树结构,索引的演变史本质上是一场性能与复杂度的博弈------如何在保证查询效率的同时,应对数据规模爆炸式增长与并发访问的极致需求?
索引:数据检索的"第一性原理"
索引的本质,是通过预排序的数据结构将随机I/O转化为顺序I/O,从而突破磁盘性能的物理瓶颈。早期的数据库系统依赖B树(B-Tree)及其变种B+树,通过多级平衡树结构实现高效的点查询与范围扫描。例如,MySQL的InnoDB引擎以B+树为核心,将数据按主键有序存储,叶子节点形成链表以支持快速范围查询。然而,B+树的局限性逐渐显现:频繁的节点分裂导致写放大,随机更新引发性能波动,而面对海量数据时,树高增长带来的元数据管理成本也愈发高昂。
B-link树:并发控制的破局者
为了解决B+树在高并发场景下的锁竞争问题,B-link树应运而生。它在B+树的非叶子节点增加"兄弟指针"(Link Pointer),允许查询时直接跳过已锁定的节点,显著降低锁粒度。PostgreSQL的索引实现便采用这一设计,在保持B+树有序性的同时,提升了写入吞吐量。这一改进揭示了索引设计的趋势:在结构微调中寻找性能增益的边际。
LSM树:顺序写与分层合并的智慧
当数据写入成为瓶颈时,LSM树(Log-Structured Merge Tree)以颠覆性的思路登场。它摒弃随机更新,将数据先写入内存MemTable,再按层合并为有序的SSTable,利用磁盘顺序写的高效性实现"以空间换时间"。HBase、RocksDB等NoSQL系统依托LSM树,在写入密集型场景中实现每秒数十万次操作。但这一设计也带来读放大与空间放大问题,需通过布隆过滤器、分层压缩等策略平衡取舍。
索引的未来:从单一结构到混合范式
现代数据库的索引设计已不再局限于单一结构。例如,Cassandra结合LSM树与二级B+树索引,兼顾写入与查询;TiDB的TiKV采用RocksDB(LSM树)与TiDB Server的B+树混合架构,实现分布式事务下的高效索引。与此同时,AI驱动的自适应索引(如基于查询模式的动态索引选择)正在探索索引的"智能化"未来。
2.索引初识
索引是数据库中用于加速数据检索的核心数据结构,其种类可按功能属性、存储结构、数据结构等多个维度分类。不同分类方式对应不同的应用场景,以下结合主流数据库(如MySQL、PostgreSQL)的特性,详细介绍各类索引的特点、适用场景及实现差异。
2.1 按功能属性分类
此类分类基于索引的业务功能和约束条件,是数据库设计中最直观的分类方式。
- 主键索引(Primary Key Index)
定义:主键索引是唯一索引的特殊类型,用于标识表中每一行的唯一性,要求索引列非空且唯一(NOT NULL + UNIQUE)。
特点:每个表只能有一个主键索引(因主键唯一标识一行);
在InnoDB存储引擎中,主键索引默认是聚簇索引(Clustered Index),即索引与数据行物理存储在一起,叶子节点直接包含完整数据行。
适用场景:
- 表的唯一标识列(如用户表的user_id、订单表的order_id);
- 需要快速主键查询(如SELECT * FROM users WHERE id = 1)或范围查询(如SELECT * FROM orders WHERE id BETWEEN 100 AND 200)的场景。
sql
CREATE TABLE users (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键索引(聚簇索引)
name VARCHAR(50) NOT NULL
);- 唯一索引(Unique Index)
定义:确保索引列的值唯一 (MySQL中唯一索引可以有多个NULL值,因为NULL不等于任何值,包括NULL)
特点:用于保证数据的唯一性(如用户表的email、手机号);可以是单列或组合列(组合列要求组合值唯一)。
适用场景:
- 需要唯一约束但非主键的列(如email、username);
- 避免重复数据插入(如注册时的邮箱唯一性校验)。
sql
CREATE UNIQUE INDEX idx_users_email ON users(email); -- 唯一索引(非聚簇)- 普通索引(Normal Index)
定义:最基本的索引类型,无唯一性约束,允许重复值和NULL。
特点:用于加速频繁查询但无唯一性要求的列(如商品表的category_id、订单表的status);
可以是单列或组合列(组合列需遵循最左前缀原则,即查询时需从组合列的最左列开始使用)。
适用场景:
- 经常出现在WHERE、JOIN、ORDER BY子句中的列(如SELECT * FROM products WHERE category_id = 5);
- 需要加速查询但无需唯一约束的场景。
sql
CREATE INDEX idx_products_category ON products(category_id); -- 普通索引(非聚簇)- 组合索引(Composite Index)
定义:在多个列上创建的索引(如(user_id, order_date)),用于加速多列查询。
特点:
(1) 遵循最左前缀原则(Leftmost Prefix Rule):查询时需从组合列的最左列开始使用,否则索引失效。例如,组合索引(a, b, c)可覆盖a、a,b、a,b,c的查询,但无法覆盖b、c、b,c的查询;
(2) 组合列的顺序需根据查询频率和选择性(列值的唯一程度)排序,将选择性高的列放在左侧。
适用场景:
- 多条件查询(如SELECT * FROM orders WHERE user_id = 1 AND order_date > '2023-01-01');
- 排序或分组操作(如SELECT * FROM orders WHERE user_id = 1 ORDER BY order_date)。
sql
CREATE INDEX idx_orders_user_date ON orders(user_id, order_date); -- 组合索引(非聚簇)- 全文索引(Full-Text Index)
定义:专门用于文本内容的快速检索,能够对CHAR、VARCHAR、TEXT等文本类型字段中的内容进行分词处理并建立索引。
特点:
(1) 存储引擎支持:MySQL 5.6版本前仅支持MyISAM,5.6及以上版本同时支持InnoDB
(2) 支持高级文本查询功能,包括关键词匹配、布尔查询和短语查询等,查询语法示例:MATCH(content) AGAINST('database index')
适用场景:
- 文本数据量较大的字段(如文章正文、评论内容等)
- 需要实现高效全文搜索的应用场景(如博客系统、论坛内容检索等)5. 全文索引(Full-Text Index)
sql
CREATE FULLTEXT INDEX idx_articles_content ON articles(content); -- 全文索引(非聚簇)- 空间索引(Spatial Index)
定义:用于空间数据类型(如GEOMETRY、POINT、LINESTRING、POLYGON)的索引,支持空间查询(如包含、相交、距离)。
特点:MySQL中仅支持MyISAM存储引擎;创建空间索引的列必须声明为NOT NULL。
适用场景:
地理信息系统(GIS)数据(如地图中的点、线、面);
需要空间查询的场景(如"查找附近的餐厅""查询某区域内的订单")。
sql
CREATE SPATIAL INDEX idx_restaurants_location ON restaurants(location); -- 空间索引(非聚簇)2.2 按存储结构分类
此类分类基于索引与数据行的物理存储关系,决定了数据检索的方式(是否需要"回表")。
- 聚簇索引(Clustered Index)
定义:索引与数据行物理存储在一起,即索引的叶子节点直接包含完整的数据行。
特点:
(1) 每个表只能有一个聚簇索引(因数据行只能按一种顺序物理存储);
(2) 在InnoDB中,聚簇索引默认是主键索引(若未定义主键,则选择第一个唯一非空索引;若仍无,则隐式创建ROW_ID作为聚簇索引);
优点:数据访问速度快(无需回表),适合主键查询和范围查询(如SELECT * FROM users WHERE id = 1);
缺点:插入/更新成本高(若插入无序数据,会导致"页分裂",即数据行需要移动到正确的物理位置,消耗额外磁盘空间和I/O)。
适用场景:
- 主键查询频繁的场景(如订单表按order_id查询);
- 范围查询频繁的场景(如SELECT * FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31')。
- 非聚簇索引(Non-Clustered Index)
定义:索引与数据行物理分离,索引的叶子节点存储索引键值和指向数据行的指针(在InnoDB中是主键值,在MyISAM中是数据行的物理地址)。
特点:
每个表可以有多个非聚簇索引(如唯一索引、普通索引、组合索引);
查询时需两次查找(先查非聚簇索引找到主键值,再查聚簇索引找到数据行),称为"回表"(Bookmark Lookup);
优点:插入/更新成本低(不影响数据物理顺序);
缺点:查询效率低于聚簇索引(需回表)。
适用场景:
辅助查询(如按email查用户,需先查email的非聚簇索引,再回表查数据);
频繁更新的列(如status列,非聚簇索引不会影响数据物理顺序)。
这里我再额外补充一下,面试中常问到的另一个概念,覆盖索引。
覆盖索引(Covering Index)可以是非聚簇索引,也可以是聚簇索引。
覆盖索引是指查询所需的所有字段均包含在索引中,因此无需回表访问数据行即可返回结果。例如:
sql
-- 假设索引包含 (user_id, name)
SELECT user_id, name FROM users WHERE user_id = 100;若索引 (user_id, name)存在,则查询可直接从索引中获取数据,无需回表。
覆盖索引与非聚簇索引的关系
-
非聚簇索引的覆盖场景
在 非聚簇索引 中,叶子节点存储索引键值和主键(InnoDB)或数据地址(MyISAM)。若查询的字段全部包含在非聚簇索引中,则构成覆盖索引。例如:
非聚簇索引结构:(email, phone)(假设主键为 id)
查询:SELECT email, phone FROM users WHERE email = 'a@b.com'
索引直接返回 email和 phone,无需回表,属于覆盖索引。
-
聚簇索引的覆盖场景
在 聚簇索引 中,叶子节点存储完整数据行。若查询的字段全部包含在聚簇索引键中,则同样构成覆盖索引。例如:
聚簇索引结构:主键 (id),数据行包含 id, name, age
查询:SELECT id, name FROM users WHERE id BETWEEN 100 AND 200
聚簇索引直接返回 id和 name,无需回表,属于覆盖索引。
| 维度 | 覆盖索引(非聚簇) | 覆盖索引(聚簇) |
|---|---|---|
| 索引类型 | 非聚簇索引(二级索引) | 聚簇索引(主键索引) |
| 数据来源 | 索引键值 + 主键(InnoDB) | 完整数据行 |
| 适用场景 | 多列查询、避免回表 | 主键范围查询、直接获取完整数据 |
| 示例 | 组合索引 (email, phone) 的查询 | 主键索引 (id) 的查询 |
-
非聚簇索引的覆盖优势
减少回表开销:例如,在订单表中为 (user_id, order_date)建立组合索引,查询用户最近订单时无需回表。
优化分页查询:通过覆盖索引直接获取排序字段和主键,避免全表扫描。
-
聚簇索引的覆盖特性
主键查询的高效性:若查询仅需主键字段,聚簇索引可直接返回数据,效率等同于覆盖索引。
范围查询的天然优势:如 SELECT * FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31',聚簇索引直接按顺序返回数据。
所以, 覆盖索引可以是非聚簇索引:当非聚簇索引包含查询所需的所有字段时,直接通过索引返回结果。
覆盖索引也可以是聚簇索引:当聚簇索引包含查询所需的所有字段时,同样无需回表。
核心判断标准:是否所有查询字段均被索引覆盖,而非索引类型本身。
2.3 按数据结构分类
此类分类基于索引的底层数据结构, 注重底层实现,决定了索引的查询效率和适用场景。
- B+树索引(B+ Tree Index)
定义:最常用的索引结构,基于B+树(B-Tree的变种)实现,所有数据行存储在叶子节点,且叶子节点通过双向链表连接(便于范围查询)。 这个第3部分我会展开说说, 毕竟是mysql数据索引的重点。
特点:
支持等值查询(=)、范围查询(>, <, BETWEEN)、排序(ORDER BY);
非叶子节点仅存储索引键和子节点指针(不存储数据),因此树高更低(减少磁盘I/O);
是MySQL(InnoDB、MyISAM)、PostgreSQL等关系型数据库的默认索引结构。
适用场景:
几乎所有查询场景(除哈希索引更适合的等值查询);
需要范围查询或排序的场景(如SELECT * FROM users WHERE age > 18 ORDER BY age)。
- 哈希索引(Hash Index)
定义:基于哈希表实现,通过将索引键值转换为哈希值,直接定位到数据行的存储位置。
特点:仅支持等值查询(=、IN),不支持范围查询(>, <)或排序(ORDER BY);
查询效率极高(O(1)时间复杂度),但哈希冲突(不同键值转换为相同哈希值)会影响性能;
仅Memory存储引擎(MySQL)和PostgreSQL(部分场景)支持。
适用场景:
内存数据库(如Redis、Memcached)的键值查询;
需要极快等值查询的场景(如SELECT * FROM users WHERE id = 1,但B+树索引也能满足,除非数据量极大且查询极频繁)。
- R树索引(R Tree Index)
定义:用于空间数据的索引结构,基于R树(Rectangle Tree)实现,将空间对象(如点、线、面)用最小边界矩形(MBR)表示,便于空间查询(如包含、相交、距离)。
特点:
支持空间查询(如SELECT * FROM restaurants WHERE location WITHIN (POLYGON(...)));
是PostgreSQL(GiST、SP-GiST)、MySQL(空间索引)的空间索引底层结构。
适用场景:
地理信息系统(GIS)数据(如地图中的点、线、面);
需要空间查询的场景(如"查找附近的餐厅""查询某区域内的订单")。
- 倒排索引(Inverted Index)
定义:用于全文检索的索引结构,将单词映射到包含该单词的文档(如文章),便于快速查找包含特定单词的文档。
特点:支持全文搜索(如MATCH(content) AGAINST('database index'));
是MySQL(全文索引)、Elasticsearch(搜索引擎)的核心索引结构。
适用场景:
文本内容较多的列(如文章表的content、评论表的comment);
需要实现全文搜索功能的场景(如博客、论坛的内容检索)。
2.4 索引选择的关键因素
查询场景:根据查询类型(等值、范围、全文、空间)选择对应的索引类型(如等值查询选哈希索引,范围查询选B+树索引);
数据特性:根据数据的唯一性(主键选主键索引,唯一约束选唯一索引)、数据类型(文本选全文索引,空间数据选空间索引)选择索引;
性能需求:根据插入/更新频率(频繁更新选非聚簇索引,频繁查询选聚簇索引)、查询效率(热点数据选自适应哈希索引,多列查询选组合索引)选择索引;
存储引擎:不同存储引擎支持的索引类型不同(如MyISAM支持空间索引,InnoDB支持聚簇索引)。
常见误区
- 索引越多越好❌:索引会增加插入/更新成本(需维护索引结构),且占用额外存储空间;
- 聚簇索引一定比非聚簇索引好❌:聚簇索引适合主键查询和范围查询,但插入/更新成本高;非聚簇索引适合频繁更新的列,但查询效率低;
- 哈希索引适合所有等值查询❌:哈希索引不支持范围查询和排序,且哈希冲突会影响性能,B+树索引更适合大多数等值查询场景。
3.索引数据结构介绍
3.1 B+ Tree
B+树是现代数据库与文件系统的"索引基石"。
B+树(B+ Tree)是一种多路平衡查找树,是数据库(如MySQL InnoDB)、文件系统(如NTFS、EXT4)中最常用的索引结构。
它通过"索引与数据分离"的设计,完美解决了磁盘存储的随机I/O瓶颈,同时支持高效的等值查询、范围查询和顺序访问,是现代数据存储的"隐形骨架"。
| 维度 | B树 | B+树 |
|---|---|---|
| 数据存储 | 所有节点存数据 | 仅叶子节点存数据 |
| 查询路径 | 可在内部节点终止(路径不固定) | 必须到叶子节点(路径固定) |
| 范围查询效率 | 中序遍历(低效) | 链表遍历(高效) |
| 空间利用率 | 低(树高较高) | 高(树高较低) |
| 应用场景 | 随机访问频繁的小规模数据 | 大数据量、范围查询频繁的数据库索引 |
3.1.1 B+树的核心定义与结构
B+树是B树(B-Tree)的变种,其核心特征是"数据仅存储在叶子节点,内部节点仅作索引"。一棵m阶B+树(m为"阶数",表示每个节点最多有m个子节点)的结构分为三层:
- 根节点(Root Node)
树的顶端节点,是索引的"入口"。
存储索引键值(如user_id)和子节点指针(指向内部节点或叶子节点)。
作用:引导查找方向,将查询路由到正确的子树。
-
内部节点(Internal Node)
位于根节点与叶子节点之间,是"索引的中间层"。
仅存储索引键值和子节点指针,不存储实际数据。
作用:缩小查找范围,将查询从根节点逐步引导至叶子节点(类似"目录")。
-
叶子节点(Leaf Node)
树的底层节点,是实际数据的存储位置。
存储完整数据行(如InnoDB的聚簇索引)或索引键值+主键值(如InnoDB的二级索引),以及指向下一个叶子节点的指针(形成双向链表)。
作用:直接返回查询结果(如SELECT * FROM users WHERE id = 1);
支持范围查询(如SELECT * FROM users WHERE id BETWEEN 100 AND 200),通过叶子节点的链表顺序遍历即可。
3.1.2 B+树的关键特点
B+树之所以成为数据库索引的"标配",源于其适配磁盘存储的设计:
-
数据仅存于叶子节点,内部节点"轻量"
内部节点不存储数据,因此可以存储更多索引键值(如m阶B+树的内部节点可存储m-1个键值),减少树的高度(如10亿条数据的B+树高度约为3-4层)。
树高越低,磁盘I/O次数越少(每次I/O读取一个节点),查询效率越高。
-
叶子节点链表:范围查询的"神器"
叶子节点通过双向链表连接(如next和prev指针),因此范围查询无需回溯父节点,只需:
(1)找到范围的起始叶子节点(如id = 100);
(2)沿链表顺序遍历至范围的结束叶子节点(如id = 200)。
例如,SELECT * FROM orders WHERE create_time BETWEEN '2023-01-01' AND '2023-01-31',B+树可通过叶子链表快速获取所有符合条件的订单,无需多次访问内部节点。
- 多路平衡:避免"树倾斜"
B+树是平衡树(所有叶子节点在同一层),且每个节点可以有多个子节点(m阶),因此不会出现二叉树的"倾斜"问题(如插入有序数据时退化为链表)。
平衡操作(如节点分裂、合并)仅在叶子节点或内部节点满员时触发,维护成本远低于二叉树。
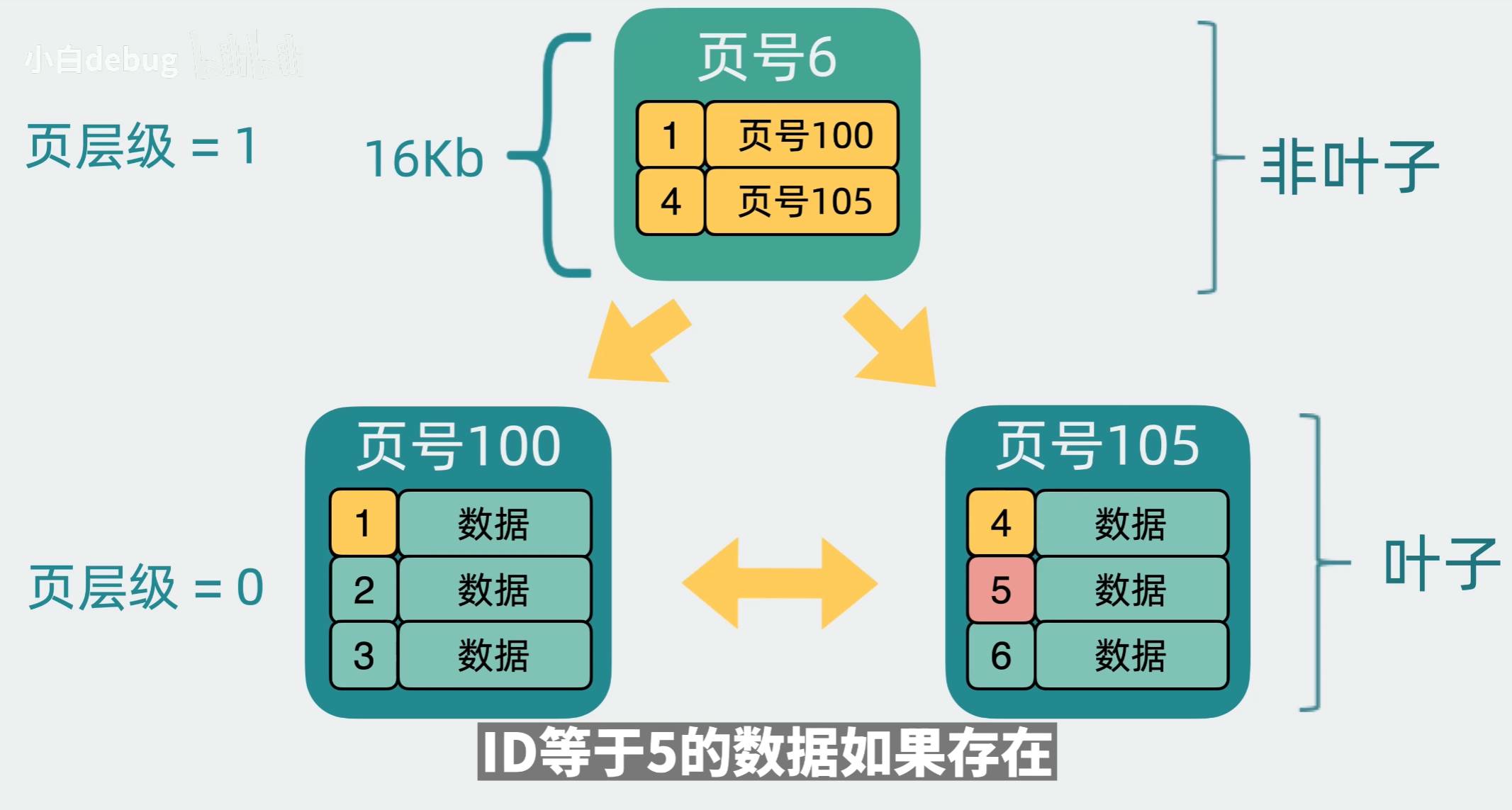
3.1.3 B+树的工作流程(以查询为例)
以SELECT * FROM users WHERE id = 5(假设id是主键,B+树索引)为例,B+树的查询流程如下:
访问根节点:根节点存储3, 7(假设),5介于3和7之间,因此选择指向中间子节点的指针。
访问内部节点:中间子节点存储5, 6,5等于5,因此选择指向左叶子节点的指针。
访问叶子节点:左叶子节点存储1, 3, 5, 7,找到id = 5的数据行,返回结果。
整个流程仅需3次磁盘I/O(根→内部→叶子),效率极高。
3.1.4 B+树 vs B树:为什么B+树更适合数据库?
B树(B-Tree)是B+树的前身,但其内部节点存储数据的设计导致以下问题:
磁盘I/O次数多:内部节点存储数据,导致每个节点可存储的索引键值减少,树高增加(如10亿条数据的B树高度约为5-6层),查询需更多I/O。
范围查询效率低:B树的叶子节点无链表,范围查询需回溯父节点,效率远低于B+树。
因此,B+树逐渐成为数据库的"主流索引结构"(MySQL建议单表最多2kw行),而B树仅用于部分文件系统(如HDFS)。
3.1.5 B+树的图示(简化版)
以下是B+树的逻辑结构示意图(以3阶B+树为例,id为主键):
根节点(内部节点)
┌───────┐
│ 5, 10 │ ← 存储索引键值
└───────┘
/ | \
/ | \
/ | \
内部节点1 内部节点2 内部节点3 ← 仅存储索引
┌─────┐ ┌─────┐ ┌─────┐
│3, 4 │ │6, 7 │ │11,12│
└─────┘ └─────┘ └─────┘
/ \ / \ / \
/ \ / \ / \
叶子节点1 叶子节点2 叶子节点3 叶子节点4 ← 存储数据行+链表指针
┌───────┐ ┌───────┐ ┌───────┐ ┌───────┐
│1,2,3 │ │4,5,6 │ │7,8,9 │ │10,11,12│
│next→ │ │next→ │ │next→ │ │next→ │ ← 叶子节点链表
└───────┘ └───────┘ └───────┘ └───────┘根节点和内部节点仅存储索引键值(5,10、3,4等),用于引导查找。
叶子节点存储实际数据行(1,2,3等),并通过next指针形成链表,支持范围查询。
3.1.6 B+树总结
B+树是关系型数据库的核心索引结构,主要用于:
主键查询:如SELECT * FROM users WHERE id = 1,通过B+树快速定位数据行。
范围查询:如SELECT * FROM orders WHERE create_time BETWEEN '2023-01-01' AND '2023-01-31',通过叶子链表顺序遍历。
排序操作:如SELECT * FROM users ORDER BY id ASC,叶子节点的有序性可直接返回排序结果。
B+树通过"索引与数据分离"、"叶子节点链表"、"多路平衡"的设计,完美解决了磁盘存储的随机I/O瓶颈,同时支持高效的等值查询、范围查询和顺序访问。它是现代数据库(如MySQL InnoDB)、文件系统(如NTFS)的"索引基石",也是理解数据库性能优化的关键知识点。
额外阅读材料
- 视频讲解B+树的生成过程
- 视频讲解MongoDB架构, MongoDB用到了变种B+树,且更新叶子结点数据时使用了Copy On Write机制,提升了并发性能。
- 为什么说mysql数据库单表最大两千万?依据是啥?
3.2 B-link Tree
B-link树是B+树的扩展版本,专为高并发场景和分布式数据库设计,通过引入双向链接和延迟分裂机制优化了传统B+树的性能。
| 特性 | B+树 | B-link树 |
|---|---|---|
| 节点分裂处理 | 需要加锁或阻塞父节点 | 通过双向链接实现无锁分裂 |
| 并发性能 | 高竞争场景下性能受限 | 支持更高并发插入 |
| 分裂传播 | 立即更新父节点 | 延迟更新,通过指针自动发现 |
| 适用场景 | 单机数据库索引 | 分布式数据库、高并发写入场景 |
3.2.1 B-link树的核心机制
(1) 双向链接(Forward/Backward Link)
普通B+树:叶子节点通过单向链表连接,非叶子节点无链接。
B-link树:
叶子节点:保留双向链表(支持范围查询)。
非叶子节点:新增右兄弟指针(Forward Link),指向同一层右侧相邻节点。
(2) 延迟分裂(Deferred Splitting)
传统B+树分裂:当节点满时,分裂后立即更新父节点,可能导致锁竞争。
B-link树分裂:
创建新节点,将原节点的部分键值迁移到新节点。
通过右兄弟指针,让父节点的下次访问自动发现新节点,无需立即更新父节点。
异步合并:父节点在后续访问中检测到分裂,再触发合并或调整。
假设插入数据导致节点分裂:
分裂节点:将原节点分为两部分,右侧部分形成新节点。
设置右兄弟指针:原节点的右兄弟指针指向新节点。
父节点延迟更新:
下次访问父节点时,若发现子节点的键值范围超出预期,会沿着右兄弟指针遍历,自动合并分裂后的节点。
3.2.3 优势与应用场景
高并发写入:减少锁竞争,适合大规模并发插入(如分布式数据库)。
分布式扩展:通过右兄弟指针实现自动分片,无需频繁重构树结构。
容错性:分裂后的节点可通过指针快速定位,降低数据丢失风险。
LevelDB/RocksDB:底层使用类似B-link树的LSM-Tree结构,通过分层和合并优化写入性能。(rocksDB)
分布式数据库:TiDB、CockroachDB 在节点分裂时借鉴了B-link树的延迟分裂思想。
postgreSQL索引也可以选择使用B-link树来支持高频写入场景。
B-link树通过双向链接和延迟分裂机制,在保持B+树高效范围查询能力的同时,显著提升了高并发场景下的写入性能,是现代分布式数据库和大规模存储系统的关键技术之一。
3.3 LSM tree
LSM树由多层有序文件组成,数据写入路径为:
内存 → 磁盘(SSTable),通过合并(Compaction) 逐步优化存储。
-
内存组件:MemTable
结构:通常为跳表(Skip List)或有序数组,支持快速插入和范围查询。
作用:暂存新写入的数据,达到阈值后转为只读MemTable(Immutable MemTable)。
-
磁盘组件:SSTable(Sorted String Table)
结构:磁盘上的有序文件,每个SSTable内部数据按Key排序,支持二分查找。
分层存储:
Level 0:最新数据,可能存在重叠Key(需通过Compaction合并)。
Level 1~N:历史数据,Key范围互不重叠,减少读放大。
3.3.1 LSM树的工作流程
-
写入流程
写入请求 → MemTable(内存) → 达到阈值 → 转为Immutable MemTable → 刷盘生成SSTable(Level 0)
-
合并流程(Compaction)
Minor Compaction:
合并同一层的多个SSTable,生成更大的有序文件(如Level 0 → Level 1)。
Major Compaction:
跨层级合并,清理过期数据(如TTL)和重复键,优化存储效率。
-
读流程
bash
查询请求 →
1. 检查MemTable →
2. 遍历Level 0 → Level 1 → ... → 最终返回结果3.3.2 核心优势与局限
| 特性 | 优势 |
|---|---|
| 高写入吞吐 | 顺序写磁盘(避免随机写),写入速度接近内存操作。 |
| 压缩效率高 | 通过Compaction合并小文件,减少磁盘碎片和存储空间占用。 |
| 适合大规模数据 | 支持PB级数据存储,通过分层设计平衡读写性能。 |
| 代价 | 表现 |
|---|---|
| 读放大 | 一次查询可能需要遍历多层SSTable,需通过布隆过滤器(Bloom Filter)优化。 |
| 写放大 | Compaction会触发多次磁盘写入,需权衡合并频率与存储成本。 |
| 空间放大 | 历史版本数据暂存,需定期清理(如Cassandra的Size - Tiered Compaction) |
LSM树 vs B+树:适用场景对比
| 场景 | LSM树 | B+树 |
|---|---|---|
| 写密集型 | ✔️ 高吞吐(如日志、实时分析) | ❌ 随机写性能差 |
| 读密集型 | ❌ 需多次IO(需布隆过滤器优化) | ✔️ 直接定位数据 |
| 数据规模 | ✔️ 支持PB级数据 | ❌ 单表易达存储瓶颈 |
| 事务支持 | ❌ 通常不支持复杂事务 | ✔️ 支持ACID事务 |
3.3.3 额外阅读材料
总结
LSM树通过牺牲读性能换取写性能,是大数据场景下的最优选择。若需平衡读写,可结合LSM树与B+树(如TiDB的TiKV存储引擎)。实际应用中需根据业务场景选择合适的存储结构。
LSM树的优化手段
-
布隆过滤器(Bloom Filter)
快速判断Key是否存在于SSTable,减少无效磁盘IO。
-
分层合并策略
如Leveled Compaction(Cassandra)与Size-Tiered Compaction(HBase)。
-
时钟缓存(Clock Cache)
缓存热点数据,加速读取。