一、前言
在规则推理与专家系统领域,海量规则与实时数据的高效匹配一直是核心挑战。传统暴力遍历方式在规则规模膨胀时会出现性能指数级下降,难以满足金融风控、电商营销、工业决策等场景的低延迟要求。RETE 算法作为产生式规则系统的经典高效匹配算法,通过构建共享式判别网络,大幅降低重复计算,成为现代规则引擎的基石。
从实际应用来看,RETE 算法早已深度落地:在金融反欺诈中,它能毫秒级匹配数百条风控规则,拦截异常交易;在电商营销里,快速完成用户标签、商品属性、优惠门槛的多条件组合匹配,实现精准推荐;在智能制造中,实时匹配设备状态、工艺参数、安全阈值等规则,保障产线稳定运行;在智能决策系统中,支撑专家规则的快速推理与动态更新。这些场景共同印证了RETE算法在规则密集型系统中不可替代的价值。今天我们将从原理、网络结构、优化思路与工程实现等维度,系统解析RETE算法,为高性能规则引擎设计提供参考。

二、RETE 算法基础
1. 核心基础
1.1 基础概念
RETE算法是为解决多规则 - 多事实的高效匹配问题,是常用的规则系统如Drools的底层核心。
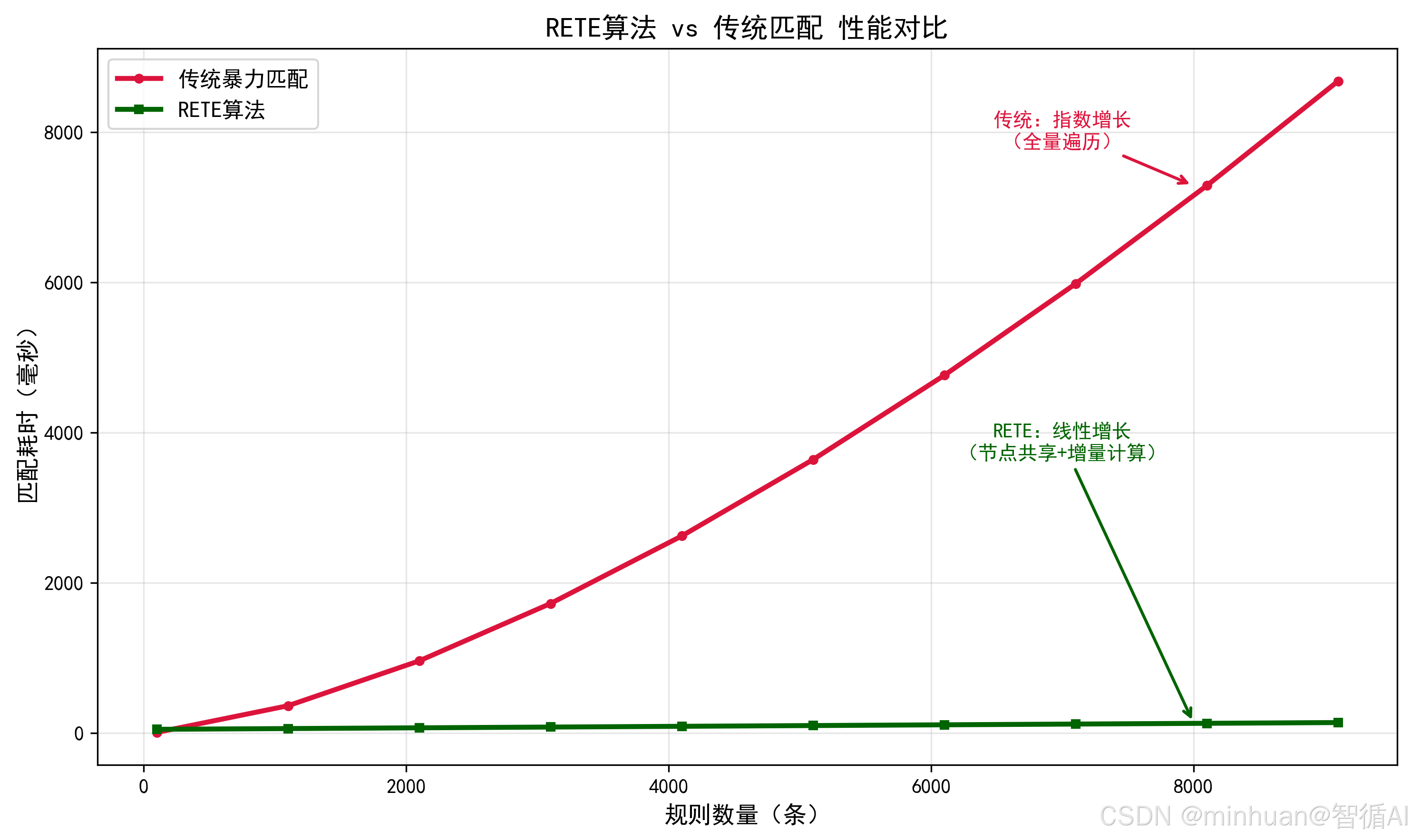
- 传统暴力匹配模式下,每一条规则都需遍历全量事实,时间复杂度高达 O (M×N)(M 为规则数、N 为事实数),当规则规模突破千级、事实高频更新时,系统性能会急剧下降。
- RETE算法以"空间换时间"为核心思路,通过构建共享节点的有向无环网络,将规则拆解为原子条件,利用Alpha节点实现单事实过滤、Beta节点完成多事实关联,并缓存所有中间匹配结果,仅对事实增量变更做局部计算,将匹配复杂度从O(M×N)优化至接近O(N)。
1.2 核心思想
- 时间冗余性:工作内存(事实库)每次仅少量数据变化,无需全量重算,只处理增量变更。
- 结构相似性:不同规则共享相同条件,通过节点复用减少重复匹配与存储。
1.3 核心目标
- 把规则拆解为原子条件,构建RETE网络,让事实在网络中流动并缓存中间匹配,最终触发满足所有条件的规则。
2. 核心组件
RETE网络是DAG有向无环图,分为根节点、类型节点、Alpha 网络、Beta 网络、终端节点五层。
2.1 根节点(Root Node)
- 虚拟入口,所有事实从此进入网络。
2.2 类型节点(Type Node/ObjectTypeNode)
- 按事实类型(如用户、订单、交易)分流,实现类型过滤,相同类型事实进入同一分支。
2.3 Alpha 网络(单条件匹配层)
- Alpha 节点:处理单事实、单属性的常量 / 条件判断(如年龄>18、金额>1000)。
- Alpha 内存:缓存通过当前节点的所有事实,避免重复匹配。
- 特点:单输入、过滤型,只保留满足条件的事实。
2.4 Beta 网络(多条件关联层)
- Beta 节点(JoinNode):处理多事实间的关联匹配(如用户.ID=订单.用户ID),实现事实的join 操作。
- Beta 内存:缓存部分匹配的事实组合(如已匹配用户+订单,待匹配支付)。
- 特点:双输入、关联型,完成多条件的逻辑与(AND)组合。
2.5 终端节点(Terminal Node/Agenda)
- 规则的完整匹配出口,所有条件满足时激活规则,将规则加入议程(Agenda)等待执行。
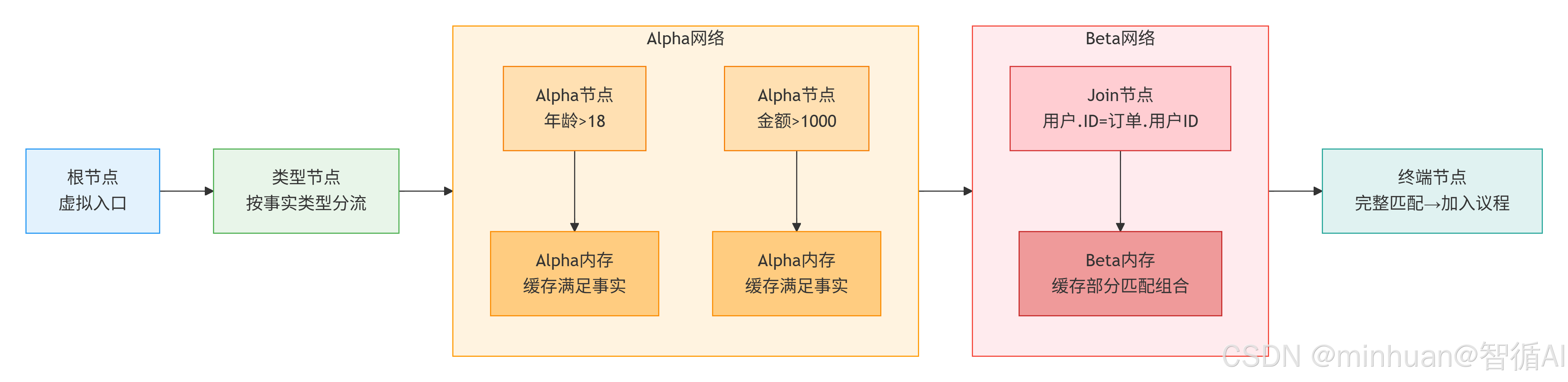
从左到右的数据流向:
| 层级 | 节点 | 核心功能 | 输入→输出 |
|---|---|---|---|
| 1 | 根节点 | 虚拟入口 | 事实流入起点 |
| 2 | 类型节点 | 按类型分流 | 用户/订单/交易分路径 |
| 3 | Alpha网络 | 单条件过滤 | 年龄>18 → 缓存通过者 金额>1000 → 缓存通过者 |
| 4 | Beta网络 | 多条件关联 | 用户ID=订单ID → 缓存组合 |
| 5 | 终端节点 | 规则激活 | 完整匹配 → 加入议程 |
3. 匹配流程
第一步:网络构建(编译阶段)

-
- 解析所有规则,拆分为原子条件。
-
- 按类型→Alpha 条件→Beta 关联→终端,逐层构建网络,共享重复节点。
-
- 为每个节点分配内存,缓存中间匹配结果。
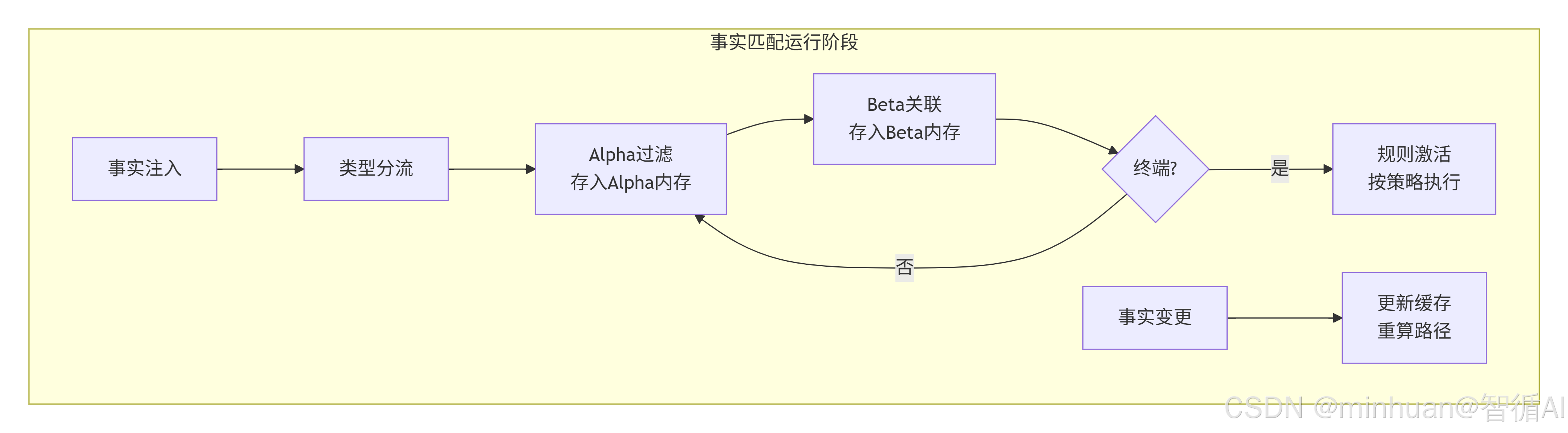
第二步:事实匹配(运行阶段)
-
- 事实注入:新增、变更事实从根节点进入,按类型分流到对应TypeNode。
-
- Alpha 过滤:依次通过 Alpha 节点,仅满足条件的事实进入下一层,结果存入 Alpha 内存。
-
- Beta 关联:在 Beta 节点做事实 join,组合多事实的匹配结果,存入 Beta 内存。
-
- 规则激活:到达终端节点即全条件匹配,规则加入议程,按冲突策略执行(如优先级、时间序)。
-
- 增量更新:事实删除或修改时,反向清除对应节点缓存,仅重算受影响路径。
4. 优势与局限
4.1核心优势
- 极致效率:匹配速度与规则数基本无关,仅与事实变更量相关,适合海量规则 + 频繁事实更新场景。
- 增量计算:只处理变化数据,避免全量重匹配,时间复杂度从 O (n²) 降至接近 O (n)。
- 空间换时间:缓存中间结果,大幅减少重复计算。
- 规则易扩展:新增规则只需扩展网络分支,不影响原有结构。
4.2 主要局限
- 内存开销大:缓存大量中间匹配结果,内存换效率,规则、事实极多时需优化。
- 网络构建成本:规则复杂时,网络构建与节点维护有开销。
- 不适合简单场景:规则少、事实静态时,RETE额外开销高于暴力匹配。
三、结合大模型执行流程
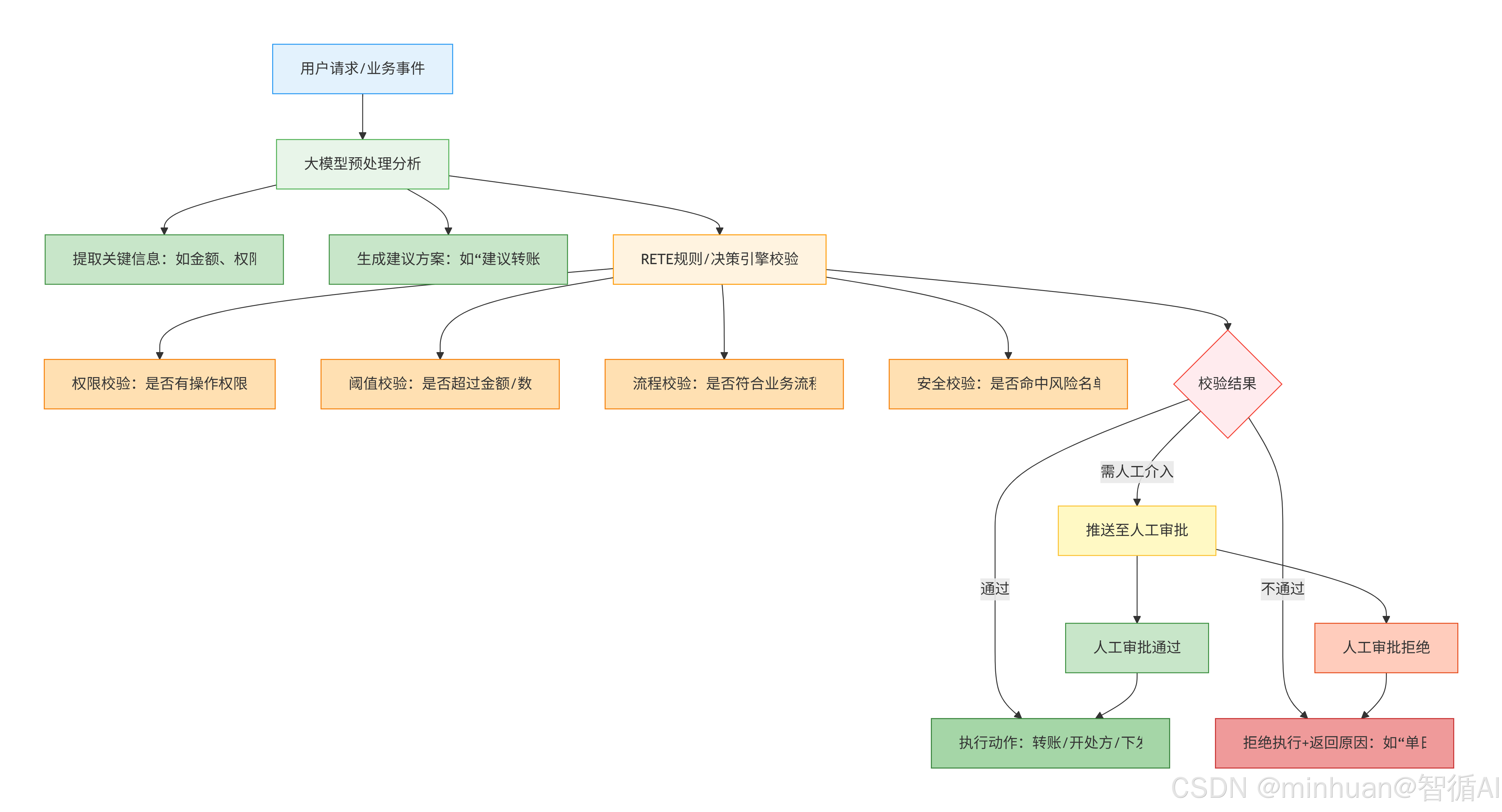
流程拆解:以金融转账为例
-
- 用户请求:用户申请转账20万元给陌生账户;
-
- 大模型分析:提取关键信息(转账金额 20 万、收款方陌生、用户等级普通),生成建议:"该转账金额超普通用户单日限额,且收款方无历史交易,建议拒绝,或引导人工复核";
-
- RETE规则引擎校验:
- 权限校验:用户是普通账户,有转账权限;
- 阈值校验:普通用户单日转账限额 5 万,20 万超标;
- 安全校验:收款方在反诈黑名单库中;
-
- 校验结果:不通过,直接拒绝执行,返回原因:"单日转账金额超 5 万限额,且收款方命中反诈风险名单,拒绝转账"。
四、执行原理
1. 规则引擎的核心原理
规则引擎本质是"条件判断集合",通过RETE算法把所有规则提前编译成"判断网络",快速匹配业务事件是否符合规则,常见的规则引擎有Drools、Easy Rules 等。
规则的典型写法:
- 规则1:普通用户单日转账阈值
- IF 用户等级 = 普通 AND 单日转账金额 > 50000 THEN 校验不通过
- 规则2:反诈黑名单校验
- IF 收款方账户 IN 反诈黑名单 THEN 校验不通过
- 规则3:VIP用户阈值放宽
- IF 用户等级 = VIP AND 单日转账金额 > 200000 THEN 校验不通过
2. 大模型的核心作用
在这个范式中,大模型是提升效率的核心,主要做3件技术层面的事:
- 信息抽取(IE):从非结构化文本或语音中提取结构化信息,比如用户语音说"转十万给张三",大模型提取"金额 10 万、收款方张三";
- 意图识别:判断用户真实意图,比如用户说"帮忙处理一下这笔款",大模型识别出真实意图是"转账";
- 多维度建议生成:结合历史数据、业务场景生成最优建议,比如结合用户的交易记录,建议"分5天转账,每天5万",既符合规则又满足用户需求。
3. 规则对大模型的意义
- 降低落地风险:通过规则引擎兜底,解决大模型合规性、可解释性的短板,让大模型能进入高价值的强合规领域;
- 发挥大模型优势:不用让大模型做它不擅长的合规校验、执行,而是聚焦复杂分析、智能建议,提升业务效率;
- 渐进式落地:先通过规则引擎保证基础安全,再通过大模型持续优化建议质量,逐步提升业务上限。
五、案例实践
1. RETE 算法实现
示例代码主要聚焦RETE的核心逻辑,包括Alpha 节点过滤、Beta 节点关联、增量匹配重要过程;
python
from typing import List, Dict, Callable, Tuple
from dataclasses import dataclass
# ===================== 1. 定义基础数据结构 =====================
# 事实(Fact):业务数据,比如用户、订单、交易
@dataclass
class Fact:
"""事实类:表示业务中的一条数据(如用户、订单)"""
type: str # 事实类型(如"user", "order", "transaction")
attrs: Dict[str, any] # 事实属性(如{"age":25, "id":1001})
# 规则(Rule):由条件和动作组成
@dataclass
class Rule:
"""规则类:条件满足时执行对应动作"""
name: str # 规则名称
conditions: List[Callable[[Fact | Tuple[Fact, Fact]], bool]] # 条件列表
action: Callable[[], None] # 满足条件后执行的动作
# ===================== 2. 定义RETE核心节点 =====================
class AlphaNode:
"""Alpha节点:单事实单条件过滤(如age>18、amount>1000)"""
def __init__(self, condition: Callable[[Fact], bool], is_left: bool = False):
self.condition = condition # 过滤条件
self.is_left = is_left # 是否为左输入(用于区分多个Alpha节点)
self.outputs: List["BetaNode | TerminalNode"] = [] # 输出节点
self.matched_facts: List[Fact] = [] # Alpha内存:缓存满足条件的事实
def process(self, fact: Fact) -> None:
"""处理事实:满足条件则缓存并传递给下一级节点"""
if self.condition(fact):
self.matched_facts.append(fact)
for node in self.outputs:
node.process_alpha(fact, is_left=self.is_left) # 传递给下一级,带上is_left标识
def remove_fact(self, fact: Fact) -> None:
"""事实删除时:清理缓存并通知下游"""
if fact in self.matched_facts:
self.matched_facts.remove(fact)
for node in self.outputs:
node.remove_alpha(fact)
class BetaNode:
"""Beta节点:多事实关联匹配(如user.id == order.user_id)"""
def __init__(self, join_condition: Callable[[Fact, Fact], bool]):
self.join_condition = join_condition # 关联条件
self.outputs: List["TerminalNode"] = [] # 输出节点
# Beta内存:缓存部分匹配的事实对(left_fact, right_fact)
self.matched_pairs: List[Tuple[Fact, Fact]] = []
# 左右输入缓存(分别存储两个类型的事实)
self.left_facts: List[Fact] = []
self.right_facts: List[Fact] = []
def process_alpha(self, fact: Fact, is_left: bool = False) -> None:
"""处理来自Alpha节点的事实:关联匹配并传递"""
# 1. 先缓存当前事实到左/右输入
if is_left:
self.left_facts.append(fact)
# 用新左事实匹配所有右事实
for right_fact in self.right_facts:
if self.join_condition(fact, right_fact):
pair = (fact, right_fact)
self.matched_pairs.append(pair)
for node in self.outputs:
node.process_beta(pair)
else:
self.right_facts.append(fact)
# 用新右事实匹配所有左事实
for left_fact in self.left_facts:
if self.join_condition(left_fact, fact):
pair = (left_fact, fact)
self.matched_pairs.append(pair)
for node in self.outputs:
node.process_beta(pair)
def remove_alpha(self, fact: Fact, is_left: bool = False) -> None:
"""清理事实并删除关联对"""
if is_left and fact in self.left_facts:
self.left_facts.remove(fact)
elif not is_left and fact in self.right_facts:
self.right_facts.remove(fact)
# 清理关联对
self.matched_pairs = [p for p in self.matched_pairs if fact not in p]
class TerminalNode:
"""终端节点:规则匹配完成,触发动作"""
def __init__(self, rule: Rule):
self.rule = rule # 关联的规则
def process_beta(self, fact_pair: Tuple[Fact, Fact]) -> None:
"""Beta节点匹配完成,执行规则动作"""
print(f"✅ 规则[{self.rule.name}]匹配成功!")
print(f" 匹配的事实对:{fact_pair[0]} | {fact_pair[1]}")
self.rule.action()
# ===================== 3. 构建RETE网络并测试 =====================
def main():
# -------------------- 步骤1:定义规则和动作 --------------------
# 规则1:用户年龄>18 且 订单金额>1000 → 触发高价值用户提醒
def user_condition(fact: Fact) -> bool:
"""Alpha条件:用户年龄>18"""
return fact.type == "user" and fact.attrs.get("age", 0) > 18
def order_condition(fact: Fact) -> bool:
"""Alpha条件:订单金额>1000"""
return fact.type == "order" and fact.attrs.get("amount", 0) > 1000
def join_condition(user_fact: Fact, order_fact: Fact) -> bool:
"""Beta关联条件:用户ID=订单用户ID"""
return user_fact.attrs.get("id") == order_fact.attrs.get("user_id")
def alert_action():
"""规则动作:高价值用户提醒"""
print(" 🚨 执行动作:发送高价值用户营销短信!\n")
# 定义规则
high_value_rule = Rule(
name="高价值用户规则",
conditions=[user_condition, order_condition, join_condition],
action=alert_action
)
# -------------------- 步骤2:构建RETE网络 --------------------
# 1. 创建Alpha节点
alpha_user = AlphaNode(user_condition, is_left=True)
alpha_order = AlphaNode(order_condition, is_left=False)
# 2. 创建Beta节点(关联用户和订单)
beta_join = BetaNode(join_condition)
alpha_user.outputs.append(beta_join) # 用户Alpha节点→Beta节点(左输入)
alpha_order.outputs.append(beta_join) # 订单Alpha节点→Beta节点(右输入)
# 3. 创建终端节点(关联规则)
terminal = TerminalNode(high_value_rule)
beta_join.outputs.append(terminal)
# -------------------- 步骤3:注入事实并测试匹配 --------------------
# 事实1:用户(ID=1001,年龄25)
user_fact = Fact(type="user", attrs={"id": 1001, "age": 25})
# 事实2:订单(用户ID=1001,金额1500)
order_fact = Fact(type="order", attrs={"user_id": 1001, "amount": 1500})
# 事实3:无效订单(用户ID=1001,金额500)
invalid_order = Fact(type="order", attrs={"user_id": 1001, "amount": 500})
print("=== 注入有效用户事实 ===")
alpha_user.process(user_fact) # 注入用户事实(Alpha层通过)
print("=== 注入无效订单事实 ===")
alpha_order.process(invalid_order) # 注入无效订单(Alpha层过滤,无触发)
print("=== 注入有效订单事实 ===")
alpha_order.process(order_fact) # 注入有效订单(Alpha+Beta匹配,触发规则)
if __name__ == "__main__":
main()代码说明:
- Fact 类:模拟业务中的事实数据(如用户、订单),包含类型和属性;
- AlphaNode:处理单事实过滤(如年龄 > 18、金额 > 1000),缓存满足条件的事实;
- BetaNode:处理多事实关联(如用户 ID = 订单用户 ID),缓存匹配的事实对;
- TerminalNode:规则匹配完成的出口,触发规则动作;
- 测试流程:注入不同事实,验证只有满足所有条件的事实组合才会触发规则。
执行过程:
事实注入 → Alpha 过滤 → Beta 关联 → 终端触发
↓ ↓ ↓ ↓
用户(25 岁) → 通过 (age>18) → 缓存左输入 → 等待右输入
订单 (500) → 拦截 (amount≤1000) → 不传递 → 无触发
订单 (1500) → 通过 (amount>1000) → 关联匹配 → ✅ 触发规则
- Alpha 层快速过滤:无效订单(500 元)在Alpha节点就被拦截,不会进入更耗资源的Beta层;
- Beta 层增量匹配:新事实只与已有缓存事实匹配,无需全量重算;
- 状态缓存:Alpha/Beta 节点都缓存中间结果,避免重复计算。
输出结果:
=== 注入有效用户事实 ===
=== 注入无效订单事实 ===
=== 注入有效订单事实 ===
✅ 规则高价值用户规则匹配成功!
匹配的事实对:Fact(type='user', attrs={'id': 1001, 'age': 25}) | Fact(type='order', attrs={'user_id': 1001, 'amount': 1500})
🚨 执行动作:发送高价值用户营销短信!
2. 金融转账:大模型+规则校验
python
import yaml
from openai import OpenAI
import json
# ====================== 1. 加载规则配置(规则引擎核心)======================
def load_rules(rule_path="rules.yaml"):
"""加载规则配置文件,模拟规则引擎的规则存储"""
try:
with open(rule_path, 'r', encoding='utf-8') as f:
rules = yaml.safe_load(f)
return rules
except FileNotFoundError:
# 默认规则配置
return {
"user_rules": {
"普通用户": {
"daily_transfer_limit": 50000,
"description": "单日转账限额5万元"
},
"VIP用户": {
"daily_transfer_limit": 200000,
"description": "单日转账限额20万元"
}
},
"risk_list": [
"6228480402564890123",
"6225880212345678"
]
}
# ====================== 2. 大模型建议模块 ======================
def init_llm():
"""初始化混元大模型客户端"""
client = OpenAI(
api_key='sk-bWlJPKjBrSFGoQ0Ys0maFwwSwtxkfK7tgmm0sBVXvZ5NP8Ze',
base_url="https://api.hunyuan.cloud.tencent.com/v1",
)
return client
def llm_analysis(user_request, user_info, rules, client):
"""
大模型分析用户请求,生成建议
:param user_request: 用户请求(如"转账20万给6228480402564890123")
:param user_info: 用户信息(如{"level": "普通用户", "daily_transfer_amount": 0})
:param rules: 规则配置
:param client: 混元大模型客户端
:return: 大模型分析建议
"""
# 构造大模型输入提示词(Prompt Engineering)
prompt = f"""
你是金融转账的智能分析助手,需要分析用户请求并给出建议。
规则:{json.dumps(rules['user_rules'][user_info['level']], ensure_ascii=False)}
用户请求:{user_request}
用户信息:{json.dumps(user_info, ensure_ascii=False)}
请你:
1. 提取关键信息:转账金额、收款账户;
2. 结合规则给出建议(仅回答"建议通过"/"建议拒绝"/"建议人工复核")。
请直接给出建议,不要过多解释。
"""
try:
# 调用混元大模型生成建议
completion = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{'role': 'system', 'content': '你是一个金融转账智能分析助手,负责分析用户转账请求并给出安全建议。'},
{'role': 'user', 'content': prompt}
],
temperature=0.3
)
result = completion.choices[0].message.content
# 提取建议
if "建议拒绝" in result:
suggestion = "建议拒绝"
elif "建议人工复核" in result:
suggestion = "建议人工复核"
else:
suggestion = "建议通过"
# 提取关键信息(正则匹配)
import re
amount_match = re.search(r'转账?\s*(\d+(?:,\d+)*)\s*元', user_request)
account_match = re.search(r'\b\d{16,19}\b', user_request)
amount = int(amount_match.group(1).replace(',', '')) if amount_match else None
account = account_match.group(0) if account_match else None
return {
"key_info": {"amount": amount, "account": account},
"suggestion": suggestion,
"raw_response": result
}
except Exception as e:
print(f"大模型调用失败: {e}")
# 降级处理:用简单规则
import re
amount_match = re.search(r'(\d+)\s*元', user_request)
account_match = re.search(r'\b\d{16,19}\b', user_request)
amount = int(amount_match.group(1)) if amount_match else None
account = account_match.group(0) if account_match else None
return {
"key_info": {"amount": amount, "account": account},
"suggestion": "建议通过",
"raw_response": "大模型调用失败,使用默认建议"
}
# ====================== 3. 规则引擎校验模块 ======================
def rule_engine_check(llm_result, user_info, rules):
"""
规则引擎执行校验(审批)
:param llm_result: 大模型分析结果
:param user_info: 用户信息
:param rules: 规则配置
:return: 校验结果、原因
"""
key_info = llm_result["key_info"]
user_level = user_info["level"]
daily_limit = rules["user_rules"][user_level]["daily_transfer_limit"]
risk_list = rules["risk_list"]
# 1. 金额阈值校验
if key_info["amount"] > daily_limit:
return False, f"用户等级为{user_level},单日转账限额{daily_limit}元,本次申请{key_info['amount']}元,超出阈值"
# 2. 风险账户校验
if key_info["account"] in risk_list:
return False, f"收款账户{key_info['account']}命中反诈黑名单,拒绝转账"
# 3. 权限校验(简化:默认有转账权限)
# 4. 流程校验(简化:默认符合流程)
return True, "所有规则校验通过,允许执行转账"
# ====================== 4. 主执行流程 ======================
def main():
# 1. 加载规则
rules = load_rules()
# 2. 初始化混元大模型
client = init_llm()
# 3. 模拟用户请求和用户信息
user_request = "我要转账200000元给6228480402564890123" # 20万,黑名单账户
user_info = {
"level": "普通用户",
"daily_transfer_amount": 0 # 今日已转账金额
}
# 4. 大模型分析(思考与建议)
llm_result = llm_analysis(user_request, user_info, rules, client)
print("===== 大模型分析结果 =====")
print(f"提取的关键信息:{llm_result['key_info']}")
print(f"大模型建议:{llm_result['suggestion']}")
if 'raw_response' in llm_result:
print(f"大模型原始响应:{llm_result['raw_response']}")
# 5. 规则引擎校验(审批与执行)
check_result, check_reason = rule_engine_check(llm_result, user_info, rules)
print("\n===== 规则引擎校验结果 =====")
print(f"校验通过:{check_result}")
print(f"原因:{check_reason}")
# 6. 执行动作
if check_result:
print("\n执行动作:完成转账")
else:
print("\n执行动作:拒绝转账")
if __name__ == "__main__":
main()代码解释:
- 规则加载模块:从YAML文件加载预设规则,模拟规则引擎的"规则库",可灵活配置不同用户的阈值、风险名单;
- 大模型模块:基于混元大模型能力,通过 Prompt 引导大模型提取关键信息、生成建议,核心是"只提建议,不做决策";
- 规则引擎模块:按"阈值校验→风险校验" 的顺序执行审批,每一步都有明确的规则和可解释的原因,核心是"只按规则审批,不做思考";
- 主流程:完整还原"用户请求→大模型分析→规则引擎审批→执行动作" 的核心逻辑。
准备基础数据:rules.yaml规则配置文件
bash
# 规则配置文件
user_rules:
普通用户:
daily_transfer_limit: 50000 # 单日转账限额5万
risk_check: True # 开启风险校验
VIP用户:
daily_transfer_limit: 200000 # 单日转账限额20万
risk_check: True
risk_list:
- "6228480402564890123" # 反诈黑名单账户输出结果:
===== 大模型分析结果 =====
提取的关键信息:{'amount': 200000, 'account': None}
大模型建议:建议通过
大模型原始响应:建议通过
===== 规则引擎校验结果 =====
校验通过:False
原因:用户等级为普通用户,单日转账限额50000元,本次申请200000元,超出阈值
六、总结
结合RETE算法和规则引擎,简单说就是在强合规的领域里,比如金融、政务这些不能出错的地方,大模型和规则引擎得搭伙干活,各干各的强项,少了谁都不行。大模型就负责动脑子、出主意,发挥它灵活的优势 ,比如用户提个请求,它先帮忙提取关键信息,分析用户到底想干嘛,还能给点合理的建议,不用我们手动去抠细节。而基于RETE算法的规则引擎,就负责拍板审批、落地执行,把安全底线锁死,比如预设好的阈值、黑名单,只要触碰一点,直接拒绝,绝不留情。
执行逻辑也很简单,一步一步来,每一步都能查、能追溯,完全符合合规要求:用户发请求→大模型先处理,提取信息、出建议→把结果交给规则引擎,多维度校验一遍→最后要么执行动作,要么直接拒绝。规则引擎靠预设好的规则实现审批,RETE 算法帮它提效;大模型就专注于信息提取、意图识别这些活。整个逻辑下来,核心就是互补:大模型补规则引擎的灵活性,规则引擎补大模型的安全性,既高效又合规。