一、前言
在数字化时代,匹配是贯穿各类场景的核心需求,题库要按知识点和难度自动组卷、企业要为岗位匹配最合适的候选人、客服系统要为用户问题匹配最精准的答案。这些场景的核心痛点有两个:一是如何理解匹配双方的语义内涵,比如"岗位要求的沟通能力"和"候选人简历中的协调经验"是否匹配;二是如何在理解的基础上实现全局最优配对,比如10个岗位匹配10个人,整体匹配度最高。
基于最优匹配的匈牙利算法解决的是最优配对的问题,而大模型解决的是语义理解与对齐的问题。今天我们就由浅入深拆解这一融合技术体系,通俗易懂的了解这个实用的智能匹配技术。

二、核心概念
1. 理解匹配
在日常生活中,"匹配" 无处不在:
- 在广大婚恋平台,平台会根据性格、兴趣、价值观匹配最合适的人;
- 网购时,平台会根据我们的浏览记录匹配最可能购买的商品;
- 考试组卷时,老师会根据知识点、难度、题型匹配符合要求的题目。
从技术角度,匹配的本质是在两个不同集合中建立元素间的关联关系,而最优匹配则是在所有可能的关联关系中,找到满足"全局收益最大化、成本最小化"的那一组。
通俗而言,假设一个HR,要为3个岗位(运营、技术、产品)匹配3个候选人(A、B、C)。如果只看"是否能做",可能有多种匹配方式,比如A做运营、B做技术、C做产品;或A做技术、B做产品、C做运营,但"最优匹配"是让 3 个岗位和候选人的匹配度总分最高的那一种。
2. 二分图
要理解匈牙利算法,首先要掌握"二分图"这个基础概念,这是所有匹配问题的数学载体,也是匈牙利算法的适用前提。
2.1 二分图的定义
二分图是一种特殊的图结构,它的所有顶点可以被划分为两个互不相交的集合,通常称为"左集合"和"右集合",且图中所有边的两个端点分别属于这两个集合,同一集合内的顶点之间没有边相连。
举个例子:
- 左集合:{岗位 1、岗位 2、岗位 3},右集合:{候选人 A、候选人 B、候选人 C};
- **边:**岗位1和候选人A之间有边(表示A能做岗位 1),岗位2和候选人B之间有边,但岗位1和岗位2之间没有边,候选人A和候选人B之间也没有边。
2.2 二分图的关键属性
- **顶点集划分:**必须严格分成两个不相交的集合,这是二分图的核心特征。判断一个图是否是二分图的简单方法:能否用两种颜色给所有顶点染色,使得相邻顶点颜色不同。
- **边的方向性:**二分图的边是无向的,但在匹配问题中,我们通常会给边赋予"权重",比如匹配度),此时边的权重是核心参考指标。
- 匹配的类型:
- 完美匹配:两个集合的顶点数量相同,且每个顶点都能找到唯一的匹配对象,比如3个岗位匹配3个候选人,每个岗位和候选人都有且仅有一个匹配;
- 最大匹配:在顶点数量不同时,找到能匹配的最多顶点对,比如5个候选人匹配3个岗位,最多匹配3对;
- 最优匹配:在所有匹配中,边的权重总和最大或最小的匹配,这是我们结合大模型的核心应用场景。
3. 匈牙利算法
匈牙利算法由匈牙利数学家提出,核心是从"最大匹配"到"最优匹配",最初用于解决二分图的"最大匹配" 问题,后来被扩展到"带权最优匹配",也称为KM算法,是匈牙利算法的升级版。
3.1 核心定位
- **基础版匈牙利算法:**解决是否能匹配的问题,目标是找到最多的匹配对,无权重的概念;
- **最优匹配版(KM 算法):**解决如何匹配最好的问题,目标是在带权重的二分图中,找到权重总和最大的完美匹配,若顶点数不同,可补0权重边转化为完美匹配。
3.2 大模型在匹配中的核心角色
在传统的匈牙利算法应用中,边的权重通常是人工定义的,比如岗位匹配中,"有5年经验"记8分,"有3年经验"记5分,但这种方式存在两个致命问题:
-
- 人工定义权重无法覆盖语义层面的匹配,比如"沟通能力强"和"擅长跨部门协调"本质是同一能力,但人工很难量化;
-
- 权重规则固定,无法适应复杂场景,比如不同行业对沟通能力的定义不同。
大模型的核心作用就是解决"语义对齐"问题,将非结构化的文本信息(如岗位描述、候选人简历、题目内容)转化为可量化的匹配权重,为匈牙利算法提供精准的输入。
简单来说:
- 大模型:负责理解语义,把"岗位要求"和"候选人能力"转化为0-100的匹配度分数;
- 匈牙利算法(KM):负责"最优配对",用这些分数找到全局最优的匹配组合。
4. 概念总结
- 二分图:匹配问题的数学载体,顶点分为两个不相交集合,边仅存在于集合间;
- 最优匹配:带权二分图中权重总和最大的完美匹配;
- 匈牙利算法(KM):实现最优匹配的核心算法;
- 大模型的角色:语义理解与对齐,输出量化的匹配权重。
三、基础知识
1. 二分图最优匹配的数学基础
1.1 权重矩阵:匹配问题的数值化表达
任何二分图最优匹配问题,都可以转化为"权重矩阵"的求解问题。假设左集合有 n 个元素(记为 X₁,X₂,...,Xₙ),右集合有 m 个元素(记为 Y₁,Y₂,...,Yₘ),权重矩阵 W 是一个 n×m 的矩阵,其中 W ij 表示 Xᵢ和 Yⱼ的匹配权重,即匹配度。
举个例子(岗位 - 候选人匹配):
| 候选人 A | 候选人 B | 候选人 C | |
|---|---|---|---|
| 运营岗 | 85 | 70 | 60 |
| 技术岗 | 50 | 90 | 80 |
| 产品岗 | 75 | 65 | 95 |
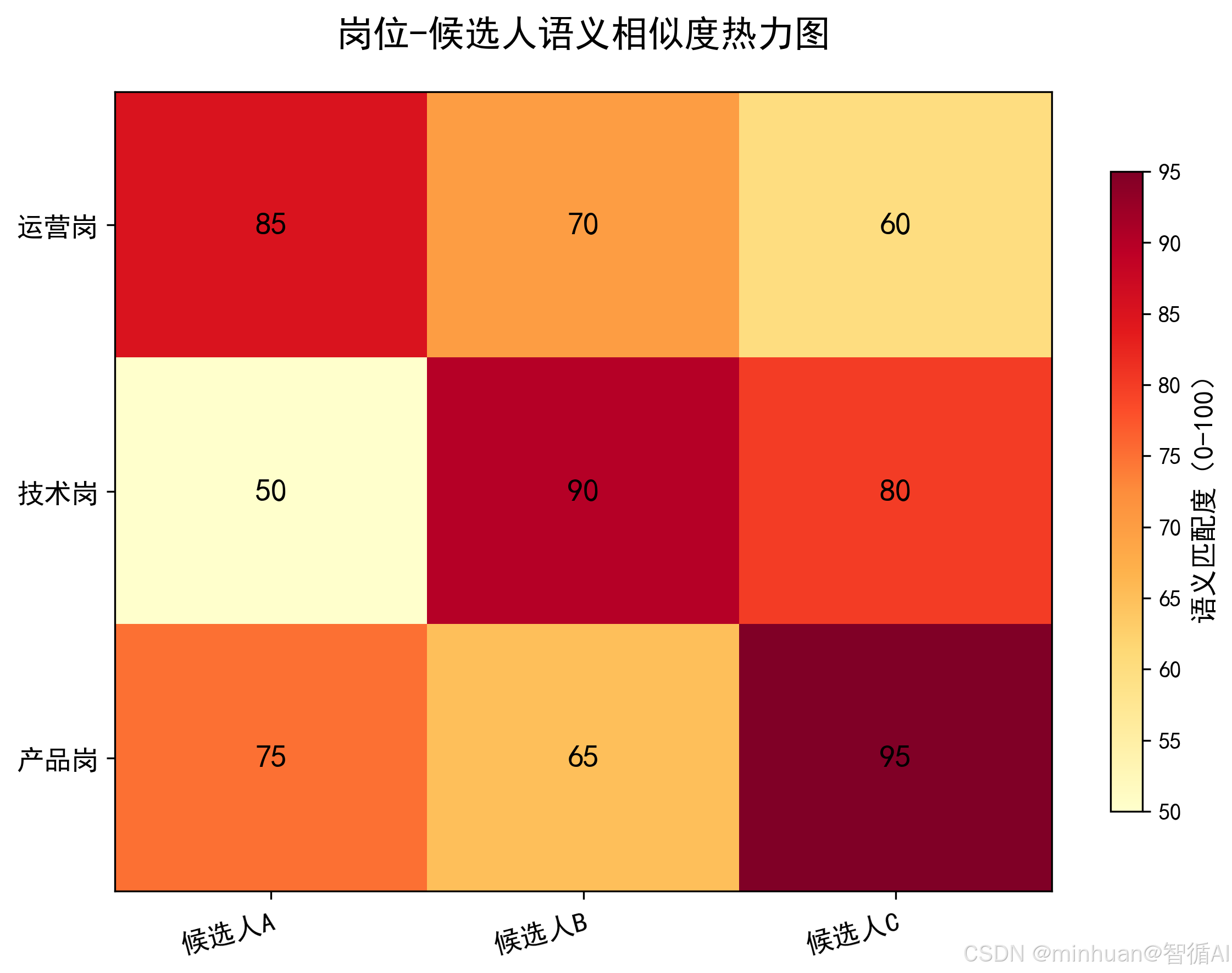
这个 3×3 的矩阵就是权重矩阵,我们的目标是从每行选一个数(每行仅选一个,每列仅选一个),使得总和最大。比如:
- 运营岗→A(85)、技术岗→B(90)、产品岗→C(95):总和 = 270;
- 运营岗→B(70)、技术岗→C(80)、产品岗→A(75):总和 = 225;
显然第一种是最优匹配。
1.2 可行顶标:KM 算法的核心工具
- KM 算法的核心思想: "通过顶标(顶点的权重)来寻找增广路,最终找到最优匹配"。
- **"可行顶标"的理解:**给每个顶点分配一个数值,使得任意一对匹配顶点的顶标之和≥它们之间的边权重,即对于 Xᵢ和 Yⱼ,有 lx i + ly j ≥ W ij。
- **KM 算法的目标:**找到一组可行顶标,使得存在完美匹配,且匹配边的顶标之和等于边权重之和,此时该匹配就是最优匹配。
1.3 相等子图:最优匹配的"候选池"
- 基于可行顶标,我们可以定义"相等子图":仅包含满足 lx i + ly j = W ij 的边的二分图。
- KM 算法的核心逻辑是:如果相等子图中存在完美匹配,那么这个匹配就是原二分图的最优匹配。
- 简单理解:相等子图是原二分图中"最有潜力"的边组成的子图,只要在这个子图中找到完美匹配,就一定是权重总和最大的。
2. 大模型的语义对齐基础
2.1 语义相似度:从"文字"到"数字"
大模型实现语义对齐的核心是"语义相似度计算",将文本转化为高维向量(Embedding),然后通过计算向量之间的相似度(如余弦相似度),得到0-1之间的相似度分数,也可放大为 0-100计算。
举个例子:
- 岗位描述:"要求具备良好的跨部门沟通能力,能协调多方资源推进项目";
- 候选人简历:"5 年项目管理经验,擅长协调研发、运营团队完成跨部门项目";
- 大模型会将这两段文本转化为向量,计算余弦相似度为 0.92,即92分,这个分数就是权重矩阵中的 W ij。
2.2 语义对齐的关键步骤

-
- 文本预处理:清洗无关信息,比如简历中的联系方式、岗位描述中的公司介绍;
-
- 文本向量化:将左集合和右集合的文本转化为Embedding向量;
-
- 相似度计算:用余弦相似度、欧氏距离等方法计算向量相似度;
-
- 分数归一化:将相似度分数转化为 0-100 的权重,方便后续算法计算。
四、核心原理
KM 算法是解决二分图最优匹配的核心,我们以"最大化权重总和"为目标,拆解其核心步骤,以n×n的完美匹配为例。
前置基础:
- 二分图的两个集合顶点数相同,若不同,补0权重边至相同;
- 权重矩阵为 n×n,元素为非负数,若有负数,可整体加一个常数转化为非负。
1. KM算法的核心步骤
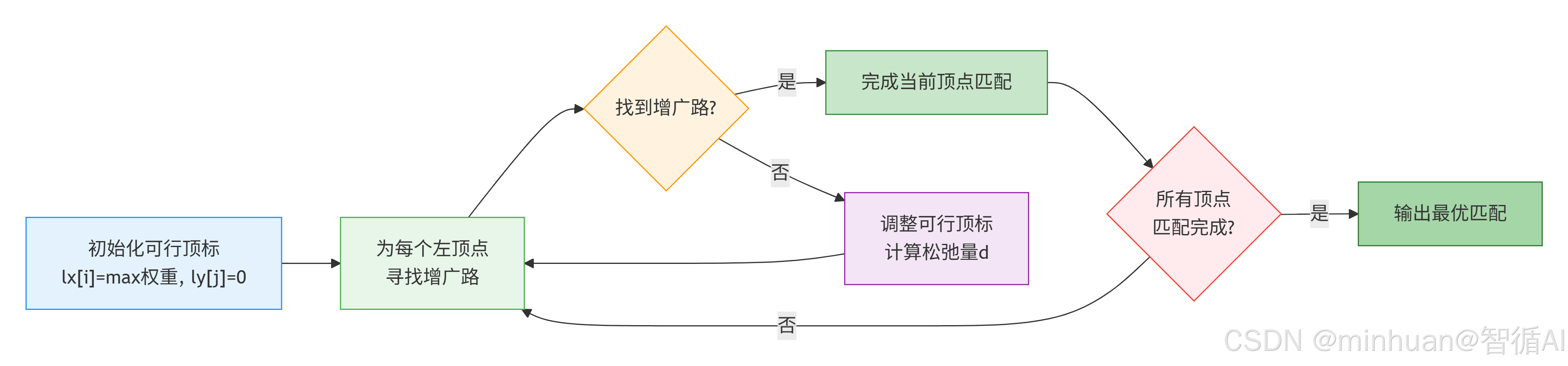
步骤 1:初始化可行顶标
- 左集合顶标 lx i:初始化为第i行的最大权重,lx i = max (W i0, W i1, ..., W in-1);
- 右集合顶标 ly j:初始化为 0;
这样初始化能保证 "lx i + ly j ≥ W ij",因为 lx i 是该行最大权重,ly j=0,所以和≥任意 W ij,满足可行顶标的要求。
步骤 2:为每个左集合顶点寻找增广路
增广路是 KM 算法的核心概念,我们可以理解为:"为当前顶点找到一个未被匹配的右集合顶点,或调整已有匹配,使得当前顶点能匹配到更优的右集合顶点"。
对于每个左集合顶点 Xᵢ:
-
- 初始化访问标记,标记哪些顶点已被访问,避免重复;
-
- 尝试为 Xᵢ找到匹配:遍历所有右集合顶点 Yⱼ,若 Yⱼ未被访问且 lx i + ly j = W ij,即属于相等子图,则标记 Yⱼ为已访问;
-
- 若 Yⱼ未被匹配,则找到增广路,完成匹配;若 Yⱼ已被匹配,则通过递归方式尝试为 Yⱼ的原匹配顶点寻找新的增广路;
-
- 若找不到增广路,说明当前相等子图中没有完美匹配,需要调整可行顶标。
步骤 3:调整可行顶标
当某个左集合顶点找不到增广路时,需要降低左集合顶点的顶标、提高右集合顶点的顶标,使得相等子图中加入新的边,即扩大候选池。
调整规则:
-
- 计算"松弛量"d:d = min (lx i + ly j - W ij),仅针对已访问的左顶点和未访问的右顶点;
-
- 已访问的左顶点顶标减 d;
-
- 已访问的右顶点顶标加 d;
-
- 调整后,原有相等子图的边仍满足 lx i+ly j=W ij,因为左减 d、右加 d,和不变,同时会有新的边加入相等子图,因为 lx i+ly j-W ij = d,调整后和为 W ij。
步骤 4:重复步骤 2-3,直到找到完美匹配
当所有左集合顶点都找到匹配时,此时的匹配就是最优匹配。
2. KM算法的实例推演
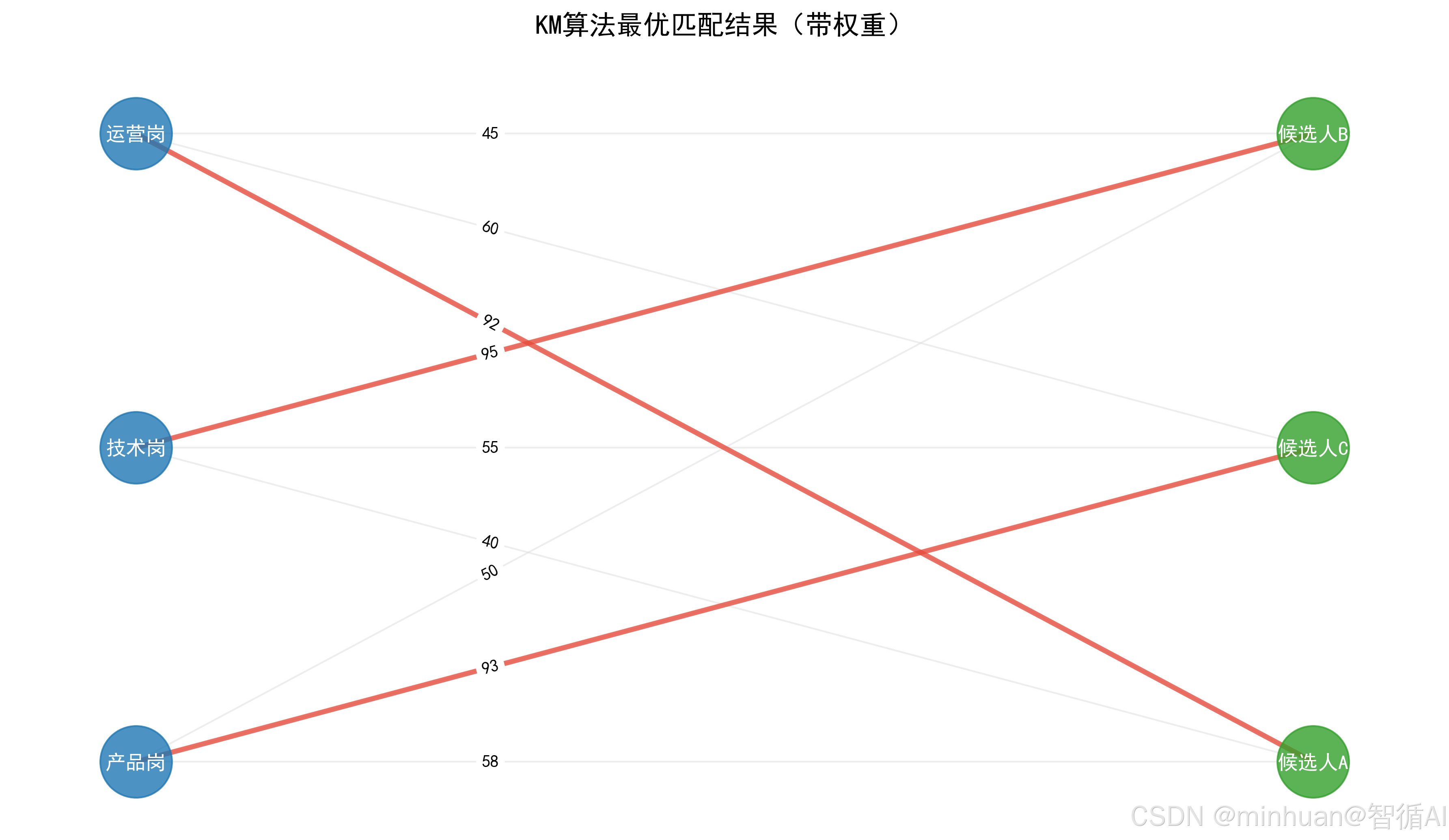
以之前的岗位 - 候选人权重矩阵为例:
权重矩阵W = [
85, 70, 60, # 运营岗
50, 90, 80, # 技术岗
75, 65, 95 # 产品岗
]
步骤 1:初始化顶标
- lx = 85, 90, 95,每行最大值;
- ly = 0, 0, 0。
步骤 2:为运营岗(X₀)找匹配
- 遍历 Y₀(候选人A):lx 0+ly 0 = 85 = W 00,Y₀未匹配,匹配 X₀→Y₀。
步骤 3:为技术岗(X₁)找匹配
- 遍历 Y₀:lx 1+ly 0 = 90 ≠ 50(W 10),跳过;
- 遍历 Y₁:lx 1+ly 1 = 90 = W 11,Y₁未匹配,匹配 X₁→Y₁。
步骤 4:为产品岗(X₂)找匹配
- 遍历 Y₀:lx 2+ly 0 = 95 ≠ 75,跳过;
- 遍历 Y₁:lx 2+ly 1 = 95 ≠ 65,跳过;
- 遍历 Y₂:lx 2+ly 2 = 95 = W 22,Y₂未匹配,匹配 X₂→Y₂。
此时所有顶点都匹配完成,匹配结果为:运营岗→A、技术岗→B、产品岗→C,总和 = 85+90+95=270,即最优匹配。
3. 大模型的语义对齐原理
大模型实现语义对齐实际是从文本到权重的过程,核心是"词嵌入(Word Embedding)"和"句嵌入(Sentence Embedding)",我们详细的拆解其原理。
3.1 文本向量化的本质
自然语言是离散的符号,比如"沟通能力"是4个汉字,计算机无法直接理解,因此需要将其转化为连续的数值向量,这个过程就是向量化。
大模型的向量化原理:
-
- 预训练阶段:模型通过海量文本学习到"语义相似的文本,向量距离更近"的规律,比如"沟通能力"和"协调能力"的向量夹角很小;
-
- 推理阶段:输入文本后,模型输出一个固定长度的向量,比如768维,这个向量包含了文本的语义信息。
3.2 相似度计算的数学原理
常用的相似度计算方法是 "余弦相似度",其公式为: (向量a·向量b)/(||向量a||×||向量b||)
其中:
- 向量a·向量b:向量 a 和 b 的点积;
- ||向量a||:向量 a 的模长;
- 余弦相似度的取值范围是 -1,1,越接近 1 表示语义越相似。
举个例子:
- 向量 a(沟通能力):0.2, 0.5, 0.8;
- 向量 b(协调能力):0.3, 0.4, 0.7;
- 点积:0.2×0.3 + 0.5×0.4 + 0.8×0.7 = 0.06 + 0.2 + 0.56 = 0.82;
- 模长:||a||=√(0.2²+0.5²+0.8²)=√(0.04+0.25+0.64)=√0.93≈0.96;||b||=√(0.3²+0.4²+0.7²)=√(0.09+0.16+0.49)=√0.74≈0.86;
- 余弦相似度:0.82/(0.96×0.86)≈0.82/0.8256≈0.993,即 99.3 分,说明语义高度相似。
3.3 大模型语义对齐的优化
- 文本截断:将长文本(如简历)截断为模型支持的最大长度,如512个字符,避免截断关键信息;
- 关键词提取:先提取文本中的核心关键词,如岗位要求的"沟通能力、Python、项目管理",再对关键词向量化,提升匹配精准度;
- 分数校准:对相似度分数进行归一化,如将-1,1转化为0,100,并根据业务场景调整权重,比如技术岗的"编程能力"权重更高。
4. 大模型 + KM算法的完整链路
现在我们将两者结合,形成完整的智能匹配链路:

关键节点说明:
- 文本预处理:去除无关信息,如简历中的手机号、岗位描述中的公司地址,统一格式,如小写、去除特殊符号;
- 向量化:使用大模型将预处理后的文本转化为 Embedding 向量;
- 相似度计算:计算左集合和右集合文本的余弦相似度;
- 分数归一化:将-1,1的相似度转化为0,100的权重,方便KM算法计算;
- 权重矩阵生成:将归一化后的分数按左、右集合的顺序排列,形成 n×m 的矩阵;
- KM 算法求解:对权重矩阵执行 KM 算法,得到最优匹配结果;
- 结果输出:展示匹配对(如"运营岗→候选人A")和总匹配度(如270分)。
五、示例实践
1. KM 算法实现最优匹配
本示例实现KM最优匹配算法:通过顶标初始化、增广路搜索、顶标调整三步骤,在二分图中寻找权重和最大的完美匹配。核心是用贪心+回溯策略,确保全局最优而非局部最优。适用于任务分配、资源调度等需最大化总效益的配对场景;
python
import numpy as np
class KMAlgorithm:
def __init__(self, weight_matrix):
"""
初始化KM算法
:param weight_matrix: 权重矩阵(n×n),numpy数组
"""
self.n = weight_matrix.shape[0] # 顶点数
self.weight = weight_matrix # 权重矩阵
self.lx = np.zeros(self.n) # 左集合顶标
self.ly = np.zeros(self.n) # 右集合顶标
self.match_to = -np.ones(self.n, dtype=int) # 右集合匹配的左顶点
self.visited_x = np.zeros(self.n, dtype=bool) # 左顶点访问标记
self.visited_y = np.zeros(self.n, dtype=bool) # 右顶点访问标记
self.slack = np.zeros(self.n) # 松弛量,优化查找效率
def find_augmenting_path(self, x):
"""
递归寻找增广路
:param x: 当前左顶点索引
:return: 是否找到增广路
"""
self.visited_x[x] = True
for y in range(self.n):
if not self.visited_y[y]:
# 计算当前顶标和与权重的差值
diff = self.lx[x] + self.ly[y] - self.weight[x][y]
if abs(diff) < 1e-6: # 差值足够小,视为相等(处理浮点误差)
self.visited_y[y] = True
# 如果y未匹配,或y的匹配顶点能找到新的增广路
if self.match_to[y] == -1 or self.find_augmenting_path(self.match_to[y]):
self.match_to[y] = x
return True
else:
# 更新松弛量
if self.slack[y] > diff:
self.slack[y] = diff
return False
def solve(self):
"""
执行KM算法,返回最优匹配结果和总权重
:return: 匹配结果(左顶点→右顶点)、总权重
"""
# 步骤1:初始化左集合顶标为每行最大值
for i in range(self.n):
self.lx[i] = np.max(self.weight[i])
# 步骤2:为每个左顶点寻找增广路
for x in range(self.n):
# 初始化松弛量为无穷大
self.slack = np.ones(self.n) * np.inf
while True:
# 重置访问标记
self.visited_x = np.zeros(self.n, dtype=bool)
self.visited_y = np.zeros(self.n, dtype=bool)
# 找到增广路,跳出循环
if self.find_augmenting_path(x):
break
# 未找到,调整顶标
d = np.min(self.slack[~self.visited_y]) # 计算松弛量d
# 已访问的左顶点顶标减d
self.lx[self.visited_x] -= d
# 已访问的右顶点顶标加d
self.ly[self.visited_y] += d
# 更新松弛量
self.slack[~self.visited_y] -= d
# 计算总权重和匹配结果
total_weight = 0
match_result = {}
for y in range(self.n):
x = self.match_to[y]
if x != -1:
total_weight += self.weight[x][y]
match_result[x] = y
return match_result, total_weight
# 测试KM算法
if __name__ == "__main__":
# 测试权重矩阵(岗位-候选人)
test_weight = np.array([
[92, 45, 60],
[40, 95, 55],
[58, 50, 93]
])
km = KMAlgorithm(test_weight)
match, total = km.solve()
print("最优匹配结果(左顶点索引→右顶点索引):", match)
print("总匹配度:", total)输出结果:
最优匹配结果(左顶点索引→右顶点索引): {np.int64(0): 0, np.int64(1): 1, np.int64(2): 2}
总匹配度: 280
2. 大模型 + KM算法完整实现
示例表示用BERT将文本转化为语义向量,通过余弦相似度量化匹配程度,再用KM算法求解全局最优分配。核心是将模糊的人岗匹配问题转化为可计算的数学问题,实现智能、公平、高效的资源分配决策。
python
import numpy as np
from scipy.spatial.distance import cosine
import networkx as nx
import matplotlib.pyplot as plt
from transformers import AutoTokenizer, AutoModel
import torch
from modelscope.hub.snapshot_download import snapshot_download
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial']
plt.rcParams['axes.unicode_minus'] = False
# ---------------------- 配置项 ----------------------
cache_dir = "D:\\modelscope\\hub"
model_name = "google-bert/bert-base-chinese"
# 下载模型到本地
local_model_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision="master"
)
# 加载模型和分词器
tokenizer = AutoTokenizer.from_pretrained(local_model_path)
model = AutoModel.from_pretrained(local_model_path)
# ---------------------- KM算法 ----------------------
class KMAlgorithm:
def __init__(self, weight_matrix):
self.n = weight_matrix.shape[0]
self.weight = weight_matrix
self.lx = np.zeros(self.n)
self.ly = np.zeros(self.n)
self.match_to = -np.ones(self.n, dtype=int)
self.visited_x = np.zeros(self.n, dtype=bool)
self.visited_y = np.zeros(self.n, dtype=bool)
self.slack = np.zeros(self.n)
def find_augmenting_path(self, x):
self.visited_x[x] = True
for y in range(self.n):
if not self.visited_y[y]:
diff = self.lx[x] + self.ly[y] - self.weight[x][y]
if abs(diff) < 1e-6:
self.visited_y[y] = True
if self.match_to[y] == -1 or self.find_augmenting_path(self.match_to[y]):
self.match_to[y] = x
return True
else:
if self.slack[y] > diff:
self.slack[y] = diff
return False
def solve(self):
for i in range(self.n):
self.lx[i] = np.max(self.weight[i])
for x in range(self.n):
self.slack = np.ones(self.n) * np.inf
while True:
self.visited_x = np.zeros(self.n, dtype=bool)
self.visited_y = np.zeros(self.n, dtype=bool)
if self.find_augmenting_path(x):
break
d = np.min(self.slack[~self.visited_y])
self.lx[self.visited_x] -= d
self.ly[self.visited_y] += d
self.slack[~self.visited_y] -= d
total_weight = 0
match_result = {}
for y in range(self.n):
x = self.match_to[y]
if x != -1:
total_weight += self.weight[x][y]
match_result[x] = y
return match_result, total_weight
# ---------------------- 大模型语义对齐 ----------------------
def get_embedding(text):
"""
使用本地BERT模型获取文本向量
:param text: 输入文本
:return: numpy向量
"""
text = text.replace("\n", " ")
try:
inputs = tokenizer(text, return_tensors="pt", padding=True, truncation=True, max_length=512)
with torch.no_grad():
outputs = model(**inputs)
# 取[CLS] token的向量作为文本的整体嵌入
embedding = outputs.last_hidden_state[:, 0, :].squeeze().numpy()
return embedding
except Exception as e:
print(f"获取向量失败:{e}")
return None
def calculate_similarity(vec1, vec2):
"""
计算两个向量的余弦相似度
:param vec1: 向量1
:param vec2: 向量2
:return: 相似度分数 (0-100)
"""
if vec1 is None or vec2 is None:
return 0.0
similarity = 1 - cosine(vec1, vec2)
return round(similarity * 100, 2)
# ---------------------- 可视化 ----------------------
def visualize_matching(jobs, candidates, match_result):
"""
可视化匹配结果
:param jobs: 岗位列表
:param candidates: 候选人列表
:param match_result: 匹配结果(岗位索引→候选人索引)
"""
# 创建二分图
G = nx.Graph()
# 添加左集合节点(岗位)
job_nodes = [f"岗位{i+1}: {jobs[i][:40]}..." for i in range(len(jobs))]
# 添加右集合节点(候选人)
cand_nodes = [f"候选人{chr(65+i)}: {candidates[i][:40]}..." for i in range(len(candidates))]
G.add_nodes_from(job_nodes, bipartite=0)
G.add_nodes_from(cand_nodes, bipartite=1)
# 添加所有边(非匹配边为灰色,匹配边为红色)
all_edges = []
match_edges = []
for i, job_node in enumerate(job_nodes):
for j, cand_node in enumerate(cand_nodes):
all_edges.append((job_node, cand_node))
if i in match_result and match_result[i] == j:
match_edges.append((job_node, cand_node))
# 绘制图形
pos = nx.bipartite_layout(G, job_nodes)
plt.figure(figsize=(12, 8))
# 绘制非匹配边
nx.draw_networkx_edges(G, pos, edgelist=all_edges, edge_color="gray", alpha=0.3, width=1)
# 绘制匹配边
nx.draw_networkx_edges(G, pos, edgelist=match_edges, edge_color="red", alpha=1.0, width=2)
# 绘制节点
nx.draw_networkx_nodes(G, pos, nodelist=job_nodes, node_color="lightblue", node_size=2000)
nx.draw_networkx_nodes(G, pos, nodelist=cand_nodes, node_color="lightgreen", node_size=2000)
# 绘制节点标签
nx.draw_networkx_labels(G, pos, font_size=8)
# 隐藏坐标轴
plt.axis("off")
plt.title("岗位-候选人最优匹配结果", fontsize=14, weight="bold")
plt.tight_layout()
plt.show()
# ---------------------- 主函数 ----------------------
if __name__ == "__main__":
# 1. 数据准备
jobs = [
"负责用户增长和活动运营,要求良好的沟通能力、文案能力,有1-3年运营经验",
"负责后端开发,要求熟练掌握Python、MySQL,有接口开发经验,逻辑思维强",
"负责产品需求分析和原型设计,要求用户思维、跨部门沟通能力,有产品规划经验"
]
candidates = [
"1年运营经验,擅长文案撰写和用户活动策划,沟通能力良好",
"3年Python开发经验,熟悉MySQL,做过多个接口开发项目,逻辑思维强",
"2年产品经验,擅长需求分析和原型设计,有跨部门协调经验,用户思维突出"
]
# 2. 文本向量化
print("正在获取文本向量...")
job_embeddings = [get_embedding(job) for job in jobs]
candidate_embeddings = [get_embedding(candidate) for candidate in candidates]
# 3. 计算相似度矩阵
print("正在计算相似度矩阵...")
similarity_matrix = np.zeros((len(jobs), len(candidates)))
for i, job_vec in enumerate(job_embeddings):
for j, cand_vec in enumerate(candidate_embeddings):
similarity_matrix[i][j] = calculate_similarity(job_vec, cand_vec)
print("相似度矩阵:")
print(similarity_matrix)
# 4. KM算法求解最优匹配
print("正在求解最优匹配...")
km = KMAlgorithm(similarity_matrix)
match_result, total_weight = km.solve()
print("最优匹配结果(岗位索引→候选人索引):", match_result)
print(f"总匹配度:{total_weight}")
# 5. 结果可视化
print("正在绘制匹配结果图...")
visualize_matching(jobs, candidates, match_result)
# 6. 输出可读的匹配结果
print("\n=== 最终匹配结果 ===")
job_names = ["运营岗", "技术岗", "产品岗"]
cand_names = ["候选人A", "候选人B", "候选人C"]
for job_idx, cand_idx in match_result.items():
print(f"{job_names[job_idx]} → {cand_names[cand_idx]}(匹配度:{similarity_matrix[job_idx][cand_idx]})")主要函数说明:
- KMAlgorithm 类:实现了完整的 KM 算法,包含初始化、增广路查找、顶标调整和结果计算;
- get_embedding 函数:调用本地的向量模型bert-base-chinese获取文本向量,处理了基本的异常;
- calculate_similarity 函数:计算余弦相似度并归一化到0-100;
- visualize_matching 函数:使用 NetworkX 和 Matplotlib 绘制二分图匹配结果,直观展示匹配关系;
- 主函数:串联整个流程,从数据准备到结果可视化,输出可读的匹配结果。
输出结果:
正在获取文本向量...
正在计算相似度矩阵...
相似度矩阵:
\[87.65000153 82.13999939 88.91999817
81.84999847 87.56999969 85.69000244
85.51999664 83.88999939 92.62000275\]
正在求解最优匹配...
最优匹配结果(岗位索引→候选人索引): {np.int64(0): 0, np.int64(1): 1, np.int64(2): 2}
总匹配度:267.84000396728516
正在绘制匹配结果图...
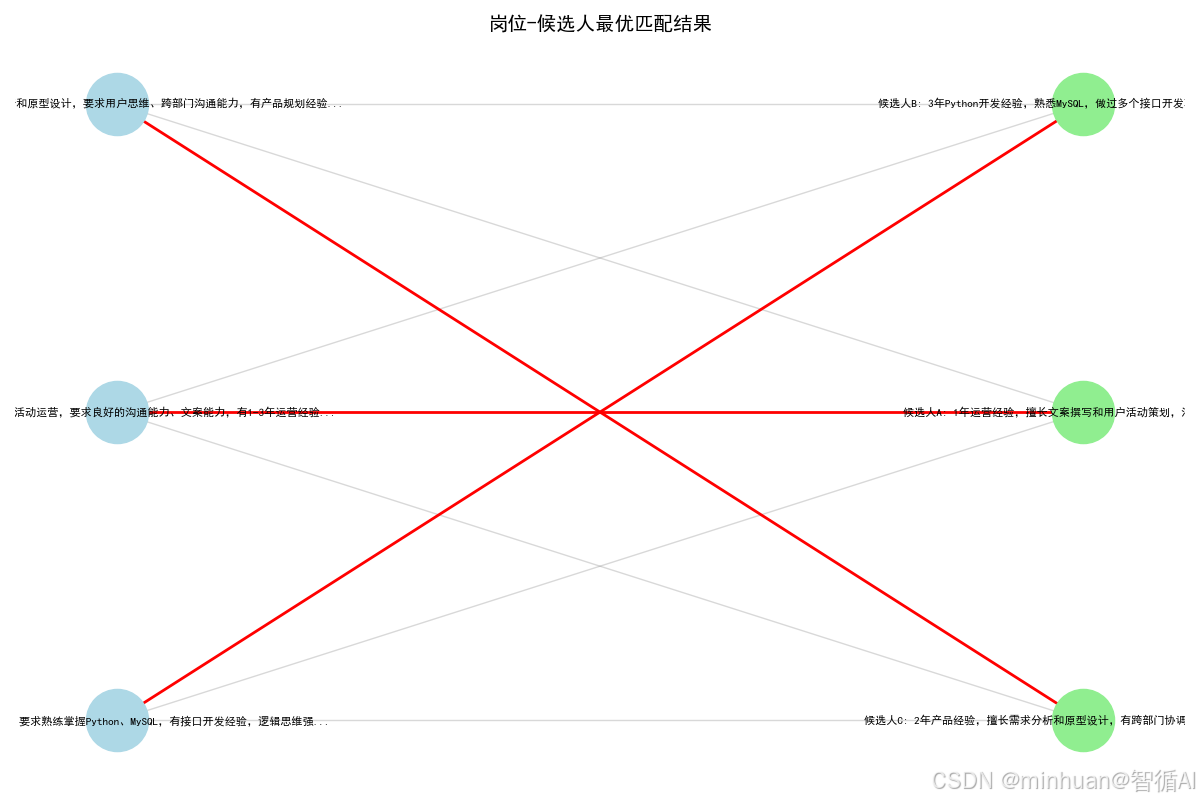
=== 最终匹配结果 ===
运营岗 → 候选人A(匹配度:87.6500015258789)
技术岗 → 候选人B(匹配度:87.56999969482422)
产品岗 → 候选人C(匹配度:92.62000274658203)
六、大模型的意义总结
1. 大模型解决了传统匹配的核心痛点
在大模型出现之前,传统的二分图最优匹配存在以下核心痛点:
- 权重定义人工化:匹配权重依赖人工规则,如"有Python经验记80分,无则记0分",规则繁琐且无法覆盖语义层面的匹配;
- 规则扩展性差:新增匹配维度(如"用户思维")需要重新定义规则,维护成本高;
- 语义理解缺失:无法识别"沟通能力"和"跨部门协调能力"是同一能力,导致匹配精准度低;
- 适配性差:不同行业、不同场景的匹配规则不同,传统方法无法快速适配。
大模型的出现彻底解决了这些问题:
- 语义理解自动化:无需人工定义规则,大模型能自动理解文本的语义内涵;
- 权重生成智能化:通过相似度计算自动生成权重,覆盖所有语义维度;
- 扩展性强:新增匹配维度只需输入新的文本,无需修改代码;
- 跨场景适配:同一套代码可适配岗位匹配、题库组卷、问题-答案匹配等多个场景。
2. 大模型在匹配流程中的核心作用
2.1 文本理解与归一化
大模型能将非结构化的文本转化为结构化的向量,实现语义归一化,比如:
- "Python熟练"、"精通 Python"、"有3年Python开发经验"都被转化为相似的向量;
- "用户增长"、"拉新"、"获客"都被识别为同一语义,避免因表述不同导致的匹配偏差。
2.2 权重的精准量化
传统方法的权重是"离散的",如 0/50/100,而大模型的权重是"连续的",如 92.3 分、85.7 分,能更精准地反映匹配程度。
2.3 复杂场景的适配
对于复杂场景,如"多维度匹配",大模型能自动融合多个维度的语义信息:
- 岗位匹配中,同时考虑"技能"、"经验"、"软能力"等维度,无需人工拆分;
- 题库组卷中,同时考虑"知识点"、"难度"、"题型"等维度,生成精准的权重。
3. 大模型与匈牙利算法的互补性
大模型和匈牙利算法是"智能匹配"的两个核心组件,互补性极强:
- 大模型负责"输入精准":确保权重矩阵能真实反映匹配双方的语义相似度;
- 匈牙利算法负责"输出最优":确保在精准的权重基础上,找到全局最优的匹配组合;
- 两者结合:实现"精准理解 + 最优配对"的端到端智能匹配,远超传统方法的效果。