1.队列是否一直存在?下一次定时任务是否要重新创建队列?
答:队列是否一直存在取决于队列是不是持久化的队列,如果是的话则一直存在不是的话就不是一直存在,比如说像rbmq,rocketmq这些中间件就是持久化存在的,启动时创建一次,然后就一直存在
java
@Configuration
public class RabbitMqConfig {
@Bean
public Queue myTaskQueue() {
// durable=true:持久化队列,Broker重启后仍存在
return QueueBuilder.durable("task.queue").build();
}
}像定时任务内部的内存队列(如 ThreadPoolExecutor),@Async的异步线程池,它们都是属于jvm层面的,每次启动会创建,每次关闭会销毁。
即;
- RabbitMQ 这类持久化中间件队列:创建后永久存在(除非手动删),仅首次启动创建一次,后续无需重建;
- JVM 内存队列(@Async / 定时任务线程池队列):项目关闭即销毁,每次项目启动都会重新创建(但启动后只创建一次,运行期间复用,不是每次执行任务都创建)。
2.消费者的并发线程数是多少?
消费者并发线程数没有固定值,核心取决于业务场景、硬件资源、消息生产速度、消费逻辑耗时:
- 理论参考值:
线程数 = CPU核心数 * (1 + 等待时间/计算时间)(阿姆达尔定律)。比如消费逻辑以 IO 等待(查 DB、调用接口)为主,等待时间远大于计算时间,线程数可设为 CPU 核心数的 2~4 倍;如果是纯内存计算,线程数接近 CPU 核心数即可。 - 项目实操:比如基于 RocketMQ 的订单消费场景,服务器是 8 核 16G,消费逻辑需要调用支付接口(IO 密集),最终设置并发线程数为 16~24,同时配合流控、重试机制,避免线程过多导致上下文切换频繁或数据库连接池耗尽。
3.JVM 内存调优(堆大小、新生代 / 老年代分配)
调优前必须先通过工具(JVisualVM、Arthas、Prometheus+Grafana)分析GC 日志、内存快照(heap dump),明确问题(如频繁 Full GC、OOM、Young GC 耗时过长),而非盲目调参。
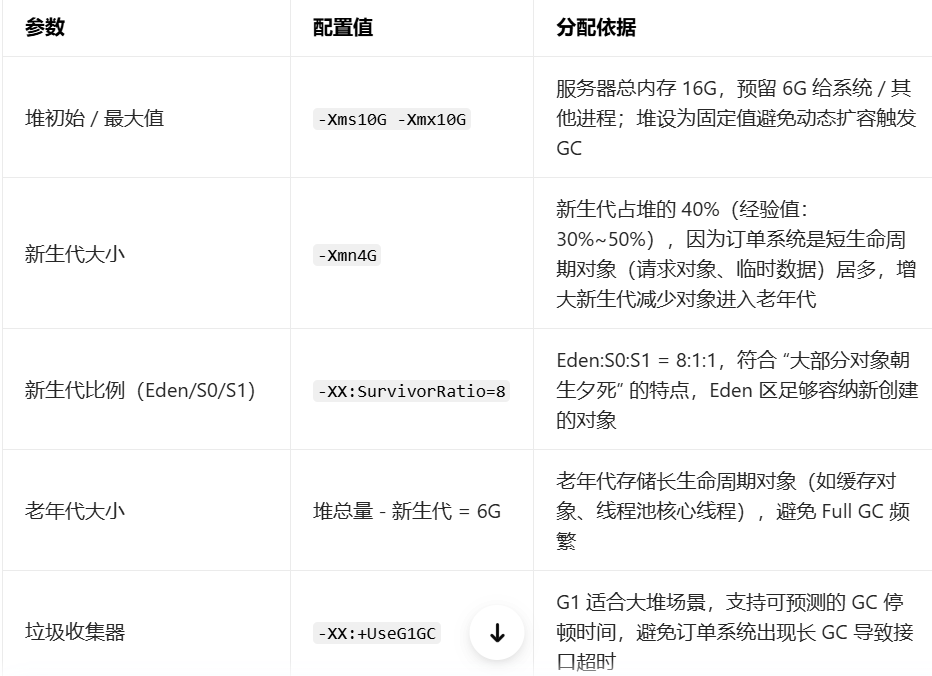
- 观察 Young GC 频率:从原来的 1 分钟 / 次优化为 5 分钟 / 次,单次耗时从 200ms 降至 50ms 以内;
- Full GC 频率:从原来的 1 小时 / 次降至 24 小时 / 次(仅凌晨低峰期出现);
- 接口响应时间:P99 从 500ms 降至 150ms 以内。
4.对 MySQL 索引的了解及项目中的使用场景?
索引本质:MySQL 索引是帮助引擎快速获取数据的数据结构(B + 树为主),核心作用是减少磁盘 IO,提升查询效率。
核心类型:聚簇索引(主键索引)、二级索引(普通索引、唯一索引、联合索引)、全文索引等
索引一般有:B+树,hash索引,倒排索引,R树索引。
索引从存储方式又分为:聚簇索引和非聚簇索引。
聚簇索引: 聚簇索引是基于主键构建的索引(主键索引)
非聚簇索引: 非主键的那些字段(也是索引)
-
一张表有很多棵 B+ 树
- 1 棵 聚簇索引树(主键)
- 每建一个普通索引,就多 1 棵 非聚簇索引树
-
**非聚簇索引树里存什么?**只存:
- 索引字段的值
- 主键 id不存其他数据。
-
查询流程
- 先走 非聚簇索引树
- 找到对应的 主键 id
- 拿着 id 去 聚簇索引树 查
- 聚簇索引的 叶子节点存整行数据
-
所有真实数据,只存在聚簇索引里
5.订单号长度不等时,索引如何处理?
订单号长度不等(比如有的是 16 位、有的是 20 位),只要订单号字段是字符串类型(VARCHAR/CHAR),创建索引依然生效,但需要注意:
- 建议使用
VARCHAR而非CHAR:CHAR 是定长,长度不等时会浪费存储空间;VARCHAR 是变长,仅存储实际长度 + 1 字节(长度标识); - 避免前缀截断:如果订单号长度差异大,不要盲目用
前缀索引(如KEY idx_order_sn (order_sn(10))),除非能保证前缀的唯一性,否则会导致索引失效或回表次数增加; - 项目实操:订单表
order_sn字段定义为VARCHAR(64),直接创建唯一索引UNIQUE KEY idx_order_sn (order_sn),即使长度不等,查询WHERE order_sn = 'xxx'依然能走索引,且效率不受影响。
6.可变字符串作为索引是否生效?会有什么问题?
订单号长度不等(比如有的是 16 位、有的是 20 位),只要订单号字段是字符串类型(VARCHAR/CHAR),创建索引依然生效,但需要注意:
- 建议使用
VARCHAR而非CHAR:CHAR 是定长,长度不等时会浪费存储空间;VARCHAR 是变长,仅存储实际长度 + 1 字节(长度标识); - 避免前缀截断:如果订单号长度差异大,不要盲目用
前缀索引(如KEY idx_order_sn (order_sn(10))),除非能保证前缀的唯一性,否则会导致索引失效或回表次数增加; - 项目实操:订单表
order_sn字段定义为VARCHAR(64),直接创建唯一索引UNIQUE KEY idx_order_sn (order_sn),即使长度不等,查询WHERE order_sn = 'xxx'依然能走索引,且效率不受影响。
7.联合索引的顺序与查询效率是否相关?
高度相关,核心遵循 "最左匹配原则":
- 联合索引的顺序决定了查询是否能命中索引,以及索引的筛选效率;
- 设计原则:区分度高的字段放前面(区分度 = 不同值的数量 / 总记录数)。
- 示例:项目中订单表的联合索引
idx_user_time (user_id, create_time):- 命中索引:
WHERE user_id = 100 AND create_time > '2026-01-01'(全匹配)、WHERE user_id = 100(左前缀匹配); - 不命中索引:
WHERE create_time > '2026-01-01'(跳过左前缀); - 效率差异:如果把区分度低的
create_time放前面,索引筛选性差,比如WHERE create_time > '2026-01-01' AND user_id = 100,即使能通过优化器调整顺序,但索引树的结构依然低效,查询时需要扫描更多索引节点。
- 命中索引:
8.聚簇索引能否手动单独建立多个?
不能。
- 聚簇索引的核心特点:InnoDB 引擎中,聚簇索引的叶子节点直接存储整行数据,且一张表只能有一个聚簇索引;
- 默认规则:InnoDB 会优先以主键 作为聚簇索引;如果没有主键,会选择第一个唯一非空索引;如果都没有,会隐式创建一个 6 字节的
row_id作为聚簇索引; - 注意:无法手动创建多个聚簇索引,因为这会导致数据存储结构混乱(整行数据无法同时存储在多个 B + 树的叶子节点),如果需要多维度查询,应创建二级索引(普通 / 联合索引),而非试图创建多个聚簇索引