前面我们学习了 Pod 的原理和一些基本使用,但是在实际使用的时候并不会直接使用 Pod,而是会使用各种更高层级的控 制器,Kubernetes 中运行了一系列控制器来确保集群的当前状态与期望状态保持一致,它们就是 Kubernetes 的大脑。 例如,ReplicaSet 控制器负责维护集群中运行的 Pod 数量;Node 控制器负责监控节点的状态,并在节点出现故障时及 时做出响应。总而言之,在 Kubernetes 中,每个控制器只负责某种类型的特定资源。
控制器
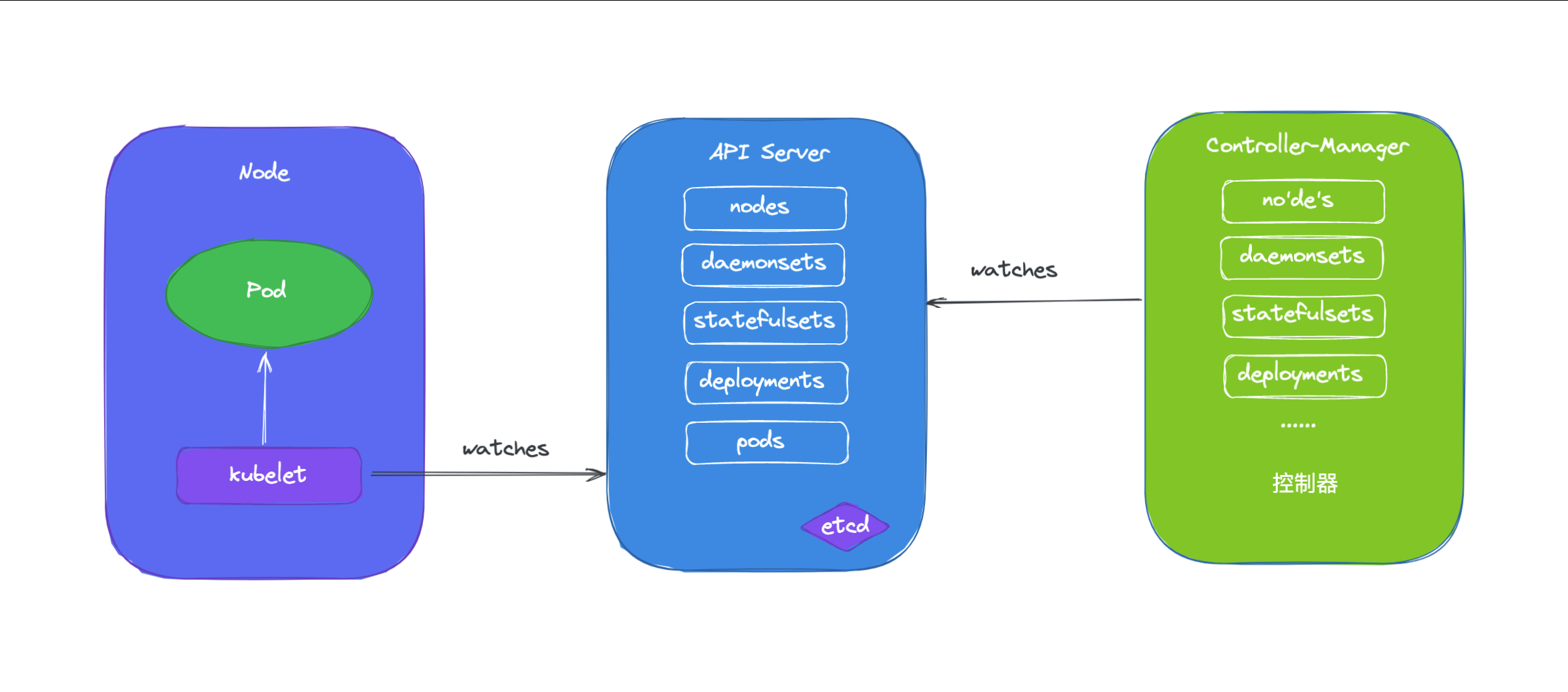
通过前面的课程学习我们知道了 master 的各组件中,API Server 仅负责将资源存储于 etcd 中,并将其变动通知给各 其他组件,如 kubelet、kube-scheduler、kube-proxy 和 kube-controller-manager 等,kube-scheduler 监控到处于未绑定状态的 Pod 对象出现时就启动调度器为其挑选最合适的工作节点,另外 Kubernetes 的核心功能之一 还在于要确保各资源对象的当前状态(status)已匹配用户期望的状态(spec),使当前状态不断地向期望状态"调谐" (Reconcile)来完成容器应用管理,这些就是 kube-controller-manager 的任务,kube-controller-manager 是一个独立的组件,但是它却包含了很多功能不同的控制器。
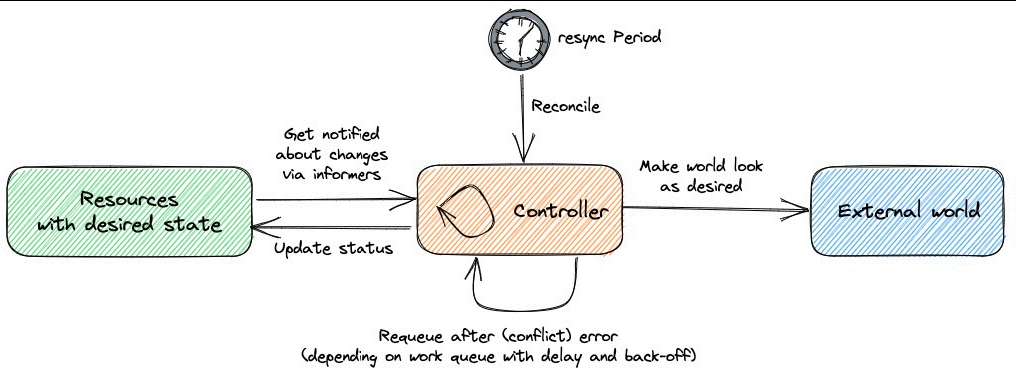
Kubernetes 控制器会监听资源的 创建/更新/删除 事件,并触发 Reconcile 调谐函数作为响应,整个调整过程被称 作 Reconcile Loop(调谐循环) 或者 Sync Loop(同步循环)。Reconcile 是一个使用资源对象的命名空间和资 源对象名称来调用的函数,使得资源对象的实际状态与 资源清单中定义的状态保持一致。调用完成后,Reconcile 会将资 源对象的状态更新为当前实际状态。我们可以用下面的一段伪代码来表示这个过程:
// 控制器循环伪代码
for {
// 获取期望的状态
desired := getDesiredState()
// 获取当前实际状态
current := getCurrentState()
// 如果状态不一致则调整编排,直到一致为止
if current != desired {
// 将当前状态调整为期望状态
reconcile(current, desired)
}
// 等待一段时间再继续循环
time.Sleep(reconcileInterval)
}这个编排模型就是 Kubernetes 项目中的一个通用编排模式,即:控制循环(control loop)。
创建为具体的控制器对象之后,每个控制器均通过 API Server 提供的接口持续监控相关资源对象的当前状态,并在因故 障、更新或其他原因导致系统状态发生变化时,尝试让资源的当前状态向期望状态迁移。简单来说,每个控制器对象运行一个 调谐循环负责状态同步,并将目标资源对象的当前状态写入到其 status 字段中。
实现调谐功能是依靠的 Kubernetes 实现的核心机制之一的 List-Watch,在资源对象的状态发生变动时,由 API Server 负责写入 etcd 并通过水平触发机制主动通知给相关的客户端程序以确保其不会错过任何一个事件。控制器通过 API Server 的 Watch 接口实时监控目标资源对象的变动并执行调谐操作,但并不会与其他控制器进行任何交互。 工作负载(workload)一类的控制器资源类型包括 ReplicaSet、Deployment、DaemonSet、StatefulSet、Job 和 CronJob 等,它们分别代表了一种类型的 Pod 控制器资源,接下来我们将分别介绍这些工作负载控制器的使用。
ReplicaSet
假如我们现在有一个 Pod 正在提供线上的服务,我们来想想一下我们可能会遇到的一些场景:
- 某次运营活动非常成功,网站访问量突然暴增
- 运行当前 Pod 的节点发生故障了,Pod 不能正常提供服务了
第一种情况,可能比较好应对,活动之前我们可以大概计算下会有多大的访问量,提前多启动几个 Pod 副本,活动结束后再 把多余的 Pod 杀掉,虽然有点麻烦,但是还是能够应对这种情况的。
第二种情况,可能某天夜里收到大量报警说服务挂了,然后起来打开电脑在另外的节点上重新启动一个新的 Pod,问题可以 解决。
但是如果我们都人工的去解决遇到的这些问题,似乎又回到了以前刀耕火种的时代了是吧?如果有一种工具能够来帮助我们自 动管理 Pod 就好了,Pod 挂了自动帮我在合适的节点上重新启动一个 Pod,这样是不是遇到上面的问题我们都不需要手动 去解决了。
而 ReplicaSet 这种资源对象就可以来帮助我们实现这个功能,ReplicaSet(RS) 的主要作用就是维持一组 Pod 副 本的运行,保证一定数量的 Pod 在集群中正常运行,ReplicaSet 控制器会持续监听它说控制的这些 Pod 的运行状态, 在 Pod 发送故障数量减少或者增加时会触发调谐过程,始终保持副本数量一定。
和 Pod 一样我们仍然还是通过 YAML 文件来描述我们的 ReplicaSet 资源对象,如下 YAML 文件是一个常见的 ReplicaSet 定义:
# nginx-rs.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx-rs
namespace: default
labels:
app: nginx
version: v1
spec:
replicas: 3
selector:
matchLabels:
app: nginx
version: v1
template:
metadata:
labels:
app: nginx
version: v1
spec:
containers:
- name: nginx
image: nginx:1.27.0
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
protocol: TCP
resources:
requests:
memory: "64Mi"
cpu: "250m"
limits:
memory: "128Mi"
cpu: "500m"
restartPolicy: Always上面的 YAML 文件结构和我们之前定义的 Pod 看上去没太大两样,有常见的 apiVersion、kind、metadata,在 spec 下面描述 ReplicaSet 的基本信息,其中包含 3 个重要内容:
- replias:表示期望的 Pod 的副本数量
- selector:Label Selector,用来匹配要控制的 Pod 标签,需要和下面的 Pod 模板中的标签一致
- template:Pod 模板,实际上就是以前我们定义的 Pod 内容,相当于把一个 Pod 的描述以模板的形式嵌入到了 ReplicaSet 中来。
Pod 模板这个概念非常重要,因为后面我们讲解到的大多数控制器,都会使用 Pod 模板来统一定义它所要管理的 Pod。更有意思的是,我们还会看到其他类型的对象模板,比如 Volume 的模板等。
上面就是我们定义的一个普通的 ReplicaSet 资源清单文件,ReplicaSet 控制器会通过定义的 Label Selector 标 签去查找集群中的 Pod 对象:
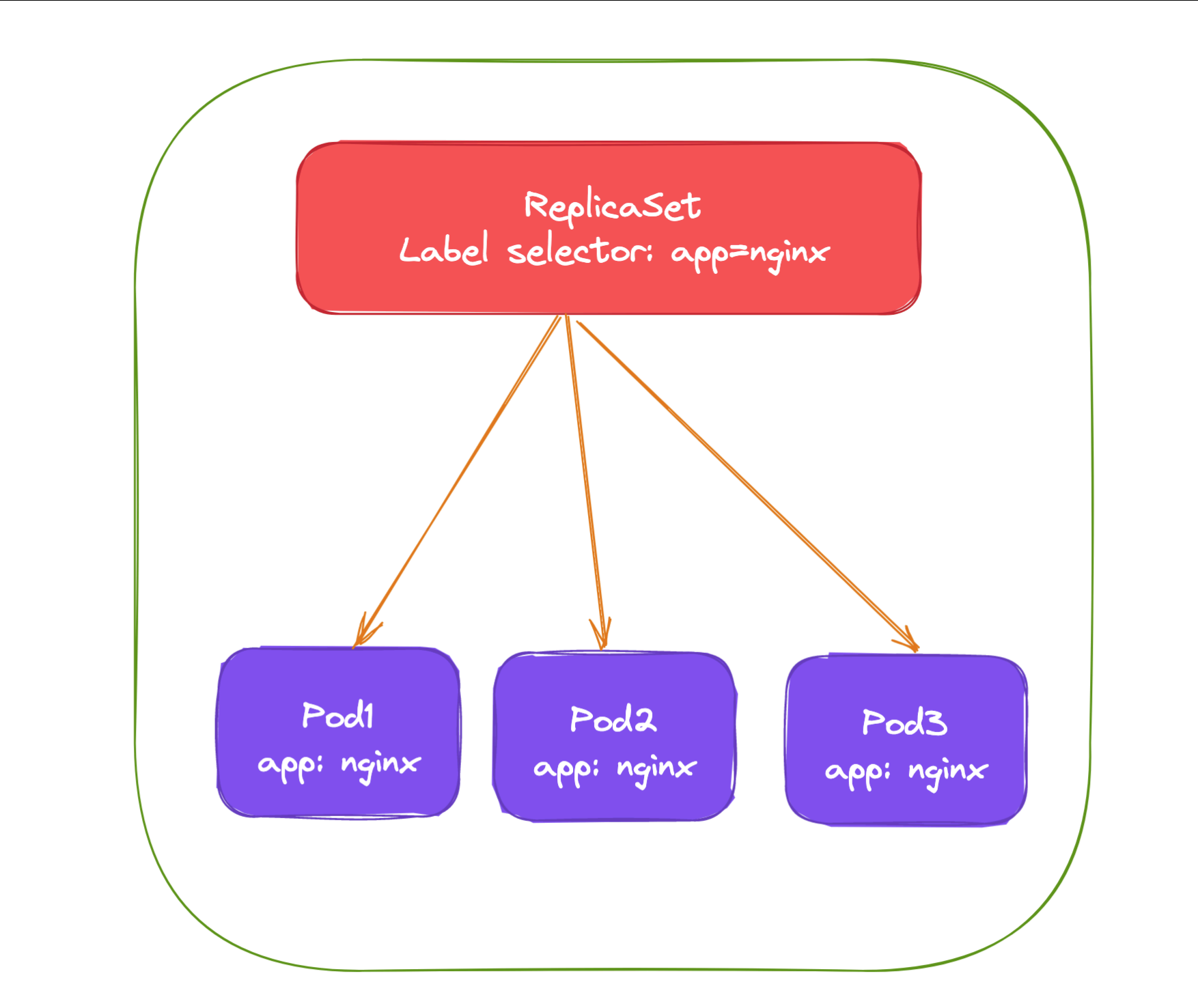
我们直接来创建上面的资源对象:
root@master01:~/kubernetes# kubectl apply -f nginx-rs.yaml
replicaset.apps/nginx-rs created
root@master01:~/kubernetes# kubectl get rs -l app=nginx
NAME DESIRED CURRENT READY AGE
nginx-rs 3 3 3 5m53s通过查看 RS 可以看到当前资源对象的描述信息,包括 DESIRED、CURRENT、 READY 的状态值,创建完成后,可以利用 如下命令查看下 Pod 列表:
root@master01:~/kubernetes# kubectl get rs -l app=nginx
NAME DESIRED CURRENT READY AGE
nginx-rs 3 3 3 5m53s
root@master01:~/kubernetes# kubectl get pod -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-rs-542kp 1/1 Running 0 6m34s
nginx-rs-dcll4 1/1 Running 0 6m34s
nginx-rs-qmh8p 1/1 Running 0 6m34s可以看到现在有 3 个 Pod,这 3 个 Pod 就是我们在 RS 中声明的 3 个副本,比如我们删除其中一个 Pod:
root@master01:~/kubernetes# kubectl delete pod nginx-rs-542kp
pod "nginx-rs-542kp" deleted然后再查看 Pod 列表:
root@master01:~/kubernetes# kubectl get pod -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-rs-dcll4 1/1 Running 0 8m12s
nginx-rs-jfvqh 1/1 Running 0 29s
nginx-rs-qmh8p 1/1 Running 0 8m12s可以看到又重新出现了一个 Pod,这个就是上面我们所说的 ReplicaSet 控制器为我们做的工作,我们在 YAML 文件中 声明了 3 个副本,然后现在我们删除了一个副本,就变成了两个,这个时候 ReplicaSet 控制器监控到控制的 Pod 数量 和期望的 3 不一致,所以就需要启动一个新的 Pod 来保持 3 个副本,这个过程上面我们说了就是调谐的过程。同样可以 查看 RS 的描述信息来查看到相关的事件信息:
root@master01:~/kubernetes# kubectl describe rs nginx-rs
Name: nginx-rs
Namespace: default
Selector: app=nginx,version=v1
Labels: app=nginx
version=v1
Annotations: <none>
Replicas: 3 current / 3 desired
Pods Status: 3 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
version=v1
Containers:
nginx:
Image: nginx:1.27.0
Port: 80/TCP
Host Port: 0/TCP
Limits:
cpu: 500m
memory: 128Mi
Requests:
cpu: 250m
memory: 64Mi
Environment: <none>
Mounts: <none>
Volumes: <none>
Node-Selectors: <none>
Tolerations: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 9m4s replicaset-controller Created pod: nginx-rs-dcll4
Normal SuccessfulCreate 9m4s replicaset-controller Created pod: nginx-rs-qmh8p
Normal SuccessfulCreate 9m4s replicaset-controller Created pod: nginx-rs-542kp
Normal SuccessfulCreate 81s replicaset-controller Created pod: nginx-rs-jfvqh可以发现最开始通过 ReplicaSet 控制器创建了 3 个 Pod,后面我们删除了 Pod 后, ReplicaSet 控制器又为我们 创建了一个 Pod,和上面我们的描述是一致的。如果这个时候我们把 RS 资源对象的 Pod 副本更改为 2 spec.replicas=2 ,这个时候我们来更新下资源对象:
root@master01:~/kubernetes# kubectl apply -f nginx-rs.yaml
replicaset.apps/nginx-rs configured
root@master01:~/kubernetes# kubectl describe rs nginx-rs
Name: nginx-rs
Namespace: default
Selector: app=nginx,version=v1
Labels: app=nginx
version=v1
Annotations: <none>
Replicas: 2 current / 2 desired
Pods Status: 2 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=nginx
version=v1
Containers:
nginx:
Image: nginx:1.27.0
Port: 80/TCP
Host Port: 0/TCP
Limits:
cpu: 500m
memory: 128Mi
Requests:
cpu: 250m
memory: 64Mi
Environment: <none>
Mounts: <none>
Volumes: <none>
Node-Selectors: <none>
Tolerations: <none>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 10m replicaset-controller Created pod: nginx-rs-dcll4
Normal SuccessfulCreate 10m replicaset-controller Created pod: nginx-rs-qmh8p
Normal SuccessfulCreate 10m replicaset-controller Created pod: nginx-rs-542kp
Normal SuccessfulCreate 2m49s replicaset-controller Created pod: nginx-rs-jfvqh
Normal SuccessfulDelete 4s replicaset-controller Deleted pod: nginx-rs-jfvqh可以看到 Replicaset 控制器在发现我们的资源声明中副本数变更为 2 后,就主动去删除了一个 Pod,这样副本数就和 期望的始终保持一致了:
root@master01:~/kubernetes# kubectl get pod -l app=nginx
NAME READY STATUS RESTARTS AGE
nginx-rs-dcll4 1/1 Running 0 11m
nginx-rs-qmh8p 1/1 Running 0 11m我们可以随便查看一个 Pod 的描述信息可以看到这个 Pod 的所属控制器信息:
root@master01:~/kubernetes# kubectl describe pod nginx-rs-qmh8p
Name: nginx-rs-qmh8p
Namespace: default
Priority: 0
Service Account: default
Node: node02/192.168.48.102
Start Time: Tue, 17 Feb 2026 21:41:17 +0800
Labels: app=nginx
version=v1
Annotations: cni.projectcalico.org/containerID: 0f74ab99ed4211e2e0879fca0751b79fea5bf01148121ea2fa150e79da181181
cni.projectcalico.org/podIP: 172.16.140.84/32
cni.projectcalico.org/podIPs: 172.16.140.84/32
Status: Running
IP: 172.16.140.84
IPs:
IP: 172.16.140.84
Controlled By: ReplicaSet/nginx-rs
Containers:
nginx:
Container ID: docker://c39396a53bfbc213453545dd71ec2faee67b2435b8a9cf89ed9e081339a61025
Image: nginx:1.27.0
Image ID: docker-pullable://nginx@sha256:98f8ec75657d21b924fe4f69b6b9bff2f6550ea48838af479d8894a852000e40
Port: 80/TCP
Host Port: 0/TCP
State: Running
Started: Tue, 17 Feb 2026 21:41:18 +0800
Ready: True
Restart Count: 0
Limits:
cpu: 500m
memory: 128Mi
Requests:
cpu: 250m
memory: 64Mi
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from kube-api-access-mxdsc (ro)
Conditions:
Type Status
PodReadyToStartContainers True
Initialized True
Ready True
ContainersReady True
PodScheduled True
Volumes:
kube-api-access-mxdsc:
Type: Projected (a volume that contains injected data from multiple sources)
TokenExpirationSeconds: 3607
ConfigMapName: kube-root-ca.crt
ConfigMapOptional: <nil>
DownwardAPI: true
QoS Class: Burstable
Node-Selectors: <none>
Tolerations: node.kubernetes.io/not-ready:NoExecute op=Exists for 300s
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 12m default-scheduler Successfully assigned default/nginx-rs-qmh8p to node02
Normal Pulled 12m kubelet Container image "nginx:1.27.0" already present on machine
Normal Created 12m kubelet Created container: nginx
Normal Started 12m kubelet Started container nginx另外被 ReplicaSet 持有的 Pod 有一个 metadata.ownerReferences 指针指向当前的 ReplicaSet,表示当前 Pod 的所有者,这个引用主要会被集群中的垃圾收集器使用以清理失去所有者的 Pod 对象。这个 ownerReferences 和数据库中的外键 是不是非常类似。可以通过将 Pod 资源描述信息导出查看:
root@master01:~/kubernetes# kubectl get pod nginx-rs-kubectl get pod nginx-rs-qmh8p -o yaml
apiVersion: v1
items:
- apiVersion: v1
kind: Pod
metadata:
annotations:
cni.projectcalico.org/containerID: 0f74ab99ed4211e2e0879fca0751b79fea5bf01148121ea2fa150e79da181181
cni.projectcalico.org/podIP: 172.16.140.84/32
cni.projectcalico.org/podIPs: 172.16.140.84/32
creationTimestamp: "2026-02-17T13:41:17Z"
generateName: nginx-rs-
labels:
app: nginx
version: v1
name: nginx-rs-qmh8p
namespace: default
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: ReplicaSet
name: nginx-rs
uid: c2f13fc7-889b-4a7c-8bd7-8fc2d95f4dca
resourceVersion: "132175"
uid: a446ff69-6e94-4fdd-a7a1-e1bd3b388383
......我们可以看到 Pod 中有一个 metadata.ownerReferences 的字段指向了 ReplicaSet 资源对象。如果要彻底删除 Pod,我们就只能删除 RS 对象:
root@master01:~/kubernetes# kubectl delete rs nginx-rs
replicaset.apps "nginx-rs" deleted