引言
这篇文章作为我学习skills的记录,如果有不对或者笔误的地方,请读者在评论区指出来。
什么是Skills
Skills 是 Anthropic 于 2025 年 10 月推出的一种模块化能力扩展系统,通过将领域特定的指令、元数据和资源(脚本、模板)打包成可重用的单元,使 agent 能够自动在相关场景下使用这些专业能力。
核心特点:
- 可重用性: 创建一次,自动使用
- 专业化: 为特定领域任务定制 agent 的能力
- 组合能力: 可以组合多个 Skills 构建复杂工作流
- 渐进式加载: 按需加载内容,避免上下文窗口污染
那简单来说,skills这种东西到底有什么作用?skills如果翻译过来,就是技能。那么我们平时玩游戏的时候,如果不更改技能底层机制,那么技能就是不会改变的,可重复使用的招式。下面是一些例子帮助你去理解skills的好处:
- 正因为skills是重复使用的,它就像我们企业中执行某种流程的SOP,这样可以帮助Agent做某种特定的事情流程化、规范化,不会因为LLM输出的不确定性导致最终结果不同,比如一个excel导出的skill,可以让LLM按规定的流程和格式导出excel,就像精细的工作流一样
- 正和我们玩游戏一样,我们并不会记住技能的全部机制,我们只需要记住技能的name和description就行,具体流程等到我们需要使用的时候再了解,skills也是同理。
- 因为skills只会暴露name和description,所以agent会自己判断什么场景使用这个skill,就像我们玩游戏一样,脑子已经潜移默化这种场景使用这种skills或者按这样的顺序将多种skills结合使用。
ok,经过上面的例子,你已经大概明白skills就是通过渐进式披露的形式,用于agent增加专门的知识或工作流程。
三层加载架构
经过上面的讲解,你已经懂了什么是skills了,那么我现在来讲一下skills的加载机制,skills采用三层加载架构
Skills 采用渐进式披露(Progressive Disclosure)架构,在三个不同时机加载内容:
- 发现:启动时,agent只会加载每个可用技能的名称和描述,仅足以知道何时可能相关。
- 激活 :当任务与技能描述相符时,agent会将完整的
SKILL.md指令解读到上下文中。 - 执行:AI应用按照指令执行,可根据需要加载引用的文件或执行捆绑代码。
这种方法既能保证agent快速响应,又能让他们根据需要获取更多上下文信息,可以节省上下文。
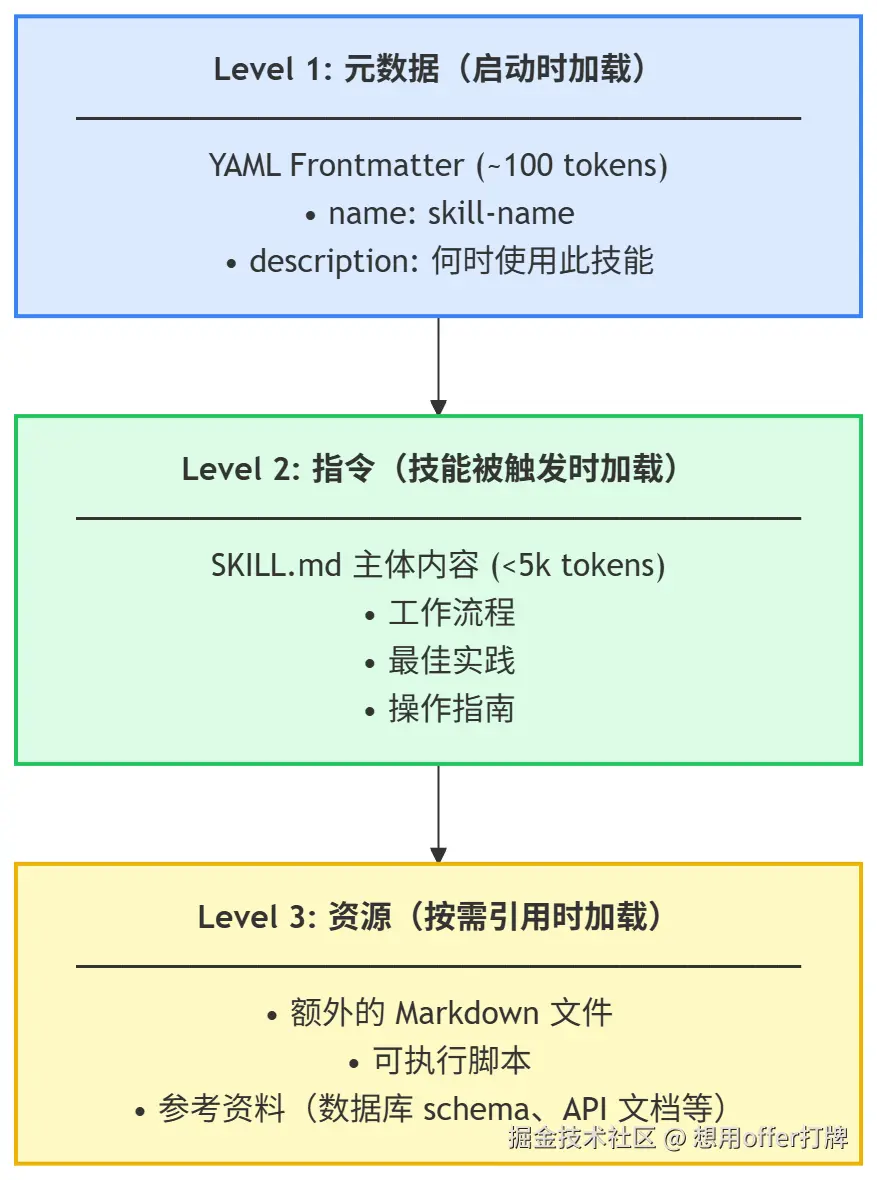
skills的架构
那么一个普通的skill应该结构可能包含什么呢?如下图所示
perl
my-skill/
├── SKILL.md # 必须:说明 + 元数据
├── scripts/ # 可选:可执行脚本代码
├── references/ # 可选:参考文档
└── assets/ # 可选:模版或资源文件我接下来会详细解释每一个部分
SKILL.md
这个md文件是一个skill必须包含的部分,文件SKILL.md必须包含 YAML 前置元数据,后跟 Markdown 内容。
前置name、description可以暴露这个skill的必要信息,但是要注意的是,这两个元数据必须要精确描述
yaml
---
name: skill-name
description: A description of what this skill does and when to use it.
---除了上面的必须项,在这个元数据部分还能添加下面的东西:
| 场地 | 必需的 | 约束条件 |
|---|---|---|
name |
是 | 最多64个字符。仅限小写字母、数字和连字符。不得以连字符开头或结尾。 |
description |
是 | 最多 1024 个字符。非空。描述技能的效果以及何时使用。 |
license |
不 | 许可证名称或捆绑许可证文件的引用。 |
compatibility |
不 | 最多 500 个字符。说明环境要求(目标产品、系统软件包、网络访问等)。 |
metadata |
不 | 任意键值映射,用于添加元数据。 |
allowed-tools |
不 | 技能可使用的预先批准工具列表,以空格分隔。(实验性功能) |
具体示例如下图所示
yaml
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents.
license: Apache-2.0
metadata:
author: example-org
version: "1.0"
---ok,接下来就是SKILL.md的正文部分,这个部分其实没有什么限制,只需编写有助于agent有效完成任务的内容即可。
但是我推荐像这样分点编写:
- 分步说明
- 输入和输出示例
- 常见边界情况
请注意,AI应用会在决定激活技能时加载整个文件。建议将较长的SKILL.md内容拆分成多个引用文件。
scripts
在这个目录下包含agent可以运行的可执行代码。脚本应:
- 要么是自包含的,要么清楚地记录依赖关系
- 包含有用的错误信息
- 优雅地处理极端情况
支持的语言取决于agent的具体实现。常见的语言包括 Python、Bash 和 JavaScript
references
references目录下包含agent需要时可查阅的其他文档:
REFERENCE.md- 详细技术参考FORMS.md- 表单模板或结构化数据格式- 域特定文件(
finance.md,,legal.md等)
保持各个参考文件的简洁性。AI应用按需加载这些文件,因此文件越小,对上下文信息的依赖就越少。
assets
在这个目录下包含静态资源:
- 模板(文档模板、配置模板)
- 图片(图表、示例)
- 数据文件(查找表、模式)
skills示例
下面是两个skills的简单架构
bash
├── ~/.claude/skills/ # Skills 目录
│ ├── pdf-processing/ # PDF 处理技能
│ │ ├── SKILL.md # 主指令文件 (必需)
│ │ ├── FORMS.md # 表单填写指南
│ │ ├── REFERENCE.md # API 参考文档
│ │ └── scripts/ # 可执行脚本
│ │ ├── extract_text.py # 文本提取
│ │ └── fill_form.py # 表单填充
│ └── excel-analysis/ # Excel 分析技能
│ ├── SKILL.md
│ ├── templates/ # 模板文件
│ └── examples/ # 示例数据
└── user_workspace/ # 用户工作区那么这个PDF的SKILL.md可以这样写。
md
---
name: pdf-processing
description: Extract text and tables from PDF files, fill forms, merge documents. Use when working with PDF files or when the user mentions PDFs, forms, or document extraction.
---
# PDF Processing Skill
## Quick Start
This skill helps you work with PDF files efficiently.
### Basic Text Extraction
Use pdfplumber to extract text:
\```python
import pdfplumber
with pdfplumber.open("document.pdf") as pdf:
page = pdf.pages[0]
text = page.extract_text()
print(text)
\```
### Table Extraction
\```python
with pdfplumber.open("document.pdf") as pdf:
page = pdf.pages[0]
tables = page.extract_tables()
for table in tables:
print(table)
\```
## Advanced Features
For form filling operations, see [FORMS.md](FORMS.md).
For complete API reference, see [REFERENCE.md](REFERENCE.md).
## Best Practices
1. Always validate PDF before processing
2. Handle errors gracefully
3. Use appropriate extraction methods based on PDF structureskill需要注意的点
现在除了你自己可以写属于自己的skills,还有官方和不少个人提供的skills。但是有需要注意的点:
- 恶意指令: Skill 可能包含误导性指令
- 代码执行: 脚本可能执行危险操作
- 数据泄露: Skill 可能访问外部 URL 泄露数据
- 工具滥用: Skills 可以调用文件操作、bash 命令等
总结
ok,经过上面的讲述,你已经了解skills了吧,把你的skills上传到Claude code和cursor等AI应用来尝试一下吧。